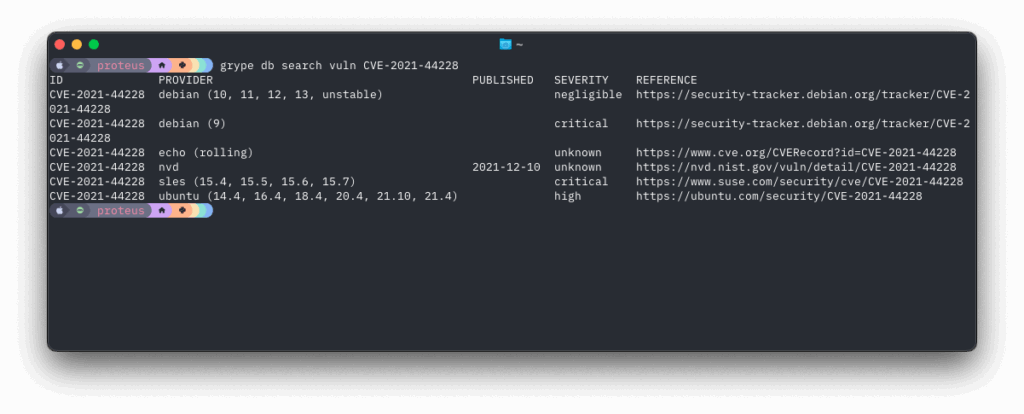
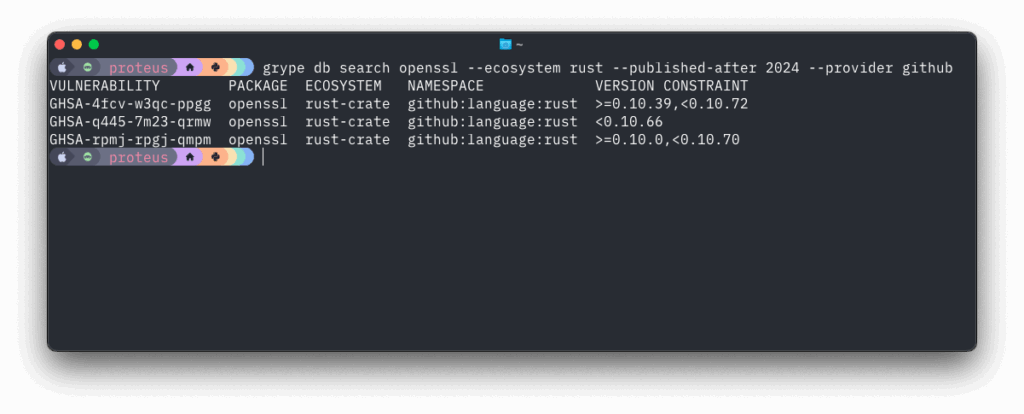
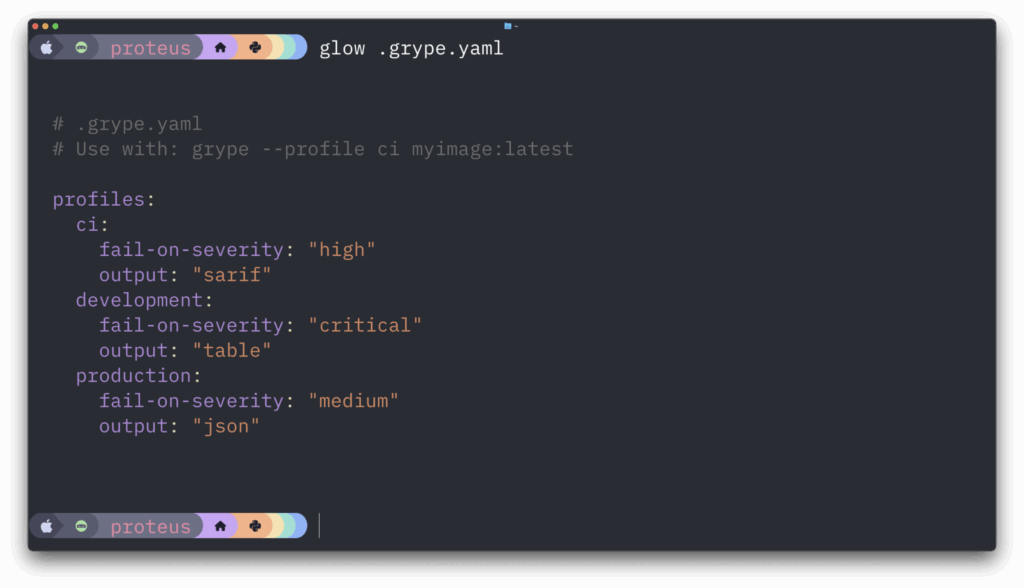
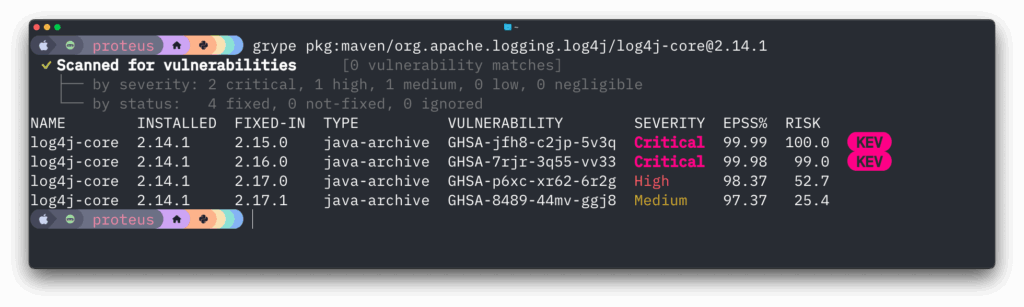
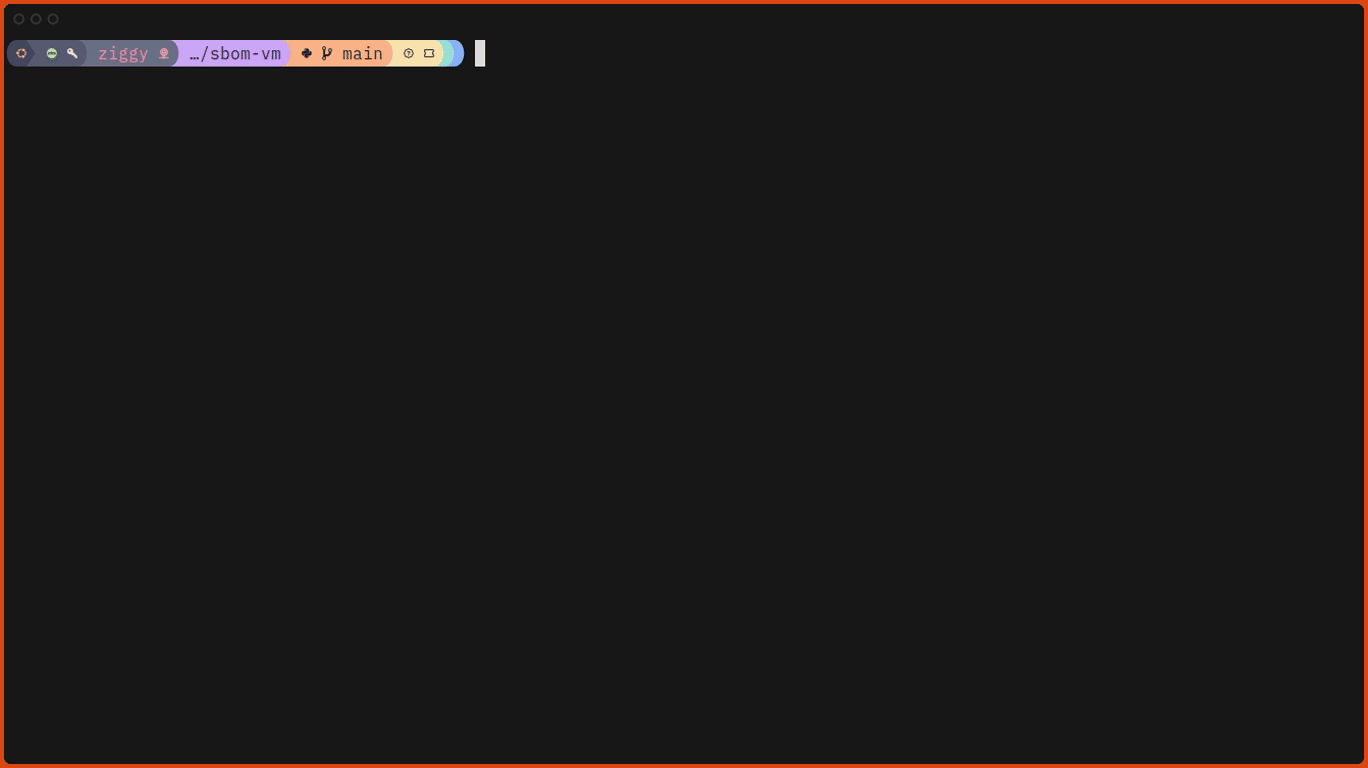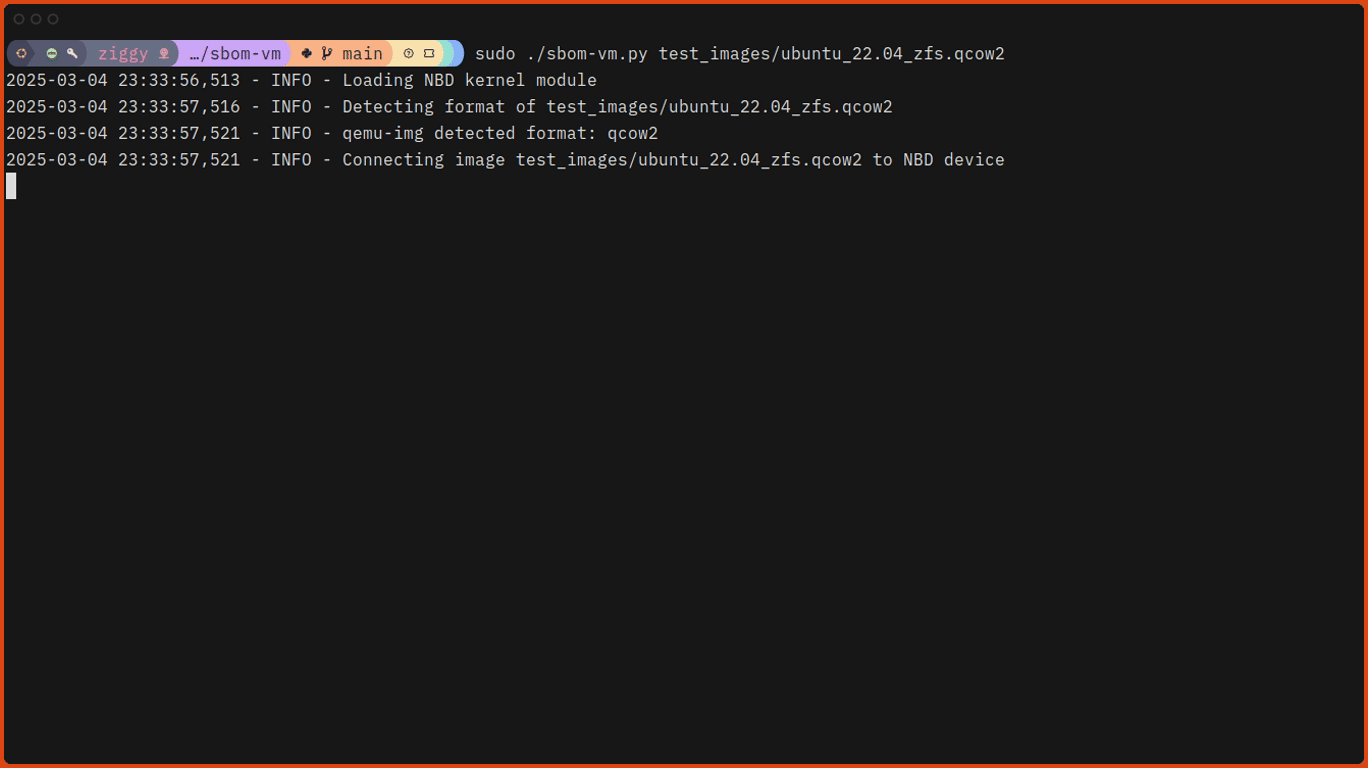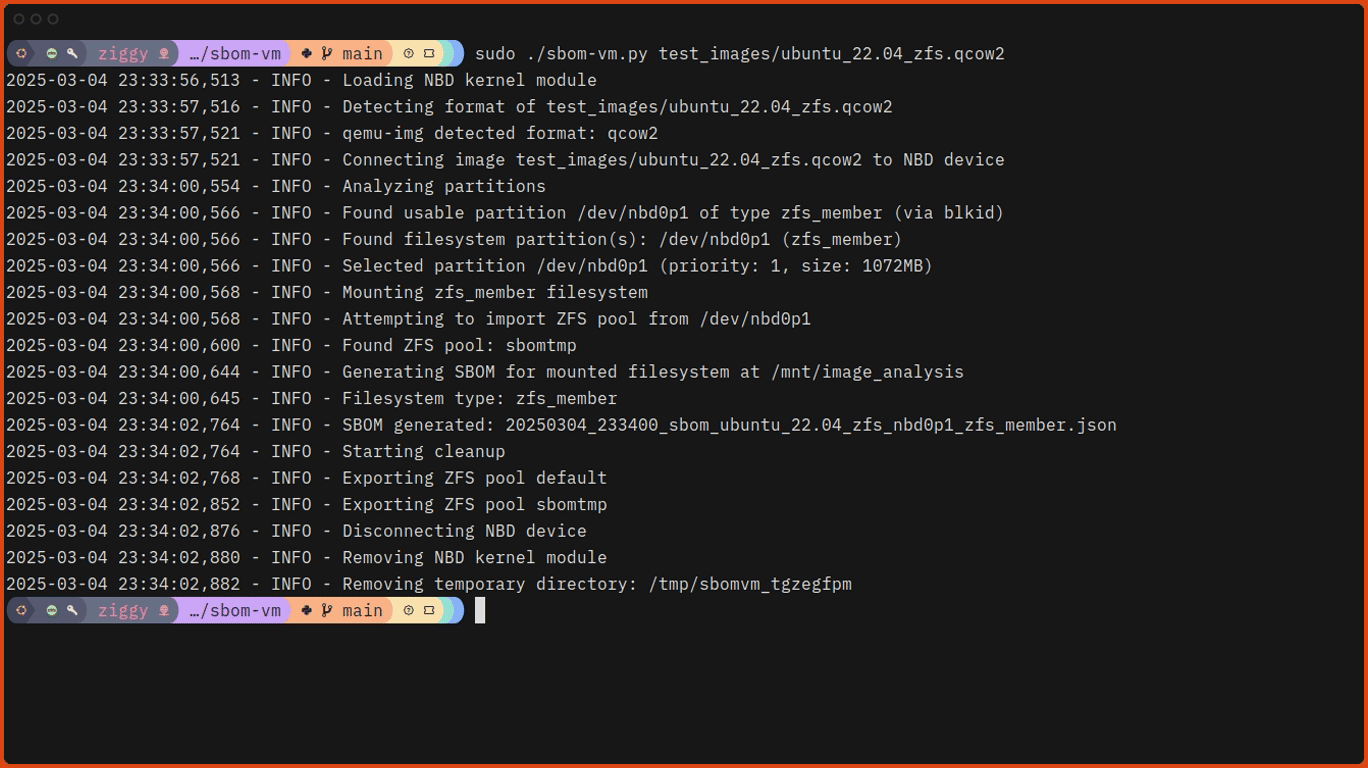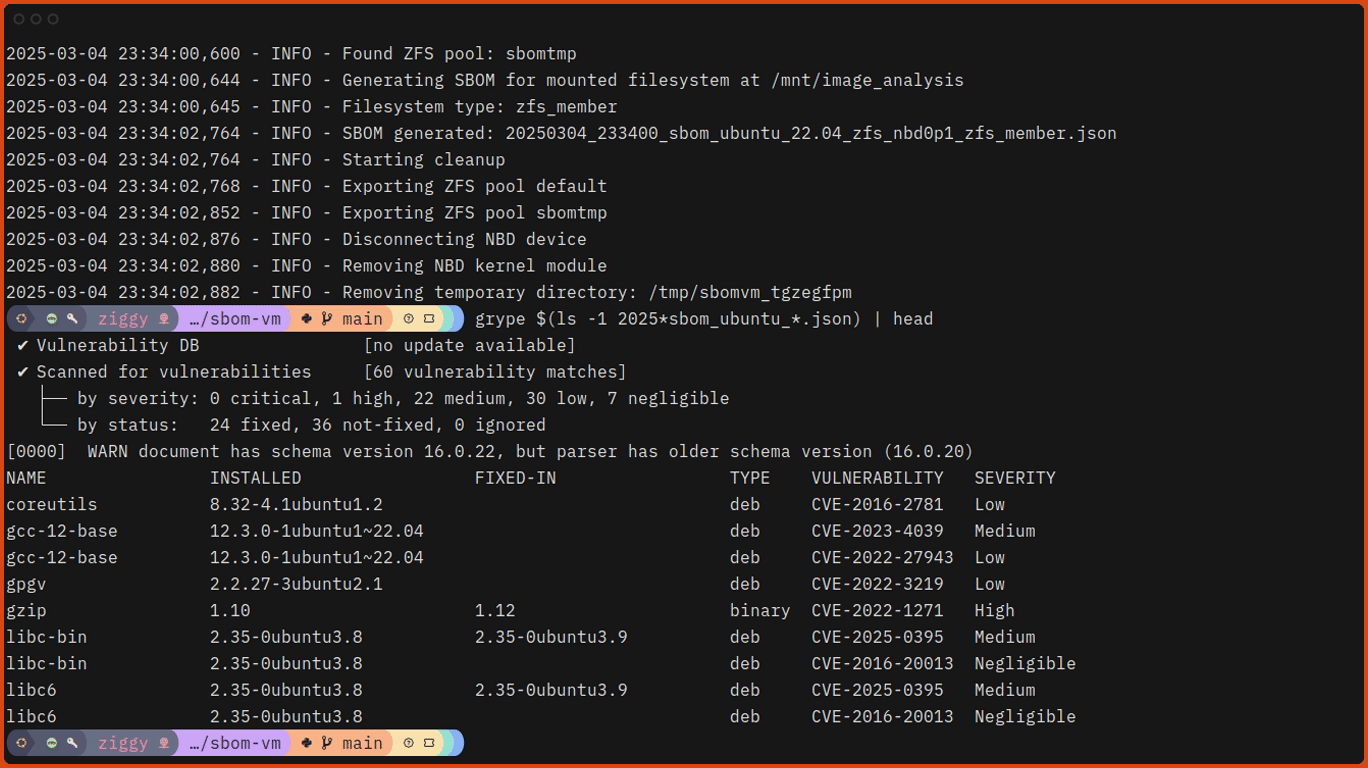
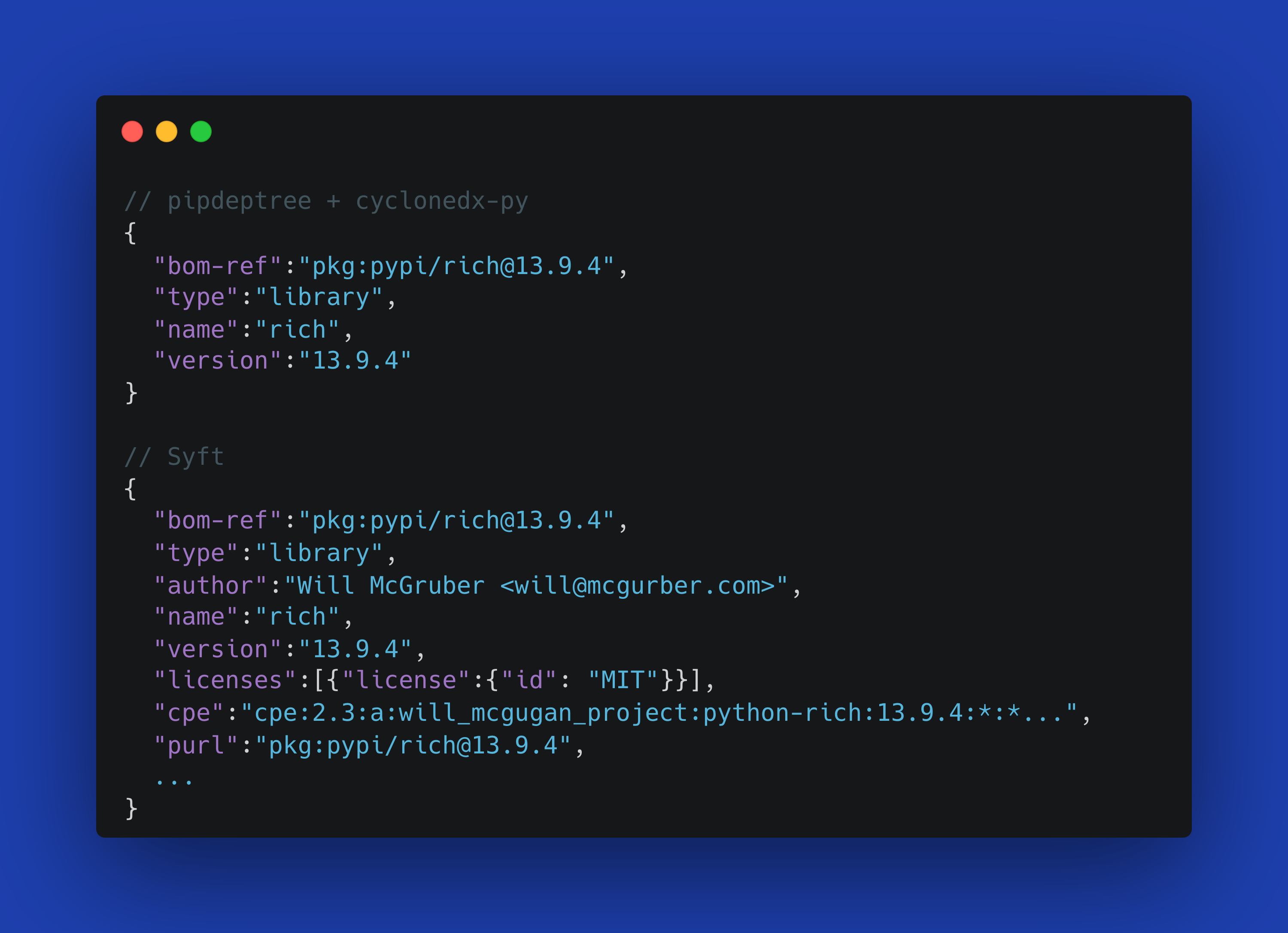
March 16, 2026 was the date the current CVE contract expired. Thanks to some reporting by Cynthia Brumfield we learned there is a future funding plan for the CVE program. It’s a very opaque funding program which means we’re not sure how much, or how long, or anything useful really. We’ll have to watch the CVE program closely going forward to see if there are any hiccups. But regardless we have averted a potential emergency.
Now that the emergency is behind us, it’s a good time to step back and see what the state of vulnerability identifiers is, and what we should expect in the future.
The loss of trust
Let’s spend a few minutes talking about what happened over the last few years, and why it has eroded trust in the existing system. CVE the identifier probably won’t ever go away, but I think it now has a trust issue that will take a lot of hard work to recover from.
In 2024 we saw the NVD just sort of stop working without any real notice or resolution. NVD still hasn’t returned to a fully functioning state. NVD has historically been a source for vulnerability severities and affected products and projects. The data was never perfect and we loved to complain about it, but we certainly missed it when it was gone.
Then in 2025 we saw the CVE program almost lose its funding. This was a wake up call for a lot of the people in the vulnerability universe. Without a functioning CVE program, was there a plan B? There wasn’t for many of us. We just sort of assumed CVE was a staple of the vulnerability universe. Something that will always exist.
I think the takeaway from all the chaos in the last few years is that everyone should have a plan B.
The next steps
After the 2025 funding hiccup from CVE, there have been a lot of groups in the vulnerability community that have been working hard on how to make sure no matter what happens in 2026 (right now), they could find vulnerability data.
We saw the European Union Vulnerability Database (EUVD) go public and start to publish data. This project hasn’t been without some hiccups, but it’s clear the EU is looking to take vulnerability data seriously.
We saw the Global CVE (GCVE) program which is run by the Computer Incident Response Center Luxembourg (CIRCL) make some incredible strides. This is the project to keep an eye on if you’re wondering what a well run vulnerability data looks like.
There are also some really impressive open source vulnerability data projects like the GitHub Advisory Database and Google’s Open Source Vulnerability (OSV) service. Back when nobody knew what was going to happen to CVE, finding new and stable sources of data was a top priority, these two were at the top of everyone’s list.
Fragmentation?
A point often discussed once we start to talk about other vulnerability data sources is that fragmentation is generally bad for an industry. It’s probably worth pointing out that a lack of competition is usually worse than fragmentation. The CVE program has a storied history of not listening to the community and often providing substandard data and services. It’s likely a total lack of competition helped build this unfortunate reality.
However, fragmenting the vulnerability identifiers ecosystem is something that happened a long time ago. Even with CVE IDs, the data NVD provides was different from the data CVE provided. GitHub has advisories that don’t have CVEs. Most large vendors publish their own advisories that use their own naming scheme. These vendor advisories sometimes refer to CVE IDs, but not always.
The companies providing private curated vulnerability datasets are also a source of fragmentation. The CVE ecosystem fragmented a long time ago, what we need now is some good competition to help push everyone forward.
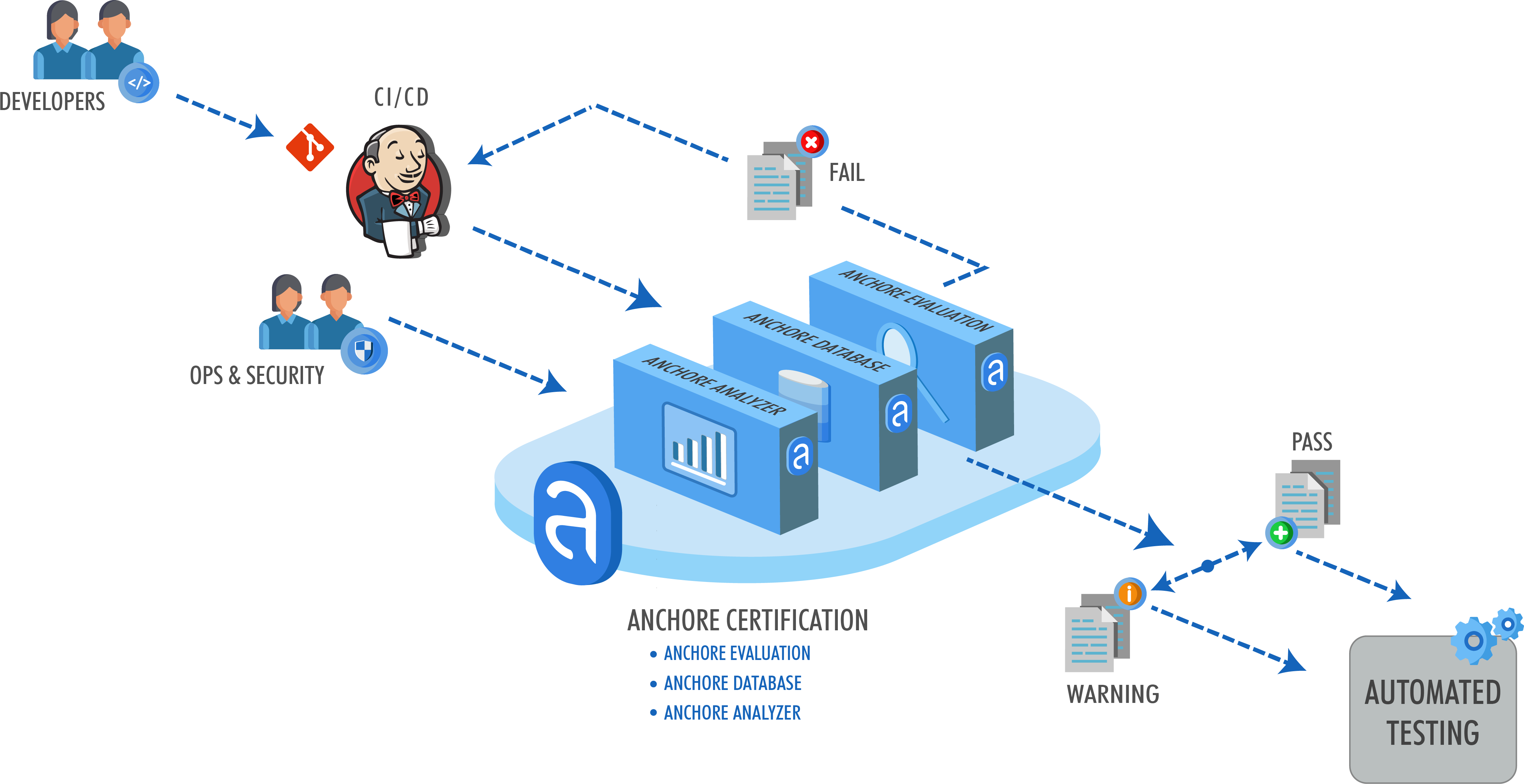
What is Anchore doing?
For the past year, Anchore has been preparing itself for a possible disruption in CVE vulnerability data. We were planning for the worst and hoping for the best. At the moment it looks like we got something closer to “best” than “worst”. This work is really about providing better overall vulnerability data, so CVE existing or not doesn’t really change the outcome. The goal is to make sure Anchore Enterprise and Grype can return high quality vulnerability information.
