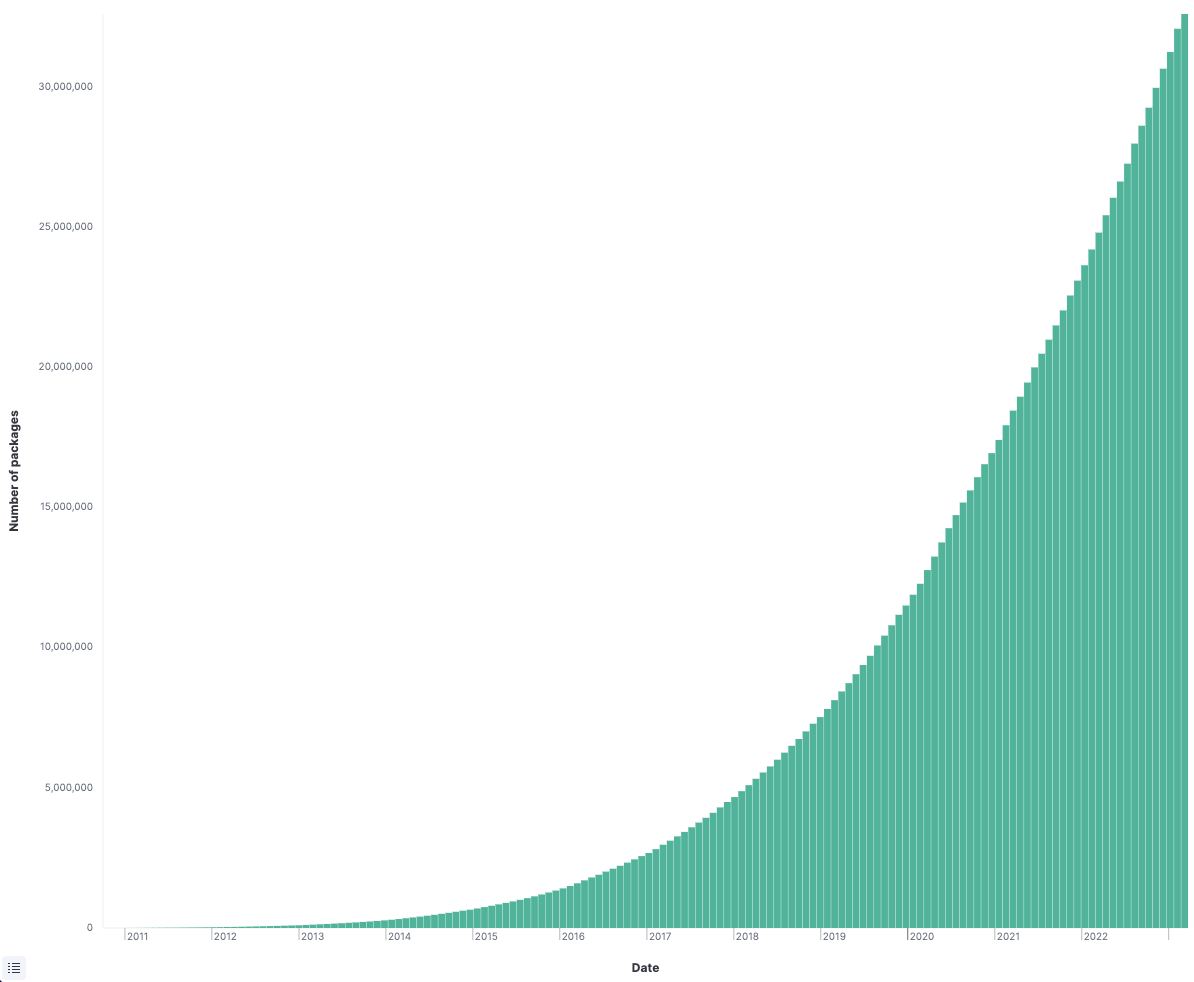
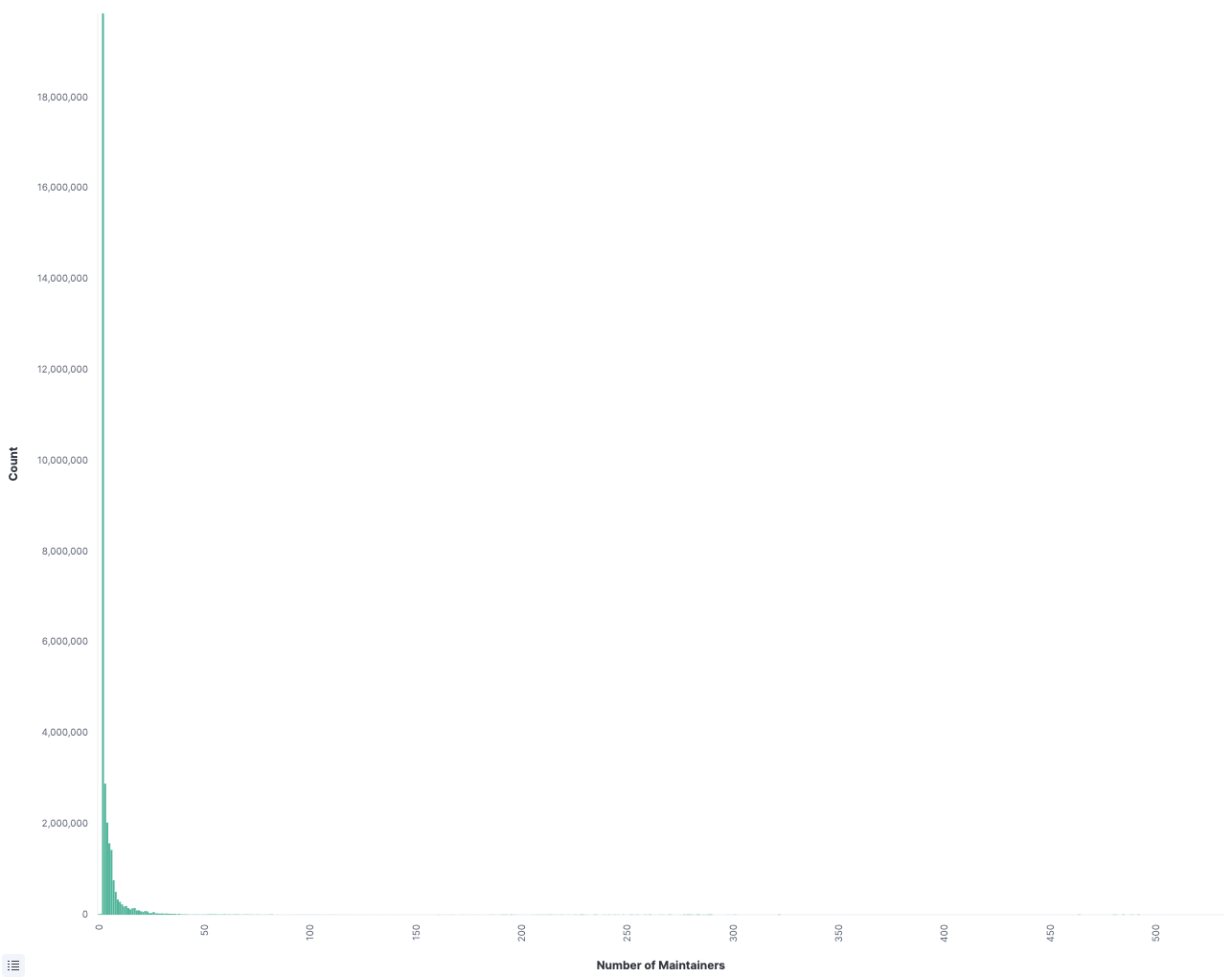
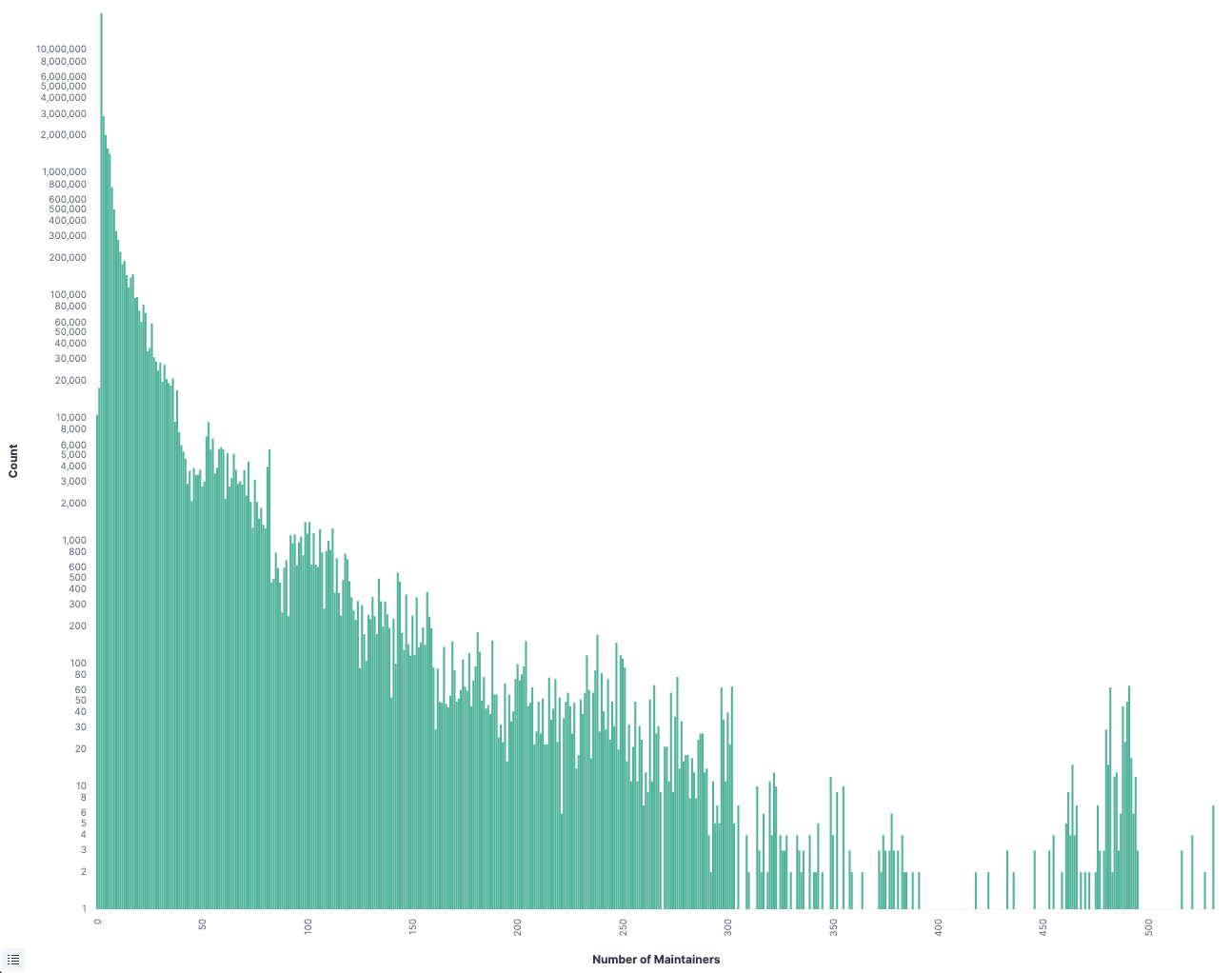
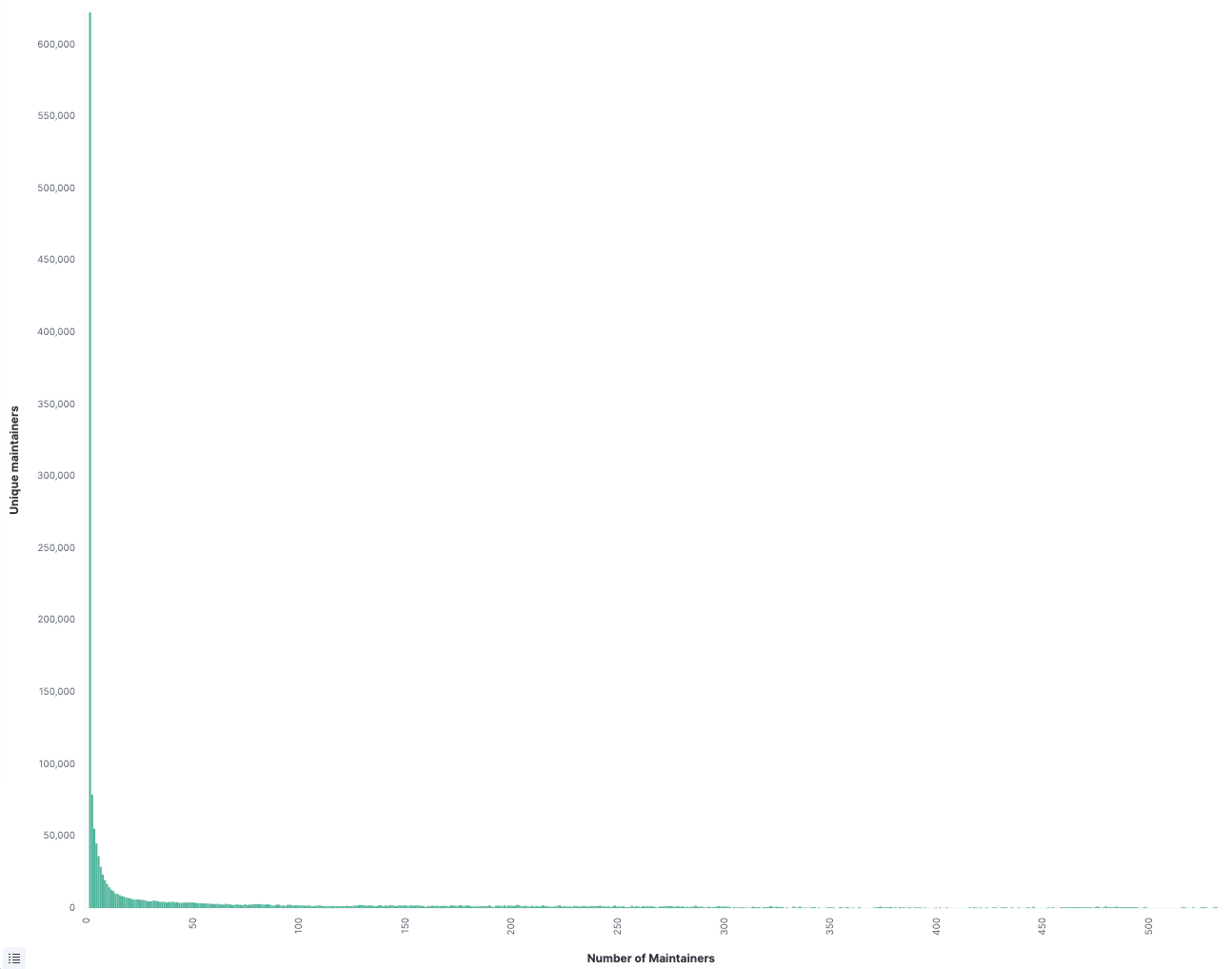
When I woke up the morning of September 8, I didn’t have the foggiest idea what the day had prepared for me. The most terrifying part of being a security person is the first few minutes of your day when you check the dashboards.
By mid-morning the now infamous blog post from Aikido Security about compromised NPM packages had found its way into Anchore’s Slack. My immediate response? Immediate panic, followed by relief when the scan of Anchore systems came back with the answer that we weren’t impacted.
We wanted to write this blog post to give the broader community a peek behind the curtains at what a zero-day vulnerability disclosure looks like from the perspective of the vendors who help customers protect their users from supply chain attacks. Spoiler: we’re just normal people making reasonable decisions while under pressure.
Let’s walk through what actually happened behind the scenes at Anchore.
The first ten minutes: actions > root cause
When I first read the Aikido post, I didn’t care about the technical details of how the attack happened or the fascinating social engineering tactics. I wanted one thing: the list of affected packages. Something actionable.
