Just as the open source software revolution fundamentally transformed software development in the 2000s—bringing massive productivity gains alongside unprecedented supply chain complexity—we’re witnessing history repeat itself with Large Language Models (LLMs). The same pattern that caused organizations to lose visibility into their software dependencies is now playing out with LLMs, creating an entirely new category of supply chain risk.
Not to worry though, The Linux Foundation has been preparing for this eventuality. SPDX 3.0 provides the foundational metadata standard needed to extend proven DevSecOps practices to applications that integrate LLMs.
By introducing AI and Dataset Profiles, it enables organizations to apply the same supply chain security practices that have proven effective for software dependencies to the emerging world of AI supply chains. History may be repeating itself but this time, we have the opportunity to get ahead of it.
LLMs Create New Supply Chain Vulnerabilities That Traditional Security Tools Can’t Grok
The integration of LLMs into software applications has fundamentally altered the threat landscape. Unlike traditional software vulnerabilities that exploit code weaknesses, LLM-era attacks target the unique characteristics of AI systems:
- their training data is both data and code, and
- their behavior (i.e., both data and code) can be manipulated by users.
This represents a paradigm shift that requires security teams to think beyond traditional application security.
LLMs merge data and code + a second supply chain to secure
LLMs are fundamentally different from traditional software components. Where conventional code follows deterministic logic paths. LLMs operate on statistical patterns learned from “training” on datasets. This fundamental difference creates a new category of “code” that needs to be secured—not just the model weights and architecture, but the training data, fine-tuning datasets, and even the prompts that guide model behavior.
When organizations integrate LLMs into their applications, they’re not just adding another software dependency. They’re creating an entire second supply chain—the LLM data supply chain—that operates alongside their traditional software supply chain.

The challenge is that this new supply chain operates with fundamentally different risk patterns. Where software vulnerabilities are typically discrete and patchable, AI risks can be subtle, emergent, and difficult to detect.
- A single compromised dataset can introduce bias that affects all downstream applications.
- A prompt injection attack can manipulate model behavior without touching any traditional code.
- Model theft can occur through API interactions that leave no trace in traditional security logs.
Data poisoning and model theft: Novel attack vectors
The emergence of LLMs has introduced attack vectors that simply didn’t exist in traditional software systems, requiring security teams to expand their threat models and defensive strategies.
- Data Poisoning Attacks represent one of the most intractable new threat categories. Training data manipulation can occur at multiple points in the AI supply chain.
Consider this: what’s stopping a threat actor from modifying a public dataset that’s regularly used to train foundational LLM models? Popular datasets hosted on platforms like Hugging Face or GitHub can be edited by contributors, and if these poisoned datasets are used in model training, the resulting models inherit the malicious behavior.
RAG poisoning attacks take this concept further by targeting the retrieval systems that many production LLM applications rely on. Attackers can create SEO-optimized content and embed hidden text with instructions designed to manipulate the model’s behavior.
When RAG systems retrieve this content as context for user queries, the hidden instructions can override the model’s original alignment, leading to unauthorized actions or information disclosure. Recent research has demonstrated that attackers can inject as few as five poisoned documents into datasets of millions and achieve over 90% success rates in manipulating model outputs. - Model Theft and Extraction attacks exploit the API-accessible nature of modern LLM deployments. Through carefully crafted queries, attackers can extract valuable intellectual property without ever accessing the underlying model files. API-based extraction attacks involve sending thousands of strategically chosen prompts to a target model and using the responses to train a “shadow model” that replicates much of the original’s functionality.
Self-instruct model replication takes this further by using the target model to generate synthetic training data, effectively teaching a competitor model to mimic the original’s capabilities.
These attacks create new categories of business risk that organizations must consider. Beyond traditional concerns about data breaches or system availability, LLM-integrated applications face risks of intellectual property theft, reputational damage from biased or inappropriate outputs, and regulatory compliance violations in increasingly complex AI governance environments.
Enterprises are losing supply chain visibility as AI-native applications grow
Organizations are mostly unaware of the fact that the data supply chain for LLMs is equally as important to track as their software supply chain. As teams integrate foundation model APIs, deploy RAG systems, and fine-tune models for specific use cases, the complexity of LLM data supply chains is exploding.
