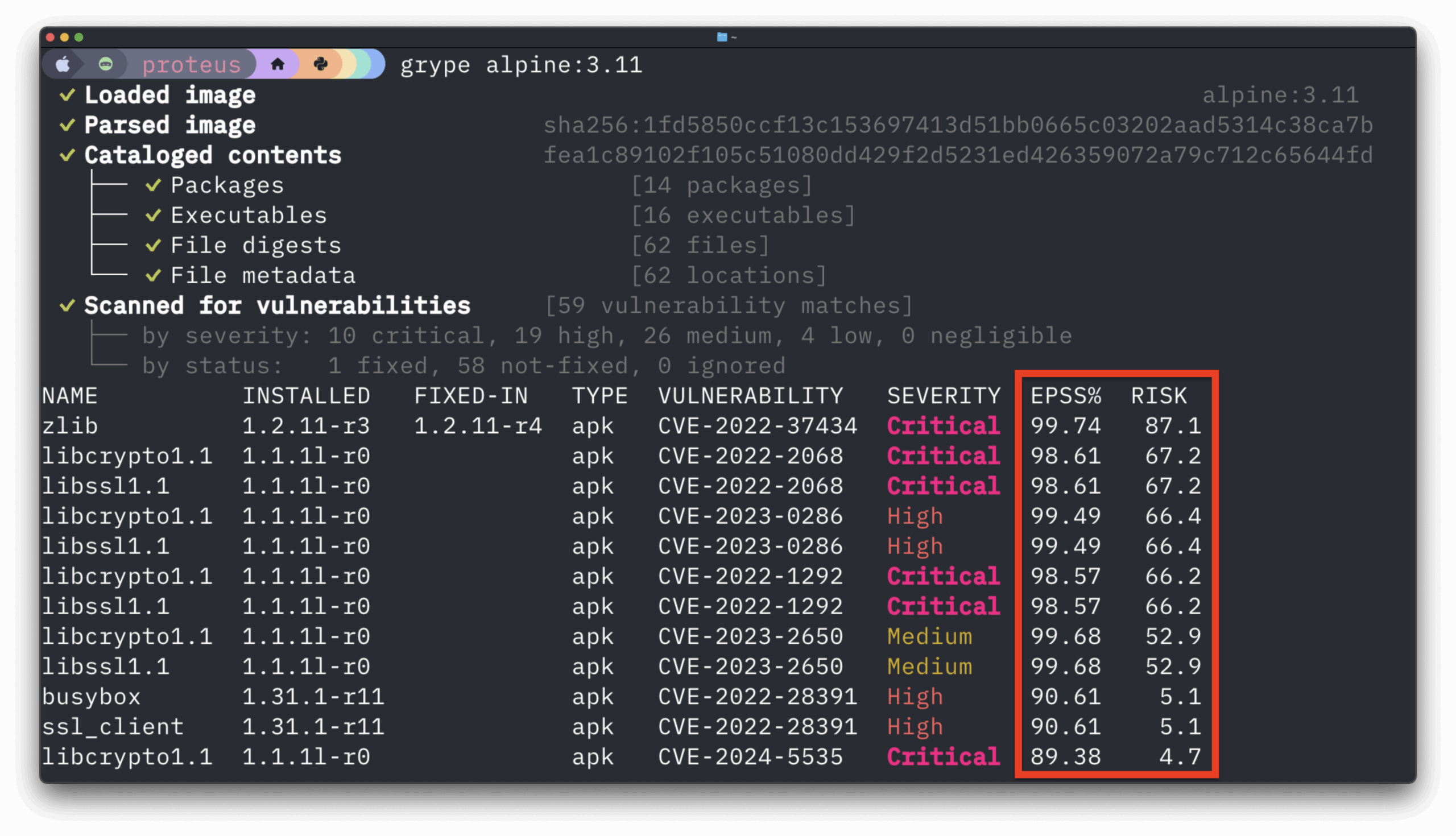
We often mention CVEs in our blogs but we usually skip over the topic, explaining that while CVE checking is important, it is just the tip of the iceberg and that you need to look deeper into the image to check configuration files, non-packaged files, software artifacts such as Ruby GEMs and Node.JS NPMs.
We recently got a Tweet from Marc Boorshtein from Tremolo Security asking why Anchore reported less CVEs in an image than were reported in scan results from the Docker Store.
interesting, @anchore scan shows much fewer CVE hits then @docker store for the same image. wonder why that is
— Marc Boorshtein (@mlbiam) March 31, 2017
So we’re going to take this opportunity to dig into some more details about CVEs to understand what they are, where the data comes from, and how we report on vulnerabilities, and then we’ll use that information to answer Marc’s question. For those who don’t want to read all the way through, the tl;dr here is that Anchore’s results are correct!
The Common Vulnerabilities and Exposures (CVE) system establishes a standard for reporting and tracking vulnerabilities. CVE Identifiers are assigned to vulnerabilities to make it easier to share and track information about these issues. The identifier takes the following form: CVE-YEAR-NUMBER, for example CVE-2014-0160.
