In previous posts, we’ve demonstrated how to create a Kubernetes cluster on AWS Elastic Kubernetes Service (EKS) and how to deploy Anchore Enterprise in your EKS cluster. The focus of this post is to demonstrate how to configure a more production-like deployment of Anchore with integrations such as SSL support, RDS database backend and S3 archival.
Prerequisites:
Configuring the Ingress/Application Load Balancer
Anchore’s Helm Chart provides a deployment template for configuring an ingress resource for your Kubernetes deployment. EKS supports the use of an AWS Elastic Load Balancing Application Load Balancer (ALB) ingress controller, an NGINX ingress controller or a combination of both.
For the purposes of this demonstration, we will focus on deploying the ALB ingress controller using the Helm chart.
To enable ingress deployment in your EKS cluster, simply add the following ingress configuration to your anchore_values.yaml:
Note: If you haven’t already, make sure to create the necessary RBAC roles, role bindings and service deployment required by the AWS ALB Ingress controller. See ALB Ingress Controller for more details.
ingress:
enabled: true
labels: {}
apiPath: /v1/*
uiPath: /*
annotations:
kubernetes.io/ingress.class: alb
alb.ingress.kubernetes.io/scheme: internet-facing
Specify Custom Security Groups/Subnets
By default, the ingress controller will deploy a public-facing application load balancer and create a new security group allowing access to your deployment from anywhere over the internet. To prevent this, we can update the ingress annotations to include additional information such as a custom security group resource. This will enable you to use an existing security group within the cluster VPC with your defined set of rules to access the attached resources.
To specify a security group, simply add the following to your ingress annotations and update the value with your custom security group id:
alb.ingress.kubernetes.io/security-groups: "sg-012345abcdef"
We can also specify the subnets we want the load balancer to be associated with upon deployment. This may be useful if we want to attach our load balancer to the cluster’s public subnets and have it route traffic to nodes attached to the cluster’s private subnets.
