The Department of Defense’s (DoD) Software Modernization Implementation Plan, unveiled in March 2023, represents a significant stride towards transforming software delivery timelines from years to days. This ambitious plan leverages the power of containers and modern DevSecOps practices within a DoD software factory.
Our latest white paper, titled “DevSecOps for a DoD Software Factory: 6 Best Practices for Container Images,” dives deep into the security practices for securing container images in a DoD software factory. It also details how Anchore Federal—a pivotal tool within this framework—supports these best practices to enhance security and compliance across multiple DoD software factories including the US Air Force’s Platform One, Iron Bank, and the US Navy’s Black Pearl.
Key Insights from the White Paper
Securing Container Images: The paper outlines six essential best practices ranging from using trusted base images to continuous vulnerability scanning and remediation. Each practice is backed by both DoD guidance and relevant NIST standards, ensuring alignment with federal requirements.
Role of Anchore Federal: As a proven tool in the arena of container image security, Anchore Federal facilitates these best practices by integrating seamlessly into DevSecOps workflows, providing continuous scanning, and enabling automated policy enforcement. It’s designed to meet the stringent security needs of DoD software factories, ready for deployment even in classified and air-gapped environments.
Supporting Rapid and Secure Software Delivery: With the DoD’s shift towards software factories, the need for robust, secure, and agile software delivery mechanisms has never been more critical. Anchore Federal is the turnkey solution for automating security processes and ensuring that all container images meet the DoD’s rigorous security and compliance requirements.
Download the White Paper Today
Empower your organization with the insights and tools needed for secure software delivery within the DoD ecosystem. Download our white paper now and take a significant step towards implementing best-in-class DevSecOps practices in your operations. Equip your teams with the knowledge and technology to not just meet, but exceed the modern security demands of the DoD’s software modernization efforts.
In November 2022, the US Department of Navy (DON) released the RAISE 2.0 Implementation Guide to support its Cyber Ready initiative, pivoting from a time-intensive compliance checklist and mindset to continuous cyber-readiness with real-time visibility. RAISE 2.0 embraces a “shift left” philosophy, performing security checks at all stages of the SDLC and ensuring security issues are found as early as possible when they are faster and easier to fix.
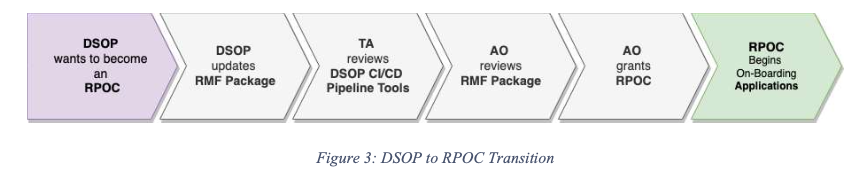
RAISE 2.0 provides a way to automate the Implement, Assess, and Monitor phases of the Risk Management Framework (RMF). New containerized applications can be developed using an existing DevSecOps platform (DSOP) that already has an Authorization to Operate (ATO) and meets the RAISE requirements. This eliminates the need for a new application to get its own separate ATO because it inherits the ATO of the DSOP.
There are three primary things you need to know about RAISE 2.0:
Who must follow RAISE 2.0?
RAISE 2.0 only applies to applications delivered via containers
RAISE 2.0 requires all teams starting or upgrading containerized software applications to use a pre-vetted DevSecOps platform called a RAISE Platform of Choice (RPOC)
What is an RPOC?
RPOC is a designation that a DevSecOps Platform (DSOP) receives after its inheritable security controls have received an ATO
A DSOP that wants to become an RPOC must follow the process outlined in the Implementation Guide
How does an RPOC accelerate ATO?
The containerized application will be assessed and incorporated into the existing RPOC ATO and is not required to have a separate ATO
What are the requirements of RAISE?
The RAISE 2.0 Implementation Guidelines outline the requirements for an RPOC. They represent best practices for DevSecOps platforms and incorporate processes and documentation required by the US government.
The guidelines also define the application owner’s ongoing responsibilities, which include overseeing the entire software development life cycle (SDLC) of the application running in the RPOC.
RPOC Requirements
The requirements for the RPOC include standard DevSecOps best practices and specifically call out tooling, such as:
CI/CD pipeline
Container Orchestrator
Container Repository
Code Repository
It also requires specific processes, such as:
Continuous Monitoring (ConMon)
Ongoing vulnerability scans
Ad-hoc vulnerability reporting and dashboard
Penetration testing
Ad-hoc auditing via a cybersecurity dashboard
If you’re looking for a comprehensive list of RPOC requirements, you can find them in the RAISE 2.0 Implementation Guide on the DON website.
Application Owner Requirements
Separate from the RPOC, the application owner that deploys their software via an RPOC has their own set of requirements. The application owner’s requirements are focused less on the DevSecOps tooling and more on the implementation of the tooling specific to their application. Important callouts are:
Maintain a Security Requirements Guide (SRG) and Security Technical Implementation Guide (STIG) for their application
Again, if looking for a comprehensive list of application owner requirements, you can find them in the RAISE 2.0 Implementation Guide on the DON website.
Anchore Federal integrates seamlessly with CI/CD pipelines and enables teams to meet essential RPOC requirements, including RPOC requirements 4, 5, 15, 19, 20, and 24. The reporting capabilities also assist in the Quarterly Reviews, fulfilling QREV requirements 6 and 7. Finally it helps application owners to meet requirements APPO 7, 8, 9, and 10.
Continuous container monitoring in production
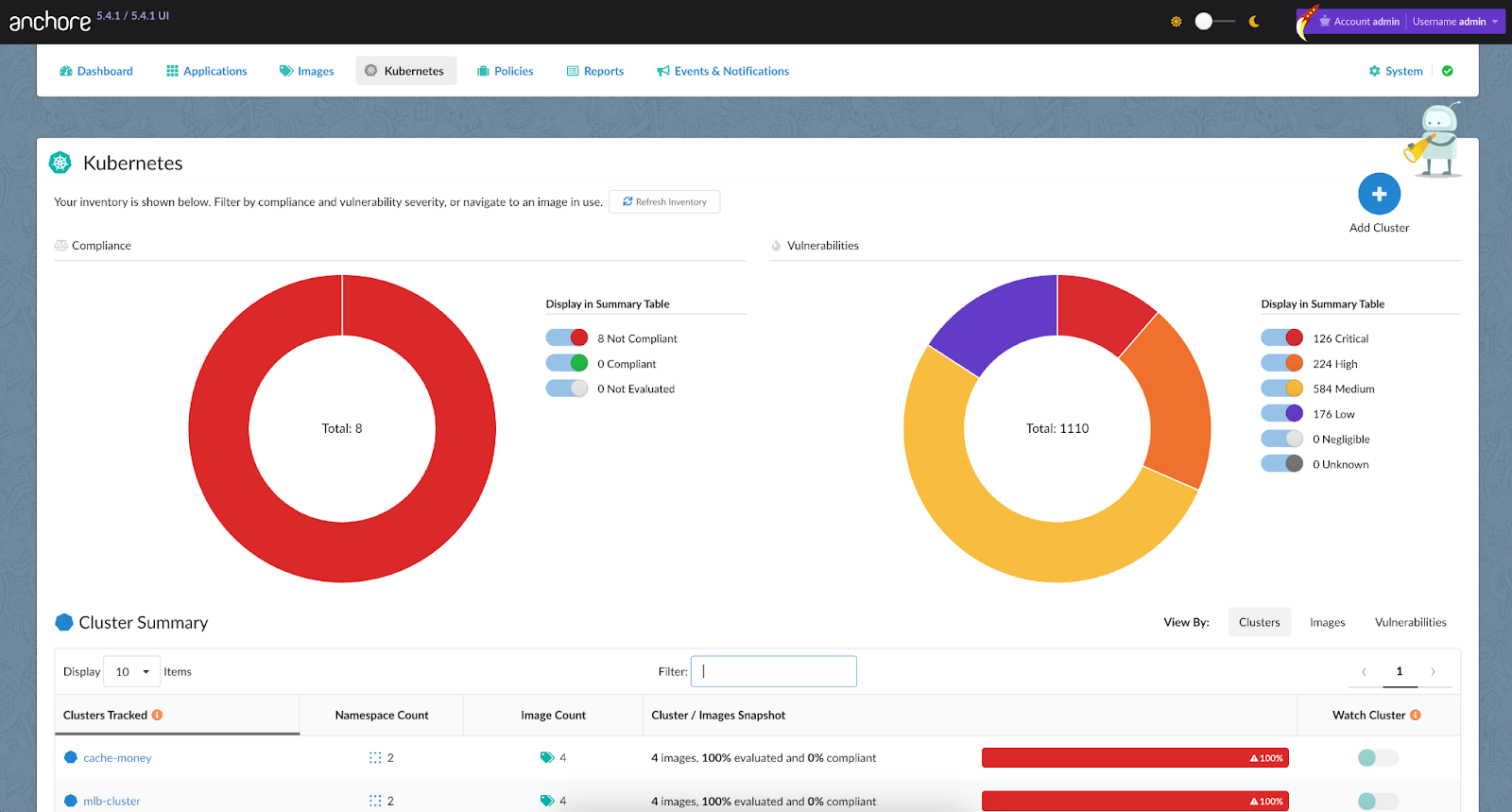
Anchore Federal includes the anchore-k8s-inventory tool, which continuously monitors selected Kubernetes clusters and namespaces and identifies the container images running in production. This automated tool that integrates directly with any standard Kubernetes distribution allows RPOCs to meet “RPOC 4: Must support continuous monitoring”.
The Anchore Federal UI provides dashboards summarizing vulnerabilities and your compliance posture across all your clusters. You can drill down into the details for an individual cluster or namespace and filter the dashboard. For example, selecting only high and critical vulnerabilities will only show the clusters and namespaces with those vulnerabilities.
