SANTA BARBARA, CA – October 9, 2025 – Anchore, a leading provider of software supply chain security solutions, today announced that it has achieved “Awardable” status through the Platform One (P1) Solutions Marketplace.
The P1 Solutions Marketplace is a digital repository of post-competition, 5-minute long readily-awardable pitch videos, which address the Government’s greatest requirements in hardware, software and service solutions.
Anchore’s solutions are designed to secure the software supply chain through comprehensive SBOM generation, vulnerability scanning, and compliance automation. They are used by a wide range of businesses, including Fortune 500 companies, government agencies, and organizations across defense, healthcare, financial services, and technology sectors.
“We’re honored to achieve Awardable status in the P1 Solutions Marketplace,” said Tim Zeller, Senior Vice President of Sales and Strategic Partnerships at Anchore. “Nation-state actors and advanced persistent threats are actively targeting the open source supply chain to infiltrate Department of Defense infrastructure. Our recognition in the P1 marketplace demonstrates that Anchore’s approach—combining open source tools like Syft and Grype with enterprise-grade solutions—can help defense organizations detect and defend against these sophisticated supply chain attacks at scale.”
Anchore’s video, “Secure Your Software Supply Chain with Anchore Enterprise,” accessible only by government customers on the P1 Solutions Marketplace, presents an actual use case in which the company demonstrates automated SBOM generation, vulnerability detection, and compliance monitoring across containerized and traditional software deployments. Anchore was recognized among a competitive field of applicants to the P1 Solutions Marketplace whose solutions demonstrated innovation, scalability, and potential impact on DoD missions. Government customers interested in viewing the video solution can create a P1 Solutions Marketplace account at https://p1-marketplace.com/.
It’s very likely you’ve heard of a new software supply chain memo from the US White House that came out in September 2022. The content of the memo has been discussed at length by others. The actual memo is quite short and easy to read, you wouldn’t regret just reading it yourself.
The very quick summary of this document is that everyone working with the US Government will need to start following NIST 800-218, also known as the NIST Secure Software Development Framework, or SSDF. This is a good opportunity to talk about how we can start to do something with SSDF today. For the rest of this post we’re going to review the actual SSDF standard and start creating a plan of tackling what’s in it. The memo isn’t the interesting part, SSDF is.
This is going to be the first of many, many blog posts as there’s a lot to cover in the SSDF. Some of the controls are dealt with by policy. Some are configuration management, some are even software architecting. Depending on each control, there will be many different ways to meet the requirements. No one way is right, but there are solutions that are easier than others. This series will put extra emphasis on the portions of SSDF that deal with software bill of materials (SBOM) specifically, but we are not going to ignore the other parts.
An Introduction to the Secure Software Development Framework (SSDF)
If this is your first time trying to comply with a NIST standard, keep in mind this will be a marathon. Nobody starts following the entire compliance standard on day one. Make sure to set expectations with yourself and your organization appropriately. Complying with a standard will often take months. There’s also no end state, these standards need to be thought about as continuous projects, not one and done.
If you’re looking to start this journey I would suggest you download a spreadsheet NIST has put together that details the controls and standards for SSDF. It looks a little scary the first time you load it up, but it’s really not that bad. There are 42 controls. That’s actually a REALLY small number as far as NIST standards go. Usually you will see hundreds or even thousands.
