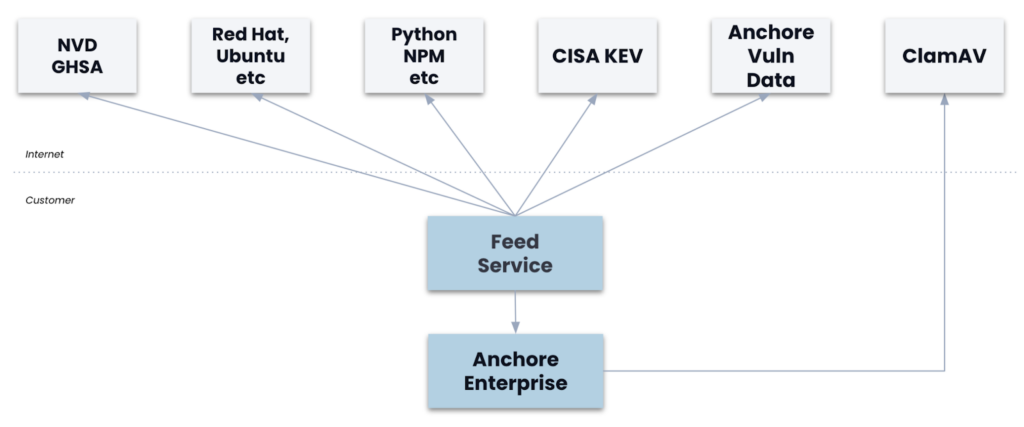
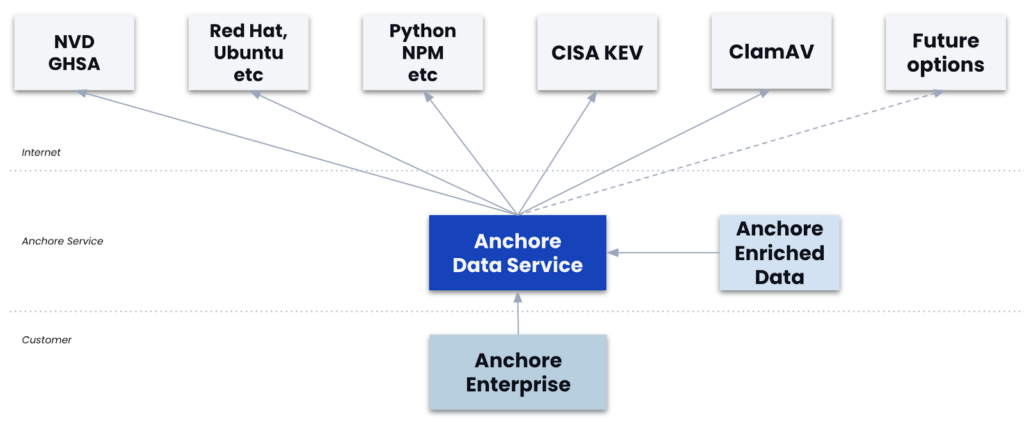
Fast Facts
- To help organizations meet the DoD’s security controls, DISA develops Security Technical Implementation Guides (STIGs) to provide guidance on how to secure operating systems, network devices, software, and other IT systems. DISA regularly updates and releases new STIG versions.
- STIG compliance is mandatory for any organization that operates within the DoD network or handles DoD information, including DoD contractors and vendors, government agencies, and DoD IT teams.
- With more than 500 total STIGs (and counting!), your organization can streamline the STIG compliance process by identifying applicable STIGs upfront, prioritizing fixes, establishing a maintenance schedule, and assigning clear responsibilities to team members.
- Tools like DISA STIG Viewer, Anchore Enterprise, and SCARP Compliance Checker can help track and automate STIG compliance.
In the rapidly modernizing landscape of cybersecurity compliance, evolving to a continuous compliance posture is more critical than ever, particularly for organizations involved with the Department of Defense (DoD) and other government agencies. In February 2025, Microsoft reported that governments are in the top 3 most targeted sectors worldwide.
At the heart of the DoD’s modern approach to software development is the DoD Enterprise DevSecOps Reference Design, commonly implemented as a DoD Software Factory. A key component of this framework is adhering to the Security Technical Implementation Guides (STIGs) developed by the Defense Information Systems Agency (DISA).