If a zero-day or new vulnerability arises, you can easily see the impacted clusters and containers to assess the blast radius.
Security gates that directly integrate into CI/CD pipeline
Anchore Federal automates required security gates for RPOCs and application owners (i.e., “RPOC 5: Must support the execution of Security Gates” and “APPO 9: Application(s) deployments must successfully pass through all Security Gates”). It integrates seamlessly into the CI/CD pipeline and the container registry, automatically generates SBOMs, and scans containers for vulnerabilities and secrets/keys (Gates 2, 3, and 4 in the RAISE 2.0 Implementation Guide).
Anchore’s security gating feature is backed by a flexible policy engine that allows both RPOCs and application owners to collaborate on the security gates that need to be passed for any container going through a CI/CD pipeline and customized gates specific to the application. The Anchore Policy Engine accelerates the move to RAISE 2.0 by offering pre-configured policy packs, including NIST SP 800-53, and extensive docs for building custom policies. It is already used by DevSecOps platforms across the DON, including Black Pearl, Party Barge, and Lighthouse installations, and is ready to deploy in classified and air-gapped environments, including IL4 and IL6.
Production container inventory
On top of continuously monitoring production for vulnerabilities in containers, the anchore-k8s-inventory tool can be utilized to create an inventory of all containers in production which can then be queried by the container registry in order to meet “RPOC 15: Must retain every image that is currently deployed”. This easily automates this requirement and keeps DON programs compliant with no additional manual work.
Single-pane-of-glass security dashboard
Anchore Federal maintains a complete repository of SBOMs, vulnerabilities, and policy evaluations. Dashboards and reports provide auditability that containers have met the necessary security gates to meet “RPOC 20: Must ensure that the CI/CD pipeline meets security gates”.
Customizable vulnerability reporting and comprehensive dashboard
Anchore Federal comes equipped with a customizable report builder for regular vulnerability reporting and a vulnerability dashboard for ad hoc reviews. This ensures that RPOCs and application owners meet the “RPOC 24: Must provide vulnerability reports and/or vulnerability dashboards for Application Owner review” requirement.
Aggregated vulnerability reporting
Not only can Anchore Federal generate application specific reporting, it can provide aggregated reporting for vulnerabilities for all applications and containers on the RPOC. This is vital functionality for meeting the “QREV 6: Consolidated vulnerabilities report of all applications deployed, via the RAISE process” requirement.
Generate and store security artifacts
Anchore Federal both generates and stores security artifacts from the entire CI/CD pipeline. This meets the software supply chain security requirements of “QREV 7: Application Deployment Artifacts”. Specifically this includes, SBOMs (i.e., dependency reports), container security scans, SRG/STIG scans.
Anchore Federal produces a number of the required reports, including STIG results, container security scan reports, and SBOMs, along with pass/fail reports of policy controls.
Remediation recommendations and automated allowlists
RAISE 2.0 requires that Application Owners remediate or mitigate all vulnerabilities with a severity of high or above within 21 calendar days. Anchore Federal helps speed remediation efforts to meet the 21-day deadline. It suggests recommended fixes and includes an Action Workbench where security reviewers can specify an Action Plan detailing what developers should do to remediate each vulnerability.
Anchore Federal also provides time-based allowlists to enforce the 21-day timeline. With the assistance of remediation recommendations and automated allowlists, application owners knows that their applications are always in compliance with “APPO 7: Must review and remediate, or mitigate, all findings listed in the vulnerabilities report per the timelines defined within this guide”.
Automate STIG checks in CI/CD pipeline
The RPOC ISSM and the Application Owner must work together to determine what SRGs and STIGs to implement. Anchore’s Static STIG Checker tool automates STIG checks on Kubernetes environments and then uploads the results to Anchore Federal through a compliance API. That allows users to leverage additional functionality like reporting and correlating the runtime environment to images that have been analyzed.
This automated workflow specifically addresses the “APPO 10: Must provide and continuously maintain a complete Security Requirements Guide (SRG) and Security Technical Implementation Guide (STIG)” requirement.
Getting to RAISE 2.0 with Anchore Federal
Anchore Federal is a complete software supply chain security solution that gets RPOCs and application owners to RAISE 2.0 faster and easier. It is already proven in many Navy programs and across the DoD. With Anchore Federal you can:
Automate RAISE requirements
Meet required security gates
Generate recurring reports
Integrate with existing DSOPs
Anchore Federal was designed specifically to automate compliance with Federal and Department of Defense (DoD) compliance standards (e.g., RAISE, cATO, NIST SSDF, NIST 800-53, etc.) for application owners and DSOPs that would rather utilize a turnkey solution to software supply chain security rather than DIY a solution. The easiest way to achieve RAISE 2.0 is by adopting a DoD software factory which is the general version of the Navy’s RPOC.
If you’re interested to learn more about how Anchore can help your organization embed DevSecOps tooling and principles into your software development process, click below to read our white paper.
The clock is ticking again for software producers selling to federal agencies. In the second half of 2024, CEOs or their designees must begin providing an SSDF attestation that their organization adheres to secure software development practices documented in NIST SSDF 800-218.
Maintaining provenance (e.g., via SBOMs) for internal code and third-party components, and
Using automated tools to check for security vulnerabilities.
This new requirement is not to be taken lightly. It applies to all software producers, regardless of whether they provide a software end product as SaaS or on-prem, to any federal agency. The SSDF attestation deadline is June 11, 2024, for critical software and September 11, 2024, for all software. However, on-prem software developed before September 14, 2022, will only require SSDF attestation when a new major version is released. The bottom line is that most organizations will need to comply by 2024.
Companies will make their SSDF attestation through an online Common Form that covers the minimum secure software development requirements that software producers must meet. Individual agencies can add agency-specific instructions outside of the Common Form.
Organizations that want to ensure they meet all relevant requirements can submit a third-party assessment instead of a CEO attestation. You must use a Third-Party Assessment Organization (3PAO) that is FedRAMP-certified or approved by an agency official. This option is a no-brainer for cloud software producers who use a 3PAO for FedRAMP.
Details over details – so we put together a practical guide to the SSDF attestation requirements and how to meet them “SSDF Attestation 101: A Practical Guide for Software Producers”. We also included how Anchore Enterprise automates the SSDF attestation compliance by directly integrating into your software development pipeline and utilizing continuous policy scanning to detect issues before they hit production.
Today, we are announcing the release of Anchore Enterprise 5.5, the fifth in our regular minor monthly releases. There are a number of improvements to GUI performance, multi-tenancy support and AnchoreCTL but with the uncertainty at NVD continuing, the main news is updates to our feed drivers which help customers adapt to the current situation at NIST.
The NIST NVD interruption and backlog
A few weeks ago, Anchore alerted the security community to the changes at the National Vulnerability Database (NVD) run by the US National Institute of Standards and Technology (NIST). As of February 18th, there was a massive decline in the number of records published with metadata such as severity and CVSS records. Less publicized but no less problematic has been that the service availability of the API that enables access to NVD records has also been erratic during the same period.
While the uncertainty around NVD continues and recognizing that it continues to be a federally mandated data source (e.g., within FedRAMP), Anchore has updated its drivers to give customers flexibility in how they interact with its data.
In a typical Anchore Enterprise deployment, NVD data has served two functions. The first is a catalog of CVEs that can be correlated with advisories from other vendors to help provide more context around an issue. The second is as a matching source of last resort for surfacing vulnerabilities where no other vulnerability data exists. This often comes with a caveat that the expansiveness of the NVD database means there is variable data quality which can lead to false positives.
See it in action!
To see the latest features in action, please join our webinar “Adapting to the new normal at NVD with Anchore Vulnerability Feed” on May 7th at 10am PT/1pm EST. Register Now.
Improvements to the Anchore Vulnerability Feed Service
The Exclusion feed
Anchore released its own Vulnerability Feed with v4.1 which provided an ‘Exclusion Feed’ to avoid NVD false positives by preventing matches against vulnerability records that were known to be inaccurate.
As of v5.5, we have extended the Anchore Vulnerability Feed service to provide two additional data features.
Simplify network management with 3rd party vulnerability feed
The first is the ability to download a copy of 3rd party vulnerability feed data sets, including NVD, directly from Anchore, so that transient service availability issues don’t generate alerts. This simplifies network management by only requiring one firewall rule to be created to enable the retrieval of any vulnerability data for use with Anchore Enterprise. This proxy-mode is the default in 5.5 for the majority of feeds but customers who want to continue to benefit from autonomous operations that don’t rely on Anchore and contact NVD and other vendor endpoints directly can continue to use the direct-mode as before.
Enriched data
The second change is that Anchore is continuing to add new CVE records from the NVD database that customers use while providing Enriched Data to the records, specifically for CPE information which helps map affected versions. While Anchore can’t provide NVD severity or CVSS records, which by definition have to be provided by NVD themselves, these records and metadata will continue to allow customers to reference CVEs. This data is available by default in the proxy-mode mentioned above or as a configuration option with the Direct Mode.
How it works
For the 3rd party vulnerability data, Anchore is running the same feed service software that customers would run in their local site which periodically retrieves the data from all of its available sources and structures the data into a format ready to be downloaded by customers. Using the existing feed drivers in their local feed service (NVD, GitHub, etc) customers download the entire database in one atomic operation. This contrasts with the API based approach in the direct-mode which means that individual records are retrieved one at a time which can take time. This can be enabled on a driver-by-driver basis.
For the enriched data, Anchore is running a service which looks for new CVE records from other upstream sources, for example the CVE5 database hosted by MITRE and custom data added by Anchore engineers. The database tables that host the NVD records are then populated with these CVE updates. CPE data is sourced from vendor records (e.g., Red Hat Security Advisories) and added to the NVD records to enable matching logic.
