That’s why we’re excited to announce our new white paper, “Unlocking Federal Markets: The Enterprise Guide to FedRAMP.” This comprehensive resource is designed for cloud service providers (CSPs) looking to navigate the complex FedRAMP authorization process, providing actionable insights and step-by-step guidance to help you access the lucrative federal cloud marketplace.
From understanding the authorization process to implementing continuous monitoring requirements, this guide offers a clear roadmap through the FedRAMP journey. More than just a compliance checklist, it delivers strategic insights on how to approach FedRAMP as a business opportunity while minimizing the time and resources required.
⏱️ Can’t wait till the end? 📥 Download the white paper now 👇👇👇
FedRAMP is the gateway to federal cloud business, but many organizations underestimate its complexity and strategic importance. Our white paper transforms your approach by:
Clarifying the Authorization Process: Understand the difference between FedRAMP authorization and certification, and learn the specific roles of key stakeholders.
Streamlining Compliance: Learn how to integrate security and compliance directly into your development lifecycle, reducing costs and accelerating time-to-market.
Establishing Continuous Monitoring: Build sustainable processes that maintain your authorization status through the required continuous monitoring activities.
Creating Business Value: Position your FedRAMP authorization as a competitive advantage that opens doors across multiple agencies.
What’s Inside the White Paper?
Our guide is organized to follow your FedRAMP journey from start to finish. Here’s a preview of what you’ll find:
FedRAMP Overview: Learn about the historical context, goals and benefits of the program.
Key Stakeholders: Understand the roles of federal agencies, 3PAOs and the FedRAMP PMO.
Authorization Process: Navigate through all phases—Preparation, Authorization and Continuous Monitoring—with detailed guidance for each step.
Strategic Considerations: Make informed decisions about impact levels, deployment models and resource requirements.
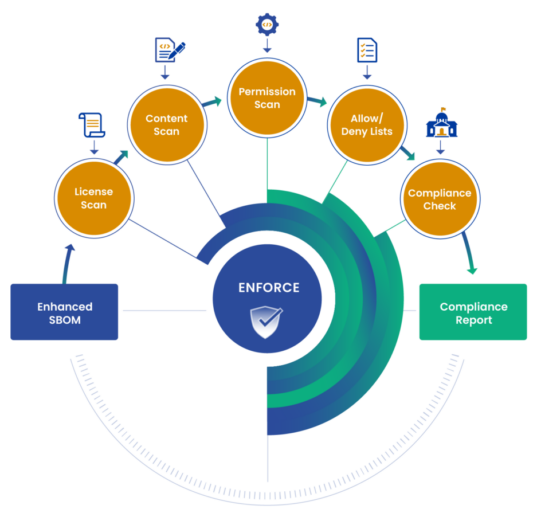
Compliance Automation: Discover how Anchore Enforce can transform FedRAMP from a burdensome audit exercise into a streamlined component of your software delivery pipeline.
You’ll also find practical insights on staffing your authorization effort, avoiding common pitfalls and estimating the level of effort required to achieve and maintain FedRAMP authorization.
Transform Your Approach to Federal Compliance
The white paper emphasizes that FedRAMP compliance isn’t just a one-time hurdle but an ongoing commitment that requires a strategic approach. By treating compliance as an integral part of your DevSecOps practice—with automation, policy-as-code and continuous monitoring—you can turn FedRAMP from a cost center into a competitive advantage.
Whether your organization is just beginning to explore FedRAMP or looking to optimize existing compliance processes, this guide provides the insights needed to build a sustainable approach that opens doors to federal business opportunities.
Download the White Paper Today
FedRAMP authorization is more than a compliance checkbox—it’s a strategic enabler for your federal market strategy. Our comprehensive guide gives you the knowledge and tools to navigate this complex process successfully.
📥 Download the white paper now and unlock your path to federal markets.
Learn how to navigate FedRAMP authorization while avoiding all of the most common pitfalls.
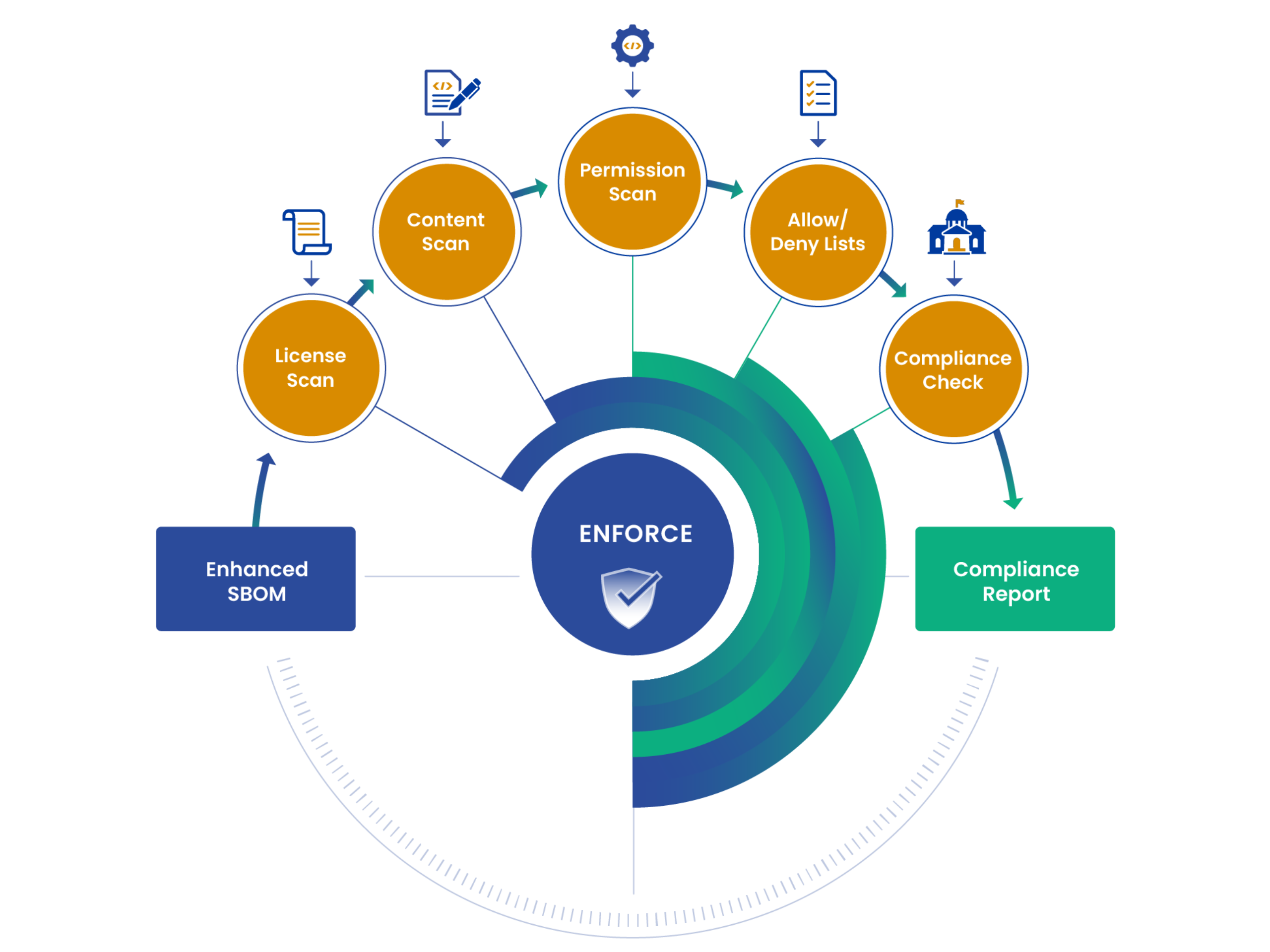
Security engineers at modern enterprises face an unprecedented challenge: managing software supply chain risk without impeding development velocity, all while threat actors exploit the rapidly expanding attack surface. With over 25,000 new vulnerabilities in 2023 alone and supply chain attacks surging 540% year-over-year from 2019 to 2022, the exploding adoption of open source software has created an untenable security environment. To overcome these challenges security teams are in need of tools to scale their impact and invert the they are a speed bump for high velocity software delivery.
If your DevSecOps pipeline utilizes the open source Harbor registry then we have the perfect answer to your needs. Integrating Anchore Enterprise—the SBOM-powered container vulnerability management platform—with Harbor offers the force-multiplier security teams need. This one-two combo delivers:
Proactive vulnerability management: Automatically scan container images before they reach production
Actionable security insights: Generate SBOMs, identify vulnerabilities and alert on actionable insights to streamline remediation efforts
Lightweight implementation: Native Harbor integration requiring minimal configuration while delivering maximum value
Improved cultural dynamics: Reduce security incident risk and, at the same time, burden on development teams while building cross-functional trust
This technical guide walks through the implementation steps for integrating Anchore Enterprise into Harbor, equipping security engineers with the knowledge to secure their software supply chain without sacrificing velocity.
Learn the essential container security best practices to reduce the risk of software supply chain attacks in this white paper.
Anchore Enterprise can integrate with Harbor in two different ways—each has pros and cons:
Pull Integration Model
In this model, Anchore uses registry credentials to pull and analyze images from Harbor:
Anchore accesses Harbor using standard Docker V2 registry integration
Images are analyzed directly within Anchore Enterprise
Results are available in Anchore’s interface and API
Ideal for organizations where direct access to Harbor is restricted but API access is permitted
Push Integration Model
In this model, Harbor uses its native scanner adapter feature to push images to Anchore for analysis:
Harbor initiates scans on-demand through its scanner adapter as images are added
Images are scanned within the Anchore deployment
Vulnerability scan results are stored in Anchore and sent to Harbor’s UI
Better for environments with direct access to Harbor that want immediate scans
Both methods provide strong security benefits but differ in workflow and where results are accessed.
Setting Up the Pull Integration
Let’s walk through how to configure Anchore Enterprise to pull and analyze images from your Harbor registry.
Prerequisites
Anchore Enterprise installed and running
Harbor registry deployed and accessible
Harbor user account with appropriate permissions
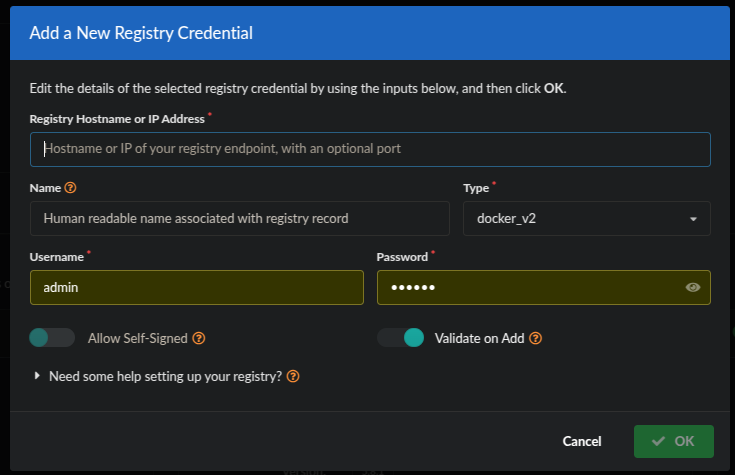
Step 1: Configure Registry Credentials in Anchore
In Anchore Enterprise, navigate to the “Registries” section
Select “Add Registry”
Fill in the following details:
Registry Hostname or IP Address: [your Harbor API URL or IP address, e.g., http://harbor.yourdomain.com]Name: [Human readable name]Type: docker_v2Username: [your Harbor username, e.g., admin]Password: [your Harbor password]
Configure any additional options like SSL validation if necessary
Test the connection
Save the configuration
Step 2: Analyze an Image from Harbor
Once the registry is configured, you can analyze images stored in Harbor:
Navigate to the “Images” section in Anchore Enterprise
Select “Add Image”
Choose your Harbor registry from the dropdown
Specify the repository and tag for the image you want to analyze
Click “Analyze”
Anchore will pull the image from Harbor, decompose it, generate an SBOM, and scan for vulnerabilities. This process typically takes a few minutes depending on image size.
Step 3: Review Analysis Results
After analysis completes:
View the vulnerability report in the Anchore UI
Check the generated SBOM for all dependencies
Review compliance status against configured policies
Export reports or take remediation actions as needed
Setting Up the Push Integration
Now let’s configure Harbor to push images to Anchore for scanning using the Harbor Scanner Adapter.
Review the results in your Harbor UI once scanning completes
Advanced Configuration Features
Now that you have the base configuration working for the Harbor Scanner Adapter, you are ready to consider some additional features to increase your security posture.