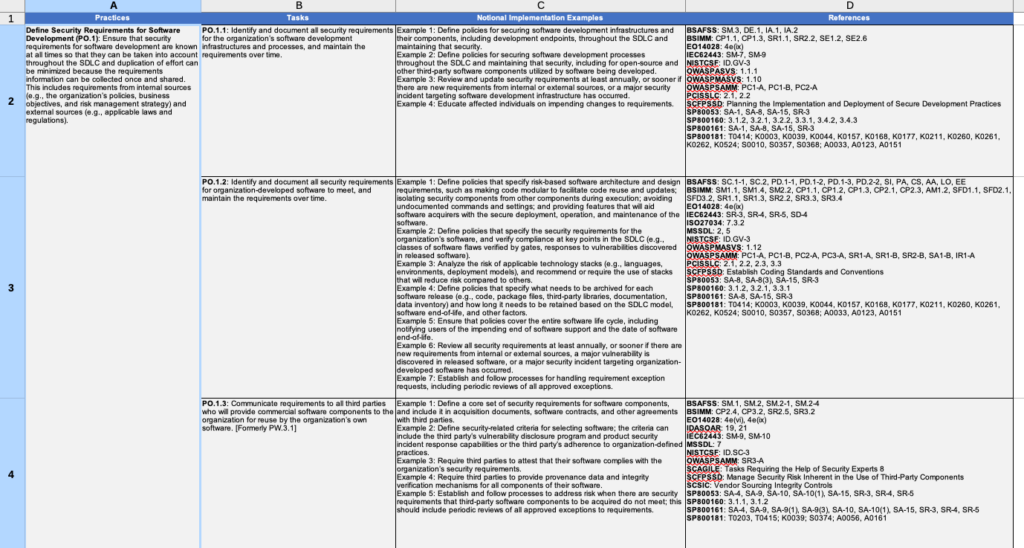
An Overview of the NIST SSDF Spreadsheet
There are 4 columns: Practices, Tasks, Notional Implementation Examples, References
If we break it down further we see there are 19 practices and 42 Tasks. While this all can be intimidating, we can work with 19 practices and 42 tasks. The practices are the logical groupings of tasks, and the tasks are the actual controls we have to meet. The SSDF document covers all this in greater detail, but the spreadsheet makes everything more approachable and easy to group together.
The Examples Column
The examples column is where the spreadsheet really shines. The examples are how we can better understand the intent of a given control. Every control has multiple examples and they are written in a way anyone can understand. The idea here isn’t to force a rigid policy on anyone, but to show there are many ways to accomplish these tasks. Most of us learn better from examples than we do from technical control text, so be sure to refer to the examples often.
The References Section
The references sections are scary looking. Those are a lot of references and anyone who tries to read them all will be stuck for weeks or months. It’s OK though, they aren’t something you have to actively read, it’s to help give us additional guidance if something isn’t clear. There’s already a lot of security guidance out there, it can be easier to cross reference work that already exists than it is to make up all new content. This is how you can get clarifying guidance on the tasks. It’s also possible you already are following one or more of these standards which means you’ve already started your SSDF journey.
The Tasks
Every task has a certain theme. There’s no product you can buy that will solve all of these requirements. Some themes can only be met with policy. Some are secure software development processes. Most will have multiple ways to meet them. Some can be met with commercial tools, some can be met with open source tools.
Interpreting the Requirements
Let’s cover a very brief example (we will cover this in far more detail in a future blog post). PO 1.3. 3rd party requirements. The text of this reads
PO.1.3: Communicate requirements to all third parties who will provide commercial software components to the organization for reuse by the organization’s own software. [Formerly PW.3.1]
This requirement revolves around communicating your own requirements to your suppliers. But today the definition of supplier isn’t always obvious. You could be working with a company. But what if you’re working with open source? What if the company you’re working with is using open source? The important part of this is better explained in the examples: Example 3: Require third parties to attest that their software complies with the organization’s security requirements.
It’s easier to understand this in the context of having your supplier prove they are in compliance with your requirements. Proving compliance can be difficult in the best situations. Keep in mind you can’t just do this in one step. You probably first just need to know what you have (SBOM is a great way to do this.) Once you know what you have, you can start to define expectations for others. And once you have expectations and an SBOM you can hand out an attestation.
One of the references for this one is NIST 800-160. If we look at section 3.1.1, there are multiple pages that explain the expectations. There isn’t a simple solution as you will see if you read through NIST 800-160. This is an instance where a combination of policy, technology, and process will all come together to ensure the components used are held to a certain standard.
This is a lot to try to take in all at once, so we should think about how to break this down. Many of us already have existing components. How we tackle this with existing components is not the same approach we would take with a brand new application security project. One way to think about this is you will first need an inventory of your components before you can even try to create expectations for your suppliers.
We could go on explaining how to meet this control, but for now let’s just leave this discussion here. The intent was to show what this challenge looks like, not to try to solve it today. We will revisit this in another blog post when we can dive deep into the requirements and some ideas on how to meet the control requirements, and even define what those requirements are!
