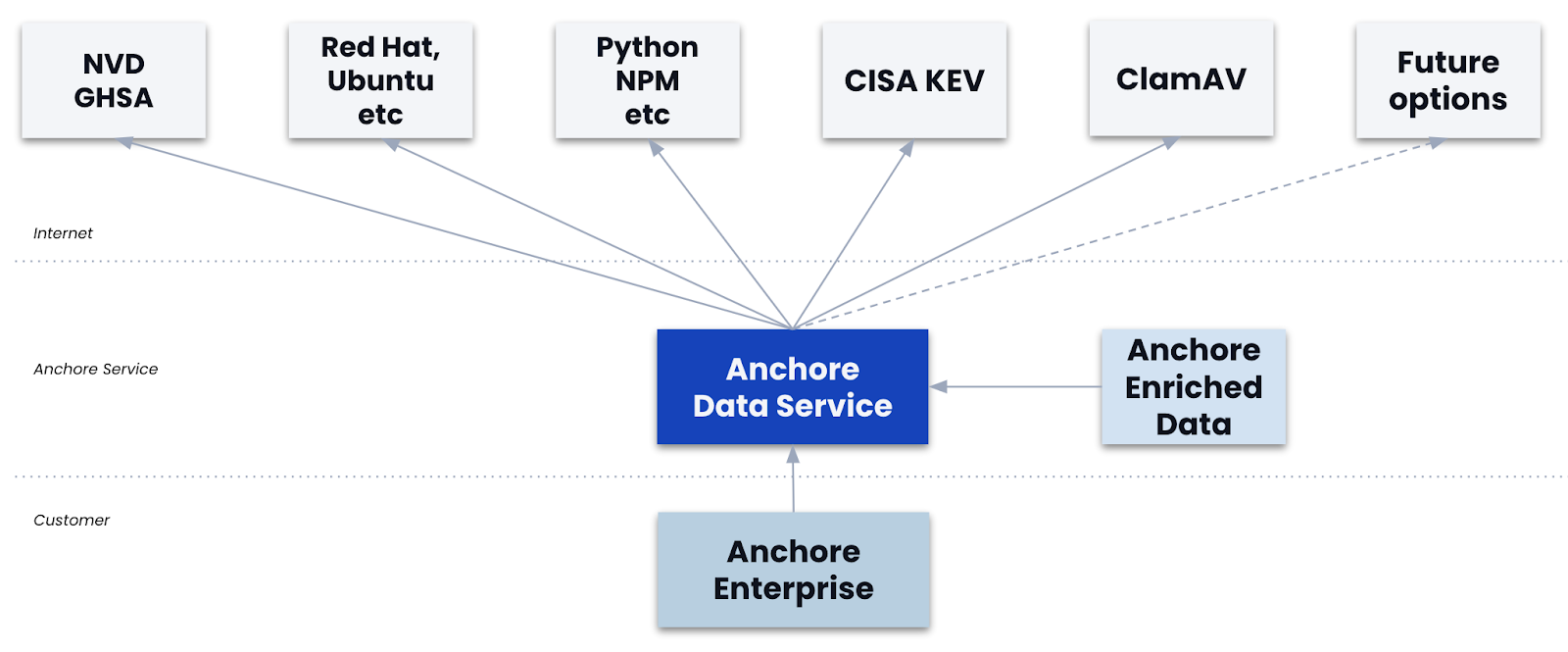
Modern software development is complex to say the least. Vulnerabilities often lurk within the vast networks of dependencies that underpin applications. A typical scenario involves a simple app.go source file that is underpinned by a sprawling tree of external libraries and frameworks (check the go.mod file for the receipts). As developers incorporate these dependencies into their applications, the security risks escalate, often surpassing the complexity of the original source code. This real-world challenge highlights a critical concern: the hidden vulnerabilities that are magnified by the dependencies themselves, making the task of securing software increasingly daunting.