The list was originally buried at the bottom of their blog post, which meant those first few minutes involved a lot of scrolling and muttering. But once we had it, everything clicked into place. This is lesson number one when a zero-day disclosure hits: get to the actionable information as fast as possible. Skip the drama, find the indicators, and start checking.
Step one: are we affected?
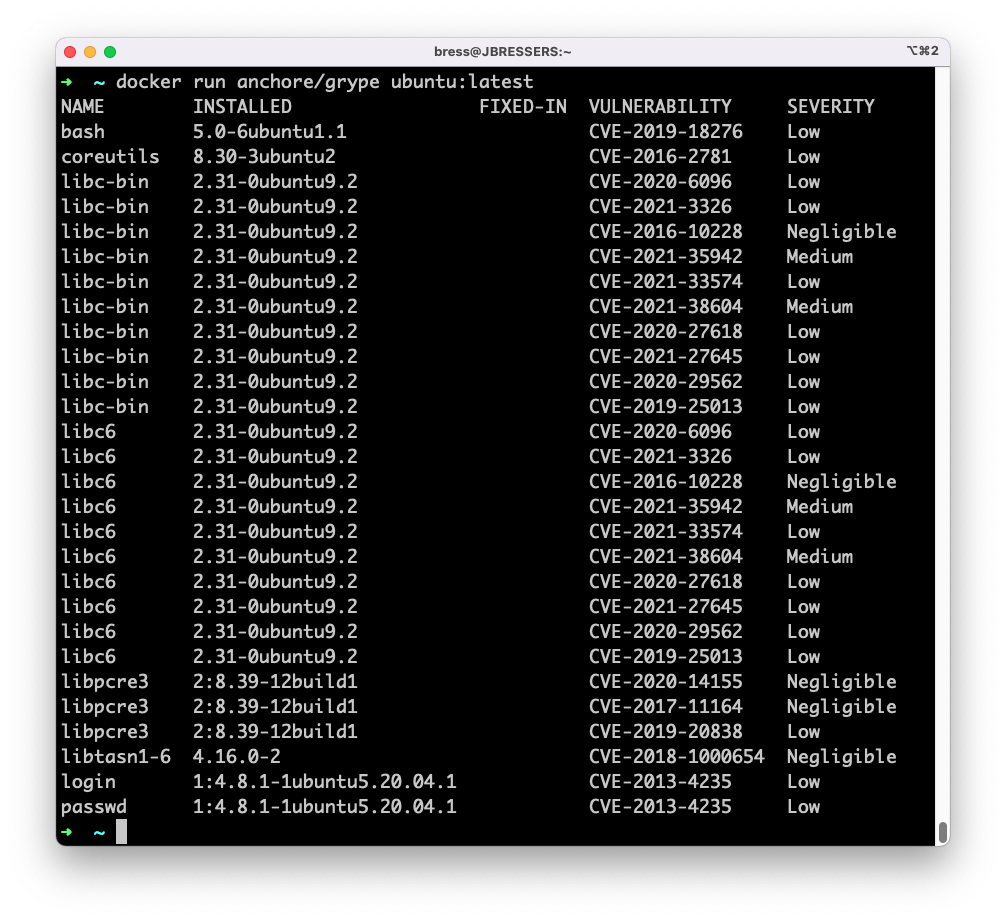
At Anchore, we dogfood our own products constantly (the Anchore Enterprise instance is literally named “dogfood”). On any given day, it’s somewhere between number two and three on my daily TODO list. On this day, I pulled up the latest build of Anchore Enterprise, and got to work.
First check: our latest releases. Our latest release was from the Friday before this all happened, so the timing meant the malicious packages couldn’t have made it into our most recent release. That’s good news, but it’s just the start.
Next check: the development versions of Anchore Enterprise. We pulled up our SBOMs and started looking. No malicious packages as direct dependencies—that’s a relief. But we did have some of the targeted packages as transitive dependencies! Luckily the packages we had inherited were not the malicious versions. Our dependency management had kept us safe, but we needed to verify this everywhere.
Then we checked with the UI team. Did anyone have these packages installed in their development environments? Did anything make it into CI? Nope, everything checked out.
