When CVE-2025-1974 (#IngressNightmare) was disclosed, incident response teams had hours—at most—before exploits appeared in the wild. Imagine two companies responding:
- Company A rallies a war room with 13 different teams frantically running kubectl commands across the org’s 30+ clusters while debugging inconsistent permission issues.
- Company B’s security analyst runs a single query against their centralized SBOM inventory and their policy-as-code engine automatically dispatches alerts and remediation recommendations to affected teams.
Which camp would you rather be in when the next critical CVE drops? Most of us prefer the team that built visibility for their software supply chain security before the crisis hit.
CVE-2025-1974 was particularly acute because of ingress-nginx‘s popularity as a Kubernetes Admission Controller (40%+ of Kubernetes administrators) and the type/severity of the vulnerability (RCE & CVSS 9.8—scary!) We won’t go deep on the details; there are plenty of good existing resources already.
Instead we’ll focus on:
- The inconsistency between the naive incident response guidance and real-world challenges
- The negative impacts common to incident response for enterprise-scale Kubernetes deployments
- How Anchore Enterprise alleviates these consequences
- The benefits of an integrated incident response strategy
- How to utilize Anchore Enterprise to respond in real-time to a security incident
Learn how SBOMs enable organizations to react to zero-day disclosures in minutes rather than days or weeks.

An Oversimplified Response to a Complex Threat
When the Ingress Nightmare vulnerability was published, security blogs and advisories quickly filled with remediation advice. The standard recommendation was clear and seemed straightforward: run a simple kubectl command to determine if your organization was impacted:
kubectl get pods --all-namespaces --selector app.kubernetes.io/name=ingress-nginxIf vulnerable versions were found, upgrade immediately to the patched versions.
This advice isn’t technically wrong. The command will indeed identify instances of the vulnerable ingress-nginx controller. But it makes a set of assumptions that bear little resemblance to Kubernetes deployments in modern enterprise organizations:
- That you run a single Kubernetes cluster
- That you have a single Kubernetes administrator
- That this admin has global privileges across the entire cluster
For the vast majority of enterprises today, none of these assumptions are true.
The Reality of Enterprise-Scale Kubernetes: Complex & Manual
The reality of Kubernetes deployments at large organizations is far more complex than most security advisories acknowledge:
1. Inherited Complexity
Kubernetes administration structures almost always mirror organizational complexity. A typical enterprise doesn’t have a single cluster managed by a single team—they have dozens of clusters spread across multiple business units, each with their own platform teams, their own access controls, and often their own security policies.
This organizational structure, while necessary for business operations, creates significant friction for vital incident response activities; vulnerability detection and remediation. When a critical CVE like Ingress Nightmare drops, there’s no single person who can run that kubectl command across all environments.
2. Vulnerability Management Remains Manual
While organizations have embraced Kubernetes to automate their software delivery pipelines and increase velocity, the DevOps-ification of vulnerability and patch management have lagged. Instead they retain their manual, human-driven processes.
During the Log4j incident in 2021, we observed engineers across industries frantically connecting to servers via SSH and manually dissecting container images, trying to determine if they were vulnerable. Three years later, for many organizations, the process hasn’t meaningfully improved—they’ve just moved the complexity to Kubernetes.
The idea that teams can manually track and patch vulnerabilities across a sprawling Kubernetes estate is not just optimistic—it’s impossible at enterprise-scale.
The Cascading Negative Impacts: Panic, Manual Coordination & Crisis Response
When critical vulnerabilities emerge, organizations without supply chain visibility face:
