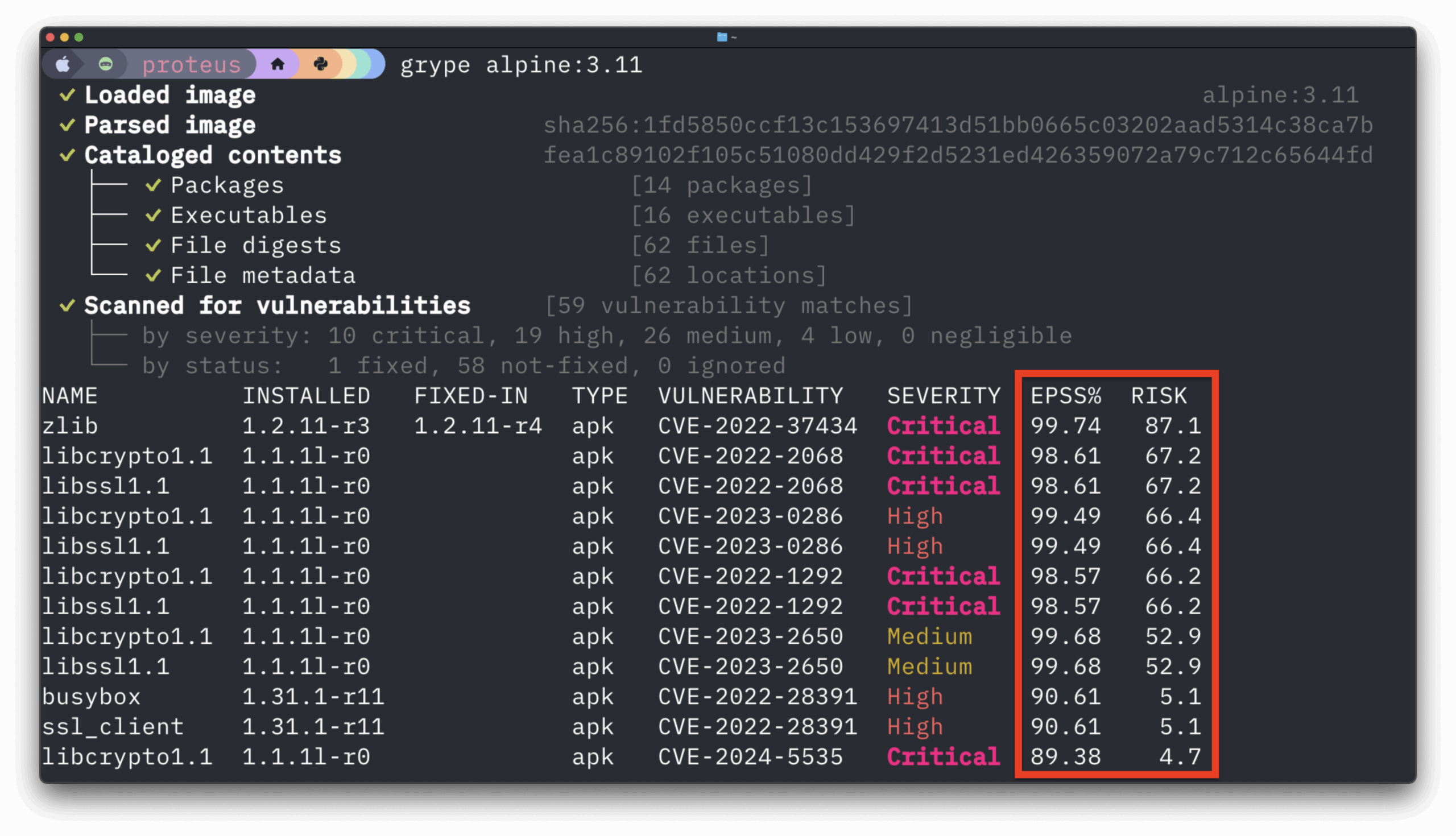
If you haven’t read Part 1 please do so before reading this article as we rely heavily on concepts and vocabulary established in that article. In this article, we’ll dive more deeply into matching metrics gathered in our first part with opportunities to tune the performance of a given Anchore deployment.
Just to refresh, the steps for image analysis and evaluation in Anchore Engine is as follows:
1) The Image is downloaded.
2) The Image is unpacked.
3) The Image is analyzed locally.
4) The result of the analysis is uploaded to core services.
5) The analysis data that was uploaded to core services is then evaluated during a vulnerability scan or policy evaluation.
Steps 1-3 are the most intensive operational costs for Anchore. Package, file and image analysis is both CPU and Disk intensive as operations. Making sure we’re on a host that has good disk throughput and high single-thread CPU performance will help greatly here.
Overall deployment performance depends on a few things: how the services interact and can scale together, how performant the database service is in response to the rest of the services, and how each service is provisioned with their own resources.