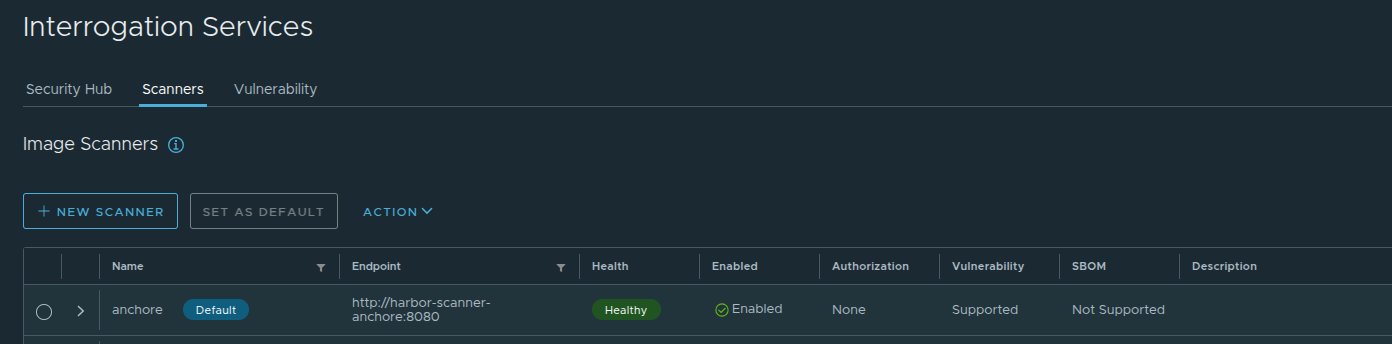
Scheduled Scanning
Beyond on-push scanning, you can configure scheduled scanning to catch newly discovered vulnerabilities in existing images:
In Harbor, navigate to “Administration” → “Interrogation Services” → “Vulnerability”
Set the scan schedule (hourly, daily, weekly, etc.)
Save the configuration
This ensures all images are regularly re-scanned as vulnerability databases are updated with newly discovered and documented vulnerabilities.
Security Policy Enforcement
To enforce security at the pipeline level:
In your Harbor project, navigate to “Configuration”
Enable “Prevent vulnerable images from running”
Select the vulnerability severity level threshold (Low, Medium, High, Critical)
Images with vulnerabilities above this threshold will be blocked from being pulled*
*Be careful with this setting for a production environment. If an image is flagged as having a vulnerability and your container orchestrator attempts to pull the image to auto-scale a service it may cause instability for users.
Proxy Image Cache
Harbor’s proxy cache capability provides an additional security layer:
Navigate to “Registries” in Harbor and select “New Endpoint”
Configure a proxy cache to a public registry like Docker Hub
All images pulled from Docker Hub will be cached locally and automatically scanned for vulnerabilities based on your project settings
Security Tips and Best Practices from the Anchore Team
Use Anchore Enterprise for highest fidelity vulnerability data
The Anchore Enterprise dashboard surfaces complete vulnerability details
Full vulnerability data can be configured with downstream integrations like Slack, Jira, ServiceNow, etc.
“Good data empowers good people to make good decisions.”
—Dan Perry, Principal Customer Success Engineer, Anchore
Configuration Best Practices
For optimal security posture:
Configure per Harbor project: Use different vulnerability scanning settings for different risk profiles
Mind your environment topology: Adjust network timeouts and SSL settings based on network topology; make sure Harbor and Anchore Enterprise deployments are able to communicate securely
Secure Access Controls
Adopt least privilege principle: Use different credentials per repository
Utilize API keys: For service accounts and integrations, use API keys rather than user credentials
Conclusion
Integrating Anchore Enterprise with Harbor registry creates a powerful security checkpoint in your DevSecOps pipeline. By implementing either the pull or push model based on your specific needs, you can automate vulnerability scanning, enforce security policies, and maintain compliance requirements.
This integration enables security teams to:
Detect vulnerabilities before images reach production
Generate and maintain accurate SBOMs
Enforce security policies through prevention controls
Maintain continuous security through scheduled scans
With these tools properly integrated, you can significantly reduce the risk of deploying vulnerable containers to production environments, helping to secure your software supply chain.
Save your developers time with Anchore Enterprise. Get instant access with a 15-day free trial.
The blog post is meant to remain “public” so that it will continue to show on the /blog feed. This will help discoverability for people browsing the blog and potentially help SEO. If it is clicked on it will automatically redirect to the pillar page.
Software Bill of Materials (SBOMs) are no longer optional—they’re mission-critical.
That’s why we’re excited to announce the release of our new white paper, “Unlock Enterprise Value with SBOMs: Use-Cases for the Entire Organization.” This comprehensive guide is designed for security and engineering leadership at both commercial enterprises and federal agencies, providing actionable insights into how SBOMs are transforming the way organizations manage software complexity, mitigate risk, and drive business outcomes.
From software supply chain security to DevOps acceleration and regulatory compliance, SBOMs have emerged as a cornerstone of modern software development. They do more than provide a simple inventory of application components; they enable rapid security incident response, automated compliance, reduced legal risk, and accelerated software delivery.
⏱️ Can’t wait till the end? 📥 Download the white paper now 👇👇👇
SBOMs are no longer just a checklist item—they’re a strategic asset. They provide an in-depth inventory of every component within your software ecosystem, complete with critical metadata about suppliers, licensing rights, and security postures. This newfound transparency is revolutionizing cross-functional operations across enterprises by:
Accelerating Incident Response: Quickly identify vulnerable components and neutralize threats before they escalate.
Enhancing Vulnerability Management: Prioritize remediation efforts based on risk, ensuring that developer resources are optimally deployed.
Reducing Legal Risk: Manage open source license obligations proactively, ensuring that every component meets your organization’s legal and security standards.
What’s Inside the White Paper?
Our white paper is organized by organizational function; each section highlighting the relevant SBOM use-cases. Here’s a glimpse of what you can expect:
Security: Rapidly identify and mitigate zero-day vulnerabilities, scale vulnerability management, and detect software drift to prevent breaches.
Engineering & DevOps: Eliminate wasted developer time with real-time feedback, automate dependency management, and accelerate software delivery.
Regulatory Compliance: Automate policy checks, streamline compliance audits, and meet requirements like FedRAMP and SSDF Attestation with ease.
Legal: Reduce legal exposure by automating open source license risk management.
Sales: Instill confidence in customers and accelerate sales cycles by proactively providing SBOMs to quickly build trust.
Also, you’ll find real-world case studies from organizations that have successfully implemented SBOMs to reduce risk, boost efficiency, and gain a competitive edge. Learn how companies like Google and Cisco are leveraging SBOMs to drive business outcomes.
Empower Your Enterprise with SBOM-Centric Strategies
The white paper underscores that SBOMs are not a one-trick pony. They are the cornerstone of modern software supply chain management, driving benefits across security, engineering, compliance, legal, and customer trust. Whether your organization is embarking on its SBOM journey or refining an established process, this guide will help you unlock cross-functional value and future-proof your technology operations.
Download the White Paper Today
SBOMs are more than just compliance checkboxes—they are a strategic enabler for your organization’s security, development, and business operations. Whether your enterprise is just beginning its SBOM journey or operating a mature SBOM initiative, this white paper will help you uncover new ways to maximize value.
Explore SBOM use-cases for almost any department of the enterprise and learn how to unlock enterprise value to make the most of your software supply chain.
SBOM (software bill of materials) generation is becoming increasingly important for software supply chain security and compliance. Several approaches exist for generating SBOMs for Python projects, each with its own strengths. In this post, we’ll explore two popular methods: using pipdeptree with cyclonedx-py and Syft. We’ll examine their differences and see why Syft is better for many use-cases.
Learn the 5 best practices for container security and how SBOMs play a pivotal role in securing your software supply chain.
Before diving into the tools, let’s understand why generating an SBOM for your Python packages is increasingly critical in modern software development. Security analysis is a primary driver—SBOMs provide a detailed inventory of your dependencies that security teams can use to identify vulnerabilities in your software supply chain and respond quickly to newly discovered threats. The cybersecurity compliance landscape is also evolving rapidly, with many organizations and regulations (e.g., EO 14028) now requiring SBOMs as part of software delivery to ensure transparency and traceability in an organization’s software supply chain.
From a maintenance perspective, understanding your complete dependency tree is essential for effective project management. SBOMs help development teams track dependencies, plan updates, and understand the potential impact of changes across their applications. They’re particularly valuable when dealing with complex Python applications that may have hundreds of transitive dependencies.
License compliance is another crucial aspect where SBOMs prove invaluable. By tracking software licenses across your entire dependency tree, you can ensure your project complies with various open source licenses and identify potential conflicts before they become legal issues. This is especially important in Python projects, where dependencies might introduce a mix of licenses that need careful consideration.
Generating a Python SBOM with pipdeptree and cyclonedx-py
The first approach we’ll look at combines two specialized Python tools: pipdeptree for dependency analysis and cyclonedx-py for SBOM generation. Here’s how to use them:
# Install the required tools$ pip install pipdeptree cyclonedx-bom# Generate requirements with dependencies$ pipdeptree --freeze > requirements.txt# Generate SBOM in CycloneDX format$ cyclonedx-py requirements requirements.txt > cyclonedx-sbom.json
This Python-specific approach leverages pipdeptree‘s deep understanding of Python package relationships. pipdeptree excels at:
Detecting circular dependencies
Identifying conflicting dependencies
Providing a clear, hierarchical view of package relationships
Generating a Python SBOM with Syft: A Universal SBOM Generator
Syft takes a different approach. As a universal SBOM generator, it can analyze Python packages and multiple software artifacts. Here’s how to use Syft with Python projects:
# Install Syft (varies by platform)# See: https://github.com/anchore/syft#installation$ curl -sSfL https://raw.githubusercontent.com/anchore/syft/main/install.sh | sh -s -- -b /usr/local/bin# Generate SBOM from requirements.txt$ syft requirements.txt -o cyclonedx-json# Or analyze an entire Python project$ syft path/to/project -o cyclonedx-json
Key Advantages of Syft
Syft’s flexibility in output formats sets it apart from other tools. In addition to the widely used CycloneDX format, it supports SPDX for standardized software definitions and offers its own native JSON format that includes additional metadata. This format flexibility allows teams to generate SBOMs that meet various compliance requirements and tooling needs without switching between multiple generators.
Syft truly shines in its comprehensive analysis capabilities. Rather than limiting itself to a single source of truth, Syft examines your entire Python environment, detecting packages from multiple sources, including requirements.txt files, setup.py configurations, and installed packages. It seamlessly handles virtual environments and can even identify system-level dependencies that might impact your application.
The depth of metadata Syft provides is particularly valuable for security and compliance teams. For each package, Syft captures not just basic version information but also precise package locations within your environment, file hashes for integrity verification, detailed license information, and Common Platform Enumeration (CPE) identifiers. This rich metadata enables more thorough security analysis and helps teams maintain compliance with security policies.