GitHub Actions workflows were next. Sometimes we have opportunistic dependencies that get pulled during builds. Some of the packages were there, but not the vulnerable versions.
This whole process took maybe twenty minutes. Twenty minutes to check our current state across multiple products and teams. That’s only possible because we generate and store SBOMs for every build and create the tools to search through the growing inventory efficiently. We have stored SBOMs for every nightly and release of Anchore Enterprise. I can search them all very quickly.
Step two: the historical question
Now that we have confirmed that our infrastructure isn’t breached, the next question to answer is “has Anchore ever had any of these malicious packages?” Not just today, but at any point in our history. Granted the history was really just a few days in this instance, but you can imagine a situation like Log4Shell where there were years of history to wade through.
We have 1,571 containers in our build history. If we had to manually check each one, we’d still be working on it. But because we maintain a historical inventory of SBOMs in our database for all of our container builds, this became a simple query. A few seconds later: nothing found across our entire history.
These are the kinds of questions that keep me up at night during incidents: “Are we affected now?” is important, but “were we ever affected?” can be just as critical. Imagine discovering three months later that you shipped a compromised package to customers. The blast radius of that is enormous.
Having historical tracking isn’t fancy or sexy. It’s just good operational hygiene. And in moments like this, it means the difference between answering “I don’t know” and “we’re good.”
Step three: can we protect our customers?
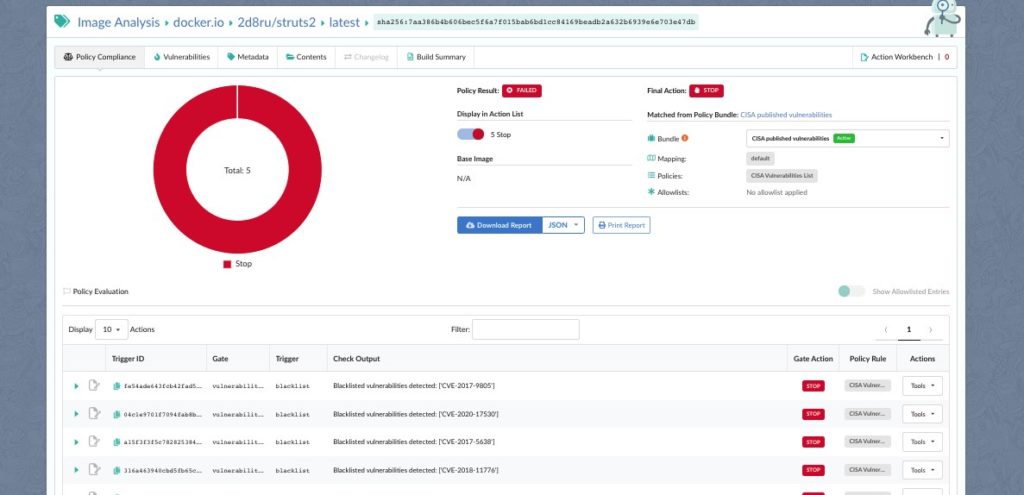
Okay, so Anchore is clean. Great. But we sell the security tools that automate this kind of incident response—our customers are depending on us to help them figure out if they’re affected and detect these malicious packages.