How To Improve Step 1: Enable Layer Caching
It is very likely that many of your images share common layers, especially if a standard base image is being used to build services. Performance can be improved by using caching on each of those layers contained in your image manifest. Anchore has a setting that enables a layer-specific caching for analyzers in order to reduce operational cost over time. In your Prometheus analysis, look at anchore_analysis_time_seconds for insight into when layer caching would be beneficial.
To enable the cache you can define a temp directory the config.yaml for each analyzer, shown below. We should make sure that whatever you define should have the same throughput considerations as scaling the overall container throughput: Make sure you have fast SSD or local disk to each analyzer, as the cache layer is not shared between nodes, and is ephemeral.
If we have set the following mount for a tmp_dir:
tmp_dir: '/scratch'
Then in order to utilize /scratch within the container make sure config.yaml is updated to use /scratch as the temporary directory for image analysis. We suggest the temporary directory should be sized to at least 3 times the uncompressed image size to be analyzed. To enable the layer caching, let’s enable the “layer_cache_enable” parameter and the “layer_cache_max_gigabytes” parameter as follows:
analyzer:
enabled: True
require_auth: True
cycle_timer_seconds: 1
max_threads: 1
analyzer_driver: 'nodocker'
endpoint_hostname: '${ANCHORE_HOST_ID}'
listen: '0.0.0.0'
port: 8084
layer_cache_enable: True
layer_cache_max_gigabytes: 4
In this example, the cache is set to 4 gigabytes. The temporary volume should be sized to at least 3 times the uncompressed image size + 4 gigabytes. The minimum size for the cache is 1 gigabyte and the cache uses a least recently used (LRU) policy. The cache files will be stored in the anchore_layercache directory of the /tmp_dir volume.
How To Improve Steps 2-3: Improve Service I/O Throughput
This is pretty straight forward: better throughput performance for CPU and disk will improve the most I/O and CPU intensive tasks of Anchore’s analysis process. High single-thread CPU performance and fast disk read/write speeds for each Anchore analyzer service will speed up the steps where we pull, extract and do file analysis of any given container image. On premise, this may mean a beefier CPU spec and SSDs in your bare metal. In the cloud, you may be choosing to not run EBS to back your analyzer tmp directories and selecting for higher compute instances.
How To Improve Step 4: Scaling Anchore Engine Components
This tip is to address a very wide scope of performance, so there’s a wide scope of metrics to be watching, but in general scaling analyzer services and core services according to a consistent ratio is one way to ensure throughput overall can be maintained. In general, we suggest 1 core service for every 4 analyzers. Keeping this scale means that we can ensure throughput for core services grows with the number of analyzers.
How To Improve Step 5: Tune Max Connection Settings For Postgres
One of the most common questions about deploying Anchore in production is how to architect the Postgres instance used by Anchore Engine. While Anchore has installation methods that include a Postgres service container in our docker-compose YAML and helm chart, we do expect that production deployments will not use that Postgres container and instead will utilize a Postgres service, either on-premises or in the cloud (such as RDS, etc.) Using a cloud service like Using something like RDS is not only an easy way to control allocated resources to your DB instance but RDS specifically also automatically configures Postgres with pretty good settings for the chosen instance type out of the box.
For a more in-depth guide on tuning your Postgres deployments, you’ll want to consult with Postgres documentation or use a tool like pg_tune. For this guide’s purpose, we can check the performance stats in the DB with “select * from pg_stat_activity;” executed in your Postgres container.
When you are looking at Postgres performance stats from your pg_stat_activity table, you want to pay attention to connection statistics. Every Anchore service touches the database, and every service has a config YAML file where you can set client pool connections with a default set to 30. The setting on the anchore services side control how many client connections each service can make concurrently. In the Postgres configuration, max connections control how many clients total can connect at once. Anchore uses sql alchemy, which employs a connection pooling technique, so each service may allocate connection pool size number of client connections.
For example, in pg_stat_database we can see numbackends. We can from that number and the max_connections setting in pg_settings infer how close we are to forcing connection waits. This is because the percentage of max connections in use is numbackends as a percentage of max_connections. In a nutshell, with Anchore database client connections setting at 300, and deployment with 100 Anchore services, that could lead to 30000 client connections to the database. Without adjusting max_connections, this could lead to a serious bottleneck.
We typically recommend leaving the Anchore client max connection setting at its defaults and bumping up the max connections in Postgres configuration appropriately. With the client default at 30, the corresponding max connections setting for our deployment of 100 Anchore services should be at least 3000 (30 * 100). As long as your database has enough resources to handle incoming connections then the Anchore service pool won’t bottleneck.
I want to caution that this guide isn’t the comprehensive list of things that can be tuned to help performance. It is intended to address a wide audience and is based on the most common performance issues we’ve seen in the field.