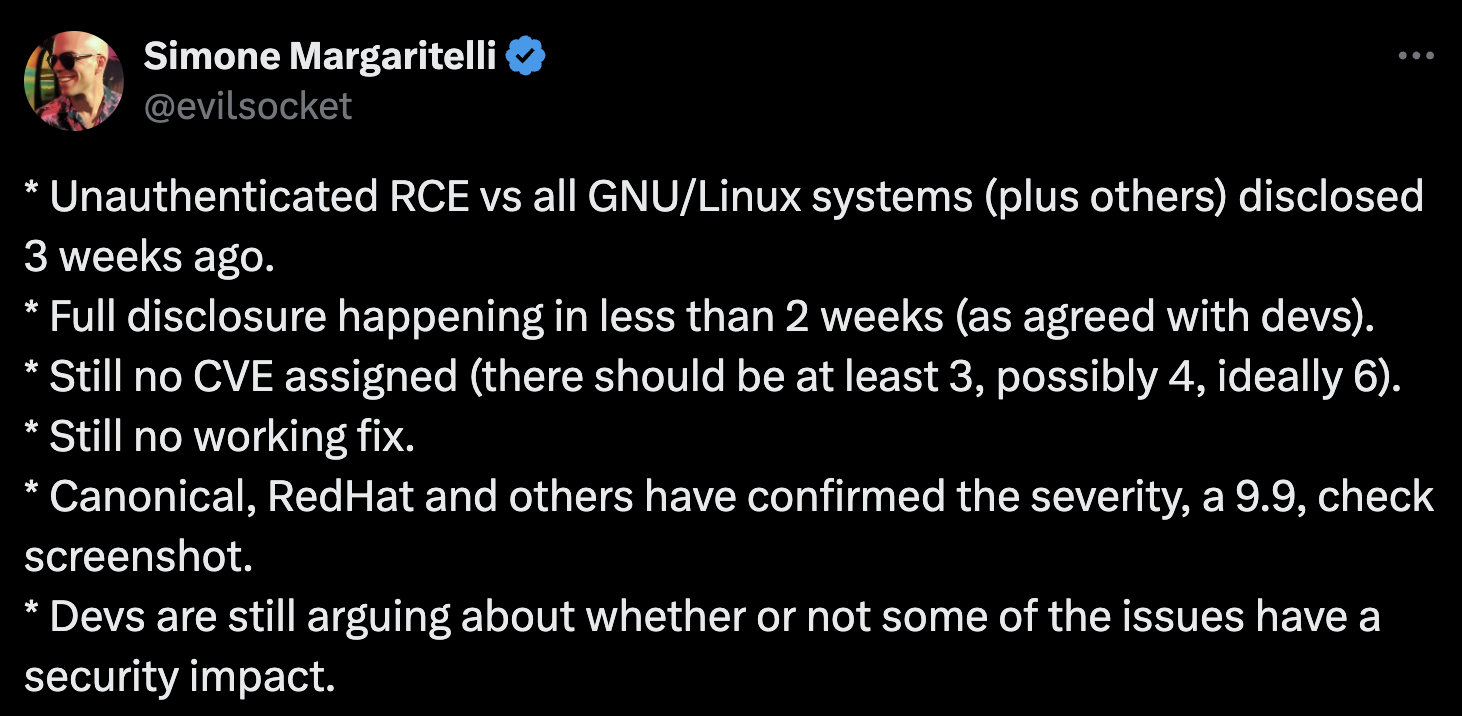
One morning, you wake up and see a tweet like the one above. The immediate response is often panic. This sounds bad; it probably affects everyone, and nobody knows for certain what to do next. Eventually, the panic subsides, but we still have a problem that needs to be dealt with. So the question to ask is: What can we do?
Don’t panic
Having a vague statement about a situation that apparently will probably affect everyone sounds like a problem we can’t possibly prepare for. Waiting is generally the worst option in situations like this, but there are some things we can do to help us out.
One of the biggest challenges in modern infrastructure is just understanding what you have. This sounds silly, but it’s a tough problem because of how most software is built now. You depend on a few open-source projects, and those projects depend on a few other open-source projects, which rely on even more open-source projects. And before you know it, you have 300 open-source projects instead of the 6 you think you installed.