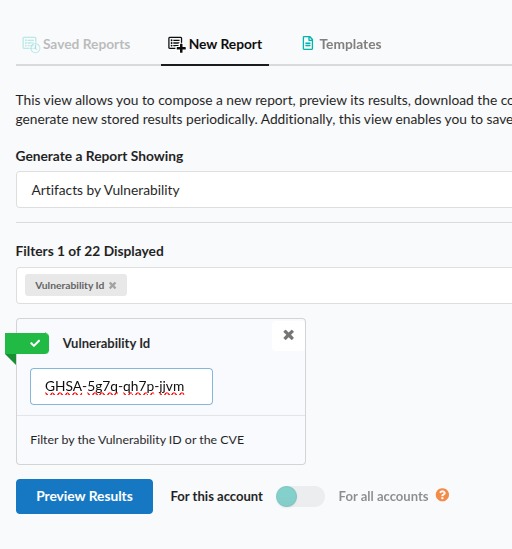
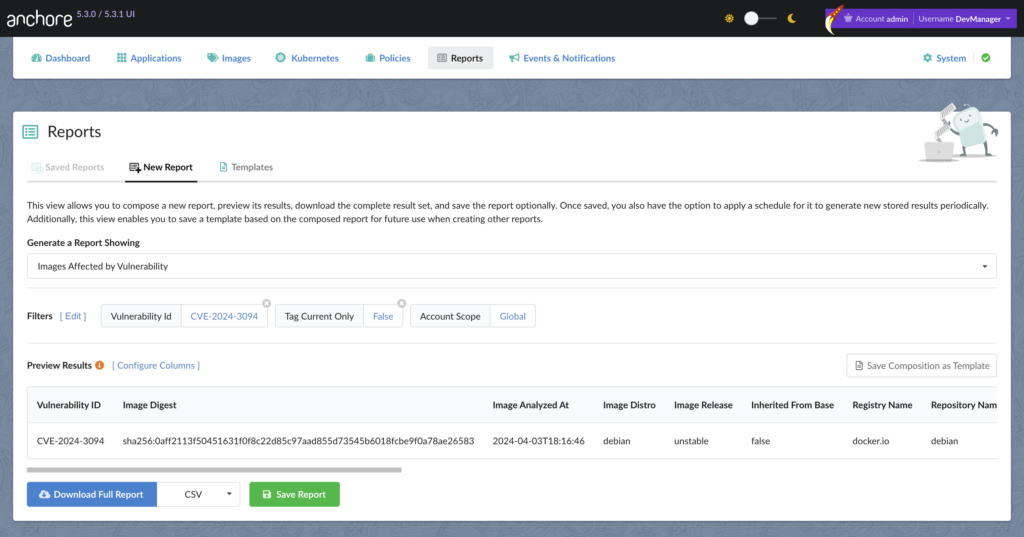
Early in the incident, the GitHub Advisory Database made an understandable but problematic decision: they set the affected versions of these packages to 0, which meant all versions would be flagged as vulnerable. This potentially created mass confusion for users who rely on the GHSA DB for vulnerability results. If anyone ran a vulnerability scan with this version of the GHSA DB their scanners would have lit up like Christmas trees, flagging packages that were known to be good.
In order to protect our customers from this panic inducing possibility we made the call: stop our vulnerability database build. We’d never tried to kill a build mid-process before, but this was one of those “figure it out as we go” moments. We stopped the build, then went to make pull requests to the GitHub Advisory Database to fix the version ranges.
By the time we got there, the GitHub team had already found the issue and a fix was in-flight. This is how the open source community works when everything is going right—multiple teams identifying the same problem and coordinating to fix it.
As soon as GitHub pushed their fix, we rebuilt our vulnerability database and messaged our customers. The goal was simple: make sure our customers had accurate information and could trust their scans. From detection to customer notification happened in hours, not days.
Why is GitHub in this story?
I want to make an important point about why the GitHub Vulnerability Database is an important part of this story. At Anchore, we have an open source vulnerability scanner called Grype. In order for Grype to work, we need vulnerability data that’s available to the public. Most vulnerability data companies don’t let you publish their data to the public, for free, for some reason.
GitHub is an important source of vulnerability data for both Anchore Enterprise and Grype. We have a number of vulnerability data sources and we do quite a lot of work on our own to polish up data without a robust source. Rather than pull in GitHub’s data and treat it like our own, we take the open source approach of working with our upstream. Anytime there are corrections needed in any of our upstream data, we go to the source with the fixes. This helps the entire community with accuracy of data. Open source only works when you get involved. So we are involved.
What actually matters during a zero-day
Looking back at this incident, a few lessons stand out about what actually matters when something like this hits:
Get to actionable information fast. The technical details are interesting for a blog post later, but when you’re responding, you need indicators. Package names. Version numbers. Hashes. Don’t get distracted by the story until you’ve handled the response.
Check yourself first, but don’t stop there. We needed to know if Anchore was affected, but we couldn’t stop at “we’re fine.” Our customers depend on us to help them figure out their exposure.
