Sometimes, the best changes are the ones that you don’t notice. Well, some of you reading this may not have noticed, but there’s a good chance that many of you did notice a hiccup or two in Grype database availability that suddenly became a lot more stable.
One of the greatest things about Anchore, is that we are empowered to make changes quickly when needed. This is the story about doing just that: identifying issues in our database distribution mechanism and making a change to improve the experience for all our users.
A Heisenbug is born
It all started some time ago, in a galaxy far away. As early as 2022, when we received reports that some users had issues downloading the Grype database. These issues included general slowness and timeouts, with users receiving the dreaded: context deadline exceeded; and manually downloading the database from a browser could show similar behavior:

Debugging these transient single issues among thousands of legitimate, successful downloads was problematic for the team, as no one could reproduce these reliably, so it remained unclear what the cause was. A few more reports trickled in here and there, but everything seemed to work well whenever we tested this ourselves. Without further information, we had to chalk this up to something like unreliable network transfers in specific regions or under certain conditions, exacerbated by the moderately large size of the database: about 200 MB, compressed.
To determine any patterns or provide feedback to our CDN provider that users are having issues downloading the files, we set up a job to download the database periodically, adding DataDog monitoring across many regions to do the same thing. We noticed a few things: periodic and regular issues downloading the database, and the failures seemed to correlate to high-volume periods – just after a new database was built, for example. We continued monitoring these, but the intermittent failures didn’t seem frequent enough to cause great concern.
Small things matter
At some point leading up to August, we also began to get reports of users experiencing issues downloading the Grype database listing file. When Grype downloads the database, it first downloads a listing file to determine if a newer database exists. At the time, this file contained a historical record of 450 databases worth of metadata (90 days × each of the 5 Grype database versions), so the listing file clocked in around 200 KB.
Grype only really needs the latest database, so the first thing we did was trim this file down to only the last few days; once we shrunk this file to under 5k, the issues downloading the listing file itself went away. This was our first clue about the problem: smaller files worked fine.