Looking forward
Throughout the year, we will be looking to make additional improvements to the Anchore Vulnerability Feed to help customers not just navigate through the uncertainty at NVD but reduce their false positive and false negative count in general.
See it in action!
Join our webinar Adapting to the new normal at NVD with Anchore Vulnerability Feed. May 7th at 10am PT/1pm EST
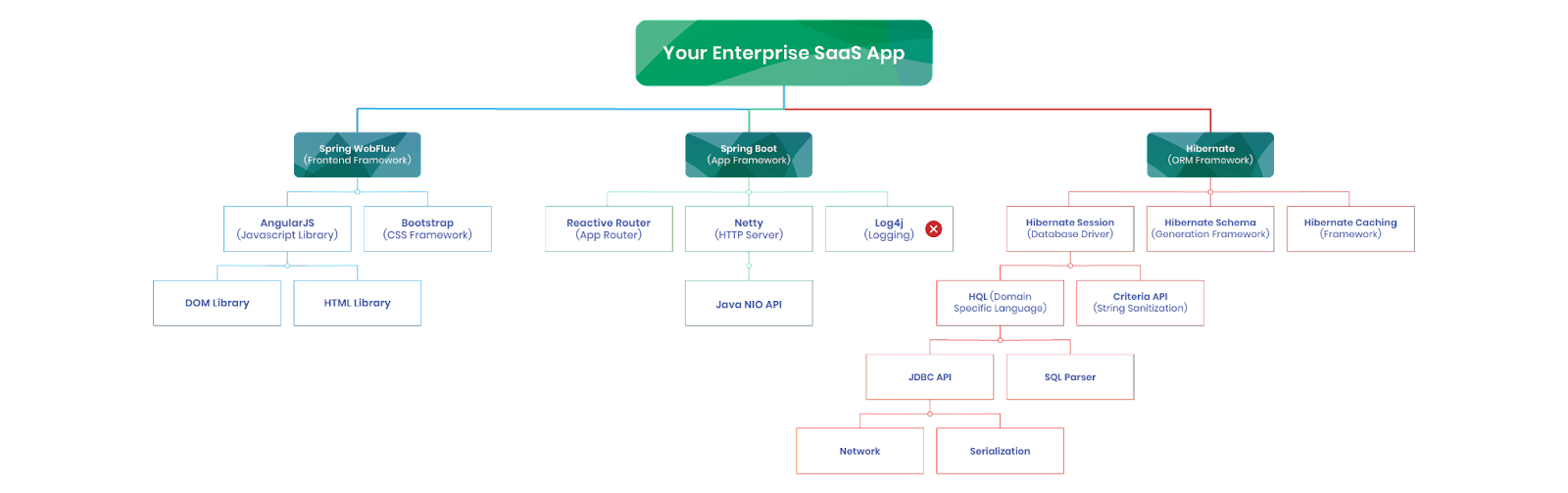
Modern software development is complex to say the least. Vulnerabilities often lurk within the vast networks of dependencies that underpin applications. A typical scenario involves a simple app.go source file that is underpinned by a sprawling tree of external libraries and frameworks (check the go.mod file for the receipts). As developers incorporate these dependencies into their applications, the security risks escalate, often surpassing the complexity of the original source code. This real-world challenge highlights a critical concern: the hidden vulnerabilities that are magnified by the dependencies themselves, making the task of securing software increasingly daunting.
Addressing this challenge requires reimagining software supply chain security through a different lens. In a recent webinar with the famed Kelsey Hightower, he provides an apt analogy to help bring the sometimes opaque world of security into focus for a developer. Software security can be thought of as just another test in the software testing suite. And the system that manages the tests and the associated metadata is a data pipeline. We’ll be exploring this analogy in more depth in this blog post and by the end we will have created a bridge between developers and security.
The Problem: Modern software is built on a tower
Modern software is built from a tower of libraries and dependencies that increase the productivity of developers but with these boosts comes the risks of increased complexity. Below is a simple ‘ping-pong’ (i.e., request-response) application written in Go that imports a single HTTP web framework:
With this single framework comes a laundry list of dependencies that are needed in order to work. This is the go.mod file that accompanies the application:
The dependencies for the application end up being larger than the application source code. And in each of these dependencies is the potential for a vulnerability that could be exploited by a determined adversary. Kelsey Hightower summed this up well, “this is software security in the real world”. Below is an example of a Java app that hides vulnerabile dependencies inside the frameworks that the application is built off of.
As much as we might want to put the genie back in the bottle, the productivity boosts of building on top of frameworks are too good to reverse this trend. Instead we have to look for different ways to manage security in this more complex world of software development.
If you’re looking for a solution to the complexity of modern software vulnerability management, be sure to take a look at the Anchore Enterprise platform and the included container vulnerability scanner.
The Solution: Modeling software supply chain security as a data pipeline
Software supply chain security is a meta problem of software development. The solution to most meta problems in software development is data pipeline management.
Developers have learned this lesson before when they first build an application and something goes wrong. In order to solve the problem they have to create a log of the error. This is a great solution until you’ve written your first hundred logging statements. Suddenly your solution has become its own problem and a developer becomes buried under a mountain of logging data. This is where a logging (read: data) pipeline steps in. The pipeline manages the mountain of log data and helps developers sift the signal from the noise.
The same pattern emerges in software supply chain security. From the first run of a vulnerability scanner on almost any modern software, a developer will find themselves buried under a mountain of security metadata.
$ grype dir:~/webinar-demo/examples/app:v2.0.0 ✔ Vulnerability DB [no update available] ✔ Indexed file system ~/webinar-demo/examples/app:v2.0.0 ✔ Cataloged contents 889d95358bbb68b88fb72e07ba33267b314b6da8c6be84d164d2ed425c80b9c3 ├── ✔ Packages [16 packages] └── ✔ Executables [0 executables] ✔ Scanned for vulnerabilities [11 vulnerability matches] ├── by severity: 1 critical, 5 high, 5 medium, 0 low, 0 negligible └── by status: 11 fixed, 0 not-fixed, 0 ignored NAME INSTALLED FIXED-IN TYPE VULNERABILITY SEVERITY github.com/gin-gonic/gin v1.7.2 1.7.7 go-module GHSA-h395-qcrw-5vmq High github.com/gin-gonic/gin v1.7.2 1.9.0 go-module GHSA-3vp4-m3rf-835h Medium github.com/gin-gonic/gin v1.7.2 1.9.1 go-module GHSA-2c4m-59x9-fr2g Medium golang.org/x/crypto v0.0.0-20200622213623-75b288015ac9 0.0.0-20211202192323-5770296d904e go-module GHSA-gwc9-m7rh-j2ww High golang.org/x/crypto v0.0.0-20200622213623-75b288015ac9 0.0.0-20220314234659-1baeb1ce4c0b go-module GHSA-8c26-wmh5-6g9v High golang.org/x/crypto v0.0.0-20200622213623-75b288015ac9 0.0.0-20201216223049-8b5274cf687f go-module GHSA-3vm4-22fp-5rfm High golang.org/x/crypto v0.0.0-20200622213623-75b288015ac9 0.17.0 go-module GHSA-45x7-px36-x8w8 Medium golang.org/x/sys v0.0.0-20200116001909-b77594299b42 0.0.0-20220412211240-33da011f77ad go-module GHSA-p782-xgp4-8hr8 Medium log4j-core 2.15.0 2.16.0 java-archive GHSA-7rjr-3q55-vv33 Critical log4j-core 2.15.0 2.17.0 java-archive GHSA-p6xc-xr62-6r2g High log4j-core 2.15.0 2.17.1 java-archive GHSA-8489-44mv-ggj8 Medium
All of this from a single innocuous include statements to your favorite application framework.
Again the data pipeline comes to the rescue and helps manage the flood of security metadata. In this blog post we’ll step through the major functions of a data pipeline customized for solving the problem of software supply chain security.
Modeling SBOMs and vulnerability scans as unit tests
I like to think of security tools as just another test. A unit test might test the behavior of my code. I think this falls in the same quality bucket as linters to make sure you are following your company’s style guide. This is a way to make sure you are following your company’s security guide.
Kelsey Hightower
This idea from renowned developer, Kelsey Hightower is apt, particularly for software supply chain security. Tests are a mental model that developers utilize on a daily basis. Security tooling are functions that are run against your application in order to produce security data about your application rather than behavioral information like a unit test. The first two foundational functions of software supply chain security are being able to identify all of the software dependencies and to scan the dependencies for known existing vulnerabilities (i.e., ‘testing’ for vulnerabilities in an application).
This is typically accomplished by running an SBOM generation tool like Syft to create an inventory of all dependencies followed by running a vulnerability scanner like Grype to compare the inventory of software components in the SBOM against a database of vulnerabilities. Going back to the data pipeline model, the SBOM and vulnerability database are the data sources and the vulnerability report is the transformed security metadata that will feed the rest of the pipeline.
This was previously done just prior to pushing an application to production as a release gate that would need to be passed before software could be shipped. As unit tests have moved forward in the software development lifecycle as DevOps principles have won the mindshare of the industry, so has security testing “shifted left” in the development cycle. With self-contained, open source CLI tooling like Syft and Grype, developers can now incorporate security testing into their development environment and test for vulnerabilities before even pushing a commit to a continuous integration (CI) server.
From a security perspective this is a huge win. Security vulnerabilities are caught earlier in the development process and fixed before they come up against a delivery due date. But with all of this new data being created, the problem of data overload has led to a different set of problems.
Vulnerability overload; Uncovering the signal in the noise
Like the world of application logs that came before it, at some point there is so much information that an automated process generates that finding the signal in the noise becomes its own problem.