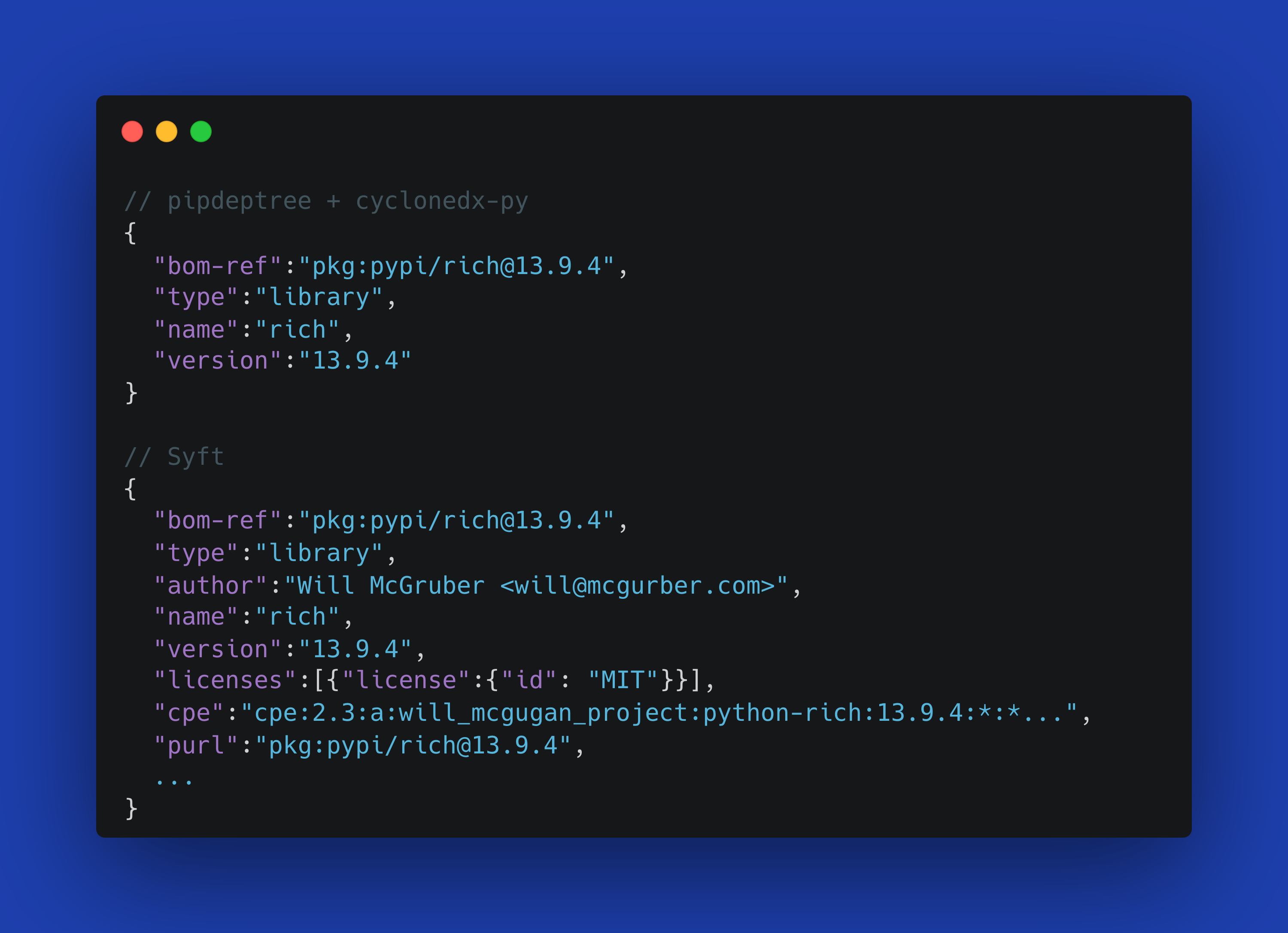
Comparing the Outputs
We see significant differences in detail and scope when examining the outputs from both approaches. The pipdeptree with cyclonedx-py combination produces a focused output that concentrates specifically on Python package relationships. This approach yields a simpler, more streamlined SBOM that’s easy to read but contains limited metadata about each package.
Syft, on the other hand, generates a more comprehensive output that includes extensive metadata for each package. Its SBOM provides rich details about package origins, includes comprehensive CPE identification for better vulnerability matching, and offers built-in license detection. Syft also tracks the specific locations of files within your project and includes additional properties that can be valuable for security analysis and compliance tracking.
Here’s a snippet comparing the metadata for the rich package in both outputs:
While both approaches are valid, Syft offers several compelling advantages. As a universal tool that works across multiple software ecosystems, Syft eliminates the need to maintain different tools for different parts of your software stack.
Its rich metadata gives you deeper insights into your dependencies, including detailed license information and precise package locations. Syft’s support for multiple output formats, including CycloneDX, SPDX, and its native format, ensures compatibility with your existing toolchain and compliance requirements.
The project’s active development means you benefit from regular updates and security fixes, keeping pace with the evolving software supply chain security landscape. Finally, Syft’s robust CLI and API options make integrating into your existing automation pipelines and CI/CD workflows easy.
How to Generate a Python SBOM with Syft
Ready to generate SBOMs for your Python projects? Here’s how to get started with Syft:
While pipdeptree combined with cyclonedx-py provides a solid Python-specific solution, Syft offers a more comprehensive and versatile approach to SBOM generation. Its ability to handle multiple ecosystems, provide rich metadata, and support various output formats makes it an excellent choice for modern software supply chain security needs.
Whether starting with SBOMs or looking to improve your existing process, Syft provides a robust, future-proof solution that grows with your needs. Try it and see how it can enhance your software supply chain security today.
Learn about the role that SBOMs for the security of your organization in this white paper.
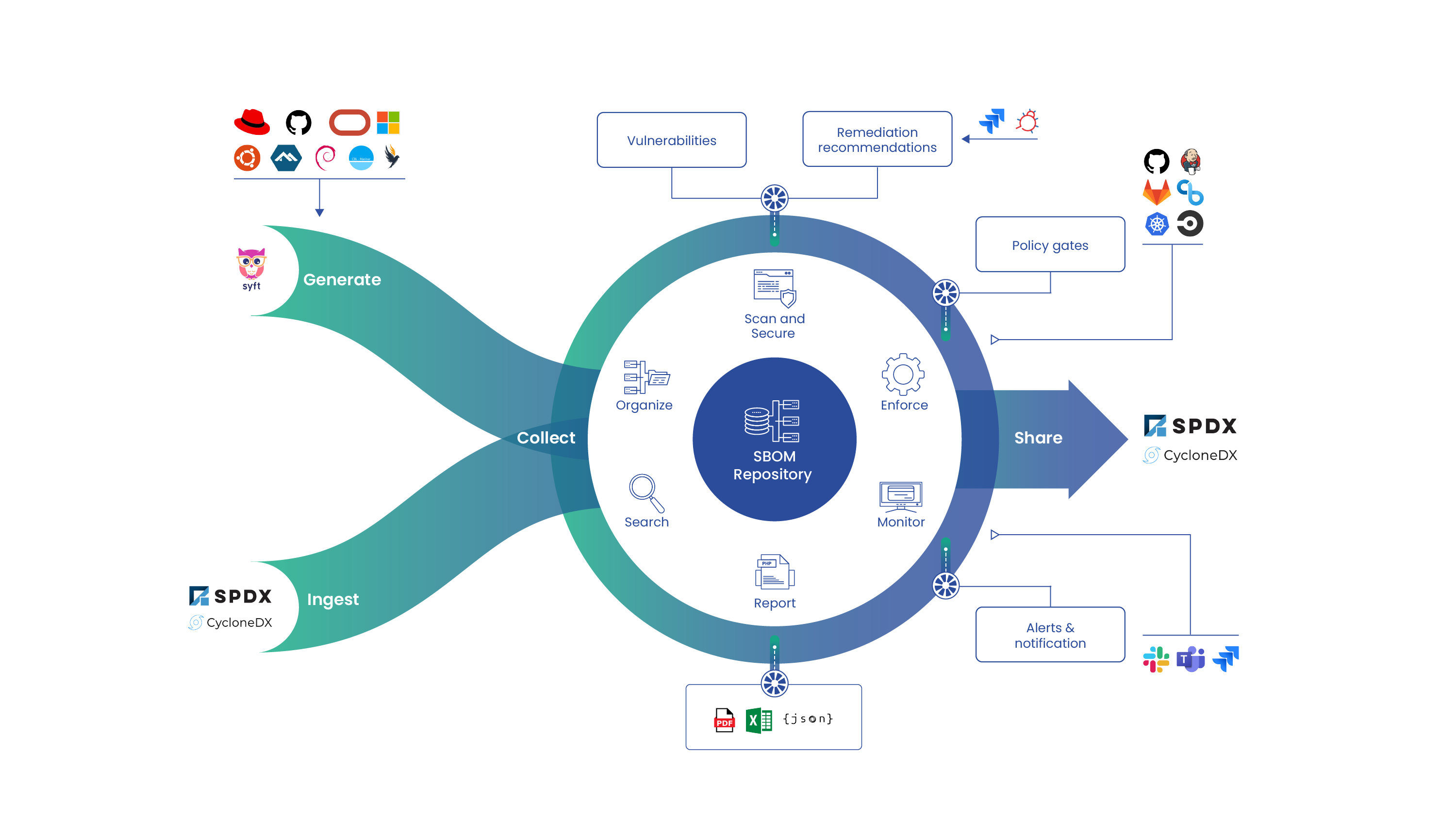
As software supply chain security becomes a top priority, organizations are turning to Software Bill of Materials (SBOM) generation and analysis to gain visibility into the composition of their software and supply chain dependencies in order to reduce risk. However, integrating SBOM analysis tools into existing workflows can be complex, requiring extensive configuration and technical expertise. Anchore Enterprise, a leading SBOM management and container security platform, simplifies this process with seamless integration capabilities that cater to modern DevSecOps pipelines.
This article explores how Anchore makes SBOM analysis effortless by offering automation, compatibility with industry standards, and integration with popular CI/CD tools.
Learn about the role that SBOMs for the security of your organization in this white paper.
SBOMs play a crucial role in software security, compliance, and vulnerability management. However, organizations often face challenges when adopting SBOM analysis tools:
Complex Tooling: Many SBOM solutions require significant setup and customization.
Scalability Issues: Enterprises managing thousands of dependencies need scalable and automated solutions.
Compatibility Concerns: Ensuring SBOM analysis tools work seamlessly across different DevOps environments can be difficult.
Anchore addresses these challenges by providing a sleek approach to SBOM analysis with easy-to-use integrations.
How Anchore Simplifies SBOM Analysis Integration
1. Automated SBOM Generation and Analysis
Anchore automates SBOM generation from various sources, including container images, software packages, and application dependencies. This eliminates the need for manual intervention, ensuring continuous security and compliance monitoring.
Automatically scans and analyzes SBOMs for vulnerabilities, licensing issues, and security and compliance policy violations.
Provides real-time insights to security teams.
2. Seamless CI/CD Integration
DevSecOps teams require tools that integrate effortlessly into their existing workflows. Anchore achieves this by offering:
Popular CI/CD platform plugins: Jenkins, GitHub Actions, GitLab CI/CD, Azure DevOps and more.
API-driven architecture: Embed SBOM generation and analysis in any DevOps pipeline.
Policy-as-code support: Enforce security and compliance policies within CI/CD workflows.
AnchoreCTL: A command-line (CLI) tool for developers to generate and analyze SBOMs locally before pushing to production.
3. Cloud Native and On-Premises Deployment
Organizations have diverse infrastructure requirements, and Anchore provides flexibility through:
Cloud native support: Works seamlessly with Kubernetes, OpenShift, AWS, and GCP.
On-premises deployment: For organizations requiring strict control over data security.
Hybrid model: Allows businesses to use cloud-based Anchore Enterprise while maintaining on-premises security scanning.
Bonus: Anchore also offers an air-gapped deployment option for organizations working with customers that provide critical national infrastructure like energy, financial services or defense.
A major challenge in SBOM adoption is developer resistance due to complexity. Anchore makes security analysis developer-friendly by:
Providing CLI and API tools for easy interaction.
Delivering clear, actionable vulnerability reports instead of overwhelming developers with false positives.
Integrating directly with development environments, such as VS Code and JetBrains IDEs.
Providing an industry standard 24/7 customer support through Anchore’s customer success team.
Conclusion
Anchore has positioned itself as a leader in SBOM analysis by making integration effortless, automating security checks, and supporting industry standards. Whether an organization is adopting SBOMs for the first time or looking to enhance its software supply chain security, Anchore provides a scalable and developer-friendly solution.
By integrating automated SBOM generation, CI/CD compatibility, cloud native deployment, and compliance management, Anchore enables businesses (no matter the size) and government institutions to adopt SBOM analysis without disrupting their workflows. As software security becomes increasingly critical, tools like Anchore will play a pivotal role in ensuring a secure and transparent software supply chain.For organizations seeking a simple to deploy SBOM analysis solution, Anchore Enterprise is here to deliver results to your organization. Request a demo with our team today!
Learn the 5 best practices for container security and how SBOMs play a pivotal role in securing your software supply chain.
We’re excited to announce Syft v1.20.0! If you’re new to the community, Syft is Anchore’s open source software composition analysis (SCA) and SBOM generation tool that provides foundational support for software supply chain security for modern DevSecOps workflows.
The latest version is packed with performance improvements, enhanced SBOM accuracy, and several community-driven features that make software composition scanning more comprehensive and efficient than ever.
Scanning projects with numerous DLLs was reported to take peculiarly long when running on Windows, sometimes up to 50 minutes. A sharp-eyed community member (@rogueai) discovered that certificate validation was being performed unnecessarily during DLL scanning. A fix was merged into this release and those lengthy scans have been dramatically reduced from to just a few minutes—a massive performance improvement for Windows users!
Bitnami Embedded SBOM Support: Maximum Accuracy
Container images from Bitnami include valuable embedded SBOMs located at /opt/bitnami/. These SBOMs, packaged by the image creators themselves, represent the most authoritative source for package metadata. Thanks to community member @juan131 and maintainer @willmurphyscode, Syft now includes a dedicated cataloger for these embedded SBOMs.