Our goal is to create an inventory of all our software. If we have an accurate and updated inventory, you don’t have to wonder if you’re running some random application, like CUPS. You will know beyond a reasonable doubt. Knowing what software you do (or don’t) have deployed can bring an amazing amount of peace of mind.
This is not new
This was the same story during log4J and xz emergencies. What induced panic in everyone wasn’t the vulnerabilities themselves but the scramble to find where those libraries were deployed. In many instances, we observed engineers manually connecting to servers with SSH and dissecting container images.
These security emergencies will never end, but they all play out similarly. There is a time between when something is announced and good actionable guidance appearing. The security community will come to a better understanding of the issue, then we can figure out the best way to deal with whatever the problem is. This could be updating packages, it could mean adjusting firewall rules, or maybe changing a configuration option.
While we wait for the best guidance, what if we were going through our software inventory? When Log4Shell happened almost everyone spent the first few days or weeks (or months) just figuring out if they had Log4j anywhere. If you have an inventory, those first few days can be spent putting together a plan for applying the guidance you know is coming. It’s a much nicer way to spend time than frantically searching!
The inventory
Creating an inventory sounds like it shouldn’t be that hard. How much software do you REALLY have? It’s hard, and software poses a unique challenge because there are nearly infinite ways to build and assemble any given application. Do you have OpenSSL as an operating system package? Or is it a library in a random directory? Maybe it’s statically compiled into the binary. Maybe we download a copy off the internet when the application starts. Maybe it’s all of these … at the same time.
This complexity is taken to a new level when you consider how many computers, servers, containers, and apps are deployed. The scale means automation is the only way we can do this. Humans cannot handcraft an inventory. They are too slow and make too many mistakes for this work, but robots are great at it!
But the automation we have today isn’t perfect. It’s early days for many of these scanners and inventory formats (such as a Software Bill of Materials or SBOM). We must grasp what possible blind spots our inventories may have. For example, some scanners do a great job finding operating system packages but aren’t as good at finding Java archives (jar files). This is part of what makes the current inventory process difficult. The tooling is improving at an impressive rate; don’t write anything off as too incomplete. It will change and get better in the future.
Enter the SBOM
Now that we have mentioned SBOMs, we should briefly explain how they fit into this inventory universe. An SBOM does nothing by itself; it’s just a file format for capturing information, such as a software inventory.
Anchore developers have written plenty over the years about what an is SBOM, but here is the tl;dr:
An SBOM is a detailed list of all software project components, libraries, and dependencies. It serves as a comprehensive inventory that helps understand the software’s structure and the origins of its components.
An SBOM in your project enhances security by quickly identifying and mitigating vulnerabilities in third-party components. Additionally, it ensures compliance with regulatory standards and provides transparency, which is essential for maintaining trust with stakeholders and users.
An example
To explain what all this looks like and some of the difficulties, let’s go over an example using the eclipse-temurin Java runtime container image. It would be very common for a developer to build on top of this image. It also shows many of the challenges in trying to pin down a software inventory.
The Dockerfile we’re going to reference can be found on GitHub, and the container image can be found on Docker Hub.
The first observation is that this container uses Ubuntu as the underlying container image.
This is great, Ubuntu has a very nice packaging system and it’s no trouble to see what’s installed. We can easily do this with Syft.
bress@anchore → ~ syft ubuntu:24.04
✔ Parsed image sha256:61b2756d6fa9d6242fafd5b29f674404779be561db2d0bd932aa3640ae67b9e1
✔ Cataloged contents 74f92a6b3589aa5cac6028719aaac83de4037bad4371ae79ba362834389035aa
├── ✔ Packages [91 packages]
├── ✔ File digests [2,259 files]
├── ✔ File metadata [2,259 locations]
└── ✔ Executables [722 executables]
NAME VERSION TYPE
apt 2.7.14build2 deb
base-files 13ubuntu10.1 deb
base-passwd 3.6.3build1 deb
bash 5.2.21-2ubuntu4 deb
bsdutils 1:2.39.3-9ubuntu6.1 deb
coreutils 9.4-3ubuntu6 deb
dash 0.5.12-6ubuntu5 deb
debconf 1.5.86ubuntu1 deb
debianutils 5.17build1 deb
diffutils 1:3.10-1build1 deb
dpkg 1.22.6ubuntu6.1 deb
e2fsprogs 1.47.0-2.4~exp1ubuntu4.1 deb
findutils 4.9.0-5build1 deb
gcc-14-base 14-20240412-0ubuntu1 deb
gpgv 2.4.4-2ubuntu17 deb
grep 3.11-4build1 deb
gzip 1.12-1ubuntu3 deb
hostname 3.23+nmu2ubuntu2 deb
init-system-helpers 1.66ubuntu1 deb
⋮There has been nothing exciting so far. But if we look a little deeper at the eclipse temurin Dockerfile, we see it’s installing the Java JDK using wget. That’s not something we’ll find just by looking at Ubuntu packages.
