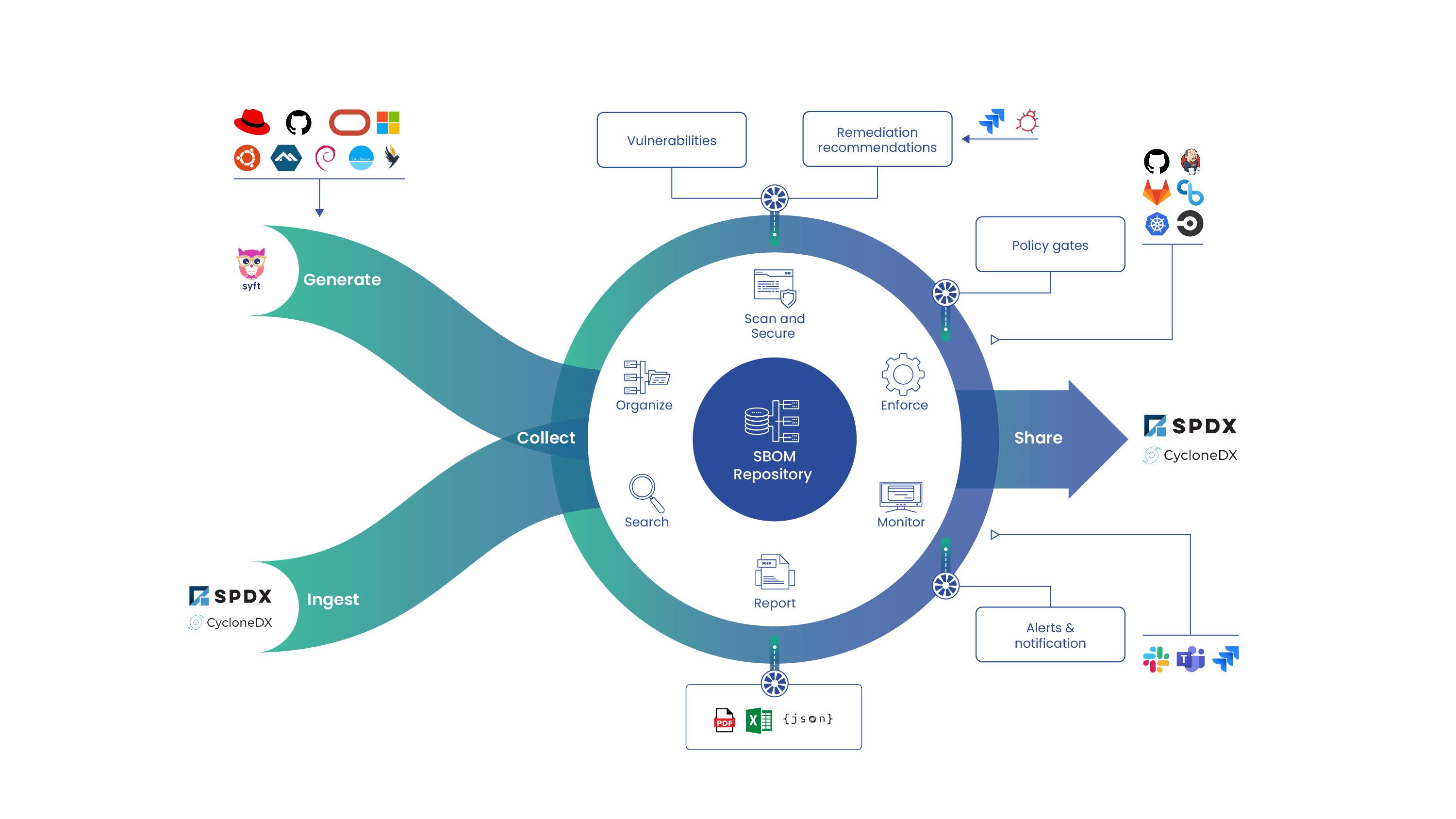
In today’s DevSecOps environment filled with microservices and containers, applications are developed with the idea of scaling in mind. Performing security checks on thousands – or even millions – of container images may seem like a giant undertaking, but Anchore was built with the idea of scaling to handle vast amounts of image analyses. While Anchore conveniently provides quickstarts using both Docker-Compose and Helm for general usage and proof-of-concepts, preparing a production-grade deployment for Anchore requires some more in-depth planning.
In this blog, we will take a look at some of the architectural features that help facilitate scaling an Anchore installation into a more production-ready deployment. Every deployment is different, as is every environment, and keeping these general ideas in mind when planning the underlying architecture for Anchore will help reduce issues while setting you up to scale with Anchore as your organization grows.