Addressing this challenge requires reimagining software supply chain security through a different lens. In a recent webinar with the famed Kelsey Hightower, he provides an apt analogy to help bring the sometimes opaque world of security into focus for a developer. Software security can be thought of as just another test in the software testing suite. And the system that manages the tests and the associated metadata is a data pipeline. We'll be exploring this analogy in more depth in this blog post and by the end we will have created a bridge between developers and security.
The Problem: Modern software is built on a tower
Modern software is built from a tower of libraries and dependencies that increase the productivity of developers but with these boosts comes the risks of increased complexity. Below is a simple 'ping-pong' (i.e., request-response) application written in Go that imports a single HTTP web framework:
package main
import (
"net/http"
"github.com/gin-gonic/gin"
)
func main() {
r := gin.Default()
r.GET("/ping", func(c *gin.Context) {
c.JSON(http.StatusOK, gin.H{
"message": "pong",
})
})
r.Run()
}With this single framework comes a laundry list of dependencies that are needed in order to work. This is the go.mod file that accompanies the application:
module app
go 1.20
require github.com/gin-gonic/gin v1.7.2
require (
github.com/gin-contrib/sse v0.1.0 // indirect
github.com/go-playground/locales v0.13.0 // indirect
github.com/go-playground/universal-translator v0.17.0 // indirect
github.com/go-playground/validator/v10 v10.4.1 // indirect
github.com/golang/protobuf v1.3.3 // indirect
github.com/json-iterator/go v1.1.9 // indirect
github.com/leodido/go-urn v1.2.0 // indirect
github.com/mattn/go-isatty v0.0.12 // indirect
github.com/modern-go/concurrent v0.0.0-20180228061459-e0a39a4cb421 // indirect
github.com/modern-go/reflect2 v0.0.0-20180701023420-4b7aa43c6742 // indirect
github.com/ugorji/go/codec v1.1.7 // indirect
golang.org/x/crypto v0.0.0-20200622213623-75b288015ac9 // indirect
golang.org/x/sys v0.0.0-20200116001909-b77594299b42 // indirect
gopkg.in/yaml.v2 v2.2.8 // indirect
)The dependencies for the application end up being larger than the application source code. And in each of these dependencies is the potential for a vulnerability that could be exploited by a determined adversary. Kelsey Hightower summed this up well, "this is software security in the real world". Below is an example of a Java app that hides vulnerabile dependencies inside the frameworks that the application is built off of.
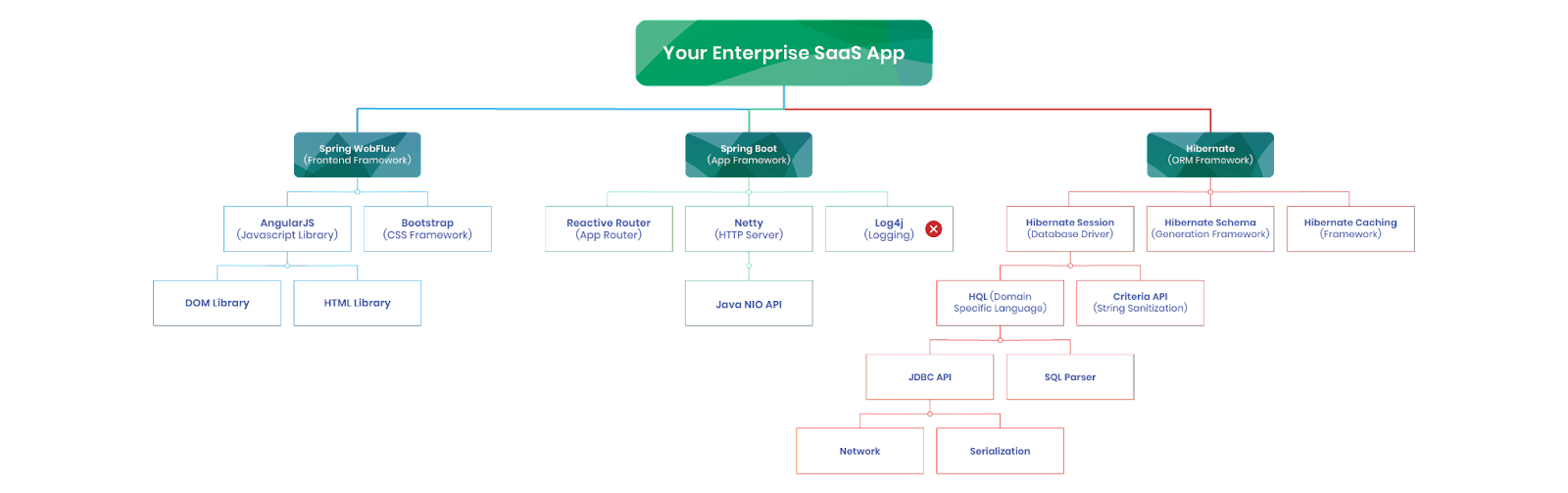
As much as we might want to put the genie back in the bottle, the productivity boosts of building on top of frameworks are too good to reverse this trend. Instead we have to look for different ways to manage security in this more complex world of software development.