To manually specify which subnets the load balancer should be associated with upon deployment, update your annotations with the following value:
alb.ingress.kubernetes.io/subnets: "subnet-1234567890abcde, subnet-0987654321edcba"
To test the configuration, apply the Helm chart:
helm install <deployment_name> anchore/anchore-engine -f anchore_values.yaml
Next, describe your ingress controller configuration by running kubectl describe ingress
You should see the DNS name of your load balancer next to the address field and under the ingress rules, a list of annotations including the specified security groups and subnets.
Note: If the load balancer did not deploy successfully, review the following AWS documentation to ensure the ingress controller is properly configured.
Configure SSL/TLS for the Ingress
You can also configure an HTTPS listener for your ingress to secure connections to your deployment.
First, create an SSL certificate using AWS Certificate Manager and specify a domain name to associate with your certificate. Note the ARN of your new certificate and save it for the next step.
Next, update the ingress annotations in your anchore_values.yaml with the following parameter and provide the certificate ARN as the value.
alb.ingress.kubernetes.io/certificate-arn: "arn:aws:acm::"
Additionally, we can configure the Enterprise UI to listen on HTTPS or a different port by including the following annotations to the ingress with the desired port configuration. See the following example:
alb.ingress.kubernetes.io/listen-ports: '[{"HTTPS": 443}, {"HTTP": 80}]'
alb.ingress.kubernetes.io/actions.ssl-redirect: '{"Type": "redirect", "RedirectConfig": { "Protocol": "HTTPS", "Port": "443", "StatusCode": "HTTP_301"}}'
Next, install the deployment if this is a new deployment:
helm install anchore/anchore-engine -f anchore_values.yaml
Or upgrade your existing deployment
helm upgrade anchore/anchore-engine -f anchore_values.yaml
To confirm the updates were applied, run kubectl describe ingress and verify your certificate ARN, as well as the updated port configurations, appear in your annotations.
Analyze Archive Storage Using AWS S3
AWS’s S3 Object Storage allows users to store and retrieve data from anywhere in the world. It can be particularly useful as an archive system. For more information on S3, please see the documentation from Amazon.