All CVE and NVD data is proxied and enriched by Anchore
There was once a time Anchore’s products would download the NVD data directly and turn it into a local vulnerability database. This is no longer the case. Anchore tracks our enriched CVEs in a GitHub repo we call Vulnerability Index Spec Files (naming things is hard). This is where we track our enriched CVE data that is used by Anchore Enterprise and Grype. We can update this data as we see fit, build new databases, and push them out very quickly now.
Anchore will be working with the community for data
Even if CVE continues working as before, it’s no secret that the CVE vulnerability data isn’t the best. There is an entire industry that has popped up just to fix all the problems in the CVE data. Anchore is not interested in trying to be a vulnerability data provider. This isn’t a business we want to be a part of. Even our public vulnerability data isn’t something we wanted to do, but we had to have a way to enrich CVE data and fill in all the gaps.
As the year progresses and we learn more about what will happen with CVE and all the other data sources, Anchore will ensure we will help the community any way we can. Finding and helping groups that are using tried and true methods of open source with vulnerability data is a top priority.
We can’t say for sure what comes next, but no matter what happens, it’s probably going to be interesting, and at Anchore we will not only try to help, but we know Anchore Enterprise and Grype will keep working as if nothing happened.
Here’s a scenario: You do the right thing; you choose a minimal, hardened base image (like a Bitnami Secure Image (BSI) 😉) as your app’s foundation. You run a vulnerability scan expecting a clean bill of health, but instead, you get a massive wall of false positives. What gives? The culprit is your scanner failing to recognize the security patches the upstream maintainers applied behind the scenes.
This disconnect is a frustrating reality for teams trying to do “the right thing”. We’ve always admired Bitnami’s approach to building incredibly lean, secure container images (see PhotonOS). But we also know that if the open source ecosystem is going to build on these foundations, scanning tools need to stay in sync with the rest of the community.
That’s why we’re excited to share that Grype now natively supports PhotonOS vulnerability data. This update bridges the data gap. It also continues our proud collaboration with Bitnami to build a more secure, transparent, and quieter software supply chain. Teams no longer need to worry about false positives or missed vulnerabilities. Instead, they can confidently build on BSI knowing their risk is meaningfully reduced.
Scanning Hardening Container Images
As organizations strive to build secure applications, many have turned to minimal, hardened base images. While these lean images are excellent for reducing attack surfaces, accurately scanning them requires domain specific software package analysis and vulnerability data. As a prime example of this, the BSI catalog provides stable software packaging methods as well as a specific vulnerability source to enable accurate scanning.
The Anchore team deployed a two-part technical update to our vulnerability data pipeline. First, we added a new PhotonOS vulnerability provider to Vunnel, the tool that fetches and normalizes our vulnerability data. Second, we updated the Grype database to include this new photon namespace in its daily builds. With these additions, we’re able to support scanning across the BSI software stack (from PhotonOS to the Bitnami specific SBOM cataloger), adding it to the set of supported ecosystems.
You can review the complete technical details of this integration here.
What This Means for Your Security Posture
Going forward, users scanning PhotonOS-based environments, including the ecosystem of Bitnami container images, will see an immediate improvement in the accuracy and reliability of their security scans:
Increased Coverage: Grype now pulls directly from the official PhotonOS metadata, reliably catching genuine vulnerabilities it previously ignored.
Reduced Noise: By understanding PhotonOS-specific versions, Grype correctly identifies when a security fix has been backported, drastically reducing false alerts.
Seamless Updates: You don’t need to change your code. As long as you run grype db update, the new Photon provider is automatically utilized.
Anchore’s Commitment to the Open Source Supply Chain
This update is about more than just a new data feed. It’s about giving developers their time back. You shouldn’t have to waste hours chasing down inaccurate data. Anchore takes its commitment to the open source community seriously. Our partnerships with other leading OSS contributors, like Bitnami, are our way of putting our money where our mouth is.
Ready to see the difference? Run grype db update to grab the latest PhotonOS data, and point Grype at your base images. We encourage the community to grab the latest version of Grype, and try scanning Bitnami Secure Images today!
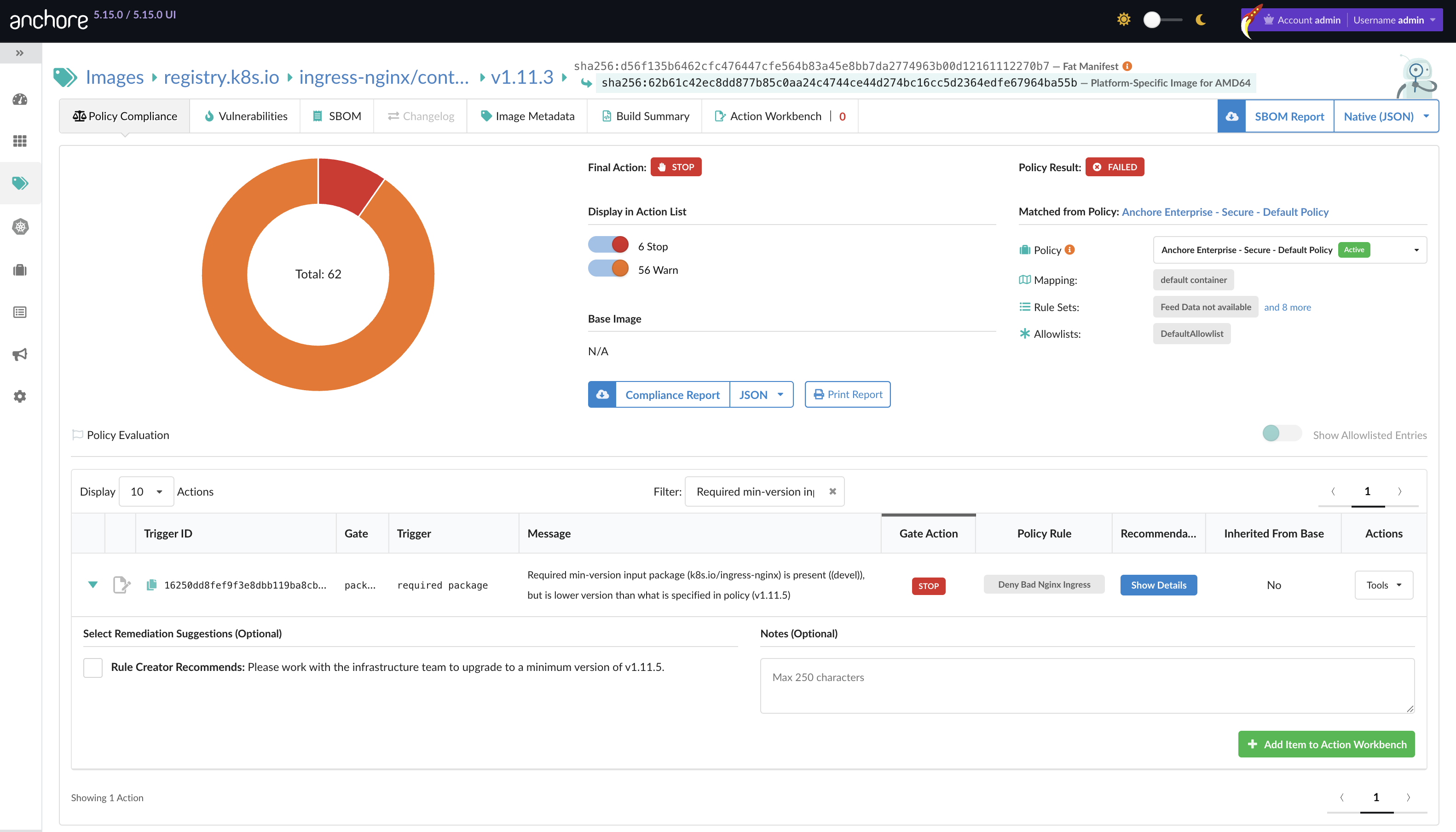
Anchore Enterprise 5.25 introduces a completely rewritten scanning engine and comprehensive upgrades to imported SBOM management. This release is designed to streamline your software supply chain security by delivering consistent analysis across developer and production workflows, advanced EPSS and CISA KEV vulnerability filtering, and automated artifact lifecycle policies. As organizations scale their supply chain security, this update helps DevSecOps teams maintain absolute accuracy while significantly reducing vulnerability noise.
Organizations today are ingesting thousands of SBOMs from 3rd-party vendors, open source projects, and internal builds. The challenge is no longer just generating or collecting these documents; it is managing, filtering, and prioritizing the vulnerabilities within them without drowning in noise or paying for unnecessary storage bloat. Platform engineers require absolute consistency between what a developer sees in their local CLI and what the enterprise backend reports in production.
Anchore Enterprise 5.25 addresses these challenges directly through two major platform upgrades.
The Unified Scanning Engine: Native Syft and Grype Alignment
Organizations often face friction when developer CLI tools and enterprise backend systems utilize different underlying analysis pathways. This can occasionally lead to inconsistent SBOM generation or varying vulnerability results across different workflows, eroding developer trust.
Anchore Enterprise’s image analysis and vulnerability scanning engine has been completely rewritten to align natively with Syft and Grype (Anchore’s flagship open source tools).
Unified Accuracy: SBOMs generated via AnchoreCTL and Anchore Enterprise’s backend are now perfectly consistent, utilizing the same underlying library. You get the exact same results regardless of the workflow. (Note: Because of this alignment, you may observe slight differences in SBOM content and vulnerability results when comparing images analyzed prior to v5.25 against the same image analyzed with v5.25).
Performance & Cost Efficiency: The rewritten engine yields significant performance improvements during analysis and reduces object storage size due to smaller data artifacts, directly controlling infrastructure costs at scale.
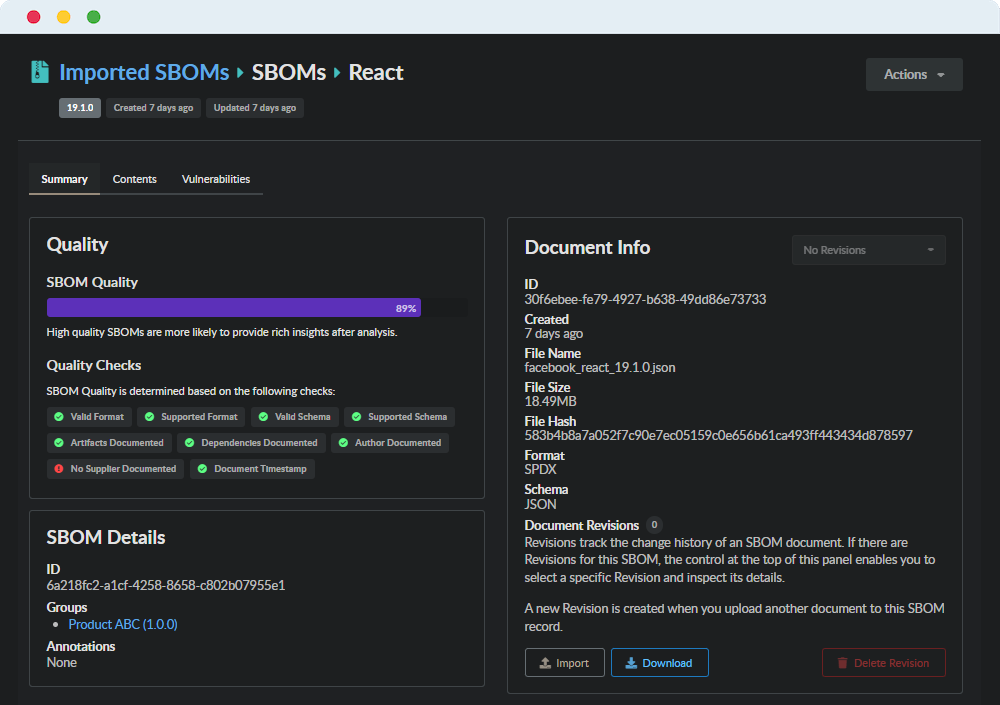
Elevating Imported SBOMs to First-Class Citizens
Traditionally, imported SBOMs have been treated as somewhat opaque flat files compared to natively scanned container images. Anchore Enterprise 5.25 fundamentally changes this, bringing the deep context, discoverability, and lifecycle management previously reserved for container images directly to imported SBOMs.
These upgrades reflect the reality that modern supply chain security extends far beyond containers.
Deep Context via SBOM “Type” Attribute: A new required field classifies exactly what an imported SBOM represents (e.g., Application, Container, Device, File System, Firmware, Library, Virtual Machine Disk). This transforms flat files into context-rich assets, providing immediate clarity on what type of codebase element is being analyzed.
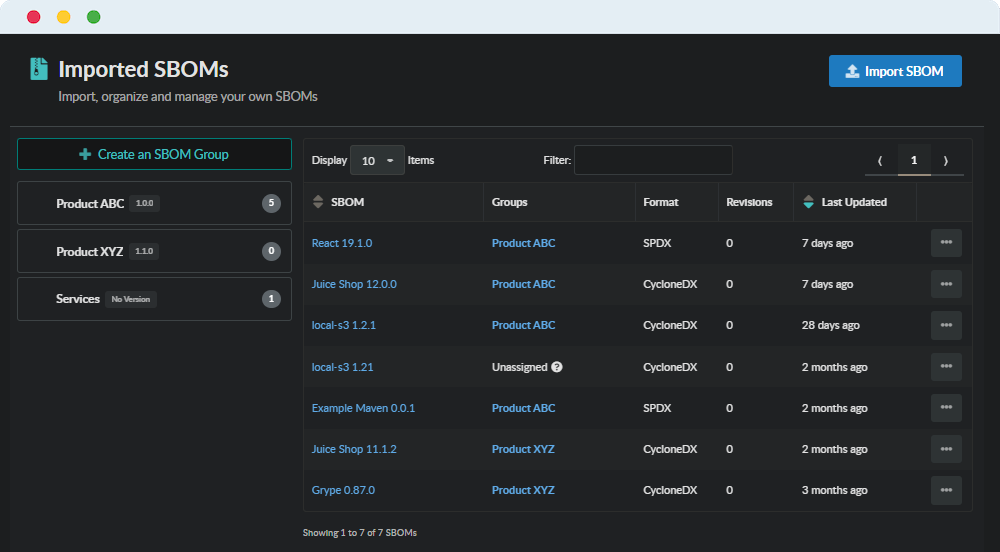
Enhanced Discoverability: New filters on the imported SBOMs page allow teams to search by Name, Version, and Type. As organizations scale to thousands of stored SBOMs, security teams can instantly pinpoint the exact assets they need to review.
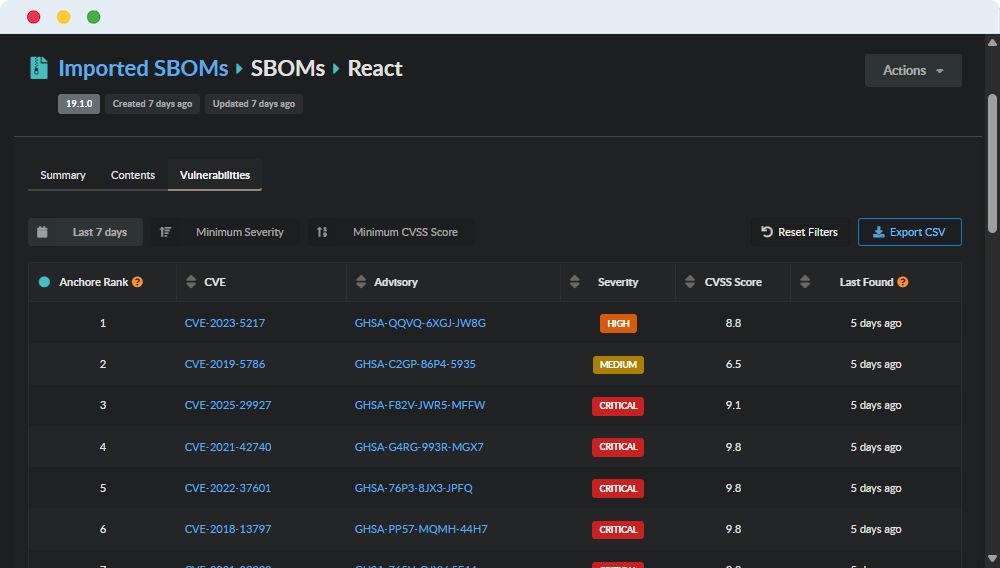
High-Signal Vulnerability Filters: New filters on the imported SBOMs vulnerability page include Minimum CVSS, Minimum EPSS Score, On CISA KEV List, Vulnerability Name/ID, and Severity. Cures vulnerability fatigue. By filtering for highly exploitable vulnerabilities (via EPSS and CISA KEV), security teams can focus their remediation efforts on what actually poses a risk, rather than drowning in low-severity CVEs.
Automated Artifact Lifecycle Policies: Support for Imported SBOMs has been added to the Artifact Lifecycle Policy engine. Platform engineers can automate the cleanup of “old” or stale imported SBOMs based on user-defined criteria, maintaining strict control over object storage bloat.
How It Works: Managing Imported SBOM Lifecycles
To prevent storage bloat, you can now configure lifecycle policies for imported SBOMs directly alongside your container image policies.
For example, you can automatically purge imported SBOMs of an “Unknown” type that are older than 90 days. This can be configured via the API or directly in the UI under Policies → Artifact Lifecycle.
Developers: Benefit from “Unified Accuracy.” By using AnchoreCTL locally, developers see the exact same SBOM and vulnerability results that the security team will see in the enterprise backend, eliminating the “it passed on my machine” friction.
Security Architects: Can apply modern, exploit-driven prioritization metrics (CISA KEV and EPSS) to third-party software and firmware, dramatically reducing triage time.
Platform Engineers: Gain programmatic control over storage costs with automated Artifact Lifecycle Policies for thousands of imported SBOMs.
Ready to Upgrade?
Anchore Enterprise 5.25 delivers the unified consistency developers want and the comprehensive, scalable supply chain security that enterprise platform and security teams demand.
Existing Customers:
Upgrade to Anchore Enterprise 5.25 today. Reach out to your Account Manager for upgrade support.
The one-and-done approach to cybersecurity compliance has been obsolete for more than a decade. Even periodic, audit-driven assessments of an organization’s compliance posture are no longer sufficient in modern environments.
In recent years, this urgency has only intensified. The pace of technological change, the expansion of the software supply chain, and escalating regulatory scrutiny have made automation and continuous compliance not just best practices, but operational necessities. Here’s why:
Constantly Evolving Threat Landscape
New vulnerabilities are discovered every day, from zero-day exploits to newly disclosed CVEs in widely used software. A system that met compliance requirements last quarter may already contain exploitable weaknesses today. At the same time, attackers are increasingly using automation and AI to scan for vulnerabilities at scale, dramatically shortening the window between disclosure and exploitation. In this environment, static controls quickly become outdated.
Dynamic Infrastructure (Cloud & Containers)
Modern infrastructure is no longer static. Cloud resources, containers, and serverless functions are constantly spinning up and down, meaning the environment you audited last month may not even exist today. Infrastructure as Code enables rapid changes, but a single misconfiguration pushed through a CI/CD pipeline can introduce compliance violations across an entire environment in minutes. Continuous visibility is required to maintain control.
Software Supply Chain Complexity
Today’s applications are built on layers of open source dependencies, many of which include nested, transitive components. A newly discovered vulnerability in any one of those dependencies can introduce risk long after your software is deployed. Additionally, organizations increasingly rely on third-party vendors and SaaS providers, expanding the compliance boundary beyond internal systems and requiring ongoing vendor risk management rather than one-time assessments.
The Shifting Sands of Regulatory Requirements
Compliance frameworks are not static documents. Standards such as SOC 2, ISO 27001, FedRAMP, PCI DSS, and NIST regularly update their guidance to reflect emerging threats and best practices. At the same time, new regulations—particularly around data privacy and cybersecurity reporting—continue to emerge across different jurisdictions. Organizations must continuously adapt to remain compliant.
Rapid DevOps & CI/CD Pipelines
Development cycles have accelerated dramatically. Code is deployed weekly, daily, or even multiple times per day, meaning compliance controls must operate at the same speed. Security can no longer be a checkpoint at the end of a release cycle; it must be integrated into development workflows from the beginning. Without automation and embedded validation, compliance quickly falls behind deployment velocity.
What is Continuous Compliance Monitoring?
Continuous compliance monitoring is the practice of validating security and regulatory controls on an ongoing basis across the software lifecycle—not just at audit time. Rather than relying on static reports or periodic assessments, it embeds automated policy enforcement, vulnerability detection, and configuration checks directly into CI/CD pipelines and runtime environments. The objective is to maintain real-time evidence that controls are functioning as intended as code, dependencies, and infrastructure evolve.
Continuous compliance doesn’t happen by accident. It requires intentional design: systems that can scale with modern software delivery, surface meaningful signals from noise, and reduce dependency on manual oversight. Those capabilities rest on three foundational pillars.
The 3 Key Pillars of Continuous Compliance
At its core, continuous compliance monitoring rests on three foundational pillars:
Compliance automation: Manual processes are slow, prone to human error, and simply can’t keep up with the pace of change. Automation is the engine that drives continuous monitoring, gathering data, checking configurations, and identifying deviations without constant human intervention.
Real-time visibility: This isn’t about looking at yesterday’s reports. It’s about having an immediate view into your compliance posture. If a critical system’s configuration drifts out of compliance, you know about it now, not next week. This visibility allows for immediate corrective action.
Actionable insights: Raw data isn’t enough. Continuous monitoring systems don’t just collect information; they analyze it, correlate events, and present you with clear, actionable insights. This means distinguishing between minor anomalies and critical violations, empowering security teams to prioritize remediation while providing clear reporting and evidence to key stakeholders.
Together, these pillars create a robust defense that constantly checks your systems, networks, and data against your defined compliance standards, ensuring deviations are caught and addressed promptly.
How to Implement Continuous Compliance Monitoring: A Step-by-Step Approach
Embarking on continuous compliance monitoring might seem daunting, but like any significant journey, it becomes manageable when broken down into clear, actionable steps.
Step 1: Define Your Compliance Scope and Objectives
Before you can monitor anything, you need to know what you’re monitoring for and why. Begin by clearly identifying all relevant regulatory frameworks, industry standards, and internal policies that apply to your organization. This might include FedRAMP, NIST 800-53, GDPR, HIPAA (for healthcare organizations), PCI DSS, ISO 27001, or a combination thereof. For each, articulate specific, measurable compliance objectives. What does “compliant” look like for each requirement? This foundational step ensures your efforts are focused and aligned with your organizational goals.
Step 2: Identify Key Controls and Metrics
Once your scope is defined, translate those compliance requirements into specific technical and administrative controls. For example, if a requirement is “data must be encrypted at rest,” your control might be “ensure all database storage volumes are encrypted using AES-256.” For each control, establish clear metrics that indicate its health and compliance status. How will you measure if encryption is enabled? What defines “successful” patch management? These metrics will be the data points your monitoring system relies on.
Step 3: Select the Right Technology and Tools
Continuous compliance is only as strong as the systems enforcing it. If your controls depend on manual reviews, disconnected scanners, or point-in-time reporting, you’re not operating a continuous model—you’re layering automation onto a compliance audit workflow. The right tooling must integrate directly into how software is built, delivered, and run.
To operationalize continuous compliance effectively, organizations should look for automated tools that provide:
Software composition visibility & SBOM management: Modern applications are built on complex open source ecosystems, and compliance requirements increasingly demand traceability across dependencies. Tools should generate accurate, reproducible Software Bills of Materials (SBOMs) and allow teams to manage and evaluate them over time.
Policy-driven vulnerability & compliance enforcement: Detecting CVEs is table stakes. The real requirement is the ability to codify compliance frameworks (whether federal, internal, or otherwise) into enforceable policies that run automatically in CI/CD pipelines and registries.
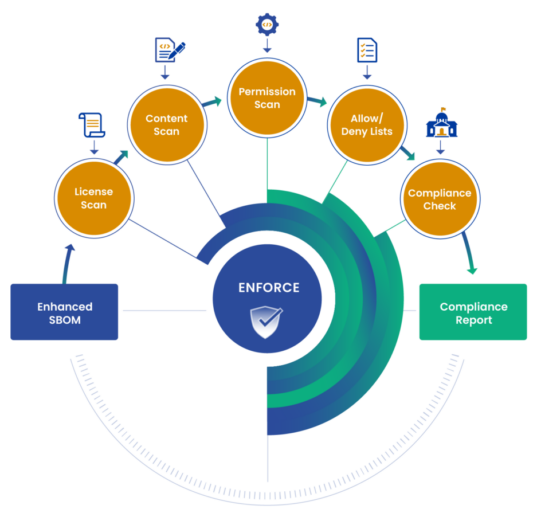
🛡️ How Anchore helps: Anchore allows you to deploy a ready-to-use policy to achieve compliance with a variety of federal standards. Each rule is mapped to the specific control version for easy report and evidence generation.
Lifecycle-wide risk evaluation:Cybersecurity compliance cannot stop at build time. The risk profile of deployed software changes as new vulnerabilities are disclosed. Tools should continuously re-evaluate existing artifacts against updated vulnerability intelligence to identify newly introduced risk.
🛡️ How Anchore helps: Anchore continuously analyzes stored SBOMs against fresh vulnerability feeds, ensuring you’re alerted when previously compliant software becomes non-compliant.
Actionable, context-rich intelligence: Security teams don’t need more dashboards—they need prioritization. Tools should correlate vulnerabilities with severity, exploitability, and policy impact so teams can focus on meaningful remediation.
🛡️ How Anchore helps: Anchore makes it easy to prioritize vulnerability rating based on CVSS Score and Severity, EPSS, and CISA KEV data, reduce noise and drastically improve triage time.
Developer-aligned, automation-first integration: Continuous compliance only works when it integrates seamlessly into CI/CD pipelines, artifact registries, and cloud-native workflows without slowing delivery.
In short, continuous compliance isn’t achieved by running more scans—it’s achieved by embedding enforceable, automated policy controls into the fabric of software delivery. The right tools don’t just help you pass an audit; they help you maintain provable compliance as your software and threat landscape evolve.
Step 4: Establish Automated Monitoring and Alerting
With your tools in place, set up continuous data collection and automated checks against your defined controls and metrics. This means configuring your systems to constantly scan for misconfigurations, policy violations, unauthorized access attempts, and other deviations from your compliance baselines. Crucially, establish a robust alerting system. Who needs to be notified when a critical control fails? How are alerts prioritized? Define clear thresholds and escalation paths so that issues are promptly brought to the attention of the right personnel.
Step 5: Integrate with Incident Response and Remediation
Monitoring is only useful if detected issues are addressed. Integrate your continuous compliance system with your existing incident response and remediation processes. When an alert fires, it should trigger a predefined workflow. This might involve automatically creating a ticket in your service desk system, notifying a specific security or operations team, or even triggering automated remediation actions (e.g., reverting a misconfigured setting). The goal is to move seamlessly from detection to resolution, minimizing the window of non-compliance.
Step 6: Regularly Review and Refine Your Program
Compliance isn’t a one-time project; it’s an ongoing journey. Regularly review the effectiveness of your continuous compliance monitoring program. Are your controls still relevant? Are your metrics accurate? Are there new regulations or threats that require adjustments? Conduct periodic internal audits of your monitoring system itself. Gather feedback from the teams responsible for responding to alerts. This iterative process of review and refinement ensures your program remains robust, relevant, and continuously improves over time.
Getting Started with Continuous Compliance Monitoring
In a world where software changes daily and regulatory expectations evolve just as quickly, continuous compliance is no longer optional. Anchore Enterprise helps organizations move beyond audit-driven security by embedding automated, policy-based enforcement directly into the software supply chain. Contact us today for a personalized demo.
Watch our customer Dreamfactory explain how Anchore Enterprise simplifies and automates their compliance needs.
For a decade, the security industry’s rallying cry was “you can’t secure, what you can’t see.” We demanded to know what was in our software. But now that we have it, we are discovering a harsh truth: visibility without context is just noise. Security teams are currently drowning in a flood of disjointed manifests and static spreadsheets, creating a paradox where we have more data than ever, yet remain unable to answer the fundamental question: “Are we safe?”
This paradox, where more artifacts lead to less clarity, is what we term “SBOM Sprawl.” In our recent webinar, How to Identify and Tackle SBOM Sprawl, Alex Rybak (Anchore) and Russ Eling (OSS Consultants) dissected this growing challenge, outlining how organizations can move from simple compliance generation to intelligent orchestration.
Key takeaways from their discussion include:
The Assembly Paradox: Why modern software development mirrors the tiered supply chain of Boeing’s aerospace manufacturing
The Map vs. The Territory: Why a static SBOM is merely a roadmap, and how its value depends entirely on the tools that consume it
The 4-Day Clock: How SEC material event regulations are forcing security teams to prioritize query speed over data volume
Realistic Scope: Understanding that SBOMs are tools for managing known vulnerabilities, not magic wands for unforeseen threats
The Complexity Trap: Lessons from Aerospace
Alex Rybak, Director of Product Management at Anchore, notes a critical parallel between physical and digital supply chains.
An airplane has 10s of millions of parts, and Boeing ultimately builds the tail fin, rear fuselage and wing fairings…that’s it.
This observation highlights a fundamental reality: modern engineering is an assembly challenge, not a fabrication challenge. In the software world, dependency trees have exploded from dozens of libraries to thousands of direct and transitive components.
This complexity is fundamentally different from the monolithic applications of the past. Where traditional software was written in-house with a few trusted libraries, modern cloud-native applications are assembled from global, open source supply chains. When an organization generates SBOMs without a strategy for this complexity, they don’t gain visibility; they simply generate noise.
The Evolution of SBOM Sprawl
This isn’t the first time the industry has faced a visibility crisis. The pattern we’re seeing with SBOM regulation is remarkably similar to the early days of open source adoption. First came the explosion of usage, followed by the scramble for governance.
