We generate a lot of tooling at Anchore. What started as a few focused utilities has grown into a suite of open source tools for software supply chain security: Syft for SBOM generation, Grype for vulnerability scanning, Grant for license compliance, … and more on the way.
For a while, we made do with putting all content into in-repo READMEs. The reality is, we’ve reached a new inflection point where there is simply too much rich tooling and content to reasonably cram into a handful of README files. We’re growing, we’re expanding, and we need a proper home to capture everything we’re building.
And so, we present the shiny new hub for documenting all things related to Anchore OSS: oss.anchore.com.
Why a separate site?
The short answer: there’s just too much to say.
Our tools have matured. They support dozens of package ecosystems and operating systems. They have configuration options that deserve proper explanation. Users have real workflows: generating SBOMs in CI, scanning container images, and building license compliance reports. All of these workflows deserve guides that walk a user through them properly.
We also wanted a place to share some of the thinking behind how we build things. What component analysis capabilities do we have for each language ecosystem? What’s our philosophy and conventions around building go tools? What are a set of really useful jq recipes when working with Syft JSON output? These are things that don’t fit neatly into a README but are genuinely useful if you’re trying to understand or contribute to the projects.
What you’ll find there
The site is organized around a few main areas:
User Guides cover the things you’re most likely trying to do: generate an SBOM, scan for vulnerabilities, check license compliance. These are task-oriented and walk you through real workflows.
Ecosystem and OS Coverage describes what we support and how. Different package managers and operating systems have their own quirks; this is where we document them.
Per-Tool Reference is where you’ll find the detailed stuff: CLI documentation, configuration file reference, JSON schema definitions. The kind of thing you need when you want to know every nook and cranny of what you can make the tools describe.
Architecture and Philosophy gets into the “why” and “how” behind the tools. How Syft catalogs packages, how Grype matches vulnerabilities, how we think about building Go utilities on the Anchore OSS team.
Contributing Guides are for folks who want to get involved. We’ve tried to lower the barrier to entry for new contributors.
This is where it all lives now
We’re not abandoning READMEs entirely. They’ll still point you in the right direction and cover installation basics. But for anything beyond “here’s how to install it and run a basic command,” oss.anchore.com is the place to find everything else.
The site codebase is open source like everything else we do. If you spot something wrong, something missing, or something confusing about the doc site itself; PRs are welcome. We’d love feedback on what’s helpful and what’s not.
In our latest Grype release, we’ve updated the DB schema to v6. This update isn’t just a cosmetic change; it’s a thoughtful redesign that optimizes data storage and matching performance. For you, this means faster database updates (65MB vs 210MB downloads), quicker scans, and more comprehensive vulnerability detection, all while maintaining the familiar output format and user experience you rely on.
The Past: Schema v5
Originally, grype’s vulnerability data was managed using two main tables:
VulnerabilityModel: This table stores package-specific vulnerability details. Each affected package version required a separate row, which led to significant metadata duplication.
VulnerabilityMetadataModel: To avoid duplicating large strings (like detailed vulnerability descriptions), metadata was separated into its own table.
This v1 design was born out of necessity. Early CGO-free SQLite drivers didn’t offer SQLite’s plethora of features. In later releases we were able to swap out the SQLite driver to the newly available modernc.org/sqlite driver and use GORM for general access.
However, v2 – v5 had the same basic design approach. This led to space inefficiencies: the on-disk footprint grew to roughly 1.6 GB, and the cost was notable even after compression (210 MB as a tar.gz).
When it came to searching the database, we organized rows into “namespaces” which was a string that indicated the intended ecosystem this affected (e.g. a specific distro name + version, a language name, etc, for instance redhat:distro:redhat:7 or cpe:nvd).
When searching for matches in Grype, we would cast a wide net on an initial search within the database by namespace + package name and refine the results by additionally parsed attributes, effectively casting a smaller net as we progressed. As the database grew we came across more examples where the idea of a “namespace” just didn’t make sense (for instance, what if you weren’t certain what namespace your software artifact landed in, do you simply search all namespaces?). We clearly needed to remove the notion of namespaces as a core input into searching the database.
Another thing that happened after the initial release of the early Grype DB schemas: the Open Source Vulnerability schema (OSV) was released. This format enabled a rich, machine-readable format that could be leveraged by vulnerability data providers when publishing vulnerability advisories, and meant that tools could more easily consume data from a broad set of vulnerability sources, providing more accurate results for end users. We knew that we wanted to more natively be able to ingest this format and maybe even express records internally in a similar manner.