Server Resourcing
Whether your Anchore installation is deployed on-premise with underlying virtual machines or in a cloud environment such as AWS, GCP, or Azure, there are some key components that should be considered to facilitate the proper functioning of Anchore. Some of the areas to consider when doing capacity planning are the number of underlying instances, the resource allocation per node, and whether having a few larger nodes is more beneficial than having multiple smaller nodes.
Resource Allocation
As with any application, resource allocation is a crucial component to allow Anchore to perform at its highest level. With the initial deployment, Anchore synchronizes with upstream feed data providers which can be somewhat resource-intensive. After the initial feeds sync, the steady operating state is much lower, but it is recommended for a production-scale deployment that each of Anchore’s services is allocated at least 8GB of memory; these include the following services:
- analyzer
- API
- catalog
- queue
- policy-engine
- enterprise-feeds (if using Anchore Enterprise)
CPU utilization can vary per service, but generally, each service can benefit from 1-2 dedicated vCPUs. As more images are added for concurrent analysis, these values should also be increased to support the load.
Cluster Size and Autoscaling
The appropriate sizing for your deployment will vary based on factors such as the number of images you are scanning over a given period of time, the average size of your images, the location of the database service tier, but a good rule of thumb to start is to use a few larger nodes over multiple smaller nodes. This enables the cluster to adequately support regular operations during non-peak times when the system is primarily on standby and provides services room to scale as additional resources are needed.
Another approach which adheres more with an autoscaling architecture is to use a combination of larger nodes for the core Anchore services (API, catalog, policy-engine, and queue), and smaller nodes that can be used as dedicated nodes for the analyzer services; ideally one analyzer per smaller node for best results. This can be used in conjunction with autoscaling groups and spot instances, enabling the cluster to scale as memory or CPU utilization increases.
Storage Resourcing
When considering allocating storage for an Anchore installation, not only does database capacity planning play a crucial role, but underlying instance disk space and various persistent storage volume space should also be considered. Volume space per node can be roughly calculated by 3-4x the size of the largest image that will be analyzed. Anchore uses a local directory for image analysis operations including downloading layers and unpacking the image content for the analysis process. This space is necessary for each analyzer worker service and should not be shared. The scratch space is ephemeral and can have its lifecycle bound to that of the service container.
Anchore uses the following persistent storage types for storing image metadata, analysis reports, policy evaluation, subscriptions, tags, and other artifacts.
Configuration Volume – This volume is used to provide persistent storage of database configuration files and optionally certificates. (Requires less than 1MB of storage)
Object Storage – The Anchore Engine stores documents containing archives of image analysis data and policies as JSON documents.
By default, this data is persisted in a PostgreSQL service container defined in the default helm chart and docker-compose template for Anchore. While this storage solution is sufficient for testing and smaller deployments, storage consumption may grow rapidly with the number of images analyzed, requiring a more scalable solution for medium and large production deployments.
To address storage growth and reduce database overhead, we recommend using an external object store for long-term data storage and archival. Offloading persistent object storage provides scalability, improves API performance, and supports the inclusion of lifecycle management policies to reduce storage costs over time. External object storage can be configured by updating the following section of your deployment template:
...
services:
...
catalog:
...
object_store:
compression:
enabled: false
min_size_kbytes: 100
storage_driver:
name: db
config: {}Anchore currently supports the use of Simple Storage Service (AWS S3), Swift, and MinIO for Kubernetes deployments.
You can learn more about the configuration and advantages of external object storage in our docs.
Database Connection Settings
A standard Anchore deployment includes an internal PostgreSQL service container for persistent storage, but for production deployments, we recommend utilizing an external database instance, either on-premises or in the cloud (Amazon RDS, Azure SQL, GCP Cloud SQL). Every Anchore service communicates with the database, and every service has a configuration option that allows you to set client pool connections, with the default set at 30. Client pool connections control how many client connections each service can make concurrently. In the Postgres configuration, max connections control how many clients total can connect at once.
By default, the settings in PostgreSQL out of the box are around 100 max connections. To improve scalability and performance, we recommend leaving the Anchore client max connection setting at its defaults and bumping up the max connections in Postgres configuration appropriately. With the client default at 30, the corresponding max connections setting for our deployment of 100 Anchore services should be at least 3000 (30 * 100).
Archival/Deletion Rules & Migration
As your organization grows, it may not be necessary to store older image analysis in your database in the active working set. In fact, hanging onto this type of data in the database can quickly lead to a bloated database with information no longer relevant to your organization. To help reduce the storage capacity of the database and keep the active working set focused on what is current, Anchore offers an “Analysis Archive” tool that allows users to manually archive and delete old image analysis data or to create a ruleset that automatically archives and deletes image analysis data after a specified period of time. Images that are archived can be restored to the active working set at any time, but using the archive allows users to reduce the necessary storage size for the database while maintaining analysis records for audit trails and provenance.