Your Next Steps
Make sure you check back for the next post in this series where we will take a deep dive into every control specified by the SSDF. New compliance requirements are a challenge, but they exist to help us improve what we are already doing in terms of secure software development practices. Securing the software supply chain is not just a popular topic, it’s a real challenge we all have to meet now. It’s easy to talk about securing the software supply chain, it’s a lot of hard work to actually secure it. But luckily for us there is more information and examples to build off of than ever before. Open source isn’t about code, it’s about sharing information and building communities. Anchore has several ways to help you on this journey. You can contact us, join our community Discourse forum, and check out our open source projects: Syft and Grype.
Josh Bressers Josh Bressers is vice president of security at Anchore where he guides security feature development for the company’s commercial and open source solutions. He serves on the Open Source Security Foundation technical advisory council and is a co-founder of the Global Security Database project, which is a Cloud Security Alliance working group that is defining the future of security vulnerability identifiers.
Last week the NSA, CISA, and ODNI released a guide that lays out supply chain security, but with a focus on developers. This was a welcome break from much of the existing guidance we have seen which mostly focuses on deployment and integration rather than the software developers. The software supply chain is a large space, and that space includes developers.
The guide is very consumable. It’s short and written in a way anyone can understand. The audience on this one is not compliance professionals. They also provide fantastic references. Re-explaining the document isn’t needed, just go read it.
However, even though the guide is very readable, it could be considered immature compared to much of the other guidance we have seen come from the government recently. This immaturity of a developer focused supply chain guide came through likely because this is in fact an immature space. Developer compliance has never been successful outside of some highly regulated industries and this guide reminds us why. Much of the guidance presented has themes of the old heavy handed way of trying to do security, while also attempting to incorporate some new and interesting concepts being pioneered by groups such as the Open Source Security Foundation (OpenSSF).
For example, there is guidance being presented that suggests developer systems not be connected to the Internet. This was the sort of guidance that was common a decade ago, but no developers could imagine trying to operate a development environment without Internet access now. This is a non-starter in most organizations. The old way of security was to create heavy handed rules developers would find ways to work around. The new way is to empower developers while avoiding catastrophic mistakes.
But next to outdated guidance, we see modern guidance such as using Supply chain Levels for Software Artifacts, or SLSA. SLSA is a series of levels that can be attained when creating software to help ensure integrity of the built artifacts. SLSA is an open source project that is part of the OpenSSF project that is working to create controls to help secure our software artifacts.
If we look at SLSA Level 1 (there are 4 levels), it’s clearly the first step in a journey. All we need to do for SLSA level 1 is keep metadata about how an artifact was built and what is in it. Many of us are already doing that today! The levels then get increasingly more structured and strict until we have a build system that cannot connect to the internet, is version controlled, and signs artifacts. This gradual progress makes SLSA very approachable.
There are also modern suggestions that are very bleeding edge and aren’t quite ready yet. Reproducible builds are mentioned, but there is lack of actionable guidance on how to accomplish this. Reproducible builds are an idea where you can build the source code for a project on two different systems and get the exact same output, bit for bit. Today everyone doing reproducible builds does so from enormous efforts, not because the build systems allow it. It’s not realistic guidance for the general public yet.
The guide expands the current integrator guidance of SBOM and verifying components is an important point. It seems to be pretty accepted at this point that generating and consuming SBOMs are table stakes in the software world. The guide reflects this new reality.
Overall, this guide has an enormous amount of advice contained in it. Nobody could do all of this even if they wanted to, don’t feel like this is an all or none effort. This is a great starting point for developer supply chain security. We need to better define the guidance we can give to developers to secure the supply chain. This guide is the first step, the first draft is never perfect, but the first draft is where the journey begins.
Understand what you are doing today, figure out what you can easily do tomorrow, and plan for some of the big things well into the future. And most importantly, ignore the guidance that doesn’t fit into your environment. When guidance doesn’t match with what you’re doing it doesn’t mean you’re doing it wrong. Sometimes the guidance needs to be adjusted. The world often changes faster than compliance does.