How Anchore Enterprise manages SBOMs and vulnerability scans
Centralized management of SBOMs and vulnerability scans can end up being a massive headache. No need to come up with your own storage and data management solution. Just configure the AnchoreCTL CLI tool to automatically submit SBOMs and vulnerability scans as you run them locally. Anchore Enterprise stores all of this data for you.
On top of this, Anchore Enterprise offers data analysis tools so that you can search and filter SBOMs and vulnerability scans by version, build stage, vulnerability type, etc.
Combining local developer tooling with centralized data management creates a best of both worlds environment where engineers can still get their tasks done locally with ease but offload the arduous management tasks to a server.
Added benefit, SBOM drift detection
Another benefit of distributed SBOM generation and vulnerability scanning is that this security check can be run at each stage of the build process. It would be ideal to believe that the software that is written on in a developers local environment always makes it through to production in an untouched, pristine state but this is rarely the case.
Running SBOM generation and vulnerability scanning at development, on the build server, in the artifact registry, at deploy and during runtime will create a full picture of where and when software is modified in the development process and simplify post-incident investigations or even better catch issues well before they make it to a production environment.
This historical record is a feature provided by Anchore Enterprise called Drift Detection. In the same way that an HTTP cookie creates state between individual HTTP requests, Drift detection is security metadata about security metadata (recursion, much?) that allows state to be created between each stage of the build pipeline. Being the central store for all of the associated security metadata makes the Anchore Enterprise platform the ideal location to aggregate and scan for these particular anomalies.
Policy as a lever
Being able to filter through all of the noise created by integrating security checks across the software development process creates massive leverage when searching for a particular issue but it is still a manual process and being a full-time investigator isn’t part of the software engineer job description. Wouldn’t it be great if we could automate some if not the majority of these investigations?
I’m glad we’re of like minds because this is where policy comes into picture. Returning to Kelsey Hightower’s original comparison between security tools as linters, policy is the security guide that is codified by your security team that will allow you to quickly check whether the commit that you put together will meet the standards for secure software.
By running these checks and automating the feedback, developers can quickly receive feedback on any potential security issues discovered in their commit. This allows developers to polish their code before it is flagged by the security check in the CI server and potentially failed. No more waiting on the security team to review your commit before it can proceed to the next stage. Developers are empowered to solve the security risks and feel confident that their code won’t be held up downstream.
Anchore Enterprise designed its policy engine to ingest the individual policies as JSON objects that can be integrated directly into the existing software development tooling. Create a policy in the UI or CLI, generate the JSON and commit it directly to the repo.
This prevents the painful context switching of moving between different interfaces for developers and allows engineering and security teams to easily reap the rewards of version control and rollbacks that come pre-baked into tools like version control. Anchore Enterprise was designed by engineers for engineers which made policy-as-code the obvious choice when designing the platform.
Remediation automation integrated into the development workflow
Being able to be alerted when a commit is violating your company’s security guidelines is better than pushing insecure code and waiting for the breach to find out that you forgot to sanitize the user input. Even after you get alerted to a problem, you still need to understand what is insecure and how to fix it. This can be done by trying to Google the issue or starting up a conversation with your security team. But this just ends up creating more work for you before you can get your commit into the build pipeline. What if you could get the answer to how to fix your commit in order to make it secure directly into your normal workflow?
Anchore Enterprise provides remediation recommendations to help create actionable advice on how to resolve security alerts that are flagged by a policy. This helps point developers in the right direction so that they can resolve their vulnerabilities quickly and easily without the manual back and forth of opening a ticket with the security team or Googling aimlessly to find the correct solution. The recommendations can be integrated directly into GitHub Issues or Jira tickets in order to blend seamlessly into the workflows that teams depend on to coordinate work across the organization.
Wrap-Up
From the perspective of a developer it can sometimes feel like the security team is primarily a frustration that only slows down your ability to ship code. Anchore has internalized this feedback and has built a platform that allows developers to still move at DevOps speeds and do so while producing high quality, secure code. By integrating directly into developer workflows (e.g., CLI tooling, CI/CD integrations, source code repository integrations, etc.) and providing actionable feedback Anchore Enterprise removes the traditional roadblock mentality that has typically described the relationship between development and security.
If you’re interested to see all of the features described in this blog post via a hands-on demo, check out the webinar by clicking on the screenshot below and going to the workshop hosted on GitHub.
If you’re looking to go further in-depth with how to build and secure containers in the software supply chain, be sure to read our white paper: The Fundamentals of Container Security.
FedRAMP compliance is hard, not only because there are hundreds of controls that need to be reviewed and verified. On top of this, the controls can be interpreted and satisfied in multiple different ways. It is admirable to see an enterprise achieve FedRAMP compliance from scratch but most of us want to achieve compliance without spending more than a year debating the interpretation of specific controls. This is where turnkey solutions like Anchore Enterprise come in.
Overview of FedRAMP, who it applies to and the challenges of compliance
FedRAMP, or the Federal Risk and Authorization Management Program, is a federal compliance program that standardizes security assessment, authorization, and continuous monitoring for cloud products and services. As with any compliance standard, FedRAMP is modeled from the “Trust but Verify” security principle. FedRAMP standardizes how security is verified for Cloud Service Providers (CSP).
One of the biggest challenges with achieving FedRAMP compliance comes from sorting through the vast volumes of data that make up the standard. Depending on the level of FedRAMP compliance you are attempting to meet, this could mean complying with 125 controls in the case of a FedRAMP low certification or up to 425 for FedRAMP high compliance.
While we aren’t going to go through the entire FedRAMP standard in this blog post, we will be focusing on the container security controls that are interleaved into FedRAMP.
FedRAMP container security requirements
1) Hardened Images
FedRAMP requires CSPs to adhere to strict security standards for hardened images used by government agencies. The standard mandates that:
Only essential services and software are included in the images
2) Container Build, Test, and Orchestration Pipelines
FedRAMP sets stringent requirements for container build, test, and orchestration pipelines to protect federal agencies. These include:
Hardened base images (see above)
Automated build processes with integrity checks
Strict configuration management
Immutable containers
Secure artifact management
Containers security testing
Comprehensive logging and monitoring
3) Vulnerability Scanning for Container Images
FedRAMP mandates rigorous vulnerability scanning protocols for container images to ensure their security within federal cloud deployments. This includes:
Comprehensive scans integrated into CI/CD pipelines
Prioritize remediation based on severity
Re-scanning policy post-remediation
Detailed audit and compliance reports
Checks against secure baselines (i.e., CIS or STIG)
4) Secure Sensors
FedRAMP requires continuous management of the security of machines, applications, and systems by identifying vulnerabilities.
Authorized scanning tools
Authenticated security scans to simulate threats
Reporting and remediation
Scanning independent of developers
Direct integration with configuration management to track vulnerabilities
5) Registry Monitoring
While not explicitly called out in FedRAMP as either a control or a control family, there is still a requirement that the images stored in a container registry are scanned at least every 30-days if the images are deployed to production.
6) Asset Management and Inventory Reporting for Deployed Containers
FedRAMP mandates thorough asset management and inventory reporting for deployed containers to ensure security and compliance. Organizations must maintain detailed inventories including:
Container images
Source code
Versions
Configurations
Continuous monitoring of container state
7) Encryption
FedRAMP mandates robust encryption standards to secure federal information, requiring the use of NIST-approved cryptographic methods for both data at rest and data in transit. It is important that any containers that store data or move data through the system meet FIPS standards.
How Anchore helps organizations comply with these requirements
Anchore is the leading software supply chain security platform for meeting FedRAMP compliance. We have helped hundreds of organizations meet FedRAMP compliance by deploying Anchore Enterprise as the solution for achieving container security compliance. Below you can see an overview of how Anchore Enterprise integrates into a FedRAMP compliant environment. For more details on how each of these integrations meet FedRAMP compliance keep reading.
1) Hardened Images
Anchore Enterprise integrates multiple tools in order to meet the FedRAMP requirements for hardened container images. We provide compliance policies that scan specifically for compliance with container hardening standards, such as, STIG and CIS. These tools were custom built to perform the checks necessary to meet the two relevant standards or both!
2) Container Build, Test, and Orchestration Pipelines
Anchore integrates directly into your CI/CD pipelines either the Anchore Enterprise API or pre-built plug-ins. This tight integration meets the FedRAMP standards that require all container images are hardened, all security checks are automated within the build process and all actions are logged and audited. Anchore’s FedRAMP policy specifically checks to make sure that any container in any stage of the pipeline will be checked for compliance.
Anchore Enterprise can be integrated into each stage of the development pipeline, offer remediation recommendations based on severity (e.g., CISA’s KEV vulnerabilities can be flagged and prioritized for immediate action), enforce re-scanning of containers after remediation and produce compliance artifacts to automate compliance. This is accomplished with Anchore’s container scanner, direction pipeline integration and FedRAMP policy.
4) Secure Sensors
Anchore Enterprise’s container vulnerability scanner and Kubernetes inventory agent are both authorized scanning tools. The container vulnerability scanner is integrated directly into the build pipeline whereas the k8s agent is run in production and scans for non-compliant containers at runtime.
6) Asset Management and Inventory Reporting for Deployed Containers
Anchore Enterprise includes a full software component inventory workflow. It can scan all software components, generate Software Bill of Materials (SBOMs) to keep track of the component and centrally store all SBOMs for analysis. Anchore Enterprises’s Kubernetes inventory agent can perform the same service for the runtime environment.
7) Encryption
Anchore Enterprise Static STIG tool can ensure that all containers are maintaining NIST & FIPS encryption standards. Verifying that containers are encrypting data at-rest and in-transit for each of thousands of containers is a difficult chore but easily automated via Anchore Enterprise.