From Static Files to Dynamic Systems
Phase 1: The Artifact Era (Pre-2021) was characterized by sporadic, manual inventory tracking. Organizations viewed SBOMs as “nice-to-have” documentation. Security reviews were manual because release cadences were slower. Visibility was limited, but so was the volume of data.
Phase 2: The Regulatory Explosion (2021-2024) brought transformation via EO 14028 and the EU Cyber Resilience Act. Requirements exploded, leading to “SBOM Sprawl.” Every customer demanded different formats (SPDX 2.3 vs. CycloneDX), fields, and delivery mechanisms. This led to data conflicts, where the SBOM generated by engineering didn’t match the one scanned in production, complicating response to incidents like Log4j.
Phase 3: The Systemization Era (2025-Present) emerged as standards like SPDX 3.0 and ISO 5230 provided structure. Organizations realized that generation is a commodity; the value lies in ingestion, analysis, and VEX (Vulnerability Exploitability eXchange) implementation.
We are now seeing this evolution compressed into a much shorter timeframe, driven by aggressive regulatory deadlines.
Learn how to transform your SBOMs from a compliance checkbox into a strategic asset, with the controls needed to prevent sprawl and maximize value.
The presence of an SBOM file does not equate to security posture. As Rybak emphasizes:
“Just having an SBOM doesn’t fix problems, it gives you a roadmap on your parts…an SBOM is only as good as the tools or people that built it.”
A static SBOM is fundamentally different from a managed software supply chain. A file on a disk ages the moment it is generated. If that roadmap is inaccurate, outdated, or disconnected from vulnerability intelligence, it becomes a liability rather than an asset.
Effective governance requires moving from “having an SBOM” to maintaining a dynamic inventory that maps assets to risks. This means integrating SBOM generation into the CI/CD pipeline, ensuring that every build produces a high-fidelity record that can be queried when the next zero-day hits.
The Financial Imperative: The 4-Day Clock
The stakes for accurate data have shifted from technical debt to legal liability. Rybak points out the specific pressure created by the SEC:
“If you look at SEC regulations, if there has been a material security event, the clock starts. You have four days to create an 8K report.”
This requirement fundamentally alters the role of the security team. Incident response is no longer just a technical triage; it is a financial disclosure workflow.
When a material event occurs, organizations cannot afford to spend days grep-ing through repositories or emailing engineering leads to ask, “Do we use this library?” The 4-day window requires instant, queryable visibility. Sprawl the enemy of speed.
Pragmatism and Scope
While SBOMs are essential, Russ Eling, Founder of OSS Consultants, offers a necessary reality check regarding their capabilities:
“SBOMs are not a cybersecurity cure-all. They’re effective at managing known vulnerabilities. They don’t necessarily extend to detecting unforeseen threats.”
An SBOM provides transparency into known components and allows organizations to map them against known vulnerabilities (CVEs). It does not inherently detect zero-day exploits or behavioral anomalies in runtime.
However, the key insight is that without an SBOM, you cannot effectively manage the knowns, which leaves zero bandwidth to hunt for the unknowns. By automating the management of known vulnerabilities through high-quality SBOMs and VEX, security teams free up human capital to focus on advanced threat hunting and architectural security.
Where Do We Go From Here?
To tame SBOM sprawl and turn compliance artifacts into security assets, organizations must adopt a phased approach.
Crawl: Standardization and Governance
Define the Standard: Select a primary internal format (e.g., SPDX 2.3 or 3.0) for storage, regardless of what customers request. Use converters for export only.
Establish Ownership: As Eling suggests, define whether the OSPO, Product Security, or Engineering owns the SBOM process.
Align with ISO 5230: Use the OpenChain standard to establish the foundational governance required to produce trusted data.
Walk: Automation and Context
Automate Generation: Integrate tools like Syft or Anchore Enterprise into the build pipeline. No manual generation.
Centralize Ingestion: Feed all SBOMs into a central management platform. A dispersed inventory is a useless inventory.
Implement VEX: Stop chasing false positives. Use VEX to communicate which vulnerabilities are not exploitable, reducing noise for downstream consumers.
The Strategic Imperative
The window of opportunity to establish these systems is open, but it won’t remain that way indefinitely. Just as organizations that ignored open source governance paid a heavy price during the Log4j crisis, those who ignore SBOM sprawl will face compounding technical debt and regulatory friction.
Organizations that transition from generating files to managing systems will gain significant agility. They will turn the 4-day SEC mandate from a crisis into a standard operating procedure, demonstrating resilience to customers and regulators alike.
Learn how to transform your SBOMs from a compliance checkbox into a strategic asset, with the controls needed to prevent sprawl and maximize value.
Manual security checks are the enemy of speed. For Federal System Administrators and ISSOs, “stigging” a system manually (going line-by-line through hundreds of XML checks) is not only tedious; it’s impossible at the scale of modern software factories.
With the Department of Defense (DoD) moving toward continuous Authority to Operate (cATO), the days of manually creating .ckl files once every 90 days are over. To meet the requirements of the Risk Management Framework (RMF) without halting deployment, automation is the only path forward.
In this post, we break down the top tools for 2025, categorized by their specific role in your infrastructure; from traditional OS hardening to modern container security.
At a Glance: Top STIG Compliance Tools
If you are looking for the right tool for a specific job, here is the quick breakdown:
Tool
Best For
Type
Cost
Anchore Enterprise
Containers & Kubernetes
Automated Compliance Platform
Commercial
DISA STIG Viewer
Viewing Manual Checklists
Desktop Utility
Free (Gov)
SCAP Compliance Checker (SCC)
Local OS Scanning
Scanner
Free (Gov)
MITRE SAF
DIY DevSecOps / Custom Profiles
Open Source Framework
Free (Open Source)
SteelCloud ConfigOS
Windows/Linux Remediation
Remediation Tool
Commercial
Tenable.sc (ACAS)
Network & VM Scanning
Vulnerability Management
Commercial
Evaluate-STIG
Documentation/Checklists
Documentation Utility
Free (Gov)
Essential Free Utilities
Every federal engineer needs these two utilities installed. They are the “gold standard” provided directly by DISA and are often the baseline against which other tools are measured.
1. DISA STIG Viewer
Type: Desktop Utility (Java)
Best For: Manually viewing STIGs and creating .ckl files.
The DISA STIG Viewer is the official tool for viewing XCCDF (eXtensible Configuration Checklist Description Format) files. It allows you to import a STIG, view the specific requirements (Vuln IDs, Rule IDs), and manually mark them as Open, Closed, or Not Applicable.
Pros: It is the official system of record. If you are submitting a checklist to an ISSO, it usually needs to be in a format this tool can read.
Cons: It is entirely manual. It does not “scan” your system; it is simply a digital clipboard for you to record your findings.
2. SCAP Compliance Checker (SCC)
Type: Local Scanner
Best For: Ad-hoc scanning of local Windows or Linux servers.
SCC is DISA’s comprehensive scanning tool. Unlike the STIG Viewer, SCC actually scans the target operating system against the SCAP (Security Content Automation Protocol) content. It produces a compliance score and a detailed report of which settings failed.
Pros: Extremely accurate for traditional Operating Systems (RHEL, Windows Server).
Cons: It is a “point-in-time” scanner. It doesn’t scale well for cloud-native environments or CI/CD pipelines where containers are created and destroyed in minutes.
Best Tools for Container & Cloud-Native STIG Compliance
Traditional tools often struggle with containers. They treat a container like a small server, attempting to SSH in and scan it—a practice that breaks the immutable nature of containers. For modern DoD Software Factories, you need tools built for the cloud-native stack.
3. Anchore Enterprise
Type: Container Security & Compliance Platform
Best For: DoD Software Factories, Kubernetes, and CI/CD Pipelines.
Anchore Enterprise is built to solve the specific challenge of securing the software supply chain. Unlike traditional scanners that wait until a system is running to check it, Anchore scans container images before they are deployed.
Why it stands out:
Legacy scanners (like ACAS) often can’t see inside the layers of a container image effectively, leading to false positives or missed findings. Anchore analyzes the image contents—packages, binaries, and configuration files—and matches them against DoD-specific policy packs.
Automated Gates: Block builds in Jenkins/GitLab if they fail STIG checks (e.g., a container running as root).
Policy-as-Code: Define your STIG policies once and enforce them across every build, ensuring that only compliant images ever reach your Kubernetes cluster.
Remediation: Provides clear guidance to developers on why a build failed, reducing the friction between security and engineering.
Best For: DIY DevSecOps teams building custom validation profiles.
MITRE SAF is an open-source project that brings together testing libraries (like InSpec) and data converters to visualize security data. It is excellent for teams that want to write custom tests (“InSpec profiles”) to validate specific application configurations that standard STIGs might miss.
Connection: Anchore collaborates with the MITRE SAF team to ensure that compliance data can be shared and visualized effectively across different platforms.
Learn how to harden your containers and make them “STIG-Ready” with our definitive guide.
For the “iron” of your data center—routers, switches, and bare-metal servers—these tools remain the industry heavyweights.
5. SteelCloud ConfigOS
Type: Remediation Automation
Best For: Mass-remediation of Windows/Linux servers.
While most tools find the problem, SteelCloud’s ConfigOS is famous for fixing it. It automates the remediation process, effectively “healing” the system to bring it into compliance with the STIG.
Key Feature: Its “Remediation with Rollback” capability allows admins to apply STIG controls to thousands of endpoints and roll them back if a configuration breaks a critical application.
6. Tenable.sc / ACAS
Type: Vulnerability Management
Best For: General network scanning and continuous monitoring.
In the DoD, you will know this simply as ACAS (Assured Compliance Assessment Solution). It is the mandated vulnerability scanning suite for government networks.
Context: ACAS is powerful for mapping your network and finding unpatched servers. However, for DevSecOps teams, reliance solely on ACAS can be a bottleneck, as scans often happen late in the staging environment rather than in the build pipeline.
7. SolarWinds Network Configuration Manager (NCM)
Type: Network Management
Best For: Network engineers managing Cisco/Juniper switches.
For the network layer, SolarWinds NCM provides automated config backups and vulnerability assessments. It can automatically check device configurations against NIST and DISA STIG standards to ensure a router hasn’t drifted out of compliance.
Best Tools for Documentation & Checklist Automation
8. Evaluate-STIG (NAVSEA)
Type: Documentation Utility
Best For: Automating the creation of .ckl files.
Originally developed by NAVSEA, Evaluate-STIG is a utility designed to bridge the gap between raw scan data and the manual checklist. It allows you to import scan results (from SCC or ACAS) and automatically populate the corresponding checks in the STIG checklist.
Why it matters: It drastically reduces the “paperwork fatigue” of compliance, allowing ISSOs to focus on the open findings rather than manually checking boxes for passing items.
Implementation Tips for STIG Automation
Adopting tools is only half the battle. Here is how to implement them effectively in a DevSecOps workflow:
Map specific CCIs to your controls: Don’t just “scan for STIGs” in a vacuum. You need to know which Control Correlation Identifiers (CCIs) map to your required NIST 800-53 controls. This mapping is what allows you to prove to an assessor that your automated scan actually satisfies a specific security requirement.
Shift Left (for real): Waiting for a scan in the staging environment is too late. By the time a vulnerability is caught there, the developer has already moved on to the next task. Use tools like Anchore to fail builds in the CI/CD pipeline immediately if they violate STIG policies. This creates a tight feedback loop and cheaper remediation.
Automate the “Not Applicable” findings: A huge part of STIG fatigue is reviewing items that simply don’t apply to your architecture. Use overlays or policy files to permanently mark irrelevant checks as “N/A” (with justification). This ensures your engineers stop reviewing the same irrelevant findings every week.
Choosing the Right Tool for the Mission
There is no single “magic bullet” for compliance. A robust RMF strategy requires a stack of tools:
SCC & STIG Viewer for your baseline, ad-hoc checks.
ACAS (Tenable) for your network-wide vulnerability management.
Anchore Enterprise to secure the containers and software supply chain that run your modern applications.
Modern DoD software factories cannot rely on manual checklists. Automation is not just about saving time; it is the only way to move at the speed of the mission while maintaining a hard security posture.
Learn how to harden your containers and make them “STIG-Ready” with our definitive guide.
If you look at the trajectory of the software supply chain over the last few years, one thing becomes painfully clear: the old playbook is broken. For a decade, our industry has operated under the assumption that if we just hired enough people, bought enough scanners, and worked hard enough, we could reach a state of “perfect” security. We chased a clean dashboard with zero CVEs and a fortress-like perimeter.
But as we look toward 2026, that goal isn’t just difficult; it is mathematically impossible. We are facing a convergence of pressures that no amount of manual effort can withstand. The winners of the next era won’t be the ones with the cleanest reports. They will be the ones who have automated their compliance and built the engines to upgrade faster than the bad actors can attack.
To be honest, we don’t have a crystal ball. Nobody does. But we are trying our best to skate to where the puck is going. We want to share what we’re seeing so we can all navigate this shift together.
Reachability is not a silver bullet
For a long time, we pinned our hopes on “reachability.” The idea was simple: if a vulnerability isn’t reachable in the code, we don’t need to fix it. It was a triage strategy born of necessity.
However, the sheer volume of CVEs is growing out of control. Reachability is becoming a noisy, diminishing metric. It struggles to keep up with the flood. Reachability struggles with weakly typed languages like Python and Nodejs, which also happen to be two insanely popular languages. There’s also the problem of while you might not be using the code in question, can an attacker? The infosec world likes to call this “living off the land”. And there’s always the problem where someone starts using code that wasn’t used in the past, now you have a vulnerability that jumps out of nowhere unexpectedly.
We are moving toward a new metric: high velocity hygiene.
The question is shifting from “Is this vulnerable?” to “How fast can we upgrade?” We need to upgrade everything faster, not just the things with red flags attached to them. The goal is general hygiene across all of our code and dependencies. Technology that didn’t exist even a few years ago has come a long way to help us solve this problem. Hardened container images, vendored libraries, and automatic updates can make a gigantic difference. And of course vulnerability scanners that are fast and cover more ecosystems than ever before double check our work.
Supply chain attacks on steroids
Attacks will continue to rise because the fundamental incentives haven’t changed. Attackers still see many package repositories as prime targets, and every package repository is still struggling with resources. The rate of growth is not matching the rate of attacks. In fact, the attackers are about to get an upgrade.
We expect a significant increase in scale and sophistication as attackers leverage Large Language Models (LLMs). There is a distinct asymmetry at play here. Attackers have “zero red tape.” They can adopt new AI tools for exploitation immediately. We saw the start of this behavior with the Shai-Hulud attack in 2025.
Defenders, conversely, are slowed by procurement, legal reviews, and legacy infrastructure integration. This speed gap favors the adversary. While prevention is ideal, rapid response is the only viable reality for 2026.
EU CRA wake-up call
The industry is largely caught off guard regarding the EU Cyber Resilience Act (CRA). Later this year, (specifically; September 11) both vulnerability management and incident response will become law. As most deadlines work, the vast majority of organizations will start working on this around September 10.
This introduces strict reporting obligations (Article 14). Organizations must report actively exploited vulnerabilities and severe incidents to national authorities (CSIRTs) and ENISA within strict timelines.
Beyond reporting, SBOM requirements will be a critical part of this compliance landscape. You cannot report on what you do not know you have. Organizations will be forced to finally understand their software composition in depth, not as a “nice to have,” but to stay legal.
The inevitability of CompOps
“CompOps” (Compliance Operations) sounds like a buzzword nobody wants. Nobody likes compliance work. Also, it’s boring. But that is exactly why it will succeed.
As requirements mount, the only practical way to meet them is by applying DevOps principles to compliance. CompOps emerges as a survival mechanism. It is compliance that “just happens” through automation rather than a manual checklist. Most teams will start doing this by accident as compliance requirements get baked into the existing DevOps process.
We need to stop treating compliance as an annual audit event. It must be a continuous stream of evidence generated by the pipeline itself.
We need to watch how major foundations like the Python Software Foundation (PSF), Apache, and Eclipse handle this pressure. They are facing the dual challenge of massive growth and new compliance requirements like the CRA demands on open source stewards.
The human element remains a serious risk. Developer burnout and funding are critical issues. We don’t yet know how far automation can take us in mitigating this, but the limit is being tested. We will be keeping an eye on the Sovereign Tech Agency in 2026.
Building the right boat
For too long, software supply chain security has relied on heroics. We relied on security engineers working late nights to triage thousands of CVEs. We relied on release managers scrambling to generate spreadsheets for auditors.
By 2026, that era must close. The sheer scale of the ecosystem means human heroism is no longer a scalable defense strategy.
We must build a system resilient by design. We need to treat the SBOM as a dynamic layer of observability. This allows teams to instantly query their entire software fleet to answer “where is X installed?”
Anchore helps organizations make this shift. We maintain open source tools like Syft (SBOM generation) and Grype (vulnerability scanning) to provide the data layer. For enterprises, the Anchore platform acts as the CompOps engine. It embeds “Policy-as-Code” directly into the CI/CD pipeline, enforcing rules automatically on every commit. This ensures you have the immediate, granular visibility needed to meet strict 24-hour incident reporting timelines without slowing down developers.
The outlook for 2026 isn’t about panic. It’s a “keep calm and carry on” moment. The flood waters are rising, but we are finally building the right boat.
Learn the 5 best practices for container security and how SBOMs play a pivotal role in securing your software supply chain.
Just as the shift from monolithic architectures to microservices fundamentally transformed infrastructure management in the 2010s…bringing agility alongside massive operational complexity…we are witnessing a similar structural shift in software transparency. The definition of “software” itself has expanded. It is no longer just lines of deterministic code; it is now an interconnected web of data, models, hardware, and services.
History is repeating itself, but with higher stakes. The same pattern of opacity that plagued open source adoption two decades ago is now playing out with AI and critical infrastructure. How are we dealing with this repetition of history? We are extending an already well-known standard; SBOMs.
In a recent deep-dive conversation, Kate Stewart, VP of Dependable Embedded Systems at The Linux Foundation and founder of SPDX, laid out the roadmap for SPDX 3.0. Her insights reveal that we are moving from simple file tracking to comprehensive system analysis.
Here is how the landscape is changing and why the “S” in SBOM is evolving from “Software” to “System.”
Learn about SBOMs, how they came to be and how they are used to enable valuable use-cases for modern software.
To understand where we are going, we must map the trajectory of supply chain visibility.
The OSS License Era (2010s) was characterized by license risk. Organizations needed to know if they were accidentally shipping GPL code. Manual tracking was feasible because dependency trees were relatively shallow.
The CVE Era (2018-2023) brought a security-first focus. Incidents like Log4j exposed the depth of transitive dependencies. The SBOM became a security artifact. But it was still largely static; a snapshot of a moment in time.
The AI Era (Present) has emerged as LLMs and embedded systems explode in complexity. We are no longer just tracking libraries. We are tracking: training data, hardware configurations, and model weights.
This evolution brings us to the core challenges Kate Stewart highlighted.
Data is now code
AI systems are fundamentally different from traditional software components. Where conventional code follows logic paths written by humans, AI models operate on patterns learned from data. This creates a visibility crisis: if you do not know the data, you do not know the risk.
Kate Stewart framed this relationship with a perfect analogy that defines the new requirement for AI transparency:
“If you don’t have the transparency into the data sets used to train the models, you can’t build trust in the models. Source code is to build artifacts as data sets are to AI models. The data sets are really what’s biasing the behavior.”
We can no longer treat an AI model as a black box. To trust the output, we must have visibility into the input. SPDX 3.0 addresses this by introducing specific profiles for AI models and pre-training data sets, allowing organizations to track the lineage of a model just as they would track a Git commit.
Risk as the north star
Despite the complexity of AI and systems, the core principle of supply chain security remains unchanged. It is a concept that Kate Stewart has championed since the early days of SPDX, when legal teams first demanded cryptographic hashes to ensure integrity.
“Transparency is the path to minimizing risk.”
It sounds simple, but at scale, it is a complex orchestration problem. Whether it is a satellite operating system running Zephyr or a cloud-native financial application, you cannot mitigate what you cannot see. The industry is moving toward a model where transparency is not just a “nice to have” for open source compliance. Instead it is a baseline requirement for operations.
Evidence instead of remediation
One of the most expensive activities in cybersecurity is chasing false positives. Traditional vulnerability scanners operate on the potential risk of an exploit. If a package version is bad, it is vulnerable. But in complex systems, the presence of a package does not equal exploitation.
Kate Stewart noted that high-fidelity SBOMs allow for a fundamentally different approach to vulnerability management:
“If we can be authoritative by saying, ‘no, that file with the vulnerability is not in my image.’ Then you don’t have to remediate and you can prove it. Instead, you can create a VEX and say, ‘okay, I’m asserting this and I can attribute it to….’ Knowing if you are truly exposed is critical in this space, right?”
This is the shift from reactive firefighting to strategic analysis. By using VEX (Vulnerability Exploitability eXchange) documents alongside high-fidelity SBOMs, organizations can prove they are not affected. In sectors like automotive or medical devices, where patching requires expensive recertification, this prevents unnecessary suspension of sales or recalls.
The Economic Power of Regulation
What started as voluntary cybersecurity best practices is rapidly hardening into market-access requirements. The EU Cyber Resilience Act (CRA) is forcing manufacturers to take security hygiene seriously:
“The penalties for manufacturers are pretty steep [for the EU CRA]. They’re taking it pretty seriously over there. I think transparency is going to improve the practices, right? And people don’t do things unless they have to. It becomes an economic concern at this point and they want to save money, right?”
Regulation is acting as the forcing function for transparency. It is shifting the conversation from “technical debt” to “revenue risk.”
Where do we go from here?
The move to System BOMs and SPDX 3.0 is inevitable, but it does not happen overnight. Organizations can follow a phased approach to get ahead of the curve.
Crawl: Establish the Baseline
Ensure you are generating standard SBOMs for all build artifacts. Use established tools like Syft to capture the “ingredients list” of your containers and filesystems. This builds the foundational muscle memory for transparency.
Walk: Add Context and VEX
Begin filtering the noise. Implement VEX to flag vulnerabilities that are not exploitable in your specific configuration. This reduces the burden on developer teams and shifts the focus to real risk.
Run: Adopt System Profiles
As tooling matures, begin mapping the broader system. Link your software SBOMs to the data sets used in your AI models and the hardware profiles of your deployment targets. This creates the “knowledge graph” that Kate Stewart envisions.
The window of opportunity to build these processes voluntarily is closing. As regulations like the CRA come online, system-level transparency will become the price of admission for global markets.
Learn about SBOMs, how they came to be and how they are used to enable valuable use-cases for modern software.
A lot has happened over the last few months for Anchore Open-Source – as a small OSS engineering team, we’re proud of the work we’ve done in the creation and ongoing evolution of the Anchore OSS tools, but are equally honored and thankful to work in concert with our vibrant community of users and contributors of all kinds.
This week, the primary Anchore OSS projects (Syft, Grype and Grant) have tipped past the 50 Million Downloads mark, which we feel is a milestone well worth sharing and celebrating with all of you – after all, you’re the ones who, through your discussions, bug reports, feature requests, code contributions, community meetings and use of the tool suite have made this milestone happen – thank you, and congratulations!!
Quick tour of recent activity
Anchore OSS projects continue to grow across the board – here are some fun rollups derived from public github project stats, as of January 2026:
Project
Stars
Contributors
Community Reach
Syft
8.3k+ +6.4%
217 +4.8%
Powering SBOM generation for 450+ dependent projects with many enterprises amongst them.
Grype
11.4k+ +5.6%
134 +3.1%
Proving the principle of ‘get the data (SBOM), use the data (vuln scan)’: used by 160+ major public repos.
Grant
133 +18.7%
12 +9.1%
A specialized, burgeoning tool for license policy and compliance.
Here is a look back at just a few of the recent technical themes where a lot of improvements and new functionality has been delivered over just the past couple of months:
Syft/Grype/Vunnel– extended the breadth of software coverage for SBOM generation vulnerability scanning, and license detection through the addition of new software ecosystems, hardened container image projects, new binary catalogers, and new Linux distributions
Grant – can now ingest even richer license data from the SBOM layer for more accurate license compliance and policy checking capabilities
Syft– added support for cataloging an entirely new type of material – LLM models in GGUF format, to surface AI/ML elements in the form of an (S/AI)BOM
Thank you again all around – working together with all of you to hit 50 million downloads in just a few short years has been an incredible journey, and there is a lot more we have planned! At a time where the sheer pace of software being produced, and thus the surface area of the global software is exploding in magnitude, having the tech that gives you the ability to take a deep look at what your projects depend on – contextualize, check, validate, analyze – will continue to move from ‘best practice superpower’ to a ‘fundamental need’ in concert.
We love contributions – start topical discussions, report issues / bugs, contribute new features and bug fixes – come join us over on our newly launched docs site where you’ll find up-to-date links to the all of Anchore’s OSS project github pages, our community discourse, and guides for using and contributing to Anchore OSS!
In the modern theater of digital warfare, the Department of War (DoW) is transitioning to a Zero Trust Architecture (ZTA). At the heart of this transition lies a fundamental principle: “Never Trust, Always Verify.”
For software applications, this means verifying every single component, library, and dependency before it ever touches a mission-critical network. Anchore Enterprise serves as a cornerstone for this verification, providing the deep visibility and continuous monitoring required to satisfy DoW Zero Trust mandates.
Setting the Stage: Zero Trust References
To understand how Anchore fits into the mission, it is important to first understand the context of Zero Trust within the DoW. Here is a breakdown of the critical documents and frameworks:
The Foundation (NIST 800-207): Defines the “Logic.” These are the underlying definitions that the Strategy and Reference Architecture are built upon.
The Vision (DoW ZT Strategy): Defines the “Why” and “When.” This sets the timeline and establishes the 7 Pillars of Zero Trust.
The Blueprint (DoW ZT Ref Arch): Defines the “How.” This outlines the technical capabilities organizations must build and defines the 5 Tenets of Zero Trust.
The Measuring Stick (CISA Maturity Model): The “Progress Tracker” used to measure how far along the path you are.
The 7 Pillars of Zero Trust: What We Protect
Anchore Enterprise plays a critical role in securing the pillars that support the DoW’s Zero Trust strategy. While traditional security focuses heavily on the perimeter, Anchore secures the workload itself.
User and Device Integrity
The first line of defense is ensuring that only authorized users and secure devices access the network. Anchore integrates with LDAP and Single Sign-On services (like Okta and Entra ID) to enforce strict identity management. For devices, we go a step further by generating Software Bills of Materials (SBOMs) to evaluate the security posture of the systems themselves. Using CI/CD techniques, virtual machines can have their SBOMs validated using policy-as-code to ensure they meet DoW requirements before they ever reach production.
Applications, Workloads, and Data
Securing the software layer (i.e., containers, virtual machines, and source code) is Anchore’s specialty. We generate SBOMs for containers, filesystems, and source code, applying strict policy checks to ensure compliance. By utilizing a Kubernetes Admission Controller, Anchore can stop non-compliant container deployments in their tracks. Furthermore, we leverage strict Role-Based Access Control (RBAC) to ensure least privilege for data, verifying that containers are built correctly with the right encryption and access parameters every time.
Network, Automation, and Visibility
To prevent lateral movement, Anchore ensures containers are configured with least privilege, exposing only necessary services. We automate this protection via policy packs that check for exposed secrets, malware, and misconfigurations at scale. Finally, we provide deep visibility into container registries and production workloads, logging data to your SIEM to allow for querying across the entire landscape.
Quick Reference: The 7 Pillars
Pillar
Focus
Anchore Capability
User
Continuous authentication
SSO Integration (LDAP, Okta, Entra ID)
Device
Device health & compliance
SBOM generation for system posture validation
Applications
Securing code & containers
SBOMs, Policy checks, K8s Admission Control
Data
Encryption & Labeling
RBAC, Least Privilege enforcement, Integrity checks
Network
Segmentation
Least privilege configuration checks
Automation
Scalable response
Automated Policy Packs (Secrets, Malware, CVEs)
Visibility
Analytics & Logging
Runtime Inventory & SIEM integration
The Five Tenets of Zero Trust: How We Protect
The DoW defines five foundational tenets that influence every aspect of Zero Trust. Anchore Enterprise turns these abstract tenets into operational realities.
Operating in a Hostile Environment
We must assume that the environment is hostile and that all users, devices, and applications are untrusted, regardless of their location. Anchore adopts this mindset by assuming that any software component…even those from “trusted” vendors…could be a vector for attack. We treat source code, containers, and VM images as untrusted until they are explicitly verified against security policies.
Presume Breach and Verify Constantly
Operating with the assumption that an adversary is already present requires constant vigilance. Anchore performs continuous re-scanning not just in registries, but also in Kubernetes using runtime inventory. If a new vulnerability is announced today, Anchore identifies exactly where that threat exists in your currently running environment immediately. We deny access by default, preventing the “trust” of a container image simply because it exists in a registry.
Scrutiny and Unified Analytics
Trust is not given; it is earned through scrutiny. Anchore analyzes multiple attributes to derive high confidence levels for access. This includes secrets, software licenses, and file-level integrity. We centralize this data to provide unified analytics, delivering a searchable, auditable history of every application or virtual machine that has ever touched the mission network.
Quick Reference: The 5 Tenets
Tenet
Principle
Anchore Approach
Hostile Environment
Treat everything as untrusted
Verify all components (code, containers, VMs) explicitly.
Presume Breach
Adversary is already present
Continuous re-scanning & runtime inventory.
Never Trust/Verify
Deny access by default
Policy-as-code gates in CI/CD pipelines.
Scrutinize Explicitly
Contextual access analysis
Deep analysis of secrets, licenses, and file integrity.