The Present: Schema v6
To address these challenges, we’ve entirely reimagined how Grype stores and accesses vulnerability data:
At a high level, the new DB is primarily a JSON blob store for the bulk of the data, with specialized indexes for efficient searching. The stored JSON blobs are heavily inspired by the OSV schema, but tailored to meet Grype’s specific needs. Each entity we want to search by gets its own table with optimized indexes, and these rows point to the OSV-like JSON blob snippets.
Today, we have three primary search tables:
AffectedPackages: These are packages that exist in a known language, packaging ecosystem, or specific Linux distribution version.
AffectedCPEs: These are entries from NVD which do not have a known packaging ecosystem.
Vulnerabilities: These contain core vulnerability information without any packaging information.
One of the most significant improvements is removing “namespaces” entirely from within the DB. Previously, client-based changes were needed to craft the correct namespace for database searches. This meant shipping software updates for what were essentially data corrections. In v6, we’ve shifted these cases to simple lookup tables in the DB, normalizing search input. We can fix or add search queries through database updates alone, no client update required.
Moreover, the v6 schema’s modular design simplifies extending functionality. Integrating additional vulnerability feeds or other external data sources is now far more straightforward, ensuring that Grype remains flexible and future-proof.
The Benefits: What’s New in the Database
In terms of content, v6 includes everything from v5 plus important additions:
Withdrawn vulnerabilities: We now persist “withdrawn” vulnerabilities. While this doesn’t affect matching, it improves reference capabilities for related vulnerability data
Enhanced datasets: We’ve added the CISA Known Exploited Vulnerabilities and EPSS (Exploit Prediction Scoring System) datasets to the database
The best way to explore this data is with the grype db search and grype db search vuln commands.
search allows you to discover affected packages by a wide array of parameters (package name, CPE, purl, vulnerability ID, provider, ecosystem, linux distribution, added or modified since a particular date, etc):
As with all of our tools, there is -o json available with these commands to be able to explore the raw affected package, affected CPE, and vulnerability records:
$ grype db search vuln CVE-2021-44228 -o json --provider nvd[ {"id": "CVE-2021-44228","assigner": ["[email protected]" ],"description": "Apache Log4j2 2.0-beta9 through 2.15.0 (excluding security releases 2.12.2, 2.12.3, and 2.3.1) JNDI features...","refs": [...],"severities": [...],"provider": "nvd","status": "active","published_date": "2021-12-10T10:15:09.143Z","modified_date": "2025-02-04T15:15:13.773Z","known_exploited": [ {"cve": "CVE-2021-44228","vendor_project": "Apache","product": "Log4j2","date_added": "2021-12-10","required_action": "For all affected software assets for which updates exist, the only acceptable remediation actions are: 1) Apply updates; OR 2) remove affected assets from agency networks. Temporary mitigations using one of the measures provided at https://www.cisa.gov/uscert/ed-22-02-apache-log4j-recommended-mitigation-measures are only acceptable until updates are available.","due_date": "2021-12-24","known_ransomware_campaign_use": "known","urls": ["https://nvd.nist.gov/vuln/detail/CVE-2021-44228" ],"cwes": ["CWE-20","CWE-400","CWE-502" ] } ],"epss": [ {"cve": "CVE-2021-44228","epss": 0.97112,"percentile": 0.9989,"date": "2025-03-03" } ] }]
Dramatic Size Reduction: The Technical Journey
One of the standout improvements of v6 is the dramatic size reduction:
Metric
Schema v5
Schema v6
Improvement
Raw DB Size
1.6 GB
900 MB
44% smaller
Compressed Archive
210 MB
65 MB
69% smaller
This means you’ll experience significantly faster database updates and reduced storage requirements.
We build and distribute Grype database archives daily to provide users with the most up-to-date vulnerability information. Over the past five years, we’ve added more vulnerability sources, and the database has more than doubled in size, significantly impacting users who update their databases daily.
Our optimization strategy included:
Switching to zstandard compression: This yields better compression ratios compared to gzip, providing immediate space savings.
Database layout optimization: We prototyped various database layouts, experimenting with different normalization levels (database design patterns that eliminate data redundancy). While higher normalization saved space in the raw database, it sometimes yielded worse compression results. We found the optimal balance between normalization and leaving enough unnormalized data for compression algorithms to work effectively.
Real-World Impact
These improvements directly benefit several common scenarios:
CI/CD Pipelines: With a 69% smaller download size, your CI/CD pipelines will update vulnerability databases faster, reducing build times and costs.
Air-gapped Environments: If you’re working in air-gapped environments and need to transport the database, its significantly smaller size makes this process much more manageable.
Resource-constrained Systems: The smaller memory footprint means Grype can now run more efficiently on systems with limited resources.