This feature wasn’t simple to implement. It required careful handling of package relationships and sophisticated deduplication logic to merge authoritative vendor data with Syft’s existing scanning capabilities. The result? Scanning Bitnami images gives you the most accurate SBOM possible, combining authoritative vendor data with Syft’s comprehensive analysis.
Smarter License Detection
Handling licenses for non-open source projects can be a bit tricky. We discovered that when license files can’t be matched to a valid SPDX expression, they sometimes get erroneously marked as “unlicensed”—even when valid license text is present. For example, our dpkg cataloger occasionally encountered a license like:
NVIDIA Software License Agreement and CUDA Supplement to Software License Agreement
And categorized the package as unlicensed. Ideally, the cataloger would capture this non-standards compliant license whether the maintainer follows SDPX or not.
Community member @HeyeOpenSource and maintainer @spiffcs tackled this challenge with an elegant solution: a new configuration option that preserves the original license text when SPDX matching fails. While disabled by default for compatibility, you can enable this feature with license.include-unknown-license-content: true in your configuration. This ensures you never lose essential license information, even for non-standard licenses.
Go 1.24: Better Performance and Versioning
The upgrade to Go 1.24 brings two significant improvements:
Faster Scanning: Thanks to Go 1.24’s optimized map implementations, discussed in this Bytesize Go post—and other performance improvements—we’re seeing scan times reduced by as much as 20% in our testing.
Enhanced Version Detection: Go 1.24’s new version embedding means Syft can now accurately report its version and will increasingly provide more accurate version information for Go applications it scans:
syft: go1.24.0
$ go version -m ./syft
path github.com/anchore/syft/cmd/syft
mod github.com/anchore/syft v1.20.0
This also means that as more applications are built with Go 1.24—the versions reported by Syft will become increasingly accurate over time. Everyone’s a winner!
Join the Conversation
We’re proud of these enhancements and grateful to the community for their contributions. If you’re interested in contributing or have ideas for future improvements, head to our GitHub repo and join the conversation. Your feedback and pull requests help shape the future of Syft and our other projects. Happy scanning!
Stay updated on future community spotlights and events by subscribing to our community newsletter.
Learn how MegaLinter leverages Syft and Grype to generate SBOMs and create vulnerability reports
Syft is an open source CLI tool and Go library that generates a Software Bill of Materials (SBOM) from source code, container images and packaged binaries. It is a foundational building block for various use-cases: from vulnerability scanning with tools like Grype, to OSS license compliance with tools like Grant. SBOMs track software components—and their associated supplier, security, licensing, compliance, etc. metadata—through the software development lifecycle.
At a high level, Syft takes the following approach to generating an SBOM:
Determine the type of input source (container image, directory, archive, etc.)
Orchestrate a pluggable set of catalogers to scan the source or artifact
Each package cataloger looks for package types it knows about (RPMs, Debian packages, NPM modules, Python packages, etc.)
In addition, the file catalogers gather other metadata and generate file hashes
Aggregate all discovered components into an SBOM document
Output the SBOM in the desired format (Syft, SPDX, CycloneDX, etc.)
Let’s dive into each of these steps in more detail.
Learn the 5 best practices for container security and how SBOMs play a pivotal role in securing your software supply chain.
Container images (both from registries and local Docker/Podman engines)
Local filesystems and directories
Archives (TAR, ZIP, etc.)
Single files
This flexibility is important as SBOMs are used in a variety of environments, from a developer’s workstation to a CI/CD pipeline.
When you run Syft, it first tries to autodetect the source type from the provided input. For example:
# Scan a container image syft ubuntu:latest# Scan a local filesystemsyft ./my-app/
Pluggable Package Catalogers
The heart of Syft is its decoupled architecture for software composition analysis (SCA). Rather than one monolithic scanner, Syft delegates scanning to a collection of catalogers, each focused on a specific software ecosystem.
Some key catalogers include:
apk-db-cataloger for Alpine packages
dpkg-db-cataloger for Debian packages
rpm-db-cataloger for RPM packages (sourced from various databases)
python-package-cataloger for Python packages
java-archive-cataloger for Java archives (JAR, WAR, EAR)
npm-package-cataloger for Node/NPM packages
Syft automatically selects which catalogers to run based on the source type. For a container image, it will run catalogers for the package types installed in containers (RPM, Debian, APK, NPM, etc). For a filesystem, Syft runs a different set of catalogers looking for installed software that is more typical for filesystems and source code.
This pluggable architecture gives Syft broad coverage while keeping the core streamlined. Each cataloger can focus on accurately detecting its specific package type.
If we look at a snippet of the trace output from scanning an Ubuntu image, we can see some catalogers in action:
Here, the dpkg-db-cataloger found 91 Debian packages, while the rpm-db-cataloger and npm-package-cataloger didn’t find any packages of their types—which makes sense for an Ubuntu image.
Aggregating and Outputting Results
Once all catalogers have finished, Syft aggregates the results into a single SBOM document. This normalized representation abstracts away the implementation details of the different package types.
Source information (repository, download URL, etc.)
File digests and metadata
It also contains essential metadata, including a copy of the configuration used when generating the SBOM (for reproducibility). The SBOM will contain detailed information about package evidence, which packages were parsed from (within package.Metadata).
Finally, Syft serializes this document into one or more output formats. Supported formats include:
Syft’s native JSON format
SPDX’s tag-value and JSON
CycloneDX’s JSON and XML
Having multiple formats allows integrating Syft into a variety of toolchains and passing data between systems that expect certain standards.
Revisiting the earlier Ubuntu example, we can see a snippet of the final output:
NAME VERSION TYPEapt 2.7.14build2 debbase-files 13ubuntu10.1 debbash 5.2.21-2ubuntu4 deb
Container Image Parsing with Stereoscope
To generate high-quality SBOMs from container images, Syft leverages a stereoscope library for parsing container image formats.
Stereoscope does the heavy lifting of unpacking an image into its constituent layers, understanding the image metadata, and providing a unified filesystem view for Syft to scan.
This encapsulation is quite powerful, as it abstracts the details of different container image specs (Docker, OCI, etc.), allowing Syft to focus on SBOM generation while still supporting a wide range of images.
Cataloging Challenges and Future Work
While Syft can generate quality SBOMs for many source types, there are still challenges and room for improvement.
One challenge is supporting the vast variety of package types and versioning schemes. Each ecosystem has its own conventions, making it challenging to extract metadata consistently. Syft has added support for more ecosystems and evolved its catalogers to handle edge-cases to provide support for an expanding array of software tooling.
Another challenge is dynamically generated packages, like those created at runtime or built from source. Capturing these requires more sophisticated analysis that Syft does not yet do. To illustrate, let’s look at two common cases:
Runtime Generated Packages
Imagine a Python application that uses a web framework like Flask or Django. These frameworks allow defining routes and views dynamically at runtime based on configuration or plugin systems.
For example, an application might scan a /plugins directory on startup, importing any Python modules found and registering their routes and models with the framework. These plugins could pull in their own dependencies dynamically using importlib.
From Syft’s perspective, none of this dynamic plugin and dependency discovery happens until the application actually runs. The Python files Syft scans statically won’t reveal those runtime behaviors.
Furthermore, plugins could be loaded from external sources not even present in the codebase Syft analyzes. They might be fetched over HTTP from a plugin registry as the application starts.
To truly capture the full set of packages in use, Syft would need to do complex static analysis to trace these dynamic flows, or instrument the running application to capture what it actually loads. Both are much harder than scanning static files.
Source Built Packages
Another typical case is building packages from source rather than installing them from a registry like PyPI or RubyGems.
Consider a C++ application that bundles several libraries in a /3rdparty directory and builds them from source as part of its build process.
When Syft scans the source code directory or docker image, it won’t find any already built C++ libraries to detect as packages. All it will see are raw source files, which are much harder to map to packages and versions.
One approach is to infer packages from standard build tool configuration files, like CMakeLists.txt or Makefile. However, resolving the declared dependencies to determine the full package versions requires either running the build or profoundly understanding the specific semantics of each build tool. Both are fragile compared to scanning already built artifacts.
Some Language Ecosystems are Harder Than Others
It’s worth noting that dynamism and source builds are more or less prevalent in different language ecosystems.
Interpreted languages like Python, Ruby, and JavaScript tend to have more runtime dynamism in their package loading compared to compiled languages like Java or Go. That said, even compiled languages have ways of loading code dynamically, it just tends to be less common.
Likewise, some ecosystems emphasize always building from source, while others have a strong culture of using pre-built packages from central registries.
These differences mean the level of difficulty for Syft in generating a complete SBOM varies across ecosystems. Some will be more amenable to static analysis than others out of the box.
What Could Help?
To be clear, Syft has already done impressive work in generating quality SBOMs across many ecosystems despite these challenges. But to reach the next level of coverage, some additional analysis techniques could help:
Static analysis to trace dynamic code flows and infer possible loaded packages (with soundness tradeoffs to consider)
Dynamic instrumentation/tracing of applications to capture actual package loads (sampling and performance overhead to consider)
Standardized metadata formats for build systems to declare dependencies (adoption curve and migration path to consider)
Heuristic mapping of source files to known packages (ambiguity and false positives to consider)
None are silver bullets, but they illustrate the approaches that could help push SBOM coverage further in complex cases.
Ultimately, there will likely always be a gap between what static tools like Syft can discover versus the actual dynamic reality of applications. But that doesn’t mean we shouldn’t keep pushing the boundary! Even incremental improvements in these areas help make the software ecosystem more transparent and secure.
Syft also has room to grow in terms of programming language support. While it covers major ecosystems like Java and Python well, more work is needed to cover languages like Go, Rust, and Swift completely.
As the SBOM landscape evolves, Syft will continue to adapt to handle more package types, sources, and formats. Its extensible architecture is designed to make this growth possible.
Get Involved
Syft is fully open source and welcomes community contributions. If you’re interested in adding support for a new ecosystem, fixing bugs, or improving SBOM generation, the repo is the place to get started.
There are issues labeled “Good First Issue” for those new to the codebase. For more experienced developers, the code is structured to make adding new catalogers reasonably straightforward.
No matter your experience level, there are ways to get involved and help push the state of the art in SBOM generation. We hope you’ll join us!
Learn about the role that SBOMs for the security of your organization in this white paper.
Today, we’re excited to announce the launch of “Software Bill of Materials 101: A Guide for Developers, Security Engineers, and the DevSecOps Community”. This eBook is free and open source resource that provides a comprehensive introduction to all things SBOMs.
Why We Created This Guide
While SBOMs have become increasingly critical for software supply chain security, many developers and security professionals still struggle to understand and implement them effectively. We created this guide to help bridge that knowledge gap, drawing on our experience building popular SBOM tools like Syft.
What’s Inside
The ebook covers essential SBOM topics, including:
Practical guidance for integrating SBOMs into DevSecOps pipelines
We’ve structured the content to be accessible to newcomers while providing enough depth for experienced practitioners looking to expand their knowledge.
Community-Driven Development
This guide is published under an open source license and hosted on GitHub at https://github.com/anchore/sbom-ebook. The collective wisdom of the DevSecOps community will strengthen this resource over time. We welcome contributions whether fixes, new content, or translations.
Getting Started
You can read the guide online, download PDF/ePub versions, or clone the repository to build it locally. The source is in Markdown format, making it easy to contribute improvements.
The software supply chain security challenges we face require community collaboration. We hope this guide advances our collective understanding of SBOMs and their role in securing the software ecosystem.
Learn about the role that SBOMs play for the security of your organization in this white paper.
The blog post is meant to remain “public” so that it will continue to show on the /blog feed. This will help discoverability for people browsing the blog and potentially help SEO. If it is clicked on it will automatically redirect to the pillar page.
To close out 2024, we’re going to count down the top 10 hottest hits from the Anchore blog in 2024! The Anchore content team continued our tradition of delivering expert guidance, practical insights, and forward-looking strategies on DevSecOps, cybersecurity compliance, and software supply chain management.
This top ten list spotlights our most impactful blog posts from the year, each tackling a different angle of modern software development and security. Hot topics this year include:
All things SBOM (software bill of materials)
DevSecOps compliance for the Department of Defense (DoD)
Regulatory compliance for federal government vendors (e.g., FedRAMP & SSDF Attestation)
Vulnerability scanning and management—a perennial favorite!
Our selection runs the gamut of knowledge needed to help your team stay ahead of the compliance curve, boost DevSecOps efficiency, and fully embrace SBOMs. So, grab your popcorn and settle in—it’s time to count down the blog posts that made the biggest splash this year!
The Top Ten List
10 | A Guide to Air Gapping
Kicking us off at number 10 is a blog that’s all about staying off the grid—literally. Ever wonder what it really means to keep your network totally offline?