If you're looking for a solution to the complexity of modern software vulnerability management, be sure to take a look at the Anchore Enterprise platform and the included container vulnerability scanner.
The Solution: Modeling software supply chain security as a data pipeline
Software supply chain security is a meta problem of software development. The solution to most meta problems in software development is data pipeline management.
Developers have learned this lesson before when they first build an application and something goes wrong. In order to solve the problem they have to create a log of the error. This is a great solution until you've written your first hundred logging statements. Suddenly your solution has become its own problem and a developer becomes buried under a mountain of logging data. This is where a logging (read: data) pipeline steps in. The pipeline manages the mountain of log data and helps developers sift the signal from the noise.
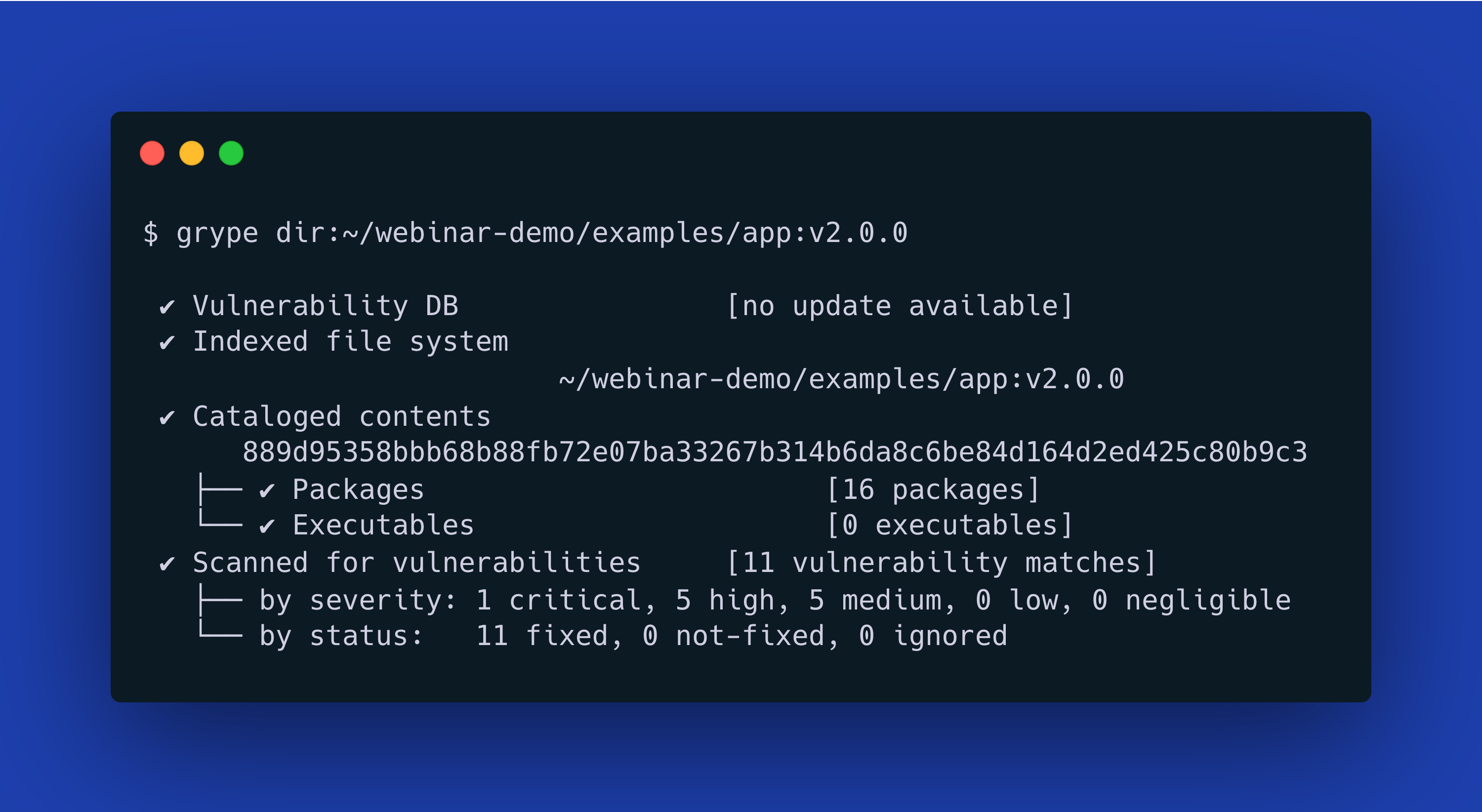
The same pattern emerges in software supply chain security. From the first run of a vulnerability scanner on almost any modern software, a developer will find themselves buried under a mountain of security metadata.
$ grype dir:~/webinar-demo/examples/app:v2.0.0
✔ Vulnerability DB [no update available]
✔ Indexed file system ~/webinar-demo/examples/app:v2.0.0
✔ Cataloged contents 889d95358bbb68b88fb72e07ba33267b314b6da8c6be84d164d2ed425c80b9c3