The CVE identifier is the official way to track vulnerabilities, however, in some cases, well-known vulnerabilities are given names and even logos such as the famous Heartbleed vulnerability. Whether this trend of naming and branding vulnerabilities is a good thing is debatable. Some argue that this branding helps raise awareness others feel it’s a distraction. Either way this trend started by Codenomicon with Heartbleed has continued with many new vulnerabilities receiving catchy names such as Dirty Cow and Badlock. Not all serious vulnerabilities get branded and not all branded vulnerabilities are serious.
The CVE database is maintained by the Mitre Corporation under contract from the US Government. While Mitre retains responsibility for maintaining the CVE list there are a number of organizations who, under Mitre’s direction, can issue CVE numbers – these are called CVE Numbering Authorities. As of today, there are 53 organizations participating in this program, usually, these are hardware or software vendors such as Canonical, Google, IBM and Red Hat. Many vendors have their own vulnerability tracking databases and CVE helps by providing the glue that links these databases together, for example, a vulnerability in vendor’s hardware appliance may be traced back to an issue in a software library used by many other applications. Having a common identifier to refer to this issue simplifies tracking and reduces complexity.
Another database that you’ll see referenced frequently is the National Vulnerability Database (NVD) which is run by the National Institute of Science and Technology (NIST). This database builds on top of the CVE database by adding extra information such as severity scores, fix information and vendor-specific details.
Let’s use an example to dig deeper into CVEs:
CVE-2016-5195 is a bug that impacts the Linux kernel. It’s a race condition that if successfully exploited can allow local users to gain root privileges. This vulnerability is better known as “Dirty COW,” since it leverages incorrect handling of a copy-on-write (COW) feature.
Reading the details in the CVE database you can see that this issue impacts Linux kernel versions 2.x, 3.x and 4.x before version 4.8.3. More details can be found in the NVD database here. Listed in the NVD database you will find information about the severity score of the vulnerability and links to vendors advisories.
So, in theory, any Linux kernel prior to version 4.8.3 is vulnerable to this exploit however in practice things are more complicated. Take for example CentOS, where the latest available kernel is version 3.10 (or more accurately 3.10.0-514.10.2).
At first, you might expect this kernel to be vulnerable to “Dirty Cow” however Red Hat backported the fix from 4.8.3 into an older kernel version. Backporting is a popular practice for enterprise focussed software products whose users want to keep a well known, stable version of a software platform but still take advantage of security fixes or new features. Backporting selective features and fixes minimize the risk of adopting a completely new release of a software platform.
As you can see from this example, while the practice of backporting has many advantages for end-users it complicates the process of auditing installed software using the CVE database.
For this reason, many vendors produce their own vulnerability tracking feeds that link back to the CVE database but provides vendor-specific information. For example, Red Hat issues Red Hat Security Advisories (RHSAs) which are publicly available and can also be used to map between RHSAs and CVEs. Other distributions such as Debian, Oracle, SUSE and Oracle provide similarly detailed feeds.
These vendor-specific feeds contain valuable information that may not be easily obtained from the NVD database. For example, a Linux distributor may discern that while the upstream project that they are using for a given software package may be impacted with a certain CVE, the way that the package is configured and compiled on their platform may not be impacted by this CVE. A good example can be seen here in Debian’s security tracker. For this reason, a combination of using a vendor’s specific feed and whitelists will provide more accurate information in a security scan.
We started this blog by referencing a Tweet that compared Anchore’s scan results to Docker Store’s scan result. The image is question was based off CentOS so we will use this as the foundation for comparison.
You can view Anchore’s analysis of the latest CentOS image in the Anchore Navigator here:
Selecting the Security tab will show known vulnerabilities.
Inspecting the same image in DockerHub or DockerStore will show significantly more vulnerabilities. With at least 12 packages with critical vulnerabilities.
 For example, here we see that the bash package has 3 critical vulnerabilities two of which date back to 2014.
For example, here we see that the bash package has 3 critical vulnerabilities two of which date back to 2014.
Let’s review the first vulnerability: CVE-2014-6277:
While the CVE database does show that bash prior to version 4.3 is vulnerable to this CVE Red Hat’s analysis of the fixes applied in their release states the following:
Red Hat no longer considers this bug to be a security issue. The change introduced in bash errata RHSA-2014:1306, RHSA-2014:1311 and RHSA-2014:1312 removed the exposure of the bash parser to untrusted input, mitigating this problem to a bug without security impact.
Using Red Hat’s data feed allows us to benefit from their detailed analysis and provide more accurate and relevant information. While this requires that Anchore needs to add distribution specific features to our codebase the benefits far outweigh the cost.
Looking in detail through the results for CentOS in DockerStore and in Anchore we are confident that we are displaying the correct results, however, this leads to a very interesting question – how would you know if we were making a mistake?
In a previous blog, we discussed Hanlon’s Razor which states: “Never attribute to malice that which is adequately explained by stupidity.” Mistakes can obviously be made in security scanners, those mistakes could be deliberate – to purposely hide an issue for some nefarious reasons, but more likely they are just innocent mistakes. At Anchore we believe that security and analysis tools should be open source so that anyone can inspect the code to validate that the results are fair and accurate. In short, we live by the mantra “trust but verify.” But that all said, remember that CVEs are just the tip of the iceberg and you need to look far deeper into your images.