The benefits of the shift left approach of Anchore Enterprise
Shift compliance left and prevent violations
Detect and remediate FedRAMP compliance violations early in the development lifecycle to prevent production/high-side violations that will threaten your hard earned compliance. Use Anchore’s “developer-bundle” in the integration phase to take immediate action on potential compliance violations. This will ensure vulnerabilities with fixes available and CISA KEV vulnerabilities are addressed before they make it to the registry and you have to report these non-compliance issues.
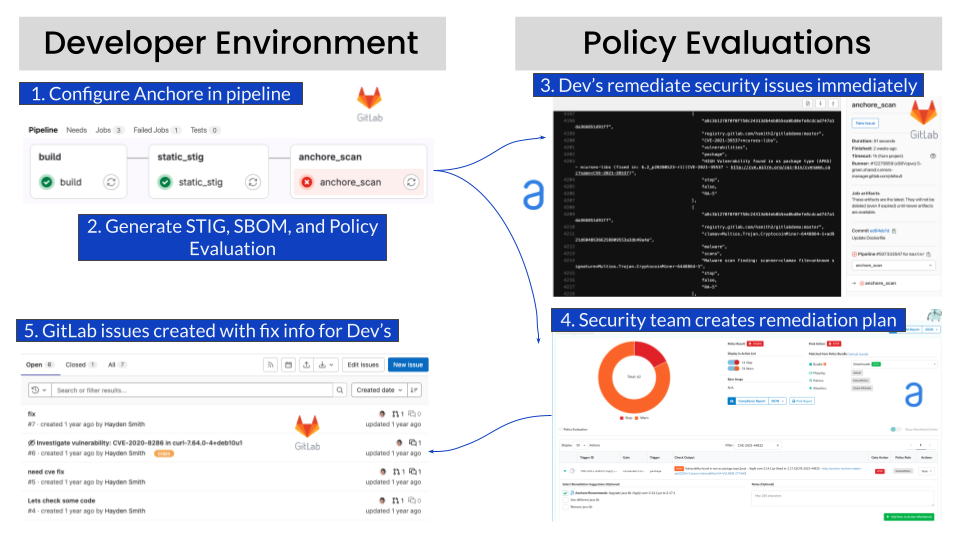
Below is an example of a workflow in GitLab of how Anchore Enterprise’s SBOM generation, vulnerability scanning and policy enforcement can catch issues early and keep your compliance record clean.
Automate Compliance Reporting
Automate monthly/annual reporting using Anchore’s reporting. Have these reports set up to auto generate based on the compliance reporting needs of FedRAMP.
Manage POA&Ms
Given that Anchore Enterprise centrally stores and manages vulnerability information for an organization, it can also be utilized to manage Plan Of Action & Milestones (POA&Ms) for any portions of the system that aren’t yet FedRAMP compliant but have a planned due date. Using Allowlists in Anchore Enterprise to centrally manage POA&Ms and assessed/justifiable findings.
Prevent Production Compliance Violations
Practice good production registry hygiene by utilizing Anchore Enterprise to scan stored images regularly. Anchore Enterprise’s Kubernetes runtime inventory will identify images that do not meet FedRAMP compliance or have not been used in the last ~7 days (company defined) to remove from your production registry.
Conclusion
Achieving FedRAMP compliance from scratch is an arduous process and not a key differentiator for many organizations. In order to maintain organizational priority on the aspects of the business that differentiate an organization from its competitors, strategic outsourcing of non-core competencies is always a recommended strategy. Anchore Enterprise aims to be that turnkey solution for organizations that want the benefits of FedRAMP compliance without developing the internal expertise, specifically for the container security aspect.
By integrating SBOM generation, vulnerability scanning, and policy enforcement into a single platform, Anchore Enterprise not only simplifies the path to compliance but also enhances overall software supply chain security. Through the deployment of Anchore Enterprise, companies can achieve and maintain compliance more quickly and with greater assurance. If you’re looking for an even deeper look at how to achieve all 7 of the container security requirements of FedRAMP with Anchore Enterprise, read our playbook: FedRAMP Pre-Assessment Playbook For Containers.
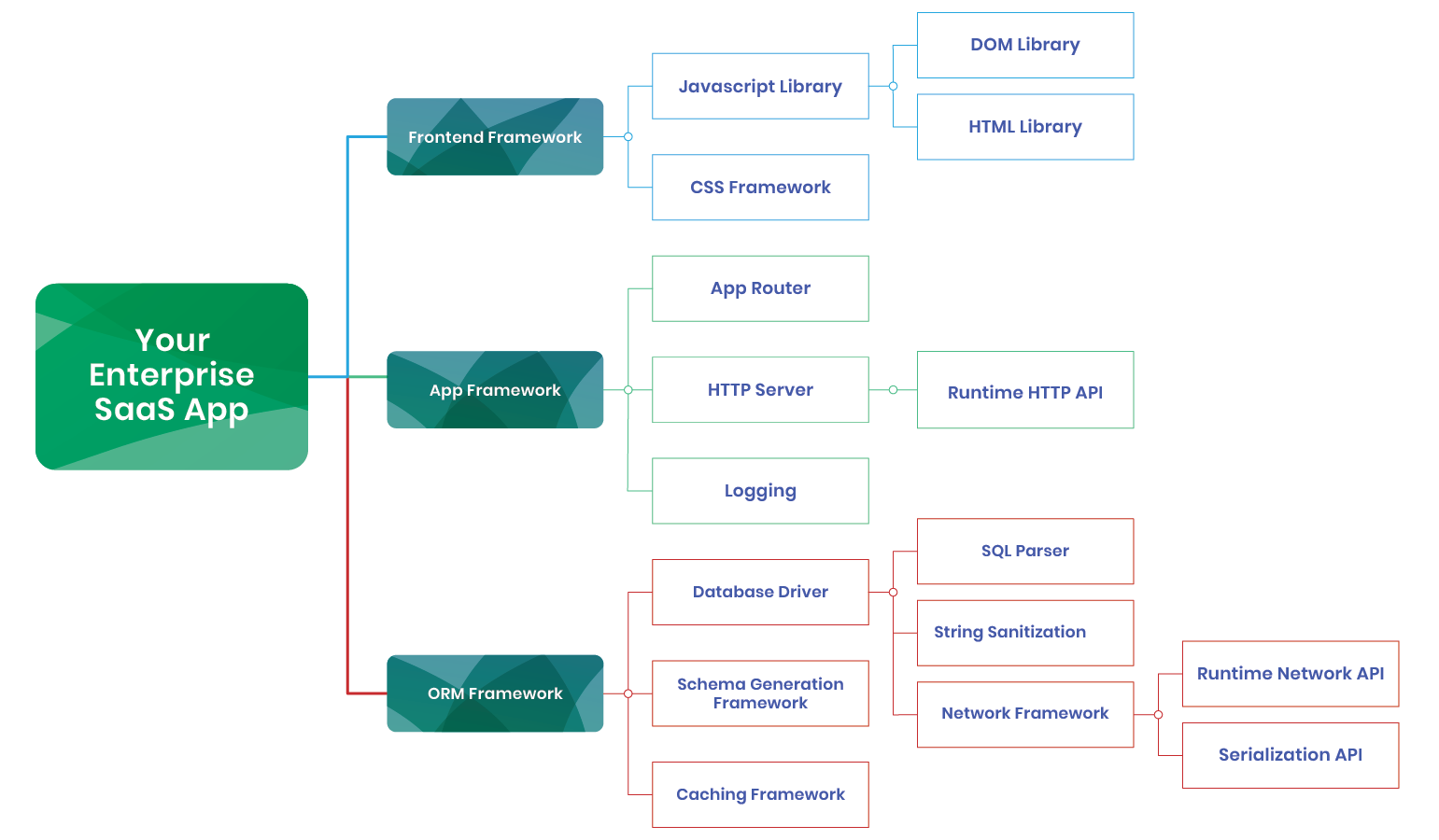
The ascent of both containerized applications and open-source software component building blocks has dramatically escalated the complexity of software and the burden of managing all of the associated licenses. Modern applications are often built from a mosaic of hundreds, if not thousands, of individual software components, each bound by its own potential licensing pitfalls. This intricate web of dependencies, akin to a supply chain, poses significant challenges not only for legal teams tasked with mitigating financial risks but also for developers who manage these components’ inventory and compliance.
Previously license management was primarily a manual affair, software wasn’t as complex in the past and more software was proprietary 1st party software that didn’t have the same license compliance issues. These original license management techniques haven’t kept up with the needs of modern, cloud-native application development. In this blog post, we’re going to discuss how automation is needed to address the challenges of continuing to manage licensing risk in modern software.
The Problem
Modern software is complex. This is fairly well known at this point but in case you need a quick visual reminder, we’ve inserted to images to quickly reinforce this idea:
Applications can be constructed from 10s or 100s or even 1000s of individual software components each with their own license for how it can be used. Modern software is so complex that this endlessly nested collection of dependencies are typically referred to as a metaphorical supply chain and there is an entire industry that has grown to provide security solutions for this quagmire called software supply chain security.
This is a complexity nightmare for legal teams that are tasked with managing the financial risk of an organization. It’s also a nightmare for the developers who are tasked with maintaining an inventory of all of the software dependencies in an organization and the associated license for each component.