STIG compliance within the DevSecOps pipeline not only accelerates the delivery of secure software but also embeds robust security practices directly into the development process, safeguarding sensitive data and reinforcing national security.
This comprehensive guide will walk you through what STIGs are, who should care about them, the levels and key categories of STIG compliance, how to prepare for the compliance process, and tools available to automate STIG implementation and maintenance. Read on for the full overview or skip ahead to find the information you need:
- What are STIGs?
- Who needs to comply?
- Levels of STIG compliance
- Key categories of requirements
- Preparing for the STIG compliance process
- STIG compliance tools

What are STIGs and who should care?
Understanding DISA and STIGs
The Defense Information Systems Agency (DISA) is the DoD agency responsible for delivering information technology (IT) support to ensure the security of U.S. national defense systems. To help organizations meet the DoD’s rigorous security controls, DISA develops Security Technical Implementation Guides (STIGs).
STIGs are configuration standards that provide prescriptive guidance on how to secure operating systems, network devices, software, and other IT systems. They serve as a secure configuration standard to harden systems against cyber threats.
For example, a STIG for the open source Apache web server would specify that encryption is enabled for all traffic (incoming or outgoing). This would require the generation of SSL/TLS certificates on the server in the correct location, updating the server’s configuration file to reference this certificate and re-configuration of the server to serve traffic from a secure port rather than the default insecure port.
Who should care about STIG compliance?
In its annual Software Supply Chain Security report, Anchore found that the average organization complies with 4.9 cybersecurity compliance standards. STIG compliance, in particular, is mandatory for any organization that operates within the DoD network or handles DoD information. This includes:
- DoD Contractors and Vendors: Companies providing products or services to the DoD, a.k.a. the defense industrial base (DIB)
- Government Agencies: Federal agencies interfacing with the DoD
- DoD Information Technology Teams: IT professionals within the DoD responsible for system security
Connection to the RMF and NIST SP 800-53
The Risk Management Framework (RMF)—known formally as NIST 800-37—is a framework that integrates security and risk management into IT systems as they are being developed. The STIG compliance process outlined below is directly integrated into the higher-level RMF process. As you follow the RMF, the individual steps of STIG compliance will be completed in turn.
STIGs are also closely connected to the NIST 800-53, colloquially known as the “Control Catalog”. NIST 800-53 outlines security and privacy controls for all federal information systems; the controls are not prescriptive about the implementation, only the best practices and outcomes that need to be achieved.
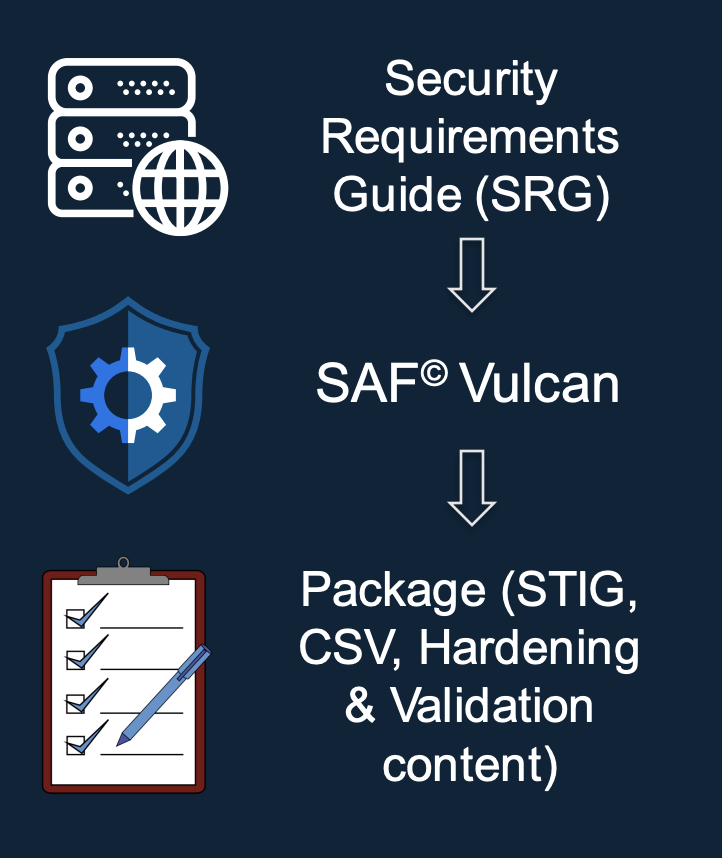
As DISA developed the STIG compliance standard, they started with the NIST 800-53 controls as a baseline, then “tailored” them to meet the needs of the DoD; these customized security best practices are known as Security Requirements Guides (SRGs). In order to remove all ambiguity around how to meet these higher-level best practices STIGs were created with implementation specific instructions.