- Organizational Panic: The CISO demands answers within the hour while security teams scramble through endless logs, completely blind to which systems contain the vulnerable components.
- Complex Manual Coordination: Security leads discover they need to scan hundreds of clusters but have access to barely a fifth of them, as Slack channels erupt with conflicting information and desperate access requests.
- Resource-Draining Incident Response: By day three of the unplanned war room, engineers with bloodshot eyes and unchanged clothes stare at monitors, missing family weekends while piecing together an ever-growing list of affected systems.
- Delayed Remediation: Six weeks after discovering the vulnerability in a critical payment processor, the patch remains undeployed as IT bureaucracy delays the maintenance window while exposed customer data hangs in the balance.
The Solution: Centralized SBOM Inventory + Automated Policy Enforcement
Organizations with mature software supply chain security leverage Anchore Enterprise to address these challenges through an integrated SBOM inventory and policy-as-code approach:
1. Anchore SBOM: Comprehensive Component Visibility
Anchore Enterprise transforms vulnerability response through its industry-leading SBOM repository. When a critical vulnerability like Ingress Nightmare emerges, security teams use Anchore’s intuitive dashboard to instantly answer the existential question: “Are we impacted?”
This approach works because:
- Role-based access to a centralized inventory is provided by Anchore SBOM for security incident response teams, cataloging every component across all Kubernetes clusters regardless of administrative boundaries
- Components missed by standard package manager checks (including binaries, language-specific packages, and container base images) are identified by AnchoreCTL, a modern software composition analysis (SCA) scanner
- Vulnerability correlation in seconds is enabled through Anchore SBOM’s repository with its purpose-built query engine, turning days of manual work into a simple search operation
2. Anchore Enforce: Automated Policy Enforcement
Beyond just identifying vulnerable components, Anchore Enforce’s policy engine integrates directly into an existing CI/CD pipeline (i.e., policy-as-code security gates). This automatically answers the follow-up questions: “Where and how do we remediate?”
Anchore Enforce empowers teams to:
- Alert code owners to the specific location of vulnerable components
- Provide remediation recommendations directly in developer workflows (Jira, Slack, GitLab, GitHub, etc.)
- Eliminate manual coordination between security and development teams with the policy engine and DevTools-native integrations
Quantifiable Benefits: No Panic, Reduced Effort & Reduced Risk
Organizations that implement this approach see dramatic improvements across multiple dimensions:
- Eliminated Panic: The fear and uncertainty that typically accompany vulnerability disclosures disappear when you can answer “Does this impact us?” in minutes rather than days.
- Immediate clarity on the impact of the disclosure is at your finger tips with the Anchore SBOM inventory and Kubernetes Runtime Dashboard
- Reduced Detection Effort: The labor-intensive coordination between security, platform, and application teams becomes unnecessary.
- Security incident response teams already have access to all the data they need through the centralized Anchore SBOM inventory generated as part of normal CI/CD pipeline use.
- Minimized Exploitation Risk: The window of vulnerability shrinks dramatically as developers are able to address vulnerabilities before they can be exploited.
- Developers receive automated alerts and remediation recommendations from Anchore Enforce’s policy engine that integrate natively with existing development workflows.
How to Mitigate CVE-2025-1974 with Anchore Enterprise
Let’s walk through how to detect and mitigate CVE-2025-1974 with Anchore Enterprise across a Kubernetes cluster. The Kubernetes Runtime Dashboard serves as the user interface for your SBOM database. We’ll demonstrate how to:
- Identify container images with
ingress-nginxintegrated - Locate images where CVE-2025-1974 has been detected
- Generate reports of all vulnerable container images
- Generate reports of all vulnerable running container instances in your Kubernetes cluster
Step 1: Identify location(s) of impacted assets