A Guide to Air Gapping: Balancing Security and Efficiency in Classified Environments breaks down the concept of “air gapping”—literally disconnecting a computer from the internet by leaving a “gap of air” between your computer and an ethernet cable. It is generally considered a security practice to protect classified, military-grade data or similar.
Our blog covers the perks, like knocking out a huge range of cyber threats, and the downsides, like having to manually update and transfer data. It also details how Anchore EnforceFederal Edition can slip right into these ultra-secure setups, blending top-notch protection with the convenience of automated, cloud-native software checks.
9 | SBOMs + Vulnerability Management == Open Source Security++
Coming in at number nine on our countdown is a blog that breaks down two of our favorite topics; SBOMs and vulnerability scanners—And how using SBOMs as your foundation for vulnerability management can level up your open source security game.
speeding up the DevSecOps process so you don’t feel the drag of legacy security tools.
By switching to this modern, SBOM-driven approach, you’ll see benefits like faster fixes, smoother compliance checks, and fewer late-stage security surprises—just ask companies like NVIDIA, Infoblox, DreamFactory and ModuleQ, who’ve saved tons of time and hassle by adopting these practices.
8 | Improving Syft’s Binary Detection
Landing at number eight, we’ve got a blog post that’s basically a backstage pass to Syft’s binary detection magic. Improving Syft’s Binary Detection goes deep on how Syft—Anchore’s open source SBOM generation tool—uncovers out the details of executable files and how you can lend a hand in making it even better.
We walk you through the process of adding new binary detection rules, from finding the right binaries and testing them out, to fine-tuning the patterns that match their version strings.
The end goal? Helping all open source contributors quickly get started making their first pull request and broadening support for new ecosystems. A thriving, community-driven approach to better securing the global open source ecosystem.
7 | A Guide to FedRAMP in 2024: FAQs & Key Takeaways
Sliding in at lucky number seven, we’ve got the ultimate cheat sheet for FedRAMP in 2024 (and 2025😉)! Ever wonder how Uncle Sam greenlights those fancy cloud services? A Guide to FedRAMP in 2024: FAQs & Key Takeaways spills the beans on all the FedRAMP basics you’ve been struggling to find—fast answers without all the fluff.
It covers what FedRAMP is, how it works, who needs it, and why it matters; detailing the key players and how it connects with other federal security standards like FISMA. The idea is to help you quickly get a handle on why cloud service providers often need FedRAMP certification, what benefits it offers, and what’s involved in earning that gold star of trust from federal agencies. By the end, you’ll know exactly where to start and what to expect if you’re eyeing a spot in the federal cloud marketplace.
By using SBOMs, Grant can quickly show you which licenses are in play—and whether any have changed from something friendly to something more restrictive. With handy list and check commands, Grant makes it easier to spot and manage license risk, ensuring you keep shipping software without getting hit with last-minute legal surprises.
5 | An Overview of SSDF Attestation: Compliance Need-to-Knows
Landing at number five on tonight’s compliance countdown is a big wake-up call for all you software suppliers eyeing Uncle Sam’s checkbook: the SSDF Attestation Form. That’s right—starting now, if you wanna do business with the feds, you gotta show off those DevSecOps chops, no exceptions! In Using the Common Form for SSDF Attestation: What Software Producers Need to Know we break down the new Secure Software Development Attestation Form—released in March 2024—that’s got everyone talking in the federal software space.
In short, if you’re a software vendor wanting to sell to the US government, you now have to “show your work” when it comes to secure software development. The form builds on the SSDF framework, turning it from a nice-to-have into a must-do. It covers which software is included, the timelines you need to know, and what happens if you don’t shape up.
There are real financial risks if you can’t meet the deadlines or if you fudge the details (hello, criminal penalties!). With this new rule, it’s time to get serious about locking down your dev practices or risk losing out on government contracts.
4 | Prep your Containers for STIG
At number four, we’re diving headfirst into the STIG compliance world—the DoD’s ultimate ‘tough crowd’ when it comes to security! If you’re feeling stressed about locking down those container environments—we’ve got you covered. 4 Ways to Prepare your Containers for the STIG Process is all about tackling the often complicated STIG process for containers in DoD projects.
You’ll learn how to level up your team by cross-training cybersecurity pros in container basics and introducing your devs and architects to STIG fundamentals. It also suggests going straight to the official DISA source for current STIG info, making the STIG Viewer a must-have tool on everyone’s workstation, and looking into automation to speed up compliance checks.
Bottom line: stay informed, build internal expertise, and lean on the right tools to keep the STIG process from slowing you down.
3 | Syft Graduates to v1.0!
Give it up for number three on our countdown—Syft’s big graduation announcement! In Syft Reaches v1.0! Syft celebrates hitting the big 1.0 milestone!
Syft is Anchore’s OSS tool for generating SBOMs, helping you figure out exactly what’s inside your software, from container images to source code. Over the years, it’s grown to support over 40 package types, outputting SBOMs in various formats like SPDX and CycloneDX. With v1.0, Syft’s CLI and API are now stable, so you can rely on it for consistent results and long-term compatibility.
But don’t worry—development doesn’t stop here. The team plans to keep adding support for more ecosystems and formats, and they invite the community to join in, share ideas, and contribute to the future of Syft.
2 | RAISE 2.0 Overview: RMF and ATO for the US Navy
Next up at number two is the lowdown on RAISE 2.0—your backstage pass to lightning-fast software approvals with the US Navy! In RMF and ATO with RAISE 2.0 — Navy’s DevSecOps solution for Rapid Delivery we break down what RAISE 2.0 means for teams working with the Department of the Navy’s containerized software. The key takeaway? By using an approved DevSecOps platform—known as an RPOC—you can skip getting separate ATOs for every new app.
The guidelines encourage a “shift left” approach, focusing on early and continuous security checks throughout development. Tools like Anchore EnforceFederal Edition can help automate the required security gates, vulnerability scans, and policy checks, making it easier to keep everything compliant.
In short, RAISE 2.0 is all about streamlining security, speeding up approvals, and helping you deliver secure code faster.
1 | Introduction to the DoD Software Factory
Taking our top spot at number one, we’ve got the DoD software factory—the true VIP of the DevSecOps world! We’re talking about a full-blown, high-security software pipeline that cranks out code for the defense sector faster than a fighter jet screaming across the sky. In Introduction to the DoD Software Factory we break down what a DoD software factory really is—think of it as a template to build a DoD-approved DevSecOps pipeline.
The blog post details how concepts like shifting security left, using microservices, and leveraging automation all come together to meet the DoD’s sky-high security standards. Whether you choose an existing DoD software factory (like Platform One) or build your own, the goal is to streamline development without sacrificing security.
Tools like Anchore EnforceFederal Edition can help with everything from SBOM generation to continuous vulnerability scanning, so you can meet compliance requirements and keep your mission-critical apps protected at every stage.
Wrap-Up
That wraps up the top ten Anchore blog posts of 2024! We covered it all: next-level software supply chain best practices, military-grade compliance tactics, and all the open-source goodies that keep your DevSecOps pipeline firing on all cylinders.
The common thread throughout them all is the recognition that security and speed can work hand-in-hand. With SBOM-driven approaches, modern vulnerability management, and automated compliance checks, organizations can achieve the rapid, secure, and compliant software delivery required in the DevSecOps era. We hope these posts will serve as a guide and inspiration as you continue to refine your DevSecOps practice, embrace new technologies, and steer your organization toward a more secure and efficient future.
If you enjoyed our greatest hits album of 2024 but need more immediacy in your life, follow along in 2025 by subscribing to the Anchore Newsletter or following Anchore on your favorite social platform:
ModuleQ, an AI-driven enterprise knowledge platform, knows only too well the stakes for a company providing software solutions in the highly regulated financial services sector. In this world where data breaches are cause for termination of a vendor relationship and evolving cyberthreats loom large, proactive vulnerability management is not just a best practice—it’s a necessity.
ModuleQ required a vulnerability management platform that could automatically identify and remediate vulnerabilities, maintain airtight security, and meet stringent compliance requirements—all without slowing down their development velocity.
Learn the essential container security best practices to reduce the risk of software supply chain attacks in this white paper.
The Challenge: Scaling Security in a High-Stakes Environment
ModuleQ found itself drowning in a flood of newly released vulnerabilities—over 25,000 in 2023 alone. Operating in a heavily regulated industry meant any oversight could have severe repercussions. High-profile incidents like the Log4j exploit underscored the importance of supply chain security, yet the manual, resource-intensive nature of ModuleQ’s vulnerability management process made it hard to keep pace.
The mandate that no critical vulnerabilities reached production was a particularly high bar to meet with the existing manual review process. Each time engineers stepped away from their coding environment to check a separate security dashboard, they lost context, productivity, and confidence. The fear of accidentally letting something slip through the cracks was ever present.
The Solution: Anchore Secure for Automated, Integrated Vulnerability Management
ModuleQ chose Anchore Secure to simplify, automate, and fully integrate vulnerability management into their existing DevSecOps workflows. Instead of relying on manual security reviews, Anchore Secure injected security measures seamlessly into ModuleQ’s Azure DevOps pipelines, .NET, and C# environment. Every software build—staged nightly through a multi-step pipeline—was automatically scanned for vulnerabilities. Any critical issues triggered immediate notifications and halted promotions to production, ensuring that potential risks were addressed before they could ever reach customers.
Equally important, Anchore’s platform was built to operate in on-prem or air-gapped environments. This guaranteed that ModuleQ’s clients could maintain the highest security standards without the need for external connectivity. For an organization whose customers demand this level of diligence, Anchore’s design provided peace of mind and strengthened client relationships.
80% Reduction in Vulnerability Management Time: Automated scanning, triage, and reporting freed the team from manual checks, letting them focus on building new features rather than chasing down low-priority issues.
50% Less Time on Security Tasks During Deployments: Proactive detection of high-severity vulnerabilities streamlined deployment workflows, enabling ModuleQ to deliver software faster—without compromising security.
Unwavering Confidence in Compliance: With every new release automatically vetted for critical vulnerabilities, ModuleQ’s customers in the financial sector gained renewed trust. Anchore’s support for fully on-prem deployments allowed ModuleQ to meet stringent security demands consistently.
Looking Ahead
In an era defined by unrelenting cybersecurity threats, ModuleQ proved that speed and security need not be at odds. Anchore Secure provided a turnkey solution that integrated seamlessly into their workflow, saving time, strengthening compliance, and maintaining the agility to adapt to future challenges. By adopting an automated security backbone, ModuleQ has positioned itself as a trusted and reliable partner in the financial services landscape.
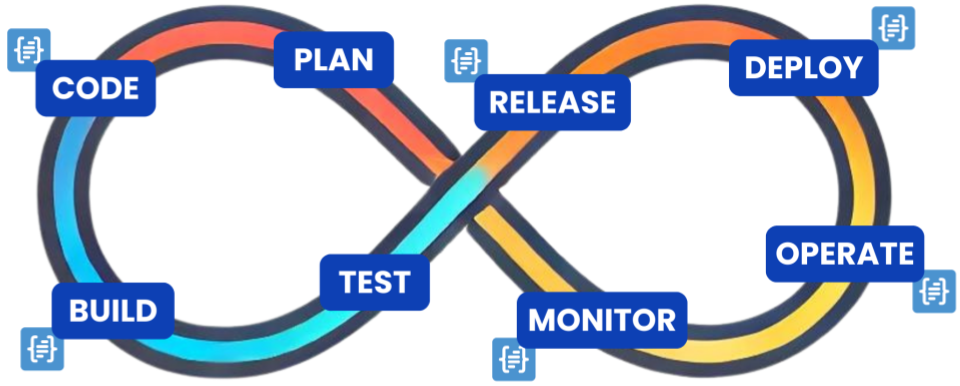
Welcome back to the second installment of our two-part series on “The Evolution of SBOMs in the DevSecOps Lifecycle”. In our first post, we explored how Software Bills of Materials (SBOMs) evolve over the first 4 stages of the DevSecOps pipeline—Plan, Source, Build & Test—and how each type of SBOM serves different purposes. Some of those use-cases include: shift left vulnerability detection, regulatory compliance automation, OSS license risk management and incident root cause analysis.
In this part, we’ll continue our exploration with the final 4 stages of the DevSecOps lifecycle, examining:
Analyzed SBOMs at the Release (Registry) stage
Deployed SBOMs during the Deployment phase
Runtime SBOMs in Production (Operate & Monitor stages)
As applications migrate down the pipeline, design decisions made at the beginning begin to ossify becoming more difficult to change; this influences the challenges that are experienced and the role that SBOMs play in overcoming these novel problems. Some of the new challenges that come up include: pipeline leaks, vulnerabilities in third-party packages, and runtime injection. All of which introduce significant risk. Understanding how SBOMs evolve across these stages helps organizations mitigate these risks effectively.
