Grype scans images for vulnerabilities, but who tests Grype? If Grype does or doesn’t find a given vulnerability in a given artifact, is it right? In this blog post, we’ll dive into yardstick, an open-source tool by Anchore for comparing the results of different vulnerability scans, both against each other and against data hand-labeled by security researchers.
Quality Gates
In Anchore’s CI pipelines, we have a concept we call a “quality gate.” A quality gate’s job is to ensure each change to each of our tools results in matching at least as good as the version before the change. To talk about quality gates, we need a couple of terms:
- Reference tool configuration, or just “reference tool” for short – this is an invocation of the tool (Grype, in this case) as it works today, without the change we are considering making
- Candidate tool configuration, or just “candidate tool” for short – this is an invocation the tool with the change we’re trying to verify. Maybe we changed Vunnel, or the grype source code itself, for example.
- Test images are images that Anchore has built that are known to have vulnerabilities
- Label data is data our researchers have labeled, essentially writing down, “for image A, for package B at version C, vulnerability X is really present (or is not really present)”
The important thing about the quality gate is that it’s an experiment – it changes only one thing to test the hypothesis. The hypothesis is always, “the candidate tool is as good or better than the reference tool,” and the one thing that’s different is the difference between the candidate tool and the reference tool. For example, if we’re testing a code change in Grype itself, the only difference between reference tool and candidate tool is the code change; the database of vulnerabilities will be the same for both runs. On the other hand, if we’re testing a change to how we build the database, the code for both Grypes will be the same, but the database used by the candidate tool will be built by the new code.
Now let’s talk through the logic of a quality gate:
- Run the reference tool and the candidate tool to get reference matches
- If both tools found nothing, the test is invalid. (Remember we’re scanning images that intentionally have vulnerabilities to test a scanner.)
- If both tools find exactly the same vulnerabilities, the test passes, because the candidate tool can’t be worse than the reference tool if they find the same things
- Finally, if both the reference tool and the candidate tool find at least one vulnerability, but not the same set of vulnerabilities, then we need to Do Match
Matching Math: Precision, Recall, and F1
The first math problem we do is easy: Did we add too many False Negatives? (Usually one is too many.) For example, if the reference tool found a vulnerability, and the candidate tool didn’t, and the label data says it’s really there, then the gate should fail – we can’t have a vulnerability matcher that misses things we know about!
The second math problem is also pretty easy: did we leave too many matches unlabeled? If we left too many matches unlabeled, we can’t do a comparison, because, if the reference tool and the candidate tool both found a lot of vulnerabilities, but we don’t know whether they’re really present or not, we can’t say which set of results is better. So the gate should fail and the engineer making the change will go and label more vulnerabilities.
Now, we get to the harder math. Let’s say the reference tool and the candidate tool both find vulnerabilities, but not exactly the same ones, and the candidate tool doesn’t introduce any false negatives. But let’s say the candidate tool does introduce a false positive or two, but it also fixes false positives and false negatives that the reference tool was wrong about. Is it better? Now we have to borrow some math from science class:
- Precision is the fraction of matches that are true positives. So if one of the tools found 10 vulnerabilities, and 8 of them are true positives, the precision is 0.8.
- Recall is the fraction of vulnerabilities that the tool found. So if there were 10 vulnerabilities present in the image and Grype found 9 of them, the recall is 0.9.
- F1 score is a calculation based on precision and recall that tries to reward high precision and high recall, while penalizing low precision and penalizing low recall. I won’t type out the calculation but you can read about it on Wikipedia or see it calculated in yardstick’s source code.
So what’s new in yardstick
Recently, the Anchore OSS team released the yardstick validate subcommand. This subcommand encapsulates the above work in a single command, which centralized a bunch of test Python spread out over the different OSS repositories.