Traditional security tools that excel at scanning software dependencies for known vulnerabilities are blind to LLM-specific risks like bias, data provenance, or model licensing complications.
This growing attack surface extends far beyond what traditional application security can address. When a software component has a vulnerability, it can typically be patched or replaced. When an AI model exhibits bias or has been trained on problematic data, the remediation may require retraining, which can cost millions of dollars and months of time. The stakes are fundamentally different, and the traditional reactive approach to security simply doesn’t scale.
So how do we deal with this fundamental shift in how we secure supply chains?
Next-Gen SBOM Formats Extend Proven Supply Chain Security to AI-Native Applications
The answer is—unsurprisingly—SBOMs. But more specifically, next-generation SBOM formats like SPDX 3.0. While Anchore doesn’t have an official tagline, if we did, there’s a strong chance it would be “you can’t secure your supply chain without knowing what is in it.” SPDX 3.0 has updated the SBOM standard to store AI model and dataset metadata, extending the proven principles of software supply chain security to the world of LLMs.
AI Bill of Materials: machine-readable security metadata for LLMs
SPDX 3.0 introduces AI and Dataset Profiles that create machine-readable metadata for LLM system components. These profiles provide comprehensive tracking of models, datasets, and their relationships, creating what’s essentially an “LLM Bill of Materials” that documents every component in an AI-powered application.
The breakthrough is that SPDX 3.0 increases visibility into AI systems by defining the key AI model metadata—read: security signals—that are needed to track risk and define enterprise-specific security policies. This isn’t just documentation for documentation’s sake; it’s about creating structured data that existing DevSecOps infrastructure can consume and act upon.
The bonus is that this works with existing tooling: SBOMs, CI/CD pipelines, vulnerability scanners, and policy-as-code evaluation engines can all be extended to handle AI profile metadata without requiring organizations to rebuild their security infrastructure from scratch.
Learn about how SBOMs have adapted to the world of micro-services architecture with the co-founder of SPDX and SBOMs.

3 novel security use-cases for AI-native apps enabled by SPDX 3.0
- Bias Detection & Policy Enforcement becomes automated through the knownBias field, which allows organizations to scan AI BOMs for enterprise-defined bias policies just like they scan software SBOMs for vulnerable components.
Traditional vulnerability scanners can be enhanced to flag models or datasets that contain documented biases that violate organizational policies. Policy-as-code frameworks can enforce bias thresholds automatically, preventing deployment of AI systems that don’t meet enterprise standards. - Risk-Based Deployment Gates leverage the safetyRiskAssessment field, which follows EU risk assessment methodology to categorize AI systems as serious, high, medium, or low risk.
This enables automated risk scoring in CI/CD pipelines, where deployment gates can block high-risk models from reaching production or require additional approvals based on risk levels. Organizations can set policy thresholds that align with their risk tolerance and regulatory requirements. - Data Provenance Validation uses fields like dataCollectionProcess and suppliedBy to track the complete lineage of training data and models. This enables allowlist and blocklist enforcement for data sources, ensuring that models are only trained on approved datasets.
Supply chain integrity verification becomes possible by tracking the complete chain of custody for AI components, from original data collection through model training and deployment.