Whether you’re aiming to enhance your security posture, streamline compliance reporting, or improve incident response times, this comprehensive guide will equip you with the knowledge to leverage SBOMs effectively from Release to Production. Additionally, we’ll offer pro tips to help you maximize the benefits of SBOMs in your DevSecOps practices.
So, let’s continue our journey through the DevSecOps pipeline and discover how SBOMs can transform the latter stages of your software development lifecycle.
Learn the 5 best practices for container security and how SBOMs play a pivotal role in securing your software supply chain.
After development is completed and the new release of the software is declared a “golden” image the build system will push the release artifact to a registry for storage until it is deployed. At this stage, an SBOM that is generated based on these container images, binaries, etc. is named an “Analyzed SBOM”by CISA. The name is a little confusing since all SBOMs should be analyzed regardless of the stage they are generated. A more appropriate name might be a Release SBOM but we’ll stick with CISA’s name for now.
At first glance, it would seem that Analyzed SBOMs and the final Build SBOMs should be identical since it is the same software but that doesn’t hold up in practice. DevSecOps pipelines aren’t hermetically sealed systems, they can be “leaky”. You might be surprised what finds its way into this storage repository and eventually gets deployed bypassing your carefully constructed build and test setup.
On top of that, the registry holds more than just first-party applications that are built in-house. It also stores 3rd-party container images like operating systems and any other self-contained applications used by the organization.
The additional metadata that is collected for an Analyzed SBOM includes:
Release images that bypass the happy path build and test pipeline
3rd-party container images, binaries and applications
Pros and Cons
Pros:
Comprehensive Artifact Inventory: A more holistic view of all software—both 1st- and 3rd-party—that is utilized in production.
Enhanced Security and Compliance Posture: Catches vulnerabilities and non-compliant images for all software that will be deployed to production. This reduces the risk of security incidents and compliance violations.
Third-Party Supply Chain Risk Management: Provides insights into the vulnerabilities and compliance status of third-party components.
Ease of implementation: This stage is typically the lowest lift for implementation given that most SBOM generators can be deployed standalone and pointed at the registry to scan all images.
Cons:
High Risk for Release Delays: Scanning images at this stage are akin to traditional waterfall-style development patterns. Most design decisions are baked-in and changes typically incur a steep penalty.
Difficult to Push Feedback into Exist Workflow: The registry sits outside of typical developer workflows and creating a feedback loop that seamlessly reports issues without changing the developer’s process is a non-trivial amount of work.
Complexity in Management: Managing SBOMs for both internally developed and third-party components adds complexity to the software supply chain.
Use-Cases
Software Supply Chain Security: Organizations can detect vulnerabilities in both their internal developed software and external software to prevent supply chain injections from leading to a security incident.
Compliance Reporting: Reporting on both 1st- and 3rd-party software is necessary for industries with strict regulatory requirements.
Detection of Leaky Pipelines: Identifies release images that have bypassed the standard build and test pipeline, allowing teams to take corrective action.
Third-Party Risk Analysis: Assesses the security and compliance of third-party container images, binaries, and applications before they are deployed.
Example: An organization subject to strict compliance standards like FedRAMP or cATO uses Analyzed SBOMs to verify that all artifacts in their registry, including third-party applications, comply with security policies and licensing requirements. This practice not only enhances their security posture but also streamlines the audit process.
Pro Tip
A registry is an easy and non-invasive way to test and evaluate potential SBOM generators. It won’t give you a full picture of what can be found in your DevSecOps pipeline but it will at least give you an initial idea of its efficacy and help you make the decision on whether to go through the effort of integrating it into your build pipeline where it will produce deeper insights.
Deploy => Deployed SBOM
As your container orchestrator is deploying an image from your registry into production it will also orchestrate any production dependencies such as sidecar containers or production dependencies. At this stage, an SBOM that is generated is named an “Deployed SBOM”by CISA.
The ideal scenario is that your operations team is storing all of these images in the same central registry as your engineering team but—as we’ve noted before—reality diverges from the ideal.
The additional metadata that is collected for a Deployed SBOM includes:
Any additional sidecar containers or production dependencies that are injected or modified through a release controller.
Pros and Cons
Pros:
Enhanced Security Posture: The final gate to prevent vulnerabilities from being deployed into production. This reduces the risk of security incidents and compliance violations.
Leaky Pipeline Detection: Another location to increase visibility into the happy path of the DevSecOps pipeline being circumvented.
Compliance Enforcement: Some compliance standards require a deployment breaking enforcement gate before any software is deployed to production. A container orchestrator release controller is the ideal location to implement this.
Cons:
Essentially the same issues that come up during the release phase.
High Risk for Release Delays: Scanning images at this stage are even later than traditional waterfall-style development patterns and will incur a steep penalty if an issue is uncovered.
Difficult to Push Feedback into Exist Workflow: A deployment release controller sits outside of typical developer workflows and creating a feedback loop that seamlessly reports issues without changing the developer’s process is a non-trivial amount of work.
Use-Cases
Strict Software Supply Chain Security: Implementing a pipeline breaking gating mechanism is typically reserved for only the most critical security vulnerabilities (think: an actively exploitable known vulnerability).
High-Stakes Compliance Enforcement: Industries like defense, financial services and critical infrastructure will require vendors to implement a deployment gate for specific risk scenarios beyond actively exploitable vulnerabilities.
Compliance Audit Automation: Most regulatory compliance frameworks mandate audit artifacts at deploy time, these documents can be automatically generated and stored for future audits.
Example: A Deployed SBOM can be used as the source of truth for generating a report that demonstrates that no HIGH or CRITICAL vulnerabilities were deployed to production during an audit period.
Pro Tip
Combine a Deployed SBOM with a container vulnerability scanner that cross-checks all vulnerabilities against CISA’s Known Exploitable Vulnerability (KEV) database. In the scenario where a matching KEV is found for a software component you can configure your vulnerability scanner to return a FAIL response to your release controller to abort the deployment.
This strategy creates an ideal balance between not adding delays to software delivery and an extremely high probability for a security incident.
Operate & Monitor (or Production) => Runtime SBOM
After your container orchestrator has deployed an application into your production environment it is live and serving customer traffic. An SBOM that is generated at this stage don’t have a name as specified by CISA. They are sometimes referred to as “Runtime SBOMs”. SBOMs are still a new-ish standard and will continue to evolve.
The additional metadata that is collected for a Runtime SBOM includes:
Modifications (i.e., intentional hotfixes or malicious malware injection) made to running applications in your production environment.
Pros and Cons
Pros:
Continuous Security Monitoring: Identifies new vulnerabilities that emerge after deployment.
Active Runtime Inventory: Provides a canonical view into an organization’s active software landscape.
Low Lift Implementation: Deploying SBOM generation into a production environment typically only requires deploying the scanner as another container and giving it permission to access the rest of the production environment.
Cons:
No Shift Left Security: By definition is excluded as a part of a shift left security posture.
Potential for Release Rollbacks: Scanning images at this stage is the worst possible place for proactive remediation. Discovering a vulnerability could potentially cause a security incident and force a release rollback.
Use-Cases
Rapid Incident Management: When new critical vulnerabilities are discovered and announced by the community the first priority for an organization is to determine exposure. An accurate production inventory, down to the component-level, is needed to answer this critical question.
Threat Detection: Continuously monitoring for anomalous activity linked to specific components. Sealing your system off completely from advanced persistent threats (APTs) is an unfeasible goal. Instead, quick detection and rapid intervention is the scalable solution to limit the impact of these adversaries.
Patch Management: As new releases of 3rd-party components and applications are released an inventory of impacted production assets provides helpful insights that can direct the prioritization of engineering efforts.
Example: When the XZ Utils vulnerability was announced in the spring of 2024, organizations that already automatically generated a Runtime SBOM inventory ran a simple search query against their SBOM database and knew within minutes—or even seconds—whether they were impacted.
Pro Tip
If you want to learn about how Google was able to go from an all-hands on deck security incident when the XZ Utils vulnerability was announced to an all clear under 10 minutes, watch our webinar with the lead of Google’s SBOM initiative.
As the SBOM standard has evolved the subject has grown considerably. What started as a structured way to store information about open source licenses has expanded to include numerous use-cases. A clear understanding of the evolution of SBOMs throughout the DevSecOps lifecycle is essential for organizations aiming to solve problems ranging from software supply chain security to regulatory compliance to legal risk management.
SBOMs are a powerful tool in the arsenal of modern software development. By recognizing their importance and integrating them thoughtfully across the DevSecOps lifecycle, you position your organization at the forefront of secure, efficient, and compliant software delivery.
Ready to secure your software supply chain and automate compliance tasks with SBOMs? Anchore is here to help. We offer SBOM management, vulnerability scanning and compliance automation enforcement solutions. If you still need some more information before looking at solutions, check out our webinar below on scaling a secure software supply chain with Kubernetes. 👇👇👇
Learn how Spectro Cloud secured their Kubernetes-based software supply chain and the pivotal role SBOMs played.
The software industry has wholeheartedly adopted the practice of building new software on the shoulders of the giants that came before them. To accomplish this developers construct a foundation of pre-built, 3rd-party components together then wrap custom 1st-party code around this structure to create novel applications. It is an extraordinarily innovative and productive practice but it also introduces challenges ranging from security vulnerabilities to compliance headaches to legal risk nightmares. Software bills of materials (SBOMs) have emerged to provide solutions for these wide ranging problems.
An SBOM provides a detailed inventory of all the components that make up an application at a point in time. However, it’s important to recognize that not all SBOMs are the same—even for the same piece of software! SBOMs evolve throughout the DevSecOps lifecycle; just as an application evolves from source code to a container image to a running application. The Cybersecurity and Infrastructure Security Agency’s (CISA) has codified this idea by differentiating between all of the different types of SBOMs. Each type serves different purposes and captures information about an application through its evolutionary process.
In this 2-part blog series, we’ll deep dive into each stage of the DevSecOps process and the associated SBOM. Highlighting the differences, the benefits and disadvantages and the use-cases that each type of SBOM supports. Whether you’re just beginning your SBOM journey or looking to deepen your understanding of how SBOMs can be integrated into your DevSecOps practices, this comprehensive guide will provide valuable insights and advice from industry experts.
Learn about the role that SBOMs for the security of your organization in this white paper.
Over the past decade the US government got serious about software supply chain security and began advocating for SBOMs as the standardized approach to the problem. As part of this initiative CISA created the Types of Software Bill of Material (SBOM) Documents white paper that codified the definitions of the different types of SBOMs and mapped them to each stage of the DevSecOps lifecycle. We will discuss each in turn but before we do, let’s anchor on some terminology to prevent confusion or misunderstanding.
Below is a diagram that lays out each stage of the DevSecOps lifecycle as well as the naming convention we will use going forward.
With that out of the way, let’s get started!
Plan => Design SBOM
As the DevSecOps paradigm has spread across the software industry, a notable best practice known as the security architecture review has become integral to the development process. This practice embodies the DevSecOps goal of integrating security into every phase of the software lifecycle, aligning perfectly with the concept of Shift-Left Security—addressing security considerations as early as possible.
At this stage, the SBOM documents the planned components of the application. The CISA refers to SBOMs generated during this phase as Design SBOMs. These SBOMs are preliminary and outline the intended components and dependencies before any code is written.
The metadata that is collected for a Design SBOM includes:
Component Inventory: Identifying potential OSS libraries and frameworks to be used as well as the dependency relationship between the components.
Licensing Information: Understanding the licenses associated with selected components to ensure compliance.
Risk Assessment Data: Evaluating known vulnerabilities and security risks associated with each component.
This might sound like a lot of extra work but luckily if you’re already performing DevSecOps-style planning that incorporates a security and legal review—as is best practice—you’re already surfacing all of this information. The only thing that is different is that this preliminary data is formatted and stored in a standardized data structure, namely an SBOM.
Pros and Cons
Pros:
Maximal Shift-Left Security: Vulnerabilities cannot be found any earlier in the software development process. Design time security decisions are the peak of a proactive security posture and preempt bad design decisions before they become ingrained into the codebase.
Cost Efficiency: Resolving security issues at this stage is generally less expensive and less disruptive than during later stages of development or—worst of all—after deployment.
Legal and Compliance Risk Mitigation: Ensures that all selected components meet necessary compliance standards, avoiding legal complications down the line.
Cons:
Upfront Investment: Gathering detailed information on potential components and maintaining an SBOM at this stage requires a non-trivial commitment of time and effort.