For example, an SRG will mandate that all systems utilize a cybersecurity best practice, such as, role-based access control (RBAC) to prevent users without the correct privileges from accessing certain systems. A STIG, on the other hand, will detail exactly how to configure an RBAC system to meet the highest security standards.
Levels of STIG Compliance
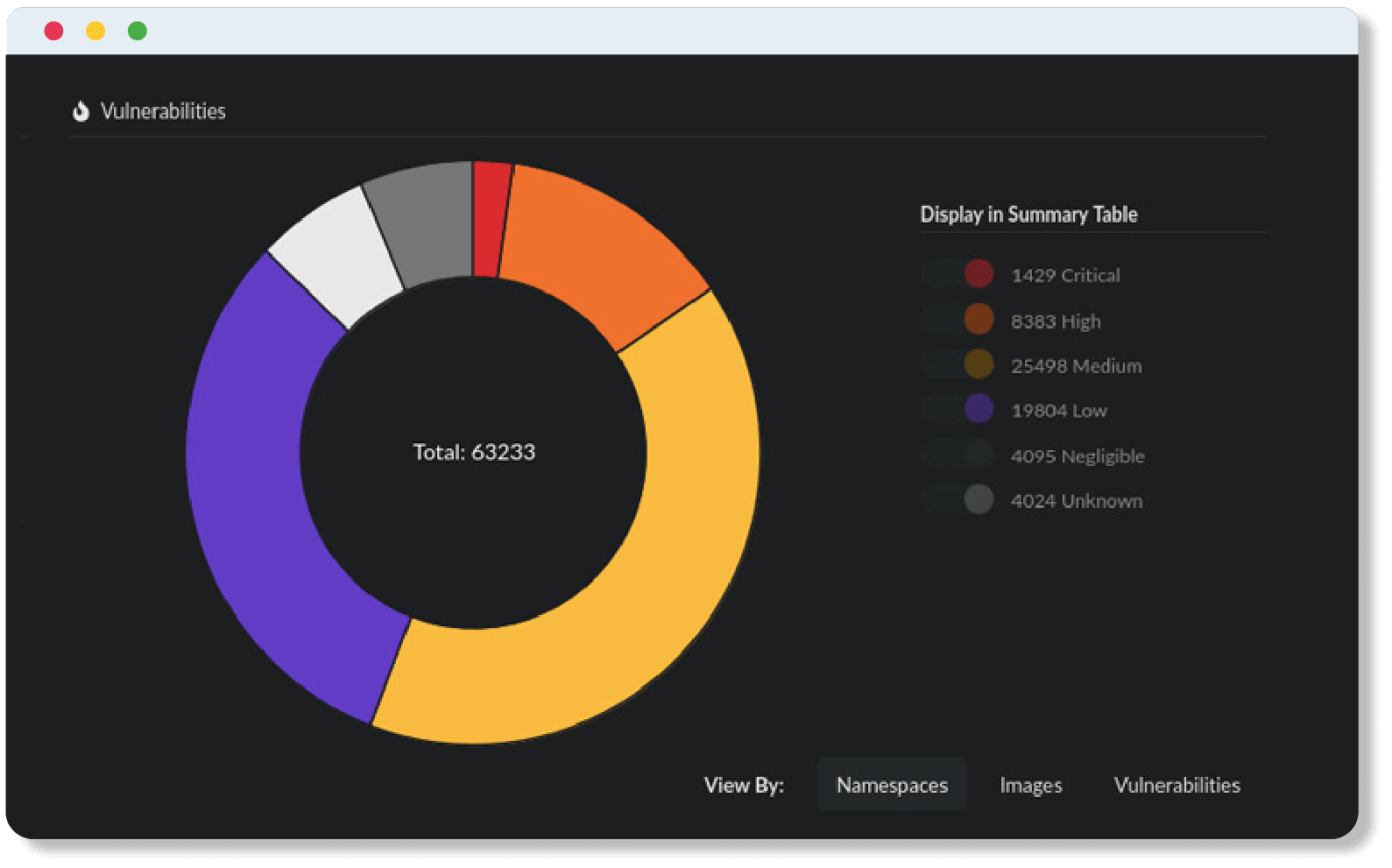
The DISA STIG compliance standard uses Severity Category Codes to classify vulnerabilities based on their potential impact on system security. These codes help organizations prioritize remediation efforts. The three Severity Category Codes are:
- Category I (Cat I): These are the highest severity or highest risk vulnerabilities, allowing an attacker immediate access to a system or network or allowing superuser access. Due to their high risk nature, these vulnerabilities be addressed immediately.