Unified Analytics
Log every transaction
Centralized, searchable SBOM & vulnerability history.
Conclusion: Continuous Verification
Zero Trust is not a “one-and-done” checkbox; it is a state of continuous verification. By aligning with the DoW pillars and tenets, Anchore Enterprise allows the Department of War to move faster, innovate with confidence, and protect the mission.
By checking against the National Vulnerability Database (NVD) and specialized feeds like the GitHub Advisory Database, Anchore ensures that the DoW is defended against both common threats and sophisticated supply chain attacks. Furthermore, by incorporating data from the Known Exploited Vulnerability (KEV) catalog and Exploit Protection Scoring System (EPSS), Anchore helps prioritize risk across the organization effectively.
As the DoW continues to mature its Zero Trust strategy, Anchore Enterprise is here to mature and protect your security posture alongside it.
Ready to get started?
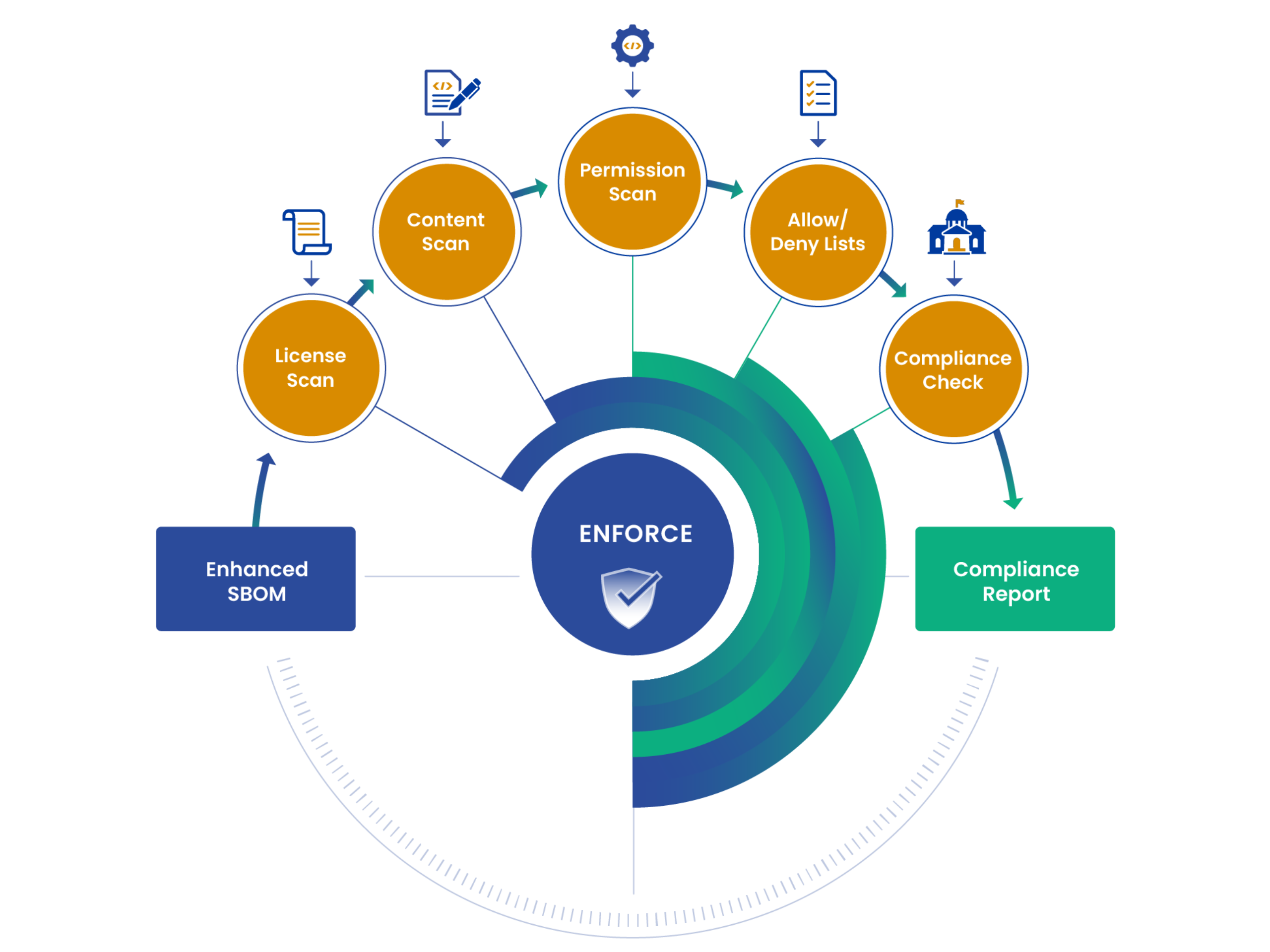
Generate: Leverage Syft to begin generating SBOMs for container images and file systems using our Getting Started guide.
Assess: Use Grype to assess your SBOMs for vulnerabilities and check them against your specific risk tolerance.
Enforce: Deploy Anchore Enterprise to bring it all together. Anchore Enterprise visualizes data, conducts STIG checks, and enforces policy-as-code across your SBOMs, container images, and source code.
For years, cATO (continuous Authorization to Operate) was largely aspirational…or maybe, directionally correct but not practical to implement. The public commitment to operationalization of the Software Fast Track (SWFT), moves the reality of cATO within striking distance. The era of static compliance checklists is over, replaced by continuous, automated security evidence; you’ve been put on notice.
Here are the key insights needed to navigate this transition:
The “Sponsor” Bottleneck: Why you cannot self-register for the Iron Bank and the specific DoD relationship you need to secure first.
The 2-Week vs. 18-Month Gap: How the centralized reciprocity model creates a massive speed-to-market advantage over legacy RMF.
The CMMC Trap: Why securing your enterprise network (CMMC) won’t prevent your software product from being rejected at the door.
The End of PDF Compliance: Why static reports are being rejected in favor of dynamic, machine-readable SBOMs.
The SWFT Initiative Is No Longer an Experiment
The SWFT initiative establishes a centralized reciprocity model for software authorization that is fundamentally different from legacy processes. By validating security compliance once at the enterprise level, the Department eliminates redundant assessments, allowing authorized software to be consumed by any DoD agency immediately.
As noted in the DoD CIO SWFT RFI Combined Summary from December 2025, “The SWFT initiative… will reform the way the Department acquires, tests, and authorizes secure software.”
Implementation Milestone: January 2026
As of January 2026, SWFT has officially transitioned from an experimental “Pilot Program” (which began in May 2025) to an evolving requirement. It is no longer optional. It is the paved road for acquisition. The DoD has signaled that “[SWFT] is shifting from an experimental ‘sprint’ into a permanent, enterprise-wide ecosystem.”
Immediate Liability Under Phase 1 Regulations
Organizations must understand the liability landscape has shifted dramatically between Phase 1 and Phase 2 regulations:
Phase 1 (Effective Nov 10, 2025): Self-attestation is already mandatory. By signing this assessment, executive leadership (CEO) assumes direct legal liability under the False Claims Act. While enforcement is currently reactive, prosecutors will likely target flagrant violations. As of November 10, 2025, all solicitations must meet this requirement.
Iron Bank is Mandatory for Containerized Software Delivery to DoD
The scope of SWFT is specific and significant: it is mandatory for any vendor delivering containerized software (e.g., Kubernetes) to Platform One, Cloud One, or DoD Software Factories.
According to Platform One, “[The] Iron Bank is the DoD Centralized Artifacts Repository (DCAR)…containers accredited in Iron Bank have DoD-wide reciprocity across classifications.”
Contractual Mandates and Operational Impact
Contracts will explicitly require a “Continuous ATO (cATO)” or “Reciprocity-eligible software.” As outlined in the DoD cATO Memo (Feb 2022), cATOs represent “the gold standard for cybersecurity risk management” and do not have an expiration date.
The operational impact of this requirement creates two distinct pathways:
Centralized Pathway (Iron Bank): Use the centralized repository to achieve reciprocity in 2-4 weeks.
Decentralized Pathway (Legacy RMF): Attempting a legacy RMF cATO independently typically takes 12-18 months, creating a high risk of ineligibility for FY26 awards.
The regulatory basis for this shift is NIST SP 800-218 (SSDF). Compliance requires proving your process of writing code is secure from day one, helping “software producers reduce the number of vulnerabilities in released software.”
Transition from Static to Dynamic Artifacts
The DoD now requires machine-readable SBOMs that update with every code change, replacing static PDFs. The SWFT initiative is effectively establishing a “clearinghouse for SBOM data,” demanding dynamic visibility rather than one-off snapshots.
This mirrors the precedent set in February 2025, when the U.S. Army mandated actual data for all new software, rejecting “self-attestations” as insufficient.
Technically, this means organizations must implement automated policy packs to generate compliant SBOMs during the build process. As reinforced by the Secretary of Defense in July 2025, the DoD “will not procure any hardware or software susceptible to adversarial foreign influence.”
SWFT Secures the Product While CMMC Secures the Network Boundary
A common point of confusion is the relationship between CMMC and SWFT. They are fundamentally different compliance domains:
CMMC protects your enterprise environment (network, laptops, email). It ensures contractor information systems can adequately protect CUI.
SWFT protects the software deliverable (The binary/code). It reforms how the DoD acquires, tests, and authorizes secure software.
You need both. A secure enterprise environment (CMMC Level 2) is necessary but insufficient if the software deliverable itself is insecure.
Accessing the Iron Bank Requires a Government Sponsor
Access to this ecosystem is gated. Iron Bank is invitation-only; vendors cannot self-register. A Government Sponsor (DoD employee with a CAC) is required to formally request onboarding.
As the Iron Bank Onboarding Guide states, “The Requestor is responsible for Identifying a DoD Mission Owner/Government Sponsor who has a CAC card.”
Sponsorship Strategy
To navigate this, vendors must engage operational sponsors. Find the operational unit (e.g., Army or Air Force customer) that intends to use the software and request that they act as the sponsor. Iron Bank prioritizes “Mission Need,” and sponsorship by an operational unit validates this need, expediting the process.
Pro Tip: When researching SWFT search for “Platform One” or “Iron Bank” to access the correct documentation. This avoids confusion with DCSA SWFT (background checks) or the international SWIFT banking system.
Conclusion & Next Steps
The transition to SWFT represents a massive opportunity for vendors who move quickly, and a barrier to entry for those who wait. To ensure you are eligible for FY26 contracts, take these three steps immediately:
Secure Your Sponsor: Identify your government sponsor today and have them submit the onboarding request.
Audit Your Artifacts: Implement automated SBOM generation, management, and submission.
Pre-validate Compliance: Scan your software against SSDF policies before submission to ensure it passes on the first try.
The “fast track” is open, but only for those who have their data ready.
Learn how to harden your containers and make them “STIG-Ready” with our definitive guide.
If you’ve been following the Department of Defense’s (DoD) modernization efforts, you have probably noticed a significant shift in how the US Navy approaches deployment. Historically, the path to an Authorization to Operate (ATO) was a grueling marathon that often delayed critical capabilities by months or years. Today, the U.S. Navy is pivoting toward a model that prioritizes speed without sacrificing the rigorous security standards required for mission-critical systems.
At the heart of this transformation is RAISE 2.0. It is a framework designed to automate the Risk Management Framework (RMF) and move away from static, one-time security checks. By leveraging an authorized RAISE Platform of Choice (RPoC), the Navy is essentially rewriting the rules of software delivery.
Visibility: The Foundation of Every Security Check
Before you can secure a system, you must understand its composition. In the microservices-based world we operate in today, software stacks have become increasingly complex. They are no longer single blocks of code but intricate webs of dependencies. The Navy recognizes that you cannot defend a “black box” against modern threats like Log4j or any of the recent supply chain compromises.
As Brian Thomason, Partner and Solutions Engineering Manager at Anchore, puts it: “It’s hard to know what to fix in your software…if you don’t know what’s in your software.” This is why the security process begins with a high-fidelity Software Bill of Materials. An SBOM is a comprehensive ingredients list for your application.
How can we expect to manage risk if we are blind to the very components we are deploying?
Stop Waiting for ATOs: The Power of Inheritance
The traditional ATO process required every new application to justify its entire existence from the hardware up. This created a massive bottleneck where security teams were constantly re-evaluating the same underlying infrastructure and DevSecOps tools. RAISE 2.0 solves this by introducing the concept of a RAISE Platform of Choice (RPoC) (i.e., the Navy’s version of the more general DoD DevSecOps Platform or DSOP) with a pre-existing ATO.
“Raise 2.0 automates the RMF…eliminating the need for a new ATO; instead you inherit the ATO of the RPoC.” This mechanism allows application teams to focus solely on the security of their specific code rather than the platform it runs on. Why waste months certifying a pipeline that has already been vetted and hardened by experts? By inheriting a certified platform’s posture, developers can move from “code complete” to “production ready” in days rather than years.
The Accidental Leak: Moving Beyond Simple CVEs
Security isn’t just about identifying known vulnerabilities in 3rd-party libraries; it’s also about catching the human errors that occur during the heat of a sprint. While we like to think our internal processes are foolproof, history shows that sensitive credentials (think: AWS or SSH keys) find their way into repositories with surprising frequency.
Anchore’s platform doesn’t just look for CVEs; it scans for these “silent” risks. Brian notes: “We also detect leaked secrets… not that anybody in your organization would do this… but companies have been known to…” This capability acts as a critical safety net for developers working in high-pressure environments. What happens to your security posture if a single accidental commit exposes the keys to your entire cloud environment?
Security for Tomorrow: Managing the Zero-Day Disclosures
The moment an application is deployed, its security posture begins to decay. New zero-day disclosures and changing requirements mean that a “clean” scan from yesterday may be irrelevant by tomorrow morning. Static security checks are insufficient for modern warfare. We need continuous intelligence that tracks code throughout its entire lifecycle.
“Future changes; new requirements, zero-day disclosures, etc. are covered by Anchore’s SBOM-based approach.” By maintaining a version-controlled SBOM in a tool like Anchore Enterprise, the Navy can rescan deployed code against new threat intelligence every 12 hours. This provides a continuous feedback loop: if a new vulnerability is discovered in a library you deployed six months ago, you are notified immediately. Is your current process capable of identifying risks in software that is already deployed in production?
The Path Forward: Two Steps and One Habit
Implementing RAISE 2.0 principles isn’t an overnight task, but it is the only viable path for modernizing federal software delivery.
Step 1: Standardize on SBOM generation. Integrate high-fidelity SBOM creation into your build process immediately to establish a baseline of truth.
Step 2: Map your RMF controls to automation. Identify which parts of your compliance checklist can be handled by a platform like Black Pearl and/or Anchore.
The Habit: Continuous Rescanning. Make it a daily practice to check your production inventory against the latest vulnerability data (KEV/EPSS), rather than waiting for your next scheduled audit.
The goal isn’t just to achieve an ATO today; it’s to build a system that remains secure and compliant through whatever challenges tomorrow brings.
At its core, any security tool is only as good as the data it uses. This is the age-old principle of “garbage in, garbage out.” If your security tooling is working with stale, incomplete, or inaccurate information, it will produce unreliable results. This leaves you with a false sense of security.
To protect your software supply chain and wrestle the ever increasing wave of CVEs effectively, you need a constant stream of high-quality, up-to-date and a matched set of vulnerability data to your software and SBOM. This is especially critical for reacting to zero-day vulnerabilities, where every second counts.
This post will take you “under the hood” to show you how Anchore Enterprise’s hosted data service. Put another way, a stream of vulnerability feeds are engineered to deliver the timely, accurate and enriched data needed to remediate vulnerabilities fast.
A lot has been changing in Anchore to provide better results with more data at your fingertips. From the introduction of KEV and EPSS datasets to the addition of secondary CVSS scores in Anchore Enterprise 5.20 and matched CPEs in 5.24. We also touch on the future of how this data can be further extended with the introduction and support of VEX (Vulnerability Exploitability eXchange) and VDR (Vulnerability Disclosure Report).
Let’s get started!
Introducing the Anchore Data Service
The landscape of software vulnerabilities is never static. New threats emerge daily, data sources are constantly updated, and upstream feeds can suffer from API changes, data inconsistencies, or inaccuracies.
Managing this high-velocity, often-chaotic stream of information is a full-time job. This is where the Anchore Data Service as a delivery vehicle comes in. The service shoulders the heavy lifting by continuously ingesting, analyzing, and correlating vulnerability data from the latest intelligence from sources like Red Hat, Canonical, GitHub, NVD, CISA KEV, EPSS and much more.
Our security team additionally publishes ‘patches’ for this data, correcting upstream errors, suppressing known false positives, and enriching records to ensure maximum accuracy. The end result is a curated, high-fidelity set of intelligence feeds that are available to your Anchore Enterprise deployment. Whether in the cloud, on-premises, or even fully air-gapped, Anchore Data Service gives you a single, trustworthy source of truth for all your vulnerability scanning.
We document the curated workflow in detail over on our vulnerability management docs pages, for this article we will unpack how this data is first made available and later how it can be utilized.
How does the Anchore Data Service work?
Anchore Data Service is designed for both robustness and flexibility. As well as catering to both internet-connected or fully air-gapped environments. The magic happens through a dedicated internal service which acts as the central hub for vulnerability data that you can download data from.
In an internet-connected deployment, your Anchore Enterprise deployment pulls data directly from Anchore Data Service, hosted at https://data.anchore-enterprise.com. You only need to allow outbound HTTPS traffic (TCP port 443) from your Anchore instance. The deployments data syncer service periodically reaches out to this endpoint and checks for new feed data. If it finds an update, it downloads and distributes it across your deployment.
For air-gapped deployments with no internet connectivity, Anchore provides a simple, secure mechanism for updating vulnerability data. Using the command-line tool, anchorectl, on a low side/internet connected machine you can use the tool to download the entire vulnerability data feed as a single bundle. Then simply transfer, or sneaker copy, this bundle into your air-gapped network. Using a local copy of anchorectl in your high side environment you will upload the feed data. This gives you full control over the data flow while maintaining a strict air gap.
The data lifecycle: From publication to matching
A question we often hear is, ‘When a newly discovered vulnerability is published, how does it and how long does it take to go from security advisory all the way to a finding in an image in your deployment?’ As with most questions in IT the answer is it depends…but the aim now is to go under the hood and look at the nuance as to how this works.
Let’s run through the steps so you can see how this works end to end.
Step 1: Anchore pulls upstream data from vendors and other sources, compiles and then publishes data to the hosted data syncer service. This happens every 6 hours. Our OSS tooling only published data every 24 hours.
Step 2: The data syncer service in an Anchore Enterprise deployment runs everyhour and checks the hosted Anchore Data Service for new vulnerability data.
Step 3: Once downloaded the data syncer service communicates with the Anchore Policy Engine and other internal components to update internal databases. This makes the new dataset, or set of feeds, available within your deployment.
With new data available to an Anchore Enterprise deployment, there are a few mechanics to understand how this new data will be utilized. For ad-hoc requests (web ui/api) for vulnerabilities on an artifact, the system returns the latest results. For example, if the SBOM shows log4j-core-2.14.0.jar, the policy engine searches the latest vulnerability data for any entries where log4j-core is the affected package and 2.14.0 falls within a vulnerable version range. When a match is found, a vulnerability is reported.
The importance of having a high quality SBOM cannot be underrated. If your SBOM is older it can be worth rescanning with the latest version of anchorectl/Syft to get improved SBOM quality and therefore results.
You need not re-scan an image as the SBOM stored acts as the reference point for mapping vulnerabilities. The reporting system by default will re-build the latest vulnerability data on a cycle timer ( anchoreConfig.reports_worker.cycle_timers.reports_image_load). The default is set to update every 600 seconds. This is configurable if you require fresher reports.
Finally, if you have a subscription watch for vulnerability data you can get notified of any changes to the vulnerability data. For example, if a user is subscribed to the library/nginx:latest tag and on the 12th of September 2025 a new vulnerability was added to the Debian 9 vulnerability feed which matched a package in the library/nginx:latest image, this would trigger a notification.
Notifications can be configured to hit a webhook, slack, email and/or other endpoints. This subscription will be checked on a cycle of every four hours but is also configurable (anchoreConfig.catalog.cycle_timers.vulnerability_scan).
Note: the subscription is disabled by default. There are other similar subscriptions for policy and tags that might also play a role here. For example, if you want to notify on changes to policy results about a CVE (e.g., a CVE changes from unknown to critical).
The data lifecycle: Trust but verify…the feeds
As you can see at this point, the Anchore Data Service is critical to your deployment’s continued operation and due to this and the ever changing nature of upstream data, we provide the Anchore Data Service status page. This page offers real-time operational health of all our backend services, including the critical vulnerability data feeds, package information, and security advisories that your Anchore Enterprise instance relies on.
If you ever suspect an issue with data synchronization or feed updates, this status page should be your first troubleshooting step. It allows you to immediately verify if Anchore is experiencing an outage or performing maintenance, saving your team valuable time in diagnosing whether an issue is local to your environment or an external upstream problem.
You can also easily verify the status of your vulnerability feeds in your own deployment using the anchorectl:
# See a list of all feeds and their last sync time$ anchorectl system feeds list
This command will show you each feed group (e.g., vulnerabilities, clamAV, nvdv2, ubuntu, etc.), the number of records, and when it was last updated. You can also login to the Anchore Enterprise Web UI with admin permissions and head to the System -> Health Page to see the feeds list and timestamps and other details like record count too.
When you see recent timestamps, you know the data is flowing correctly. Importantly each feed has its own timestamp representing the last time the service pulled data from the upstream source. If there has been no new data published upstream, this timestamp won’t be updated. The policy engine and relevant policy packs have a rule set defined to show a policy failure if upstream data is missing or not recently. The FedRAMP policy bundle will flag any instances where an evaluation is using data older than 48 hours old.
What’s in the data and why it matters
The Anchore Data Service distributes a few different types of datasets that can aid prioritizing in your remediation workflow.
For Malware checks, Anchore Enterprise utilizes ClamAV, which is disabled by default but can be enabled for all centralized image scans. This data is constantly updated and pulled from upstream ClamAv. Checks on your container image filesystem happen at scan time. This offers extra insight into your container images beyond pure vulnerabilities and as such we won’t dig much further into this here but certainly a strong signal to utilize when determining if your software is safe for production.
Another useful dataset is the Known Exploited Vulnerability (KEV), a dataset produced by CISA. It is a list of known exploited vulnerabilities; meaning if a CVE is actively being exploited in the wild, it will be on this list.
Finally there is the Exploit Prediction Scoring System (EPSS) dataset where you retrieve a score and a percentile rankings. These are based on modelled data and point to the chance of a CVE being exploited in the next 30 days.
Anchore Data Service maintains numerous vulnerability feeds upstream sources. Each entry includes some useful metadata and context, such as:
Vulnerability Identifiers: CVE or other unique ID (e.g., GHSA ) as well as external data source URLs useful to act as guidance and/orreference.
Severity Score: The CVSS 2 or 3 score and vectors, helping you prioritize what to fix first. We can also present secondary scores if needed too.
Affected Type: The type of software/ecosystem the software resides in.
Affected Package: The name of the software package or library.
Affected Versions: The specific version or version range that is vulnerable.
Fix Information: The version in which a fix is available.
CPE, CPE23 and PURL: CPE, CPE 2.3 and PURL are the primary ways to “name” a piece of software so Anchore can find and match to known vulnerabilities. Both are used and each have strengths and weaknesses, but PURL can help get the most accurate matching.
Package path: Where is this package located? Don’t forget you might have multiple instances of the same software
Feed/feed group: Which upstream data feed was used to match this CVE data.
Utilizing this information can help matching as well as remediation. It’s the difference between results that just tell you “your container has Log4j” and one that tells you “your container is using log4j-core version 2.15, which is vulnerable to CVE-2021-45046 (GHSA-7rjr-3q55-vv33) with a critical severity 9, and a fix is available in version 2.16 and this fix has been available for 4 years“.
Beyond what is included in the OSS Grype vulnerability feeds, Anchore Enterprise offers additional feeds like Microsoft MSRC vulnerability data and exclusions.
But wait there is more:
Severity Score – Secondary CVSS: Anchore can now be configured to show the highest secondary CVSS score if the Primary NVD score has not been provided for a CVE. This becomes useful as some data might have two CNA’s upstream sources associated with the same package/vulnerability.
Matched CPEs: This field contains a list of CPEs that were matched for the vulnerable package. It provides more context around how the vulnerability was identified. This extra data might help you understand the match Anchore used and identify any false positives.
During the scan, various attributes will be used from the SBOM package artifacts to match to the relevant vulnerability data. Depending on the ecosystem, the most important of these package attributes tend to be Package URL (purl) and/or Common Platform Enumeration (CPE).
The Anchore analyzer attempts to generate a best effort guess of the CPE candidates for a given package as well as the purl based on the metadata that is available at the time of analysis. For example, for Java packages, the manifest contains multiple different version specifications but sometimes stores erroneous version data.
Luckily there are some processes to help facilitate better matching and get you the most accurate results:
Enrichment: Due to the known issues with the NVD, Anchore Enterprise enhances the quality of its data for analysis by enriching the information obtained from the NVD. This process involves human intervention to review and correct the data. Once this manual process is completed, the cleaned and refined data is stored in the Anchore Enrichment Database.
Vulnerability Match Exclusions. These exclusions allow us to remove a vulnerability from the findings for a specific set of match criteria.
Correction & Hints: Anchore Enterprise provides the capability for you to adapt the SBOM and its contained packages but also provide a correction that will update a given package’s metadata so that attributes (including CPEs and Package URLs) can be corrected at the time that Anchore performs a vulnerability scan.
Vendor Data First: We surface both NVD and vendor data, but recommend and by default, surface vendor-specific data first. They understand how a package of software has been compiled and installed and therefore the impact of a known vulnerability the best. They also have awareness of accurate fix information too.
One of the most impactful features, recently released within the Anchore Enterprise ecosystem is the support for open standards VEX (Vulnerability Exploitability eXchange) and VDR (Vulnerability Disclosure Report). While these deserve a deep dive of their own, their core value is simple: they allow you to apply vulnerability annotations, like “this CVE is not applicable or code path not executed” or “investigating” directly to your SBOMs.
Not only this but you can soon also leverage VEX documents provided by upstream vendors like Red Hat if you used UBI9 base images that contained CVEs. Meaning you can eliminate noise and save significant manual triage time with confidence. Because Anchore Enterprise supports image ancestry and inheritance detection, these time savings multiply across every image in your environment. Furthermore, you can share these annotations with customers and auditors, streamlining their adoption and compliance process.
For some, simply being able to leverage a mix of data available like CVSS 2/3 or extract the PURL for downstream use cases is a must. Like matching and publishing discovered vulnerability matches and their data points into other systems like SIEM. In a larger enterprise, this helps to connect data systems, facilitate organizational automation and drive consistency across results from disparate systems.
A common example is that some compliance scenarios require NVD data specific results and whilst we lean on vendor data first, surfacing NVD results is absolutely available. Anchore Enterprise makes this simple and easy with 100% API coverage as well as a powerful notifications system providing rich exposure to the underlying data.
Summary
In vulnerability management, the “garbage in, garbage out” must be avoided as any tooling showing incomplete, outdated, or inaccurate data leads to false positives, missed threats, and wasted effort. In addition to this, having the ability to utilize additional data signals from other data sources like EPSS and KEV can truly assist your remediation and prioritization efforts in the face of the never ending wave of vulnerabilities.
This is why Anchore invests heavily in our vulnerability data feed. We do the relentless, complex work of ingesting, correlating, and curating data so you don’t have to. The result is a reliable, timely, and high-fidelity intelligence feed engineered to power your security operations, no matter your environment. By letting Anchore manage the data chaos, you gain confidence that your entire security posture is based on the latest intelligence. This allows your team to stop chasing data and focus on what matters: finding and fixing vulnerabilities.
If you have ever tried to manually apply a Security Technical Implementation Guide (STIG) to a modern containerized environment, you know it feels like trying to fit a square peg into a round hole…while the hole is moving at 60 miles per hour.
The Department of Defense’s move to DevSecOps (and adoption of the DoD Software Factory paradigm) has forced a collision between rigid compliance standards and the fluid reality of cloud-native infrastructure. The old way of “scan, patch, report” simply doesn’t scale when you are deploying thousands of containers a day.
We recently sat down with Aaron Lipult, Chief Architect at MITRE to discuss the MITRE Security Automation Framework (SAF) to discuss how they are solving this friction. The conversation moved past the basics of “what is a STIG?” and into the architectural philosophy of how we can actually automate compliance without breaking the mission.
Here are four key takeaways on why the future of government compliance is open, active, and strictly standardized.
Collaboration over monetization
In an industry often dominated by proprietary “black box” security tools, MITRE SAF stands out by being radically open. The framework wasn’t designed to lock users into a vendor ecosystem; it was designed to solve a national security problem.
The philosophy is simple: security validation code should be as accessible as the application code it protects.
“MITRE SAF came from public funds, it should go back into the public domain. In my opinion, it was built to solve a problem for everybody—not just us.”
This approach fundamentally changes the dynamic between government agencies and software vendors. Instead of every agency reinventing the wheel, the community converged on a shared standard. When one team solves a compliance check for Red Hat Enterprise Linux 8, that solution goes back into the public domain for every other agency to use. It shifts compliance from a competitive differentiator to a collaborative baseline.
“Immutable” container myth
There is a prevalent theory in DevSecOps that containers are immutable artifacts. In a perfect world, you build an image, scan it, deploy it, and never touch it again. If you need to change something, you rebuild the image.
The reality of operations is much messier. Drift happens. Emergency patches happen. Humans happen.
“Ops will still login and mess with ‘immutable’ production containers. I really like the ability to scan running containers.”