Both Anchore Engine and Anchore Enterprise can be configured to use S3 as an archiving solution. Some form of archiving is highly recommended for a production-ready environment. In order to set this up on your EKS, you must first ensure that your use case is in line with Anchore’s archiving rules. Anchore stores image analysis results in two locations. The first is the working set which is where an image is stored initially after its analysis is completed. In the working state, images are available for queries and policy evaluation. The second location is the archive set. Analysis data stored in this location is not actively ready for policy evaluation or queries but is less resource-intensive and information here can always be loaded into the working set for evaluation and queries. More information about Anchore and archiving can be found here.
To enable S3 archival, copy the following to the catalog section of your anchore_values.yaml:
anchoreCatalog:
replicaCount: 1
archive:
compression:
enabled: true
min_size_kbytes: 100
storage_driver:
name: s3
config:
bucket: ""
# A prefix for keys in the bucket if desired (optional)
prefix: ""
# Create the bucket if it doesn't already exist
create_bucket: false
# AWS region to connect to if 'url' not specified, if both are set, then 'url' has precedent
region: us-west-2
By default, Anchore will attempt to access an existing bucket specified under the config > bucket value. If you do not have an S3 bucket created, then you can set create_bucket to false and allow the Helm chart to create the bucket for you. If you already created one, put its name in the bucket parameter. Since S3 isn’t region-specific, you need to specify the region that your EKS cluster resides in with the region parameter.
Note: Whether you specify an existing bucket resource or set create_bucket to true, the cluster nodes require permissions to perform the necessary API calls to the S3 service. There are two ways to configure authentication:
Specify AWS Access and Secret Keys
To specify the access and secret keys tied to a role with permissions to your bucket resource, update the storage driver configuration in your anchore_values.yaml with the following parameters and appropriate values:
# For Auth can provide access/secret keys or use 'iamauto' which will use an instance profile or any credentials found in normal aws search paths/metadata service
access_key: XXXX
secret_key: YYYY
Use Permissions Attached to the Node Instance Profile
The second method for configuring access to the bucket is to leverage the instance profile of your cluster nodes. This eliminates the need to create an IAM role to access the bucket and manage the access and secret keys for the role separately. To configure the catalog service to leverage the IAM role attached to the underlying instance, update the storage driver configuration in your anchore_values.yaml with the following and ensure iamauto is set true:
# For Auth can provide access/secret keys or use 'iamauto' which will use an instance profile or any credentials found in normal aws search paths/metadata service
iamauto: true
You must also ensure that the role associated with your cluster nodes has GetObject, PutObject and DeleteObject permissions to your S3 bucket (see a sample policy below).
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": ["s3:ListBucket"], "Resource": ["arn:aws:s3:::test"]
},
{
"Effect": "Allow",
"Action": [
"s3:PutObject",
"s3:GetObject",
"s3:DeleteObject"
],
"Resource": ["arn:aws:s3:::test/*"]
}
]
}
Once all of these steps are completed, deploy the Helm chart by running:
helm install stable/anchore-engine -f anchore_values.yaml
Or the following, if upgrading an existing deployment:
helm upgrade stable/anchore-engine -f anchore_values.yaml
Note: If your cluster nodes reside in private subnets, they must have outbound connectivity in order to access your S3 bucket.
For cluster deployments where nodes are hosted in private subnets, a NAT gateway can be used to route traffic from your cluster nodes outbound through the public subnets. More information about creating and configuring NAT gateways can be found here.
Another option is to configure a VPC gateway allowing your nodes to access the S3 service without having to route traffic over the internet. More information regarding VPC endpoints and VPC gateways can be found here.
Using Amazon RDS as an External Database
By default, Anchore will deploy a database service within the cluster for persistent storage using a standard PostgreSQL Helm chart. For production deployments, it is recommended to use an external database service that provides more resiliency and supports features such as automated backups. For EKS deployments, we can offload Anchore’s database tier to PostgreSQL on Amazon RDS.
