Syft is an open source CLI tool and Go library that generates a Software Bill of Materials (SBOM) from source code, container images and packaged binaries. It is a foundational building block for various use-cases: from vulnerability scanning with tools like Grype, to OSS license compliance with tools like Grant. SBOMs track software components—and their associated supplier, security, licensing, compliance, etc. metadata—through the software development lifecycle.
At a high level, Syft takes the following approach to generating an SBOM:
- Determine the type of input source (container image, directory, archive, etc.)
- Orchestrate a pluggable set of catalogers to scan the source or artifact
- Each package cataloger looks for package types it knows about (RPMs, Debian packages, NPM modules, Python packages, etc.)
- In addition, the file catalogers gather other metadata and generate file hashes
- Aggregate all discovered components into an SBOM document
- Output the SBOM in the desired format (Syft, SPDX, CycloneDX, etc.)
Let’s dive into each of these steps in more detail.
Explore SBOM use-cases for almost any department of the enterprise and learn how to unlock enterprise value to make the most of your software supply chain.

Flexible Input Sources
Syft can generate an SBOM from several different source types:
- Container images (both from registries and local Docker/Podman engines)
- Local filesystems and directories
- Archives (TAR, ZIP, etc.)
- Single files
This flexibility is important as SBOMs are used in a variety of environments, from a developer’s workstation to a CI/CD pipeline.
When you run Syft, it first tries to autodetect the source type from the provided input. For example:
# Scan a container image
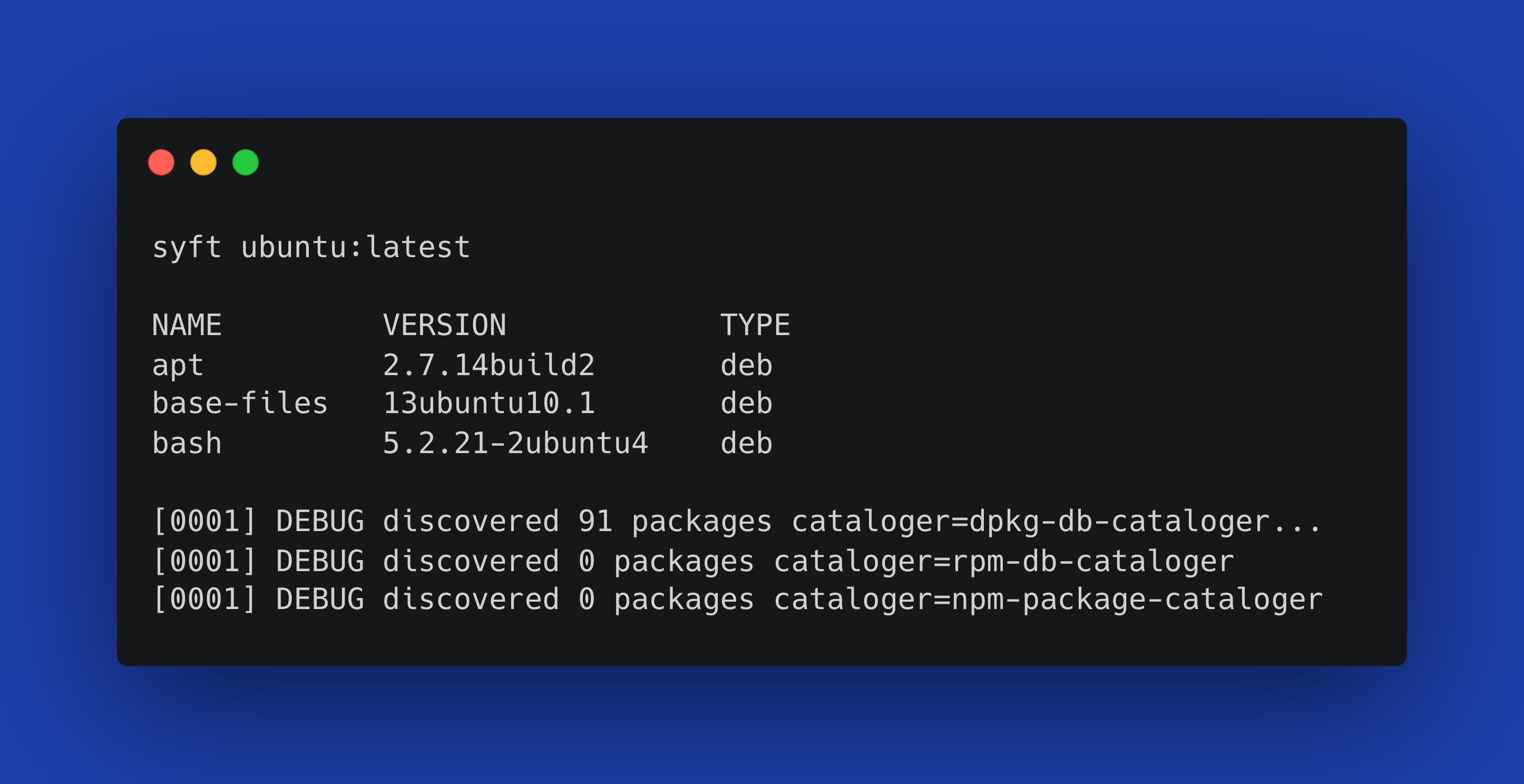
syft ubuntu:latest
# Scan a local filesystem
syft ./my-app/Pluggable Package Catalogers
The heart of Syft is its decoupled architecture for software composition analysis (SCA). Rather than one monolithic scanner, Syft delegates scanning to a collection of catalogers, each focused on a specific software ecosystem.
Some key catalogers include:
apk-db-catalogerfor Alpine packagesdpkg-db-catalogerfor Debian packagesrpm-db-catalogerfor RPM packages (sourced from various databases)python-package-catalogerfor Python packagesjava-archive-catalogerfor Java archives (JAR, WAR, EAR)npm-package-catalogerfor Node/NPM packages
Syft automatically selects which catalogers to run based on the source type. For a container image, it will run catalogers for the package types installed in containers (RPM, Debian, APK, NPM, etc). For a filesystem, Syft runs a different set of catalogers looking for installed software that is more typical for filesystems and source code.