If your compliance strategy relies solely on scanning images in the registry, you are missing half the picture. A registry scan tells you what you intended to deploy. A runtime scan tells you what is actually happening.
MITRE SAF accounts for this by enabling validation across the lifecycle. It acknowledges the operational headache that rigid immutability purism ignores: sometimes you need to know if a production container has drifted from its baseline, regardless of what the “gold image” says.
Real system interrogation vs static analysis
For years, the standard for compliance scanning has been SCAP (Security Content Automation Protocol). While valuable, legacy tools often rely on static analysis. They check file versions or registry keys without understanding the running context.
Modern infrastructure requires more than just checking if a package is installed. You need to know how it is configured, what process it is running under, and how it interacts with the system.
“Older tools like SCAP do static file system analysis. It doesn’t actually do real system interrogation. That’s what we’re changing here. If we didn’t, we would deploy insecure systems into production.”
This is the shift from “checking a box” to “verifying a state.” Real system interrogation means asking the live system questions. Is the port actually open? Is the configuration file active, or is it being overridden by an environment variable?
By moving to “real interrogation,” we stop deploying systems that are technically compliant on paper but insecure in practice.
The discipline of compliance automation
One of the most frustrating aspects of STIG compliance is the rigidity of the source material. Engineers often look at a STIG requirement and think, “I know a better way to secure this.”
But in the world of DoD authorization (ATO), creativity can be a liability. The goal of automation isn’t just security; it’s auditability.
“We write the SAF rules to follow the STIG profile ‘as written’, even if we know it could be done ‘better.’ You are being held accountable to the profile, not what is ‘best’.”
This is the hard truth of compliance automation. MITRE SAF creates a direct, defensible mapping between the written requirement and the automated check. If the STIG says “Check parameter X,” the automation must check parameter X, even if checking parameter Y would be more efficient.
This discipline ensures that when an auditor reviews your automated results, there is zero ambiguity. You aren’t being graded on your creativity; you are being graded on your adherence to the profile. By keeping the tooling “true to the document,” MITRE SAF streamlines the most painful part of the ATO process: proving that you did exactly what you said you would do.
The Path Forward
The transition to automated compliance isn’t just about buying a new tool; it’s about adopting a new mindset. It requires moving from static files to active interrogation, from proprietary silos to open collaboration, and from “creative” security to disciplined adherence.
MITRE SAF provides the framework to make this transition possible. By standardizing how we plan, harden, and validate our systems, we can finally stop fighting the compliance paperwork and start focusing on the mission.
Ready to see it in action? Watch our full webinar with the MITRE team.
Learn how to use the MITRE corporation’s SAF framework to automation compliance audits. Never fill out another compliance spreadsheet.
As 2025 draws to a close, we are looking back at the posts that defined the year in software supply chain security. If 2024 was the year the industry learned what an SBOM was, 2025 was the year we figured out how to use them effectively and why they are critical for the regulatory landscape ahead.
The Anchore content team spent the last twelve months delivering expert guides, engineering deep dives, and strategic advice to help you navigate everything from the EU Cyber Resilience Act to the complexities of Python dependencies.
This top ten list reflects a maturing industry where the focus has shifted from basic awareness to actionable implementation. Hot topics this year included:
Mastering SBOM generation for complex ecosystems like JavaScript and Python
Preparing for major regulations like the EU CRA and DoD STIGs
Reducing noise in vulnerability scanning (see ya later, false positives!)
Engineering wins that make SBOM scanning faster and vulnerability databases smaller
So, grab your popcorn and settle in; it’s time to count down the most popular Anchore blog posts of 2025!
The Top Ten List
10 | Add SBOM Generation to Your GitHub Project with Syft
Kicking us off at number 10 is a blog dedicated to making security automation painless. We know that if security isn’t easy, it often doesn’t happen.
Add SBOM Generation to Your GitHub Project with Syft is a practical guide on integrating sbom-action directly into your GitHub workflows. It details how to set up a “fire and forget” system where SBOMs are automatically generated on every push or release.
This post is all about removing friction. By automating the visibility of your software components, you take the first step toward a transparent software supply chain without adding manual overhead to your developers’ plates.
Coming in at number nine is a celebration of speed and accuracy. Two things every DevSecOps team craves.
Syft 1.20: Faster Scans, Smarter License Detection made waves this year by announcing a massive performance boost; 50x faster scans on Windows! But speed wasn’t the only headline. This release also introduced improved Bitnami support and smarter handling of unknown software licenses.
It’s a look at how we are continuously refining the open source tools that power your supply chain security. The improvements ensure that as your projects grow larger, your scans don’t get slower.
8 | False Positives and False Negatives in Vulnerability Scanning
Landing at number eight is a piece tackling the industry’s “Boy Who Cried Wolf” problem: noise.
False Positives and False Negatives in Vulnerability Scanning explores why scanners sometimes get it wrong and what we are doing about it. It details Anchore’s evolution in detection logic. Spoiler alert: we moved away from simple CPE matching toward more precise GHSA data. This was done to build trust in your scan results.
Reducing false positives isn’t just about convenience; it’s about combating alert fatigue so your security team can stop chasing ghosts and focus on the real threats that matter.
7 | Generating SBOMs for JavaScript Projects
Sliding in at lucky number seven, we have a guide for taming the chaos of node_modules.
Generating SBOMs for JavaScript Projects addresses one of the most notoriously complex ecosystems in development. JavaScript dependencies can be a labyrinth of nested packages but this guide provides a clear path for developers to map them accurately using Syft.
We cover both package.json manifests and deeply nested, transitive dependencies. This is essential for frontend, backend and full stack devs looking to secure their modern web applications against supply chain attacks.
6 | Generating Python SBOMs: Using pipdeptree and Syft
At number six, we turn our attention to the data scientists and backend engineers working in Python.
Generating Python SBOMs: Using pipdeptree and Syft offers a technical comparison between standard tools like pipdeptree and Syft’s universal approach. Python environments can be tricky, but this post highlights why Syft’s ability to capture extensive metadata offers a more comprehensive view of risks.
If you want better visibility into transitive dependencies (the libraries of your libraries) this post explains exactly how to get it.
5 | Grype DB Schema Evolution: From v5 to v6
Breaking into the top five, we have an engineering deep dive for those who love to see what happens under the hood.
Grype DB Schema Evolution: From v5 to v6 details the redesign of the Grype vulnerability database. While database schemas might not sound like the flashiest topic, the results speak for themselves: moving to Schema v6 reduced download sizes by roughly 69% and significantly sped up updates.
This is a critical improvement for users in air-gapped environments or those running high-volume CI/CD pipelines where every second and megabyte counts.
4 | Strengthening Software Security: The Anchore and Chainguard Partnership
At number four, we highlight a power move in the industry: two leaders joining forces for a unified goal.
The key takeaway? Reducing your attack surface starts with a secure base image but maintaining that secure initial state requires continuous monitoring.
3 | EU CRA SBOM Requirements: Overview & Compliance Tips
Taking the bronze medal at number three is a wake-up call regarding the “Compliance Cascade.”
EU CRA SBOM Requirements: Overview & Compliance Tips breaks down the EU Cyber Resilience Act (CRA), a regulation that is reshaping the global software market. We covered the timeline, the mandatory SBOM requirements coming in 2027, and why compliance is now a competitive differentiator.
If you sell software in Europe (or sell to a business that sells software in Europe) this post was your signal to start preparing your evidence now. Waiting until the last minute is not a strategy!
2 | DISA STIG Compliance Requirements Explained
Just missing the top spot at number two is our comprehensive guide to the DoD’s toughest security standard.
DISA STIG Compliance Requirements Explained demystifies the Security Technical Implementation Guides (STIGs). We broke down the difference between Category I, II, and III vulnerabilities and showed how to automate the validation process for containers.
This is a must-read for any vendor aiming to operate within the Department of Defense network. It turns a daunting set of requirements into a manageable checklist for your DevSecOps pipeline.
1 | How Syft Scans Software to Generate SBOMs
And finally, taking the number one spot for 2025, is the ultimate technical deep dive!
How Syft Scans Software to Generate SBOMs peeled back the layers of our open source engine to show you exactly how the magic happens. It explained Syft’s architecture of catalogers, how stereoscope parses image layers, and the logic Syft uses to determine what is actually installed in your container.
Trust requires understanding. By showing exactly how we build an SBOM, we empower teams to trust the data they rely on for critical security decisions.
Wrap-Up
That wraps up the top ten Anchore blog posts of 2025! From deep dives into scanning logic to high-level regulatory strategy, this year was about bridging the gap between knowing you need security and doing it effectively.
The common thread? Whether it’s complying with the EU CRA or optimizing a GitHub Action, the goal remains the same: security and speed at scale. We hope these posts serve as a guide as you refine your DevSecOps practice and steer your organization toward a more secure future.
Stay ahead of the curve in 2026. Subscribe to the Anchore Newsletter or follow us on your favorite social platform to catch the next big update:
If you’ve spent any time in the software security space recently, you’ve likely heard the comparison: a Software Bill of Materials (SBOM) is essentially an “ingredients list” for your software. Much like the label on a box of crackers, an SBOM tells you exactly what components, libraries, and dependencies make up your application.
But as any developer knows, a simple label can be deceptive. “Spices” on a food label could mean anything; “tomatoes” could be fresh, canned, or powdered. In software, the challenge is moving from a vague inventory to a detailed, machine-readable explanation of what is truly inside.
In a recent Cloud Native Now webinar, Anchore’s VP of Security, Josh Bressers, demystified the process of generating these critical documents using free, open source tools. He demonstrated the practical “how-to” for a world where SBOMs have moved from “nice-to-have” to “must-have.”
From Security Novelty to Compliance Mandate
For years, early adopters used SBOMs because they were “doing the right thing.” It was a hallmark of a high-maturity security program; a way to gain visibility that others lacked. But the landscape shifted recently.
“Before 2025, SBOMs were ‘novelties;’ they were ‘doing the right thing’ for security. Now they are mandatory due to compliance requirements.”
Global regulations like the EU’s Cyber Resilience Act (CRA) and FDA mandates in the U.S. have changed the math. If you want to sell software into the European market, or the healthcare sector, an SBOM is no longer a gold star on your homework; it’s the price of admission. The “novelty” phase is over. We are now in the era of enforcement.
Why Compliance is the New Proof
We often talk about SBOMs in the context of security. They are vital for identifying vulnerabilities like Log4j in minutes rather than months. However, the primary driver for adoption across the industry isn’t a sudden surge in altruism. It’s the need for verifiable evidence.
“So compliance is why we’re going to need SBOMs. That’s the simple answer. It’s not about security. It’s not about saying we are doing the right thing. It’s proof.”
Security is the outcome, but compliance is the driver. An SBOM provides the machine-readable “proof” that regulators and customers now demand. It proves you know what you’re shipping, where it came from, and that you are monitoring it for risks. In the eyes of a regulator, if it isn’t documented in a standard format like SPDX or CycloneDX, it doesn’t exist.
Getting Started: The Crawl, Walk, Run Approach
When teams realize they need an SBOM strategy, the first instinct is often to over-engineer. They look for complex database integrations or expensive enterprise platforms before they’ve even generated their first file. My advice is always to start with the simplest path possible.
“To start, store the SBOM in the project’s directory. This is one of those situations where you crawl, walk, run. Start putting them somewhere easy. Don’t overthink it.”
You don’t need a massive infrastructure to begin. Using open source tools like Syft, you can generate an SBOM from a container image or a local directory in seconds.
Crawl: Generate an SBOM manually using the CLI and save it as a JSON file in your project repo.
Walk: Integrate that generation into your CI/CD pipeline (e.g., using a GitHub Action) so an SBOM is created automatically with every release.
Run: Generate an SBOM for multiple stages of the DevSecOps pipeline, store them in a central repository and query them for actionable supply chain insights.
The Pursuit of Perfection in an Imperfect World
Software is messy. Dependencies have dependencies and scanners sometimes miss things or produce false positives. While the industry is working hard to improve the accuracy of software supply chain tools, transparency about our limitations is key.
“Our goal is perfection. We know it’s unattainable, but that’s what we’re working towards.”
We strive for a 100% accurate inventory, but “perfect” should never be the enemy of “better.” Having a 95% accurate SBOM today is infinitely more valuable during a zero-day event than having no SBOM at all while you wait for a perfect solution.
Wrap-Up
The transition from manual audits to automated, compliance-driven transparency is the biggest shift in software security this decade. By starting small with open source tooling, focusing on compliance as your baseline, and iterating toward better visibility, you can transform your security posture from reactive to proactive.
Ready to generate your first SBOM?
Download Syft: The easiest way to generate an SBOM for containers and filesystems.
Try Grype: Vulnerability scanning that works seamlessly with your SBOMs.
Watch the full webinar below.
Stay ahead of the next regulatory mandate: Follow Anchore on LinkedIn for more insights into the evolving world of software supply chain security.
We generate a lot of tooling at Anchore. What started as a few focused utilities has grown into a suite of open source tools for software supply chain security: Syft for SBOM generation, Grype for vulnerability scanning, Grant for license compliance, … and more on the way.
For a while, we made do with putting all content into in-repo READMEs. The reality is, we’ve reached a new inflection point where there is simply too much rich tooling and content to reasonably cram into a handful of README files. We’re growing, we’re expanding, and we need a proper home to capture everything we’re building.
And so, we present the shiny new hub for documenting all things related to Anchore OSS: oss.anchore.com.
Why a separate site?
The short answer: there’s just too much to say.
Our tools have matured. They support dozens of package ecosystems and operating systems. They have configuration options that deserve proper explanation. Users have real workflows: generating SBOMs in CI, scanning container images, and building license compliance reports. All of these workflows deserve guides that walk a user through them properly.
We also wanted a place to share some of the thinking behind how we build things. What component analysis capabilities do we have for each language ecosystem? What’s our philosophy and conventions around building go tools? What are a set of really useful jq recipes when working with Syft JSON output? These are things that don’t fit neatly into a README but are genuinely useful if you’re trying to understand or contribute to the projects.
What you’ll find there
The site is organized around a few main areas:
User Guides cover the things you’re most likely trying to do: generate an SBOM, scan for vulnerabilities, check license compliance. These are task-oriented and walk you through real workflows.
Ecosystem and OS Coverage describes what we support and how. Different package managers and operating systems have their own quirks; this is where we document them.
Per-Tool Reference is where you’ll find the detailed stuff: CLI documentation, configuration file reference, JSON schema definitions. The kind of thing you need when you want to know every nook and cranny of what you can make the tools describe.
Architecture and Philosophy gets into the “why” and “how” behind the tools. How Syft catalogs packages, how Grype matches vulnerabilities, how we think about building Go utilities on the Anchore OSS team.
Contributing Guides are for folks who want to get involved. We’ve tried to lower the barrier to entry for new contributors.
This is where it all lives now
We’re not abandoning READMEs entirely. They’ll still point you in the right direction and cover installation basics. But for anything beyond “here’s how to install it and run a basic command,” oss.anchore.com is the place to find everything else.
The site codebase is open source like everything else we do. If you spot something wrong, something missing, or something confusing about the doc site itself; PRs are welcome. We’d love feedback on what’s helpful and what’s not.
The transition from physical servers to Infrastructure as Code fundamentally transformed operations in the 2010s—bringing massive scalability alongside new management complexities. We’re witnessing history repeat itself with software supply chain security. The same pattern that made manual server provisioning obsolete is now playing out with Software Bill of Materials (SBOM) management. This pattern is creating an entirely new category of operational debt for organizations that refuse to adapt.
The shift from ad-hoc security scans to continuous, automated supply chain management is not just a technical upgrade. At enterprise scale, you simply cannot secure what you cannot see. You cannot trust what you cannot verify. Automation is the only mechanism that delivers consistent visibility and confidence in the system.
“Establishing trust starts with verifying the provenance of OSS code and validating supplier SBOMs. As well as, storing the SBOMs to track your ingredients over time.”
The Scale Problem: When “Good Enough” Isn’t
Manual processes work fine until they don’t. When you are managing a single application with a handful of dependencies you can get away with lots of unscalable solutions. But modern enterprise environments are fundamentally different. A single monolithic application might have had stable, well-understood libraries but modern cloud-native architectures rely on thousands of ephemeral components that change daily.
This fundamental difference creates a visibility crisis that traditional spreadsheets and manual scans cannot solve. Organizations attempting to manage this complexity with “Phase 1” tactics like manual scans or simple CI scripts typically find themselves buried under a mountain of data.
Supply Chain Security Evolution
Phase 1: The Ad-Hoc Era (Pre-2010s) was characterized by manual generation and point-in-time scanning. Developers would run a tool on their local machine before a release. This was feasible because release cycles were measured in weeks or months, and dependency trees were relatively shallow.
Phase 2: The Scripted Integration (2020s) brought entry-level automation. Teams wired open source tools like Syft and Grype into CI pipelines. This exploded the volume of security data without a solution for scaling data management. “Automate or not?” became the debate, but it missed the point. As Sean Fazenbaker, Solution Architect at Anchore, notes: “‘Automate or not?’ is the wrong question. ‘How can we make our pipeline set and forget?’ is the better question.”
Phase 3: The Enterprise Platform (Present) emerged as organizations realized that generating an SBOM is only the starting line. True security requires managing that data over time. Platforms like Anchore Enterprise transformed SBOMs from static compliance artifacts into dynamic operational intelligence, making continuous monitoring a standard part of the workflow.
The Operational Reality of “Set and Forget”
The goal of Phase 3 is to move beyond the reactive “firefighting” mode of security. In this model, a vulnerability disclosure like Log4j triggers a panic: teams scramble to re-scan every artifact in every registry to see if they are affected.
In an automated, platform-centric model, the data already exists. You don’t need to re-scan the images; you simply query the data you’ve already stored. This is fundamentally different from traditional vulnerability management.
Anchore scans SBOMs built whenever: five months from now, six months ago, 30 years in the future. If a new vulnerability is detected, you’ll know when, where and for how long.
Automation also fundamentally changes the developer experience. In traditional models, security is a gatekeeper that fails builds at the last minute, forcing context-switching and delays. In an automated, policy-driven environment, security feedback is immediate.
When automation is integrated correctly into the pull request workflow, developers can resolve issues before code ever merges. “I’ve identified issues. Fixed them. Rebuilt and pushed. I didn’t rely on another team to catch my mistakes. I shifted left instead.”
This is the promise of DevSecOps: security becomes a quality metric of the code, handled with the same speed and autonomy as a syntax error or a failed unit test.
Where Do We Go From Here?
We are still in the early stages of this evolution, which creates both risk and opportunity. First-movers can establish a trust foundation before the next major supply chain incident. Those who wait will face the crushing weight of manual management.
Crawl: The Open Source Foundation
Start with industry standards. Tools like Syft (SBOM generation) and Grype (vulnerability scanning) provide the baseline capabilities needed to understand your software.
Generate SBOMs for your critical applications using Syft.
Scan for vulnerabilities using Grype to understand your current risk posture.
Archive these artifacts to begin building a history, even if it is just in a local filesystem or S3 bucket.
Walk: Integrated Automation
Early adopters can take concrete steps to wire these tools into their daily flow:
Integrate scans into GitHub Actions (or your CI of choice) to catch issues on every commit.
Define basic policies (e.g., “fail on critical severity”) to prevent new risks from entering production.
Separate generation from scanning. It is often more efficient to generate the SBOM once and scan the JSON artifact repeatedly, rather than re-analyzing the heavy container image every time.
Container image scanning has come a long way over the years, but it still comes with its own set of, often unique, challenges. One of these being the difficulty in analyzing images for vulnerabilities when they contain a Rust payload.
If you’re a big Rust user, you may have found that some software composition analysis (SCA) tools will struggle to report on known vulnerabilities found in your software dependencies. This is typical because these dependencies are not exposed in a consistent manner for cataloging and analysis.
In this blog post we’ll show you how to embed dependency information directly in your images, allowing you to get more accurate SBOM (software bill of materials) and vulnerability results. We’ll cover:
Why Rust crates are hard to detect inside container images
How Anchore Enterprise’s image and source catalogers work and can discover dependencies from both source and binary artifacts
Why the rust-cargo-lock cataloger isn’t enabled for image scans by default
And how you can use cargo-auditable to embed crate metadata and dependency information directly into your compiled binary — so scanners can pick up every dependency without bloating your image
Why Your Rust Containers Look Empty to Security Scanners and How to Fix It
Your Container Doesn’t Look Anything Like Your Source Tree
Most container scanners can’t see inside compiled Rust binaries because by the time the image is built, it will typically only contain the final compiled Rust binary. This means that all of Cargo’s dependency metadata (cargo.toml and cargo.lock) have already been stripped away. Because of this, your image just looks like one big executable to the scanner with no dependencies. The lock file is the authoritative record of exactly which crates and versions were used to resolve the dependency graph. Without the lock file, the scanner cannot figure out the actual crate versions used at build time.
Opaque, Static Rust Binaries
Rust produces optimized, statically linked binaries. These artifacts don’t naturally contain machine-readable metadata about dependency versions. Without explicit embedding, scanners must rely on things like file names, pattern-matching or trying to infer crate versions from panic messages. This is obviously a less than desirable approach.
Stripped Binaries and Minimal Images for Production
To keep production images lean, teams will often remove any build tools from which would otherwise cause too much extra bloat in the images thus making the image more susceptible to security issues. But from a visibility standpoint, doing this will also remove almost all of the useful metadata that a scanner can use to attempt to reverse-map a binary back to its dependency graph; especially on minimal base images.
Diversity in Deployment
Different teams structure Rust deployment images differently. Some bake the entire Rust toolchain into a single monolithic image; others copy in only the compiled binary. Due to how Syft does cataloging, the filesystem layout may affect crate detection unless the environment still somewhat resembles a Rust workspace.
Even if you do recover a cargo.lock file from somewhere, it may not reflect the binary actually running in production due to potential differences in things like timestamps, environment variables, build machines, etc. This can all potentially lead to non-matching dependency graphs. This highlights why it is important to ensure the dependency graph is included at build time.
How Anchore Enterprise Catalogs Software Components
Each individual cataloger specializes in extracting package metadata from a specific ecosystem or filesystem structure. Understanding how Anchore Enterprise orchestrates these catalogers is crucial for correctly analyzing challenging artifacts, such as images with a Rust payload for security vulnerabilities.
Different Defaults for Image Scans vs. Source Scans
When scanning a container image, Syft assumes the image is an accurate representation of what is actuallyinstalled, not source code. As a result of this, many source-oriented catalogers such as the rust-cargo-lock-cataloger are disabled by default to avoid false positives. Syft provides the ability for the user to tell it to run additional catalogers that are not set by default for the target type. You can use syft --select-catalogers +rust-cargo-lock-cataloger <img> to run the non-image cataloger against the image by overriding the default behavior.
Image catalogers are optimized for installed package metadata: OS packages, Python wheels, Java archives, and so on. Unless explicitly instructed, Syft will not search for source layouts or lockfiles inside an image; production containers typically do not include them.
But when Syft scans a source code repository, it aggressively looks for manifest files like cargo.lock (Rust), package.json (NPM), gemfile.lock (Ruby). These are the files that reflect the developer’s intended dependency graph. When scanning a source repository Syft applies catalogers that assume a development environment. This includes the Rust lockfile parser, which is able to accurately capture crate version information. That is why scanning a Git repository produces richer Rust dependency data than scanning the image produced by that repository.
Why Are Lockfile-Based Rust Catalogers Not Enabled for Image Scans?
Given the points mentioned above, hopefully it is starting to become a bit easier to understand why Syft does not run the cargo.lock cataloger during image scans by default. Even if a cargo.lock file exists inside an image, there is no guarantee that it still accurately reflects the binary that is inside the image. It could be outdated or leftover from an unrelated build step. Hence why the cataloger is disabled by default, as parsing a cargo.lock without being able to confirm the validity of it against the binary could lead to incorrect dependency graphs or false positives during the vulnerability scan. As previously mentioned, you can enable lockfile-based cataloging in Syft via the CLI but this will require careful consideration of what is actually contained in the image.
cargo-autidable: A Practical Breakthrough for Creating Complete Rust SBOMs
cargo-auditable addresses all of the challenges mentioned above by embedding dependency metadata directly into Rust binaries at build time. It extracts the full dependency graph and embeds it into a special linker section. The data is a compact, compressed JSON blob containing the crate names and versions. No paths, secrets or source is included, keeping the size overhead small, often to just a few kilobytes, even for large dependency graphs.
Because now using this tool the metadata is embedded into the binary itself, Syft (v1.15+) is able to automatically extract crate metadata and include it in the SBOM.
There is also now an adoption of tools similar to cargo-auditable across the different ecosystems that were previously struggling with the difficulties of metadata being stripped from container images.
Embedding the metadata/dependency graph ensures that scanners don’t need the cargo.lock file or source files, they can just simply inspect the binary itself. This is incredibly important moving forward with the security workflow of container images.
You can adopt auditable builds in two differing models:
1. CLI Wrapper Approach
Install cargo-auditable globally and run: cargo auditable build --release. This is ideal for CI pipelines and container builds.
2. Crate-Level Integration (build.rs)
Add auditable and auditable-build to cargo.toml, then invoke auditable::inject_dependency_list!() from build.rs or the application entrypoint. This doesn’t require installing any additional cargo plugins at runtime.
A Practical Multi-Stage Dockerfile for Auditable Rust Builds
# Stage 1: BuilderFROM rust:1.75 as builderWORKDIR /usr/src/app# Copy Cargo.toml and Cargo.lock to leverage Docker's build cacheCOPY Cargo.toml Cargo.lock ./# Create a dummy src/main.rs to compile dependencies and cache themRUN mkdir src && \ echo "fn main() {println!(\"Preparing dependency cache...\")}" > src/main.rs && \ cargo build --locked --release# Remove the dummy src directoryRUN rm -rf src/# Copy the actual source codeCOPY . .# Build the project with cargo-auditable# Ensure cargo-auditable is installed or install it here if not in the base image# RUN cargo install cargo-auditable # Uncomment if neededRUN cargo auditable build --release# Stage 2: RuntimeFROM debian:stable-slimWORKDIR /app# Copy the auditable binary from the builder stageCOPY --from=builder /usr/src/app/target/release/<your-binary-name> ./CMD ["./<your-binary-name>"]# Stage 1: BuilderFROM rust:1.75 as builderWORKDIR /usr/src/app# Copy Cargo.toml and Cargo.lock to leverage Docker's build cacheCOPY Cargo.toml Cargo.lock ./# Create a dummy src/main.rs to compile dependencies and cache themRUN mkdir src && \ echo "fn main() {println!(\"Preparing dependency cache...\")}" > src/main.rs && \ cargo build --locked --release# Remove the dummy src directoryRUN rm -rf src/# Copy the actual source codeCOPY . .# Build the project with cargo-auditable# Ensure cargo-auditable is installed or install it here if not in the base imageRUN cargo install cargo-auditableRUN cargo auditable build --release# Stage 2: RuntimeFROM debian:stable-slimWORKDIR /app# Copy the auditable binary from the builder stageCOPY --from=builder /usr/src/app/target/release/<your-binary-name> ./CMD ["./<your-binary-name>"]
Enterprise production build pipelines need reproducible and minimal container images. The above Dockerfile integrates cargo-auditable cleanly into a multi-stage build, ensuring that:
dependency metadata is embedded,
the final runtime image is minimal, and
SBOM tools can extract an accurate crate inventory list.
Seamless SBOM Generation and Analysis with Anchore Enterprise
Using the Dockerfile above as a template, you can build your image (e.g vulnerable-rust-app:latest). Whether the image resides locally or in a container registry, it can be submitted to Anchore Enterprise for SBOM generation and analysis. Because we have used cargo-auditable in the build process, the resulting binary contains embedded audit metadata. Anchore Enterprise, using Syft under the hood, automatically extracts this data to produce an accurate SBOM; including all of the Rust crates used.
Next, we add the image to Anchore Enterprise using anchorectl. During this step, Anchore Enterprise invokes Syft under the hood to generate the SBOM automatically and submit it to the Enterprise services for analysis. Here is what you would see in your terminal:
Using anchorectl we can now inspect the contents of the image and filter specifically for rust-crates. Anchore Enterprise correctly and successfully identifies each of the crates that I added into this particular image via the Dockerfile, due to cargo-auditable embedding the metadata into the image.
Here is what you would see in the Anchore Enterprise dashboard:
Finally, we review the vulnerability analysis results. In this example, the image contains one high-severity vulnerability and two low-severity vulnerabilities affecting the tokio crate.
$ anchorectl image vuln docker.io/vulnerable-rust-app:latest --type non-os ✔ Fetched vulnerabilities [3 vulnerabilities] docker.io/vulnerable-rust-app:latest ┌─────────────────────┬──────────┬───────┬─────────┬────────┬──────────────┬────────────┬─────────────┬───────┬────────────────┬───────────────────────────────────────────────────┬───────────────────┐│ ID │ SEVERITY │ NAME │ VERSION │ FIX │ WILL NOT FIX │ TYPE │ FEED GROUP │ KEV │ CVES │ URL │ ANNOTATION STATUS │├─────────────────────┼──────────┼───────┼─────────┼────────┼──────────────┼────────────┼─────────────┼───────┼────────────────┼───────────────────────────────────────────────────┼───────────────────┤│ GHSA-fg7r-2g4j-5cgr │ High │ tokio │ 0.2.25 │ 1.8.4 │ false │ rust-crate │ github:rust │ false │ CVE-2021-45710 │ https://github.com/advisories/GHSA-fg7r-2g4j-5cgr │ ││ GHSA-rr8g-9fpq-6wmg │ Low │ tokio │ 0.2.25 │ 1.38.2 │ false │ rust-crate │ github:rust │ false │ │ https://github.com/advisories/GHSA-rr8g-9fpq-6wmg │ ││ GHSA-4q83-7cq4-p6wg │ Low │ tokio │ 0.2.25 │ 1.18.5 │ false │ rust-crate │ github:rust │ false │ │ https://github.com/advisories/GHSA-4q83-7cq4-p6wg │ │└─────────────────────┴──────────┴───────┴─────────┴────────┴──────────────┴────────────┴─────────────┴───────┴────────────────┴───────────────────────────────────────────────────┴───────────────────┘
This can also be viewed in the UI.