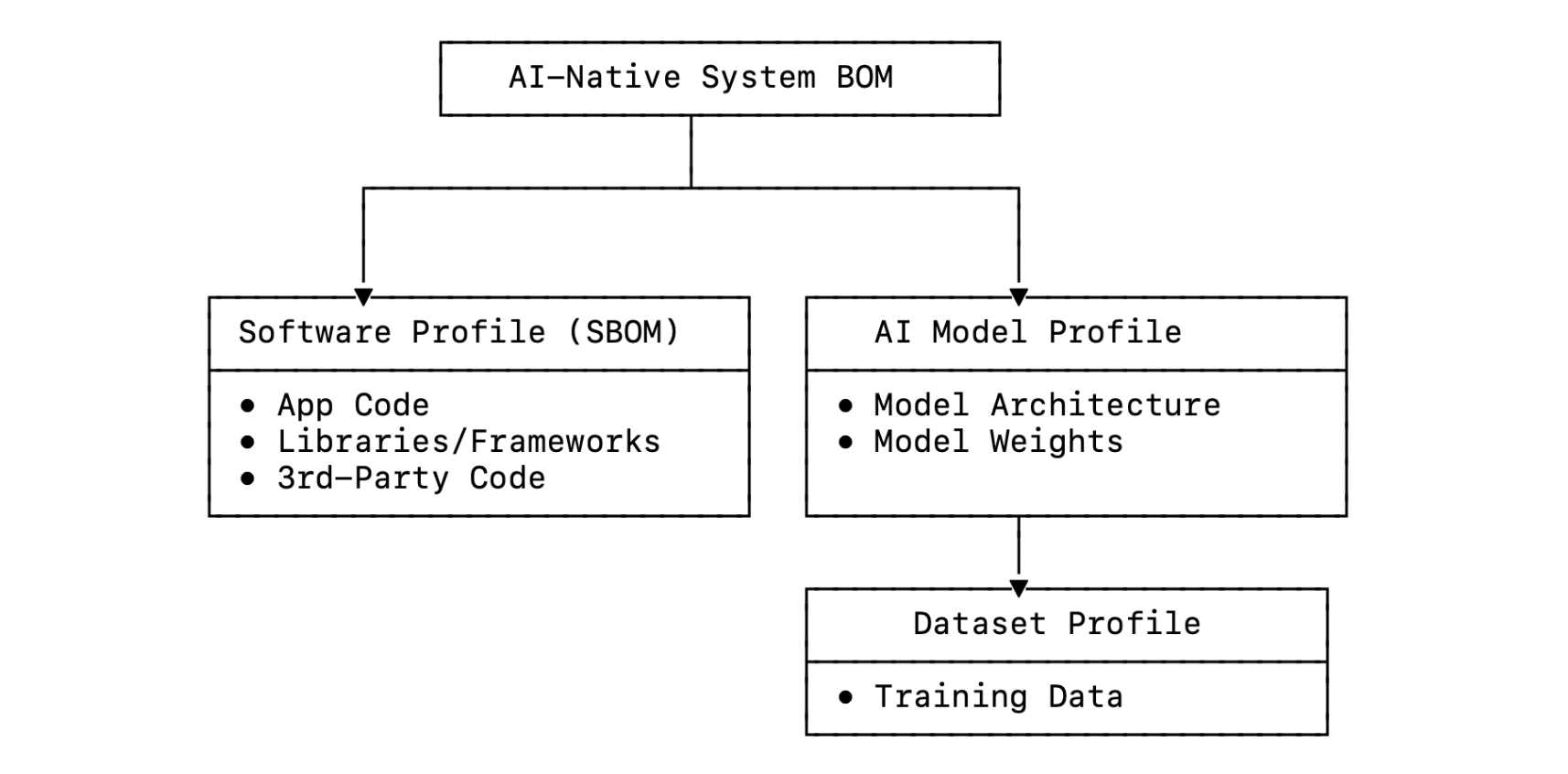
An SPDX 3.0 SBOM hierarchy for an AI-native application might look like this:

The key insight is that SPDX 3.0 makes AI systems legible to existing DevSecOps infrastructure. Rather than requiring organizations to build parallel security processes for AI workflows and components, it extends current security investments to cover the new AI supply chain. This approach reduces adoption friction by leveraging familiar tooling and processes that security teams already understand and trust.
History Repeats Itself: The Supply Chain Security Story
This isn’t the first time we’ve been through a transition where software development evolution increases productivity while also creating supply chain opacity. The pattern we’re seeing with LLM data supply chains is remarkably similar to what happened with the open source software explosion of the 2000s.
Software supply chains evolution: From trusted vendors to open source complexity to automated security
- Phase 1: The Trusted World (Pre-2000s) was characterized by 1st-party code and trusted commercial vendors. Organizations primarily wrote their own software or purchased it from established vendors with clear support relationships.
Manual security reviews were feasible because dependency trees were small and well-understood. There was high visibility into what components were being used and controlled dependencies that could be thoroughly vetted. - Phase 2: Open Source Software Explosion (2000s-2010s) brought massive productivity gains from open source libraries and frameworks. Package managers like npm, Maven, and PyPI made it trivial to incorporate thousands of 3rd-party components into applications.
Dependency trees exploded from dozens to thousands of components, creating a visibility crisis where organizations could no longer answer the basic question: “What’s actually in my application?”