Note: Your RDS instance must be accessible to the nodes in your cluster in order for Anchore to access the database. To enable connectivity, the RDS instance should be deployed in the same VPC/subnets as your cluster and at least one of the security groups attached to your cluster nodes must allow connections to the database instance. For more information, read about configuring access to a database instance in a VPC.
To configure the use of an external database, update your anchore_values.yaml with the following section and ensure enabled is set to “false”.
postgresql:
enabled: false
Under the postgres section, add the following parameters and update them with the appropriate values from your RDS instance.
postgresUser:
postgresPassword:
postgresDatabase:
externalEndpoint:
With the section configured, your database values should now look something like this:
postgresql:
enabled: false
postgresUser: anchoreengine
postgresPassword: anchore-postgres,123
postgresDatabase: postgres
externalEndpoint: abcdef12345.jihgfedcba.us-east-1.rds.amazonaws.com
To bring up your deployment run:
helm install stable/anchore-engine -f anchore_values.yaml
Finally, run kubectl get pods to confirm the services are healthy and the local postgresql pod isn’t deployed in your cluster.
Note: The above steps can also be applied to deploy the feeds postgresql database on Amazon RDS by updating the anchore-feeds-db section instead of the postgresql section of the chart.
Encrypting Database Connections Using SSL Certificates with Amazon RDS
Encrypting RDS connections is a best practice to ensure the security and integrity of your Anchore deployment that uses external database connections.
Enabling SSL on RDS
AWS provides the necessary certificates to enable SSL with your rds deployment. Download rds-ca-2019-root.pem from here. In order to require SSL connections on an RDS PostgreSQL instance, the rds.force_ssl parameter needs to be set to 1 (on). By setting this to 1, the PostgreSQL instance will set the SSL parameter to 1 (on) as well as modify the database’s pg_hba.conf file to support SSL. See more information about RDS PostgreSQL ssl configuration.