Fast forward to August 16, 2024: we awoke to multiple reports from people worldwide indicating they had the same issues downloading the database. We finally started to see the same thing ourselves after many months of being unable to reproduce the failures meaningfully. What happened? We had reached an inflection point of traffic that was causing issues with the CDN being able to deliver these files reliably to end users. Interestingly, the traffic was not from Grype but rather from Syft invocations checking for application updates: 1 million times per hour – approximately double what we saw previously, and this amount of traffic was beginning to affect users of Grype adversely – since they were served from the same endpoint, possibly due to the volume causing some throttling by the CDN provider.
The right tool for the job
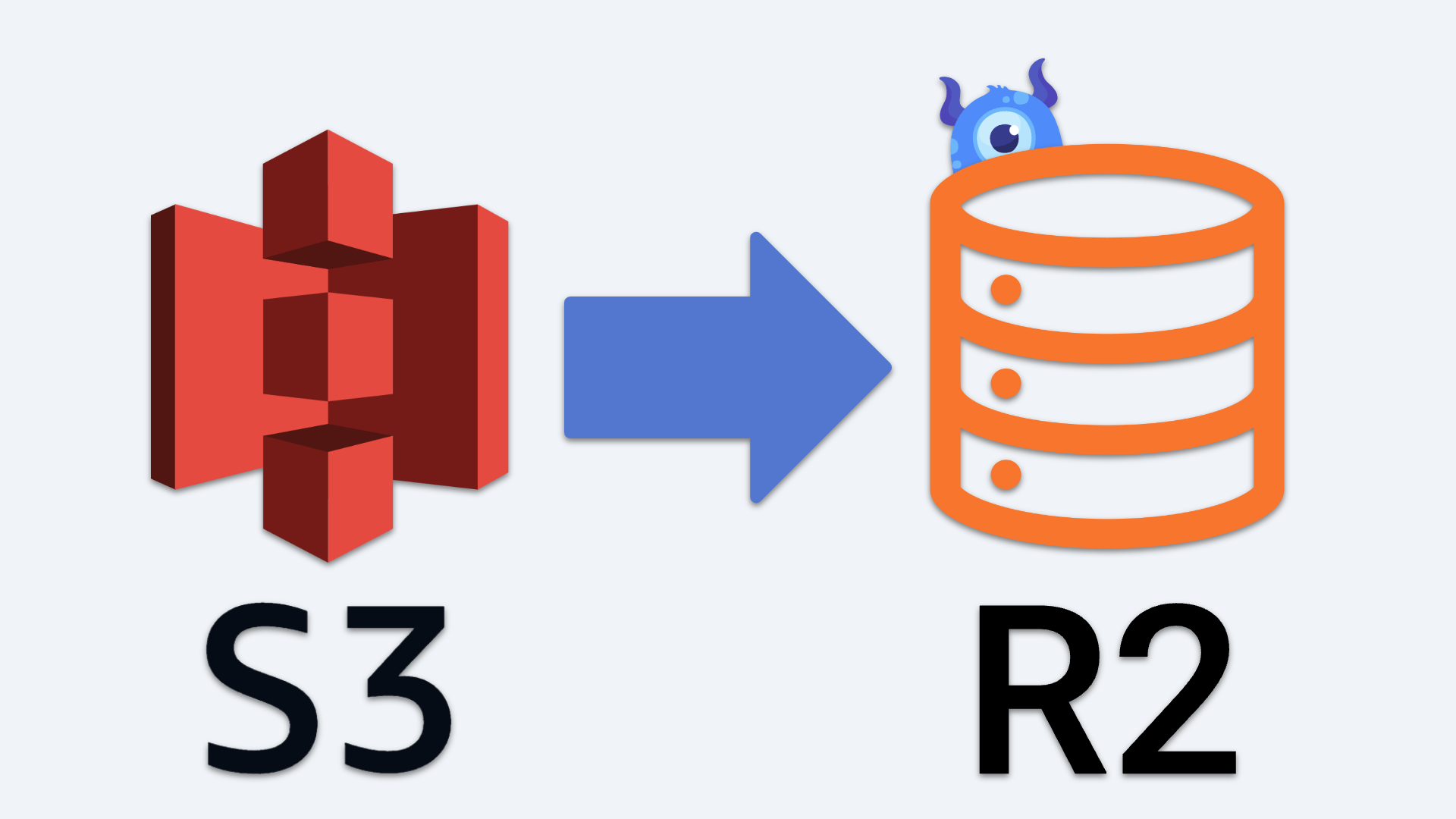
As a team, we had individually investigated these database failures, but we decided it was time for all of us to strap on our boots and solve this. The clue we had from decreasing the size of the listing file was crucial to understanding what was going on. We were using a standard CDN offering backed by AWS S3 storage.
Finding documentation about the CDN usage resulted in vague information that didn’t help us understand if we were decidedly doing something wrong or not. However, much of the documentation was evident in that it talked about web traffic, and we could assume this is how the service is optimized based on our experience with a more web-friendly sized listing file. After much reading, it started to sound like larger files should be served using the Cloudflare R2 Object Storage offering instead…

So that’s what we did: the team collaborated via a long, caffeine-fuelled Zoom call over an entire day. We updated our database publishing jobs to additionally publish databases and updated listing files to a second location backed by the Cloudflare R2 Object Storage service, served from grype.anchore.io instead of toolbox-data.anchore.io/grype.
We verified this was working as expected with Grype and finally updated the main listing file to point to this new location. The traffic load moved to the new service precisely as expected. This was completely transparent for Grype end-users, and our monitoring jobs have been green since!
While this wasn’t fun to scramble to fix, it’s great to know that our tools are popular enough to cause problems with a really good CDN service. Because of all the automated testing we have in place, our autonomy to operate independently, and robust publishing jobs, we were able to move quickly to address these issues. After letting this change operate over the weekend, we composed a short announcement for our community discourse to keep everyone informed.
Many projects experience growing pains as they see increased usage; our tools are no exception. Still, we were able almost seamlessly to provide everyone with a more reliable experience quickly and have had reports that the change has solved issues for them. Hopefully, we won’t have to make any more changes even when usage grows another 100x…
If you have any feedback for the Syft & Grype developers, head over to our community discourse.