├── ✔ Packages [16 packages]
└── ✔ Executables [0 executables]
✔ Scanned for vulnerabilities [11 vulnerability matches]
├── by severity: 1 critical, 5 high, 5 medium, 0 low, 0 negligible
└── by status: 11 fixed, 0 not-fixed, 0 ignored
NAME INSTALLED FIXED-IN TYPE VULNERABILITY SEVERITY
github.com/gin-gonic/gin v1.7.2 1.7.7 go-module GHSA-h395-qcrw-5vmq High
github.com/gin-gonic/gin v1.7.2 1.9.0 go-module GHSA-3vp4-m3rf-835h Medium
github.com/gin-gonic/gin v1.7.2 1.9.1 go-module GHSA-2c4m-59x9-fr2g Medium
golang.org/x/crypto v0.0.0-20200622213623-75b288015ac9 0.0.0-20211202192323-5770296d904e go-module GHSA-gwc9-m7rh-j2ww High
golang.org/x/crypto v0.0.0-20200622213623-75b288015ac9 0.0.0-20220314234659-1baeb1ce4c0b go-module GHSA-8c26-wmh5-6g9v High
golang.org/x/crypto v0.0.0-20200622213623-75b288015ac9 0.0.0-20201216223049-8b5274cf687f go-module GHSA-3vm4-22fp-5rfm High
golang.org/x/crypto v0.0.0-20200622213623-75b288015ac9 0.17.0 go-module GHSA-45x7-px36-x8w8 Medium
golang.org/x/sys v0.0.0-20200116001909-b77594299b42 0.0.0-20220412211240-33da011f77ad go-module GHSA-p782-xgp4-8hr8 Medium
log4j-core 2.15.0 2.16.0 java-archive GHSA-7rjr-3q55-vv33 Critical
log4j-core 2.15.0 2.17.0 java-archive GHSA-p6xc-xr62-6r2g High
log4j-core 2.15.0 2.17.1 java-archive GHSA-8489-44mv-ggj8 MediumAll of this from a single innocuous include statements to your favorite application framework.