The Anchore Enterprise Dashboard can be filtered to show all clusters with the ingress-nginx controller deployed. Thanks to the existing SBOM inventory of cluster assets, this becomes a straightforward task, allowing you to quickly pinpoint where vulnerable components might exist.
Step 2: Drill into container image analysis for additional details

By examining vulnerability and policy compliance analysis at the container image level, you gain increased visibility into the potential cluster impact. This detailed view helps prioritize remediation efforts based on risk levels.
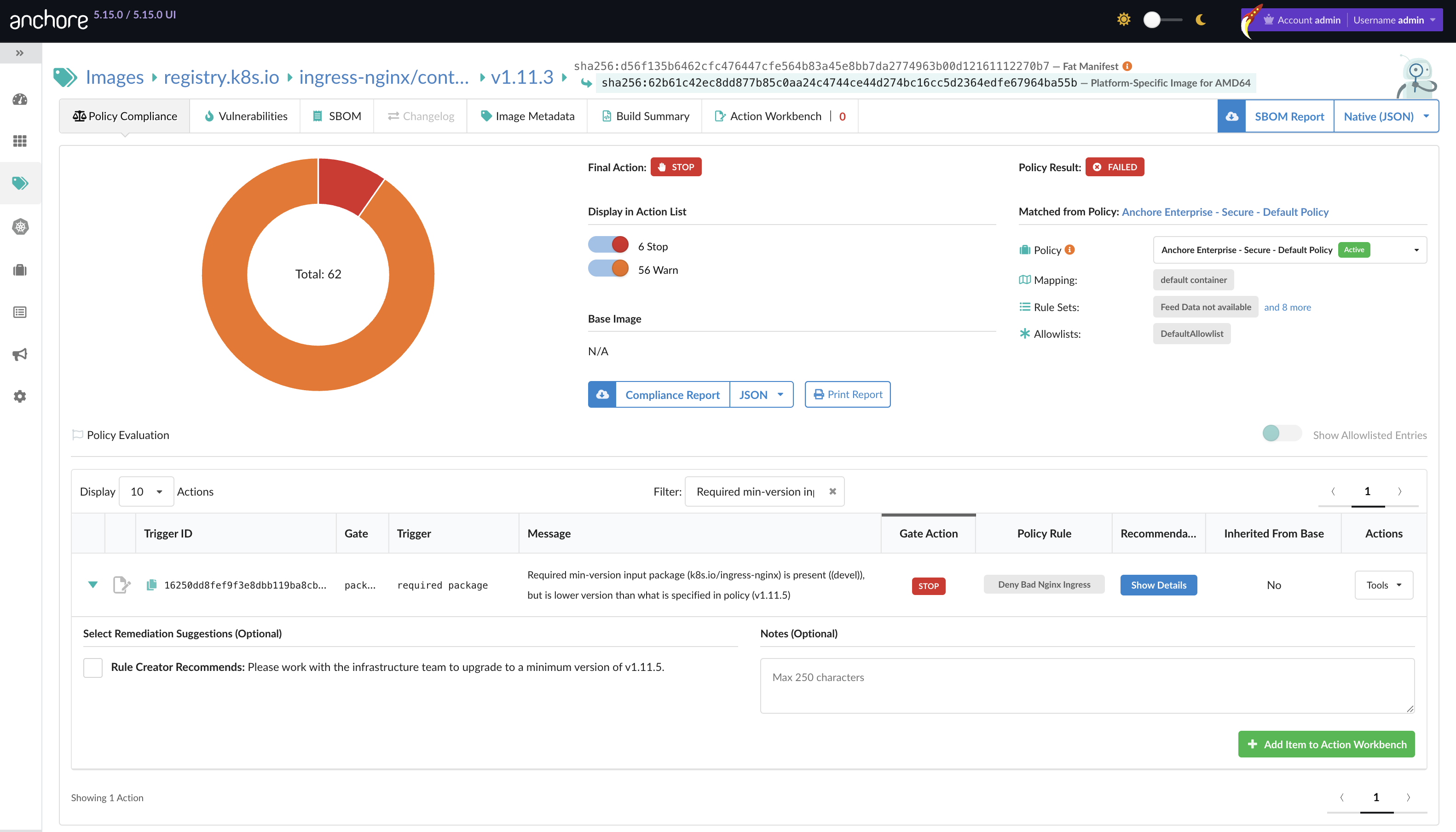
Step 3: Drill down into container image vulnerability report

When you drill down into the CVE-2025-1974 vulnerability, you can view additional details that help understand its nature and impact. Note the vulnerability’s unique identifier, which will be needed for subsequent steps. From here, you can click the ‘Report’ button to generate a comprehensive vulnerability report for CVE-2025-1974.
Step 4: Configure a vulnerability report for CVE-2025-1974

To generate a report on all container images tagged with the CVE-2025-1974 unique vulnerability ID:
- Select the
Vulnerability Idfilter - Paste the CVE-2025-1974 vulnerability ID into the filter field
- Click ‘Preview Results’ to see affected images
Step 5: Generate container image vulnerability report

The vulnerability report identifies all container images tagged with the unique vulnerability ID. To remediate the vulnerability effectively, base images that running instances are built from need to be updated to ensure the fix propagates across all cluster services.
Step 6: Generate Kubernetes namespace vulnerability report

While there may be only two base images containing the vulnerability, these images might be reused across multiple products and services in the Kubernetes cluster. A report based solely on base images can obscure the true scale of vulnerable assets in a cluster. A namespace-based report provides a more accurate picture of your exposure.
Wrap-Up: Building Resilience Before the Crisis
The next Ingress Nightmare-level vulnerability isn’t a question of if, but when. Organizations that invest in software supply chain security before a crisis occurs will respond with targeted remediation rather than scrambling in war rooms.
Anchore’s SBOM-powered SCA provides the comprehensive visibility and automated policy enforcement needed to transform vulnerability response from a chaotic emergency into a routine, manageable process. By building software supply chain security into your DevSecOps pipeline today, you ensure you’ll have the visibility you need when it matters most.
Ready to see how Anchore Enterprise can strengthen your Kubernetes security posture? Request a demo today to learn how our solutions can help protect your critical infrastructure from vulnerabilities like CVE-2025-1974.
Learn how Spectro Cloud secured their Kubernetes-based software supply chain and the pivotal role SBOMs played.