Configuring Anchore to take advantage of SSL is done through the Helm chart. Under the anchoreGlobal section in the chart, enter the certificate filename next to certStoreSecretName that we downloaded from AWS in the previous section. (see example below)
anchoreGlobal:
certStoreSecretName: rds-ca-2019-root.pem
Under the dbConfig section, set SSL to true. Set sslRootCertName to the same value as certStoreSecretName. Make sure to update the postgresql and anchore-feeds-db sections to disable the local container deployment of the services and specify the RDS database values (see the previous section on configuring RDS to work with Anchore for further details). (If running Enterprise, the dbConfig section under anchoreEnterpriseFeeds should also be updated to include the cert name under sslRootCertName)
dbConfig:
timeout: 120
ssl: true
sslMode: verify-full
sslRootCertName: rds-ca-2019-root.pem
connectionPoolSize: 30
connectionPoolMaxOverflow: 100
Once these settings have been configured, run a Helm upgrade to apply the changes to your cluster.
Conclusion
The Anchore Helm chart provided on GitHub allows users to quickly get a deployment running on their cluster, but it is not necessarily a production-ready environment. The sections above showed how to configure the ingress/application load balancer, configuring HTTPS, archiving image analysis data to an AWS S3 bucket, and setting up an external RDS instance and requiring SSL connections to it. All of these steps will ensure that your Anchore deployment is production-ready and prepared for anything you throw at it.
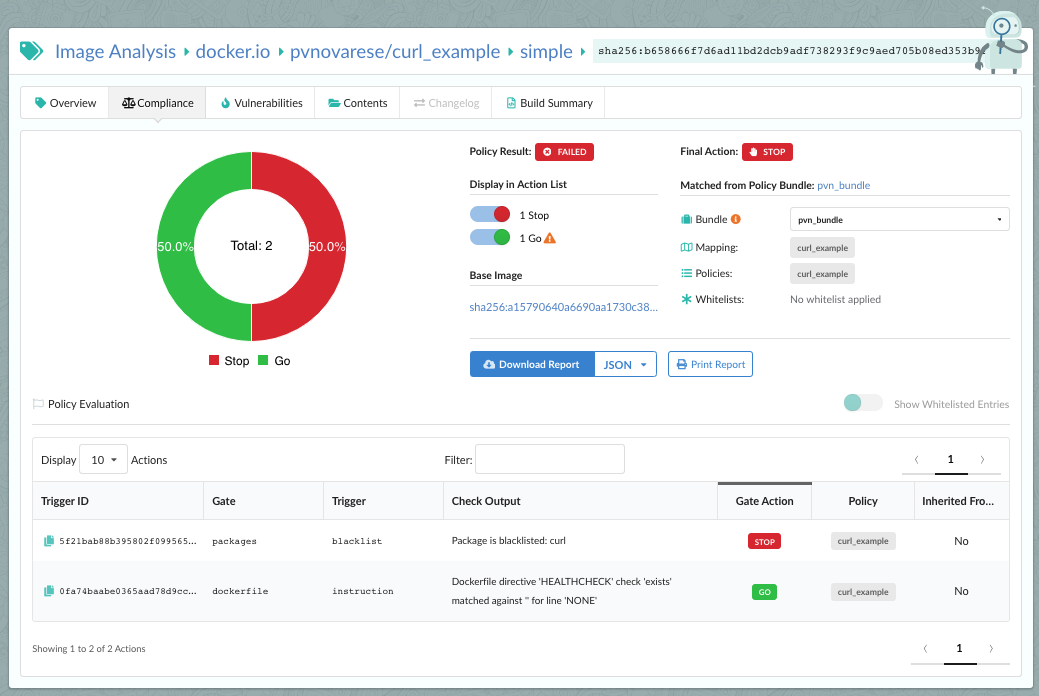
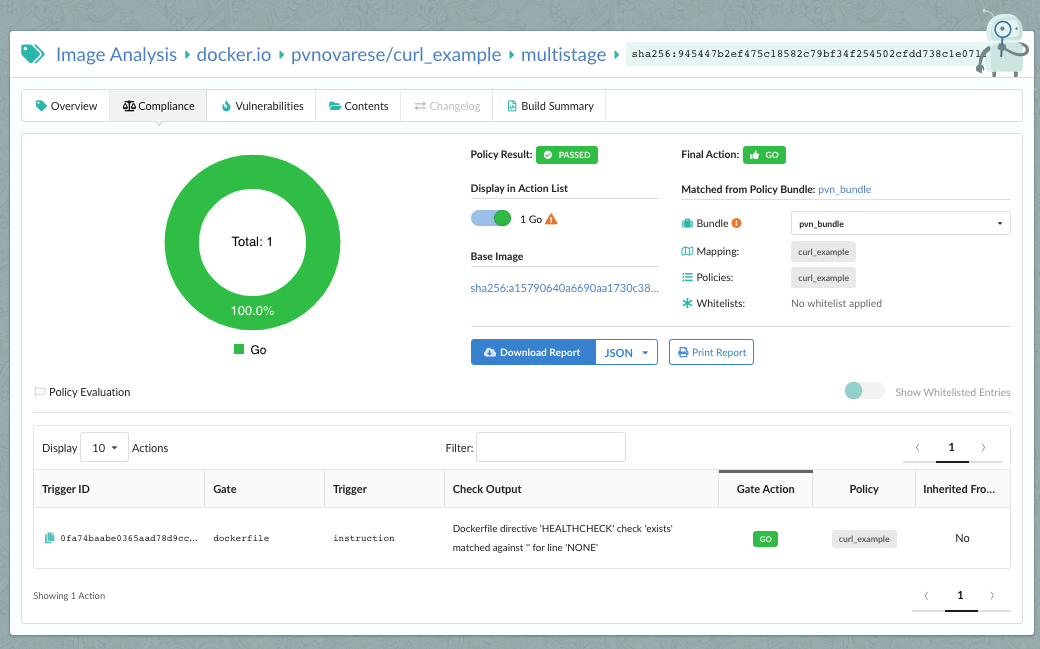

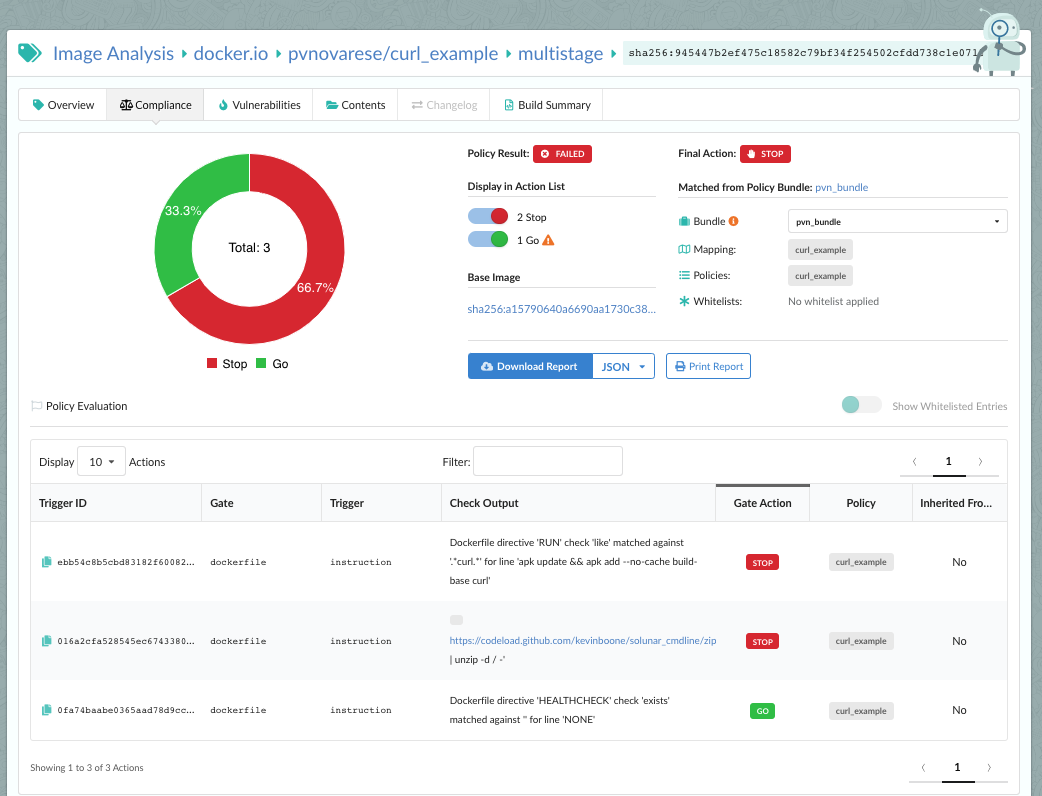
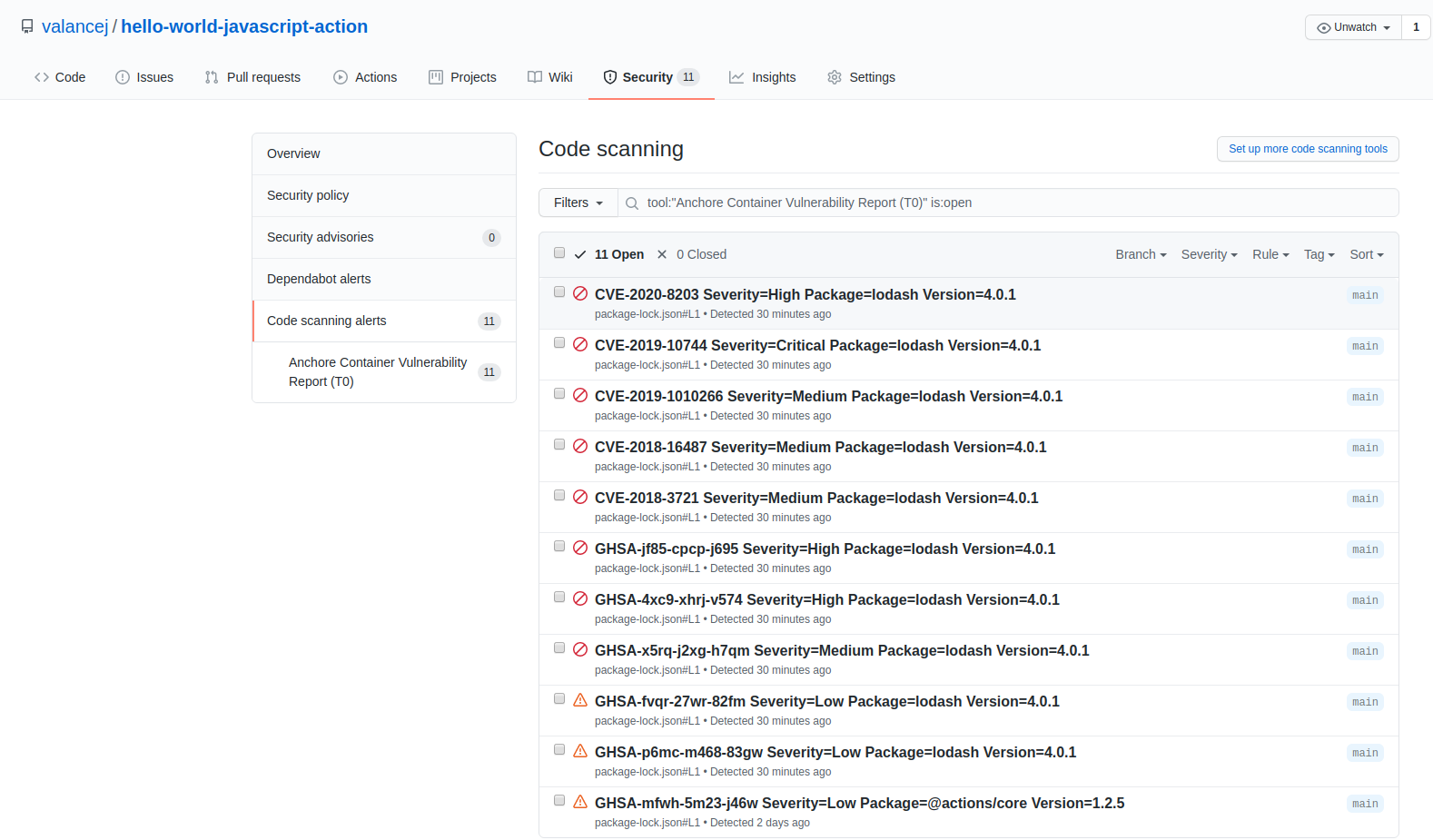
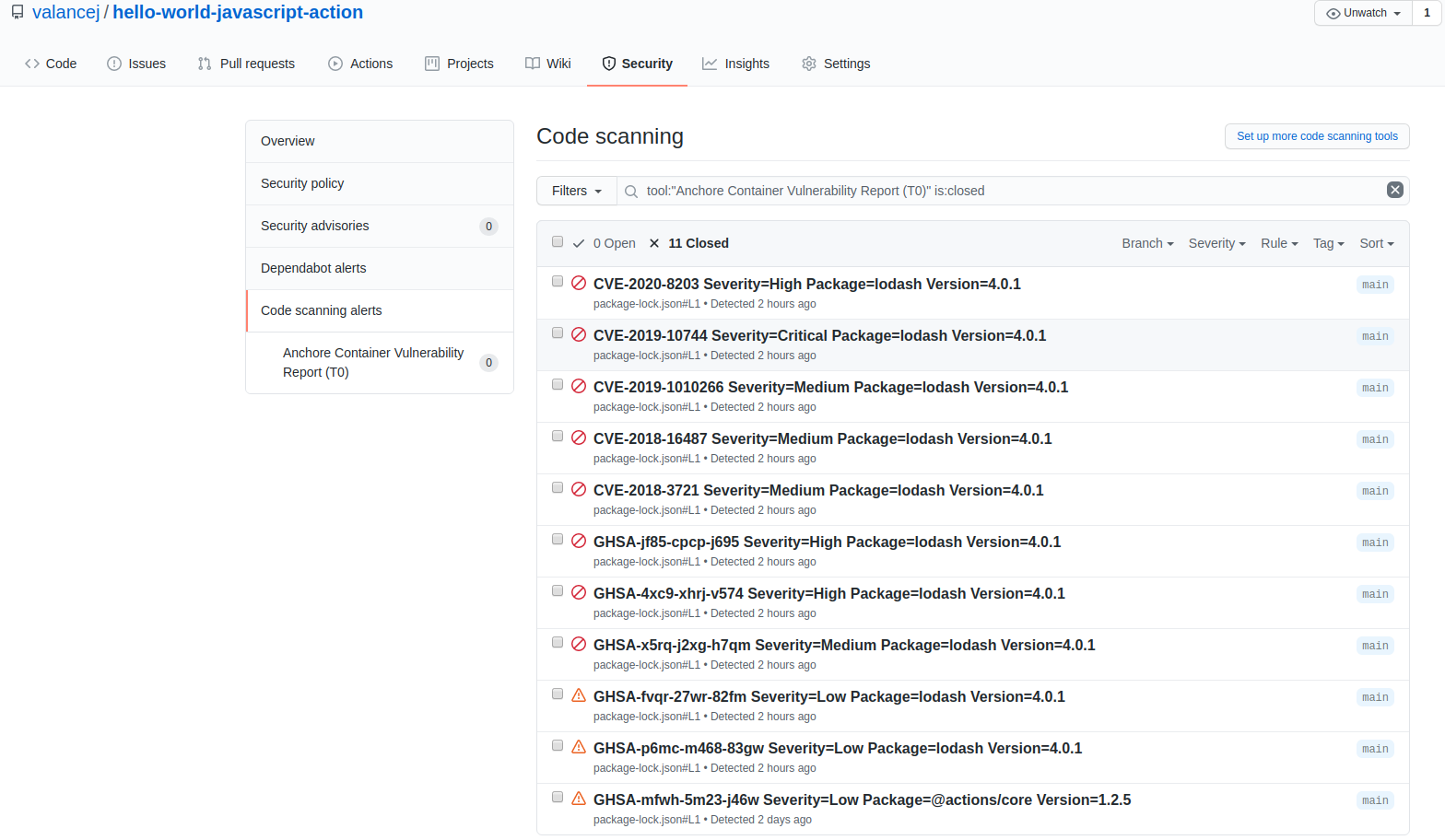



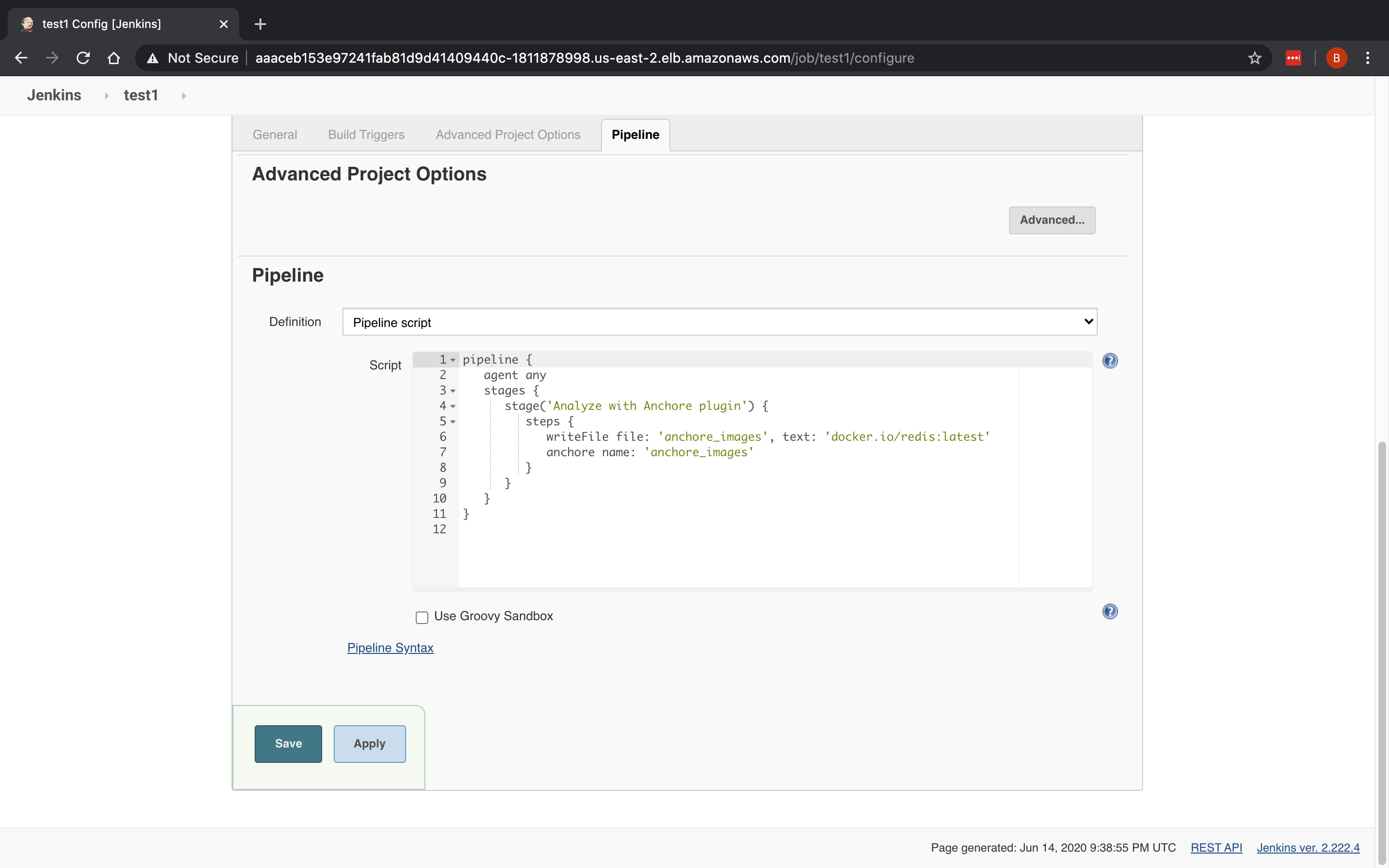
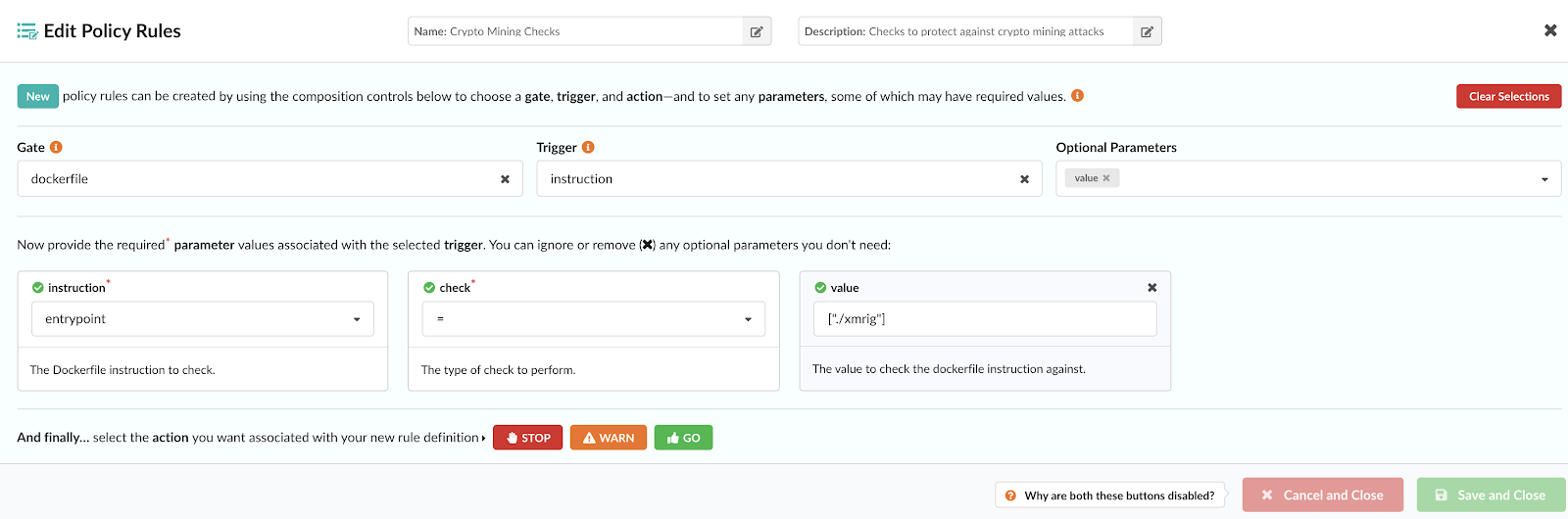
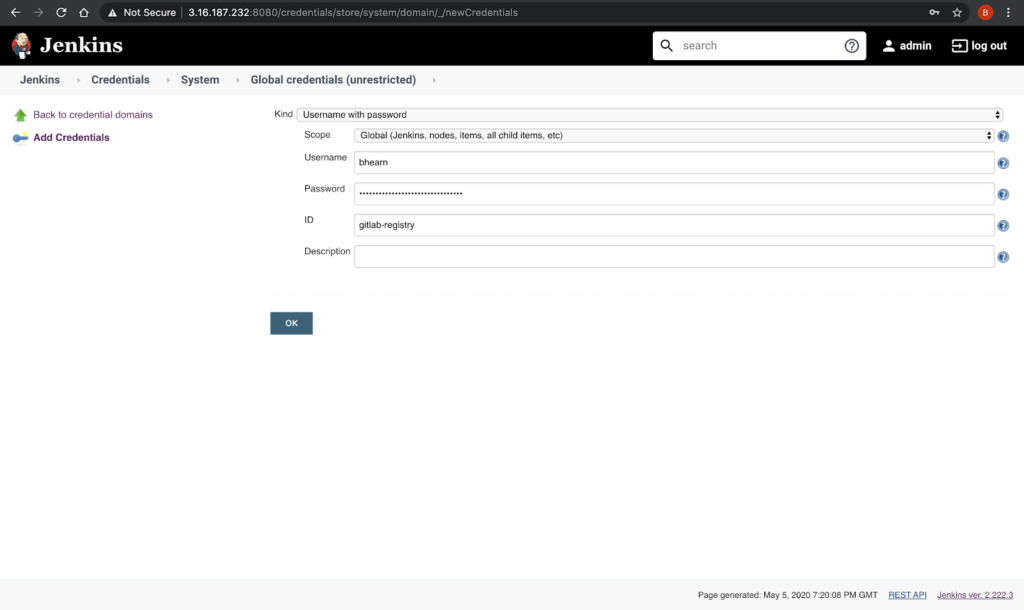
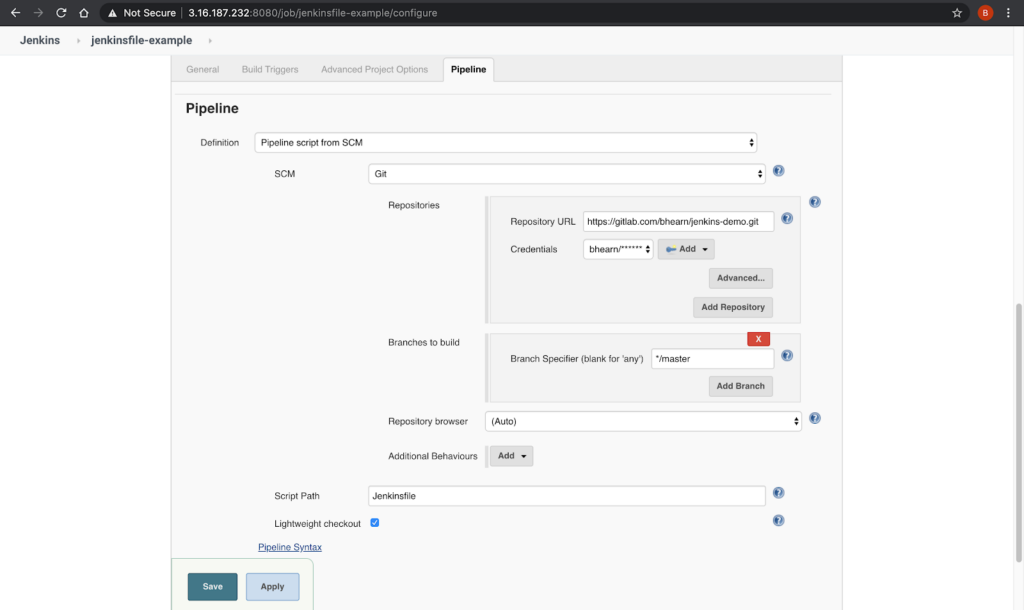
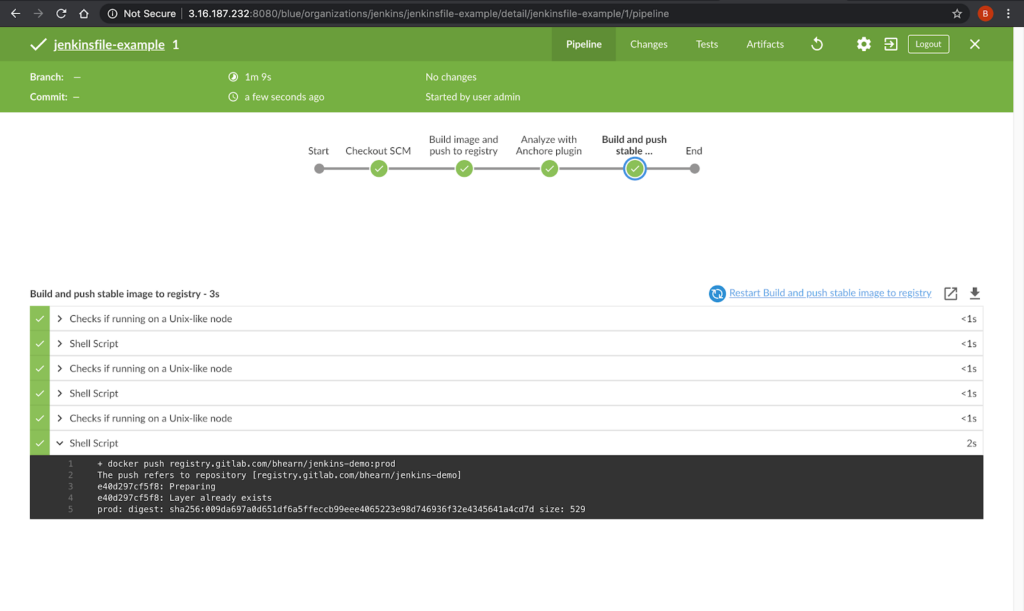
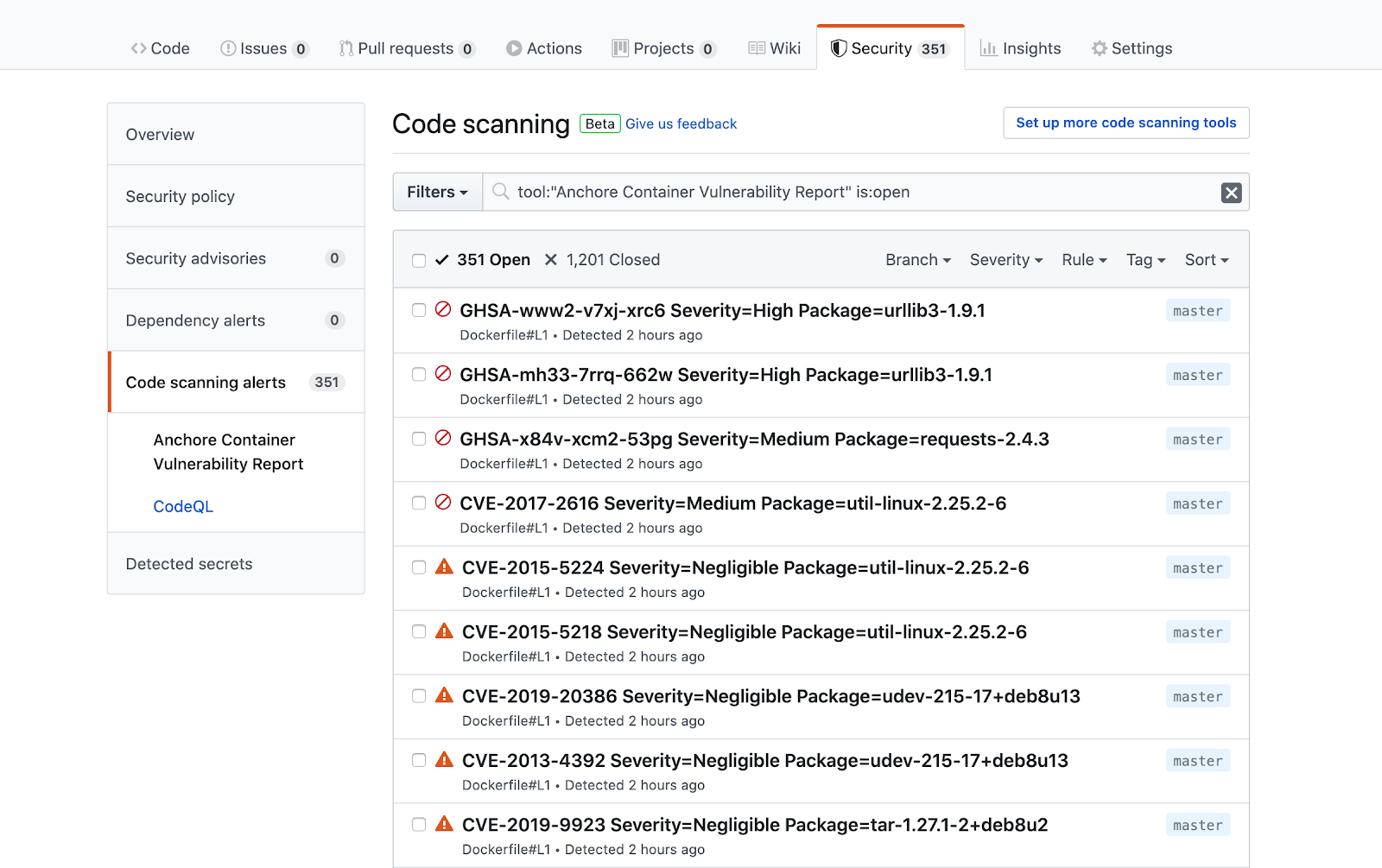
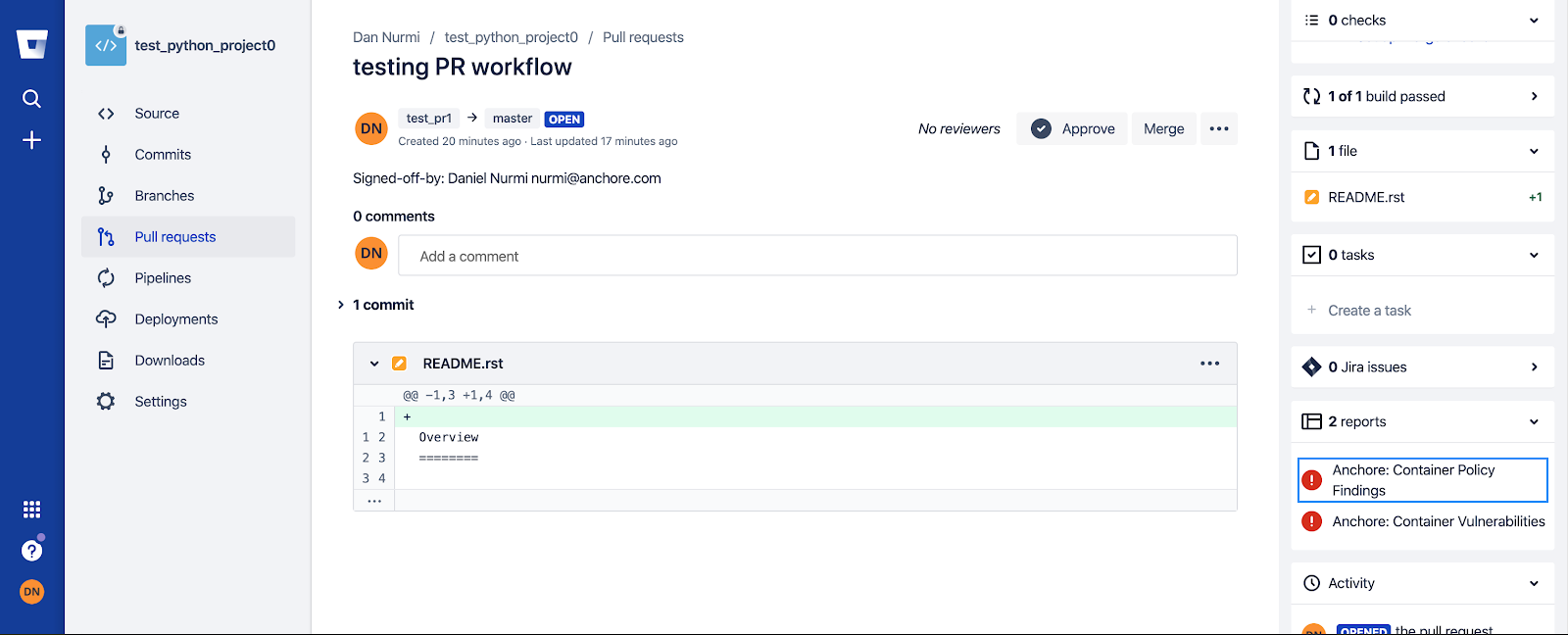
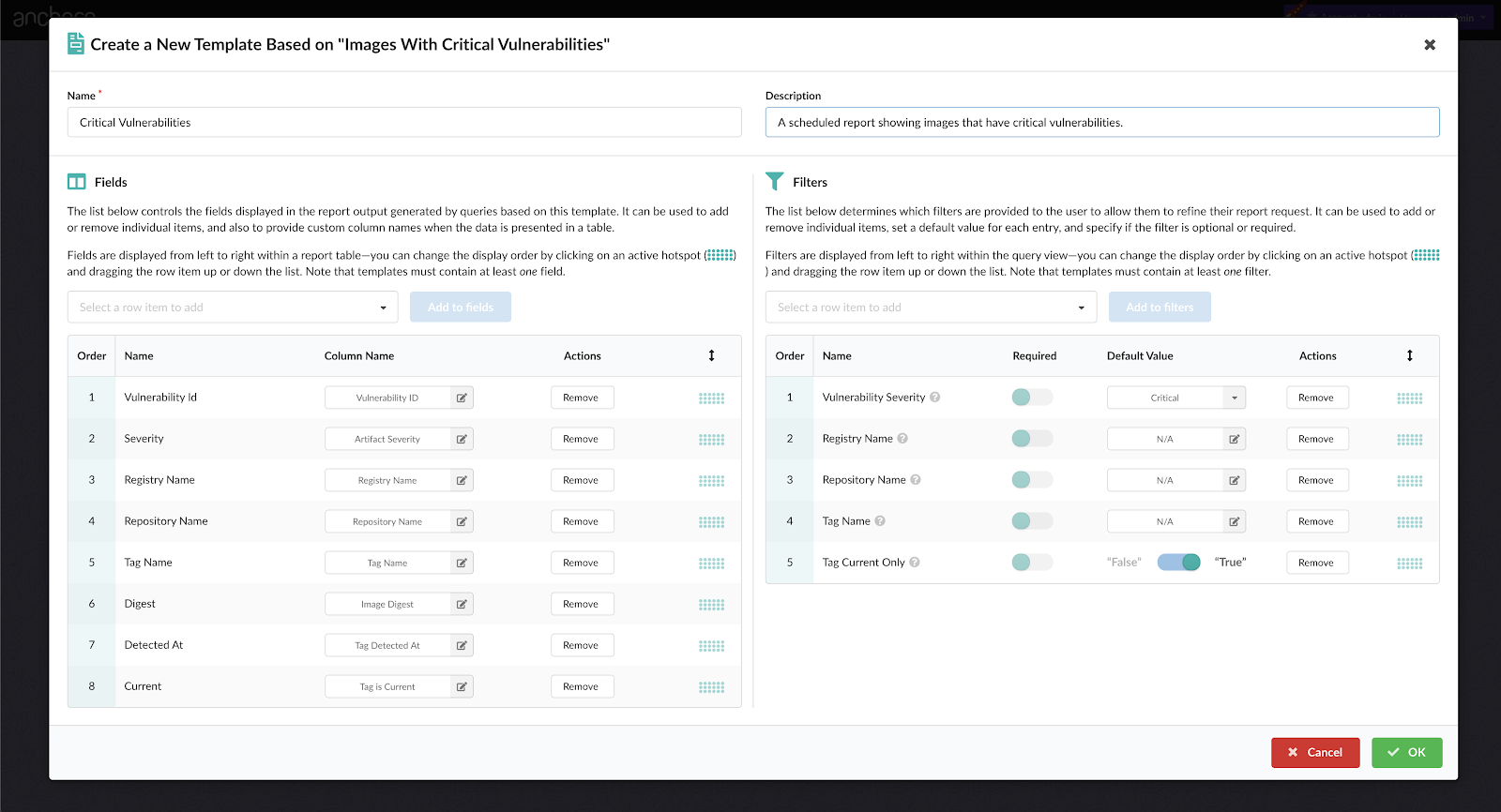
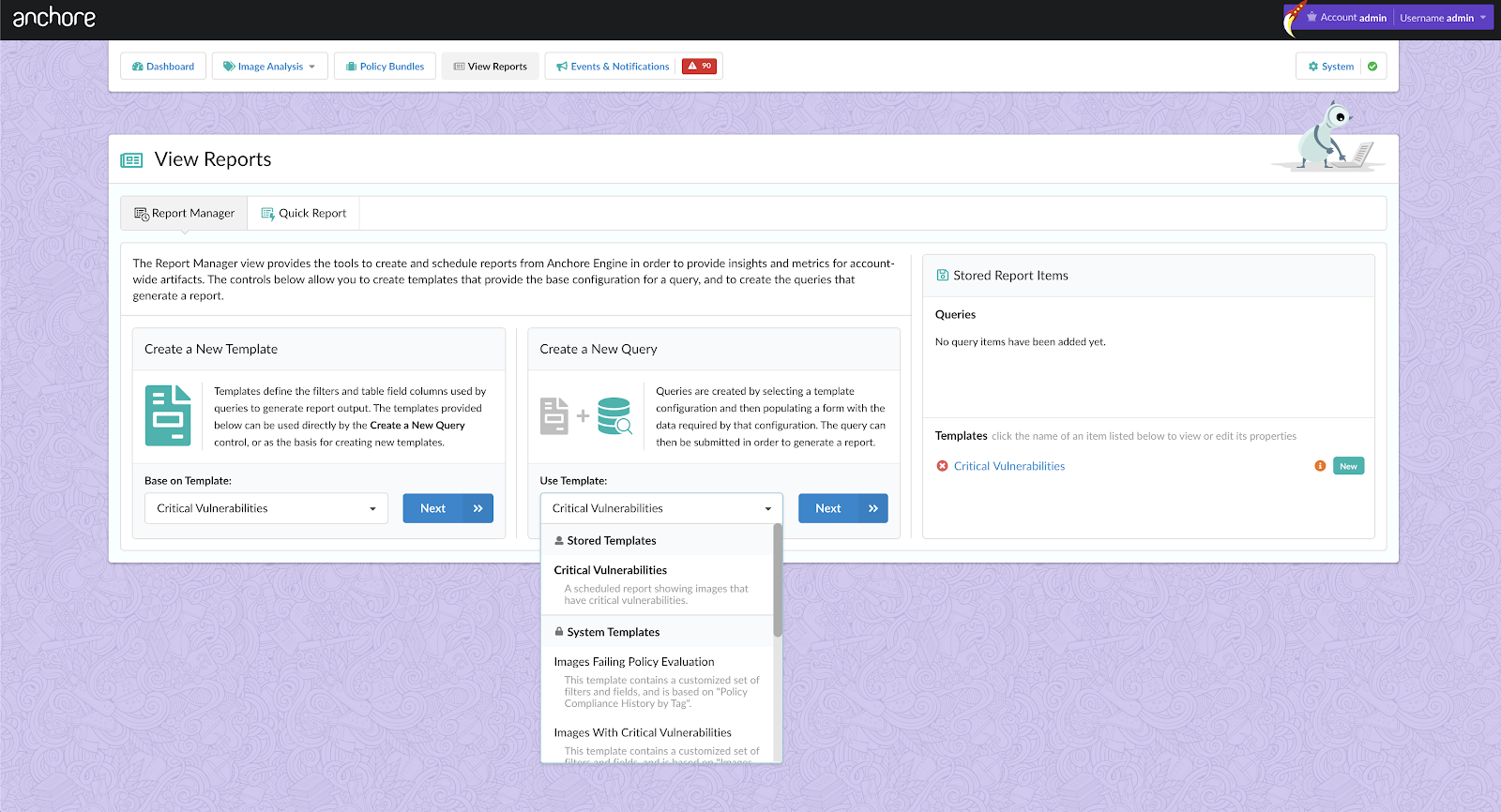
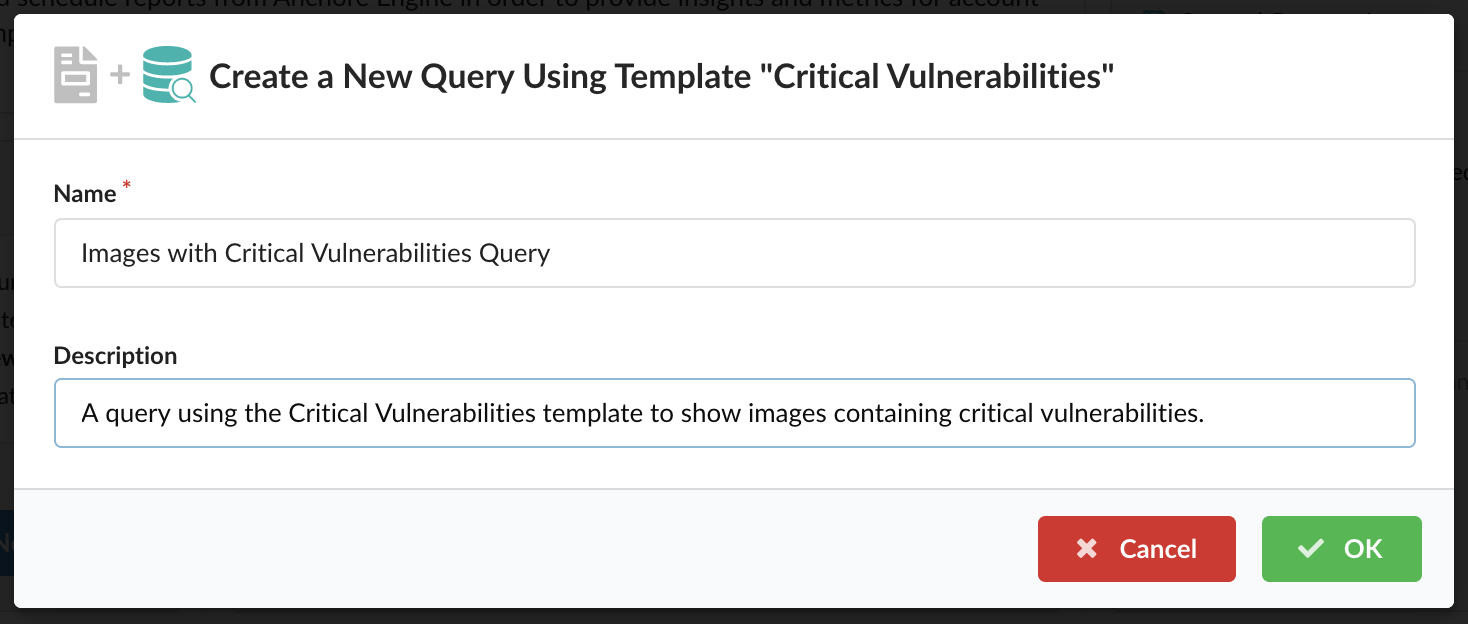

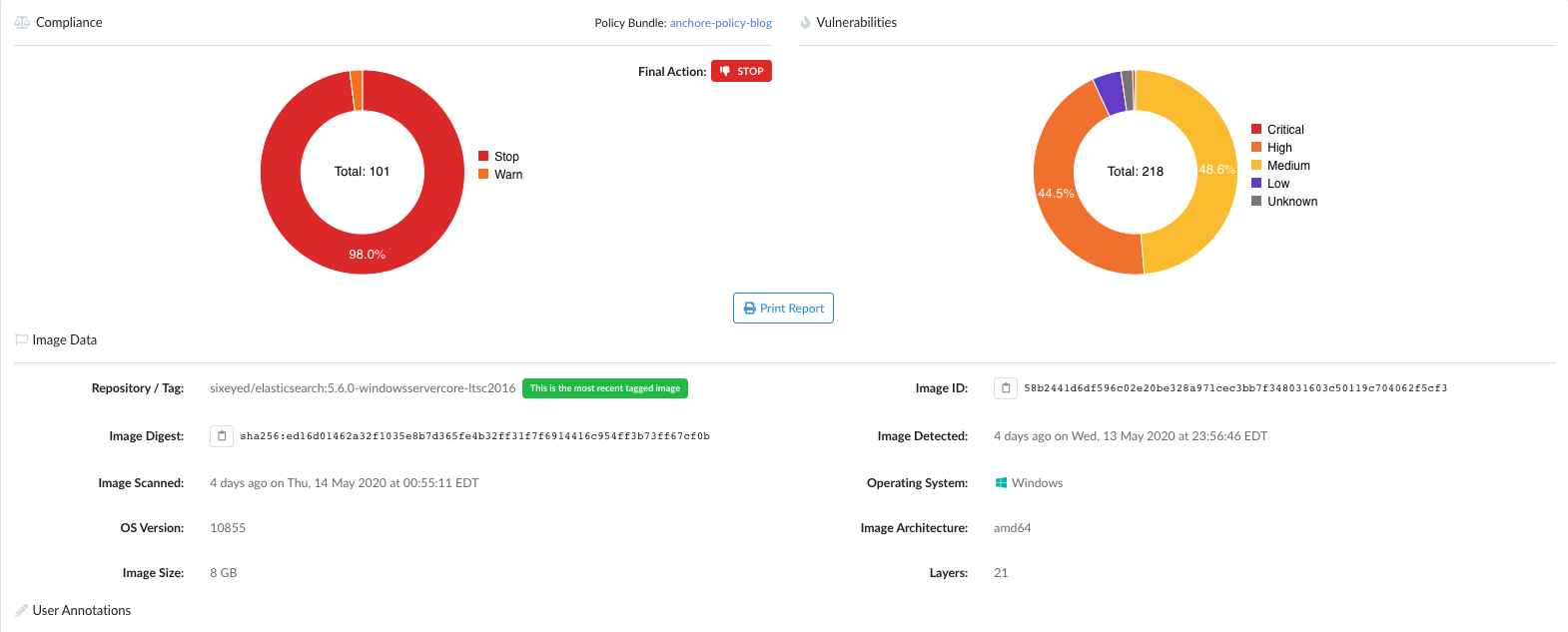
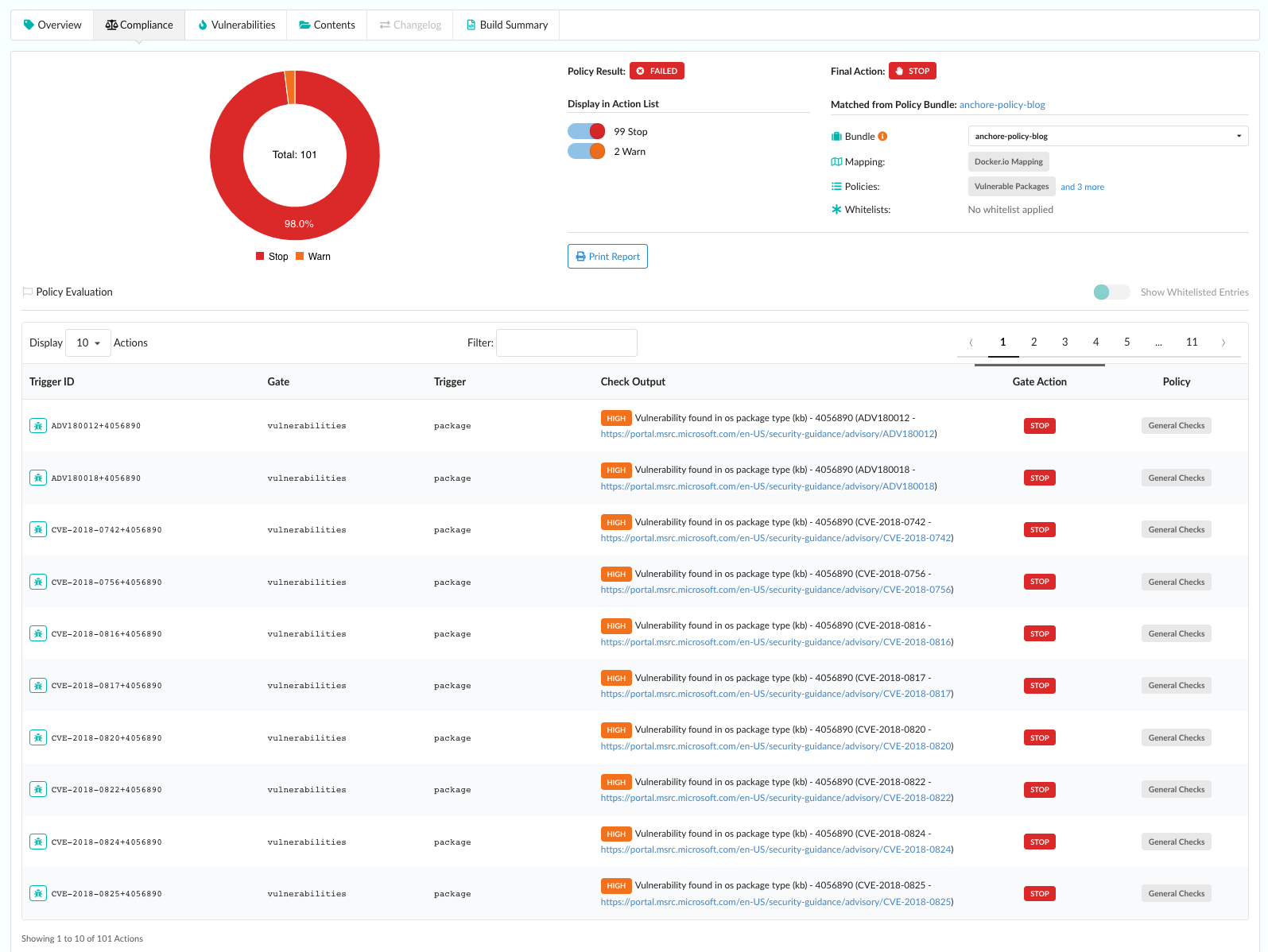