Again the data pipeline comes to the rescue and helps manage the flood of security metadata. In this blog post we'll step through the major functions of a data pipeline customized for solving the problem of software supply chain security.
Modeling SBOMs and vulnerability scans as unit tests
I like to think of security tools as just another test. A unit test might test the behavior of my code. I think this falls in the same quality bucket as linters to make sure you are following your company's style guide. This is a way to make sure you are following your company's security guide.
Kelsey Hightower
This idea from renowned developer, Kelsey Hightower is apt, particularly for software supply chain security. Tests are a mental model that developers utilize on a daily basis. Security tooling are functions that are run against your application in order to produce security data about your application rather than behavioral information like a unit test. The first two foundational functions of software supply chain security are being able to identify all of the software dependencies and to scan the dependencies for known existing vulnerabilities (i.e., 'testing' for vulnerabilities in an application).
This is typically accomplished by running an SBOM generation tool like Syft to create an inventory of all dependencies followed by running a vulnerability scanner like Grype to compare the inventory of software components in the SBOM against a database of vulnerabilities. Going back to the data pipeline model, the SBOM and vulnerability database are the data sources and the vulnerability report is the transformed security metadata that will feed the rest of the pipeline.
$ grype dir:~/webinar-demo/examples/app:v2.0.0 -o json
✔ Vulnerability DB [no update available]
✔ Indexed file system ~/webinar-demo/examples/app:v2.0.0
✔ Cataloged contents 889d95358bbb68b88fb72e07ba33267b314b6da8c6be84d164d2ed425c80b9c3
├── ✔ Packages [16 packages]
└── ✔ Executables [0 executables]
✔ Scanned for vulnerabilities [11 vulnerability matches]
├── by severity: 1 critical, 5 high, 5 medium, 0 low, 0 negligible
└── by status: 11 fixed, 0 not-fixed, 0 ignored
{
"matches": [
{
"vulnerability": {
"id": "GHSA-h395-qcrw-5vmq",
"dataSource": "https://github.com/advisories/GHSA-h395-qcrw-5vmq",
"namespace": "github:language:go",
"severity": "High",
"urls": [
"https://github.com/advisories/GHSA-h395-qcrw-5vmq"
],
"description": "Inconsistent Interpretation of HTTP Requests in github.com/gin-gonic/gin",
"cvss": [
{
"version": "3.1",
"vector": "CVSS:3.1/AV:N/AC:L/PR:N/UI:R/S:U/C:H/I:L/A:N",
"metrics": {
"baseScore": 7.1,
"exploitabilityScore": 2.8,
"impactScore": 4.2
},
"vendorMetadata": {
"base_severity": "High",
"status": "N/A"
}
}
],
. . . This was previously done just prior to pushing an application to production as a release gate that would need to be passed before software could be shipped. As unit tests have moved forward in the software development lifecycle as DevOps principles have won the mindshare of the industry, so has security testing "shifted left" in the development cycle. With self-contained, open source CLI tooling like Syft and Grype, developers can now incorporate security testing into their development environment and test for vulnerabilities before even pushing a commit to a continuous integration (CI) server.
From a security perspective this is a huge win. Security vulnerabilities are caught earlier in the development process and fixed before they come up against a delivery due date. But with all of this new data being created, the problem of data overload has led to a different set of problems.
Vulnerability overload; Uncovering the signal in the noise
Like the world of application logs that came before it, at some point there is so much information that an automated process generates that finding the signal in the noise becomes its own problem.
How Anchore Enterprise manages SBOMs and vulnerability scans
Centralized management of SBOMs and vulnerability scans can end up being a massive headache. No need to come up with your own storage and data management solution. Just configure the AnchoreCTL CLI tool to automatically submit SBOMs and vulnerability scans as you run them locally. Anchore Enterprise stores all of this data for you.
On top of this, Anchore Enterprise offers data analysis tools so that you can search and filter SBOMs and vulnerability scans by version, build stage, vulnerability type, etc.