Historical tracking matters. Being able to answer “were we ever affected?” is just as important as “are we affected now?” If you don’t have historical SBOMs, you can’t answer that question with confidence.
Speed matters, but accuracy matters more. When the GitHub Advisory Database incorrectly flagged all versions, it could have created chaos. We could have pushed that bad data to customers quickly, but we stopped, verified, and waited for the fix. A fast response is important, but an accurate response is what actually helps.
Automation is your friend. Twenty minutes to check 1,571 historical containers? That only happens with automation. Manual verification would have taken days or weeks.
Here’s something that deserves more attention: NPM pulled the malicious packages in approximately six hours. Six hours from compromise to resolution. We only have to think back to 2021 when Log4j was disclosed and the industry was still responding to the incident weeks and even months later.
This wasn’t one company with a massive security team solving the problem. This was the open source community working together. Information was shared. Multiple organizations contributed. The response was faster than any single company could have managed, no matter how large their security team.
The attackers successfully phished more than one maintainer and bypassed 2FA (clearly not phishing-resistant 2FA, but that’s a conversation for another post). This was a sophisticated attack. And the community still went from compromised to clean in six hours.
That’s remarkable, and it’s only possible because the supply chain security ecosystem has matured significantly over the last few years.
How this compares to Log4Shell
This whole process reminded me of our response to Log4Shell in December 2021. We followed essentially the same playbook: check if we’re affected, verify our detection works, inform customers, help them respond.
During Log4Shell, we discovered Anchore had some instances of Log4j, but they weren’t exploitable. We created a test Java jar container (we called it “jarjar“) to verify our scanning could detect it. We helped customers scan their historical SBOMs to determine if and when Log4j appeared in their infrastructure, this provided their threat response teams with the information to bound their investigation and clearly define their risk.
But here’s the critical difference: Log4Shell response was measured in days and weeks. This NPM incident was measured in hours. The attack surface was arguably larger—these are extremely popular NPM packages with millions of weekly downloads. But the response time was dramatically faster.
That improvement represents years of investment in better tools, better processes, and better collaboration across the industry. It’s why Anchore has been building exactly these capabilities—historical SBOM tracking, rapid vulnerability detection, automated response workflows. Not for hypothetical scenarios, but for moments exactly like this.
What this means for you
This NPM incident is hopefully over for all of us (good luck if you’re still working on it). It’s probably worth thinking about what you can do for the next one. My advice would be to start keeping an inventory of your software if you’re not already. I’m partial to SBOMs of course. There will be more supply chain attacks in the future, they will need a quick response. The gap between “we checked everything in twenty minutes” and “we’re still trying to figure out what we have” represents real business risk. That gap is also entirely preventable.
Supply chain attacks aren’t theoretical. They’re happening regularly, they’re getting more sophisticated, and they will keep happening. The only question is whether you’re prepared to respond fast.
At Anchore, we built Syft and Grype specifically for these scenarios. Syft generates SBOMs that give you a complete inventory of your software. Grype scans for vulnerabilities. These are free, open source tools that anyone can use.
For organizations that need historical SBOM tracking, policy enforcement, and compliance reporting, Anchore Enterprise provides those capabilities. This isn’t a sales pitch—these are the actual tools we used during this incident to verify our own exposure and help our customers.
None of this is magic. It’s just normal people making normal decisions about how to prepare for predictable problems. Supply chain attacks are predictable. The question is whether you’ll be ready when the next one hits.
What’s next
Here’s what I expect: more supply chain attacks, more sophisticated techniques, and continued pressure on open source maintainers. But I also expect continued improvement in response times as the ecosystem matures.
Six hours from compromise to resolution is impressive, but I bet we can do better. As more organizations adopt SBOMs, vulnerability scanning, and historical tracking, the collective response will get even faster.
The question for your organization is simple: when the next incident happens—and it will—will you spend twenty minutes verifying you’re clean, or will you spend weeks trying to figure out what you have?
The best time to prepare for a supply chain attack was 10 years ago. The second best time is now.If you want to talk about how to actually implement this stuff—not in theory, but in practice—reach out to our team. Or join the conversation on our community Discourse where we talk about exactly these kinds of incidents and how to prepare for them.