This pluggable architecture gives Syft broad coverage while keeping the core streamlined. Each cataloger can focus on accurately detecting its specific package type.
If we look at a snippet of the trace output from scanning an Ubuntu image, we can see some catalogers in action:
[0001] DEBUG discovered 91 packages cataloger=dpkg-db-cataloger...
[0001] DEBUG discovered 0 packages cataloger=rpm-db-cataloger
[0001] DEBUG discovered 0 packages cataloger=npm-package-catalogerHere, the dpkg-db-cataloger found 91 Debian packages, while the rpm-db-cataloger and npm-package-cataloger didn’t find any packages of their types—which makes sense for an Ubuntu image.
Aggregating and Outputting Results
Once all catalogers have finished, Syft aggregates the results into a single SBOM document. This normalized representation abstracts away the implementation details of the different package types.
The SBOM includes key data for each package like:
- Name
- Version
- Type (Debian, RPM, NPM, etc)
- Files belonging to the package
- Source information (repository, download URL, etc.)
- File digests and metadata
It also contains essential metadata, including a copy of the configuration used when generating the SBOM (for reproducibility). The SBOM will contain detailed information about package evidence, which packages were parsed from (within package.Metadata).
Finally, Syft serializes this document into one or more output formats. Supported formats include:
- Syft’s native JSON format
- SPDX’s tag-value and JSON
- CycloneDX’s JSON and XML
Having multiple formats allows integrating Syft into a variety of toolchains and passing data between systems that expect certain standards.
Revisiting the earlier Ubuntu example, we can see a snippet of the final output:
NAME VERSION TYPE
apt 2.7.14build2 deb
base-files 13ubuntu10.1 deb
bash 5.2.21-2ubuntu4 debContainer Image Parsing with Stereoscope
To generate high-quality SBOMs from container images, Syft leverages a stereoscope library for parsing container image formats.
Stereoscope does the heavy lifting of unpacking an image into its constituent layers, understanding the image metadata, and providing a unified filesystem view for Syft to scan.
This encapsulation is quite powerful, as it abstracts the details of different container image specs (Docker, OCI, etc.), allowing Syft to focus on SBOM generation while still supporting a wide range of images.