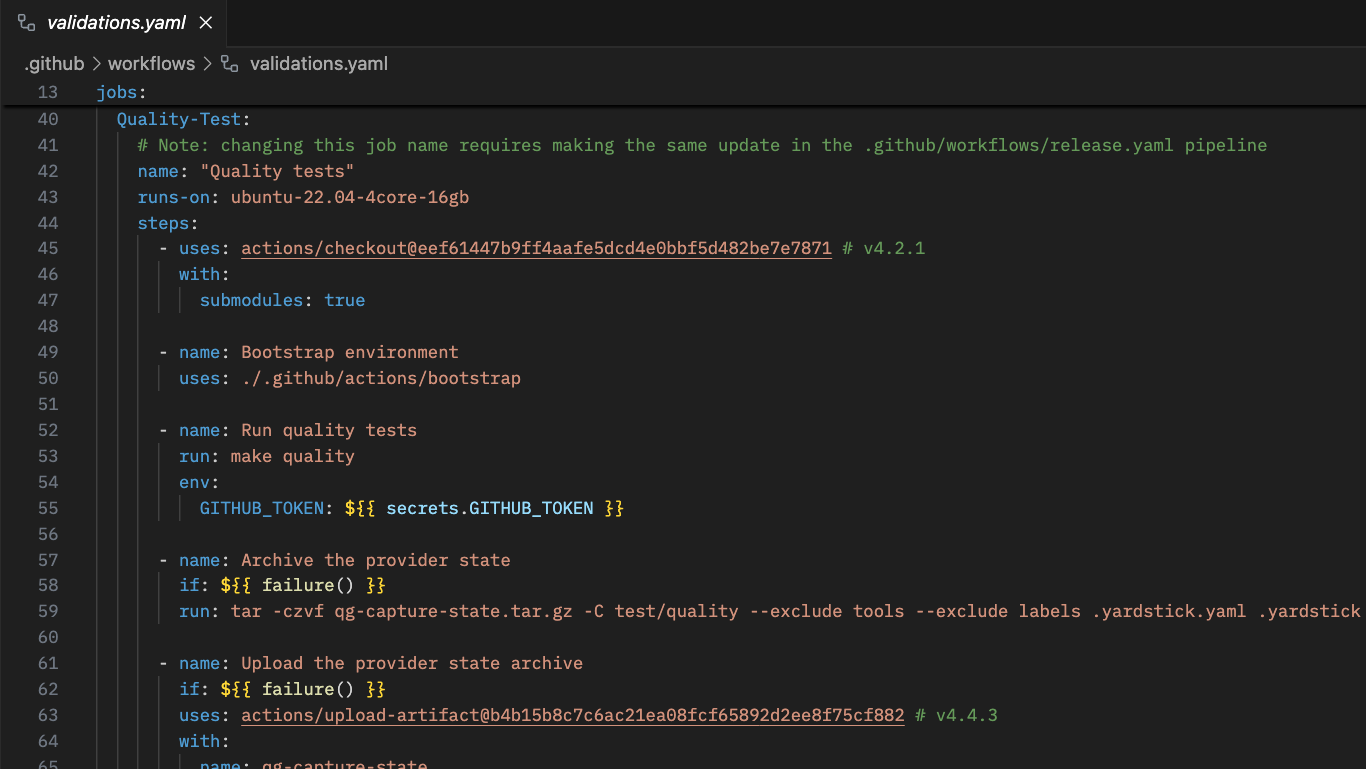
Now, to add a quality gate with a set of images, we just need to add some yaml like:
pr_vs_latest_via_sbom_2022:
description: "same as 'pr_vs_latest_via_sbom', but includes vulnerabilities from 2022 and before, instead of 2021 and before"
max_year: 2022
validations:
- max-f1-regression: 0.1 # allowed to regress 0.1 on f1 score
max-new-false-negatives: 10
max-unlabeled-percent: 0
max_year: 2022
fail_on_empty_match_set: false
matrix:
images:
- docker.io/anchore/test_images:azurelinux3-63671fe@sha256:2d761ba36575ddd4e07d446f4f2a05448298c20e5bdcd3dedfbbc00f9865240d
tools:
- name: syft
# note: we want to use a fixed version of syft for capturing all results (NOT "latest")
version: v0.98.0
produces: SBOM
refresh: false
- name: grype
version: path:../../+import-db=db.tar.gz
takes: SBOM
label: candidate # is candidate better than the current baseline?
- name: grype
version: latest+import-db=db.tar.gz
takes: SBOM
label: reference # this run is the current baselineWe think this change will make it easier to contribute to Grype and Vunnel. We know it helped out in the recent work to release Azure Linux 3 support.
If you’d like to discuss any topics this post raises, join us on discourse.