This led to major security incidents like the Equifax breach (Apache Struts vulnerability), the SolarWinds supply chain attack, and the event-stream npm package compromise that affected millions of applications. - Phase 3: Industry Response (2010s-2020s) emerged as the security industry developed solutions to restore visibility and control.
SBOM standards like SPDX and CycloneDX provided standardized ways to document software components. Software Composition Analysis (SCA) tools proliferated, offering automated scanning and vulnerability detection for open source dependencies. DevSecOps integration and “shift-left” security practices made supply chain security a standard part of the development workflow.
LLM supply chains evolution: Same same—just faster
We’re now seeing this exact pattern repeat with AI systems, just compressed into a much shorter timeframe.
Phase 1: Model Gardens (2020-2023) featured trusted foundation models from established providers like OpenAI, Google, and Anthropic. LLM-powered application architectures were relatively simple, with limited data sources and clear model provenance.
Manual AI safety reviews were feasible because the number of models and data sources was manageable. Organizations could maintain visibility into their AI components through manual processes and documentation.
Phase 2: LLM/RAG Explosion (2023-Present) has brought foundation model APIs that enable massive productivity gains for AI application development.
Complex AI supply chains now feature transitive dependencies where models are fine-tuned on other models, RAG systems pull data from multiple sources, and agent frameworks orchestrate multiple AI components.
We’re currently re-living the same but different visibility crisis where organizations have lost the ability to understand the supply chains that power their production systems. Emerging attacks like data poisoning, and model theft are targeting these complex supply chains with increasing sophistication.
Phase 3: Industry Response (Near Future) is just beginning to emerge. SBOM standards like SPDX 3.0 are leading the charge to re-enable supply chain transparency for LLM supply chains constructed from both code and data. AI-native security tools are starting to appear, and we’re seeing the first extensions of DevSecOps principles to AI systems.
Where do we go from here?
We are still in the early stages of new software supply chain evolution, which creates both risk and opportunity for enterprises. Those who act now can establish LLM data supply chain security practices before the major attacks hit, while those who wait will likely face the same painful lessons that organizations experienced during the software supply chain security crisis of the 2010s.
Crawl: Embed SBOMs into your current DevSecOps pipeline
A vital first step is making sure you have a mature SBOM initiative for your traditional software supply chains. You won’t be ready for the future transition to LLM supply chains without this base.
This market is mature and relatively lightweight to deploy. It will power software supply chain security or up-level current software supply chain security (SSCS) practices. Organizations that have already invested in SBOM tooling and processes will find it much easier to extend these capabilities to an AI-native world.
Walk: Experiment with SPDX 3.0 and system bills of materials
Early adopters who want to over-achieve can take several concrete steps:
- Upgrade to SPDX 3.0 and begin experimenting with the AI and Dataset Profiles. Even if you’re not ready for full production deployment, understanding the new metadata fields and how they map to your LLM system components will prepare you for the tooling that’s coming.
- Begin testing AI model metadata collection by documenting the models, datasets, and AI components currently in use across your organization. This inventory process will reveal gaps in visibility and help identify which components pose the highest risk.
- Insert AI metadata into SBOMs for applications that already integrate AI components. This creates a unified view of both software and LLM dependencies, enabling security teams to assess risk across the entire application stack.
- Explore trends and patterns to extract insights from your LLM component inventory. Look for patterns in data sources, model licensing, risk levels, and update frequencies that can inform policy development.
This process will eventually evolve into a full production LLM data supply chain security capability that will power AI model security at scale. Organizations that begin this journey now will have significant advantages as AI supply chain attacks become more sophisticated and regulatory requirements continue to expand.
The window of opportunity is open, but it won’t remain that way indefinitely. Just as organizations that ignored software supply chain security in the 2000s paid a heavy price in the 2010s, those who ignore AI supply chain security today will likely face significant challenges as AI attacks mature and regulatory pressure increases.
Follow us on LinkedIn or subscribe to our newsletter to stay up-to-date on progress. We will continue to update as this space evolves, sharing practical guidance and real-world experiences as organizations begin implementing LLM data supply chain security at scale.
Explore SBOM use-cases for almost any department of the enterprise and learn how to unlock enterprise value to make the most of your software supply chain.