- Category II (Cat II): These vulnerabilities provide information with a high potential of giving access to intruders. These findings are considered a medium risk and should be remediated promptly.
- Category III (Cat III): These vulnerabilities constitute the lowest risk, providing information that could potentially lead to compromise. Although not as pressing as Cat II & III issues, it is still important to address these vulnerabilities to minimize risk and enhance overall security.
Understanding these categories is crucial in the STIG process, as they guide organizations in prioritizing remediation of vulnerabilities.
Key categories of STIG requirements
Given the extensive range of technologies used in DoD environments, there are nearly 500 STIGs (as of May 2025) applicable to different systems, devices, applications, and more. While we won’t list all STIG requirements and benchmarks here, it’s important to understand the key categories and who they apply to.
1. Operating System STIGs
Applies to: System Administrators and IT Teams managing servers and workstations
Examples:
- Microsoft Windows STIGs: Provides guidelines for securing Windows operating systems.
- Linux STIGs: Offers secure configuration requirements for various Linux distributions.
2. Network Device STIGs
Applies to: Network Engineers and Administrators
Examples:
- Network Router STIGs: Outlines security configurations for routers to protect network traffic.
- Network Firewall STIGs: Details how to secure firewall settings to control access to networks.
3. Application STIGs
Applies to: Software Developers and Application Managers
Examples:
- Generic Application Security STIG: Outlines the necessary security best practices needed to be STIG compliant
- Web Server STIG: Provides security requirements for web servers.
- Database STIG: Specifies how to secure database management systems (DBMS).
4. Mobile Device STIGs
Applies to: Mobile Device Administrators and Security Teams
Examples:
- Apple iOS STIG: Guides securing of Apple mobile devices used within the DoD.
- Android OS STIG: Details security configurations for Android devices.
5. Cloud Computing STIGs
Applies to: Cloud Service Providers and Cloud Infrastructure Teams
Examples:
- Microsoft Azure SQL Database STIG: Offers security requirements for Azure SQL Database cloud service.
- Cloud Computing OS STIG: Details secure configurations for any operating system offered by a cloud provider that doesn’t have a specific STIG.
Each category addresses specific technologies and includes a STIG checklist to ensure all necessary configurations are applied.
See an example of a STIG checklist for “Application Security and Development” here.
How to Prepare for the STIG Compliance Process
Achieving DISA STIG compliance involves a structured approach. Here are the stages of the STIG process and tips to prepare:
Stage 1: Identifying Applicable STIGs
With hundreds of STIGs relevant to different organizations and technology stacks, this step should not be underestimated. First, conduct an inventory of all systems, devices, applications, and technologies in use. Then, review the complete list of STIGs to match each to your inventory to ensure that all critical areas requiring secure configuration are addressed. This step is essential to avoiding gaps in compliance.
Tip: Use automated tools to scan your environment, then match assets to relevant STIGs.
Stage 2: Implementation
After you’ve mapped your technology to the corresponding STIGs, the process of implementing the security configurations outlined in the guides begins. This step may require collaboration between IT, security, and development teams to ensure that the configurations are compatible with the organization’s infrastructure while enforcing strict security standards. Be sure to keep detailed records of changes made.