The following example shows how to configure the analysis archive to use an AWS S3 bucket to offload analysis data from the database.
...
services:
...
catalog:
...
analysis_archive:
compression:
enabled: False
min_size_kbytes: 100
storage_driver:
name: 's3'
config:
access_key: 'MY_ACCESS_KEY'
secret_key: 'MY_SECRET_KEY'
#iamauto: True
url: 'https://S3-end-point.example.com'
region: False
bucket: 'anchorearchive'
create_bucket: True
For users with existing data who want to enable an external analysis archive driver, there are some additional steps to migrate the existing data to the external analysis archive. For existing deployments, you can learn about migrating from the default database archive to a different archive driver here.
For more information, check out our documentation on Using the Analysis Archive.
Deployment Configuration
One of the quintessential features of Anchore is the ability to customize your deployment, from the aforementioned server and storage resourcing to the number of services and how Anchore can fit into your architecture. From a production perspective, a couple of areas should be considered as the organization scales to support larger numbers of images to analyze while maintaining a steady throughput; the ratio of analyzers to core service and the ability to enable layer caching are two that we have found to be helpful.
Service Replicas
Specifically, with Kubernetes deployments in mind via Helm, Anchore services can be scaled up or down using a `values.yaml` file and setting the `replicaCount` to the desired number of replicas. This can be achieved with Docker-Compose as well, but the deployment would need to be running in something like Docker Swarm or AWS ECS.
...
...
anchoreAnalyzer:
replicaCount: 1 ← Here is where the number of Analyzer services can be upped
...
Check out these links for scaling services with Docker or scaling with Kubernetes. Also, take a look at the documentation for our Helm chart for some more information on deploying with Helm.
Golden Ratio of Thumb
When scaling Anchore, we recommend keeping a 4-1 ratio of analyzers to core services. This means for a deployment that runs 16 analyzers, we recommend having 4 of the API, catalog, queue, and policy-engine services. The idea behind this stems from the potential for a situation where there are four concurrent heavy memory, cpu, and input/output tasks all happening at once in one of the core services, such as four analyzers all initiating the same task at once like sending an image to a single policy-engine. While a well-provisioned server may be able to handle something like this while still being able to support other lighter tasks, generally the underlying server can start to be overwhelmed unless it’s specifically provisioned to handle many concurrent workloads simultaneously. Additionally, using the 4-1 analyzer-to-core-services ratio helps spread the memory usage load, and where possible as outlined in the above Server Resourcing section, splitting the analyzers out to dedicated nodes helps ensure healthy resource utilization.
Layer Caching
In some cases, your container images will share a number of common layers, especially if images are built from a standard base image. Anchore can be configured to cache layers in the image manifest to eliminate the need to download layers present in multiple images. This can improve analyzer performance and speed up the analysis process.
Layer caching can be enabled by setting a max value greater than ‘0’ in your helm chart
anchoreAnalyzer:
layerCacheMaxGigabytes: 0And under the ‘Analyzer’ section of the docker-compose template:
analyzer:
enabled: True
require_auth: True
cycle_timer_seconds: 1
max_threads: 1
analyzer_driver: 'nodocker'
endpoint_hostname: '${ANCHORE_HOST_ID}'
listen: '0.0.0.0'
port: 8084
layer_cache_enable: True
layer_cache_max_gigabytes: 4By default, each analyzer container service uses ephemeral storage allocated to the container. Another consideration to improve performance is to offload temporary storage to a dedicated volume. With the cache disabled the temporary directory should be sized to at least 3 times the uncompressed image size to be analyzed. This option can be set under `scratchVolume` settings in the Global configuration section of the helm chart:
scratchVolume:
mountPath: /analysis_scratch
details:
# Specify volume configuration here
emptyDir: {}
Conclusion
In this blog, we’ve briefly touched on several of the areas that we believe to be of critical importance when scaling with Anchore. Some of the more important aspects to keep in mind, and what we’ve seen from our customers who run at scale, are as follows:
- Resource allocation
-
- Proper memory and CPU allocation is a critical component of running a successful Anchore deployment
-
- Database provisioning
-
- Database sizing is important to consider in the long-term, allowing you to analyze images for years to come without the concern of running out of DB space
- Connection pooling is another crucial aspect to consider to allow Anchore services to concurrently access the database without hitting limits
-
- Tons of configuration options
-
- Anchore has a vast amount of different configuration options to help customize Anchore to fit your organizational needs
-
While this was a high-level overview, special attention should be paid to each when performing architectural and capacity planning. From a broader perspective, cloud providers each offer documentation on architectural planning with autoscaling as well as recommendations for how to scale applications in their specific cloud environments.