Cataloging Challenges and Future Work
While Syft can generate quality SBOMs for many source types, there are still challenges and room for improvement.
One challenge is supporting the vast variety of package types and versioning schemes. Each ecosystem has its own conventions, making it challenging to extract metadata consistently. Syft has added support for more ecosystems and evolved its catalogers to handle edge-cases to provide support for an expanding array of software tooling.
Another challenge is dynamically generated packages, like those created at runtime or built from source. Capturing these requires more sophisticated analysis that Syft does not yet do. To illustrate, let’s look at two common cases:
Runtime Generated Packages
Imagine a Python application that uses a web framework like Flask or Django. These frameworks allow defining routes and views dynamically at runtime based on configuration or plugin systems.
For example, an application might scan a /plugins directory on startup, importing any Python modules found and registering their routes and models with the framework. These plugins could pull in their own dependencies dynamically using importlib.
From Syft’s perspective, none of this dynamic plugin and dependency discovery happens until the application actually runs. The Python files Syft scans statically won’t reveal those runtime behaviors.
Furthermore, plugins could be loaded from external sources not even present in the codebase Syft analyzes. They might be fetched over HTTP from a plugin registry as the application starts.
To truly capture the full set of packages in use, Syft would need to do complex static analysis to trace these dynamic flows, or instrument the running application to capture what it actually loads. Both are much harder than scanning static files.
Source Built Packages
Another typical case is building packages from source rather than installing them from a registry like PyPI or RubyGems.
Consider a C++ application that bundles several libraries in a /3rdparty directory and builds them from source as part of its build process.
When Syft scans the source code directory or docker image, it won’t find any already built C++ libraries to detect as packages. All it will see are raw source files, which are much harder to map to packages and versions.
One approach is to infer packages from standard build tool configuration files, like CMakeLists.txt or Makefile. However, resolving the declared dependencies to determine the full package versions requires either running the build or profoundly understanding the specific semantics of each build tool. Both are fragile compared to scanning already built artifacts.
Some Language Ecosystems are Harder Than Others
It’s worth noting that dynamism and source builds are more or less prevalent in different language ecosystems.
Interpreted languages like Python, Ruby, and JavaScript tend to have more runtime dynamism in their package loading compared to compiled languages like Java or Go. That said, even compiled languages have ways of loading code dynamically, it just tends to be less common.
Likewise, some ecosystems emphasize always building from source, while others have a strong culture of using pre-built packages from central registries.
These differences mean the level of difficulty for Syft in generating a complete SBOM varies across ecosystems. Some will be more amenable to static analysis than others out of the box.
What Could Help?
To be clear, Syft has already done impressive work in generating quality SBOMs across many ecosystems despite these challenges. But to reach the next level of coverage, some additional analysis techniques could help:
- Static analysis to trace dynamic code flows and infer possible loaded packages (with soundness tradeoffs to consider)
- Dynamic instrumentation/tracing of applications to capture actual package loads (sampling and performance overhead to consider)
- Standardized metadata formats for build systems to declare dependencies (adoption curve and migration path to consider)
- Heuristic mapping of source files to known packages (ambiguity and false positives to consider)
None are silver bullets, but they illustrate the approaches that could help push SBOM coverage further in complex cases.
Ultimately, there will likely always be a gap between what static tools like Syft can discover versus the actual dynamic reality of applications. But that doesn’t mean we shouldn’t keep pushing the boundary! Even incremental improvements in these areas help make the software ecosystem more transparent and secure.
Syft also has room to grow in terms of programming language support. While it covers major ecosystems like Java and Python well, more work is needed to cover languages like Go, Rust, and Swift completely.
As the SBOM landscape evolves, Syft will continue to adapt to handle more package types, sources, and formats. Its extensible architecture is designed to make this growth possible.
Get Involved
Syft is fully open source and welcomes community contributions. If you’re interested in adding support for a new ecosystem, fixing bugs, or improving SBOM generation, the repo is the place to get started.
There are issues labeled “Good First Issue” for those new to the codebase. For more experienced developers, the code is structured to make adding new catalogers reasonably straightforward.
No matter your experience level, there are ways to get involved and help push the state of the art in SBOM generation. We hope you’ll join us!
Learn about the role that SBOMs for the security of your organization in this white paper.