bress@anchore ~ syft ubuntu:24.04
✔ Parsed image sha256:61b2756d6fa9d6242fafd5b29f674404779be561db2d0bd932aa3640ae67b9e1
✔ Cataloged contents 74f92a6b3589aa5cac6028719aaac83de4037bad4371ae79ba362834389035aa
├── ✔ Packages [91 packages]
├── ✔ File digests [2,259 files]
├── ✔ File metadata [2,259 locations]
└── ✔ Executables [722 executables]
NAME VERSION TYPE
apt 2.7.14build2 deb
base-files 13ubuntu10.1 deb
base-passwd 3.6.3build1 deb
bash 5.2.21-2ubuntu4 deb
bsdutils 1:2.39.3-9ubuntu6.1 deb
coreutils 9.4-3ubuntu6 deb
dash 0.5.12-6ubuntu5 deb
debconf 1.5.86ubuntu1 deb
debianutils 5.17build1 deb
diffutils 1:3.10-1build1 deb
dpkg 1.22.6ubuntu6.1 deb
e2fsprogs 1.47.0-2.4~exp1ubuntu4.1 deb
findutils 4.9.0-5build1 deb
gcc-14-base 14-20240412-0ubuntu1 deb
gpgv 2.4.4-2ubuntu17 deb
grep 3.11-4build1 deb
gzip 1.12-1ubuntu3 deb
hostname 3.23+nmu2ubuntu2 deb
init-system-helpers 1.66ubuntu1 debIf we scan this image with Syft, we can see a few different types of packages installed.
bress@anchore ~ syft eclipse-temurin:8u422-b05-jre-noble
✔ Parsed image sha256:d2c2442dea2a2b1164bd6dd39af673db2215ff680910aff7417432b00a3c8e4d
✔ Cataloged contents 805b45dee2c503f1cca36e1ecc6e8625538592e2db32cc04e317a246fb86d0fc
├── ✔ Packages [142 packages]
├── ✔ File digests [3,856 files]
├── ✔ File metadata [3,856 locations]
└── ✔ Executables [809 executables]
NAME VERSION TYPE
⋮
hostname 3.23+nmu2ubuntu2 deb
init-system-helpers 1.66ubuntu1 deb
jaccess UNKNOWN java-archive
jce 1.8.0_422 java-archive
jfr 1.8.0_422 java-archive
jsse 1.8.0_422 java-archive
libacl1 2.3.2-1build1 deb
libapt-pkg6.0t64 2.7.14build2 deb
libassuan0 2.5.6-1build1 deb
libattr1 1:2.5.2-1build1 deb
libaudit-common 1:3.1.2-2.1build1 deb
⋮The jdk and jre are binaries in the image, as are some Java archives. This is a gotcha to watch for when you’re building an inventory. Many inventories and scanners may only look for known-good packages, not binaries and other files installed on the system. In a perfect world, our SBOM tells us details about everything in the image, not just one package type.
At this point, you can imagine a developer adding more things to the container: code they wrote, Java Archives, data files, and maybe even a few more binary files, probably installed with wget or curl.
What next
This sounds pretty daunting, but it’s not that hard to start building an inventory. You don’t need a fancy system. The easiest way is to find an open source SBOM generator, like Syft, and put the SBOMs in a directory. It’s not perfect, but even searching through those files is faster than manually finding every version of CUPS in your infrastructure.
Once you understand an initial inventory, you can investigate more complete solutions. There are countless open-source projects, products (such as Anchore Enterprise), and services that can help here. For example, when starting to build the inventory, don’t expect to go from zero to complete overnight. Big projects need immense patience.
It’s like the old proverb that the best time to plant a tree was twenty years ago; the second best time is now. The best time to start an inventory system was a decade ago; the second best time is now.
If you’d like to discuss any topics raised in this post, join us on this discourse thread.