Wrap-up
As we’ve seen, securing Rust crates in container images presents unique challenges, but not insurmountable ones. By integrating cargo-auditable into your build process, you ensure that your production binaries carry their own source of truth. This enables accurate SBOM generation and vulnerability detection without compromising on image size or performance.
Don’t let your Rust containers remain a blind spot in your security posture. With Anchore Enterprise, you can automatically leverage this embedded metadata to gain complete visibility into your software supply chain, ensuring that what you build is exactly what you secure.
Explore SBOM use-cases for almost any department of the enterprise and learn how to unlock enterprise value to make the most of your software supply chain.
Anchore Enterprise 5.24 adds native filesystem scanning and policy enforcement for imported SBOMs so platform engineers and security architects can secure non-container assets with the same rigor as containers. With software supply chains expanding beyond registries to include:
virtual machine images,
source code tarballs, and
directory-based artifacts.
This release focuses on increasing supply chain coverage and active governance. It replaces disparate, manual workflows for non-container assets with a unified approach. And turns passive 3rd-party SBOMs into active components of your compliance strategy.
What’s New in AE 5.24
This release introduces three capabilities designed to unify security operations across your entire software stack:
Native Filesystem Scanning: Ingest and analyze VMs, source directories, and archives directly via anchorectl, removing the need for manual SBOM generation steps.
Policy Enforcement for Imported SBOMs: Apply vulnerability policy gates to 3rd-party SBOMs to automate compliance decisions for software you didn’t build.
Advanced Vulnerability Search: Instantly locate specific CVEs or Advisory IDs across your entire asset inventory for rapid zero-day response.
Watch a walkthrough of new features including a demo with Alex Rybak, Director of Product.
Anchore Enterprise now natively supports the ingestion and analysis of arbitrary filesystems. Previously, users had to run Syft independently to generate an SBOM and then upload it. Now, the platform handles the heavy lifting directly via anchorectl.
This streamlines the workflow for hybrid environments. You can now scan a mounted VMDK, a tarball of source code, or a build directory using the same pipeline logic used for container images.
Using the updated anchorectlCLI, you can point directly to a directory or mount point. Anchore handles the SBOM generation and ingestion in a single step.
# Example: Ingesting a mounted VM image for analysisanchorectl sbom add \ --from ./my_vmdk_mount_point \ --name my-vm-image \ --version 1.0 \ --sbom_type file-system
Active Compliance for Imported SBOMs (BYOS)
Imported SBOMs (Bring Your Own SBOM) have graduated from read-only data artifacts to fully governed assets. AE 5.24 introduces vulnerability policy gates for imported SBOMs.
Visibility without enforcement is noise. By enabling policy assessments on imported SBOMs, you can act as a gatekeeper for vendor-supplied software. For example, you can now automatically fail a build or flag a vendor release if the provided SBOM contains critical vulnerabilities that violate your internal security standards (e.g., Block if Critical Severity count > 0).
Rapid Response with Advanced Search
When a major vulnerability (like Log4j or OpenSSL) is disclosed, the time to identify affected assets is critical. AE 5.24 adds a unified search filter to the Vulnerabilities List View that accepts both Vulnerability IDs (CVE) and Advisory IDs.
This reduces triage time during zero-day incidents. Security teams can paste a specific ID into a single filter to immediately identify exposure across all managed SBOMs and images, regardless of the asset type.
Expanded STIG Compliance Support
Continuing our support for public sector and regulated industries, this release expands the library of out-of-the-box compliance profiles. AE 5.24 adds support for:
Apache Tomcat 9
NGINX v2.3.0
These profiles map directly to DISA STIG standards, allowing teams to automate the validation of these ubiquitous web server technologies.
Using DevSecOps principles to approach software development is always the ideal. We love “secure by design” at Anchore but…unfortunately there are limits to how far this practice can stretch before it breaks. The messy reality of user needs and operational constraints often forces organizations to veer off the “golden path” paved by the best intentions of our security teams.
This is precisely where comprehensive software supply chain security and compliance solutions become critical. A start safe, stay secure approach can bridge the gap between the platonic ideal of security as it collides with the mess of real-world complexity.
Today, Anchore and Chainguard are expanding their partnership to bring that same philosophy to application dependencies. With Anchore Enterprise now integrated with Chainguard Libraries for Python, joint customers can validate the critical and high-severity CVEs Chainguard remediates. This reduces risk, eliminates unnecessary triage work, and secures dependencies without disrupting existing workflows.
What Chainguard Libraries Means for Supply Chain Security
Chainguard Libraries extends the company’s “golden path” philosophy from minimal OS images to the application dependencies built on top. It provides a set of popular open source libraries, starting with Java, Python and JavaScript. The libraries are built from source in a tamper-proof, SLSA L2-certified environment that’s immune to build-time and distribution-stage malware injections. The goal is to provide developers with a set of trusted building blocks from the very start of the development process.
Anchore Enterprise users depend on continuous scanning and policy enforcement to manage software supply chain risk. But public package registries produce a relentless stream of alerts; many of them noisy, many irrelevant, and all of them requiring investigation. Even simple patching cycles become burdensome, reactive workstreams. This integration changes that.
More details about the integration:
Validate Chainguard Python Library CVE Remediation in Anchore Enterprise Workflows: Anchore Enterprise users can now use their existing scanning pipelines to validate that CVEs remediated by Chainguard Libraries for Python correctly show up as fixed or absent. This brings trusted upstream content directly into Anchore; no new workflows and no operational friction. Just fewer critical vulnerabilities for your team to deal with.
Strengthen Dependency Security and Reduce Malware Risk: Chainguard Libraries are built in a tamper-proof environment and free from supply chain refuse. This benefits Anchore customers by eliminating unverified/compromised packages and reducing dependency triage workload. Recent ecosystem attacks like ultralytics or num2words underscore the importance of this integration.
Teams no longer start their security journey by cleaning up unknown packages from public registries. They begin with dependencies that are already vetted, traceable, and significantly safer.
Start Safe, Stay Secure, and Stay Compliant: From Golden Path to Real-World Operations
This is where Anchore Enterprise provides the critical framework to ‘Stay Secure and Compliant,’ bridging the gap between a secure-by-design foundation and the fluid realities of day-to-day operations.
Software Supply Chain Policy Scanning and Enforcement
Chainguard Libraries enable organizations to start safe. But applications evolve. Developers regularly need to diverge from these golden bases for legitimate business reasons.
How do we stay secure, even as we take a necessary side quest from the happy path? The answer is moving from static prevention to continuous policy enforcement. Anchore Enterprise enables organizations to stay both secure and compliant by enforcing risk-based policies, even when the security principles embedded in the Chainguard artifacts conflict with the immediate needs of the organization.
Zero-Day Disclosure Alerts on Chainguard OSes & Libs
A library or OS is only secure up until a zero-day disclosure is published. Chainguard publishes a security advisory feed (an OpenVEX feed) which provides a list of vulnerabilities associated with the libraries they distribute. When a new vulnerability is disclosed, Anchore Enterprise will detect this and flag it against the relevant content. This can be used to either drive a manual or automated pull of newer content from the Chainguard Libraries repo. Anchore Enterprise’s Policy Engine allows you to filter these out using simple rules to ensure you are not distracted except for the most critical of issues.
The visibility challenge extends far beyond open source language libraries. Modern enterprise applications often integrate proprietary components where the content is not in a packaged form: think 3rd-party observability (or security runtime) agents, proprietary SDKs, compiled binaries from vendors, and custom in-house tooling. Organizations still require the ability to track and remediate vulnerabilities within these closed source components.
Anchore Enterprise solves this critical gap by employing deep binary analysis techniques. This capability allows the platform to analyze compiled files (binaries) and non-standard packages to identify and report vulnerabilities, licenses, and policy violations, ensuring a truly comprehensive security posture across every layer of the stack, not just the known-good base components.
Ingest Chainguard OS & Libraries SBOMs for Full Supply Chain Visibility
Ultimately, supply chain risk visibility, compliance and risk management allow a business to make informed decisions about when and how to allocate resources. To do this well, you need a system to store, query, and generate actionable insights from your evidence.
This presents another “buy vs. build” decision. An organization can build this system itself, or it can deploy a turnkey system like Anchore Enterprise. Anchore can generate SBOMs from Chainguard OS/Libraries or ingest the SBOMs from the Chainguard Registry, providing a single system to store, query, and manage risk across your entire software supply chain.
If you follow the software supply chain space, you’ve heard the noise. The industry often gets stuck in a format war loop; debating schema rather than focusing on the utility of the stored data. It’s like arguing about font kerning on a nutrition label while the ingredients list is passed over.
We recently hosted Steve Springett, Chair of the CycloneDX Core Working Group, to cut through this noise. The conversation moved past the basic definition of an SBOM and into the mechanics of true software transparency.
Here are four takeaways on where the industry is heading—and why the specific format doesn’t matter.
1. Content is king
For years, the debate has centered on “which standard will win.” But this is the wrong question to ask. The goal isn’t to produce a perfectly formatted SBOM; the goal is to reduce systemic risk and increase software transparency.
As Springett noted during the session:
“The format doesn’t really matter as long as that format represents the use cases. It’s really about the content.”
When you focus on form over function, you end up generating an SBOM to satisfy a regulator even while your security team gains no actionable intelligence. The shift we are witnessing is from generation to consumption.
Does your data describe the components? Does it capture the licensing? More importantly, does it support your specific use case, whether that’s procurement, vulnerability management, or forensics? If the content is empty, the schema validation is irrelevant.
2. When theory and reality diverge
In physical manufacturing, there is often a gap between the engineering diagrams and the finished product. Software is no different. We have the source code (the intent) and the compiled binary (the reality).
Springett ran into a situation where a manufacturer needed a way to model the dependencies of the process that created a product:
“We created a manufacturing bill of materials (MBOM) to describe how something should be built versus how it was actually built.”
This distinction is critical for integrity. A “Design BOM” tells you what libraries you intended to pull in. In this case, the Design MBOM and the Build MBOM were able to explain what parts of the process were diverging from the ideal path. Capturing this delta allows you to verify the integrity of the pipeline itself, not just the source that entered it.
3. Solving the compliance cascade
Security teams are drowning in standards. From SSDF to FedRAMP to the EU CRA, the overlap in requirements is massive, yet the evidence collection remains manual and disjointed. It is the classic “many-to-many” problem.
Machine-readable attestations are the mechanism to solve this asymmetry.
“A single attestation can attest to multiple standards simultaneously. This saves a lot of hours!”
Instead of manually filling out a spreadsheet for every new regulation, you map a single piece of evidence—like a secure build log—to multiple requirements. If you prove you use MFA for code changes, that single data point satisfies requirements in FedRAMP, PCI DSS 4.0, and SSDF simultaneously.
This shifts compliance from a manual, document-based operation to an automated process. You attest once, and the policy engine applies it everywhere.
4. Blueprints and behavioral analysis
Reproducible builds are a strong defense, but they aren’t a silver bullet. A compromised build system can very accurately reproduce the malware that has been pulled in from a transitive dependency. To catch this, you need to understand the intended behavior of the system, not just its static composition.
This is where the concept of “blueprints” comes into play.
“Blueprints are the high-level architecture AND what the application does. This is critically important because reproducible builds are fine, but can also be compromised.”
A blueprint describes the expected architecture. It maps the data flows, the expected external connections, and the boundary crossings. If your SBOM says “Calculator App,” but the runtime behavior opens a socket to an unknown IP, a static scan won’t catch it.
By comparing the architectural blueprint against the runtime reality, you can detect anomalies that standard composition analysis misses. It moves the defense line from “what is in this?” to “what is this doing?”
The Path Forward
We’ve moved past the era of format wars. The takeaways are clear: prioritize content over schema, capture the “as-built” reality, automate your compliance evidence, and start validating system behavior, not just static ingredients.
But this is just the baseline. In the full hour, Steve Springett dives much deeper into the mechanics of transparency. He discusses how to handle AI model cards to track training data and bias, how to manage information overload so you don’t drown in “red lights,” and what’s coming next in CycloneDX 1.7 regarding threat modeling and patent tracking.
To get the complete picture—and to see how these pieces fit into a “system of systems” approach—watch the full webinar. It’s the fastest way to move your strategy from passive documentation to active verification.
Learn about how SBOMs, and CycloneDX specifically, planning for the future. Spoiler alert: compliance, attestations and software transparency are all on deck.
There’s a saying I use often, usually as a joke, but it’s often painfully true. Past me hates future me. What I mean by that is it seems the person I used to be keeps making choices that annoy the person I am now. The best example is booking that 5am flight, what was I thinking? But while I mean this mostly as a joke, we often don’t do things today that could benefit us in the future. What if we can do things that benefit us now, and in the future. Let’s talk about supply chain security in this context.
The world of supply chain security is more complicated and hard to understand than it’s ever been. There used to be a major supply chain attack or bug every couple of years. Now it seems like we see them every couple of weeks. In the past it was easy for us to mostly ignore long term supply chain problems because it was a problem for our future selves. We can’t really do that anymore, supply chain problems are something that affect present us, and future us. Also past us, but nobody likes them!
There are countless opinions on how to fix our supply chain problems. Everything from “it’s fine” to “ban all open source”. But there is one common thread every possible option has, and that’s understanding what software is in your supply chain. And when we say “software in your supply chain” we really mean all the open source you’re using. So how do we track all the open source we’re using? There are many opinions around this question, but the honest reality at this point is SBOMs (Software Bills of Material) won. So what does this have to do with us in the future?
Let’s tie all the pieces together now. We have a ton of open source. We have all these SBOMs, and we have a supply chain attack that’s going to affect future us. But not the distant future us, it’s the future us in a few weeks. It’s also possible we’re still in the middle of dealing with the last attack.
How does an inventory of our software help with future supply chain attacks?
When any sort of widespread incident happens in the world of security, the first question to ask is “am I affected” I have a blog post I wrote after one of the recent NPM incidents. A Zero-day Incident Response Story from the Watchers on the Wall. I can’t even remember where exactly it falls in the timeline of recent NPM attacks, there have been so many of these things. Most modern infrastructure is pretty complex. Asking the question “am I affected” isn’t as simple as it sounds.
If you have a container image, or a zip file, or a virtual machine that’s running your infrastructure, how do you even start to understand what’s inside? You might dig around and look for a specific filename, maybe something like “log4j.jar”. Sometimes looking for a certain file will work, sometimes it won’t. Did you know JAR files can be inside other JAR files? Now the problem is a lot harder.
It’s also worth noting that if you’re in the middle of a supply chain event, finding all your software and decompressing it isn’t a great use of time. It’s slow and a very error prone task. If you have thousands of artifacts to get through, that’s not going to happen quickly. When we’re in the middle of a security incident, we need the ability to move quickly and answer questions that come up as we learn more details.
Was I ever affected?
Let’s assume you figured out if you are, or aren’t, affected by a supply chain attack, the next question might be “was I ever affected?” Some supply chain problems don’t need a look back in time, but some do. If the problem was a single version of a malicious package that’s 6 hours old, you might not need an inventory of every version of every artifact ever deployed. But one of the challenges we have with these supply chain problems is we don’t know what’s going to happen next. If we need to know every version of every artifact that was deployed for the last two years, can most of us even answer that question?
It’s likely you’re not keeping artifacts laying around. They’re pretty big, but even if you don’t care about space, it can be really hard to keep track of everything. If you deploy once a day, and you have 20 services, that’s a lot of container images. Rather than keep the actual artifacts around taking up space, we can store just the metadata from those artifacts.
How can SBOMs help with this? SBOMs are just documents. One document per artifact. There are SBOM management systems that can help wrangle all these documents. While we’ve not yet solved the problem of storing a large number of software artifacts easily and efficiently. We have solved the problem of storing a large number of structured documents and making the data searchable.
The searchable angle is a pretty big deal. Even if you do have millions of stored container images, good luck searching through those. If you have a store of all your SBOMs, which would represent all the software you currently and have ever cared about, searching through that data is extremely fast and easy. We know how to search through structured data.
Next steps
Keep in mind that generating and collecting SBOMs is just the first step in a supply chain journey. But no journey can start without the first step. It’s also never been easier to start creating and storing SBOMs. We can benefit from the data right now. There’s a paper from the OpenSSF titled Improving Risk Management Decisions with SBOM Data that captures many of these use cases.
Fundamentally it’s an investment for our future selves who will need to know what all the software components are. It’s common for most solutions to either help present us or future us, but not both. When we start using an SBOM, why not both?
Explore SBOM use-cases for almost any department of the enterprise and learn how to unlock enterprise value to make the most of your software supply chain.
Here’s an uncomfortable truth: if you’re only scanning container images, you’re missing a key aspect of your security vulnerabilities. While container scanning is valuable for checking packaged dependencies and OS components which in itself cannot be understated, it’s not necessarily aware of the custom code vulnerabilities that attackers exploit in real-world breaches.
Think of it this way—container scanning checks whether your ingredients are fresh, but it can’t tell if your recipe is poisoned. And in today’s threat landscape, attackers are poisoning the recipe.
What Container Scanning Can’t See
Container scanners analyze built images after compilation—comparing package versions against CVE databases. They’re excellent at finding known vulnerabilities in third-party components. But, it’s not intrinsically geared towards detecting the vulnerabilities in your code.
Once your application code has been compiled into binaries, the scanner has little to no visibility into how that code actually works. It can’t analyze logic flows, trace data paths, or understand business rules.
What does this mean in practice? Container scanners are not designed to surface:
Broken authentication mechanisms that let attackers bypass login
Business logic flaws that allow transaction manipulation
These represent several of the OWASP Top 10 vulnerability categories which necessitate the need for organizations to also adopt source code scanning as part of their overall security posture.
Real Breaches That Prove the Point
Some of the most well known security incidents of recent years all share something in common: they succeeded because organizations relied on container scanning solely instead of a holistic approach which also incorporated source code scanning.
SolarWinds (2020) remains the textbook case. Russian state-sponsored attackers deployed malware on SolarWinds build servers that surgically modified source code during compilation. The malicious code was compiled, signed with valid certificates, and distributed to 18,000+ organizations including multiple U.S. federal agencies.
CodeCov (2021) demonstrates supply chain risk at the source level. Attackers modified the Bash uploader script that thousands of developers ran in their CI/CD pipelines, silently exfiltrating environment variables, API keys, and credentials for over two months. Organizations including HashiCorp and hundreds of others were compromised.
Log4Shell (2021) affected hundreds of millions of devices with a critical severity rating. The vulnerability was a missing input validation check in Apache Log4j source code that existed for eight years before discovery. Static analysis tools are specifically designed to catch input validation failures—but you have to scan the source code, not just containers.
The Timing Problem
Container scanning happens after code is compiled. By the time you scan a container image, package installation scripts have already been executed with full developer privileges—potentially accessing secrets, modifying files, or establishing persistence.
Modern package managers (npm, pip, Maven) automatically run code during installation. These scripts execute before build time, before containerization, before any scanner examines the result. If a malicious package or compromised dependency runs code during installation, container scanning only may not see it.
This is why supply chain attacks increasingly target upstream dependencies. Over 512,000 malicious packages were identified in 2024—a 156% year-over-year increase. These attacks exploit the blind spot between source code and containers.
The Solution: Dual-Layer Security
Stop treating source code scanning and container scanning as alternatives. They’re complementary layers that catch different problems at different stages. You need both.
This is exactly the approach Anchore has built: scan early at the source code level, then scan again when you build containers. It’s not redundant—it’s smart defense that covers both angles.
What Anchore’s Container Scanning Catches
Anchore’s container scanning goes deep. Using three core tools—Syft for building a software bill of materials (SBOM – a formal inventory of all the components, libraries, and dependencies that make up a piece of software), Grype for finding vulnerabilities, and Anchore Enterprise for managing it all—the platform examines every layer of your container images.
This means more than just checking package versions. The scanner looks at operating system packages, application dependencies, nested archives (like JARs inside WARs), and even scans file contents for exposed secrets, and malware signatures.
The vulnerability database draws from over 15 authoritative sources including the National Vulnerability Database, GitHub Security Advisories, and vendor-specific security data. But, Anchore doesn’t just dump a list of CVEs at you. It prioritizes risks using CVSS severity scores, EPSS (which predicts exploitation likelihood), and CISA’s list of actively exploited vulnerabilities.
What really matters: you get focused on what’s actually dangerous, not just what’s technically vulnerable.
What Anchore’s Source Code Scanning Catches
Here’s where Anchore differs from traditional static analysis tools. Instead of analyzing your custom application code for logic flaws, Anchore focuses on Software Composition Analysis (SCA)—identifying vulnerabilities in the open source dependencies you’re pulling into your projects.
The scanner reads your package manifest files (package.json, requirements.txt, pom.xml, go.mod—you name it) and checks both direct and transitive dependencies without needing to compile anything. It supports over 40 programming language ecosystems from C++ and Java to Rust and Swift.
The secrets detection capability scans both source repositories and built containers for exposed credentials: AWS keys, database passwords, API tokens, SSH keys. When it finds them, you can automatically block builds or deployments.
The key limitation: Anchore won’t catch SQL injection, cross-site scripting, or business logic flaws in your custom code. For that, you still need traditional SAST tools. Anchore’s documentation explicitly says to use both.
Why Both Layers Matter
The reality is that containers bring in way more than your application code. Base images, system libraries, runtime environments—all of these can introduce vulnerabilities that don’t exist in your source code.
At the source level, you catch vulnerable dependencies early when they’re cheap to fix. But, you’ll miss OS-level vulnerabilities, runtime environment risks, and problems introduced during the build process itself.
At the container level, you see the complete picture of what’s actually deploying to Production—but by then, you’ve already spent time and resources building the image. Finding problems at this stage costs more to fix.
Real examples make this concrete:
Container scanning catches:
Critical vulnerabilities in Alpine’s package manager or OpenSSL libraries
Log4j vulnerabilities buried deep in nested JAR dependencies
Malware injected through compromised base images
Source code scanning catches:
Vulnerable npm packages declared in package.json before they’re even installed
Exposed secrets in configuration files before they reach version control
Problematic open source licenses that could create legal issues
The two approaches complement each other and a real-world use case would be scanning a source code repository for open source licensure compliance or vulnerabilities in open source dependencies in the source code check-in stage of the build pipeline prior to an artifact (JAR, WAR, container image, etc.) being built, tested (unit, integration, automation, etc.), stored (within an artifact repository/container registry), and ultimately deployed.
One approach doesn’t also have to be done at the expense of the other as they are interchangeable with no co-dependencies. For instance, if an organization was already leveraging a traditional SAST tool for source code scanning, Anchore could then solely be utilized for container scanning within the build pipeline.
How It Works
Anchore integrates with the tools you’re already using. GitHub Actions, GitLab CI/CD, Jenkins, Azure DevOps, CircleCI—there are native integrations for all of them.
You can run source code scanning in distributed mode as described below which will work with any CI/CD system as long as the AnchoreCTL binary can be installed and run, or you can access the Enterprise APIs directly .
Distributed mode: Generate SBOMs locally and send them to Anchore for analysis
AnchoreCTL is published as a simple binary available for download either from the Anchore Enterprise deployment or Anchore’s release site.
Using AnchoreCTL, you can manage and inspect all aspects of an Anchore Enterprise deployment, either as a manual control tool or as a CLI that is designed to be used in scripted environments such as CI/CD and other automation environments.
The platform’s policy engine lets you define security gates that automatically block non-compliant code/images from deploying. Pre-built policy bundles cover FedRAMP, NIST, DISA STIG, and other compliance frameworks, or you can write custom policies in JSON.
One unique capability: continuous monitoring through stored SBOMs. When a new zero-day vulnerability like Log4Shell emerges, you can instantly query your SBOM repository to find all affected systems—no rescanning required.
Example:
In the below example, we’ll generate an SBOM from a source code repository and then analyze (for vulnerabilities) and import the resultant SBOM into an Anchore Enterprise deployment as part of a versioned application source code artifact.
AnchoreCTL is also being leveraged in distributed mode which could be automated by adding the steps to a CI/CD pipeline script.
1) Add a name for the application into Anchore Enterprise which will be mapped to the source code repository.
2) Add an application version that will be associated as a source code artifact.
user@system:~# anchorectl application version add [email protected] ✔ Added version Version Name: v1.0.0ID: 1186e645-7309-499b-8ca1-82f557710152Application ID: 034b879d-5747-4deb-b29e-dc559d73fd03Created At: 2025-11-04T15:15:28ZLast Updated: 2025-11-04T15:15:28Z
3) Generate the SBOM from the source code repository, perform analysis, and import the resultant SBOM. The source code artifact association ([email protected]) is also being done during this step with the “–application” flag.
NOTE: The source code artifact comes into play with continuous integration to track the latest code changes for a given application version.
4) Check to make sure the source code repository is known to Anchore Enterprise and analysis has occurred.
user@system:~# anchorectl source list ✔ Fetched sources ┌──────────────────────────────────────┬────────────┬──────────────────────────────┬──────────┬─────────────────┬───────────────┐│ UUID │ HOST │ REPOSITORY │ REVISION │ ANALYSIS STATUS │ SOURCE STATUS │├──────────────────────────────────────┼────────────┼──────────────────────────────┼──────────┼─────────────────┼───────────────┤│ eeab0c4a-95c4-4d10-9b3c-e5b754693cdb │ github.com │ anchore/k8s-inventory/latest │ v1.0.0 │ analyzed │ active │└──────────────────────────────────────┴────────────┴──────────────────────────────┴──────────┴─────────────────┴───────────────┘
5) Check to make sure the source code artifact is known to Anchore Enterprise.
user@system:~# anchorectl application artifact list [email protected] ✔ List artifacts ┌─────────────────────────────────────────┬────────┬────────┐│ DESCRIPTION │ TYPE │ HASH │├─────────────────────────────────────────┼────────┼────────┤│ github.com/anchore/k8s-inventory/latest │ source │ v1.0.0 │└─────────────────────────────────────────┴────────┴────────┘
6) Although not a focal point for this post, the source code repository/artifact can also be verified via the Anchore Enterprise UI. Reference below documentation for further information on functionality via the UI.
Modern applications aren’t just your code. They’re a complex stack of dependencies, libraries, system packages, and runtime environments. Security at just one layer leaves gaps.
Anchore’s dual approach—SCA and secrets detection at the source level, comprehensive container scanning for built images—gives you visibility across the entire software supply chain. From a developer’s first commit to production runtime, you’re covered.
Organizations using this approach see 75-80% reductions in vulnerability management time and deploy 50-70% faster. More importantly, they ship secure software with confidence.
Container scanning protects against known vulnerabilities in dependencies. Source code scanning protects against the unknown vulnerabilities that attackers actually exploit. Source code scanning and container scanning aren’t competing strategies—they’re layers that work in tandem to provide the complete picture you need.
If you’ve been in the security universe for the last few decades, you’ve heard of the OWASP Top Ten. It’s a list of 10 security problems that we move around every year and never really solve. Oh sure, there are a few things we’ve made less bad, but fundamentally the list shows how our use of technology changes rather than a measure of solving problems.
I was talking with a friend long ago and I made a comment along the lines of “I don’t understand why OWASP doesn’t create an effort to eradicate whatever is number one on the list”. Their response was “OWASP is mostly consultants, they don’t want to solve these problems”. I am aware of the cynical nature of that answer, but it stopped me in my tracks for a moment. The Top Ten list gets a ton of attention, and if you look at the attention the current list is receiving, it’s less about solutions and more talking about how exciting a newly shuffled list is. A new Top Ten list is exciting, and it’s especially exciting when there’s a new entry on the list.
For the rest of this post, I’m going to focus on the new supply chain entry on the list. It’s number 3.
It’s worth starting out with the premise that there is no “Software Supply Chain”. Well there is, but I mean it’s not a term or concept you can just define. I could try to define it here, and every single reader will disagree because their definition is 1) Different, and 2) Better. A clever reader might be thinking right now we should probably define what this means. We probably should. The current definition is probably “supply chain is whatever I’m trying to sell”. Oh wait, I said I wasn’t going to define it. Too late.
So anyway, the point of this blog post is to set expectations on what happens after something lands on the OWASP Top Ten list. There will be a lot of people who proclaim all the exposure the Top Ten list generates is the solution. As we all know exposure is the most valuable currency, so I’m sure the list will drive plenty of exposure. But it should come as no surprise that just being on this list isn’t a solution.
The things on the OWASP Top Ten are systemic problems in our industry. We don’t solve systemic problems by buying a security tool. You can solve part of the problem sometimes, but the actual problem isn’t something any one company solves. Let’s pick apart the Software Supply Chain as a systemic issue in the industry.
What most people mean when they say Software Supply Chain is open source. They mean they are struggling with all the open source that runs all the software now. There are countless surveys and reports that declare all software is somewhere between 80% and 99% open source. What we’re really worried about is the Open Source Software Supply Chain.
Part of what makes this so hard is there isn’t a singular Open Source Software Supply Chain; open source is a collection of millions of projects and tens of millions of people. Nobody is in charge. There can be pockets of coordination where groups work together but even then there are at most thousands of those groups and still millions of things lacking coordination. This is a number larger than anyone can possibly comprehend, much less understand. You’d be wise to avoid anyone claiming to understand open source, they are basically a bigfoot expert who has never seen bigfoot.