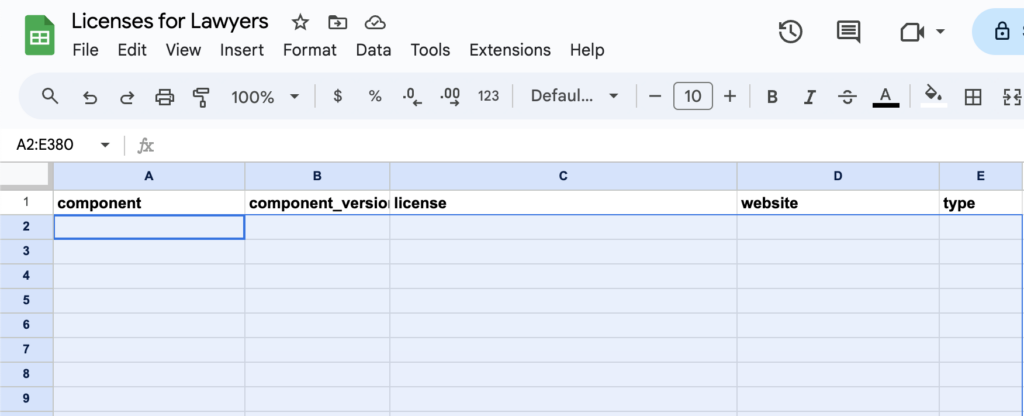
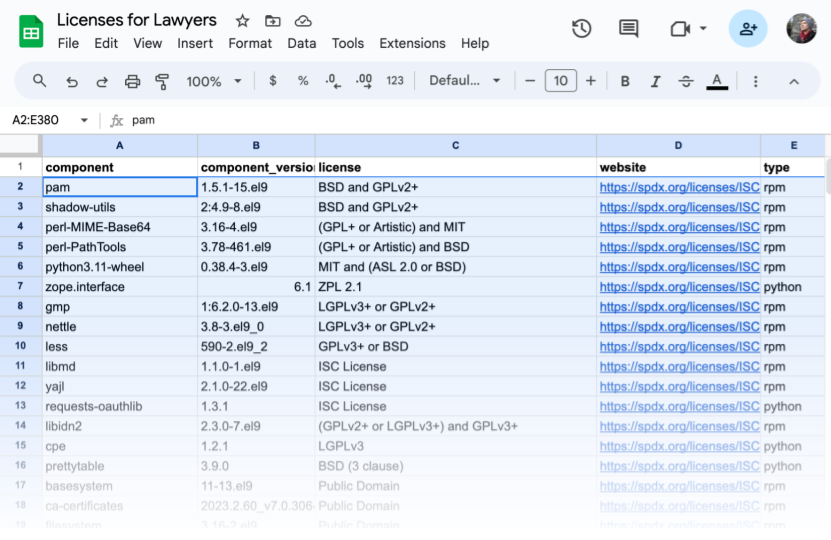
Let’s provide an example of how this normally manifests in a software startup. Assuming business is going well, you have a product and there are customers out in the world that are interested in purchasing your software. During the procurement cycle, your customer’s legal team will be tasked with assessing the risk of using your software. In order to create this assessment they will do a number of things and one of them will be to determine if your software is safe from a licensing perspective to use. In order to do this they will normally send over a document that looks like this:
As a software vendor, it will be your job to fill this out so that legal can approve the purchasing of your software and you can take that revenue to the bank.
Let’s say you manually fill this entire spreadsheet out. A developer would need to go through each dependency that is utilized in the software that you sell and “scan” the codebase for all of the licensing metadata. Component name, version number, OSS license (i.e., MIT, GPL, BSD, etc.), etc. It would take some time and be quite tedious but not an insurmountable task. In the end they would produce something like this:
This is great in the world of once-in-a-while deployments and updates. This becomes exhausting in the world of continuous integration/delivery that the DevOps movement has created. Imagine having to produce a new document like this everytime you push to production. DevOps has allowed for some times to push to production multiple times per day. Requiring that a document is manually created for all of your customers’ legal teams for each release would almost eliminate all of the velocity gains that moving to the DevOps architecture created.
The Solution
The solution to this problem is the automation of the license discovery process. If software can scan your codebase and produce a document that will exhaustively cover all of the building blocks of your application this unlocks the potential to both have your DevOps cake and eat it too.
To this end, Anchore has created and open sourced a tool that does just this.
How does Grant Integrate into my Development Workflow?
As a software license scanner, Grant operates on a software inventory artifact like an SBOM or directly on a container image. Let’s continue with the example from above to bring this to life. In the legal review example above you are a software developer that has been tasked with manually searching and finding all of the OSS license files to provide to your customer’s legal team for review.
Not wanting to do this manually by hand, you instead open up your CLI and install Grant. From there you navigate to your artifact registry and pull down the latest image of your application’s production build. Right before you run the Grant license scan on your production container image you notice that your team has been following software supply chain best practices and have already created an SBOM with a popular open-source tool called Syft. Instead of running the container through Grant which could take some time to scan the image, you instead pipe the SBOM into Grant which is already a JSON object of the entire dependency inventory of the application. A few seconds later you have a full report of all of the licenses in your application.
From here you export the full component inventory with the license enrichment into a spreadsheet and send this off to the customer’s legal team for review. A process that might have taken a full day or even multiple days to do by hand was finished in seconds with the power of open-source tooling.
Automating License Compliance with Policy
Grant is an amazing tool that can automate much of the most tedious work of protecting an organization from legal consequences but when used by a developer as a CLI tool, there is still a human in the loop which can cause traffic jams to occur. With this in mind, our OSS team made sure to launch Grant with support for policy-based filters that can automate the execution and alerting of license scanning.
Let’s say that your organization’s legal team has decided that using any GPL components in 1st party software is too risky. By writing a policy that fails any software that includes GPL licensed components and integrating the policy check as early as the staging CI environment or even allowing developers to run Grant in a one-off fashion during design as they prototype the initial idea, the potential for legally risky dependencies infiltrating into production software drops precipitously.
How Anchore Can Help
Grant is an amazing tool that automates the license compliance discovery process. This is great for small projects or software that does irregular releases. Things get much more complicated in the cloud-native, continuous integration/deployment paradigm on DevSecOps where there are new releases multiple times per day. Having Grant generate the license data is great but suddenly you will have an explosion of data that itself needs to be managed.
This is where Anchore Enterprise steps in to fill this gap. The Anchore Enterprise platform is an end-to-end data management solution that not only incorporates all of Anchore’s open-source tooling that generates artifacts like SBOMs, vulnerability scans and license scans. It also manages the massive amount of data that a high speed DevSecOps pipeline will create as part of its regular operation and on top of that apply a highly customizable policy engine that can then automate decision-making around the insights derived from the software supply chain artifacts like SBOMs, vulnerability scans and license scans.
Want to make sure that no GPL license OSS components ever make it into your SDLC? No problem. Grant will uncover all components that have this license, Anchore Enterprise will centralize these scans and the Anchore policy engine will alert the developer who just integrated a new GPL licensed OSS component into their development environment that they need to find a different component or they won’t be able to push their branch to staging. The shift left principle of DevSecOps can be applied to LegalOps as well.
Conclusion
The advent of tools like Grant, an open-source license discovery solution developed by Anchore, marks a significant advancement in the realm of open-source license management. By automating the tedious process of license verification, Grant not only enhances operational efficiency but also integrates seamlessly into continuous integration/continuous delivery (CI/CD) environments. This capability is crucial in modern DevOps practices, which demand frequent and fast-paced updates. Grant’s ability to quickly generate comprehensive licensing reports transforms a potentially day-long task into a matter of seconds.
Anchore Enterprise extends this functionality by managing the deluge of data from continuous deployments and integrating a policy engine that automates compliance decisions. This ecosystem not only streamlines the process of license management but also empowers developers and legal teams to preemptively address compliance issues, thereby embedding legal safeguards directly into the software development lifecycle. This proactive approach ensures that as the technological landscape evolves, businesses remain agile yet compliant, ready to capitalize on opportunities without being bogged down by legal liabilities.
If you’re interested to hear about the topics covered in this blog post directly from the lips of Anchore’s CTO, Dan Nurmi, and the maintainer of Grant, Christopher Phillips, you can watch the on-demand webinar here. Or join Anchore’s OSS Slack community to speak with our team directly. We look forward to hearing from you and reviewing your pull requests!
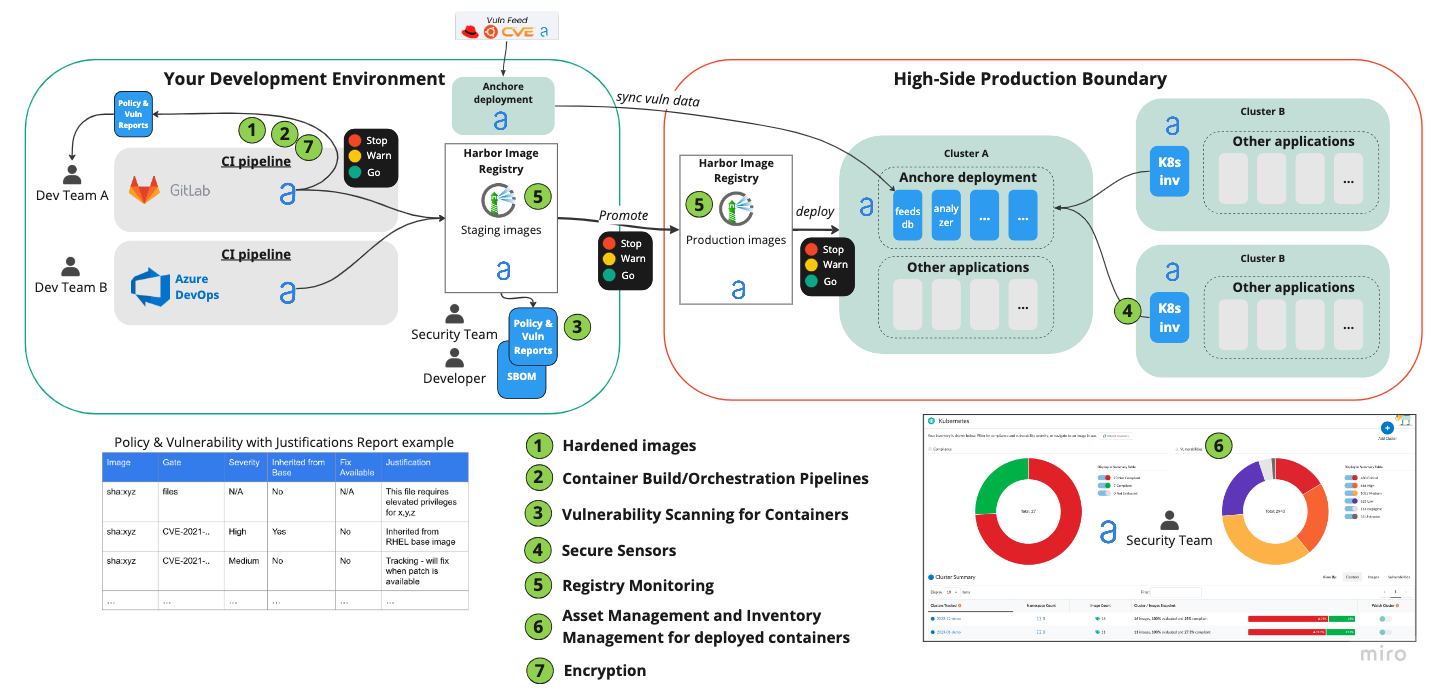
This blog post is meant as a gateway to all things DoD software factory. We highlight content from across the Anchore universe that can help anyone get up to speed on what a DoD software factory is, why to use it and how to build one. This blog post is meant as an index to be scanned for the topics that are most interesting to you as the reader with links to more detailed content.