Combining local developer tooling with centralized data management creates a best of both worlds environment where engineers can still get their tasks done locally with ease but offload the arduous management tasks to a server.
Added benefit, SBOM drift detection
Another benefit of distributed SBOM generation and vulnerability scanning is that this security check can be run at each stage of the build process. It would be ideal to believe that the software that is written on in a developers local environment always makes it through to production in an untouched, pristine state but this is rarely the case.
Running SBOM generation and vulnerability scanning at development, on the build server, in the artifact registry, at deploy and during runtime will create a full picture of where and when software is modified in the development process and simplify post-incident investigations or even better catch issues well before they make it to a production environment.
This historical record is a feature provided by Anchore Enterprise called Drift Detection. In the same way that an HTTP cookie creates state between individual HTTP requests, Drift detection is security metadata about security metadata (recursion, much?) that allows state to be created between each stage of the build pipeline. Being the central store for all of the associated security metadata makes the Anchore Enterprise platform the ideal location to aggregate and scan for these particular anomalies.
Policy as a lever
Being able to filter through all of the noise created by integrating security checks across the software development process creates massive leverage when searching for a particular issue but it is still a manual process and being a full-time investigator isn't part of the software engineer job description. Wouldn't it be great if we could automate some if not the majority of these investigations?
I'm glad we're of like minds because this is where policy comes into picture. Returning to Kelsey Hightower's original comparison between security tools as linters, policy is the security guide that is codified by your security team that will allow you to quickly check whether the commit that you put together will meet the standards for secure software.
By running these checks and automating the feedback, developers can quickly receive feedback on any potential security issues discovered in their commit. This allows developers to polish their code before it is flagged by the security check in the CI server and potentially failed. No more waiting on the security team to review your commit before it can proceed to the next stage. Developers are empowered to solve the security risks and feel confident that their code won't be held up downstream.
Policies-as-code supports existing developer workflows
Anchore Enterprise designed its policy engine to ingest the individual policies as JSON objects that can be integrated directly into the existing software development tooling. Create a policy in the UI or CLI, generate the JSON and commit it directly to the repo.
This prevents the painful context switching of moving between different interfaces for developers and allows engineering and security teams to easily reap the rewards of version control and rollbacks that come pre-baked into tools like version control. Anchore Enterprise was designed by engineers for engineers which made policy-as-code the obvious choice when designing the platform.
Remediation automation integrated into the development workflow
Being able to be alerted when a commit is violating your company's security guidelines is better than pushing insecure code and waiting for the breach to find out that you forgot to sanitize the user input. Even after you get alerted to a problem, you still need to understand what is insecure and how to fix it. This can be done by trying to Google the issue or starting up a conversation with your security team. But this just ends up creating more work for you before you can get your commit into the build pipeline. What if you could get the answer to how to fix your commit in order to make it secure directly into your normal workflow?
Anchore Enterprise provides remediation recommendations to help create actionable advice on how to resolve security alerts that are flagged by a policy. This helps point developers in the right direction so that they can resolve their vulnerabilities quickly and easily without the manual back and forth of opening a ticket with the security team or Googling aimlessly to find the correct solution. The recommendations can be integrated directly into GitHub Issues or Jira tickets in order to blend seamlessly into the workflows that teams depend on to coordinate work across the organization.
Wrap-Up
From the perspective of a developer it can sometimes feel like the security team is primarily a frustration that only slows down your ability to ship code. Anchore has internalized this feedback and has built a platform that allows developers to still move at DevOps speeds and do so while producing high quality, secure code. By integrating directly into developer workflows (e.g., CLI tooling, CI/CD integrations, source code repository integrations, etc.) and providing actionable feedback Anchore Enterprise removes the traditional roadblock mentality that has typically described the relationship between development and security.
If you're interested to see all of the features described in this blog post via a hands-on demo, check out the webinar by clicking on the screenshot below and going to the workshop hosted on GitHub.
If you're looking to go further in-depth with how to build and secure containers in the software supply chain, be sure to read our white paper: The Fundamentals of Container Security.