Incomplete Information: Projects are not static, they will adapt as unplanned challenges surface. A design SBOM likely won’t stay relevant for long.
Use-Cases
There are a number of use-cases that are enabled by
Security Policy Enforcement: Automatically checking proposed components against organizational security policies to prevent the inclusion of disallowed libraries or frameworks.
License Compliance Verification: Ensuring that all components comply with the project’s licensing requirements, avoiding potential legal issues.
Vendor and Third-Party Risk Management: Assessing the security posture of third-party components before they are integrated into the application.
Enhance Transparency and Collaboration: A well-documented SBOM provides a clear record of the software’s components but more importantly that the project aligns with the goals of all of the stakeholders (engineering, security, legal, etc). This builds trust and creates a collaborative environment that increases the chances of each individual stakeholder outcome will be achieved.
Example:
A financial services company operating within a strict regulatory environment uses SBOMs during planning to ensure that all components comply with compliance standards like PCI DSS. By doing so, they prevent the incorporation of insecure components that won’t meet PCI compliance. This reduces the risk of the financial penalties associated with security breaches and regulatory non-compliance.
Pro Tip
If your organization is still early in the maturity of its SBOM initiative then we generally recommend moving the integration of design time SBOMs to the back of the queue. As we mention at the beginning of this the information stored in a design SBOMs is naturally surfaced during the DevSecOps process, as long as the information is being recorded and stored much of the value of a design SBOM will be captured in the artifact. This level of SBOM integration is best saved for later maturity stages when your organization is ready to begin exploring deeper levels of insights that have a higher risk-to-reward ratio.
Alternatively, if your organization is having difficulty getting your teams to adopt a collaborative DevSecOps planning process mandating a SBOM as a requirement can act as a forcing function to catalyze a cultural shift.
Source => Source SBOM
During the development stage, engineers implement the selected 3rd-party components into the codebase. CISA refers to SBOMs generated during this phase as Source SBOMs. The SBOMs generated here capture the actual implemented components and additional information that is specific to the developer who is doing the work.
The additional metadata that is collected for a Source SBOM includes:
Dependency Mapping: Documenting direct and transitive dependencies.
Identity Metadata: Adding contributor and commit information.
Developer Environment: Captures information about the development environment.
Unlike Design SBOMs which are typically done manually, these SBOMs can be generated programmatically with a software composition analysis (SCA) tool—like Syft. They are usually packaged as command line interfaces (CLIs) since this is the preferred interface for developers.
Accurate and Timely Component Inventory: Reflects the actual components used in the codebase and tracks changes as codebase is actively being developed.
Shift-Left Vulnerability Detection: Identifies vulnerabilities as components are integrated but requires commit level automation and feedback mechanisms to be effective.
Facilitates Collaboration and Visibility: Keeps all stakeholders members informed about divergence from the original plan and provokes conversations as needed. This is also dependent on automation to record changes during development and the notification systems to broadcast the updates.
Example: A developer adds a new logging library to the project like an outdated version of Log4j. The SBOM, paired with a vulnerability scanner, immediately flags the Log4Shell vulnerability, prompting the engineer to update to a patched version.
Cons:
Noise from Developer Toolchains: A lot of times developer environments are bespoke. This creates noise for security teams by recording development dependencies.
Potential Overhead: Continuous updates to the SBOM can be resource-intensive when done manually; the only resource efficient method is by using an SBOM generation tool that automates the process.
Possibility of Missing Early Risks: Issues not identified during planning may surface here, requiring code changes.
Use-Cases
Faster Root Cause Analysis: During service incident retrospectives questions about where, when and by whom a specific component was introduced into an application. Source SBOMs are the programmatic record that can provide answers and decrease manual root cause analysis.
Real-Time Security Alerts: Immediate notification of vulnerabilities upon adding new components, decreasing time to remediation and keeping security teams informed.
Automated Compliance Checks: Ensuring added components comply with security or license policies to manage compliance risk.
Effortless Collaboration: Stakeholders can subscribe to a live feed of changes and immediately know when implementation diverges from the plan.
Pro Tip
Some SBOM generators allow developers to specify development dependencies that should be ignored, similar to .gitignore file. This can help cut down on the noise created by unique developer setups.
Build & Test => Build SBOM
When a developer pushes a commit to the CI/CD build system an automated process initiates that converts the application source code into an artifact that can then be deployed. CISA refers to SBOMs generated during this phase as Build SBOMs. These SBOMs capture both source code dependencies and build tooling dependencies.
The additional metadata that is collected includes:
Build Dependencies: Build tooling such as the language compilers, testing frameworks, package managers, etc.
Binary Analysis Data: Metadata for compiled binaries that don’t utilize traditional container formats.
Configuration Parameters: Details on build configuration files that might impact security or compliance.
Pros and Cons
Pros:
Build Infrastructure Analysis: Captures build-specific components which may have their own vulnerability or compliance issues.
Reuses Existing Automation Tooling: Enables programmatic security and compliance scanning as well as policy enforcement without introducing any additional build tooling.
Reuses Existing Automation Tooling: Directly integrates with developer workflow. Engineers receive security, compliance, etc. feedback without the need to reference a new tool.
Reproducibility: Facilitates reproducing builds for debugging and auditing.
Cons:
SBOM Sprawl: Build processes run frequently, if it is generating an SBOM with each run you will find yourself with a glut of files that you will have to manage.
Delayed Detection: Vulnerabilities or non-compliance issues found at this stage may require rework.
Use-Cases
SBOM Drift Detection: By comparing SBOMs from two or more stages, unexpected dependency injection can be detected. This might take the form of a benign, leaky build pipeline that requires manual workarounds or a malicious actor attempting to covertly introduce malware. Either way this provides actionable and valuable information.
Policy Enforcement: Enables the creation of build breaking gates to enforce security or compliance. For high-stakes operating environments like defense, financial services or critical infrastructure, automating security and compliance at the expense of some developer friction is a net-positive strategy.
Automated Compliance Artifacts: Compliance requires proof in the form of reports and artifacts. Re-utilizing existing build tooling automation to automate this task significantly reduces the manual work required by security teams to meet compliance requirements.
Example: A security scan during testing uses the Build SBOM to identify a critical vulnerability and alerts the responsible engineer. The remediation process is initiated and a patch is applied before deployment.
Pro Tip
If your organization is just beginning their SBOM journey, this is the recommended phase of the DevSecOps lifecycle to implement SBOMs first. The two primary cons of this phase can be mitigated the easiest. For SBOM sprawl, you can procure a turnkey SBOM management solution like Anchore SBOM.
As for the delay in feedback created by waiting till the build phase, if your team is utilizing DevOps best practices and breaking features up into smaller components that fit into 2-week sprints then this tight scoping will limit the impact of any significant vulnerabilities or non-compliance discovered.
Intermission
So far we’ve covered the first half of the DevSecOps lifecycle. Next week we will publish the second part of this blog series where we’ll cover the remainder of the pipeline. Watch our socials to be sure you get notified when part 2 is published.
If you’re looking for some additional reading in the meantime, check out our container security white paper below.
Learn the 5 best practices for container security and how SBOMs play a pivotal role in securing your software supply chain.
Choosing the right SBOM (software bill of materials) generator is tricker than it looks at first glance. SBOMs are the foundation for a number of different uses ranging from software supply chain security to continuous regulatory compliance. Due to its cornerstone nature, the SBOM generator that you choose will either pave the way for achieving your organization’s goals or become a road block that delays critical initiatives.
But how do you navigate the crowded market of SBOM generation tools to find the one that aligns with your organization’s unique needs? It’s not merely about selecting a tool with the most features or the nicest CLI. It’s about identifying a solution that maps directly to your desired outcomes and use-cases, whether that’s rapid incident response, proactive vulnerability management, or compliance reporting.
We at Anchore have been enabling organizations to achieve their SBOM-related outcomes and do it with the least amount of frustration and setbacks. We’ve compiled our learnings on choosing the right SBOM generation tool into a framework to help the wider community make decisions that set them up for success.
Below is a quick TL;DR of the high-level evaluation criteria that we cover in this blog post:
Understanding Your Use-Cases: Aligning the tool with your specific goals.
Ecosystem Compatibility: Ensuring support for your programming languages, operating systems, and build artifacts.
Data Accuracy: Evaluating the tool’s ability to provide comprehensive and precise SBOMs.
DevSecOps Integration: Assessing how well the tool fits into your existing DevSecOps tooling.
Proprietary vs. Open Source: Weighing the long-term implications of your choice.
By focusing on these key areas, you’ll be better equipped to select an SBOM generator that not only meets your current requirements but also positions your organization for future success.
Learn about the role that SBOMs for the security of your organization in this white paper.
When choosing from the array of SBOM generation tools in the market, it is important to frame your decision with the outcome(s) that you are trying to achieve. If your goal is to improve the response time/mean time to remediation when the next Log4j-style incident occurs—and be sure that there will be a next time—an SBOM tool that excels at correctly identifying open source licenses in a code base won’t be the best solution for your use-case (even if you prefer its CLI ;-D).
What to Do:
Identify and prioritize the outcomes that your organization is attempting to achieve
Map the outcomes to the relevant SBOM use-cases
Review each SBOM generation tool to determine whether they are best suited to your use-cases
It can be tempting to prioritize an SBOM generator that is best suited to our preferences and workflows; we are the ones that will be using the tool regularly—shouldn’t we prioritize what makes our lives easier? If we prioritize our needs above the goal of the initiative we might end up putting ourselves into a position where our choice in tools impedes our ability to recognize the desired outcome. Using the correct framing, in this case by focusing on the use-cases, will keep us focused on delivering the best possible outcome.
SBOMs can be utilized for numerous purposes: security incident response, open source license compliance, proactive vulnerability management, compliance reporting or software supply chain risk management. We won’t address all use-cases/outcomes in this blog post, a more comprehensive treatment of all of the potential SBOM use-cases can be found on our website.
Example SBOM Use-Cases:
Security incident response: an inventory of all applications and their dependencies that can be queried quickly and easily to identify whether a newly announced zero-day impacts the organization.
Proactive vulnerability management: all software and dependencies are scanned for vulnerabilities as part of the DevSecOps lifecycle and remediated based on organizational priority.
Regulatory compliance reporting: compliance artifacts and reports are automatically generated by the DevSecOps pipeline to enable continuous compliance and prevent manual compliance work.
Software supply chain risk management: an inventory of software components with identified vulnerabilities used to inform organizational decision making when deciding between remediating risk versus building new features.
Open source license compliance: an inventory of all software components and the associated OSS license to measure potential legal exposure.
Pro tip:While you will inevitably leave many SBOM use-cases out of scope for your current project, keeping secondary use-cases in the back of your mind while making a decision on the right SBOM tool will set you up for success when those secondary use-cases eventually become a priority in the future.
Does the SBOM generator support your organization’s ecosystem of programming languages, etc?
SBOM generators aren’t just tools to ingest data and re-format it into a standardized format. They are typically paired with a software composition analysis (SCA) tool that scans an application/software artifact for metadata that will populate the final SBOM.
Support for the complete array of programming languages, build artifacts and operating system ecosystems is essentially an impossible task. This means that support varies significantly depending on the SBOM generator that you select. An SBOM generator’s ability to help you reach your organizational goals is directly related to its support for your organization’s software tooling preferences. This will likely be one of the most important qualifications when choosing between different options and will rule out many that don’t meet the needs of your organization.
Considerations:
Programming Languages: Does the tool support all languages used by your team?
Operating Systems: Can it scan the different OS environments your applications run on top of?
Build Artifacts: Does the tool scan containers? Binaries? Source code repositories?
Frameworks and Libraries: Does it recognize the frameworks and libraries your applications depend on?
Data accuracy
This is one of the most important criteria when evaluating different SBOM tools. An SBOM generator may claim support for a particular programming language but after testing the scanner you may discover that it returns an SBOM with only direct dependencies—honestly not much better than a package.json or go.mod file that your build process spits out.
Two different tools might both generate a valid SPDX SBOM document when run against the same source artifact, but the content of those documents can vary greatly. This variation depends on what the tool can inspect, understand, and translate. Being able to fully scan an application for both direct and transitive dependencies as well as navigate non-ideomatic patterns for how software can be structured end up being the true differentiators between the field of SBOM generation contenders.
Imagine using two SBOM tools on a Debian package. One tool recognizes Debian packages and includes detailed information about them in the SBOM. The latter can’t fully parse the Debian .deb format and omits critical information. Both produce an SBOM, but only one provides the data you need to power use-case based outcomes like security incident response or proactive vulnerability management.
