It’s very likely you’ve heard of a new software supply chain memo from the US White House that came out in September 2022. The content of the memo has been discussed at length by others. The actual memo is quite short and easy to read, you wouldn’t regret just reading it yourself.
The very quick summary of this document is that everyone working with the US Government will need to start following NIST 800-218, also known as the NIST Secure Software Development Framework, or SSDF. This is a good opportunity to talk about how we can start to do something with SSDF today. For the rest of this post we’re going to review the actual SSDF standard and start creating a plan of tackling what’s in it. The memo isn’t the interesting part, SSDF is.
This is going to be the first of many, many blog posts as there’s a lot to cover in the SSDF. Some of the controls are dealt with by policy. Some are configuration management, some are even software architecting. Depending on each control, there will be many different ways to meet the requirements. No one way is right, but there are solutions that are easier than others. This series will put extra emphasis on the portions of SSDF that deal with SBOM specifically, but we are not going to ignore the other parts.
An Introduction to the Secure Software Development Framework (SSDF)
If this is your first time trying to comply with a NIST standard, keep in mind this will be a marathon. Nobody starts following the entire compliance standard on day one. Make sure to set expectations with yourself and your organization appropriately. Complying with a standard will often take months. There’s also no end state, these standards need to be thought about as continuous projects, not one and done.
If you’re looking to start this journey I would suggest you download a spreadsheet NIST has put together that details the controls and standards for SSDF. It looks a little scary the first time you load it up, but it’s really not that bad. There are 42 controls. That’s actually a REALLY small number as far as NIST standards go. Usually you will see hundreds or even thousands.
An Overview of the NIST SSDF Spreadsheet
There are 4 columns: Practices, Tasks, Notional Implementation Examples, References
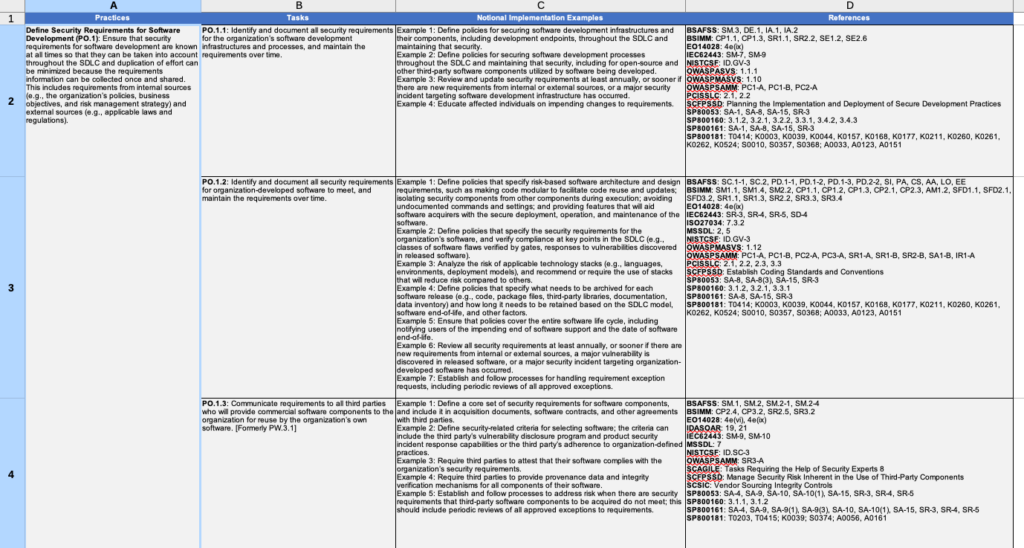
If we break it down further we see there are 19 practices and 42 Tasks. While this all can be intimidating, we can work with 19 practices and 42 tasks. The practices are the logical groupings of tasks, and the tasks are the actual controls we have to meet. The SSDF document covers all this in greater detail, but the spreadsheet makes everything more approachable and easy to group together.
The Examples Column
The examples column is where the spreadsheet really shines. The examples are how we can better understand the intent of a given control. Every control has multiple examples and they are written in a way anyone can understand. The idea here isn’t to force a rigid policy on anyone, but to show there are many ways to accomplish these tasks. Most of us learn better from examples than we do from technical control text, so be sure to refer to the examples often.
The References Section
The references sections are scary looking. Those are a lot of references and anyone who tries to read them all will be stuck for weeks or months. It’s OK though, they aren’t something you have to actively read, it’s to help give us additional guidance if something isn’t clear. There’s already a lot of security guidance out there, it can be easier to cross reference work that already exists than it is to make up all new content. This is how you can get clarifying guidance on the tasks. It’s also possible you already are following one or more of these standards which means you’ve already started your SSDF journey.
The Tasks
Every task has a certain theme. There’s no product you can buy that will solve all of these requirements. Some themes can only be met with policy. Some are secure software development processes. Most will have multiple ways to meet them. Some can be met with commercial tools, some can be met with open source tools.
Interpreting the Requirements
Let’s cover a very brief example (we will cover this in far more detail in a future blog post). PO 1.3. 3rd party requirements. The text of this reads
PO.1.3: Communicate requirements to all third parties who will provide commercial software components to the organization for reuse by the organization’s own software. [Formerly PW.3.1]
This requirement revolves around communicating your own requirements to your suppliers. But today the definition of supplier isn’t always obvious. You could be working with a company. But what if you’re working with open source? What if the company you’re working with is using open source? The important part of this is better explained in the examples: Example 3: Require third parties to attest that their software complies with the organization’s security requirements.
It’s easier to understand this in the context of having your supplier prove they are in compliance with your requirements. Proving compliance can be difficult in the best situations. Keep in mind you can’t just do this in one step. You probably first just need to know what you have (SBOM is a great way to do this.) Once you know what you have, you can start to define expectations for others. And once you have expectations and an SBOM you can hand out an attestation.
One of the references for this one is NIST 800-160. If we look at section 3.1.1, there are multiple pages that explain the expectations. There isn’t a simple solution as you will see if you read through NIST 800-160. This is an instance where a combination of policy, technology, and process will all come together to ensure the components used are held to a certain standard.
This is a lot to try to take in all at once, so we should think about how to break this down. Many of us already have existing components. How we tackle this with existing components is not the same approach we would take with a brand new application security project. One way to think about this is you will first need an inventory of your components before you can even try to create expectations for your suppliers.
We could go on explaining how to meet this control, but for now let’s just leave this discussion here. The intent was to show what this challenge looks like, not to try to solve it today. We will revisit this in another blog post when we can dive deep into the requirements and some ideas on how to meet the control requirements, and even define what those requirements are!
Your Next Steps
Make sure you check back for the next post in this series where we will take a deep dive into every control specified by the SSDF. New compliance requirements are a challenge, but they exist to help us improve what we are already doing in terms of secure software development practices. Securing the software supply chain is not just a popular topic, it’s a real challenge we all have to meet now. It’s easy to talk about securing the software supply chain, it’s a lot of hard work to actually secure it. But luckily for us there is more information and examples to build off of than ever before. Open source isn’t about code, it’s about sharing information and building communities. Anchore has several ways to help you on this journey. You can contact us, join our community Slack, and check out our open source projects: Syft and Grype.
Josh Bressers
Josh Bressers is vice president of security at Anchore where he guides security feature development for the company’s commercial and open source solutions. He serves on the Open Source Security Foundation technical advisory council and is a co-founder of the Global Security Database project, which is a Cloud Security Alliance working group that is defining the future of security vulnerability identifiers.