Conclusion
The evolution of the Grype database schema from v5 to v6 marks a significant milestone. By rethinking our database structure and using the OSV schema as inspiration, we’ve created a more efficient, scalable, and feature-rich database that directly benefits your vulnerability management workflows.
We’d like to encourage you to update to the latest version of Grype to take advantage of these improvements. If you have feedback on the new schema or ideas for further enhancements, please share them with us on Discourse, and if you spot a bug, let us know on GitHub.
If you’d like to get updates about the Anchore Open Source Community, sign up for our low-traffic community newsletter. Stay tuned for more updates as we refine Grype and empower your security practices!
When running vulnerability scans against your software dependencies it’s important to have the most up to date vulnerability information that’s been published. New vulnerabilities are found all the time, the data goes stale quickly. For current Grype users, we have a daily pipeline that builds and publishes a Grype database with the latest vulnerability data. Up until now the tooling that drives this pipeline has not been available as open source since it was originally designed as an embedded aspect of Anchore’s commercial products. Today that’s changing!
How does this help the average Grype user? By making the framework and code that are used to prepare vulnerability data sources open, the entire open source community (even you!) can contribute improvements and new vulnerability data sources, enhancing both the breadth and quality of vulnerability scanning for all.
We’re happy to announce two new open source projects: Vunnel and Grype-DB.
Vunnel (short for “vulnerability data funnel”) understands how to pull and process vulnerability from various upstream data sources, such as NVD, Github Security Advisories, and multiple Linux distribution providers. This allows you to prepare a data directory with indexed and normalized vulnerability data. This sounds simple, but all of this vulnerability data is different and varies widely in its quality and composition. Vunnel gives us some control to normalize this data in a way that gives better consistency.
Grype-DB builds an SQLite database that Grype can use based off of the data that Vunnel outputs. Even more, Grype-DB can invoke Vunnel in order to prepare a data directory for multiple providers, allowing you to orchestrate and tailor which providers you want to include in the database.
This puts the entire Grype vulnerability data pipeline and surrounding tooling into the open source! This includes all of the providers that drive Grype today: Alpine, Amazon Linux, Centos, Debian, GitHub Security Advisories, NVD, Oracle Linux, RedHat Enterprise Linux, SUSE Linux Enterprise, Ubuntu, and Wolfi. Anyone can now fully participate in the data processing for the Grype ecosystem, expanding the vulnerability matching capabilities of Grype (for example, adding support for new Linux distributions in Grype).
We’re excited to see what community contributions arise from this effort! Stay tuned for a tutorial to show you how to implement a new Vunnel provider.
We generate a lot of tooling at Anchore. We chose to write most of these tools in Go for a few reasons: the development process is delightful, cross-platform builds are easy, and the distribution of artifacts is very simple (curl the binary).
Since we target releasing tools for macOS we are beholden to the requirements put forth by Apple, something we’ve written aboutat length in the past. Tools like gon have made the process of signing and notarizing our releases much easier by wrapping xcrun and codesign utilities and hiding some of the inherent complexities. However, since gon shells out to these tools you still must be on a mac to sign and notarize your binaries. This nullifies one of the reasons why we chose Go in the first place: having simple cross-platform builds from any platform.
We’ve reworked our release process a few times over to account for this, all with unpleasant tradeoffs. It seems to come down to a couple of points:
Using Docker on macOS in CI is annoying. Due to licensing restrictions Docker is not included on the default mac runners. This is problematic since we use goreleaser to perform the build and release steps in one shot, which means we need to be able to sign/notarize our binaries at the same time as we package and release them for all platforms. This has only very recently been alleviated with the addition of colima on the default mac runner, but before this it has caused us to slice-and-dice up our release pipeline in awkward ways.
After a while we started to wonder to ourselves: Is it intrinsically necessary to require the signing and notarization steps to run on a mac? The more we looked the more we were certain the answer was “no”.
What’s in a signed binary anyway?
When you run codesign to sign your binary a new payload is added at the end of the binary with (usually) the following sections:
A Code Directory: essentially a table of hashes. Each hash is a digest of each page in the binary before the new payload. The code directory is “what” gets signed.
A PKCS7 (CMS) envelope: contains the cryptographic signature made against the Code Directory.
A Set of Requirements (optional): expressions that are evaluated against the signature that should hold true. “Designated Requirements” are a special set of requirements that describe how to determine the identity of the code being signed.
It seems that the only reason why we are signing and notarizing our releases on macOS is because Apple does not yet provide cross-platform tooling to do so…
Introducing Quill
We created a new tool called Quill to sign and notarize your macOS binary from any platform.