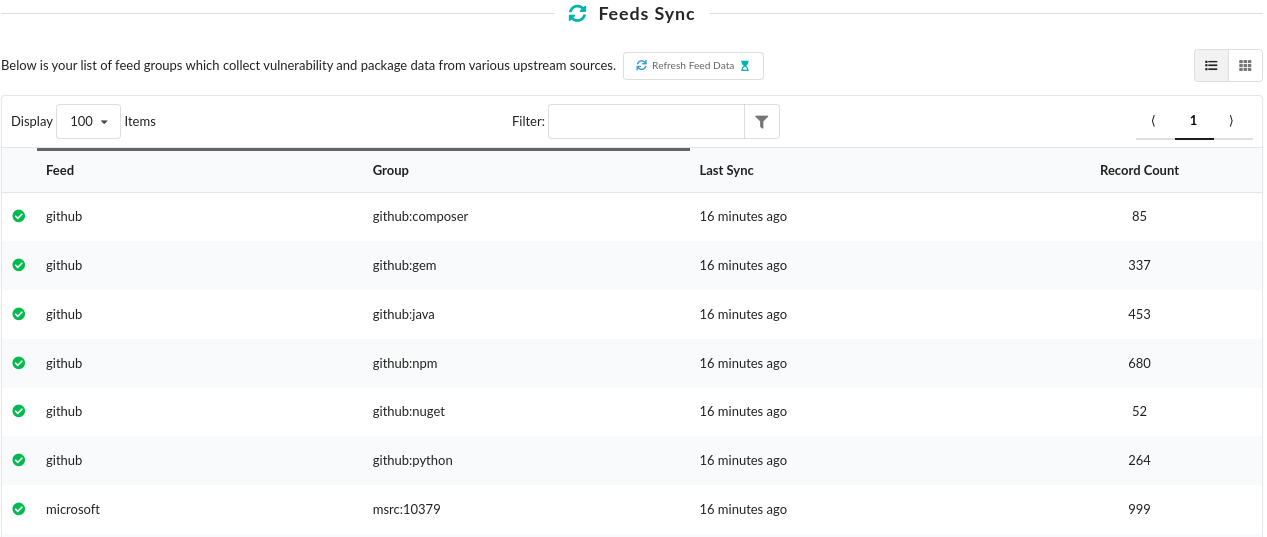
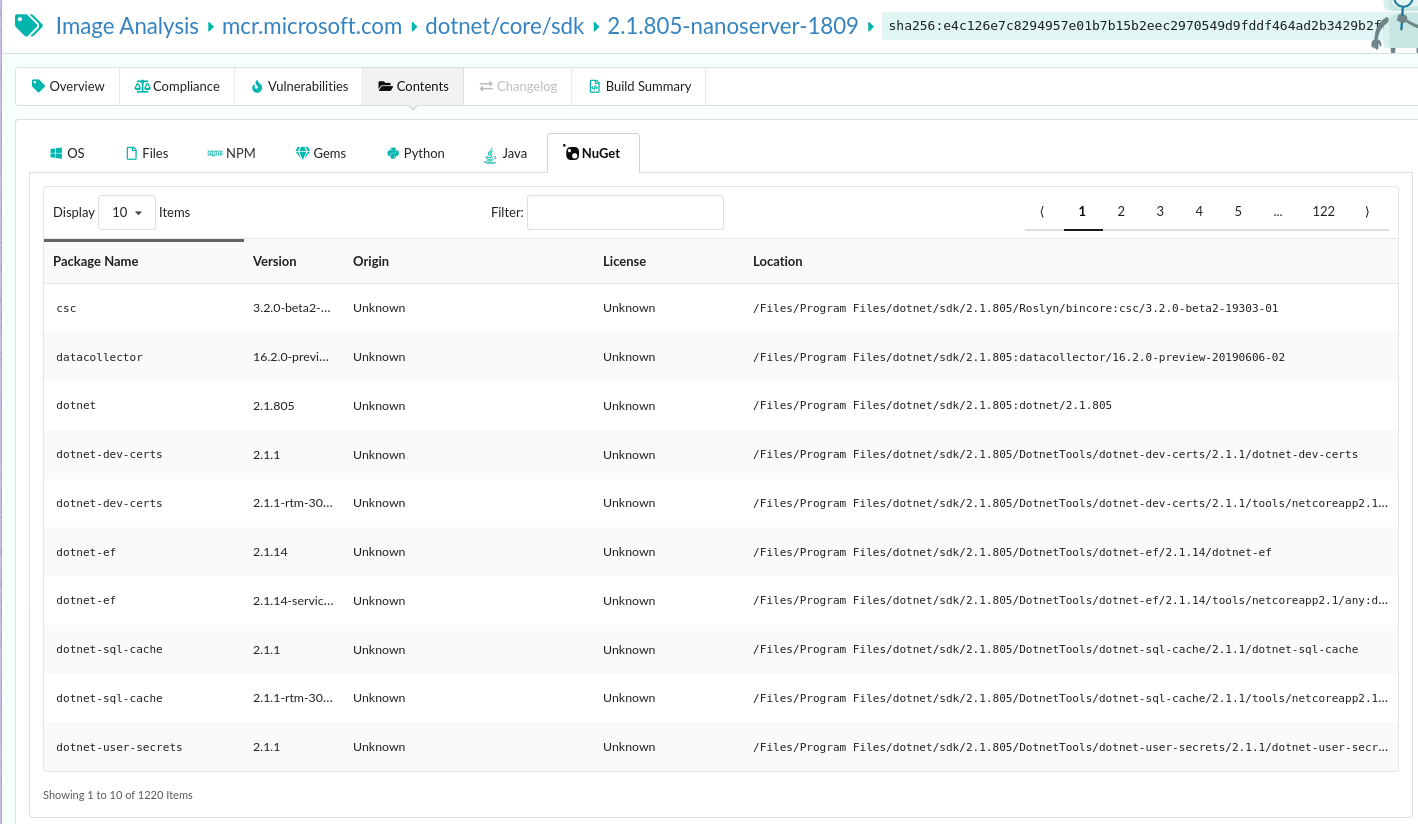



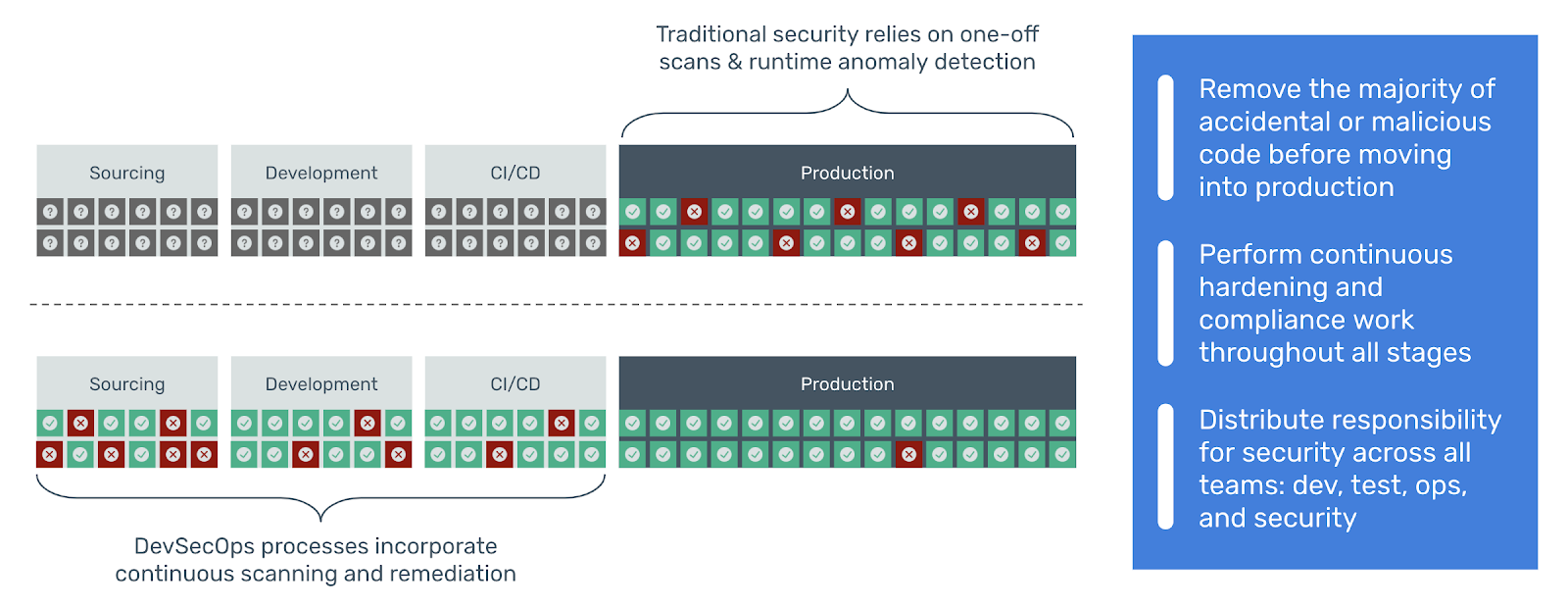
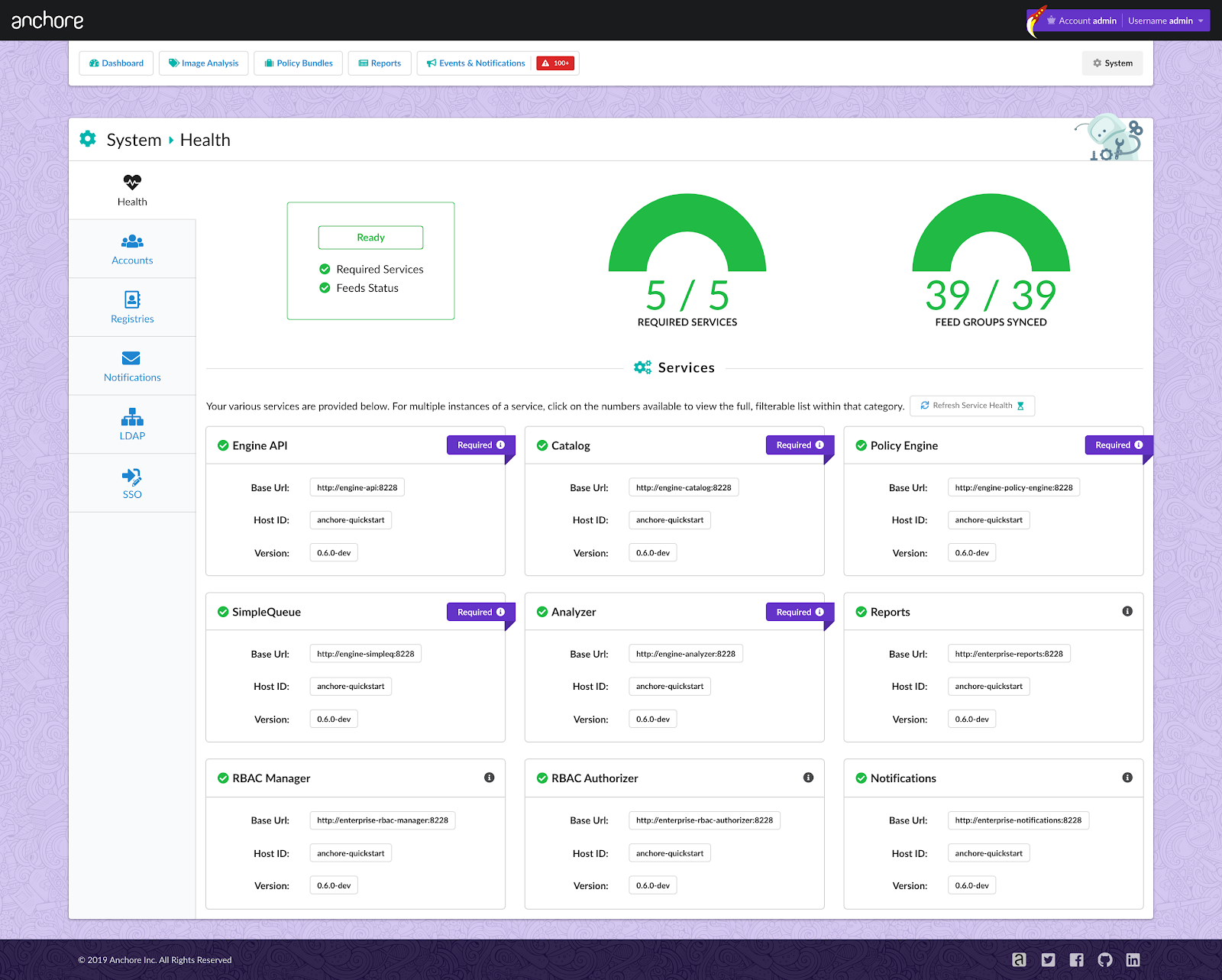
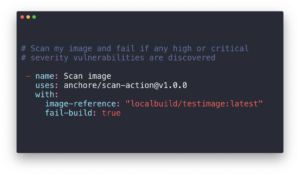 As we announced two days ago, we spent a number of weeks collaborating with GitHub to produce our
As we announced two days ago, we spent a number of weeks collaborating with GitHub to produce our 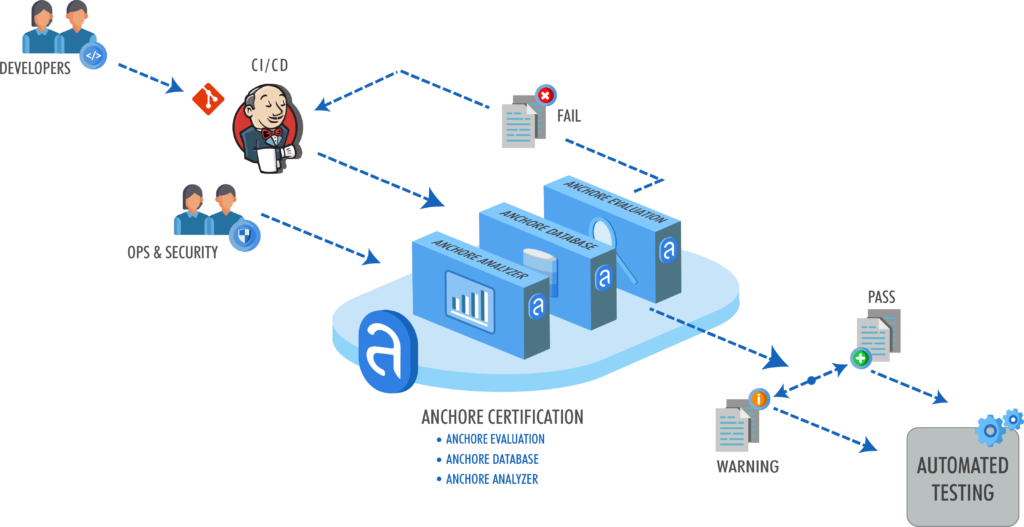

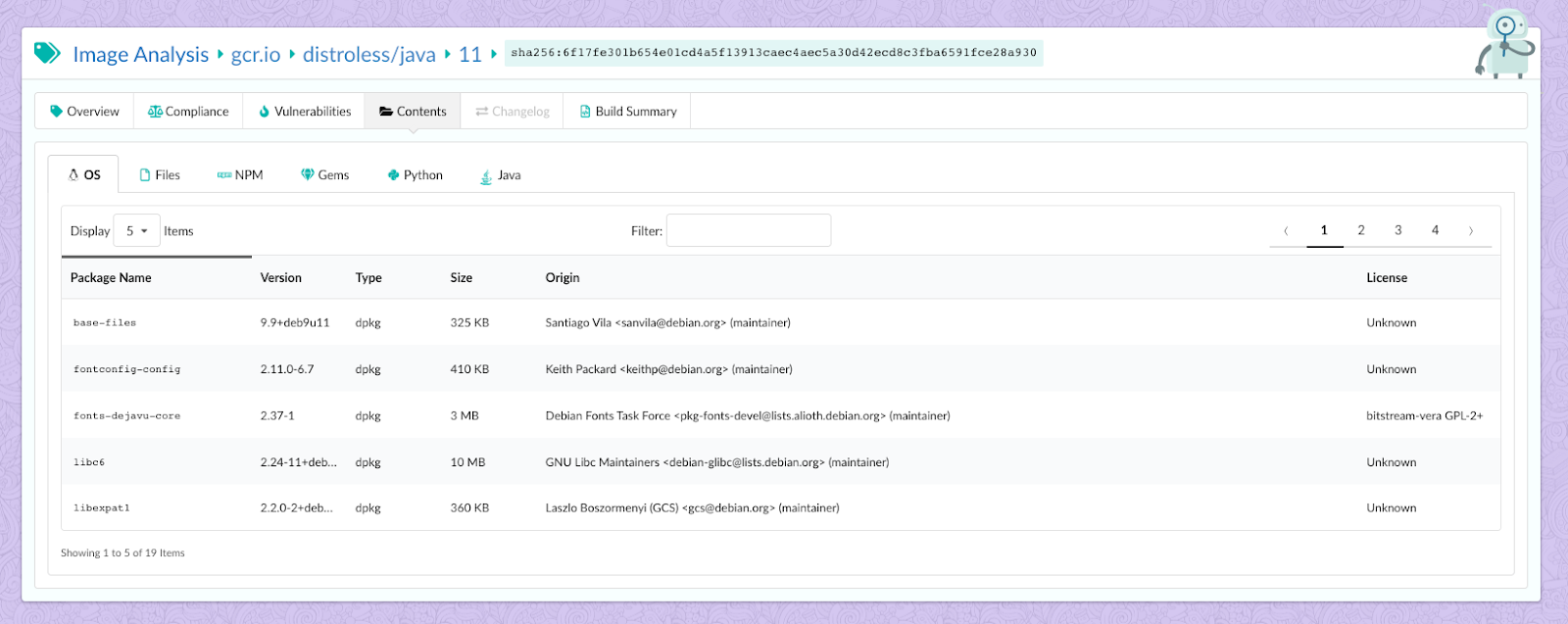

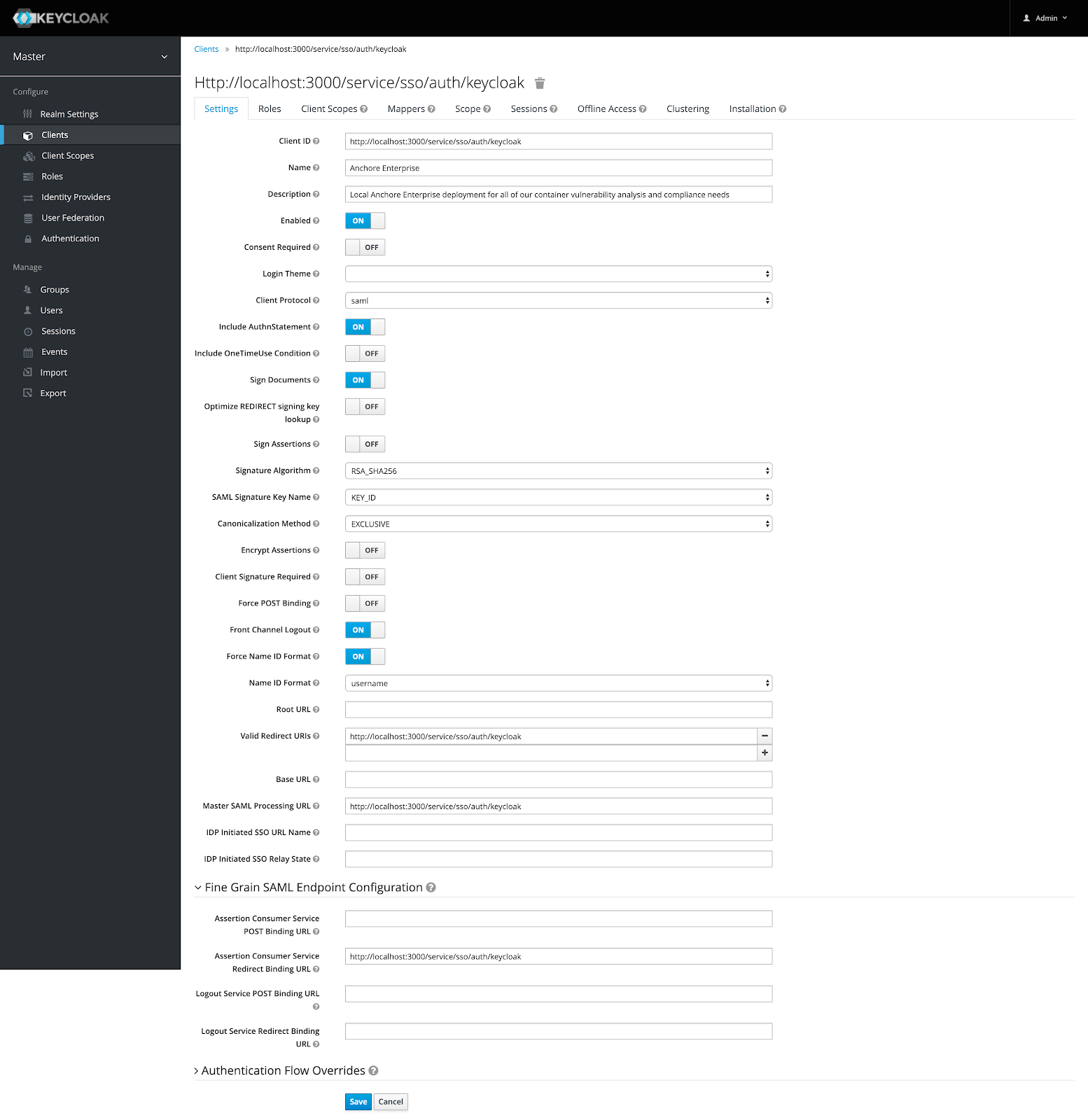
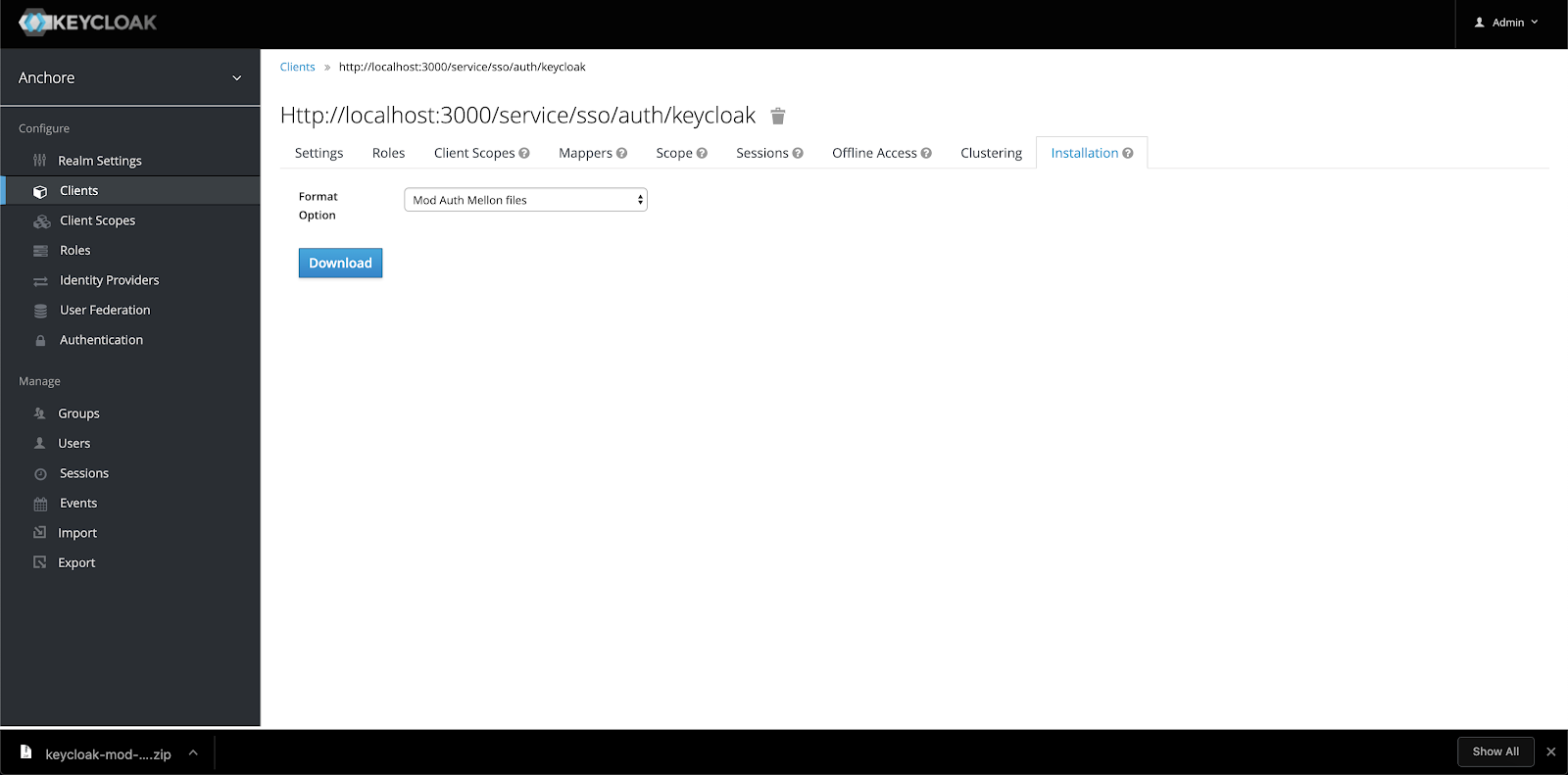
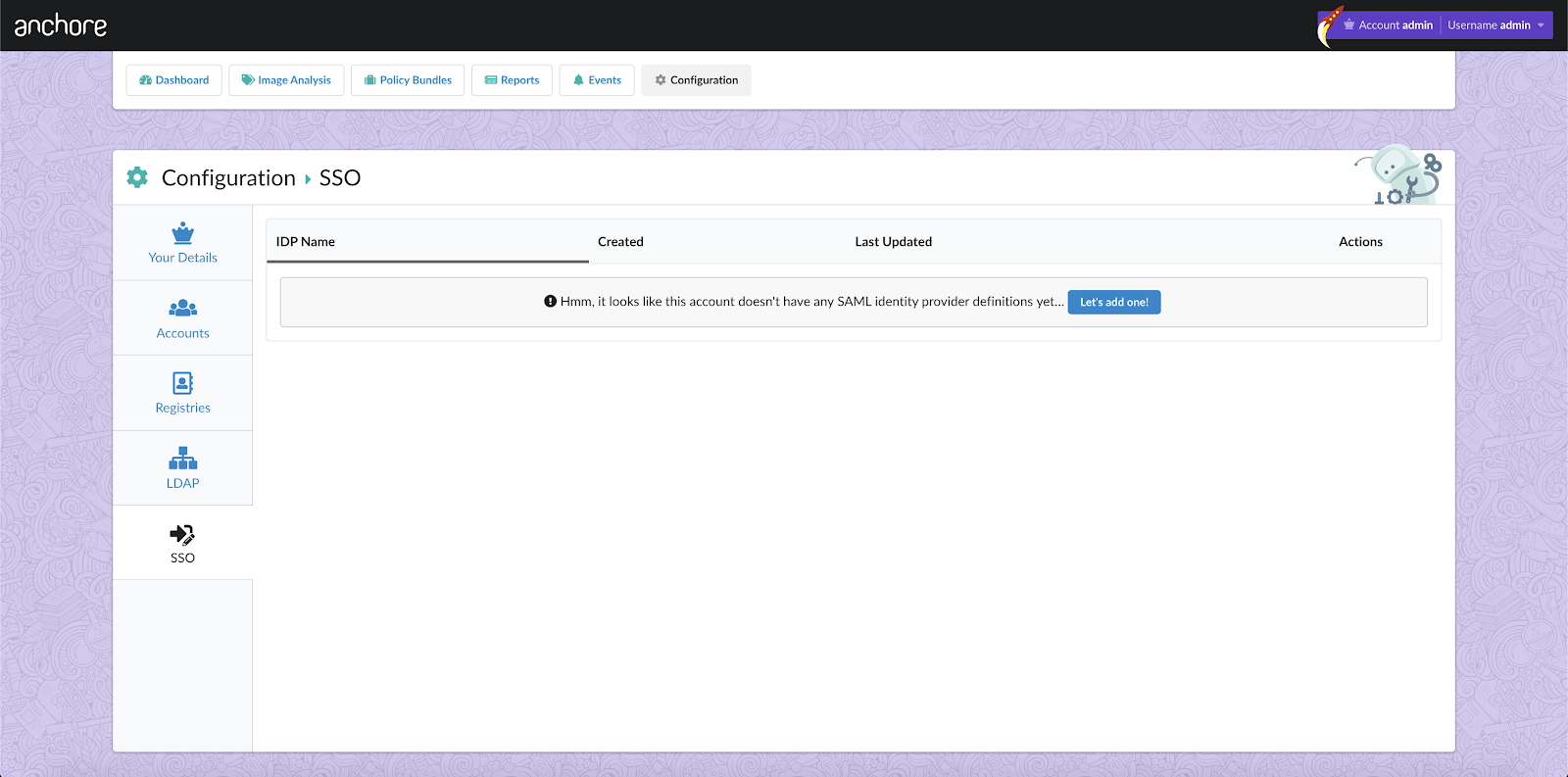
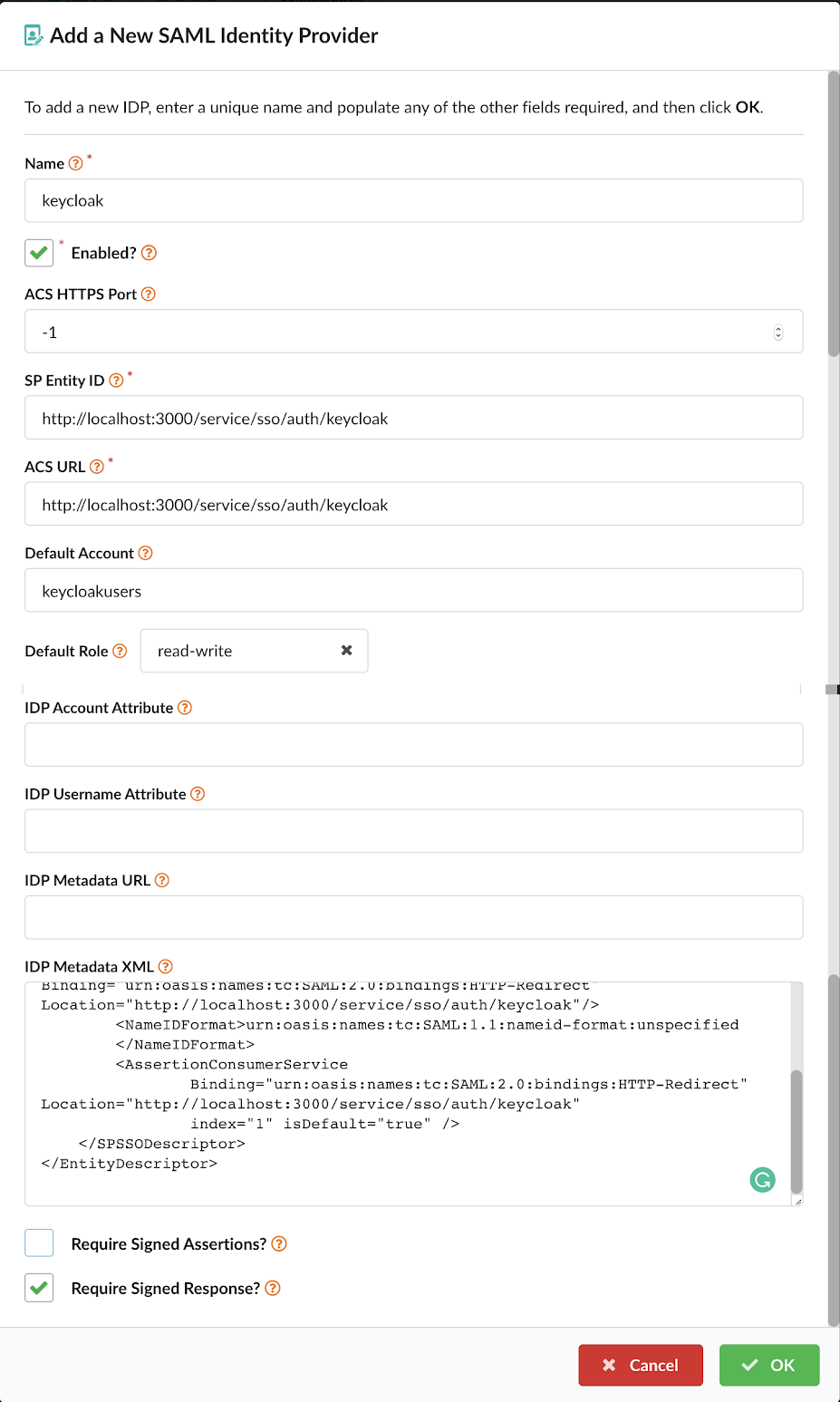
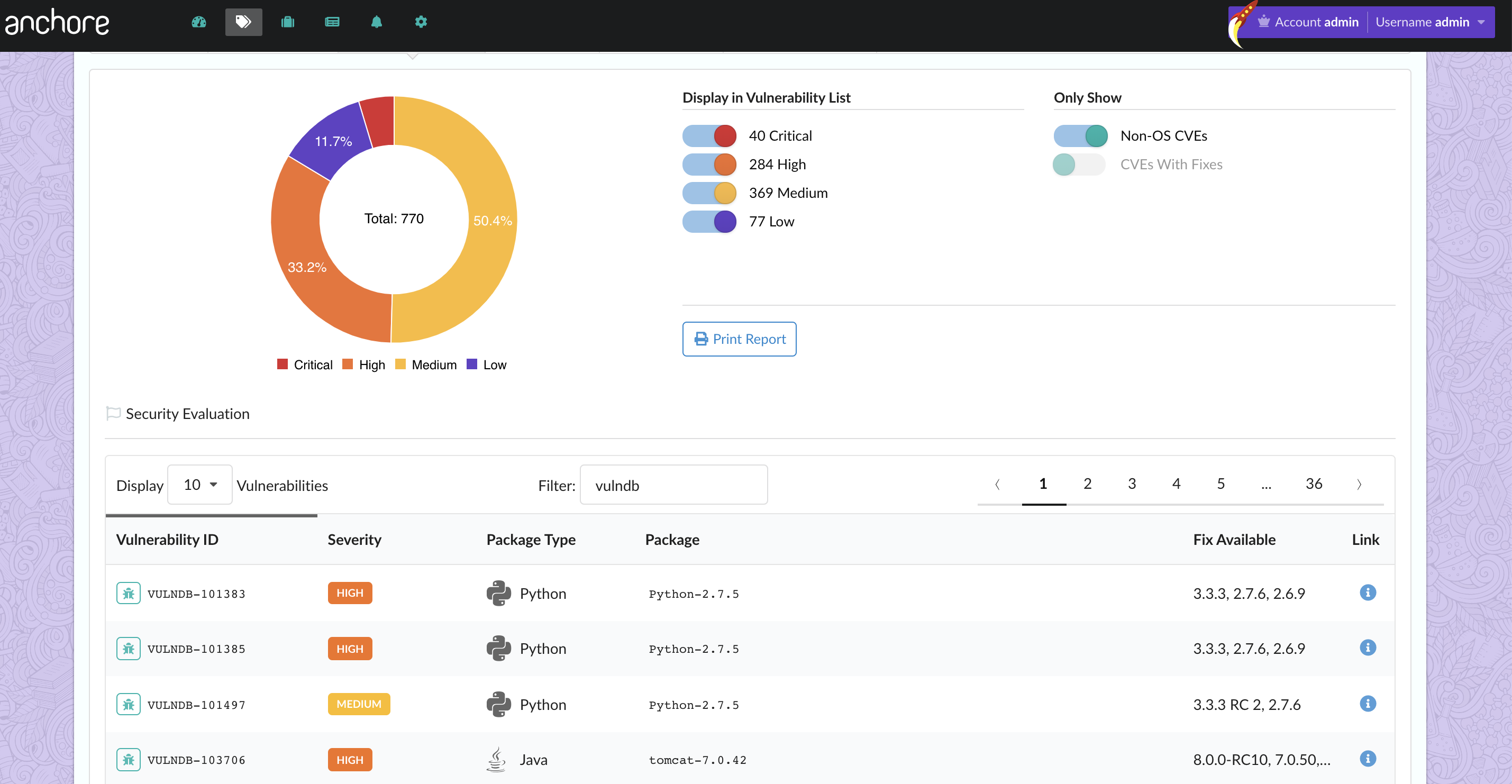
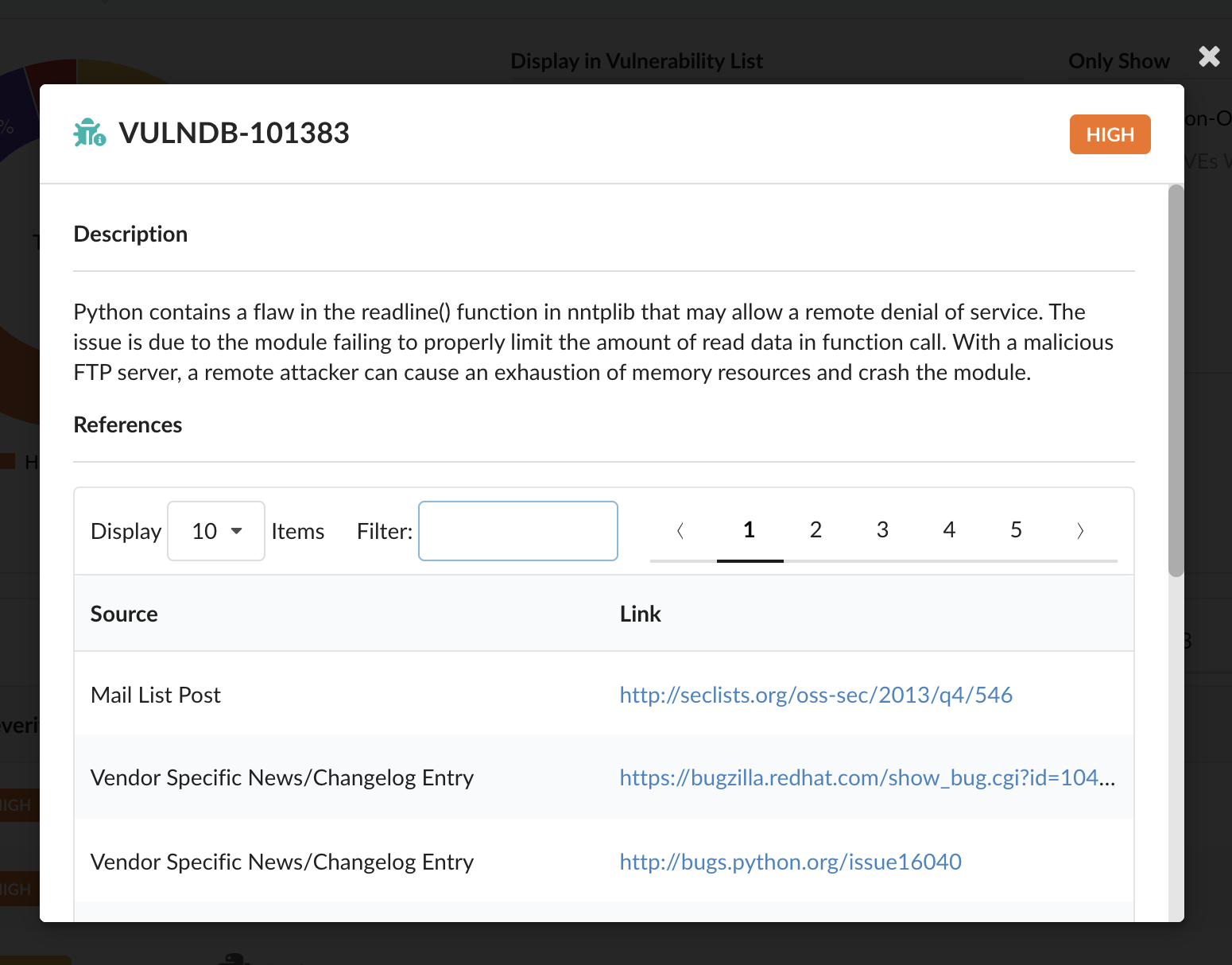
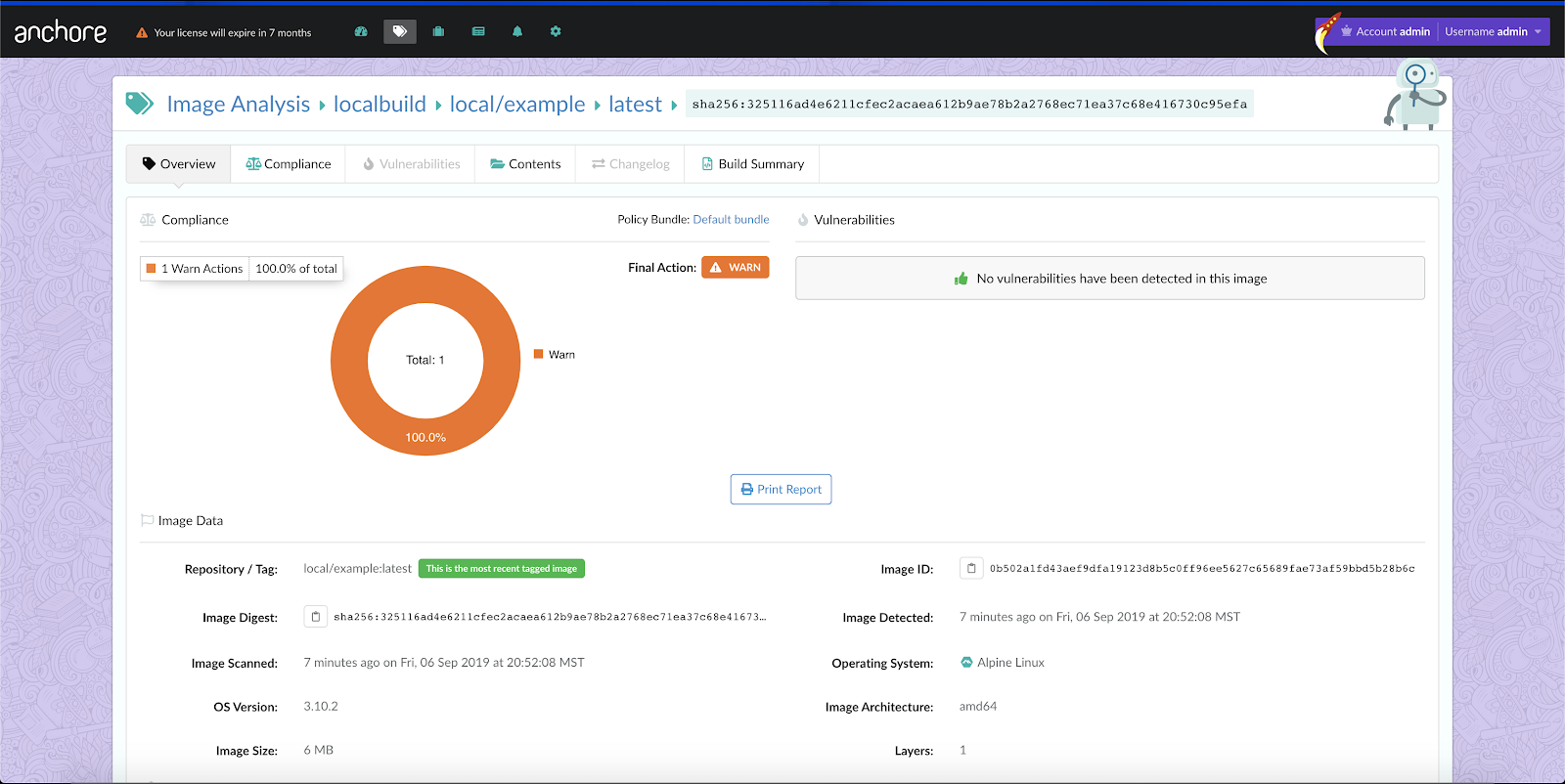
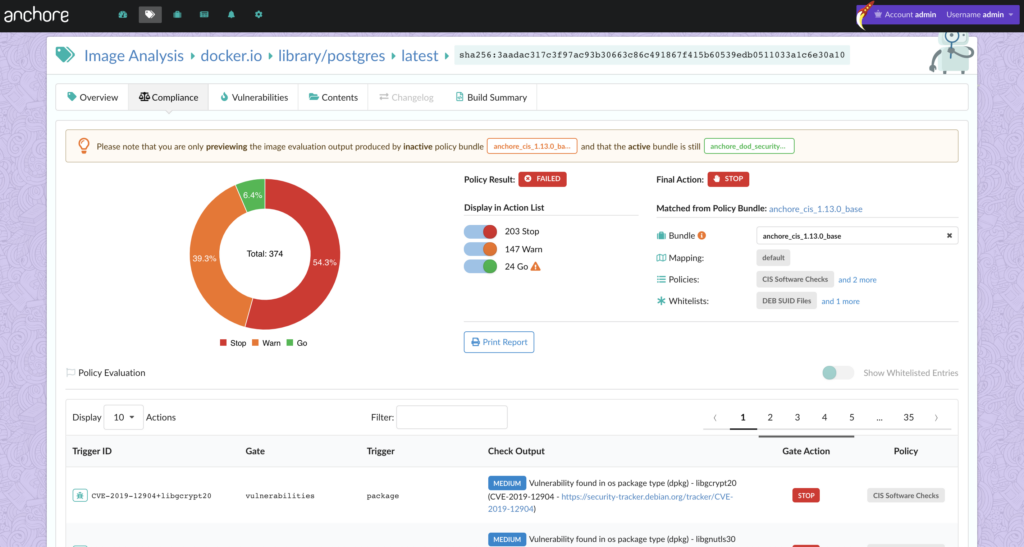


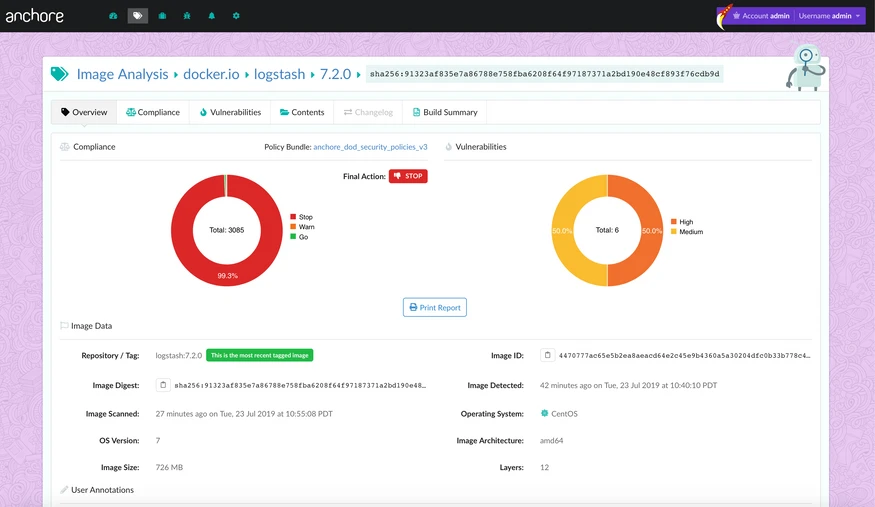
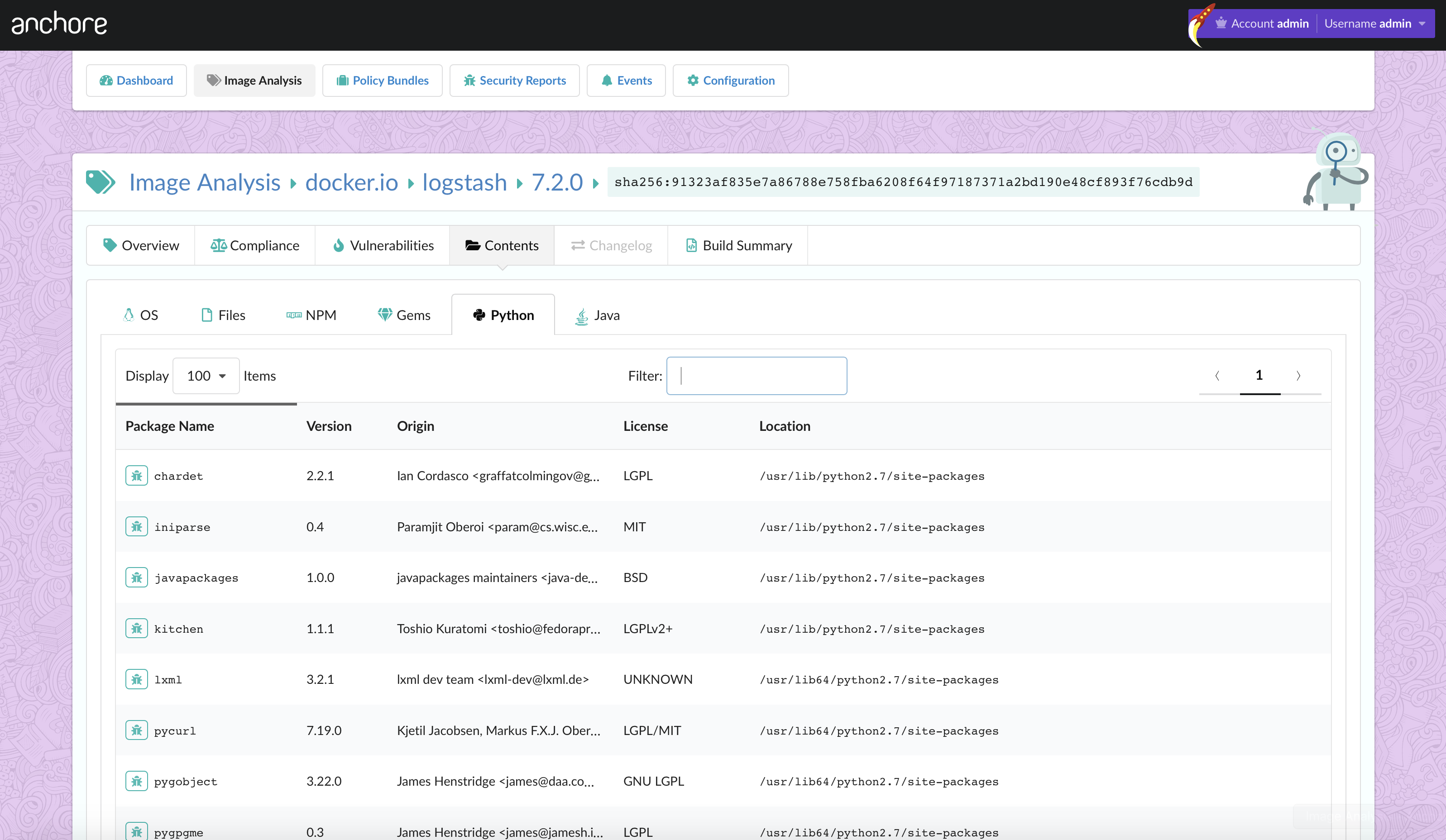
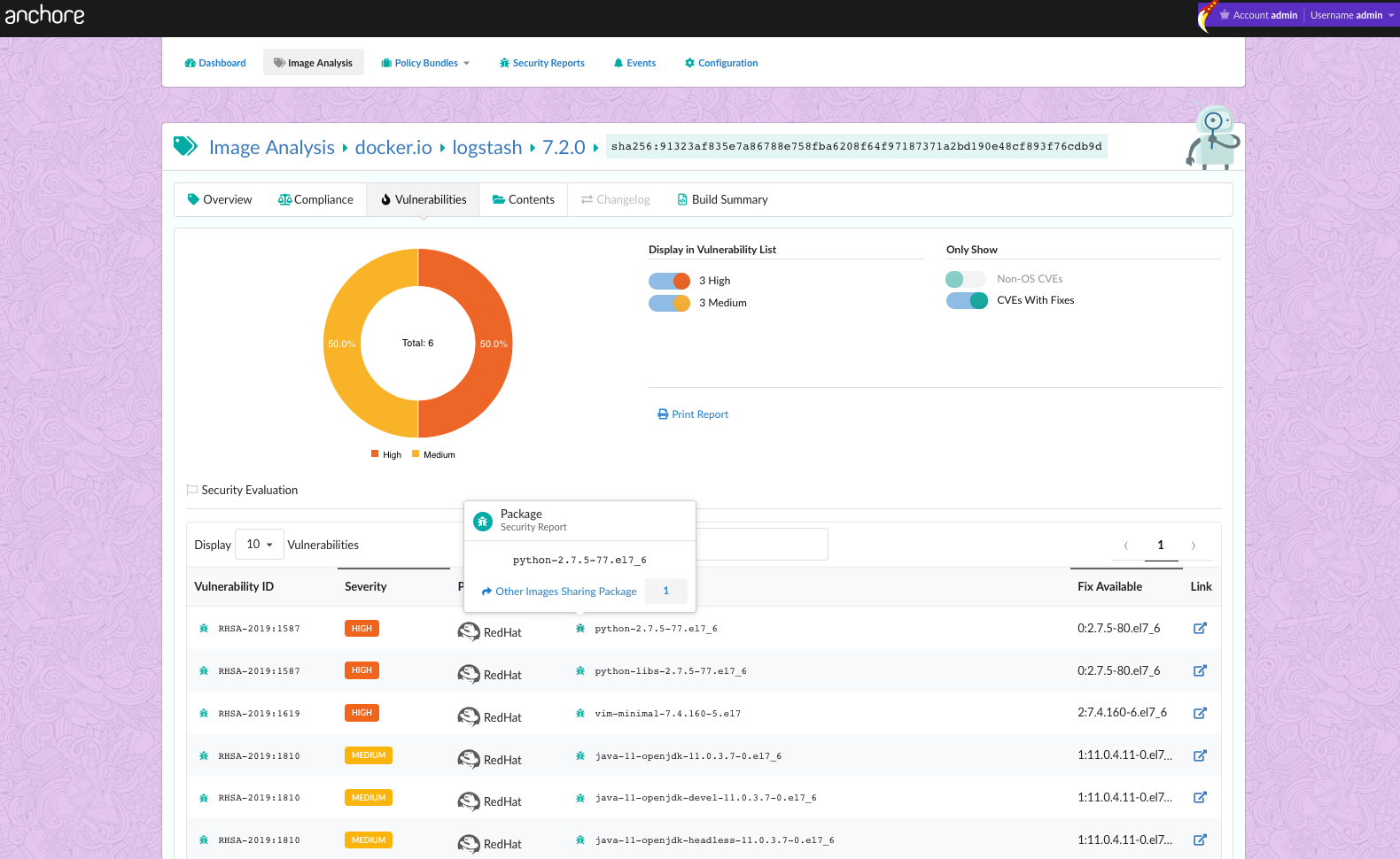
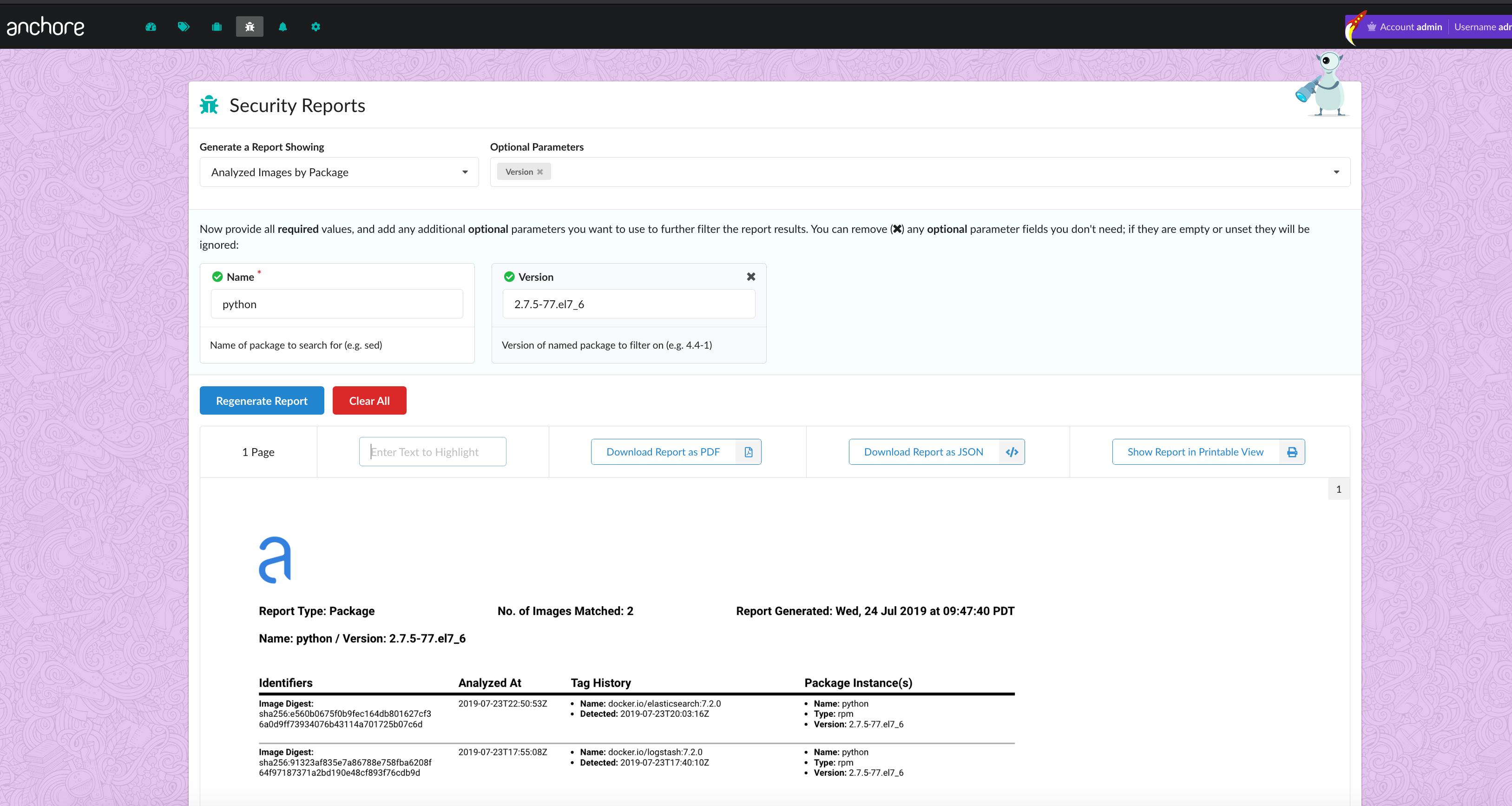
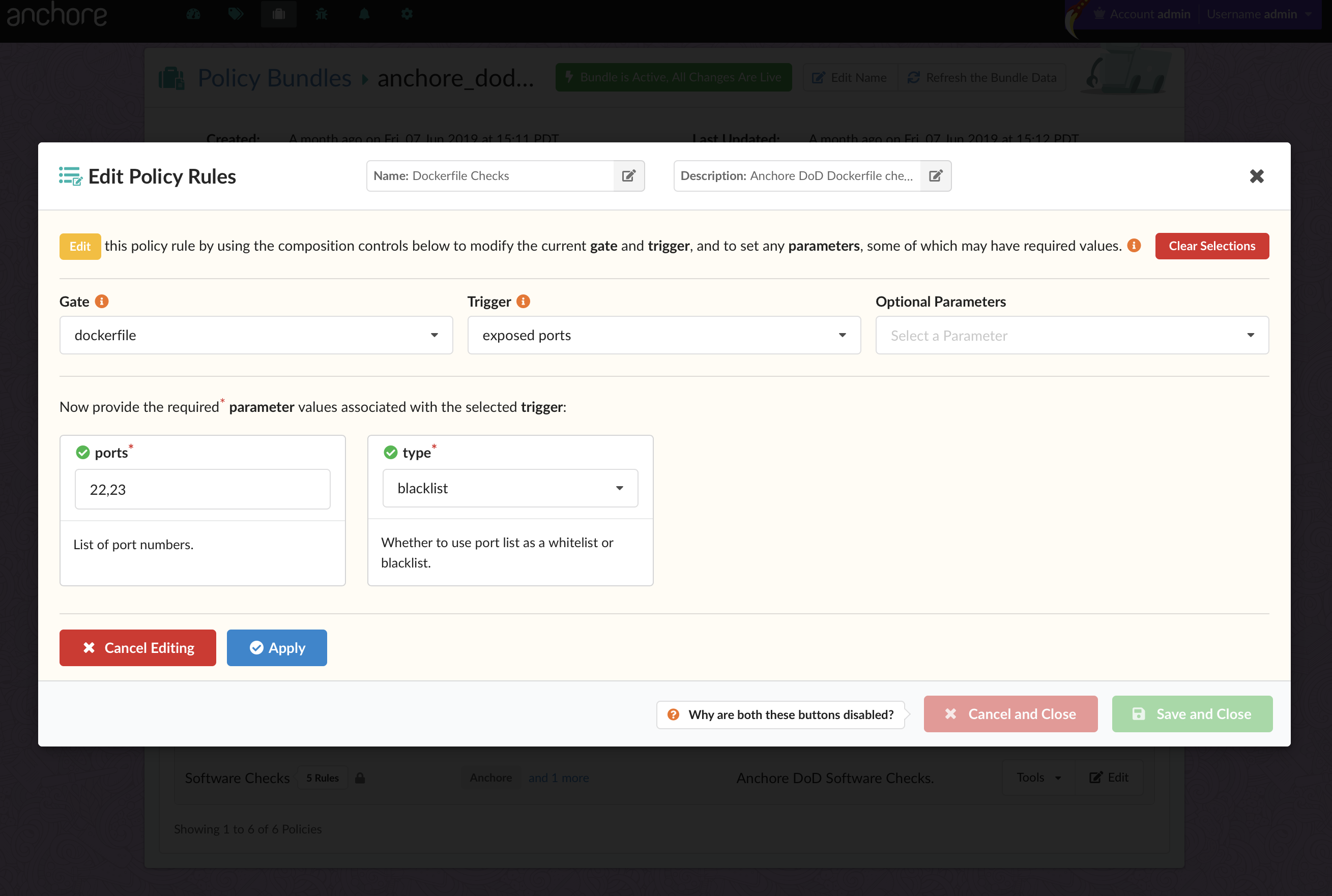
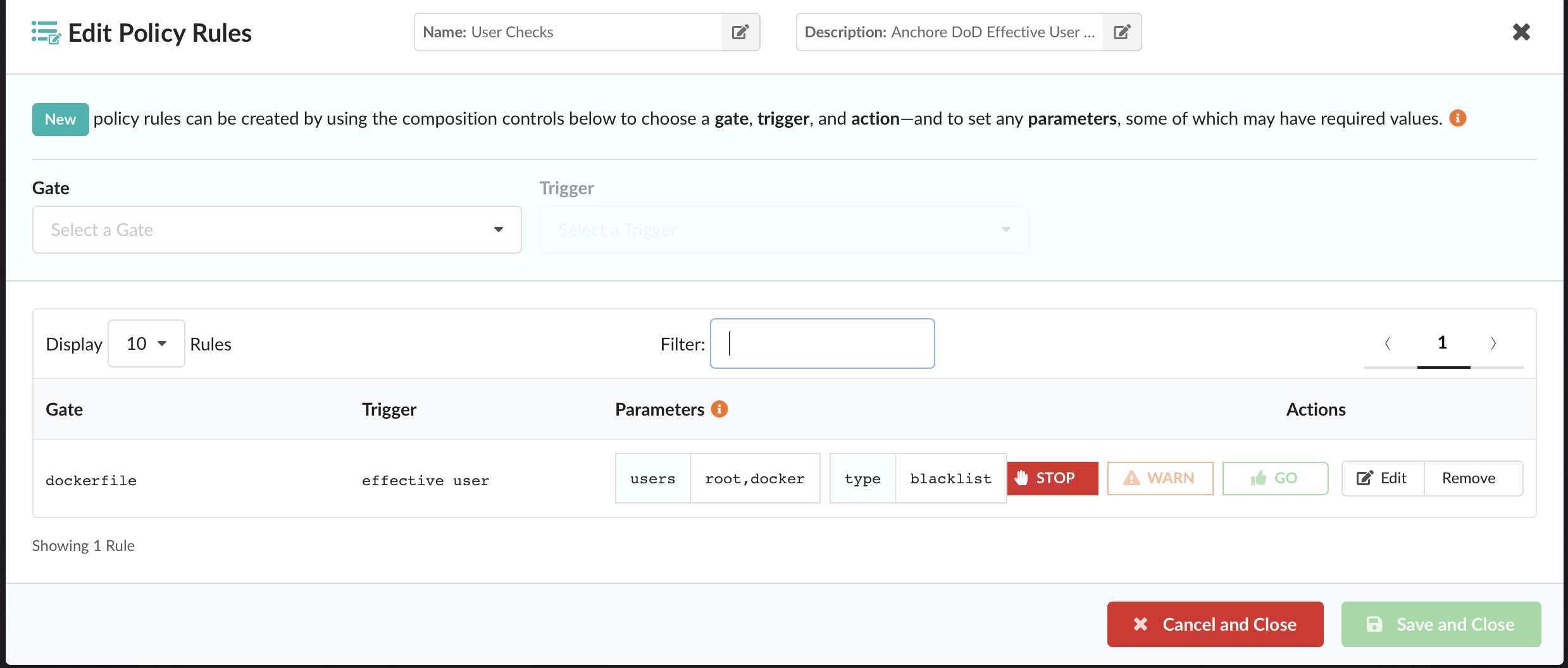

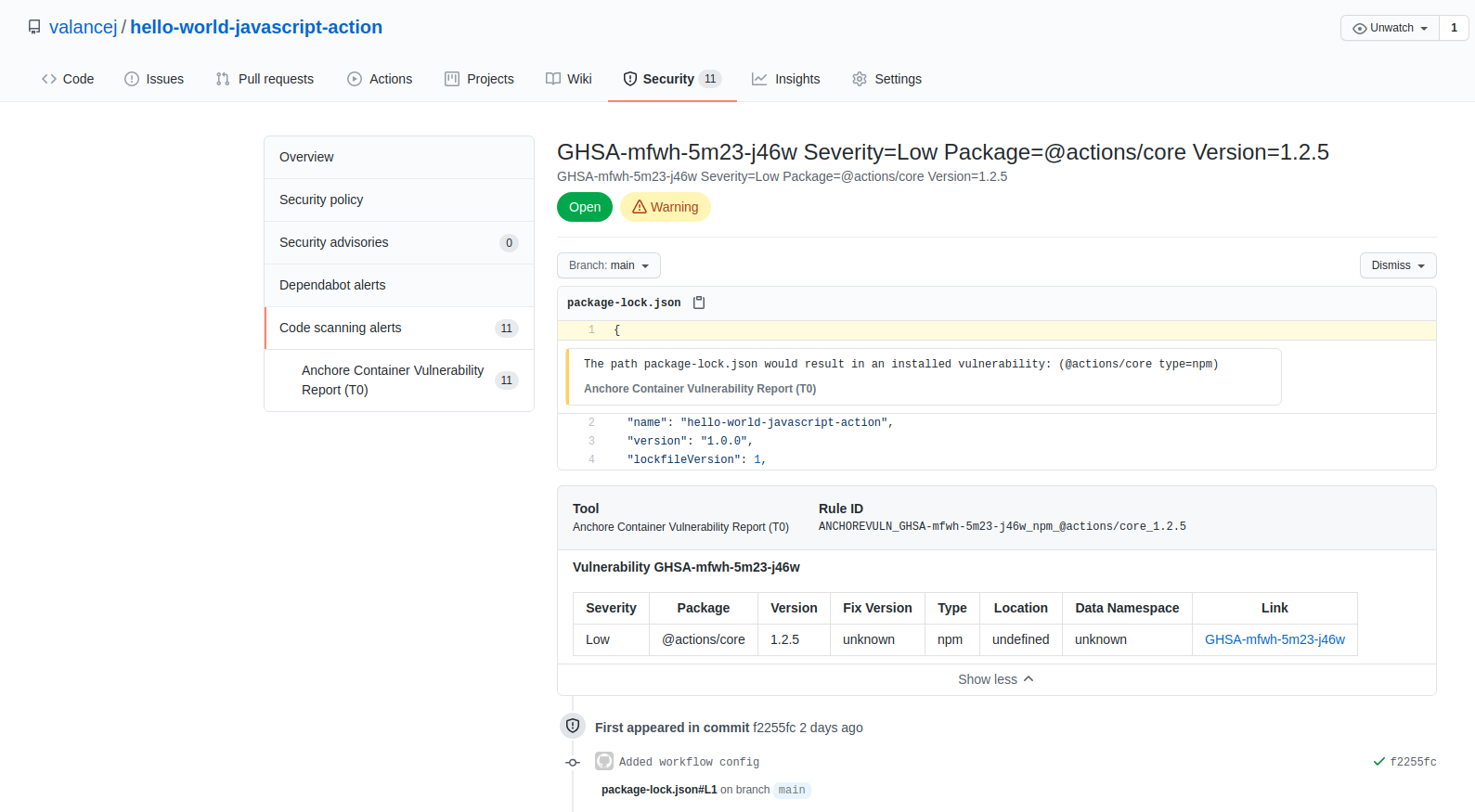
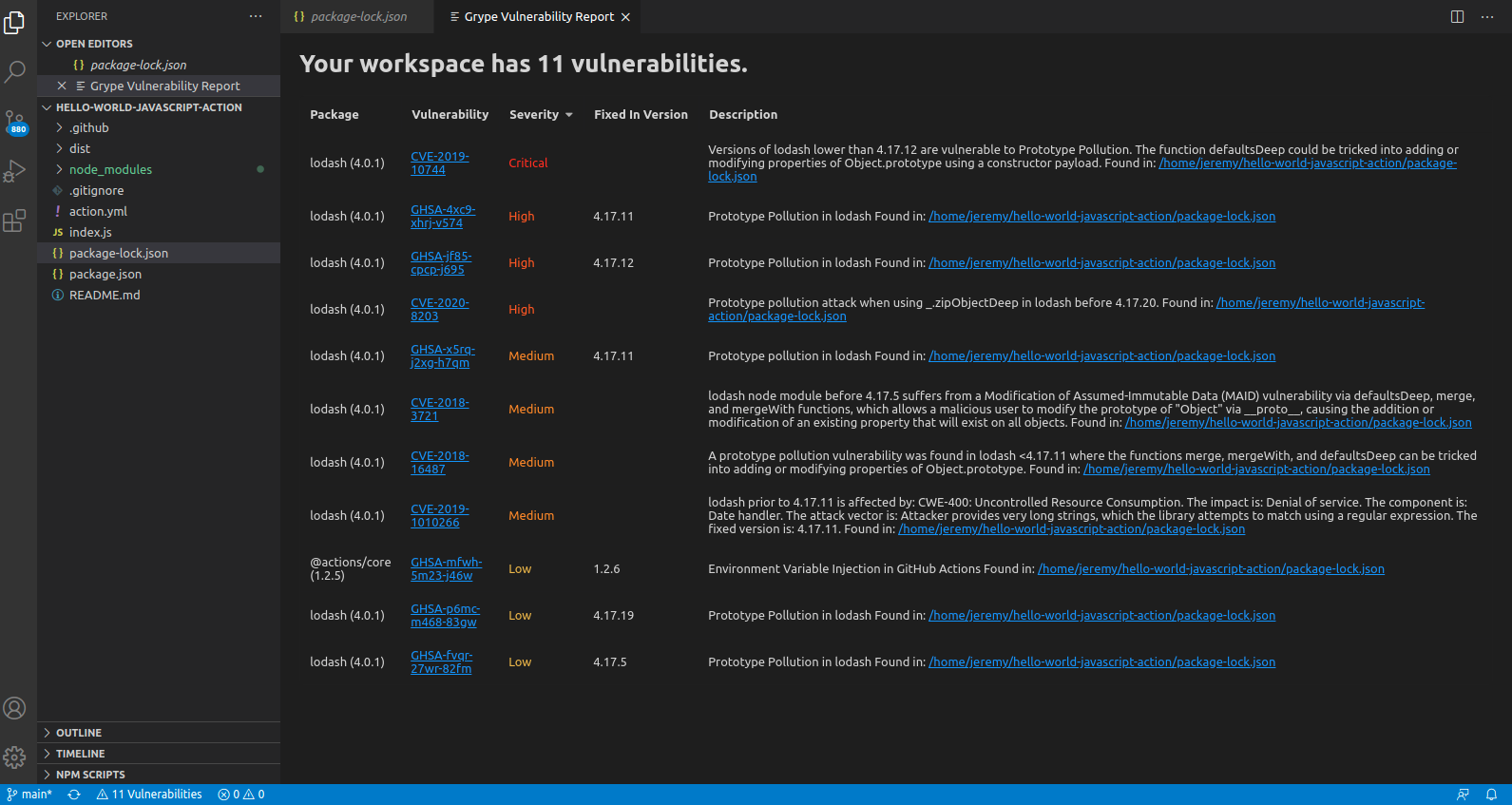
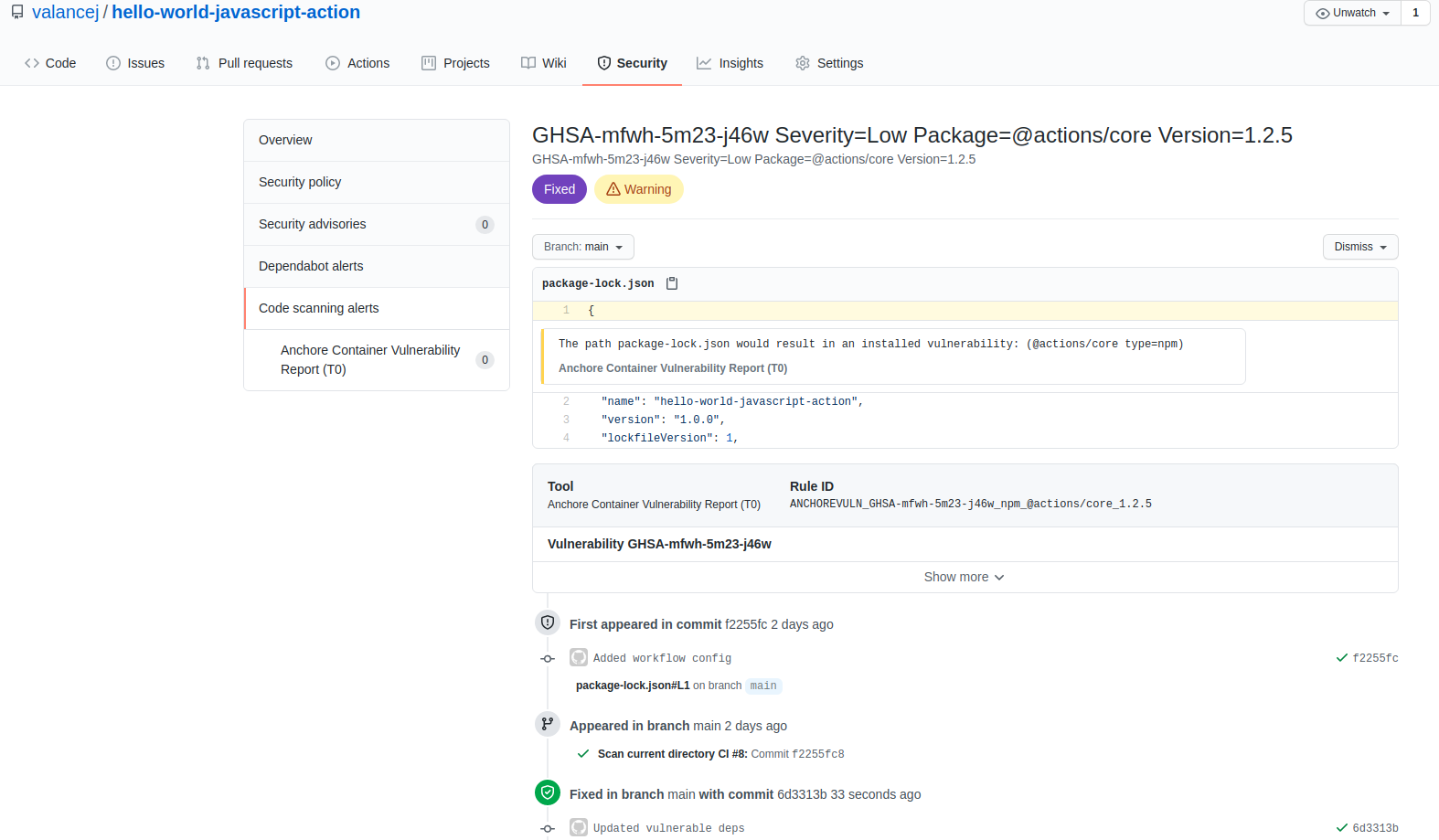
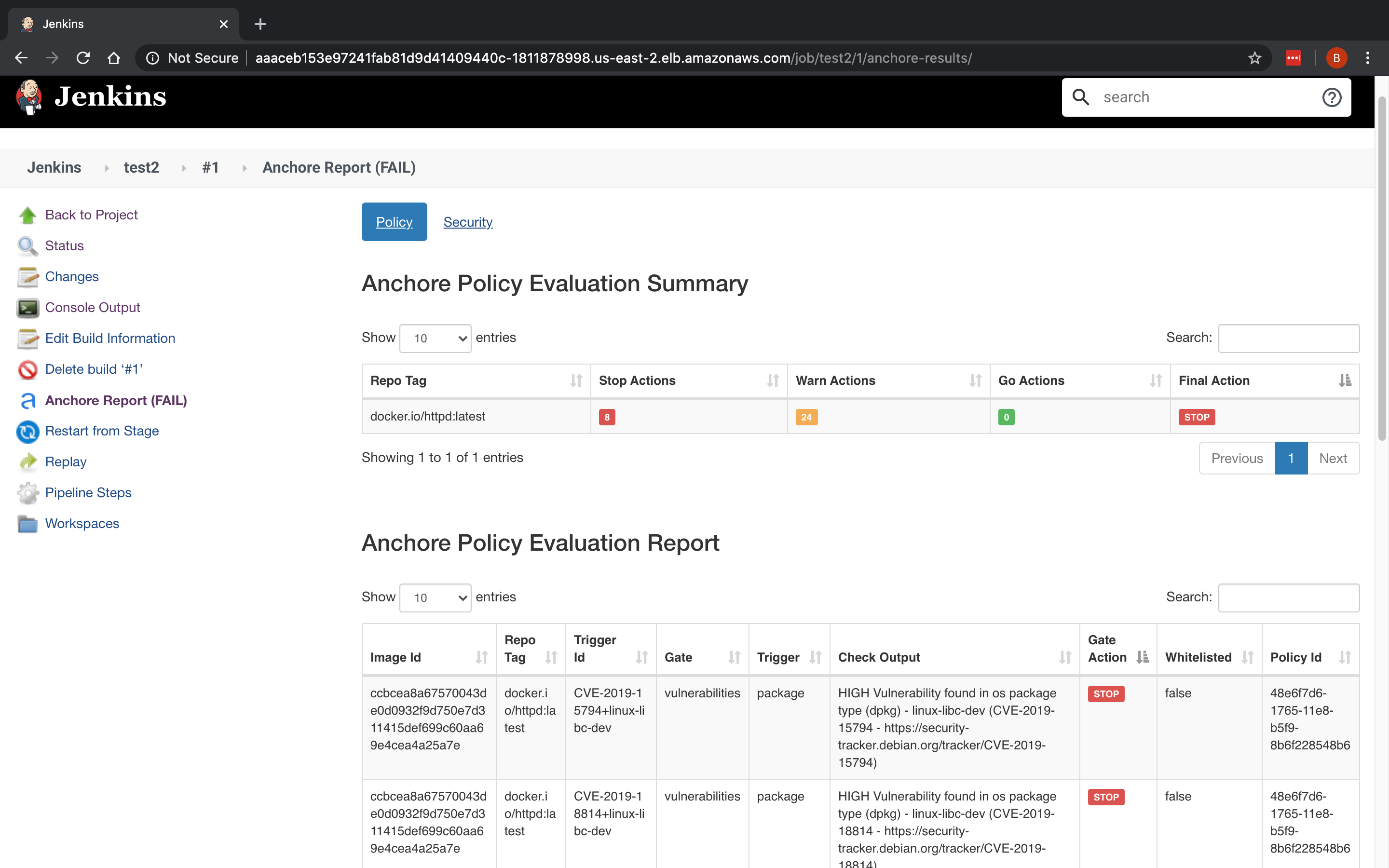
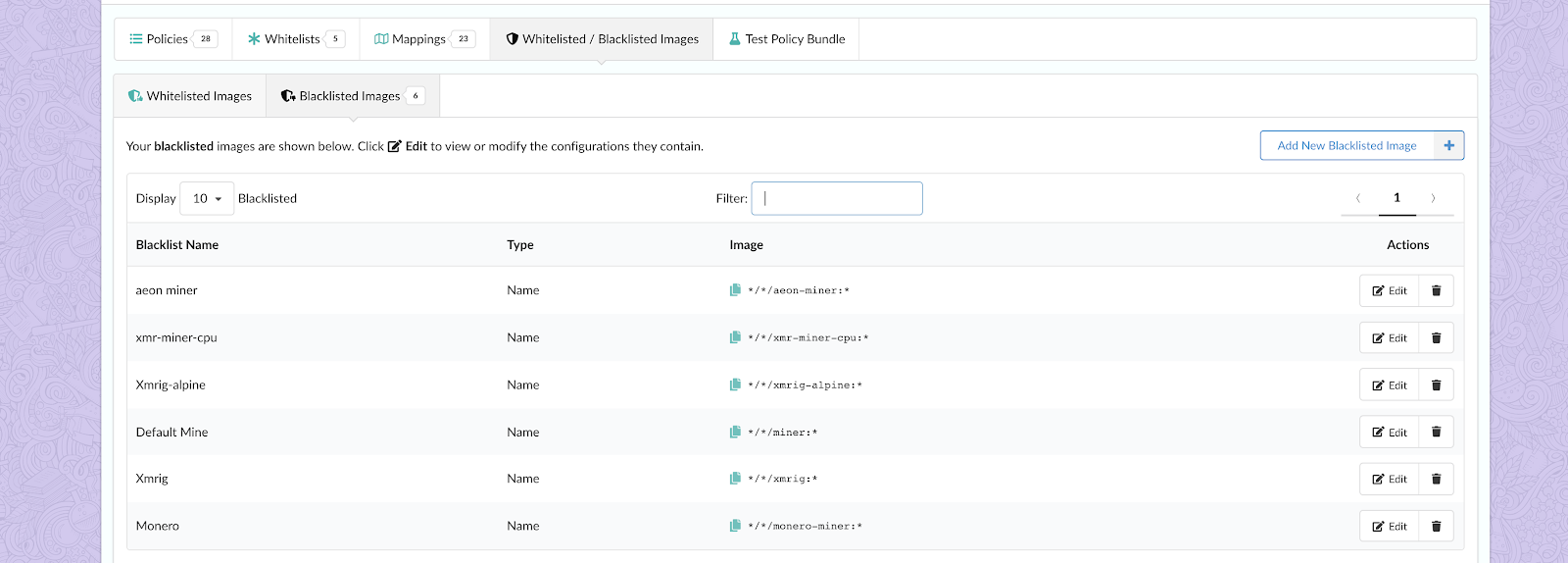
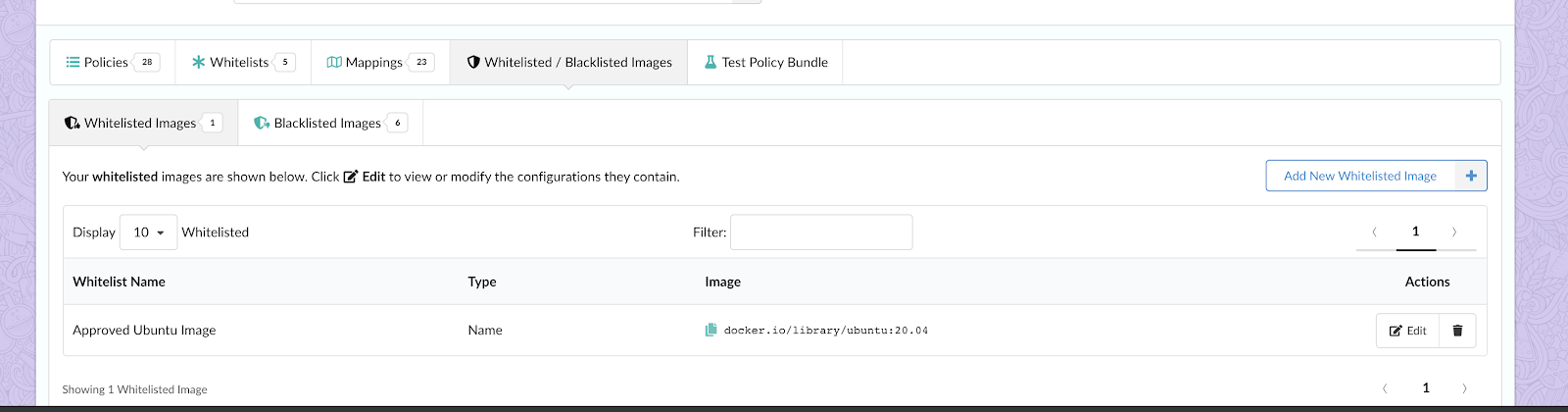
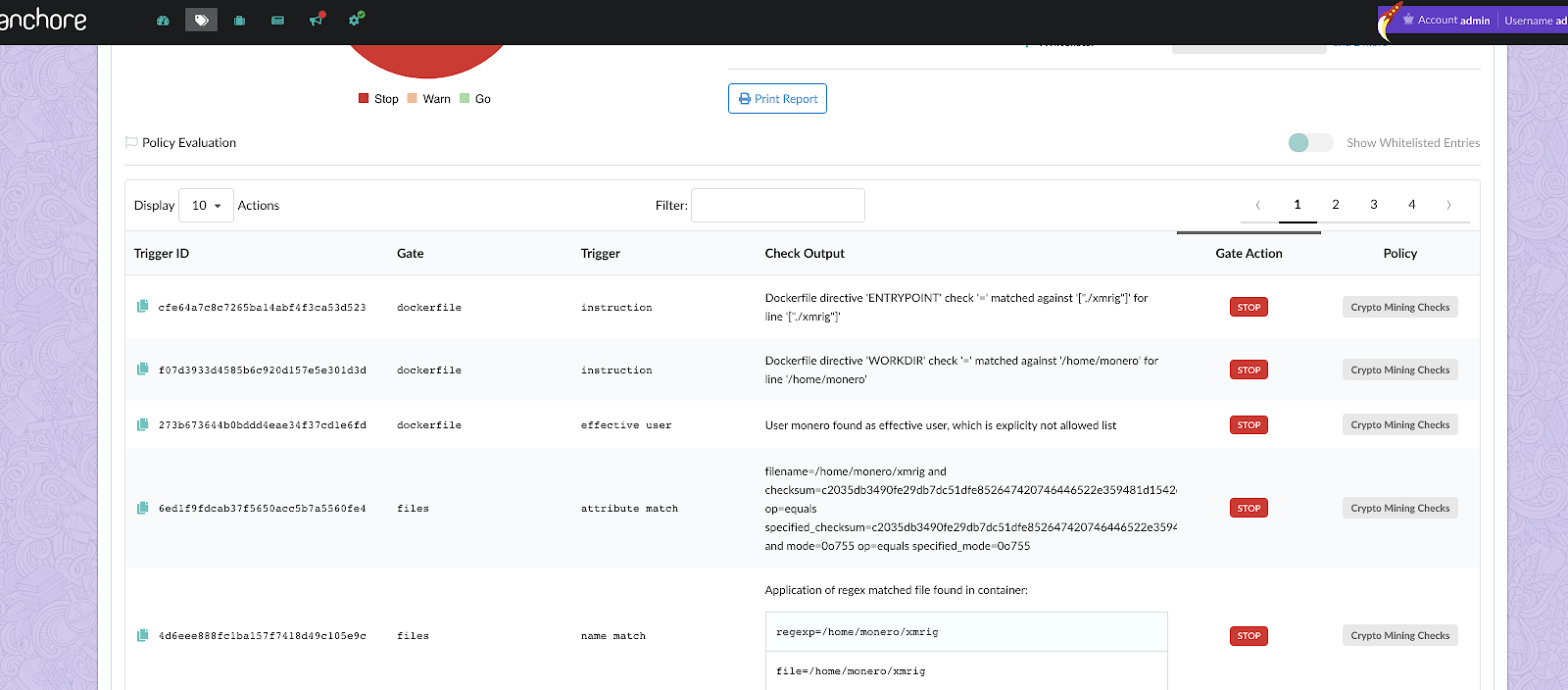
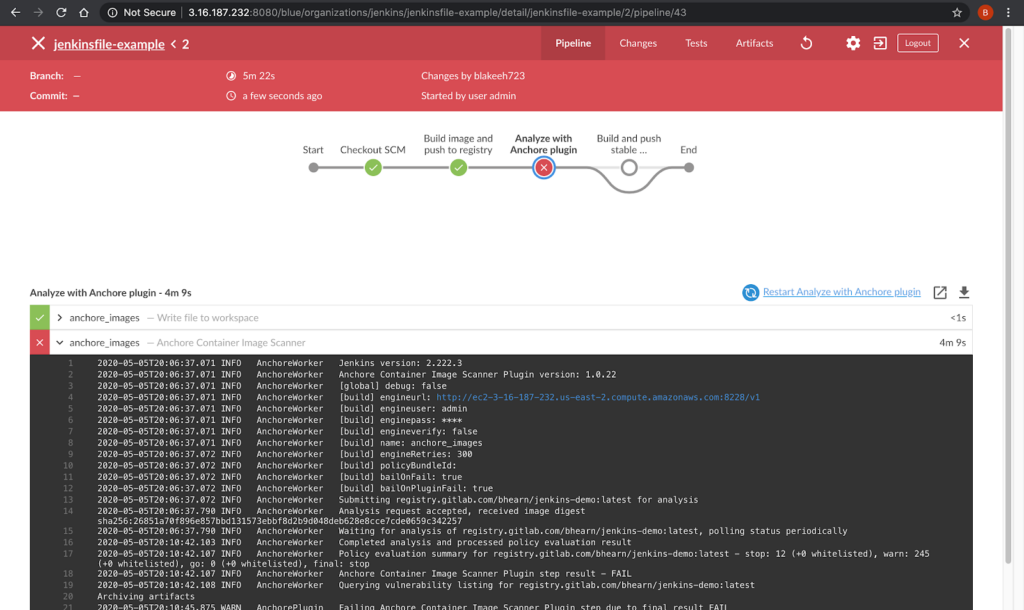
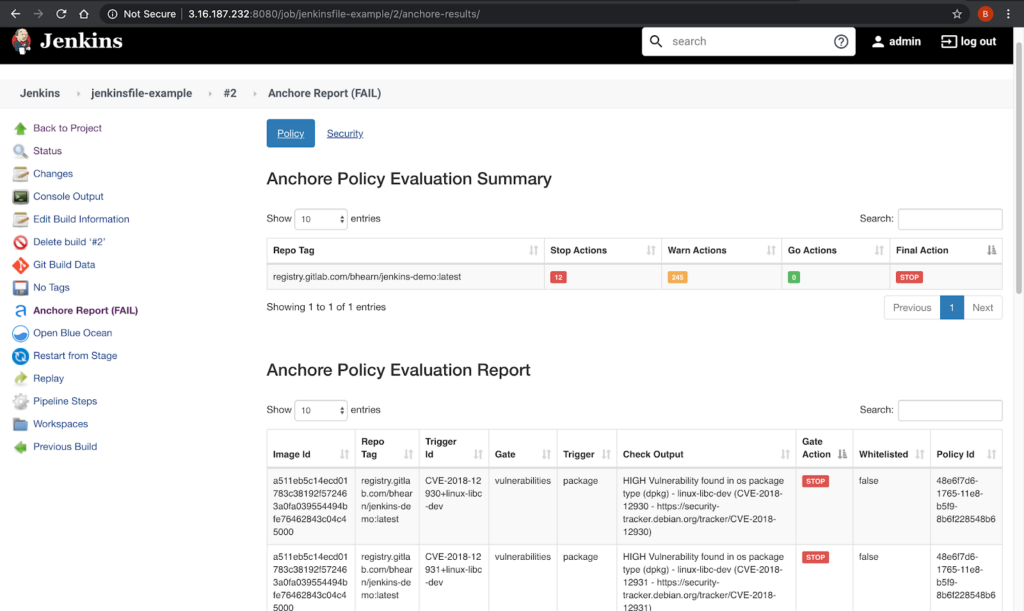
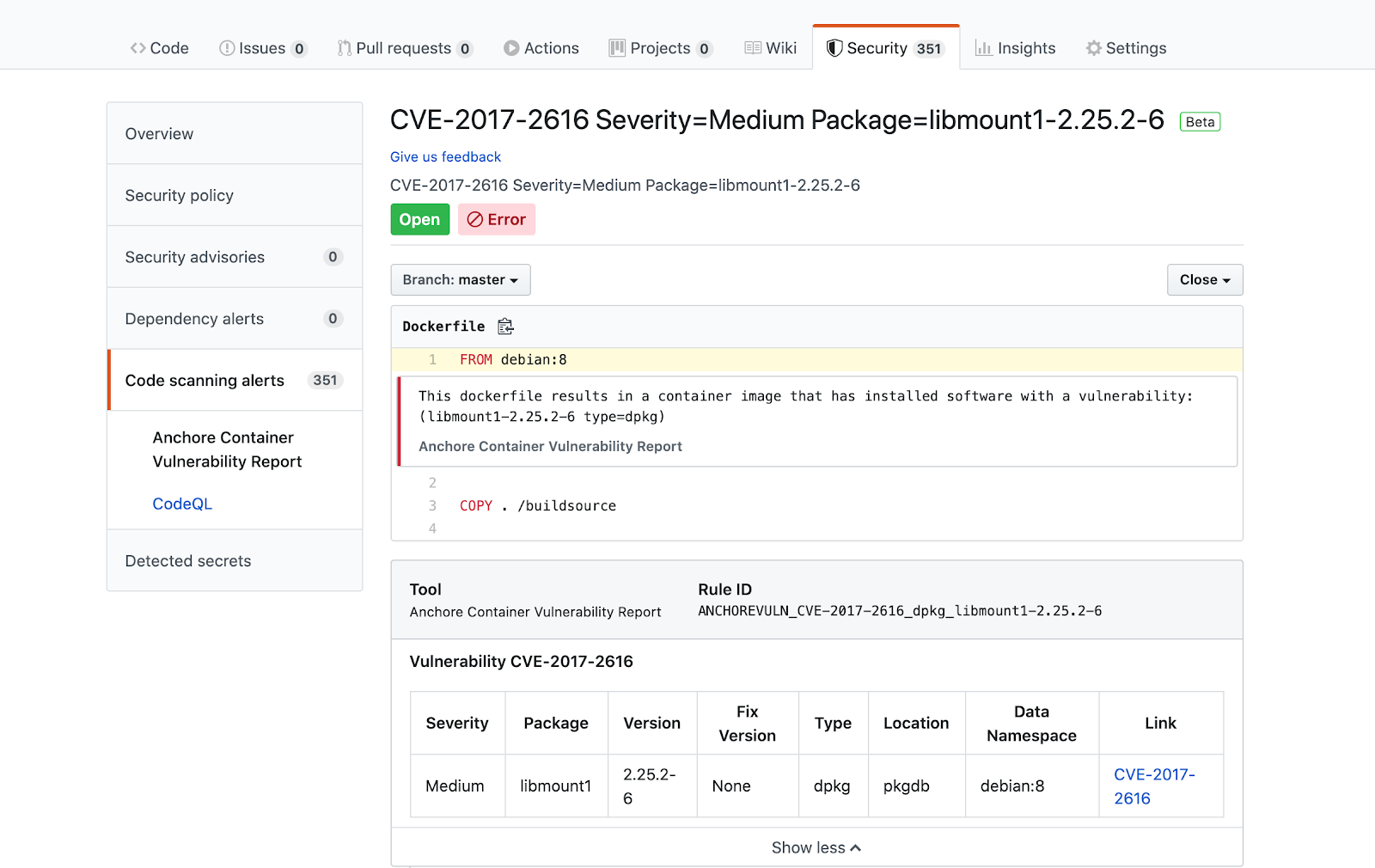
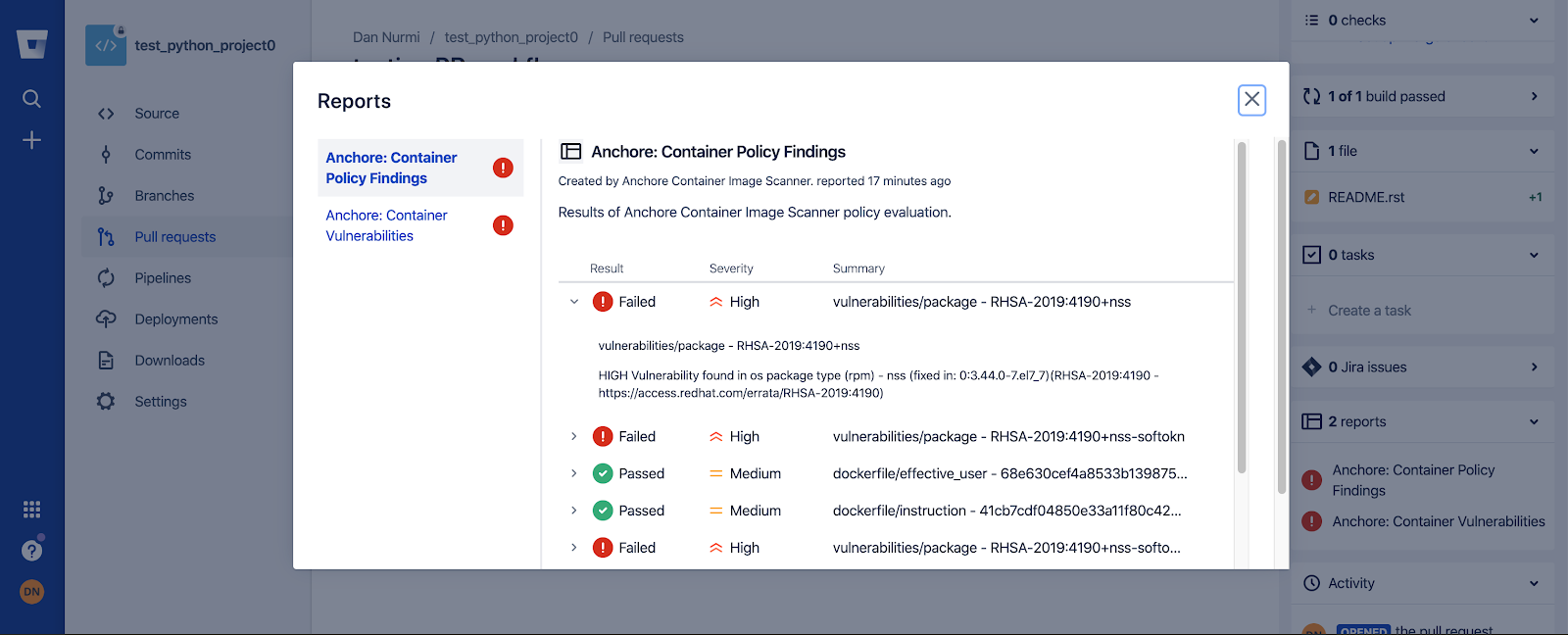
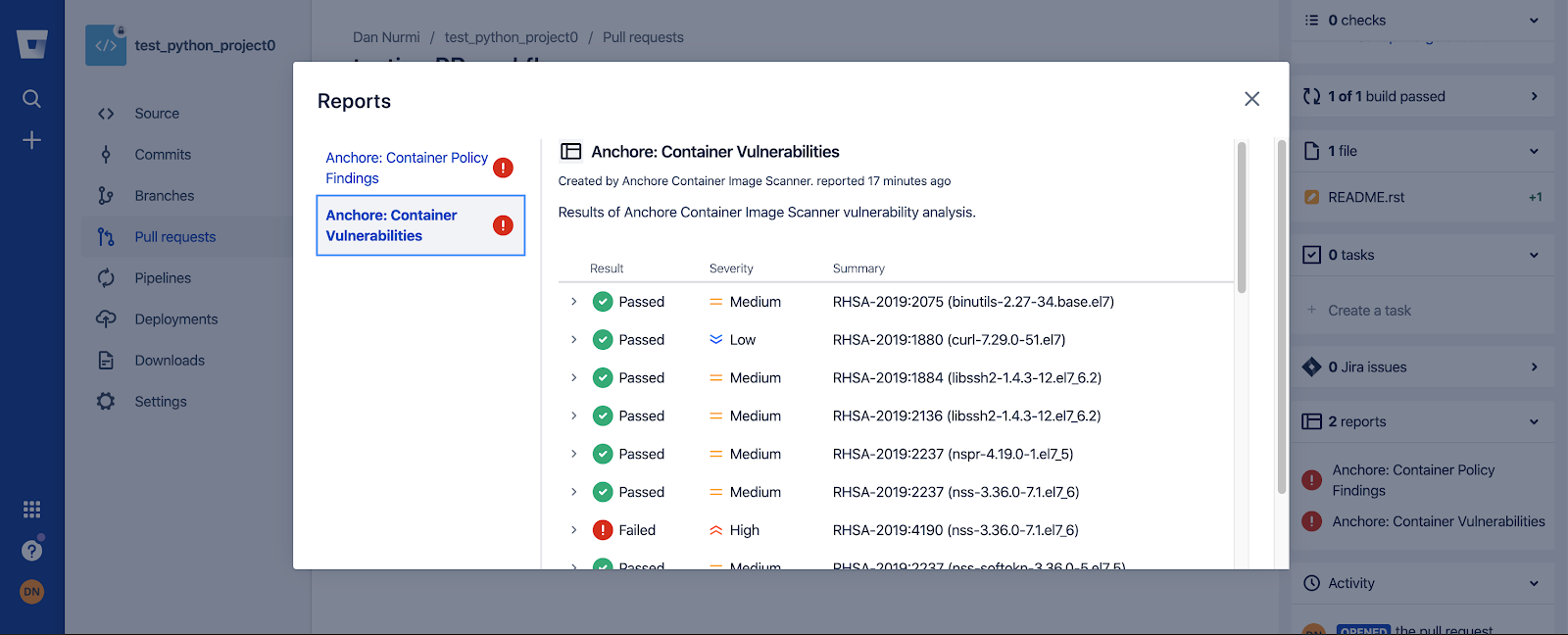
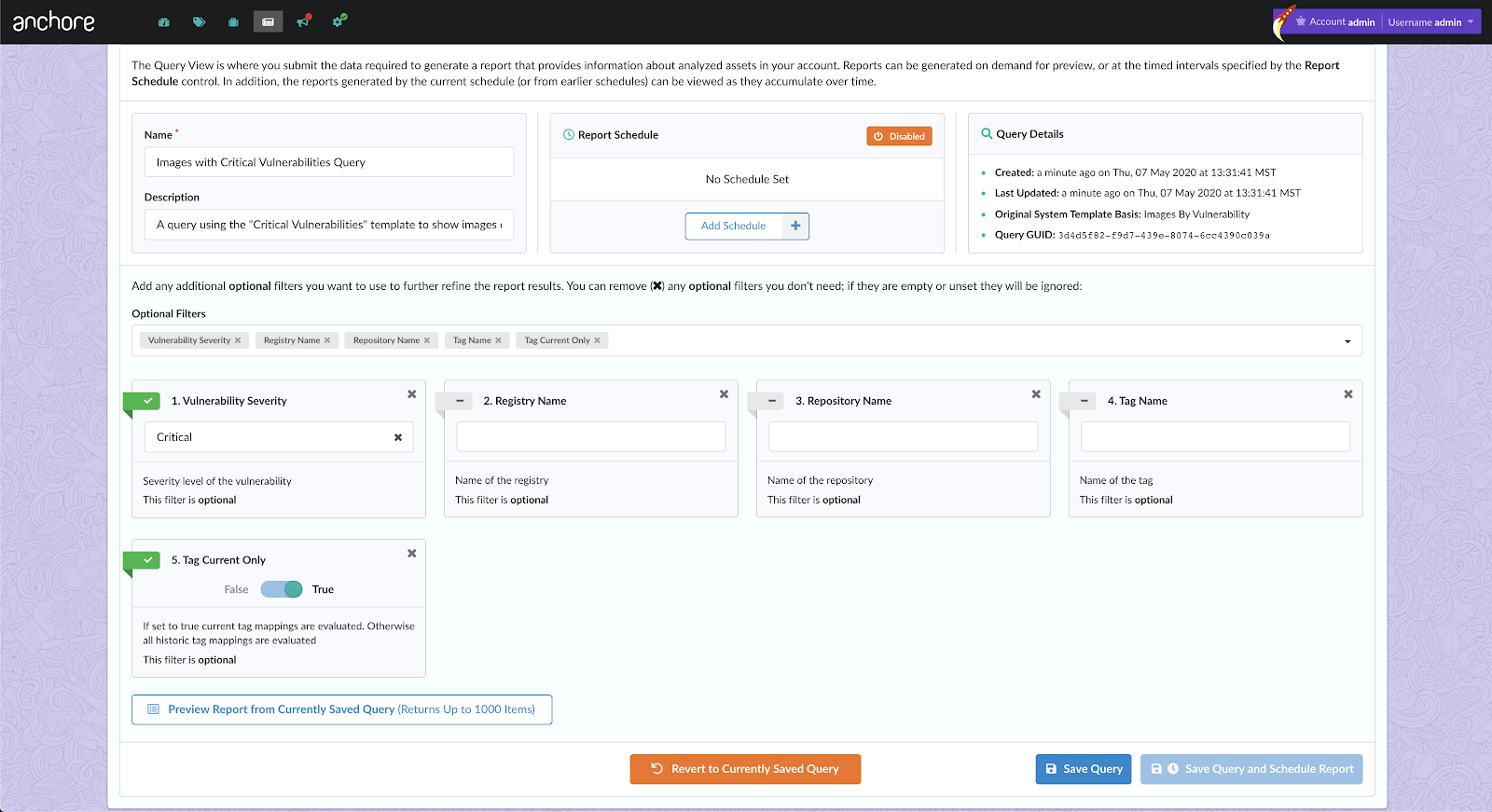
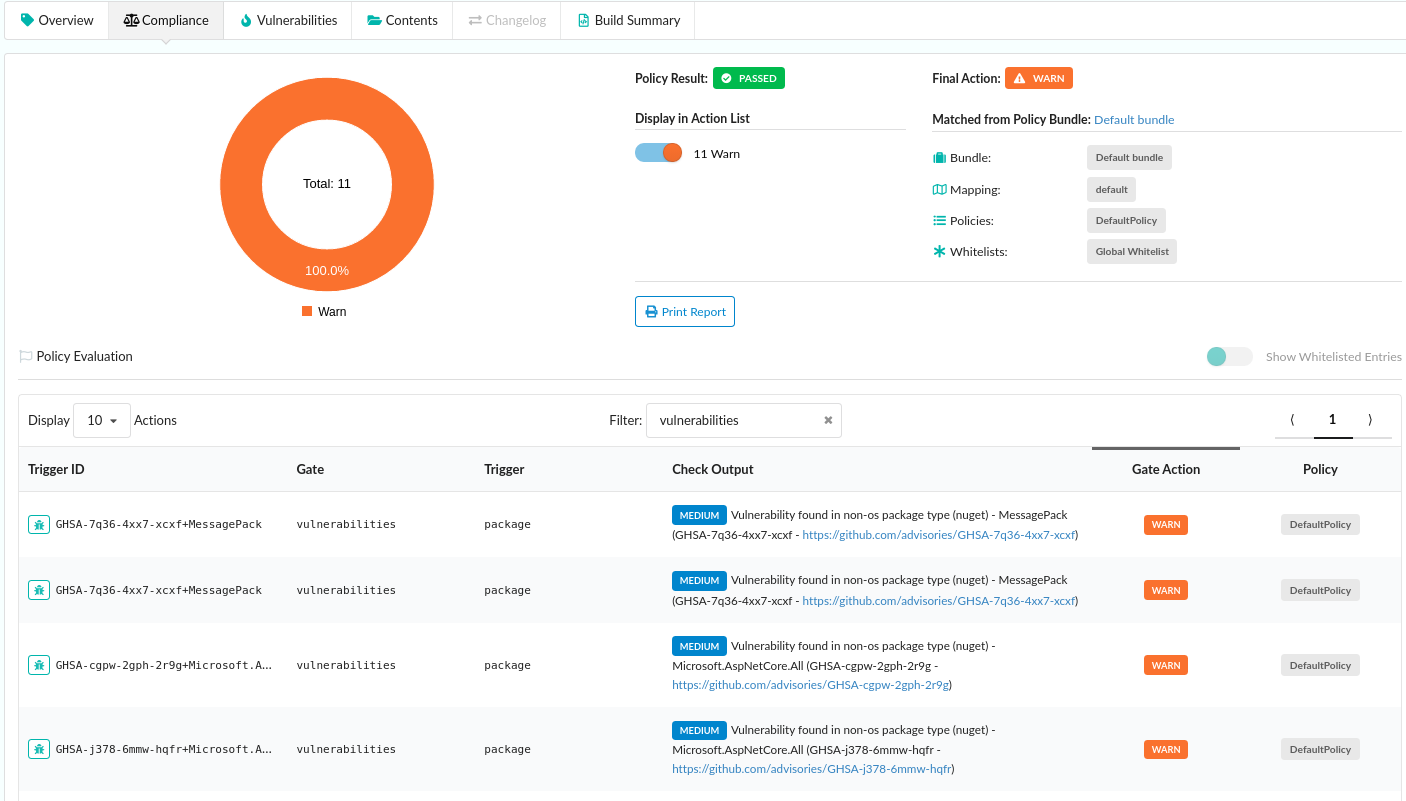
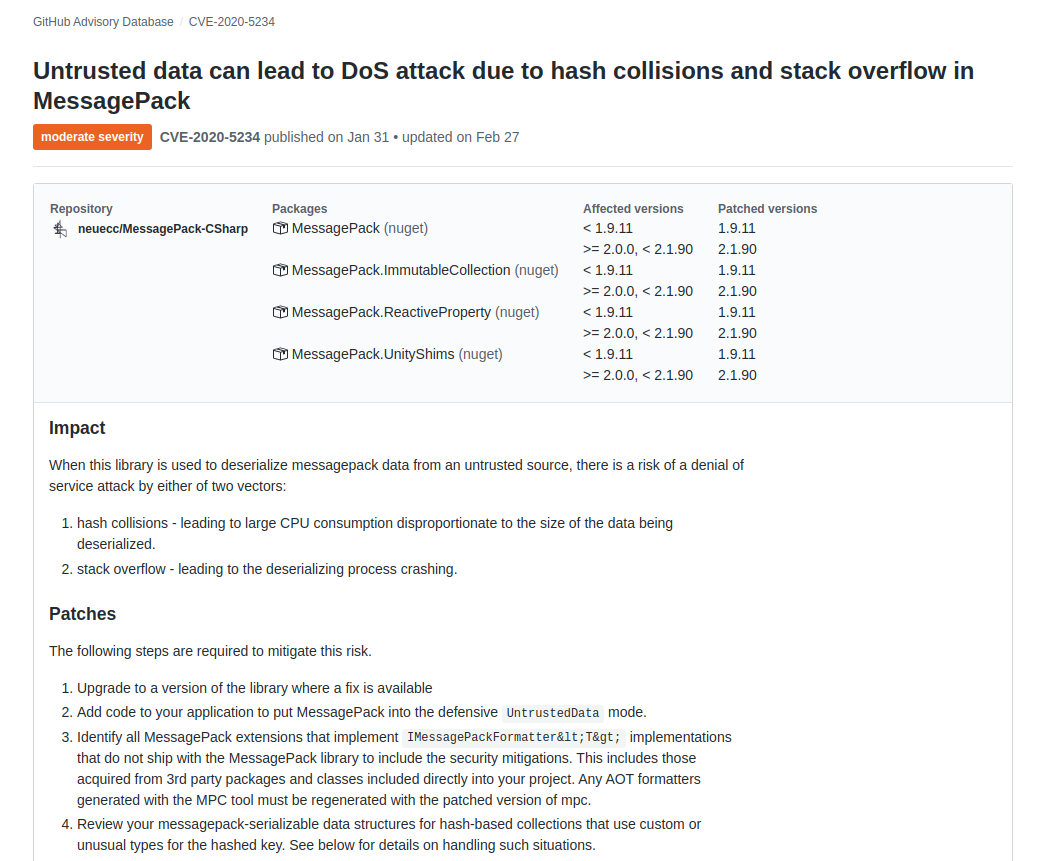
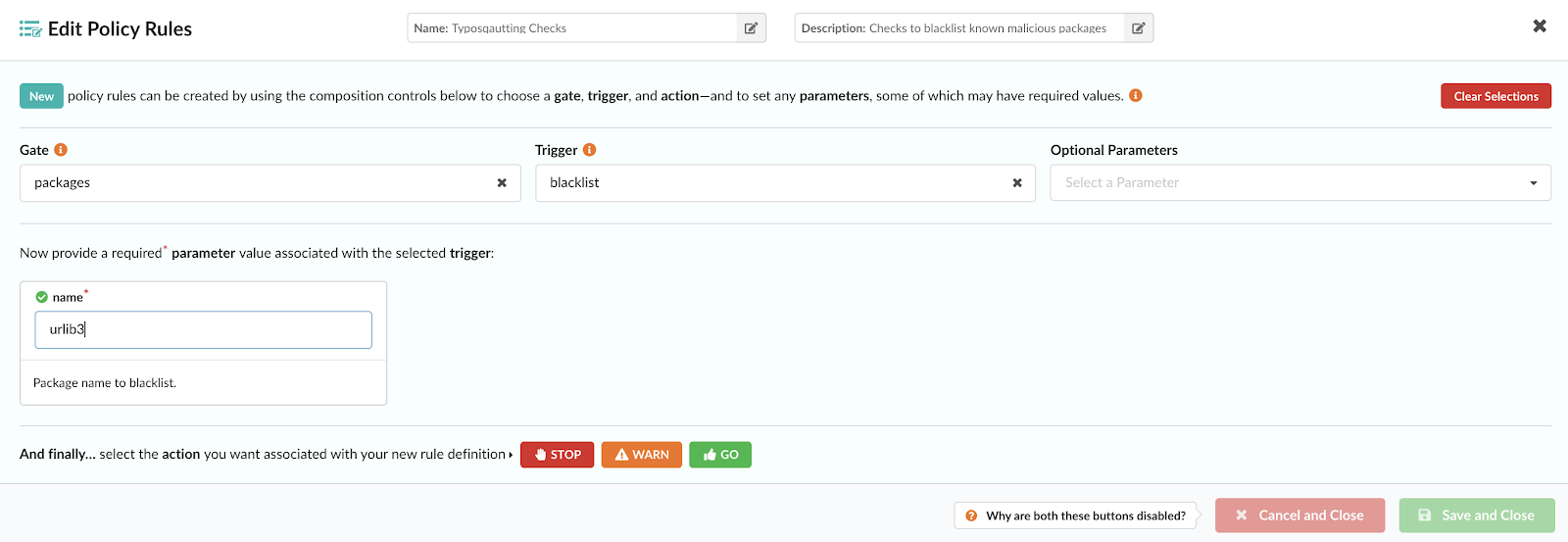
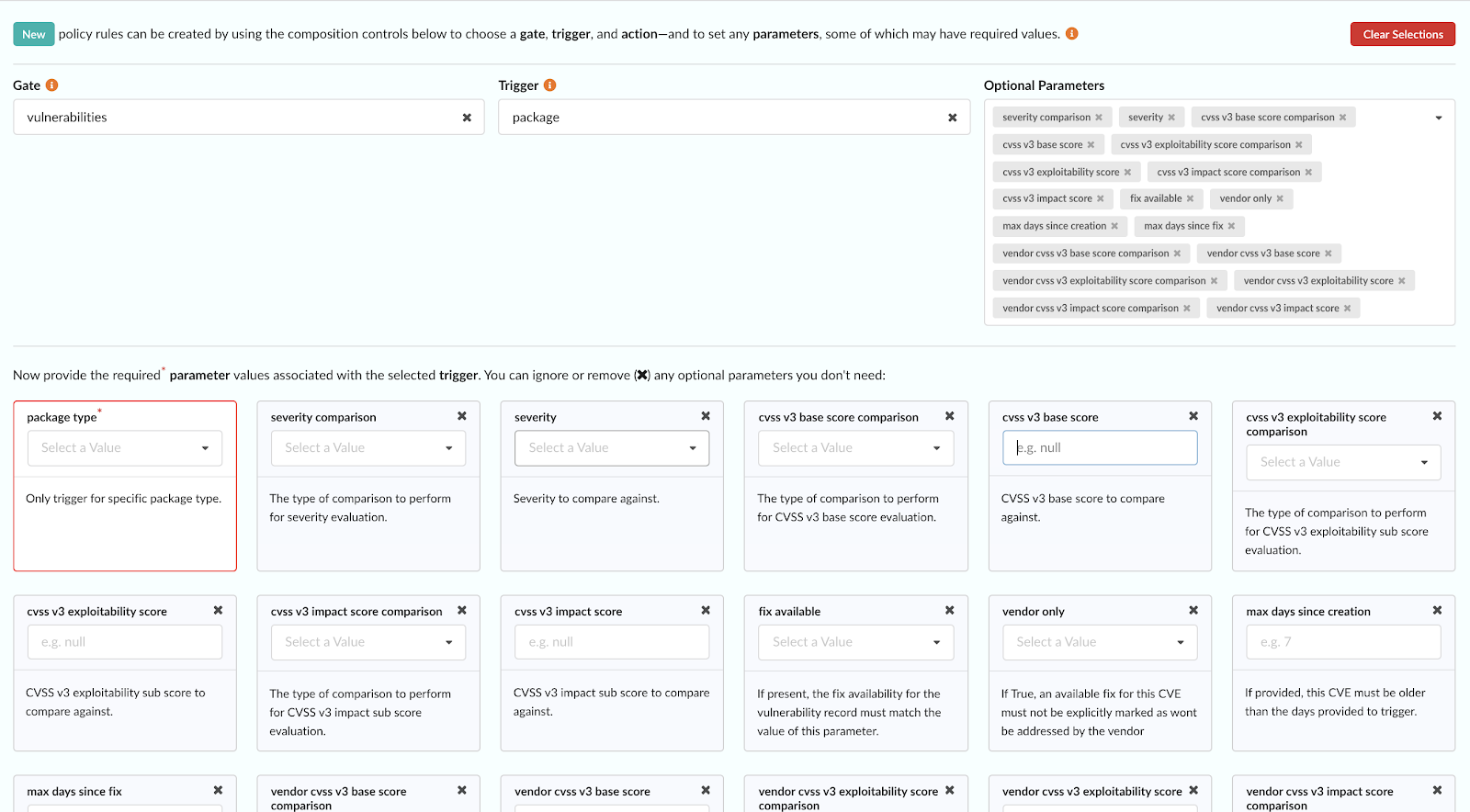
 In the above image, we can see that CVE-2019-3462 is of severity high, linked to the OS package apt-1.0.9.8.4, and there is a fix available in version 1.0.9.8.5. Also presented in the UI, is a
In the above image, we can see that CVE-2019-3462 is of severity high, linked to the OS package apt-1.0.9.8.4, and there is a fix available in version 1.0.9.8.5. Also presented in the UI, is a 
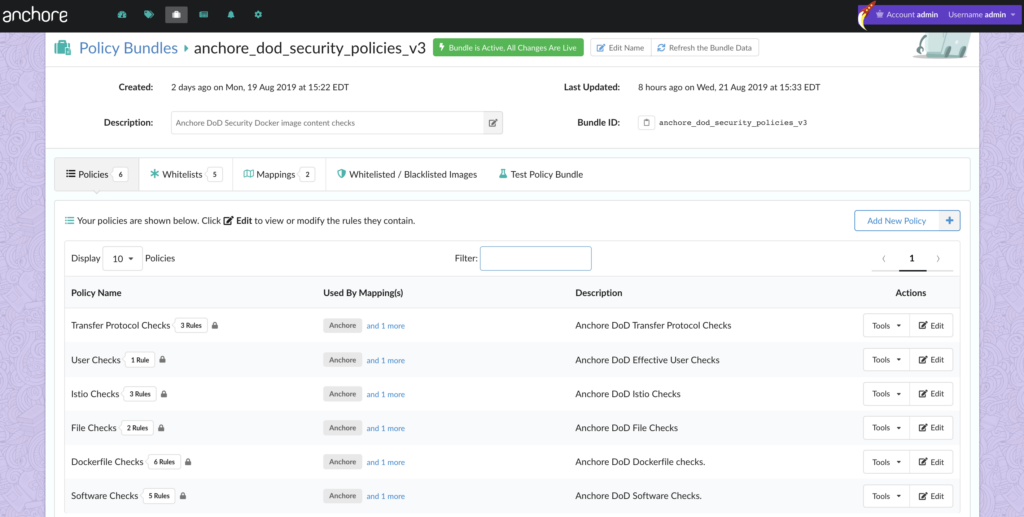
 Note – For more information on how custom Anchore policies can be created to fulfill specific compliance requirements, contact us, or navigate to our open-source