Tip: Prioritize implementing fixes for Cat I vulnerabilities first, followed by Cat II and Cat III. Depending on the urgency and needs of the mission, ATO can still be achieved with partial STIG compliance. Prioritizing efforts increases the chances that partial compliance is permitted.
Stage 3: Auditing & Maintenance
After the STIGs have been implemented, regular auditing and maintenance are critical to ensure ongoing compliance, verifying that no deviations have occurred over time due to system updates, patches, or other changes. This stage includes periodic scans, manual reviews, and remediation of any identified gaps.
Organizations should also develop a plan to stay informed about new STIG releases and updates from DISA. You can sign up for automated emails on https://www.cyber.mil/stigs.
Tip: Establish a maintenance schedule and assign responsibilities to team members. Alternatively, you can adopt a policy-as-code approach to continuous compliance by embedding STIG requirements directly into your DevSecOps pipeline, enabling automated, ongoing compliance.
General Implementation Tips
- Training: Ensure your team is familiar with STIG requirements and the compliance process.
- Collaboration: Work cross-functionally with all relevant departments, including IT, security, and compliance teams.
- Resource Allocation: Dedicate sufficient resources, including time and personnel, to the compliance effort.
- Continuous Improvement: Treat STIG compliance as an ongoing process rather than a one-time project.
- Test for Impact on Functionality: The downside of STIG controls’ high level of security is a potential to negatively impact functionality. Be sure to conduct extensive testing to identify broken features, compatibility issues, interoperability challenges, and more.
Tools to automate STIG implementation and maintenance
The 2024 Report on Software Supply Chain Security found “automating compliance checks” is a top priority, with 52% of respondents ranking it in their top 3 supply chain security challenges. For STIGs, automation can significantly streamline the compliance process. Here are a few tools that can help:
1. Anchore STIG (Static and Runtime)
- Purpose: Automates the process of checking container images against STIG requirements.
- Benefits:
- Simplifies compliance for containerized applications.
- Integrates into CI/CD pipelines for continuous compliance.
- Use Case: Ideal for DevSecOps teams utilizing containers in their deployments.
2. SCAP Compliance Checker
- Purpose: Provides automated compliance scanning using the Security Content Automation Protocol (SCAP).
- Benefits:
- Validates system configurations against STIGs.
- Generates detailed compliance reports.
- Use Case: Useful for system administrators needing to audit various operating systems.
3. DISA STIG Viewer
- Purpose: Helps in viewing and managing STIG checklists.
- Benefits:
- Allows for easy navigation of STIG requirements.
- Facilitates documentation and reporting.
- Use Case: Assists compliance officers in tracking compliance status.
4. DevOps Automation Tools
- Infrastructure Automation Examples: Red Hat Ansible, Perforce Puppet, Hashicorp Terraform
- Software Build Automation Examples: CloudBees CI, GitLab
- Purpose: Automate the deployment of secure configurations that meet STIG compliance across multiple systems.
- Benefits:
- Ensures consistent application of secure configuration standards.
- Reduces manual effort and the potential for errors.
- Use Case: Suitable for large-scale environments where manual configuration is impractical.
5. Vulnerability Management Tools
- Examples: Anchore Secure
- Purpose: Identify vulnerabilities and compliance issues within your network.
- Benefits:
- Provides actionable insights to remediate security gaps.
- Offers continuous monitoring capabilities.
- Use Case: Critical for security teams focused on proactive risk management.
Wrap-Up
Achieving DISA STIG compliance is mandatory for organizations working with the DoD. By understanding what STIGs are, who they apply to, and how to navigate the compliance process, your organization can meet the stringent compliance requirements set forth by DISA. As a bonus, you will enhance its security posture and reduce the potential for a security breach.
Remember, compliance is not a one-time event but an ongoing effort that requires regular updates, audits, and maintenance. Leveraging automation tools like Anchore STIG and Anchore Secure can significantly ease this burden, allowing your team to focus on strategic initiatives rather than manual compliance tasks.
Stay proactive, keep your team informed, and make use of the resources available to ensure that your IT systems remain secure and compliant.