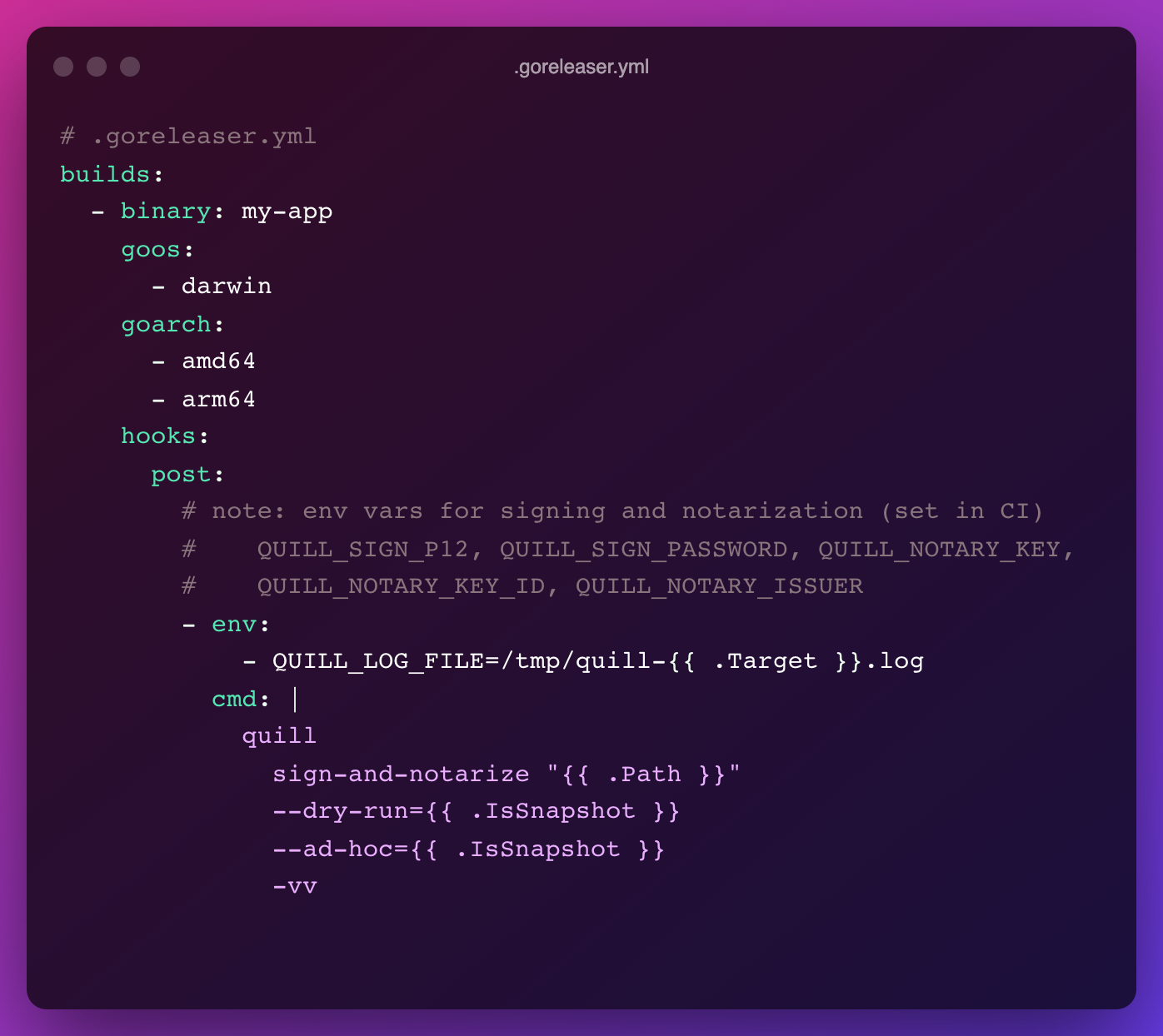
This works quite well with goreleaser as a post-build step:
In this way you can use a single goreleaser file for local builds and production builds:
Signing and notarization are performed for production builds.
Ad-hoc signing is done for snapshot builds (notarization is skipped). This means that no cryptographic material is needed as input, so the Code Directory is added to the binary but there is no signature attached.
You can additionally use Quill to:
View your previous notarization submissions with “quill submission list”
Get the logs from Apple about the details of a submission result with “quill submission logs <submission-id>”
Parse and describe a macOS binary (including all signing details) with “quill describe ./path/to/binary”
We are now using quill for our production releases of Syft and Grype and have room to implement more features in the future to expand the capabilities of quill to match that of codesign. Quill is an open source project — we would love feedback, bug reports, and pull requests!