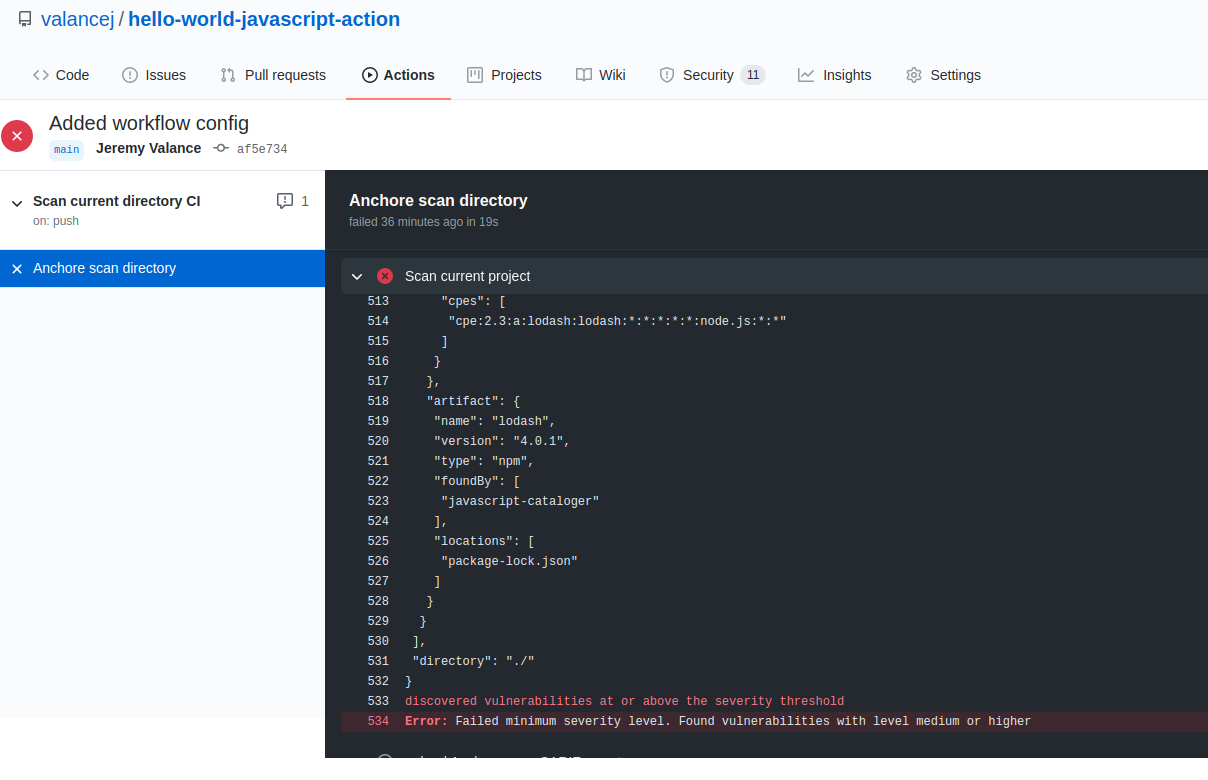
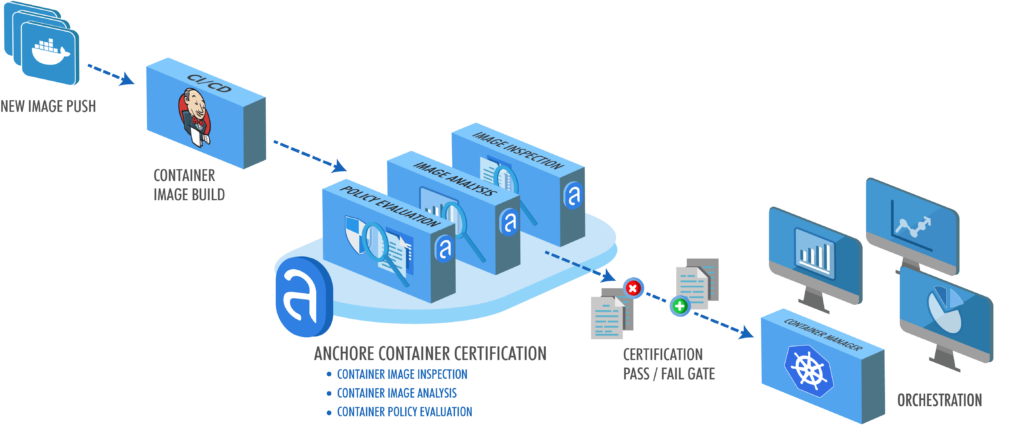
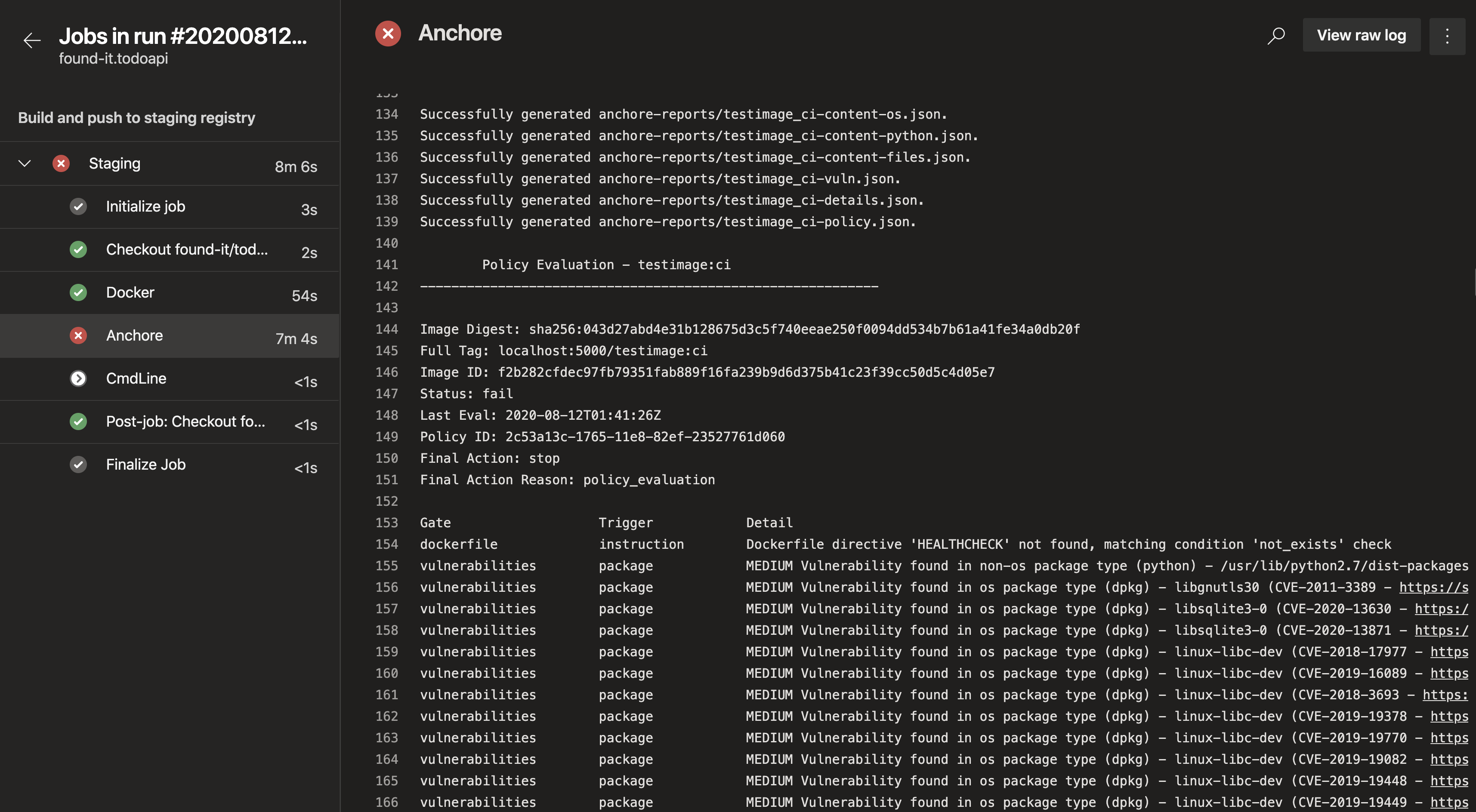
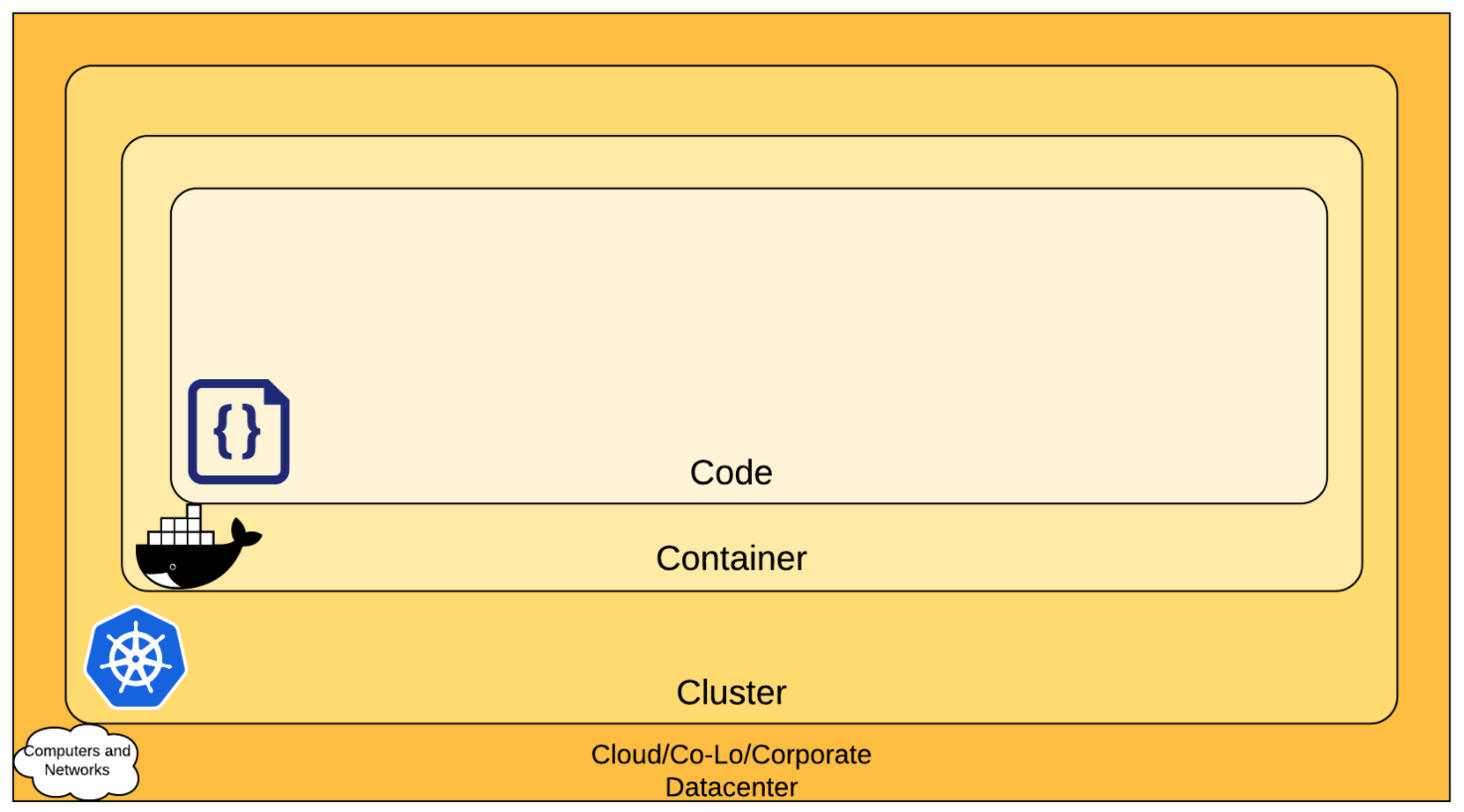
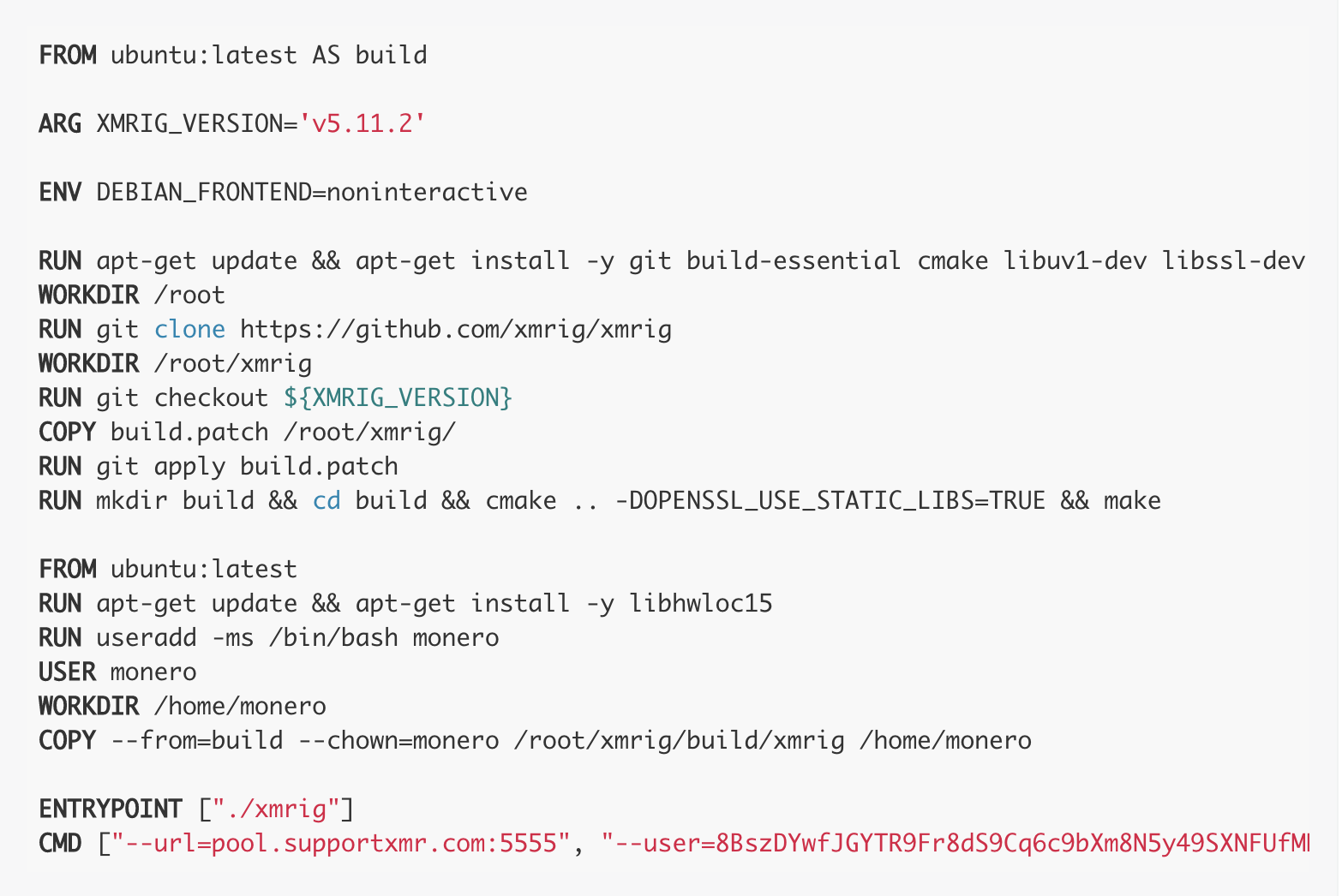
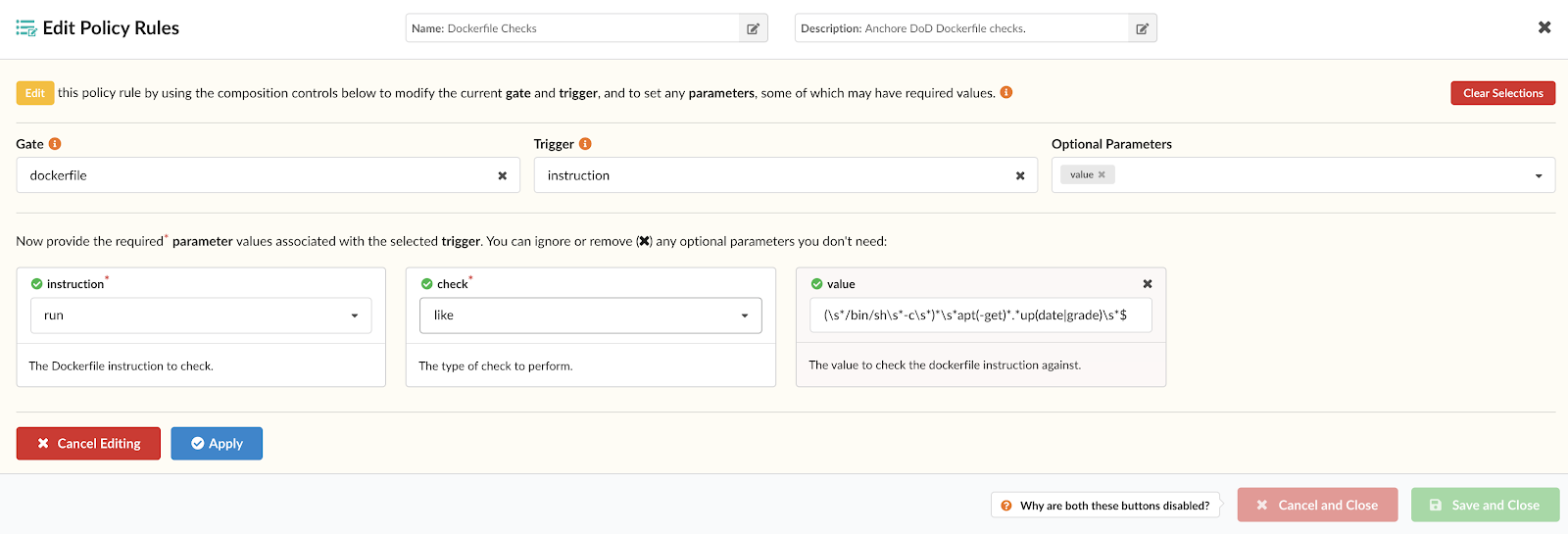
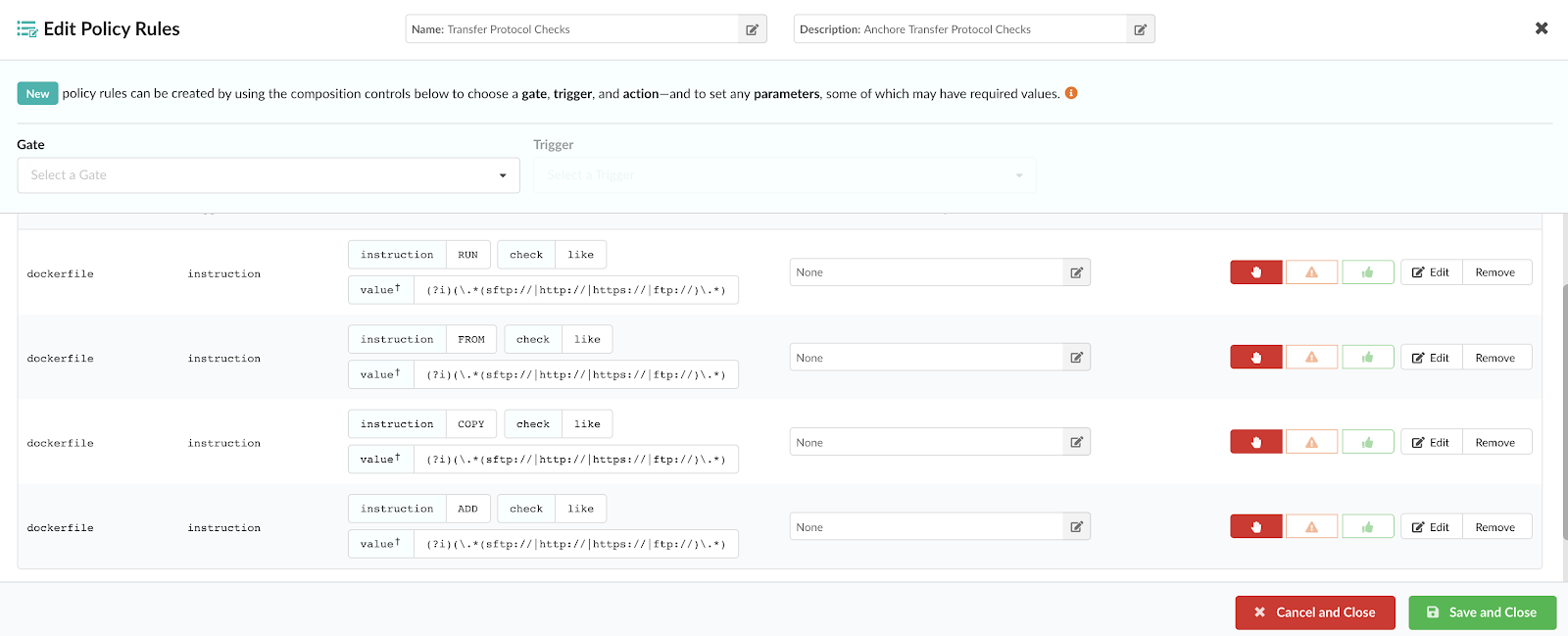
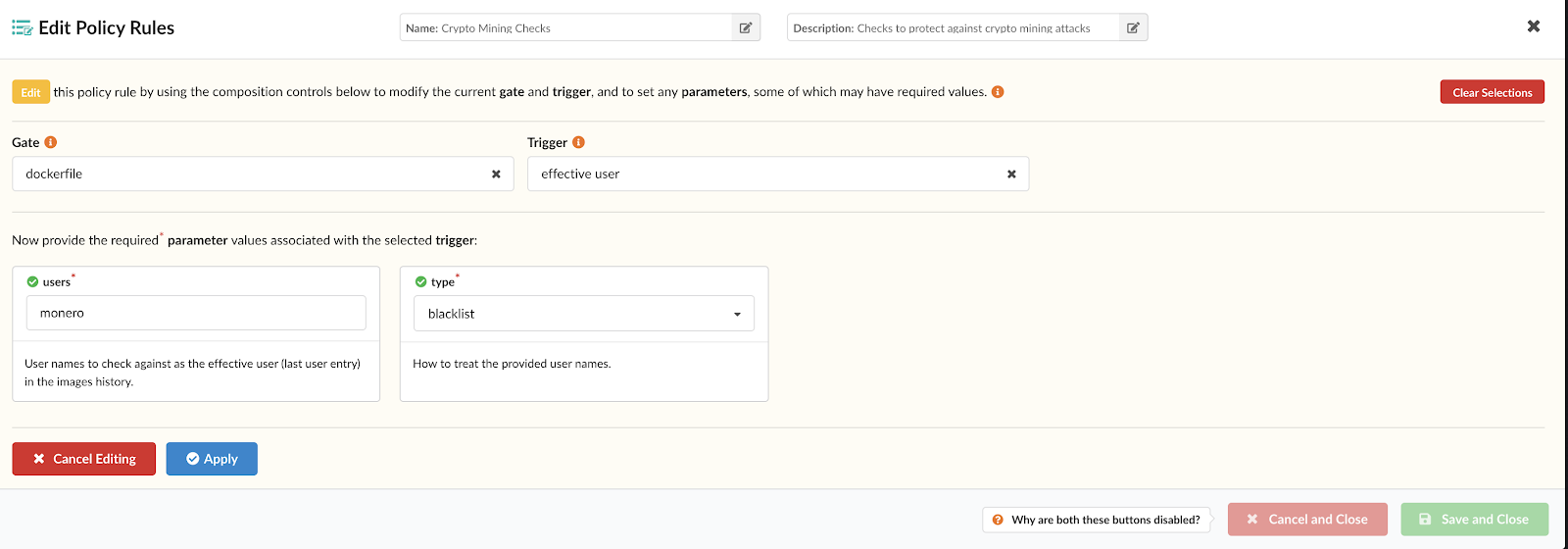
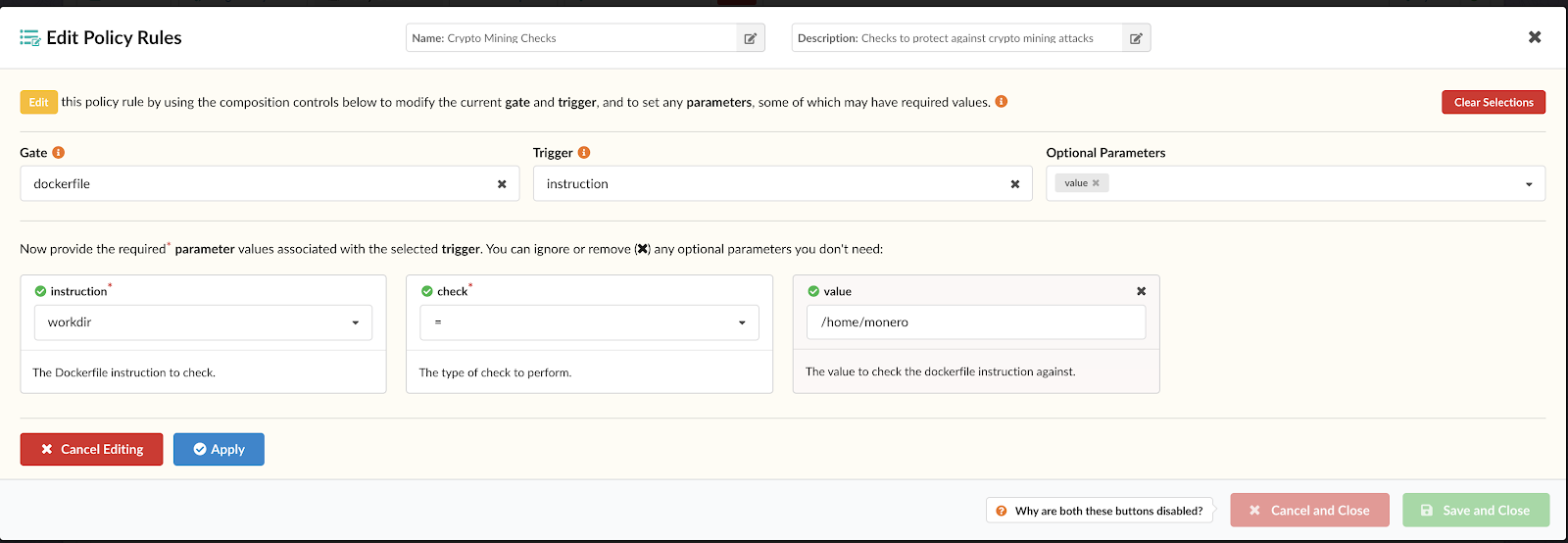
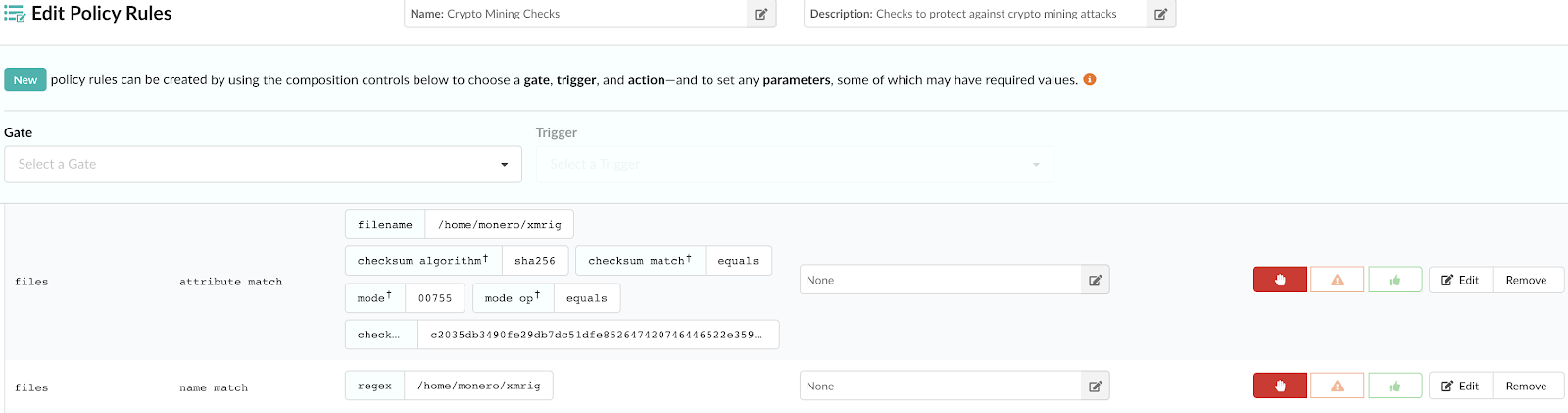
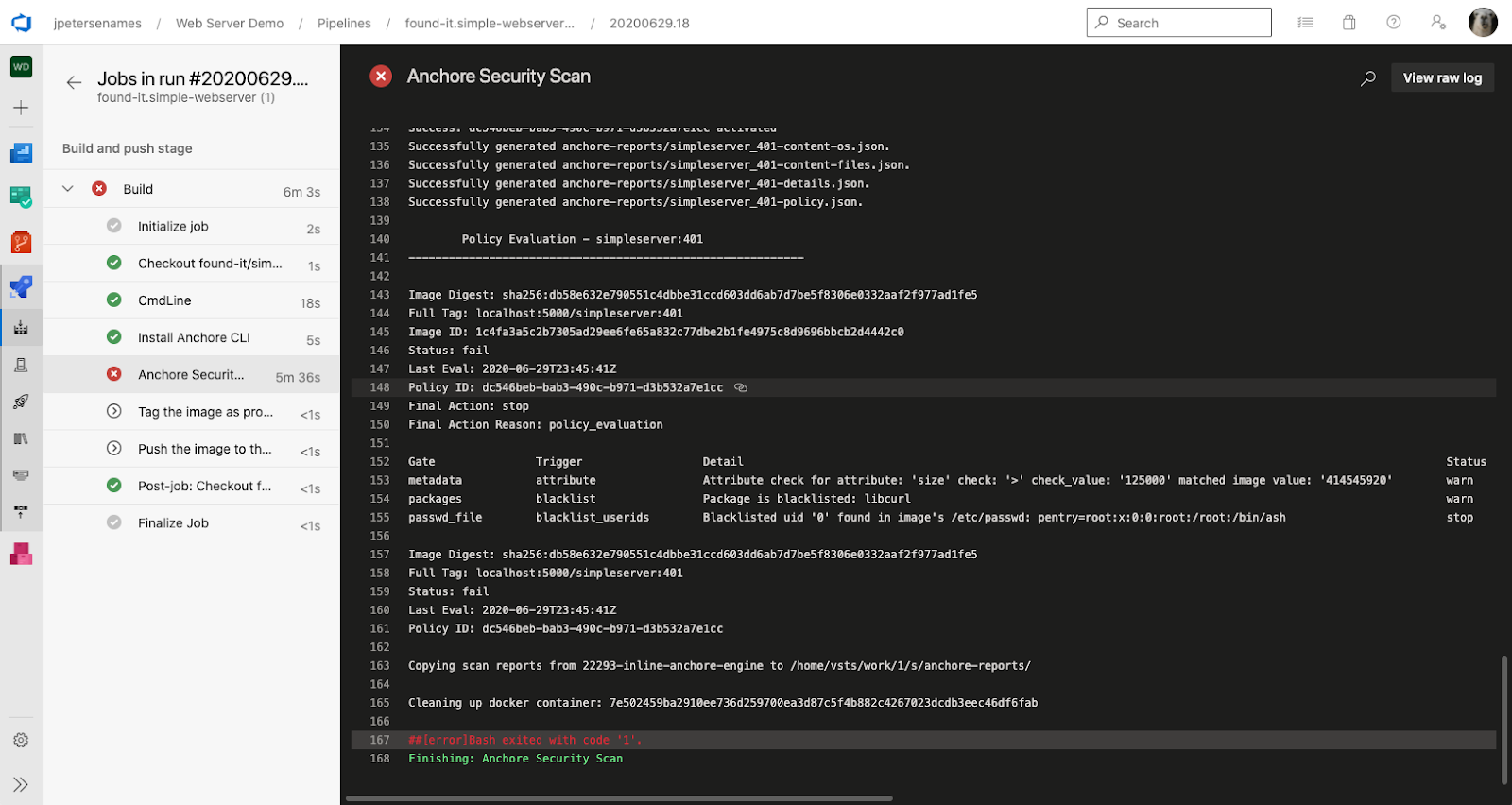
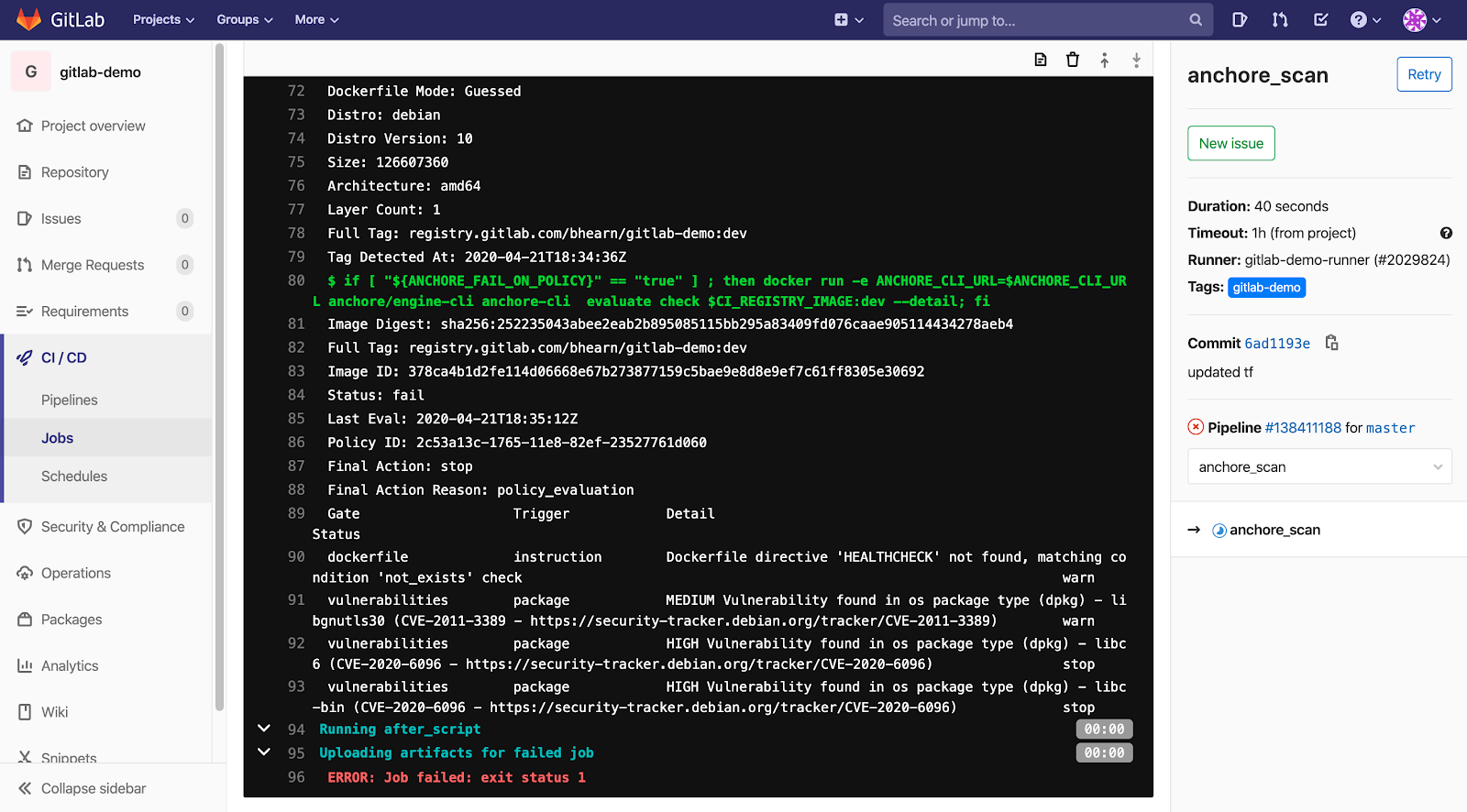
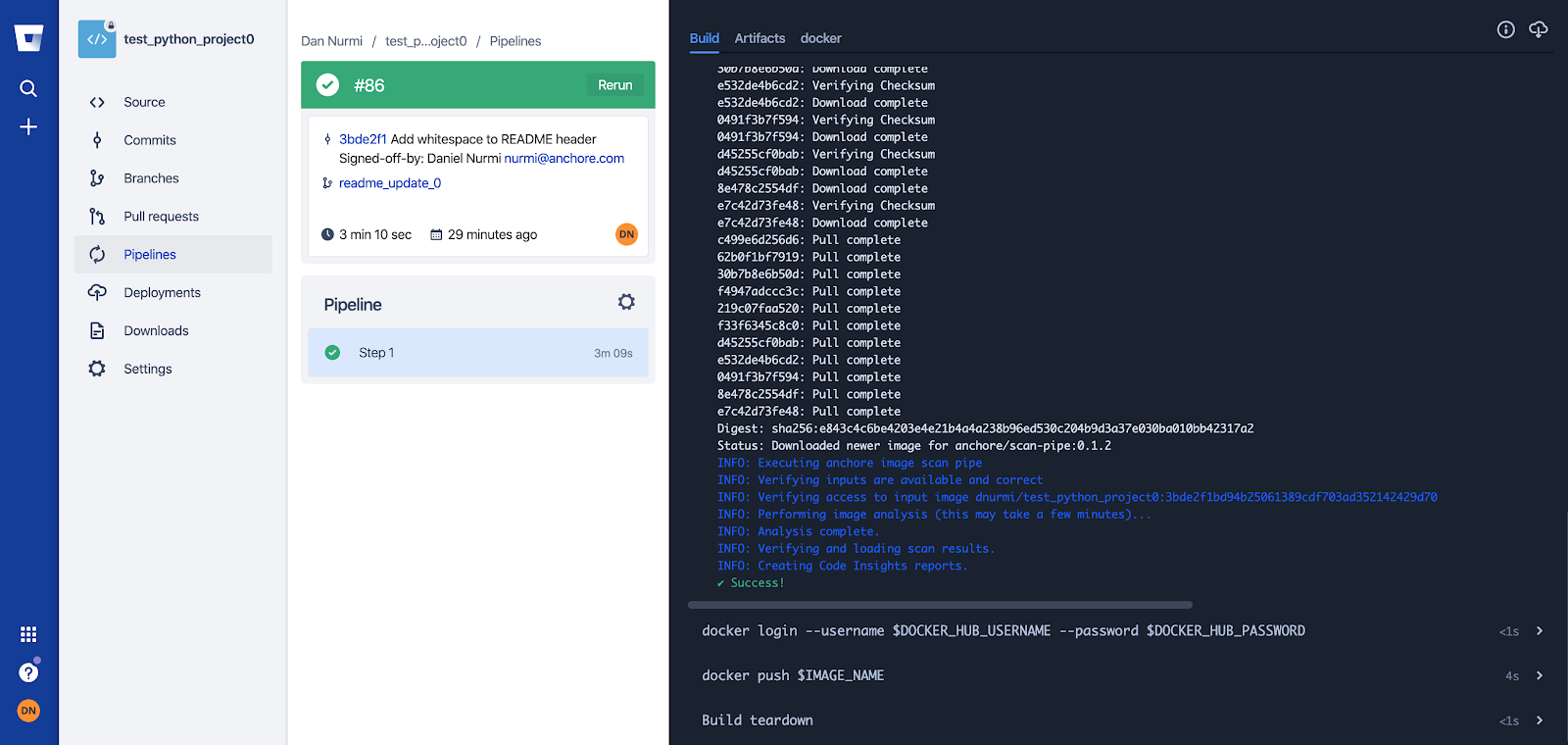
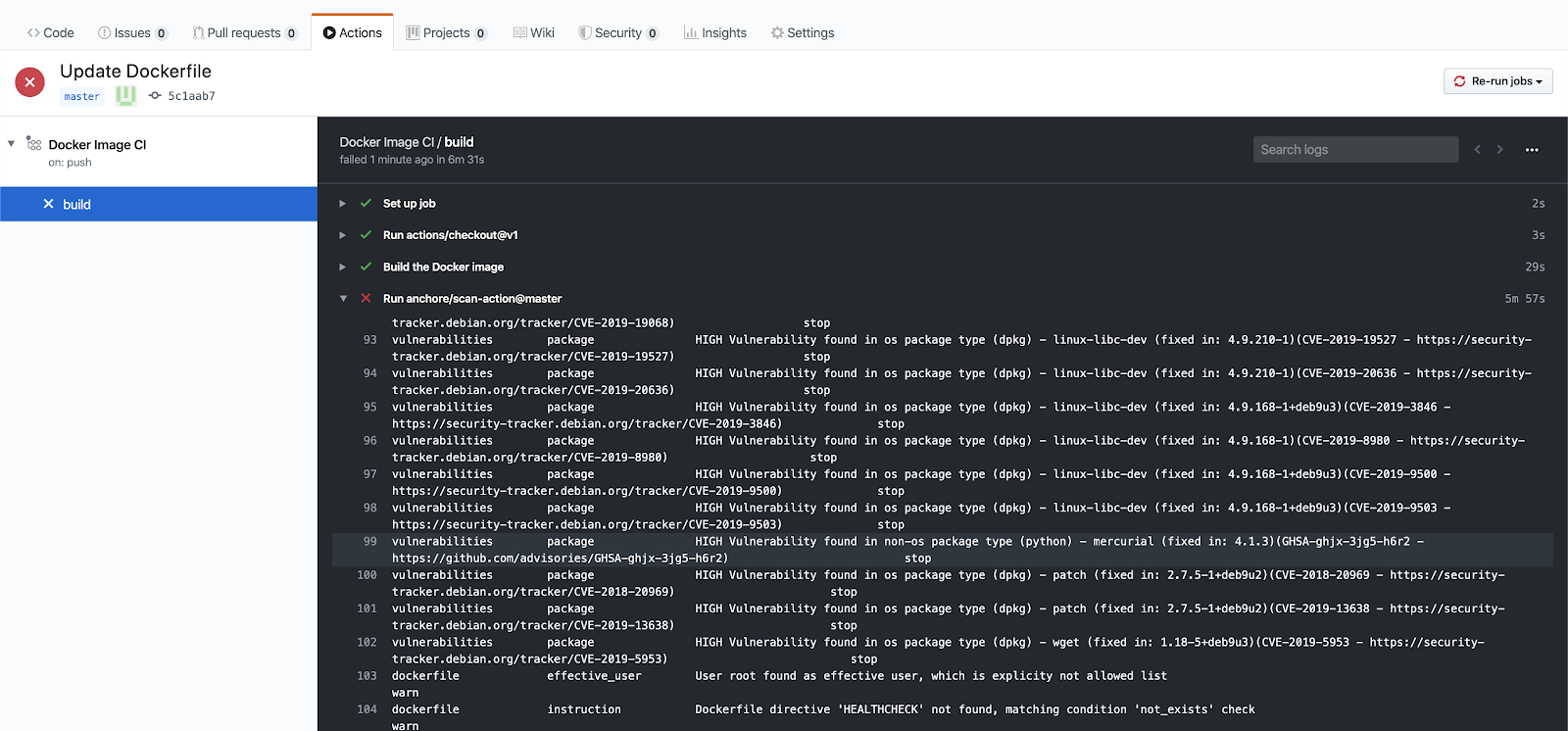
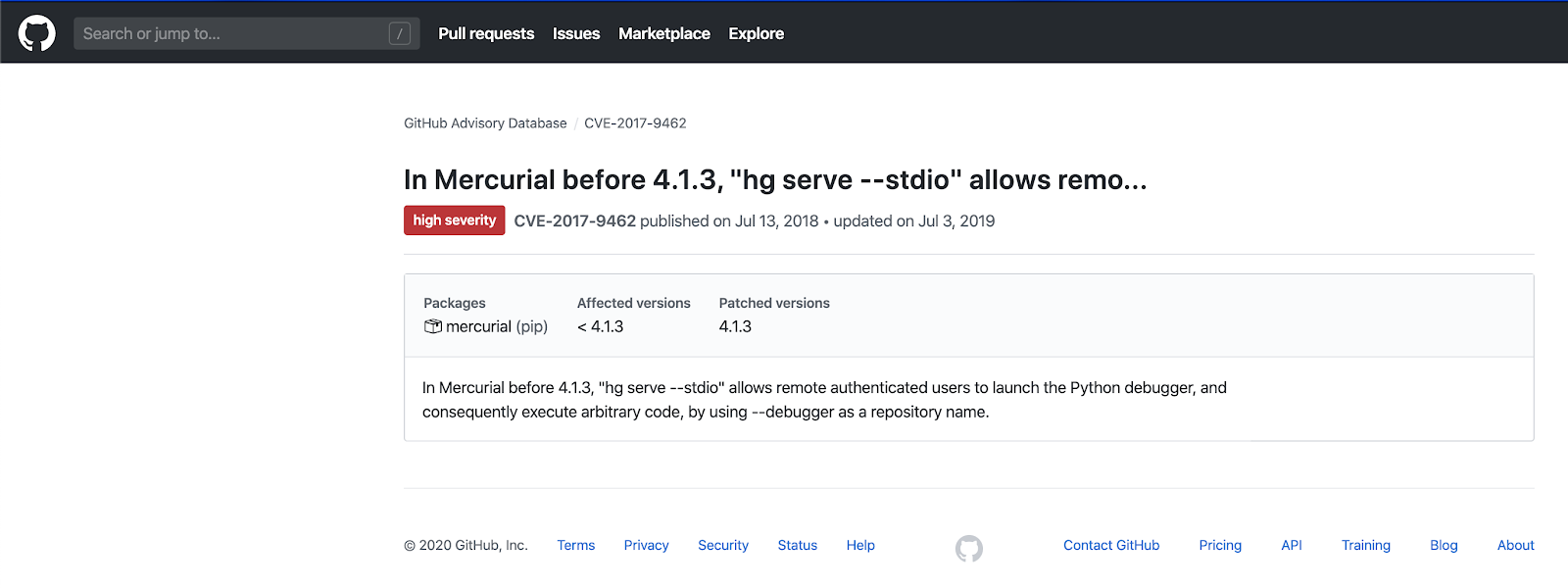
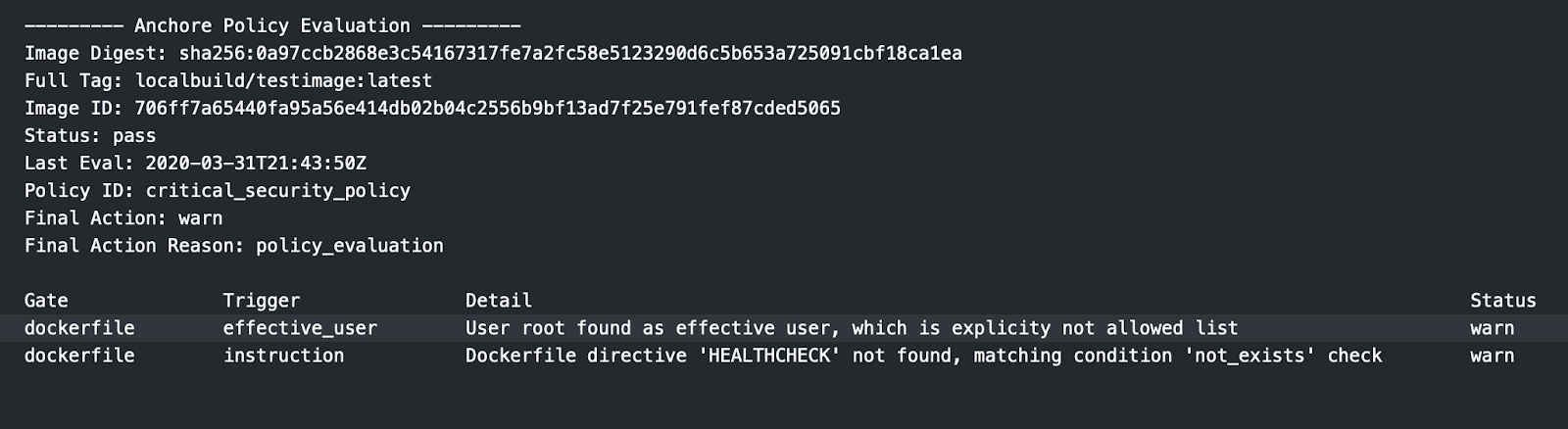
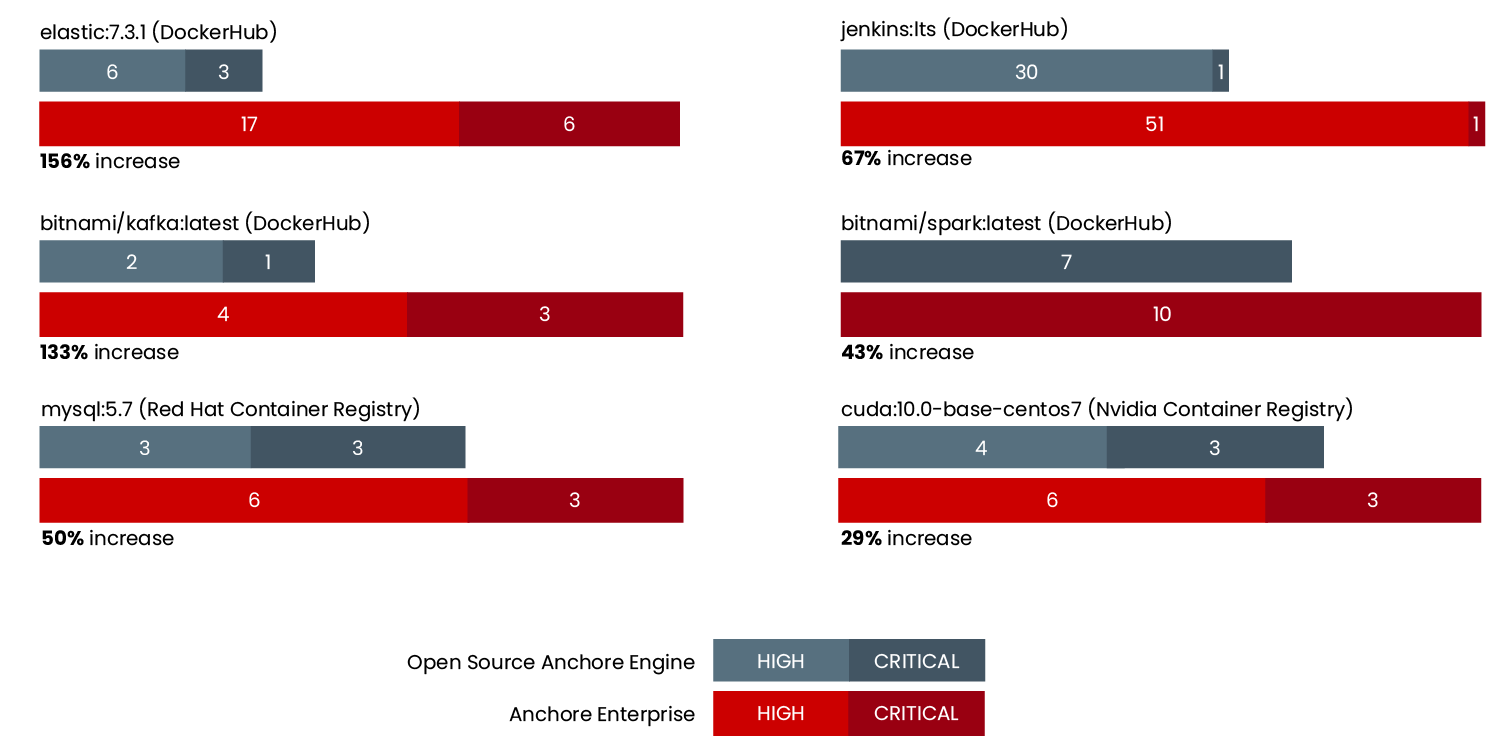
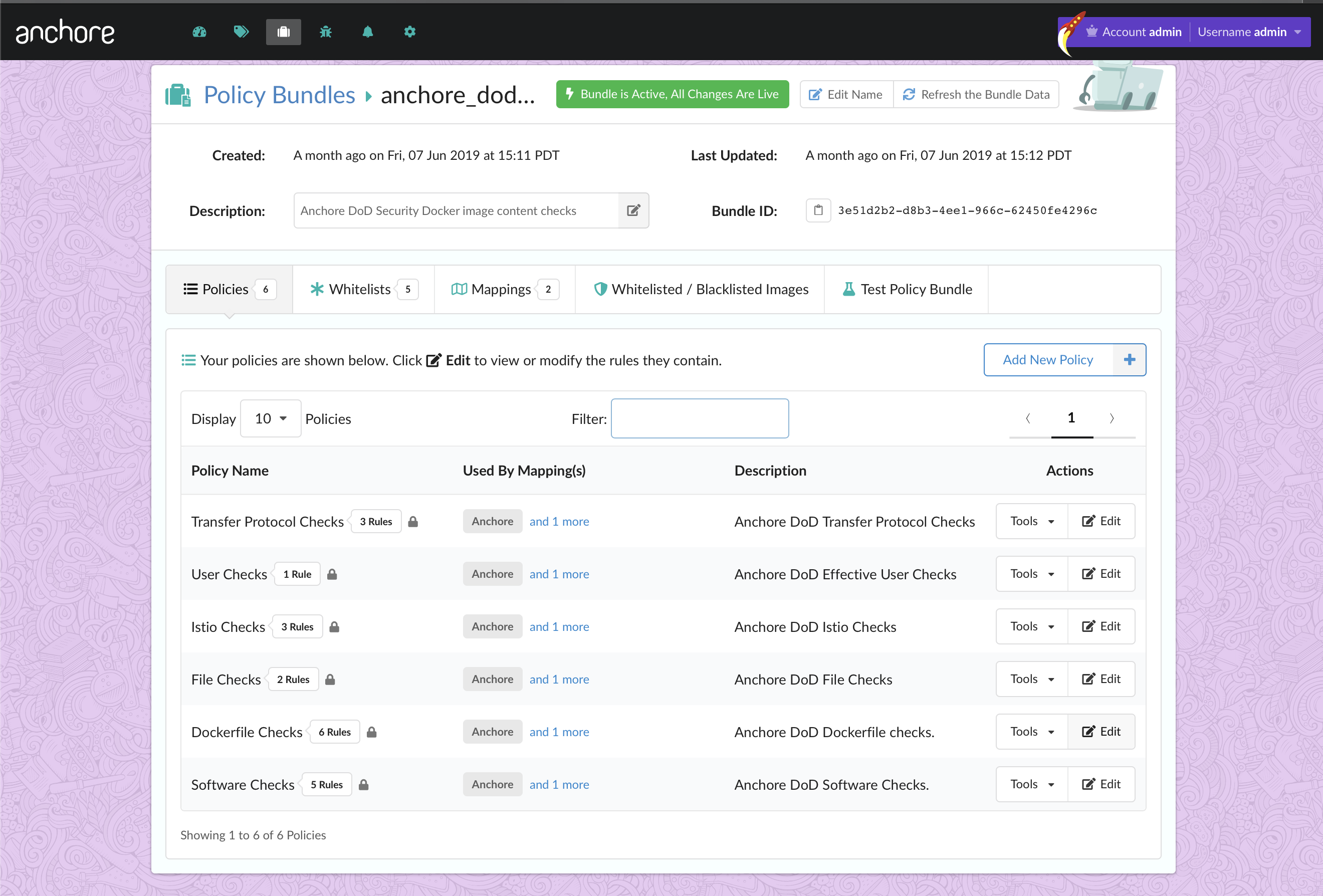
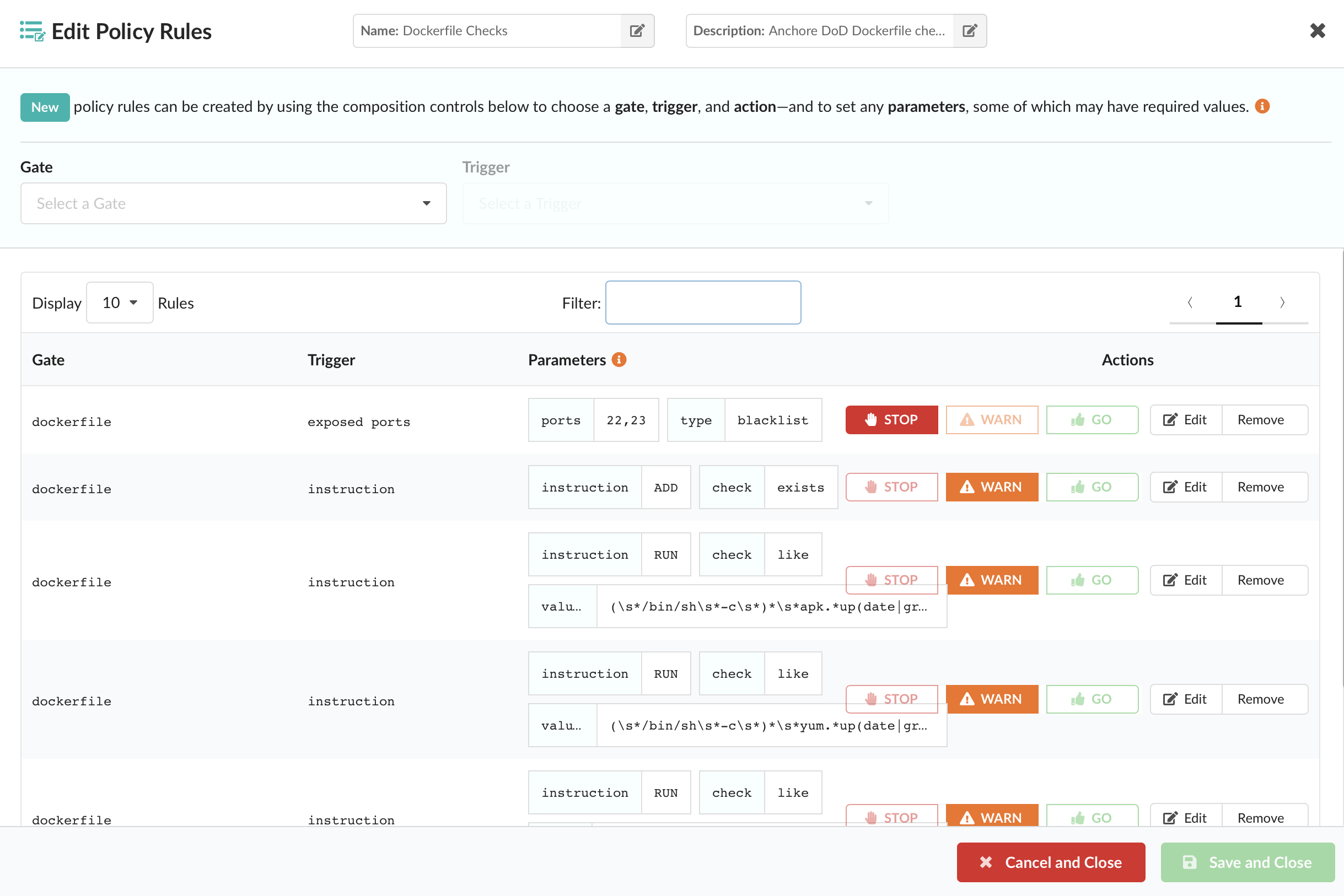
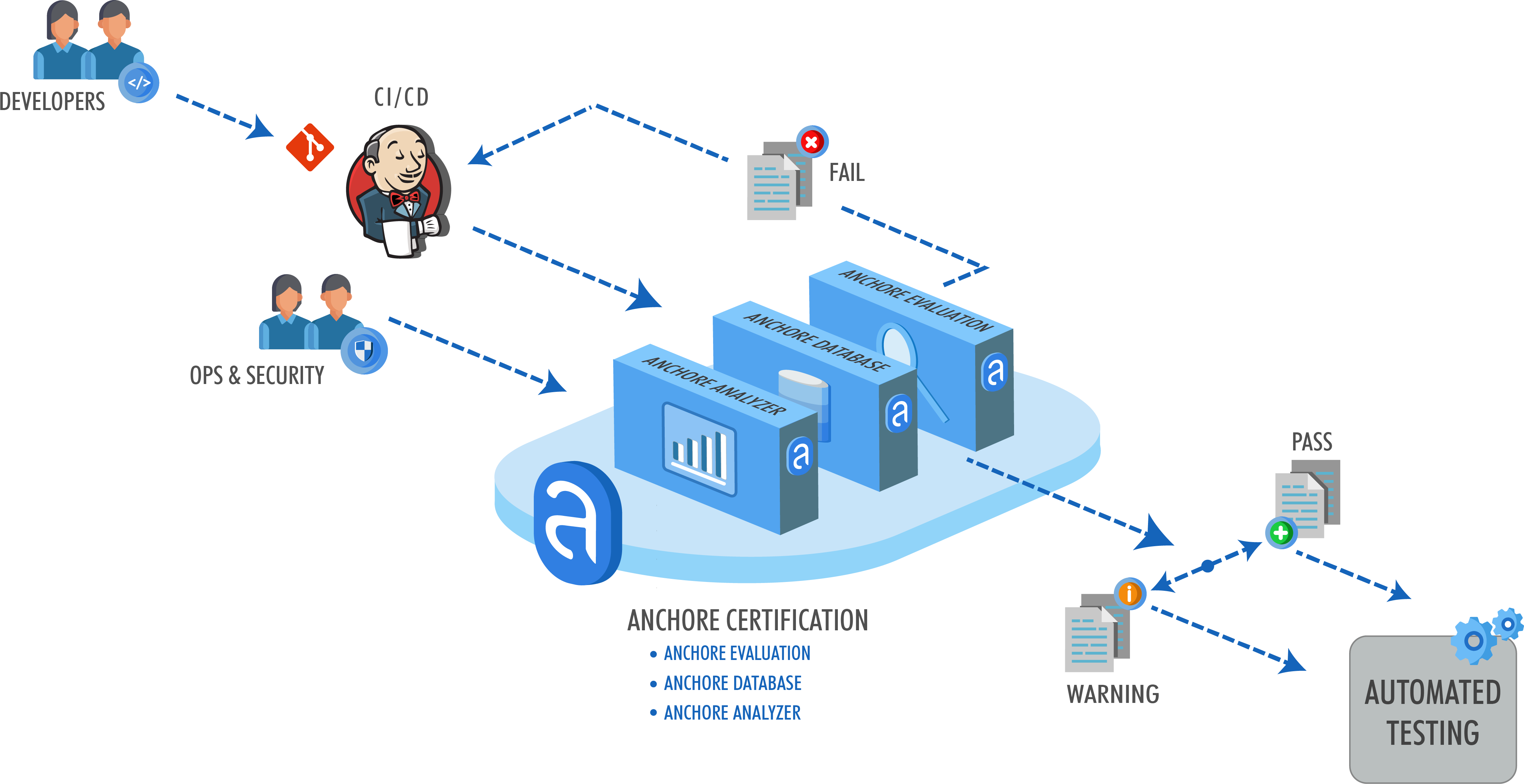
Note – For more information on how custom Anchore policies can be created to fulfill specific compliance requirements, contact us, or navigate to our open-source 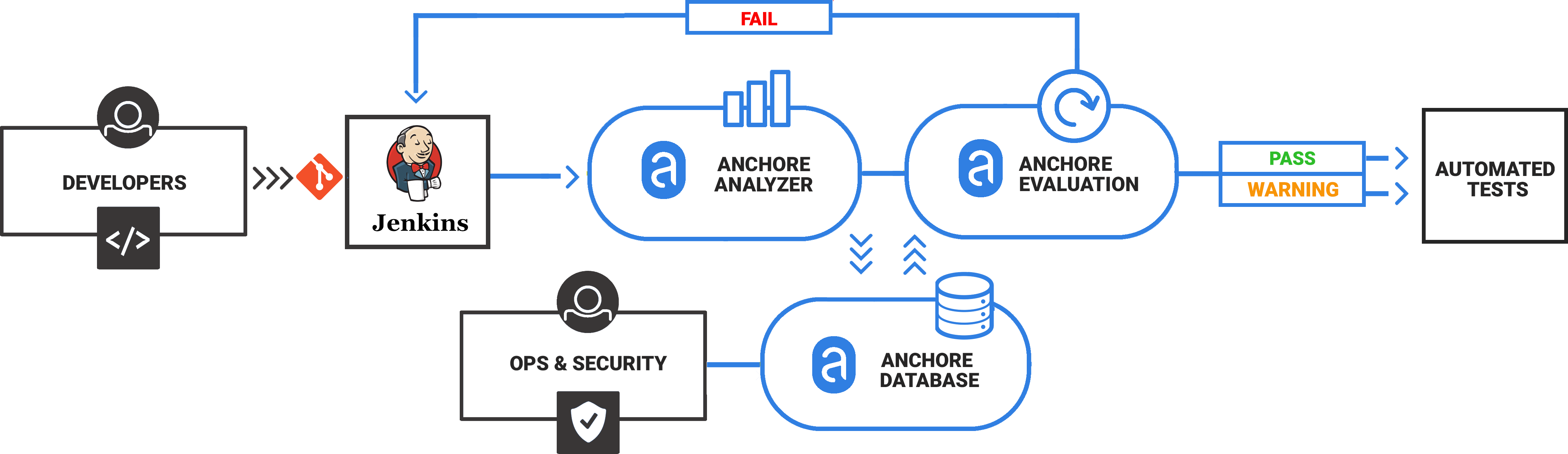 From these integrations, policy checks can be enforced to potentially fail builds. Anchore checks will provide the most value through a proper CI model. Having the ability to split up acceptable base images and application layers is critical for appropriate policy check abstraction. Multiple Anchore gates specific to each of these image layers is fundamental to the overall success of Anchore policies. As an example, prior to trusted base image promotion and push into a registry, it will need to pass Anchore checks for Dockerfile best practices (USER, non ssh open), and operating system package vulnerability checks.
From these integrations, policy checks can be enforced to potentially fail builds. Anchore checks will provide the most value through a proper CI model. Having the ability to split up acceptable base images and application layers is critical for appropriate policy check abstraction. Multiple Anchore gates specific to each of these image layers is fundamental to the overall success of Anchore policies. As an example, prior to trusted base image promotion and push into a registry, it will need to pass Anchore checks for Dockerfile best practices (USER, non ssh open), and operating system package vulnerability checks.{kind=link}