In this example, we first generate an SBOM using Syft then run it through Grype—our vulnerability scanning tool. Syft + Grype uncover 4 critical vulnerabilities.
Now let’s try the same thing but “simulate” an SBOM generator that can’t fully parse the structure of the software artifact in question:
In this case, we are returned none of the critical vulnerabilities found with the former tool.
This highlights the importance of careful evaluation of the SBOM generator that you decide on. It could mean the difference between effective vulnerability risk management and a security incident.
Can the SBOM tool integration into your DevSecOps pipeline?
If the SBOM generator is packaged as a self-contained binary with a command line interface (CLI) then it should tick this box. CI/CD build tools are most amenable to this deployment model. If the SBOM generation tool in question isn’t a CLI then it should at least run as a server with an API that can be called as part of the build process.
Integrating with an organization’s DevSecOps pipeline is key to enable a scalable SBOM generation process. By implementing SBOM creation directly into the existing build tooling, organizations can leverage existing automation tools to ensure consistency and efficiency which are necessary for achieving the desired outcomes.
Proprietary vs. open source SBOM generator?
Using an open source SBOM tool is considered an industry best practice. This is because it guards against the risks associated with vendor lock-in. As a bonus, the ecosystem for open source SBOM generation tooling is very healthy. OSS will always have an advantage over proprietary in regards to ecosystem coverage and data quality because it will get into the hands of more users which will create a feedback loop that closes gaps in coverage or quality.
Finally, even if your organization decides to utilize a software supply chain security product that has its own proprietary SBOM generator, it is still better to create your SBOMs with an open source SBOM generator, export to a standardized format (e.g., SPDX or CycloneDX) then have your software supply chain security platform ingest these non-proprietary data structures. All platforms will be able to ingest SBOMs from one or both of these standards-based formats.
Wrap-Up
In a landscape where the next security/compliance/legal challenge is always just around the corner, equipping your team with the right SBOM generator empowers you to act swiftly and confidently. It’s an investment not just in a tool, but in the resilience and security of your entire software supply chain. By making a thoughtful, informed choice now, you’re laying the groundwork for a more secure and efficient future.
Save your developers time with Anchore Enterprise. Get instant access with a 15-day free trial.
We are excited to announce two significant milestones in our partnership with Amazon Web Services (AWS) today:
Anchore Enterprise can now be purchased through the AWS marketplace and
Anchore has joined the APN’s (Amazon Partner Network) ISV Accelerate Program
Organizations like Nvidia, Cisco Umbrella and Infoblox validate our commitment to delivering trusted solutions for SBOM management, secure software supply chains, and automated compliance enforcement and can now benefit from a stronger partnership between AWS and Anchore.
Anchore’s best-in-breed container security solution was chosen by Cisco Umbrella as it seamlessly integrated in their AWS infrastructure and accelerated meeting all six FedRAMP requirements. They deployed Anchore into an environment that had to meet a number of high-security and compliance standards. Chief among those was STIG compliance for Amazon EC2 nodes that backed the Amazon EKS deployment.
In addition, Anchore Enterprise supports high-security requirements such as IL4/IL6, FIPS, SSDF attestation and EO 14208 compliance.
Anchore Enterprise is now available on AWS Marketplace
The AWS Marketplace offers a convenient and efficient way for AWS customers to procure Anchore. It simplifies the procurement process, provides greater control and governance, and fosters innovation by offering a rich selection of tools and services that seamlessly integrate with their existing AWS infrastructure.
Anchore Enterprise on AWS Marketplace benefits DevSecOps teams by enabling:
Self-procurement via the AWS console
Faster procurement with applicable legal terms provided and standardized security review
Easier budget management with a single consolidated AWS bill for all infrastructure spend
Spend on Anchore Enterprise partially counts towards EDP (Enterprise Discount Program) committed spend
By strengthening our collaboration with AWS, customers can now feel at ease that Anchore Enterprise integrates and operates seamlessly on AWS infrastructure. Joining the ISV Accelerate Program allows us to work closely with AWS account teams to ensure seamless support and exceptional service for our joint clients.
We are thrilled to announce the release of Anchore Enterprise 5.10, our tenth release of 2024. This update brings two major enhancements that will elevate your experience and bolster your security posture: the new Anchore Data Service (ADS) and expanded AnchoreCTL ecosystem coverage.
With ADS, we’ve built a fast and reliable solution that reduces time spent by DevSecOps teams debugging intermittent network issues from flaky services that are vital to software supply chain security.
It’s been a fall of big releases at Anchore and we’re excited to continue delivering value to our loyal customers. Read on to get all of the gory details >>
Announcing the Anchore Data Service
Before, customers ran the Anchore Feed Service within their environment to pull data feeds into their Anchore Enterprise deployment. To get an idea of what this looked like, see the architecture diagram of Anchore Enterprise prior to version 5.10:
Originally we did this to give customers more control over their environment. Unfortunately this wasn’t without its issues. The data feeds are provided by the community which means the services were designed to be accessible but cost-efficient. This meant they were unreliable; frequently having accessibility issues.
We only have to stretch our memory back to the spring to recall an example that made national headlines. The National Vulnerability Database (NVD) ran into funding issues. This impacted both the creation of new vulnerabilities AND the availability of their API. This created significant friction for Anchore customers—not to mention the entirety of the software industry.
Now, Anchore is running its own enterprise-grade service, named Anchore Data Service (ADS). It is a replacement for the former feed service. ADS aggregates all of the community data feeds, enriches the data (with proprietary threat data) and packages it for customers; all of this with a service availability guarantee expected of an enterprise service.
The new architecture with ADS as the intermediary is illustrated below:
As a bonus for our customers running air-gapped deployments of Anchore Enterprise, there is no more need to run a second deployment of Anchore Enterprise in a DMZ to pull down the data feeds. Instead a single file is pulled from ADS then transferred to a USB thumb drive. From there a single CLI command is run to update your air-gapped deployment of Anchore Enterprise.
Increased AnchoreCTL Ecosystem Coverage
We have increased the number of supported ecosystems (e.g., C++, Swift, Elixir, R, etc.) in Anchore Enterprise. This improves coverage and increases the likelihood that all of your organization’s applications can be scanned and protected by Anchore Enterprise.
More importantly, we have completely re-architected the process for how Anchore Enterprise supports new ecosystems. By integrating Syft—Anchore’s open source SBOM generation tool—directly into AnchoreCTL, Anchore’s customers will now get access to new ecosystem support as they are merged into Syft’s codebase.
Before Syft and AnchoreCTL were somewhat separate which caused AnchoreCTL’s support for new ecosystems to lag Syft’s. Now, they are fully integrated. This enables all of Anchore’s enterprise and public sector customers to take full advantage of the open source community’s development velocity.
Full list of support ecosystems
Below is a complete list of all supported ecosystems by both Syft and AnchoreCTL (as of Anchore Enterprise 5.10; see our docs for most current info):
Alpine (apk)
C (conan)
C++ (conan)
Dart (pubs)
Debian (dpkg)
Dotnet (deps.json)
Objective-C (cocoapods)
Elixir (mix)
Erlang (rebar3)
Go (go.mod, Go binaries)
Haskell (cabal, stack)
Java (jar, ear, war, par, sar, nar, native-image)
JavaScript (npm, yarn)
Jenkins Plugins (jpi, hpi)
Linux kernel archives (vmlinuz)
Linux kernel a (ko)
Nix (outputs in /nix/store)
PHP (composer)
Python (wheel, egg, poetry, requirements.txt)
Red Hat (rpm)
Ruby (gem)
Rust (cargo.lock)
Swift (cocoapods, swift-package-manager)
WordPress plugins
After you update to Anchore Enterprise 5.10, the SBOM inventory will now display all of the new ecosystems. Any SBOMs that have been generated for a particular ecosystem will show up top. The screenshot below gives you an idea of what this will look like:
Wrap-Up
Anchore Enterprise 5.10 marks a new chapter in providing reliable, enterprise-ready security tooling for modern software development. The introduction of the Anchore Data Service ensures that you have consistent and dependable access to critical vulnerability and exploit data, while the expanded ecosystem support means that no part of your tech stack is left unscrutinized for latent risk. Upgrade to the latest version and experience these new features for yourself.
To update and leverage these new features check out our docs, reach out to your Customer Success Engineer or contact our support team. Your feedback is invaluable to us, and we look forward to continuing to support your organization’s security needs.We are offering all of our product updates as a new quarterly product update webinar series. Watch the fall webinar update in the player below to get all of the juicy tidbits from our product team.
Save your developers time with Anchore Enterprise. Get instant access with a 15-day free trial.
Today we have released Anchore Enterprise 5.8, featuring the integration of the U.S. Cybersecurity and Infrastructure Security Agency’s (CISA) Known Exploited Vulnerabilities (KEV) catalog as a new vulnerability feed.
Previously, Anchore Enterprise matched software libraries and frameworks inside applications against vulnerability databases, such as, National Vulnerability Database (NVD), the GitHub Advisory Database or individual vendor feeds. With Anchore Enterprise 5.8, customers can augment their vulnerability feeds with the KEV catalog without having to leave the dashboard. In addition, teams can automatically flag exploitable vulnerabilities as software is being developed or gate build artifacts from being released into production.
Before we jump into what all of this means, let’s take a step back and get some context to KEV and its impact on DevSecOps pipelines.
What is CISA KEV?
The KEV (Known Exploited Vulnerabilities) catalog is a critical cybersecurity resource maintained by the U.S. Cybersecurity and Infrastructure Security Agency (CISA). It is a database of exploited vulnerabilities that is current and active in the wild. While addressing these vulnerabilities is mandatory for U.S. federal agencies under Binding Operational Directive 22-01, the KEV catalog serves as an essential public resource for improving cybersecurity for any organization.
The primary difference between CISA KEV and a standard vulnerability feed (e.g., the CVE program) are the adjectives, “actively exploited”. Actively exploited vulnerabilities are being used by attackers to compromise systems in real-time, meaning now. They are real and your organization may be standing in the line of fire, whereas CVE lists vulnerabilities that may or may not have any available exploits currently. Due to the imminent threat of actively exploited vulnerabilities, they are considered the highest risk outside of an active security incident.
The benefits of KEV enrichment
The KEV catalog offers significant benefits to organizations striving to improve their cybersecurity posture. One of its primary advantages is its high signal-to-noise ratio. By focusing exclusively on vulnerabilities that are actively being exploited in the wild, the KEV cuts through the noise of countless potential vulnerabilities, allowing developers and security teams to prioritize their efforts on the most critical and immediate threats. This focused approach ensures that limited resources are allocated to addressing the vulnerabilities that pose the greatest risk, significantly enhancing an organization’s security efficiency.
Moreover, the KEV can be leveraged as a powerful tool in an organization’s development and deployment processes. By using the KEV as a trigger for build pipeline gates, companies can prevent exploitable vulnerabilities from being promoted to production environments. This proactive measure adds an extra layer of security to the software development lifecycle, reducing the risk of deploying vulnerable code.
Additionally, while adherence to the KEV is not yet a universal compliance requirement, it represents a security best practice that forward-thinking organizations are adopting. Given the trend of such practices evolving into compliance mandates, integrating the KEV into security protocols can be seen as a form of future-proofing, potentially easing the transition if and when such practices inevitably become compliance requirements.
How Anchore Enterprise delivers KEV enrichment
With Anchore Enterprise, CISA KEV is now a vulnerability feed similar to any other data feed that gets imported into the system. Anchore Enterprise can be configured to pull this directly from the source as part of the deployment feed service.
To make use of the new KEV data, we have an additional rule option in the Anchore Policy Engine that allows a STOP or WARN to be configured when a vulnerability is detected that is on the KEV list. When any application build, registry store or runtime deploy occurs, Anchore Enterprise will evaluate the artifiact’s SBOM against the security policy and if the SBOM has been annotated with a KEV entry then the Anchore policy engine can return a STOP value to inform the build pipeline to fail the step and return the KEV as the source of the violation.
To configure the KEV feed as a trigger in the policy engine, first select vulnerabilities as the gate then kev list as a trigger. Finally choose an action.
After you save the new rule, you will see the kev list rule as part of the entire policy.
After scanning a container with the policy that has the kev list rule in it, you can view all dependencies that match the kev list vulnerability feed.
Next Steps
To stay on top of our releases, sign-up for our monthly newsletter or follow our LinkedIn account. If you are already an Anchore customer, please reach out to your account manager to upgrade to 5.8 and gain access to KEV support. We also offer a 15 day free trial to get hands on with Anchore Enterprise or you can reach out to us for a guided tour.
Save your developers time with Anchore Enterprise. Get instant access with a 15-day free trial.