The most important takeaway isn’t to view this guide as an end state. This guide is the start of something much bigger. We have to start somewhere, and developer supply chain security starts here. Both how we protect the software supply chain and how we create guidance are part of this journey. As we grow and evolve our supply chain security, we will grow and evolve the guidance and best practices.
We are pleased to announce the release of Anchore Enterprise v4.1 which contains a major new service to help reduce false positives as well as improvements to our SBOM Drift capability, RHEL 9 support, and updates to the AnchoreCTL command line tool. Read on to learn more!
Reducing False Positives with the new curated Anchore Vulnerability Feed
For most security teams who are doing vulnerability management, handling false positives is the biggest source of frustration and wasted time. A large number of false positives affect every user, independent of their environment, for one of two major reasons: incorrectly identified software contents that appear to be vulnerable or incomplete data in the vulnerability feed itself.
In 2021, to address the challenge of misidentified components, Anchore introduced two features, SBOM Hints and SBOM Corrections, that allow users to adjust the metadata to ensure more accurate generation of the SBOM. This, in turns, provides better mapping to the list of vulnerabilities.
With Anchore Enterprise 4.1, we are excited to offer the Anchore Vulnerability Feed which addresses the second issue of incomplete data in public feeds, especially from the National Vulnerability Database (NVD). The Anchore Vulnerability Feed uses data gathered from Anchore’s user community, customer environments, and research done by the Anchore Security Team. This data is used to identify inaccurate metadata in public vulnerability feeds. Once problematic metadata is identified, the Anchore Vulnerability Feed prevents matches against a software component either through a managed exclusion list or by enhancing the metadata itself.
All customers can request an assessment of a potential false positive through the Anchore support portal. As Anchore discovers and adds new data to the feed, customers will benefit from live updates which immediately reduce false positives on the customer site without any need for administration changes or software updates. This feature is available to all existing customers across all tiers.
Detect Malicious Activity and Misconfiguration with SBOM Drift Enhancements
Ever since the Solarwinds compromise, companies have become aware that malicious components can be added during development to create attack vectors. To help with detecting this type of attack, Anchore added a capability in Anchore Enterprise 4.0 called SBOM Drift which looked for when components were being added, changed, or removed during the software development life cycle. The initial feature enabled users to detect and alert on changes between builds of container images. Anchore Enterprise 4.1 further expands on this capability by adding the ability to detect drift between the SBOM generated from a source code repository and the SBOM generated from the resulting build. While some drift is normal as packages are added as dependencies or included from the base operating system, some drift is not.
New policy rules can catch changes such as downgrades in version numbers which may be a result of either tampering or misconfigurations. Drift alerts are configurable and can be set to either warn or fail a build based on your requirements. The underlying API to the service allows users to query the changes for reporting and to track dependency usage.
Unified and improved command line experience with AnchoreCTL 1.0
Part of the power of Anchore Enterprise is the extensive API coverage and the flexibility of integrating with 3rd party tools and platforms. Since the first launch of our product, the main tool for interacting with any of Anchore Enterprise’s functions via the command line has been anchore-cli. This tool was used to request operations, status, or pull data from the backend. At the beginning of the year, we introduced a next-generation tool called AnchoreCTL, written in GoLang and provided as a standalone client tool. AnchoreCTL allowed a user to interact with Anchore Enterprise application grouping and source code/image SBOM features.
Along with Anchore Enterprise 4.1, we are releasing AnchoreCTL v1.0 which now has all of the capabilities previously provided by anchore-cli, but in a simple, unified experience. Provided as a Go binary, it reduces the environment requirements to run the tool on systems such as runners in a CI/CD environment and simplifies the administrative experience of working with Anchore Enterprise.
Additionally, the user experience for interacting with operations like sbom management and application management has been massively simplified. Operations which took multiple command line invocations can now be performed with a single operation.
RHEL9 and clone support
Finally, Anchore Enterprise 4.1 can now scan and continuously monitor RHEL 9 and CentOS 9 Stream container images for any security issues present in installed packages for these operating systems. These packages are now included in generated SBOMs and customers can be applied to Anchore’s customizable policy enforcement.
For more information about the product or to get started with a trial license, please contact Anchore.