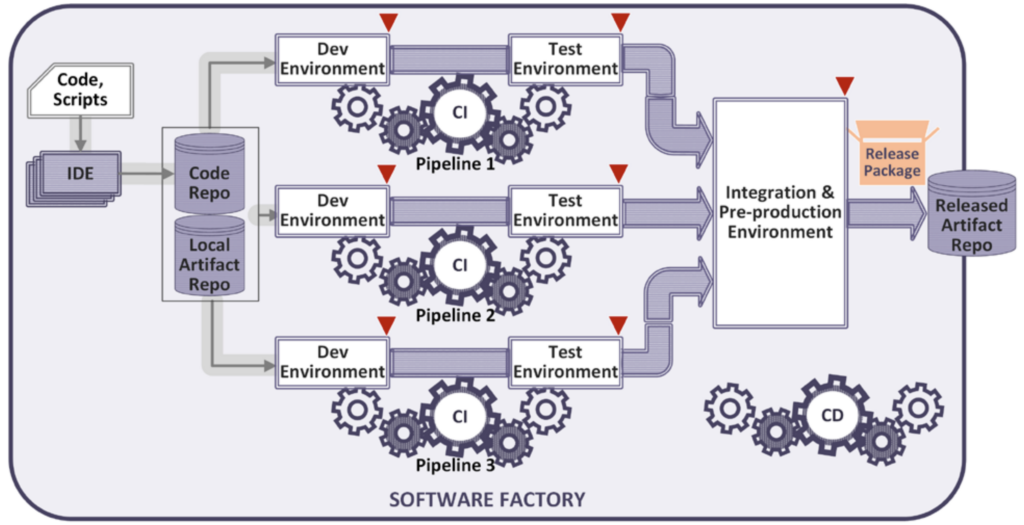
A Department of Defense (DoD) Software Factory is a software development pipeline that embodies the principles and tools of the larger DevSecOps movement with a few choice modifications that conform to the extremely high threat profile of the DoD and DIB.
Note that the diagram below looks like a traditional DevOps pipeline. The difference being that there are security controls layered into this environment that automate software component inventory, vulnerability scanning and policy enforcement to meet the requirements to be considered a DoD software factory.
Got the basics down? Go deeper and learn how Anchore can help you put the Sec into DevSecOps Reference Design by reading our DoD Software Factory Best Practices white paper.
Why do I want to utilize a DoD Software Factory?
For DoD programs, the primary reason to utilize a DoD software factory is that it is a requirement for achieving a continuous authorization to operation (cATO). The cATO standard specifically calls out that software is developed in a system that meets the DoD Enterprise DevSecOps Reference Design. A DoD software factory is the generic implementation of this design standard.
For Federal Service Integrators (FSIs), the biggest reason to utilize a DoD software factory is that it is a standard approach to meeting DoD compliance and certification standards. By meeting a standard, such as CMMC Level 2, you expand your opportunity to work with DoD programs.
Continuous Authorization to Operate (cATO)
If you’re looking for more information on cATO, Anchore has written a comprehensive guide on navigating the cATO process that can be found on our blog:
The shift from traditional software delivery to DevSecOps in the Department of Defense (DoD) represents a crucial evolution in how software is built, secured, and deployed with a focus on efficiencies and speed. Our white paper advises on best practices that are setting new standards for security and efficiency in DoD software factories.
Cybersecurity Maturity Model Certification (CMMC)
The CMMC is the certification standard that is used by the DoD to vet FSIs from the defense industrial base (DIB). This is the gold standard for demonstrating to the DoD that your organization takes security seriously enough to work with the highest standards of any DoD program. The security controls that the CMMC references when determining certification are outlined in NIST 800-171. There are 17 total families of security controls that an organization has to meet in order to meet the CMMC Level 2 certification and a DoD software factory can help check a number of these off of the list.
The specific families of controls that a DoD software factory helps meet are:
Access Control (AC)
Audit and Accountability (AU)
Configuration Management (CM)
Incident Response (IR)
Maintenance (MA)
Risk Assessment (RA)
Security Assessment and Authorization (CA)
System and Communications Protection (SC)
System and Information Integrity (SI)
Supply Chain Risk Management (SR)
If you’re looking for more information on how apply software supply chain security to meet the CMMC, Anchore has published two blog posts on the topic:
NIST SP 800-171 is the canonical list of security controls for meeting CMMC Level 2 certification. Anchore has broken down the entire 800-171 standard to give you an easy to understand overview.
Policy Enforcement is the backbone of meeting the monitoring, enforcement and reporting requirements of the CMMC. In this blog post, we break down how Anchore Federal can meet a number of the controls specifically related to software supply chain security that are outlined in NIST 800-171.
How do I meet the DevSecOps Reference Design requirements?
The DIY answer involves carefully reading and implementing the DoD Enterprise DevSecOps Reference Design. This document is massive but there are a few shortcuts you can utilize to help expedite your journey.
Container Hardening
Deciding to utilize software containers in a DevOps pipeline is almost a foregone conclusion at this point. What is less well known is how to secure your containers, especially to meet the standards of a DoD software factory.
Anchore has published a number of blogs and even a white paper that condense the information in both of these guides into more digestible content. See below:
This comprehensive white paper breaks down how to achieve a container build and deployment system that is hardened to the standards of a DoD software factory.
This blog post is great for those who are interested to see how Anchore Federal can turn all of the requirements of the DoD Container Hardening Guide and the Container Image Creation and Deployment Guide into an easy button.
This blog post deep dives into how to utilize Anchore Federal to find container vulnerabilities and alert or report on whether they are violating the security compliance required to be a DoD software factory.
Policy-based Software Supply Chain Security and Compliance
The power of a policy-based approach to software supply chain security is that it can be integrated directly into a DevOps pipeline and automate a significant amount of alerting, reporting and enforcement work. The blog posts below go into depth on how this automated approach to security and compliance can uplevel a DoD software factory:
This follow-up to the post above shows how the policy-based security platform outlined in the first blog post can have significant benefits to public sector organizations that have to focus on both internal information security and how to prove they are compliant with government standards.
Getting a bit more technical this blog details how a policy-based development workflow can be utilized as a security gate with deployment orchestration systems like Kubernetes.
An even deeper dive into what is possible with the policy-based security system provided by Anchore Enterprise, this blog gets into the nitty-gritty on how to configure policies to achieve specific security outcomes.
This blog shows how a security practitioner can extend the security signals that Anchore Enterprise collects with the assistance of a more flexible data platform like New Relic to derive more actionable insights.
Security Technical Implementation Guide (STIG)
The Security Technical Implementation Guides (STIGs) are fantastic technical guides for configuring off the shelf software to DoD hardening standards. Anchore being a company focused on making security and compliance as simple as possible has written a significant amount about how to utilize STIGs, especially for container-based DevSecOps pipelines. Exactly the kind of software development environments that meet the standards of a DoD software factory. View our previous content below:
In this blog post, we give you four quick tips to help you prepare for the STIG process for software containers. Think of this as the amuse bouche to prepare you for the comprehensive white paper that comes next.
As promised, this is the extensive document that walks you through how to build a DevSecOps pipeline based on containers that is both high velocity and secure. Perfect for organizations that are aiming to roll their own DoD software factory.
User Stories
Anchore has been supporting FSIs and DoD programs to build DevSecOps programs that meet the criteria to be called a DoD software factory for the past decade. We can write technical guides and best practices documents till time ends but sometimes the best lessons are learned from real-life stories. Below are user stories that help fill in all of the details about how a DoD software factory can be built from scratch:
Join Major Camdon Cady of Platform One and Anchore’s VP of Security, Josh Bressers as they discuss the lessons learned from building a DoD software factory from the ground up. Watch this on-demand webinar to get all of the details in a laid back and casual conversation between two luminaries in their field.
If you prefer a written format over video, this case study highlights how Platform One utilized Red Hat OpenShift and Anchore Federal to build their DoD software factory that has become the leading Managed Service Provider for DoD programs.
Conclusion
Similar to how Cloud has taken over the infrastructure discussion in the enterprise world, DoD software factories are quickly becoming the go-to solution for DoD programs and the FSIs that support them. Delivering on the promise of the DevOps movement of high velocity development without compromising security, a DoD software factory is the one-stop shop to upgrade your software development practice into the modern age and become compliant as a bonus! If you’re looking for an easy button to infuse your DevOps pipeline with security and compliance without the headache of building it yourself, take a look at Anchore Federal and how it helps organizations layer software supply chain security into a DoD software factory and achieve a cATO.