So let’s rewrite the new OWASP item. It’s not “Software Supply Chain Failures”. It’s more accurate to say “Collection of random software I found in the couch cushions that I don’t understand and we don’t know where most of it comes from”. But didn’t I just say you can’t understand your open source software? I said, you can’t understand the nebulous cloud known as Open Source; but there are things they have in common. You can understand the specific open source software that you use…if you want to. And you should.
This is like claiming instead of building a structure that can withstand a hurricane if you buy my anti-hurricane product. That’s a silly premise. What we really need are buildings that are designed to withstand the weather in the place they are built. A hurricane isn’t a concern if you’re in Chicago, but it is a concern if you’re in Miami. Using open source software is a similar problem.
The problems you will see in the NPM ecosystem are not the same as the problems you will see in the PyPI ecosystem. There are some similarities, but there are also many differences. For example, NPM has a lot of very small packages designed to do one thing, so you end up with a huge explosion of dependencies. PyPI has less dependency explosion, but they often ship pre-built binary components. Two very different sets of challenges.
So what should a proper response to Software Supply Chain Failures look like? There isn’t a single answer, but there are ideas and groups that are on the right path. The Cyber Resilience Act in the EU seems to be a good start. There are supply chain efforts in foundations like the Linux Foundation and the Eclipse Foundation. But those efforts are less about technology and more about the people. The TL;DR of many efforts is really “know what you’re shipping”. It’s the first place to start.
It’s easy to be a cynic about anything happening in the security space. There is a lot of good happening, but we need to roll up our sleeves and do the work. Open source is a team sport. Ask your vendors how they are helping. Ask your developers which projects they are helping out. Ask all the people on LinkedIn posting about the supply chain how they are helping (posting opinions on LinkedIn doesn’t count as helping).
If your first reaction to this is “that sounds hard” and your second reaction is “I don’t know where to start”, that’s OK. It is hard and it’s not always obvious where to start. The first step is knowing what you have. I’m partial to using SBOMs to figure this out, but it’s not the only way. If the open source you’re using is 99% Python, that’s where you can start. The Python Software Foundation has a bunch of working groups. If you don’t see anything you like there, go check out the OpenSSF, or OWASP, or one of the countless Linux Foundation vertical groups.
You could reach out and see if some of the python packages you are using could use help. Maybe it’s money, maybe it’s patches, maybe it’s just hanging out with them and chatting about what’s happening. You can even ask me (or someone else you know in this universe), I love talking about this stuff and I’ll point you at someone smarter than me who can help you out. There’s no one right way to get involved.
The most important takeaway from all this is just because OWASP added software supply chain (open source) to the list, doesn’t mean it will magically solve itself. Supply chain security making the OWASP list changes nothing unless we make the change happen. The things that have fallen off the OWASP list did so because groups of dedicated people did a lot of work to improve the situation. We are the dedicated people, we have to fix this. The cavalry isn’t coming to save us, we are the cavalry.
The modern software supply chain is more complex and critical than ever. In an age of high-profile breaches and new global regulations like the EU’s Cyber Resilience Act, software supply chain security has escalated from an IT concern to a top-level business imperative for every organization. In this new landscape, transparency is foundational, and the Software Bill of Materials (SBOM) has emerged as the essential element for achieving that transparency and security.
Perhaps no single individual has been more central to the global adoption of SBOMs than Dr. Allan Friedman which only serves to increase our excitement to announce that Allan has joined Anchore as a Board Advisor.
A Shared Vision for a Secure Supply Chain
For years, Anchore has partnered with Allan to help build the SBOM community he first envisioned at NTIA and CISA. From active participation in his flagship “SBOM-a-Rama” events as an “SBOM-Solutions Showcase” to contributing to the Vulnerability Exploitability eXchange (VEX) standard.
Our VP of Security, Josh Bressers, has even taken over stewardship of Allan’s weekly SBOM community calls in a new form via the OpenSSF SBOM Coffee Club.
We’re thrilled to codify the partnership that has been built over many years with Allan and his vision for software supply chain security.
An In-Depth: A Conversation with Allan Friedman
We sat down with Allan to get his candid thoughts on the future of software supply chain security, the challenges that remain, and why he’s betting on Anchore.
You’ve been one of the primary architects of SBOM and software transparency policy at the federal level. What motivated you to join in the first place and what have you accomplished throughout your tenureship?
Security relies on innovation, but it also depends on collective action, building out a shared vision of solutions that we all need. My background is technical, but my PhD was actually on the economics of information security, and there are still some key areas where collective action by a community can make it easier and cheaper to do the right thing with respect to security.
Before tackling software supply chain security, I launched the first public-private effort in the US government on vulnerability disclosure, bringing together security researchers and product security teams, and another effort on IoT “patchability.”
I certainly wasn’t the first person to talk about SBOM, but we helped build a common space where experts from across the entire software world could come together to build out a shared vision of what SBOM could look like. Like most hard problems, it wasn’t just technical, or business, or policy, and we tried to address all those issues in parallel.
I also like to think we did so in a fashion that was more accessible than a lot of government efforts, building a real community and encouraging everyone to see each other as individuals. Dare I say it was fun? I mean, they let me run an international cybersecurity event called “SBOM-a-Rama.”
SBOM is a term that’s gone from a niche concept to a mainstream mandate. For organizations still struggling with adoption, what is the single most important piece of advice you can offer?
Even before we get to compliance, let’s talk about trust. Why would your customers believe in the security–or even the quality or value–of your products or processes if you can’t say with confidence what’s in the software? We also have safety in numbers now–this isn’t an unproven idea, and not only will peer organizations have SBOMs, your potential customers are going to start asking why you can’t do this if others can.
How do you see the regulatory environment developing in the US, Europe, or Asia as it relates to SBOMs over the next few years?
SBOM is becoming less of its own thing and more part of the healthy breakfast that is broader cybersecurity requirements and third party risk management. Over 2025, the national security community has made it clear that SBOM requirements are not just not fading away but are going to be front and center.
Organizations that trade globally should already be paying attention to the SBOM requirements in the European Union’s Cyber Resilience Act. The requirements are now truly global: Japan has been a leader in sharing SBOM guidance since 2020, Korea integrated SBOM into their national guidance, and India has introduced SBOM requirements into their financial regulations.
Beyond government requirements, supply chain transparency has been discussed in sector-specific requirements and guidance, including PCI-DSS, the automotive sector, and telecommunications equipment.
Now that we see the relative success of SBOMs, as you look three to five years down the road, what do you see as the next major focus area, or challenge, in securing the software supply chain that organizations should be preparing for today?
As SBOM has gone from a controversial idea to a standard part of business, we’re seeing pushes for greater transparency across the software-driven world, with a host of other BOMs.
Artificial intelligence systems should have transparency about their software, but also about their data, the underlying models, the provenance, and maybe even the underlying infrastructure. As quantum decryption shifts from “always five years away” to something we can imagine, we’ll need inventories of the encryption tools, libraries, and algorithms across complex systems.
It would be nice if we can have transparency into the “how” as well as the “what,” and secure attestation technologies are transitioning from research to accessible automation-friendly processes that real dev shops can implement.
And lastly, one of my new passions, software runs on hardware, and we are going to need to pay a lot more attention to where those chips are from and why they can be trusted: HBOM!
What do you hope to bring to the Anchore team and its strategy from your unique vantage point in government and policy?
I’m looking forward to working with the great Anchore team on a number of important topics. For their customers, how do we help them prioritize, and use SBOM as an excuse to level up on software quality, efficiency, and digital modernization.
We also need to help the global community, especially policy-makers, understand the importance of data quality and completeness, not just slapping an SBOM label on every pile of JSON handy. This can be further supported by standardization activities, where we can help lead on making sure we’re promoting quality specifications. VEX is another area where we can help facilitate conversations with existing and potential users to make sure its being adopted, and can fit into an automated tool chain.
And lastly, security doesn’t stop with the creation of SBOM data, and we can have huge improvements in security by working with cybersecurity tooling to make sure they understand SBOM data and can deliver value with better vulnerability management, asset management, and third party risk management tooling that organizations already use today.
Building the Future of Software Security, Together
We are incredibly excited about this partnership and what it means for our customers and the open-source community. With Allan’s guidance, Anchore is better positioned than ever to help every organization build trust in their software.To stay current on the progress that Allan Friedman and Anchore are making to secure the software industry’s supply chain, sign-up for the Anchore Newsletter.
Anchore Enterprise 5.23 adds CycloneDX VEX and VDR support, completing our vulnerability communication capabilities for software publishers who need to share accurate vulnerability context with customers. With OpenVEX support shipped in 5.22 and CycloneDX added now, teams can choose the format that fits their supply chain ecosystem while maintaining consistent vulnerability annotations across both standards.
This release includes:
CycloneDX VEX export for vulnerability annotations
CycloneDX VDR (Vulnerability Disclosure Report) for standardized vulnerability inventory
Expanded policy gates for one-time scans (see below for full list)
STIG profiles delivered via Anchore Data Service
The Publisher’s Dilemma: When Your Customers Find “Vulnerabilities” You’ve Already Fixed
Software publishers face a recurring challenge: customers scan your delivered software with their own tools and send back lists of vulnerabilities that your team already knows about, has mitigated, or that simply don’t apply to the deployed context. Security teams waste hours explaining the same fixes, architectural decisions, and false positives to each customer—time that could be spent on actual security improvements.
VEX (Vulnerability Exploitability eXchange) standards solve this by allowing publishers to document vulnerability status alongside scan data—whether a CVE was patched in your internal branch, affects a component you don’t use, or is scheduled for remediation in your next release. With two competing VEX formats—OpenVEX and CycloneDX VEX—publishers need to support both to reach their entire ecosystem. Anchore Enterprise 5.23 completes this picture.
How CycloneDX VEX Works in Anchore Enterprise
The vulnerability annotation workflow remains identical to the OpenVEX implementation introduced in 5.22. Teams can add annotations through either the UI or API, documenting whether vulnerabilities are:
Not applicable to the specific deployment context
Mitigated through compensating controls
Under investigation for remediation
Scheduled for fixes in upcoming releases
The difference is in the export. When you download the vulnerability report, you can now select CycloneDX VEX format instead of (or in addition to) OpenVEX. The annotation data translates cleanly to either standard, maintaining context and machine-readability.
Adding Annotations
Via UI: Navigate to the Vulnerability tab for any scanned image, select vulnerabilities requiring annotation, and choose Annotate to add status and context.
Via API: Use the /vulnerabilities/annotations endpoint to programmatically apply annotations during automated workflows.
Exporting CycloneDX VEX
After annotations are applied:
Navigate to the Vulnerability Report for your image
Click the Export button above the vulnerability table
In the export dialog, select CycloneDX VEX (JSON or XML format)
Download the machine-readable document for distribution
The exported CycloneDX VEX document includes all vulnerability findings with their associated annotations, PURL identifiers for precise package matching, and metadata about the scanned image. Customers can import this document into CycloneDX-compatible tools to automatically update their vulnerability databases with your authoritative assessments.
VDR: Standardized Vulnerability Disclosure
The Vulnerability Disclosure Report (VDR) provides a complete inventory of identified vulnerabilities in CycloneDX format, regardless of annotation status. Unlike previous raw exports, VDR adheres to the CycloneDX standard for vulnerability disclosure, making it easier for security teams and compliance auditors to process the data.
VDR serves different use cases than VEX:
VEX communicates vulnerability status (not applicable, mitigated, under investigation)
VDR provides comprehensive vulnerability inventory (all findings with available metadata)
Organizations can export both formats from the same Export dialog: VDR for complete vulnerability disclosure to auditors or security operations teams, and VEX for communicating remediation status to customers or downstream consumers.
To generate a VDR, click the Export button above the vulnerability table and select CycloneDX VDR (JSON or XML format). The resulting CycloneDX document includes vulnerability identifiers, severity ratings, affected packages with PURLs, and any available fix information.
Enforce Gates Policy Support for One-Time Scans
Anchore One-Time Scans now support eight additional policy gates beyond vulnerability checks, enabling comprehensive compliance evaluation directly in CI/CD pipelines without persistent SBOM storage. The newly supported gates include:
This expansion allows teams to enforce compliance requirements—NIST SSDF, CIS Benchmarks, FedRAMP controls—at build time through the API. Evaluate Dockerfile security practices, verify license compliance, check for exposed credentials, and validate package integrity before artifacts reach registries.
STIG profiles delivered via Anchore Data Service
STIG profiles are now delivered through Anchore Data Service, replacing the previous feed service architecture. DoD customers receive DISA STIG updates with the same enterprise-grade reliability as other vulnerability data, supporting both static container image evaluations and runtime Kubernetes assessments required for continuous ATO processes.
The combination means organizations can implement policy-as-code for both commercial compliance frameworks and DoD-specific requirements through a single, streamlined scanning workflow.
Get Started with 5.23
Existing Anchore Enterprise Customers:
Contact your account manager to upgrade to Anchore Enterprise 5.23
The EU’s Cyber Resilience Act (CRA) is fundamentally changing how we buy and build software. This isn’t just another regulation; it’s re-shaping the market landscape. We sat down with industry experts Andrew Katz (CEO, Orcro Limited & Head of Open Source, Bristows LLP), Leon Schwarz (Principal, GTC Law Group), and Josh Bressers (VP of Security, Anchore) to discuss how to best take advantage of and prepare for this coming change .
The key takeaway? You can either continue to view compliance as a “regulatory burden” or invert the narrative and frame it as a “competitive differentiator.” The panel revealed that market pressure is already outpacing regulation, and a verifiable, automated compliance process is the new standard for winning deals and proving your company’s value.
The “Compliance Cascade” is Coming
Long before a regulator knocks on your door, your biggest customer will. The new wave of regulations creates a shared responsibility that cascades down the entire supply chain.
As Leon Schwarz explained, “If you sell enough software… you’re going to find that your customers are going to start asking the same questions that all of these regulations are asking”. Andrew Katz noted that this responsibility is recursive: “[Your] responsibility will actually be for all components at all levels of the stack. You know, it doesn’t matter which turtle you’re sitting on” .
The panel made it clear: the “compliance cascade” is about to begin. Once one major enterprise in your supply chain takes the EU CRA seriously, they will contractually force that requirement onto every supplier they have. This is a fundamentally different pressure than traditional, internal audits.
EU CRA Compliance as Market Differentiator
During the discussion, Leon Schwarz described the real-world pressure this compliance cascade creates for suppliers. His “big fear is that during diligence, somebody’s going to come in and say, ‘You didn’t do the reasonable thing here. You didn’t do what everybody else is doing'”.
That fear is the sound of the market setting a new baseline. As the “compliance cascade” forces responsibility down the supply chain, “doing what everyone else is doing” becomes the new definition for what is “reasonable” compliance expectations during procurement. Any supplier who isn’t falling in line becomes the odd one out—a high-risk partner. You will be disqualified from contracts before you even get a chance to demonstrate your value.
But this creates a fundamental, short-term opportunity.
In the beginning, many vendors and suppliers won’t be compliant. Proactive, EU CRA-ready suppliers will be the exception. This is the moment to re-frame the challenge: compliance isn’t a hurdle to be cleared; it’s a competitive differentiator that wins you the deal.
Early adopters will partner with other suppliers who take this change seriously. By having a provable process, they will be the first to adapt to the new compliance landscape, giving them the ability to win business while their competitors are still scrambling to catch up.
A Good Process Increases Your Acquisition Valuation
This new standard of diligence impacts more than just sales; it will materially affect your company’s value during an M&A event.
As Andrew Katz explained, “An organization that’s got a well-run [compliance] process is actually going to be much more valuable; different than an organization where they have to retrofit the process after the transaction has closed”.
An acquirer isn’t just buying your product; they are also buying your access to markets. A company that needs compliance tacked-on has a massive, hidden liability, and the buyer will discount your valuation to compensate for the additional risk.
Leon Schwarz summed up the new gold standard for auditors and acquirers: “It’s not enough to have a policy. It’s not enough to have a process. You have to have materials that prove you follow it”. Your process is the “engine” that creates this continuous stream of evidence; an SBOM is just one piece of that evidence.
As Andrew Katz noted, an SBOM is “just a snapshot” , which is insufficient in a world of “continuous development”. But a process that generates SBOMs for every commit, build or artifact, creates a never ending stream of compliance evidence.
CompOps is How You Automate Trust
This new, continuous demand for proof requires a fundamentally different approach: CompOps (Compliance Operations).
With the EU CRA demanding SBOMs for every release and PCI-DSS 4 requiring scans every three months, compliance must become “part of our development and operations processes” . This is where CompOps, which borrows its “resilient and repeatable” principles from DevOps, becomes essential. It’s not about manual checks; it’s about building automated feedback loops.
Leon described this perfectly: “As developers figure out that if [they] use the things in this bucket of compliant components that their code is automatically checked in; those are the components they will default to”. That “bucket” is CompOps in action—an automated process that shapes developer behavior with a simple, positive incentive (a green checkmark) and generates auditable proof at the same time.
Are You Building a Speed Bump or a Navigation System?
The experts framed the ultimate choice: you can treat compliance as a “speed bump” that slows developers and creates friction. Or, you can build a “navigible system”.
A good CompOps process acts as that navigation, guiding developers to the path of least resistance that also happens to be the compliant path. This system makes development faster while automatically producing the evidence you need to win deals and prove your value.
This is a fundamentally different way of thinking about compliance, one that moves it from a cost center to a strategic asset.
This was just a fraction of the insights from this expert discussion. The full webinar covers how to handle deep-stack dependencies, specific license scenarios, and how to get buy-in from your leadership.
RepoFlow was created with a clear goal: to provide a simple package management alternative that just works without the need for teams to manage or maintain it. Many existing solutions required constant setup, tuning, and oversight. RepoFlow focused on removing that overhead entirely, letting organizations run a reliable system that stays out of the way.
As adoption grew, one request came up often: built-in vulnerability scanning.
When “Nice-to-Have” Became Non-Negotiable
Package management complexity has reached a breaking point. Developers context-switch between npm registries, container repositories, language-specific package systems, and artifact storage platforms. Each ecosystem brings its own interface, authentication model, and workflow patterns. Tomer Cohen founded RepoFlow in 2024 to collapse this fragmentation into a single, intuitive interface where platform teams could manage packages without cognitive overhead.
Early traction validated the approach. Development teams appreciated the consolidation. But procurement conversations kept hitting the same obstacle: “We can’t adopt this without vulnerability scanning.”
This wasn’t a feature request, it was a compliance requirement. Security scanning has become table stakes for developer tooling in 2025, not because it provides competitive differentiation, but because organizations can’t justify purchases without it. The regulatory landscape around software supply chain security, from NIST SSDF to emerging EU Cyber Resilience Act requirements, means security visibility isn’t optional anymore.
But here’s the problem that most tool builders fail to solve: security tools are notorious for adding back the complexity they’re meant to protect against. Slow scans block workflows. Heavy resource consumption degrades performance. Separate interfaces force context switching. Authentication complexity creates friction. For a product whose entire value proposition centered on reducing cognitive load, adding security capabilities meant walking a tightrope. Ship it wrong, and the product’s core promise evaporates.
RepoFlow needed vulnerability scanning that was fundamentally different from traditional security tooling; fast enough not to disrupt workflows, lightweight enough not to burden infrastructure, and integrated enough to avoid context switching.
The Solution: Grype and Syft to the Rescue
RepoFlow’s engineers started from a blank slate. Two options surfaced:
Build a custom scanner: maximum control, but months of work and constant feed maintenance.
Integrate an open source tool: faster delivery, but only if the tool met strict performance and reliability bars.
They needed something fast, reliable, and light enough to run alongside package operations. Anchore’s Grype checked every box.
Grype runs as a lightweight CLI directly inside RepoFlow. Scans trigger on demand, initiated by developers rather than background daemons. It handles multiple artifact types: containers, npm, Ruby gems, PHP packages, and Rust cargo crates, without consuming extra resources.
Under the hood, results flow through a concise pattern:
Generate SBOMs (Software Bills of Materials) with Syft.
Scan those SBOMs with Grype for known CVEs (Common Vulnerabilities and Exposures).
Parse the JSON output, deduplicate results, and store in RepoFlow’s database.
Surface findings in a new Security Scan tab, right beside existing package details.
Parallel execution and caching keep even large-image scans under a minute. The UI remains responsive; users never leave the page.
This looks straightforward, run a scan, show a table but the user experience determines whether developers embrace it or work around it.
Buy vs. Build (What the Evaluation Revealed)
RepoFlow benchmarked several approaches:
Criterion
Requirement
Why Grype Won
Speed
Must not introduce developer friction
Sub-minute scan times on standard containers
Reliability
Must work across languages
Consistent results across npm, Ruby, PHP, Rust
Resource use
Must be lightweight
Minimal CPU / memory impact
Maintainability
Must stay current
Active Anchore OSS community & frequent DB updates
During testing, RepoFlow opened a few GitHub issues around database sync behavior. The Anchore OSS team responded quickly, closing each one; an example of open source collaboration shortening the feedback loop from months to days.
The result: an integration that feels native, not bolted on.
The Payoff: Context Without Complexity
Developers now see vulnerabilities in the same pane where they manage packages. No new credentials, no separate dashboards, no waiting for background jobs to finish. Security became part of the workflow rather than a parallel audit.
Adoption followed. Enterprise prospects who had paused evaluations re-engaged. Support tickets dropped. Teams stopped exporting data between tools just to validate package risk.
Anchore’s open-source stack, Syft for SBOMs, Grype for vulnerability scanning, proved that open foundations can deliver enterprise-grade value without enterprise-grade overhead.
Getting Started
For RepoFlow Users
Vulnerability scanning is available in RepoFlow version 0.4.0 and later. The Security Scan tab appears in package detail views for all supported artifact types.
The Anchore OSS community maintains active discussions on integration patterns, configuration approaches, and implementation guidance. Contributing improvements and reporting issues benefits the entire ecosystem; just as RepoFlow’s database update feedback improved the tools for all users.
As an Associate Professor of Cybersecurity, I spend a lot of time thinking about risk, and increasingly, that risk lives within the software supply chain. The current industry focus on CVEs is a necessary, but ultimately insufficient, approach to securing modern, containerized applications.
Frankly, relying on basic vulnerability scanning alone is like putting a single padlock on a vault with an open back door, it gives a false sense of security. If we are serious about container security, we need to go beyond the patch-and-pray cycle and start enforcing comprehensive, deep inspection.
The Limitation of CVE-Only Scanning
The vast majority of container security tools trumpet their ability to find CVEs or remove all CVEs from base images. While identifying known vulnerabilities is crucial, it only addresses one facet of risk. What about the other, often more insidious, security pitfalls?
Misconfigurations: An application might have zero known vulnerabilities, but if a critical configuration file is improperly set (e.g., exposed ports, weak permissions), the image is fundamentally insecure.
Hidden Secrets: The accidental inclusion of API keys, SSH keys, or database credentials is a depressingly common issue. A CVE scanner won’t catch these, but a single leaked secret can lead to total environment compromise.
Supply Chain Integrity: Is a package allowed in your image? Are you using specific, approved base images? The presence of unauthorized or blacklisted packages introduces unknown, unvetted risk.
License and attestation: Do you care about licensing and their compliance? The presence of accurate license data and attestation ensures that all software components meet legal and organizational compliance standards, reducing risk and supporting secure, transparent supply chains.
I’ve seen first hand how a policy failure, not a zero-day, is often the weakest link. True security means moving from a reactive model of patching what’s known to a proactive model of enforcing what’s correct.
Deeper Analysis with Anchore
This is where a tool like Anchore becomes essential. Anchore shifts the focus from merely reporting CVEs to enforcing a robust security and compliance policy based on a complete understanding of the container image. It allows us to codify security expectations directly into the CI/CD pipeline.
Here’s how Anchore enables a deep inspection that goes far beyond the basic vulnerability database:
1. Configuration File Compliance
Anchore analyzes the actual contents and structure of configuration files within your image.
1. Configuration File Compliance
Anchore analyzes the actual contents and structure of configuration files within your image.
Example: You can enforce a policy that fails any image where the file /etc/ssh/sshd_config contains the line PermitRootLogin yes. This policy ensures that a critical security best practice is always followed, irrespective of any package’s CVE status.
Anchore Enterprise’s Policy Engine is configured to enforce these advanced security checks. Let’s explore how to do this:
Let’s add a policy to fail the build of any image where the file /etc/ssh/sshd_config contains the line PermitRootLogin yes.
To ensure configuration files comply with security best practices, you can use the retrieved_files policy gate. This gate allows Anchore to inspect the contents of files included in your image, enabling the detection of misconfigurations and other potential issues.
In the Gate dropdown menu, select retrieved_files.
Choose a Trigger.
Specify the file path (location of the files).
Enter the regex pattern you want to detect.
Finally, apply the new rule and save the updated policy.
2. Image Whitelists and Blacklists
Moving beyond just patching vulnerabilities, Anchore allows you to control the universe of components that make up your image.
Denylisting: Automatically fail an image if it contains an unapproved or deprecated package, such as an old version of python2 or a specific cryptomining library that slipped past a developer.
Allowlisting: Enforce that only packages from a specific, trusted vendor or build are permitted, ensuring that all components adhere to strict internal quality standards.
Anchore goes beyond traditional CVE scanning by giving teams precise control over what is and isn’t allowed in their container images, enabling proactive, policy-driven security that aligns with their organization’s unique compliance and quality standards.
3. Secret and Credential Detection
Perhaps the most critical “non-CVE” check is secret and credential scanning. Anchore uses the secret_scans gates to scan the entire filesystem of the container image for patterns matching sensitive data.
For example, using this gate allows you to set a rule that fails the image build if any file contains a string that looks like a high-entropy AWS Secret Key or a standard format SSH private key. This definitely goes beyond traditional CVE scanning and prevents catastrophic credential leakage before the image ever hits a registry.
For comprehensive software supply chain hygiene, Anchore also allows policies around component licensing, ensuring you meet legal and compliance obligations for open source usage. You can also enforce build-time attestation, ensuring the image was built by an approved CI/CD system and hasn’t been tampered with.
Example: Enforcing License Denylists
A critical part of software supply chain policy is preventing the accidental use of components licensed under specific, undesirable terms. Anchore uses the License Gate and its corresponding License Trigger to check for the presence of any license you want to deny.
Let’s say your organization must block all strong copyleft licenses, such as the GNU General Public License v2.0-only (GPL-2.0-only), because it requires derivative works (like your final application) to also be published under the GPL.
How Anchore Enforces This:
Detection: Anchore scans the image and identifies every package and file licensed under GPL-2.0-only.
Policy Rule: A rule is configured in the policy to target the license trigger and set the action to STOP if GPL-2.0-only is detected in any installed package.
Conclusion: Dive Deep with Anchore Enterprise
As cybersecurity professionals, we must champion the shift from reactive vulnerability management to proactive policy enforcement.
A CVE score tells you about known weaknesses. Deep container analysis with Anchore Enterprise tells you whether the image adheres to your organization’s definition of secure and compliant.
The software supply chain is where the next major cybersecurity battles will be fought. By implementing deep inspection policies now, we can move beyond the CVE and build a truly resilient, defensible container infrastructure. We simply can’t afford to do less.
Anchore Enterprise 5.22 introduces three capabilities designed to make vulnerability management clearer, cleaner, and more trustworthy:
VEX annotations with OpenVEX export
PURLs by default, and
RHEL Extended Update Support (EUS) indicators.
Each of these features adds context and precision to vulnerability data—helping teams reduce noise, speed triage, and strengthen communication across the supply chain.
Security teams are flooded with vulnerability alerts that lack actionable context. A single CVE may appear in thousands of scans—even if it’s already fixed, mitigated, or irrelevant to the deployed package. The emerging VEX (Vulnerability Exploitability eXchange) standards aim to fix that by allowing publishers to communicate the status of vulnerabilities alongside scan data.
Anchore Enterprise 5.22 builds on this movement with better data hygiene and interoperability: improving how vulnerabilities are described (via annotations), identified (via PURLs), and evaluated (via RHEL EUS awareness).
VEX Annotations and OpenVEX Support
Anchore Enterprise users can now add annotations to individual vulnerabilities on an image—via either the API or the UI—to record their status with additional context. These annotated findings can be exported as an OpenVEX document, enabling teams to share accurate vulnerability states with downstream consumers.
When customers scan your software using their own tools, they may flag vulnerabilities that your team already understands or has mitigated. Annotations let publishers include authoritative explanations—such as “not applicable,” “patched in internal branch,” or “mitigated via configuration.” Exporting this context in OpenVEX, a widely recognized standard, prevents repetitive triage cycles and improves trust across the supply chain.
(CycloneDX VEX support is coming next, ensuring full compatibility with both major standards.)
The annotation workflow supports multiple status indicators that align with VEX standards, allowing teams to document whether vulnerabilities are:
Not applicable to the specific deployment context
Mitigated through compensating controls
Under investigation for remediation
Scheduled for fixes in upcoming releases
Once annotations are applied to an image, users can download the complete vulnerability list with all contextual annotations in OpenVEX format—a standardized, machine-readable structure that security tools can consume automatically. Read the docs →
PURLs by Default
All Anchore Enterprise APIs now return Package URLs (PURLs) by default for software components where one exists. A PURL provides a canonical, standardized identity for a package—combining its ecosystem, name, and version into a single unambiguous reference.
Unlike older CPE identifiers, PURLs precisely map vulnerabilities to the correct package—even when names or versions overlap across ecosystems. This precision improves downstream workflows such as VEX annotations, ensuring that vulnerability status is attached only to the intended software component, not an entire family of similarly named packages. This leads to more reliable matching, fewer false correlations, and a cleaner chain of evidence in SBOM and VEX exchanges.
For packages without ecosystem-specific PURLs, Anchore Enterprise continues to provide alternative identifiers while working toward comprehensive PURL coverage.