The Security Technical Implementation Guide (STIG) is a Department of Defense (DoD) technical guidance standard that captures the cybersecurity requirements for a specific product, such as a cloud application going into production to support the warfighter. System integrators (SIs), government contractors, and independent software vendors know the STIG process as a well-governed process that all of their technology products must pass. The Defense Information Systems Agency (DISA) released the Container Platform Security Requirements Guide (SRG) in December 2020 to direct how software containers go through the STIG process.
STIGs are notorious for their complexity and the hurdle that STIG compliance poses for technology project success in the DoD. Here are some tips to help your team prepare for your first STIG or to fine-tune your existing internal STIG processes.
4 Ways to Prepare for the STIG Process for Containers
Here are four ways to prepare your teams for containers entering the STIG process:
1. Provide your Team with Container and STIG Cross-Training
DevSecOps and containers, in particular, are still gaining ground in DoD programs. You may very well find your team in a situation where your cybersecurity/STIG experts may not have much container experience. Likewise, your programmers and solution architects may not have much STIG experience. Such a situation calls for some manner of formal or informal cross-training for your team on at least the basics of containers and STIGs.
Look for ways to provide your cybersecurity specialists involved in the STIG process with training about containers if necessary. There are several commercial and free training options available. Check with your corporate training department to see what resources they might have available such as seats for online training vendors like A Cloud Guru and Cloud Academy.
There’s a lot of out-of-date and conflicting information about the STIG process on the web today. System integrators and government contractors need to build STIG expertise across their DoD project teams to cut through such noise.
Including STIG expertise as an essential part of your cybersecurity team is the first step. While contract requirements dictate this proficiency, it only helps if your organization can build a “bench” of STIG experts.
Here are three tips for building up your STIG talent base:
Make STIG experience a “plus” or “bonus” in your cybersecurity job requirements for roles, even if they may not be directly billable to projects with STIG work (at least in the beginning)
Develop internal training around STIG practices led by your internal experts and make it part of employee onboarding and DoD project kickoffs
Create a “reach back” channel from your project teams to get STIG expertise from other parts of your company, such as corporate and other project teams with STIG expertise, to get support for any issues and challenges with the STIG process
Depending on the size of your company, clearance requirements of the project, and other situational factors, the temptation might be there to bring in outside contractors to shore up your STIG expertise internally. For example, the Container Platform Security Resource Guide (SRG) is still new. It makes sense to bring in an outside contractor with some experience managing containers through the STIG process. If you go this route, prioritize the knowledge transfer from the contractor to your internal team. Otherwise, their container and STIG knowledge walk out the door at the end of the contract term.
2. Validate your STIG Source Materials
When researching the latest STIG requirements, you need to validate the source materials. There are many vendors and educational sites that publish STIG content. Some of that content is outdated and incomplete. It’s always best to go straight to the source. DISA provides authoritative and up-to-date STIG content online that you should consider as your single source of truth on the STIG process for containers.
3. Make the STIG Viewer part of your Approved Desktop
Working on DoD and other public sector projects requires secure environments for developers, solution architects, cybersecurity specialists, and other team members. The STIG Viewer should become a part of your DoD project team’s secure desktop environment. Save the extra step of your DoD security teams putting in a service desk ticket to request the STIG Viewer installation.
4. Look for Tools that Automate time-intensive Steps in the STIG process
The STIG process is time-intensive, primarily documenting policy controls. Look for tools that’ll help you automate compliance checks before you proceed into an audit of your STIG controls. The right tool can save you from audit surprises and rework that’ll slow down your application going live.
Parting Thought
The STIG process for containers is still very new to DoD programs. Being proactive and preparing your teams upfront in tandem with ongoing collaboration are the keys to navigating the STIG process for containers.
A very impressive and scary attack against the xz library was uncovered on Friday, which made for an interesting weekend for many of us.
There has been a lot written about the technical aspects of this attack, and more will be uncovered over the next few days and weeks. It’s likely we’re not done learning new details about this attack. This doesn’t appear to affect as many organizations as Log4Shell did, but it’s a pretty big deal. Especially what this sort of attack means for the larger ecosystem of open source. Trying to explain the details isn’t the point of this blog post. There’s another angle of this story that’s not getting much attention. How can we solve problems like this (we can’t), and what can we do going forward?
The unsolvable problem
Sometimes reality can be harsh, but the painful truth about this sort of attack is that there is no solution. Many projects and organizations are happy to explain how they keep you safe, or how you can prevent supply chain attacks, by doing this one simple thing. However, the industry as it stands today lacks the ability to prevent an attack created by a motivated and resourced threat actor. If we want to use an analogy, preventing an attack like xz is the equivalent of the pre-crime science fiction dystopian stories. The idea behind pre-crime is to use data or technology to predict when a crime is going to happen, then stopping it. This leads to a number of problems in any society that adopts such a thing as one can probably imagine.
If there is a malicious open source maintainer, we lack the tools and knowledge to prevent this sort of attack, as you can’t actually stop such behavior until after it happens. It may be possible there’s no way to stop something like this before it happens.
HOWEVER, that doesn’t mean we are helpless. We can take a page out of the playbook of the observability industry. Sometimes we’re able to see problems as they happen or after they happen, then use that knowledge from the past to improve the future, that is a problem we can solve. And it’s a solution that we can measure. If you have a solid inventory of your software, looking for affected versions of xz becomes simple and effective.
Today and Tomorrow
Of course looking for a vulnerable version of xz, specifically versions 5.6.0 and 5.6.1, is something we should all be doing. If you’ve not gone through the software you’re running you should go do this right now. See below for instructions on how to use Syft and Anchore Enterprise to accomplish this.
Finding two specific versions of xz is a very important task right now, there’s also what happens tomorrow. We’re all very worried about these two specific versions of xz, but we should prepare for what happens next. It’s very possible there will be other versions of xz that end up having questionable code that needs to be removed or downgraded. There could be other libraries that have problems (everyone is looking for similar attacks now). We don’t really know what’s coming next. The worst part of being in the middle of attacks like this are the unknowns. But there are some things we do know. If you have an accurate inventory of your software, figuring out what software or packages you need to update becomes trivial.
Creating an inventory
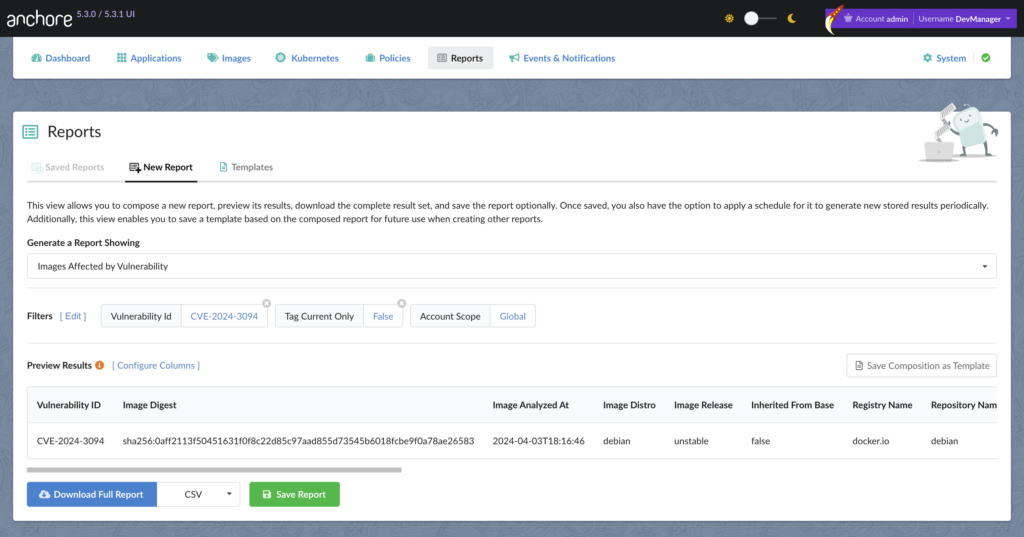
If you’re running Anchore Enterprise the good news is you already have an inventory of your software. You can create a report that will look for images affected by CVE-2024-3094.
The above image shows how a report in Anchore Enterprise can be created. Another feature of Anchore Enterprise allows you to query all of your SBOMs for instances of specified software via an API call, by package name. This is useful for gaining insights about the location, ubiquity, and the version spread of the software, present in your environment.
The package names in question are the liblzma5 and xz-libs packages, which cover the common naming across rpm, dpkg, and apkg based Linux distributions. For example:
If you’re using Syft, it’s a little bit more complicated, but still a very solvable problem. The first thing to do is generate SBOMs for the software you’re using. Let’s create SBOMs for container images in this example.
It’s important to keep those SBOMs you just created somewhere safe. If we then find out in a few days or weeks that other versions of xz shouldn’t be trusted, or if a different open source library has a similar problem, we can just run a query against those files to understand how or if we are affected.
Now that we have a directory full of SBOMs, we can run a query similar to these to figure out which SBOMs have a version of xz in them.
While the example looks for xz, if the need to quickly look for other packages arises in the near future, it’s easy to adjust your query. It’s even easier if you store the SBOMs in some sort of searchable database.
What now?
There’s no doubt it’s going to be a very interesting couple of weeks for many of us. Anyone who has been watching the news is probably wondering what wild supply chain story will happen next. The pace of solving open source security problems hasn’t kept pace with the growth of open source. There will be no quick fixes. The only way we get out of this one is a lot of hard questions and even more hard work.
But in the meantime, we can focus on understanding and defending what we have. Sometimes the best defense is a good defense.