PURLs + VEX Workflows
PURLs significantly improve the precision of VEX annotations. When documenting that a vulnerability is not applicable or has been mitigated, the PURL ensures the annotation applies to exactly the intended package—not a range of similarly-named packages across different ecosystems.
This precision prevents misapplication of vulnerability status when:
Multiple ecosystems contain packages with identical names
Different versions exist across a software portfolio
Vulnerability annotations need to be narrowly scoped
Automated tools process VEX documents
For organizations distributing software to customers with their own security scanning tools, PURLs provide the unambiguous identifiers necessary for reliable vulnerability communication.
RHEL EUS Indicators
Anchore Enterprise now detects and flags RHEL Extended Update Support (EUS) content in container images, applying the correct EUS vulnerability data automatically.
RHEL EUS subscribers receive backported fixes for longer lifecycles than standard RHEL releases. Without this visibility, scanners can misclassify vulnerabilities—either missing patches or reporting false positives. The new EUS indicators verify that vulnerability assessments are based on the right lifecycle data, ensuring consistent and accurate reporting.
If an image is based on an EUS branch (e.g., RHEL 8.8 EUS), Anchore now displays that context directly in the vulnerability report, confirming that all findings use EUS-aware data feeds.
Add annotations: via UI (Vulnerability tab → Annotate) or API (/vulnerabilities/annotations).
Export OpenVEX: from the Vulnerability Report interface or CLI to share with partners.
Check EUS status: in the Vulnerability Report summary—look for “EUS Detected.”
Integrate PURLs: via API or SBOM exports for precise package mapping.
Ready to Upgrade?
Anchore Enterprise 5.22 delivers the vulnerability communication and software identification capabilities that modern software distribution requires. The combination of OpenVEX support, PURL integration, and RHEL EUS detection enables teams to manage vulnerability workflows with precision while reducing noise in security communications.
Existing customers: Contact your account manager to upgrade to Anchore Enterprise 5.22 and begin leveraging OpenVEX annotations, PURL identifiers, and EUS detection.
Technical guidance: Visit our documentation site for detailed configuration and implementation instructions.
New to Anchore?Request a demo to see these features in action.
Learn the 5 best practices for container security and how SBOMs play a pivotal role in securing your software supply chain.
It’s starting to feel like 2025 is going to be the year of IT compliance. We hear about new regulations like the CRA, PLD, DORA, SSDF; as well as, updates to standards like FDA, PCI-DSS, and SSDF. If you’re a compliance nerd this has been an absolutely wild year. It seems like there’s a new compliance standard or update happening every other week. Why this is happening right now is a hotly contested topic. There’s no single reason we’re seeing compliance becoming more important than it’s ever been in the world of IT. But no matter the reason, and no matter if you think this is good or bad, it’s the new normal.
It should also be noted that IT isn’t special. It’s easy to claim IT isn’t comparable to other industries for many reasons; we move very fast and we don’t usually deal with physical goods. Many other industries have had regulations for tens or even hundreds of years. We can think of food safety or automobile safety as easy examples where regulations and compliance are a major driving force. If anything this shows us that IT is becoming a mature industry, just like all those other regulated spaces.
There’s a new term being used I find delightful. CompOps. Think DevOps, but with compliance—basically Compliance Operations. If you wanted to get silly we could make up something like DevCompSecOps. We like to put words in front of Ops to claim it’s a new way of doing something. In this particular instance, CompOps, there might actually be a new way of doing things. Having to conform to compliance standards is something the world of IT hasn’t really had to do at scale before. There’s no way we can comply with these standards without making some changes, so the term CompOps helps show that something is different.
When we think of how compliance in IT used to work, the first thing that comes to mind would be the annual audit. Once a year an auditor would come around and ask for a bunch of evidence. Everyone would make sure all the patches were installed, and user accounts cleaned up. Make sure the logging server was working and all that awareness training was finished. The auditor would collect their evidence, and assuming everything checked out, you were off the hook for another year!
And it’s not just about scanning, it also has to be shown that findings were resolved. This new way of adhering to a compliance standard on a constant basis will need a new process. The ideas behind CompOps is a new process. Rather than keeping your compliance staff hidden away in a dark basement until the once a year you need them, they are going to be present for everything now. We will all need guidance to ensure things are done right at the start, but also things are kept right all the time.
So how do we do this CompOps thing?
Let’s start with the difficult reality that your security budget is likely already fueled by compliance requirements. Security teams have always struggled to show business value, this has been a problem since the beginning of security. How do you prove you’re the reason something didn’t happen? When security teams do their jobs, the result is nothing. “Nothing” can’t be measured. It’s pretty easy to measure when things go wrong, but very hard to measure when things go right.
However, we can measure compliance requirements. If we can’t do business in a certain jurisdiction, or can’t take credit cards, or can’t process customer data, that’s easy to explain. If we meet these requirements, the rest of the business can do their thing. If we don’t meet those requirements everything grinds to a halt. That’s an easy story to tell. So make sure you tell it.
Security teams love to be in charge. There’s nothing more exciting than showing up and declaring everything is going to be fine because security is here! If you do this when trying to build out a compliance program you just lost before you started. It’s likely your existing development and operations teams are doing a subset of the things you’re going to need in this new compliance focused world. The only real difference might be you have to continuously collect evidence now.
Speaking of continuously collecting evidence. When you have a process you do once a year, you can sort of just wing it and deal with whatever bumps in the road show up along the way. Once a year isn’t all that often so it’s easy to justify manual effort. When you have to do something every month, or every week, or every day, the rules all change. Now we go from justifying a few extra hours of manual effort to an unacceptable amount of effort needed every single day.
The world of CompOps means we have to architect how we are going to meet our compliance requirements. It’s a lot like building software, or deploying infrastructure, except in this case it’s meeting your compliance requirements. The DevOps crowd has a lot they can teach here. DevOps is all about making systems resilient and repeatable. The exact sort of thing we’re going to need!
It’s probably better to think of all this like a product manager more than a security or compliance team. Your DevOps folks know how to architect solutions based on a set of requirements. If we think of a compliance standard as a set of detailed requirements, we can translate those requirements into something the DevOps team already knows how to handle. This whole CompOps world is going to be all about communication and cooperation.
The road ahead
For many of us, all these new compliance standards are a welcome change, but it’s also a future filled with hard work and difficult problems. Change is always hard, and this will be no exception. While many of us are familiar with meeting compliance standards, the future of compliance won’t look like the past. It’s time to implement compliance programs that are not only continuous, but are part of our development and operations processes. For an experienced DevOps team these will all be very solvable problems, assuming we communicate clearly and work with them as a trusted partner.
In a few years we won’t be talking about CompOps anymore because it will just be part of the existing DevOps process. Our job for the next year or two will be figuring out how to normalize all these new requirements. If we don’t listen to our DevOps experts, none of this is going to be smooth and painless. They can teach us a lot, make sure you listen to them. Because if we do our job right, nothing will happen.
When I woke up the morning of September 8, I didn’t have the foggiest idea what the day had prepared for me. The most terrifying part of being a security person is the first few minutes of your day when you check the dashboards.
By mid-morning the now infamous blog post from Aikido Security about compromised NPM packages had found its way into Anchore’s Slack. My immediate response? Immediate panic, followed by relief when the scan of Anchore systems came back with the answer that we weren’t impacted.
We wanted to write this blog post to give the broader community a peek behind the curtains at what a zero-day vulnerability disclosure looks like from the perspective of the vendors who help customers protect their users from supply chain attacks. Spoiler: we’re just normal people making reasonable decisions while under pressure.
Let’s walk through what actually happened behind the scenes at Anchore.
The first ten minutes: actions > root cause
When I first read the Aikido post, I didn’t care about the technical details of how the attack happened or the fascinating social engineering tactics. I wanted one thing: the list of affected packages. Something actionable.
The list was originally buried at the bottom of their blog post, which meant those first few minutes involved a lot of scrolling and muttering. But once we had it, everything clicked into place. This is lesson number one when a zero-day disclosure hits: get to the actionable information as fast as possible. Skip the drama, find the indicators, and start checking.
Step one: are we affected?
At Anchore, we dogfood our own products constantly (the Anchore Enterprise instance is literally named “dogfood”). On any given day, it’s somewhere between number two and three on my daily TODO list. On this day, I pulled up the latest build of Anchore Enterprise, and got to work.
First check: our latest releases. Our latest release was from the Friday before this all happened, so the timing meant the malicious packages couldn’t have made it into our most recent release. That’s good news, but it’s just the start.
Next check: the development versions of Anchore Enterprise. We pulled up our SBOMs and started looking. No malicious packages as direct dependencies—that’s a relief. But we did have some of the targeted packages as transitive dependencies! Luckily the packages we had inherited were not the malicious versions. Our dependency management had kept us safe, but we needed to verify this everywhere.
Then we checked with the UI team. Did anyone have these packages installed in their development environments? Did anything make it into CI? Nope, everything checked out.
GitHub Actions workflows were next. Sometimes we have opportunistic dependencies that get pulled during builds. Some of the packages were there, but not the vulnerable versions.
This whole process took maybe twenty minutes. Twenty minutes to check our current state across multiple products and teams. That’s only possible because we generate and store SBOMs for every build and create the tools to search through the growing inventory efficiently. We have stored SBOMs for every nightly and release of Anchore Enterprise. I can search them all very quickly.
Step two: the historical question
Now that we have confirmed that our infrastructure isn’t breached, the next question to answer is “has Anchore ever had any of these malicious packages?” Not just today, but at any point in our history. Granted the history was really just a few days in this instance, but you can imagine a situation like Log4Shell where there were years of history to wade through.
We have 1,571 containers in our build history. If we had to manually check each one, we’d still be working on it. But because we maintain a historical inventory of SBOMs in our database for all of our container builds, this became a simple query. A few seconds later: nothing found across our entire history.
These are the kinds of questions that keep me up at night during incidents: “Are we affected now?” is important, but “were we ever affected?” can be just as critical. Imagine discovering three months later that you shipped a compromised package to customers. The blast radius of that is enormous.
Having historical tracking isn’t fancy or sexy. It’s just good operational hygiene. And in moments like this, it means the difference between answering “I don’t know” and “we’re good.”
Step three: can we protect our customers?
Okay, so Anchore is clean. Great. But we sell the security tools that automate this kind of incident response—our customers are depending on us to help them figure out if they’re affected and detect these malicious packages.
Early in the incident, the GitHub Advisory Database made an understandable but problematic decision: they set the affected versions of these packages to 0, which meant all versions would be flagged as vulnerable. This potentially created mass confusion for users who rely on the GHSA DB for vulnerability results. If anyone ran a vulnerability scan with this version of the GHSA DB their scanners would have lit up like Christmas trees, flagging packages that were known to be good.
In order to protect our customers from this panic inducing possibility we made the call: stop our vulnerability database build. We’d never tried to kill a build mid-process before, but this was one of those “figure it out as we go” moments. We stopped the build, then went to make pull requests to the GitHub Advisory Database to fix the version ranges.
By the time we got there, the GitHub team had already found the issue and a fix was in-flight. This is how the open source community works when everything is going right—multiple teams identifying the same problem and coordinating to fix it.
As soon as GitHub pushed their fix, we rebuilt our vulnerability database and messaged our customers. The goal was simple: make sure our customers had accurate information and could trust their scans. From detection to customer notification happened in hours, not days.
Why is GitHub in this story?
I want to make an important point about why the GitHub Vulnerability Database is an important part of this story. At Anchore, we have an open source vulnerability scanner called Grype. In order for Grype to work, we need vulnerability data that’s available to the public. Most vulnerability data companies don’t let you publish their data to the public, for free, for some reason.
GitHub is an important source of vulnerability data for both Anchore Enterprise and Grype. We have a number of vulnerability data sources and we do quite a lot of work on our own to polish up data without a robust source. Rather than pull in GitHub’s data and treat it like our own, we take the open source approach of working with our upstream. Anytime there are corrections needed in any of our upstream data, we go to the source with the fixes. This helps the entire community with accuracy of data. Open source only works when you get involved. So we are involved.
What actually matters during a zero-day
Looking back at this incident, a few lessons stand out about what actually matters when something like this hits:
Get to actionable information fast. The technical details are interesting for a blog post later, but when you’re responding, you need indicators. Package names. Version numbers. Hashes. Don’t get distracted by the story until you’ve handled the response.
Check yourself first, but don’t stop there. We needed to know if Anchore was affected, but we couldn’t stop at “we’re fine.” Our customers depend on us to help them figure out their exposure.
Historical tracking matters. Being able to answer “were we ever affected?” is just as important as “are we affected now?” If you don’t have historical SBOMs, you can’t answer that question with confidence.
Speed matters, but accuracy matters more. When the GitHub Advisory Database incorrectly flagged all versions, it could have created chaos. We could have pushed that bad data to customers quickly, but we stopped, verified, and waited for the fix. A fast response is important, but an accurate response is what actually helps.
Automation is your friend. Twenty minutes to check 1,571 historical containers? That only happens with automation. Manual verification would have taken days or weeks.
The NPM community’s response was impressive
Here’s something that deserves more attention: NPM pulled the malicious packages in approximately six hours. Six hours from compromise to resolution. We only have to think back to 2021 when Log4j was disclosed and the industry was still responding to the incident weeks and even months later.
This wasn’t one company with a massive security team solving the problem. This was the open source community working together. Information was shared. Multiple organizations contributed. The response was faster than any single company could have managed, no matter how large their security team.
The attackers successfully phished more than one maintainer and bypassed 2FA (clearly not phishing-resistant 2FA, but that’s a conversation for another post). This was a sophisticated attack. And the community still went from compromised to clean in six hours.
That’s remarkable, and it’s only possible because the supply chain security ecosystem has matured significantly over the last few years.
How this compares to Log4Shell
This whole process reminded me of our response to Log4Shell in December 2021. We followed essentially the same playbook: check if we’re affected, verify our detection works, inform customers, help them respond.
During Log4Shell, we discovered Anchore had some instances of Log4j, but they weren’t exploitable. We created a test Java jar container (we called it “jarjar“) to verify our scanning could detect it. We helped customers scan their historical SBOMs to determine if and when Log4j appeared in their infrastructure, this provided their threat response teams with the information to bound their investigation and clearly define their risk.
But here’s the critical difference: Log4Shell response was measured in days and weeks. This NPM incident was measured in hours. The attack surface was arguably larger—these are extremely popular NPM packages with millions of weekly downloads. But the response time was dramatically faster.
That improvement represents years of investment in better tools, better processes, and better collaboration across the industry. It’s why Anchore has been building exactly these capabilities—historical SBOM tracking, rapid vulnerability detection, automated response workflows. Not for hypothetical scenarios, but for moments exactly like this.
What this means for you
This NPM incident is hopefully over for all of us (good luck if you’re still working on it). It’s probably worth thinking about what you can do for the next one. My advice would be to start keeping an inventory of your software if you’re not already. I’m partial to SBOMs of course. There will be more supply chain attacks in the future, they will need a quick response. The gap between “we checked everything in twenty minutes” and “we’re still trying to figure out what we have” represents real business risk. That gap is also entirely preventable.
Supply chain attacks aren’t theoretical. They’re happening regularly, they’re getting more sophisticated, and they will keep happening. The only question is whether you’re prepared to respond fast.
The tools exist
At Anchore, we built Syft and Grype specifically for these scenarios. Syft generates SBOMs that give you a complete inventory of your software. Grype scans for vulnerabilities. These are free, open source tools that anyone can use.
For organizations that need historical SBOM tracking, policy enforcement, and compliance reporting, Anchore Enterprise provides those capabilities. This isn’t a sales pitch—these are the actual tools we used during this incident to verify our own exposure and help our customers.
None of this is magic. It’s just normal people making normal decisions about how to prepare for predictable problems. Supply chain attacks are predictable. The question is whether you’ll be ready when the next one hits.
What’s next
Here’s what I expect: more supply chain attacks, more sophisticated techniques, and continued pressure on open source maintainers. But I also expect continued improvement in response times as the ecosystem matures.
Six hours from compromise to resolution is impressive, but I bet we can do better. As more organizations adopt SBOMs, vulnerability scanning, and historical tracking, the collective response will get even faster.
The question for your organization is simple: when the next incident happens—and it will—will you spend twenty minutes verifying you’re clean, or will you spend weeks trying to figure out what you have?
The best time to prepare for a supply chain attack was 10 years ago. The second best time is now.If you want to talk about how to actually implement this stuff—not in theory, but in practice—reach out to our team. Or join the conversation on our community Discourse where we talk about exactly these kinds of incidents and how to prepare for them.
October is Cybersecurity Awareness Month, an idea that’s more than 20 years old now. It’s an idea that had its day, it’s time to re-think the intended purpose. Cybersecurity is ever present now; Cybersecurity Awareness Month shouldn’t exist anymore. The modern purpose of Cybersecurity Awareness Month seems to be mostly for security people to make fun of Cybersecurity Awareness Month.
Let’s start with some history
Cybersecurity awareness month started in 2004. Back in 2004 things were VERY different. 2004 saw a bit more than 2,000 CVE IDs (we’re going to see more than 45,000 by the time 2025 ends). Windows XP SP2 was released in 2004. Many of the news stories I dug up were wondering how close we were to ending spam—how quaint. That’s not a world any of us can recognize anymore. Back in 2004 we would have contests to see who could keep a computer running the longest without rebooting (or applying security updates … or any updates). I could go on, but you get the point. It may have been 20 calendar years, but in tech that feels like 200 years. If any of us traveled back to 2004 we wouldn’t know how anything works, and if someone from 2004 showed up today, they wouldn’t be able to make anything work either.
Cybersecurity awareness month probably made sense back in 2004. It was a brand new problem. This whole internet thing was catching on. We were suddenly using computers to mail DVDs to our homes, check our account balances (instead of an ATM) and to frustrate our family doctors after consulting WebMD.
It’s no surprise that as humanity began its online journey there would be a whole new group of criminals looking for opportunity. Nobody understood that using the same password everywhere was a bad idea, or that you should install those security updates quickly, or that the email you got about winning the lottery wasn’t real. Having a month where everyone was trying to draw attention to what’s happening probably made sense. It’s hard to spread new ideas, using a gimmick is a great way to get attention.
If we fast forward to 2025, a dedicated month for cybersecurity awareness doesn’t make sense anymore. It would also be a mistake to say “every month is cybersecurity awareness month”. Security awareness also isn’t everyone’s problem. Awareness is part of every security team, it has to be. Things change faster than anyone can possibly keep up with.
Keeping people informed about security is something that happens all the time as needs arise. We can probably use compliance as a good example here. Remember when we only worried about compliance once a year when the auditor was coming to town? That’s not how it works anymore, many of the compliance standards have requirements to collect evidence all year long, not once the night before it’s due. If there’s a new SMS spam attack happening against your company, you’re not going to take a note to cover it next October, you’re going to reach out to everyone right now!
Cybersecurity awareness isn’t a point in time or a single event. It’s honestly not really even about only awareness. It’s all about building trust with whoever the people are you are there to help out. It has to be woven into constant communications about whatever matters right now. You can’t build trust once a year, trust happens through consistent communication and also positive behavior. It’s critical that the people security teams are meant to be protecting aren’t afraid to ask questions or report suspicious activities. Even if those suspicious activities were caused by something they did.
Security teams used to be all about blame. Who is to blame? Anything bad that happened was the fault of someone. We also complained constantly about how little all the other teams cared about security, or how they didn’t seem to like us very much. There are still plenty of security teams that try to assign blame, but it’s not the default anymore, at least not the good teams. Good security teams are now all about being a trusted partner. You aren’t automatically a trusted partner, you have to earn it every day. We don’t need a special month, if anything a special month might detract from a program that’s trying to build trust.
When October rolls around the only thing that you should change is maybe some extra memes making fun of awareness month.
If you’re a security team, planning security focused communications can and should happen all year long. Make sure you understand who you’re working with and why. If you’re not sure your partners trust you, they probably don’t.
October is also National Pizza Month, you can start building trust by buying everyone some pizza. Security will probably never be as loved as pizza, but we can at least try!
Explore SBOM use-cases for almost any department of the enterprise and learn how to unlock enterprise value to make the most of your software supply chain.
SANTA BARBARA, CA – October 9, 2025 – Anchore, a leading provider of software supply chain security solutions, today announced that it has achieved “Awardable” status through the Platform One (P1) Solutions Marketplace.
The P1 Solutions Marketplace is a digital repository of post-competition, 5-minute long readily-awardable pitch videos, which address the Government’s greatest requirements in hardware, software and service solutions.
Anchore’s solutions are designed to secure the software supply chain through comprehensive SBOM generation, vulnerability scanning, and compliance automation. They are used by a wide range of businesses, including Fortune 500 companies, government agencies, and organizations across defense, healthcare, financial services, and technology sectors.
“We’re honored to achieve Awardable status in the P1 Solutions Marketplace,” said Tim Zeller, Senior Vice President of Sales and Strategic Partnerships at Anchore. “Nation-state actors and advanced persistent threats are actively targeting the open source supply chain to infiltrate Department of Defense infrastructure. Our recognition in the P1 marketplace demonstrates that Anchore’s approach—combining open source tools like Syft and Grype with enterprise-grade solutions—can help defense organizations detect and defend against these sophisticated supply chain attacks at scale.”
Anchore’s video, “Secure Your Software Supply Chain with Anchore Enterprise,” accessible only by government customers on the P1 Solutions Marketplace, presents an actual use case in which the company demonstrates automated SBOM generation, vulnerability detection, and compliance monitoring across containerized and traditional software deployments. Anchore was recognized among a competitive field of applicants to the P1 Solutions Marketplace whose solutions demonstrated innovation, scalability, and potential impact on DoD missions. Government customers interested in viewing the video solution can create a P1 Solutions Marketplace account at https://p1-marketplace.com/.
We’re excited to share a new case study highlighting how Sabel Systems transformed their security review process while scaling their Code Foundry platform to support Department of Defense (DoD) missions.
Sabel Systems provides managed DevSecOps pipeline-as-a-service for DoD contractors developing mission-critical vehicle systems. With a lean team of 10 supporting over 100 developers across hundreds of applications, they faced a critical challenge: their manual vulnerability review process couldn’t keep pace with growth.
⏱️ Can’t wait till the end? 📥 Download the case study now 👇👇👇
The Challenge: Security Reviews That Couldn’t Scale
When you’re providing platform-as-a-service for DoD vehicle systems, security isn’t optional—it’s mission-critical. But Sabel Systems was facing a bottleneck that threatened their ability to serve their growing customer base.
Their security team spent 1-2 weeks manually reviewing vulnerabilities for each new build of Code Foundry. As Robert McKay, Digital Solutions Architect at Sabel Systems, explains: “We’d have to first build the actual software on the image and then go through all the different connection points and dependencies.”
This wasn’t just slow—it was unsustainable. Code Foundry serves Army, Air Force, and Navy contractors who need to achieve Authority to Operate (ATO) for their systems. These customers operate in IL5 (controlled unclassified) environments on NIPR networks, with strict requirements for zero critical vulnerabilities. The manual process meant delayed deliveries and limited capacity for growth.
Adding to the complexity, Code Foundry is designed to be cloud-agnostic and CI/CD-agnostic, deploying across different DoD-approved cloud providers and integrating with various version control systems (GitLab, Bitbucket, GitHub) and CI/CD tools (GitLab CI, Jenkins). Any security solution would need to work seamlessly across this diverse technical landscape—all while running in air-gapped, government-controlled environments.
The Solution: Automated Security at DoD Scale
Sabel Systems selected Anchore Enterprise to automate their vulnerability management without compromising their strict security standards. The results speak for themselves: vulnerability review time dropped from 1-2 weeks to just 3 days—a 75% reduction that enabled the same 10-person team to support exponentially more applications.
Here’s what made the difference:
Automated scanning integrated directly into CI/CD pipelines. Anchore Enterprise scans every container image immediately after build, providing instant feedback on security posture. Rather than security reviews becoming a bottleneck, they now happen seamlessly in the background while developers continue working.
On-premises deployment built for DoD requirements. Anchore Enterprise runs entirely within government-approved infrastructure, meeting IL5 compliance requirements. Pre-built policy packs for FedRAMP, NIST, and STIG frameworks enable automated compliance checking—no external connectivity required.
API-first architecture that works anywhere. Deploying via Helm charts into Kubernetes clusters, Anchore Enterprise integrates with whatever CI/CD stack each military branch prefers. Sabel Systems embedded AnchoreCTL directly into their pipeline images, keeping all connections within the cluster without requiring SSH access to running pods.
Perhaps most importantly for DoD work, Anchore Enterprise enables real-time transparency for government auditors. Instead of waiting weeks for static compliance reports, reviewers access live security dashboards showing the current state of all applications.
As Joe Bem, Senior Manager at Sabel Systems, notes: “The idea is that you can replace your static contract deliverables with dynamic ones—doing review meetings based on live data instead of ‘here’s my written report that took me a week to write up on what we found last week,’ and by the time the government gets it, it’s now 2-3 weeks old.”
Results: Security That Enables Growth
The implementation of Anchore Enterprise transformed how Code Foundry operates:
75% faster vulnerability reviews allowed the security team to scale without adding headcount
Zero critical vulnerabilities maintained across 100+ applications in multiple IL5 environments
Real-time audit transparency replaced weeks-old static reports with live compliance dashboards
Faster ATO processes for DoD contractors through proactive security feedback
This isn’t just about efficiency—it’s about enabling Sabel Systems to serve more DoD missions without compromising security standards. Rather than security reviews constraining business growth, they now happen seamlessly as part of the development workflow.
Learn More
The full case study dives deeper into the technical architecture, specific compliance requirements, and implementation details that enabled these results. Whether you’re supporting defense contractors, operating in regulated environments, or simply looking to scale your security operations, Sabel Systems’ experience offers valuable insights.
If you pay attention to the world of AI, you’ll have noticed that Model Context Protocol (MCP) is a very popular topic right now. The Model Context Protocol is an open standard that enables developers to build secure, two-way connections between their data sources and AI-powered tools. The architecture is straightforward: developers can either expose their data through MCP servers or build AI applications (MCP clients) that connect to these servers.
Because MCP is so popular it seemed like a great topic to do some security research with. I decided to review the top 161 MCP servers currently listed on the Docker hub, generate SBOMs for each container then run a vulnerability scan to see what the current state of that software is.
The list of the MCP server I used can be found on Docker Hub at https://hub.docker.com/mcp. The tools I am using are explained further down.
Explore SBOM use-cases for almost any department of the enterprise and learn how to unlock enterprise value to make the most of your software supply chain.
Step by step vulnerability analysis of 161 MCP servers
As a first step I pulled all the container images then I used our OSS Syft scanner to generate SBOMs for each image. When Syft scans a container it catalogs all the packages and files contained in a container image. Those SBOMs were then scanned with our OSS vulnerability scanner Grype . All scan results, SBOMs and vulnerabilities were put into Elasticsearch. I enjoy using Elasticsearch as it makes it very easy to make graphs of the data and understand what’s happening.
Keep in mind, these results are the output of Syft and Grype; if there is a bug in one of them, or they cannot detect a certain package type, that will cause a hole in the data. These results shouldn’t be treated as 100% accurate, but we can derive observations, trends, and patterns based on this data set.
How bad is it? TL;DR: It’s pretty bad.
In 161 containers, Grype found exactly 9000 vulnerabilities. The number is certainly larger now. Vulnerabilities are a point in time snapshot, it was 9000 when the scan was run in early September 2025. As time moves forward, more vulnerabilities will be uncovered. CVE is adding around 4000 new vulnerabilities per month, some of which will affect a subset of the software in these MCP containers.
Let’s start with the top 10 containers by vulnerability count.
We should dig deeper into the top image as there’s more happening than the raw numbers would suggest. What if we look at the number of vulnerabilities based on the type of package for that image?
This image is based on Debian 12 specifically, which isn’t particularly old. If we take a closer look, we see 429 Debian packages installed, 51 python modules, and 13 unpackaged binaries. 429 packages is quite a lot. The default Debian base container image contains 78 packages, 429 is a lot of new packages being added!
Before publishing, I did contact Clickhouse and they have updated their container image, it’s in way better shape now. I applaud their quick updates!
What’s the make up of a MCP container?
Rather than dwell on this one container, let’s zoom out and look at all the data first. That will allow us to better explain what’s happening with Debian and why we see these results.
Let’s look at the list of all Linux distributions in use in these MCP containers:
Image
Count
Alpine
97
Debian
61
Ubuntu
1
Wolfi
1
The observant will now say that only adds up to 160! The mcp/docker image has no distro. There are also no RPM based container images in the top MCP servers (this might only be interesting to me as I spent many years at RedHat).
Each image has various packages installed, in this instance from the Linux distributions deb and apk. It also includes packages used by the various languages in use such as Python and NPM. What does the number of packages spread across all the images look like?
Package Types
Count
go-module
3405
python
3304
apk
2178
binary
837
java-archive
208
dotnet
98
nix
22
lua-rocks
2
Anybody watching the world of package ecosystems would probably expect this distribution above; NPM is a widely used language with a lot of packages. Debian is used by many images and doesn’t focus on minimal packages like Alpine, and Go and Python are commonly used languages.
Analysis of vulnerabilities in a debian image
Now if we shift our focus back to vulnerabilities, what does the distribution of vulnerabilities by package look like?
As seen above, the Debian packages account for the vast majority of vulnerabilities in these container images.
On a side note: I want to take a moment to explain something important about the Debian results. We should not be using this data to make a claim Debian is insecure. Debian is a very well maintained distribution with a great security team. They have a huge number of packages they have to keep track of. Debian puts a ton of effort into fixing the security vulnerabilities that truly matter. When a small team of volunteers have limited time, we of course want them working on things that matter, not wasting time on low severity vulnerability noise.
If we look at the distribution of vulnerabilities affecting the Debian packages we are getting a clearer picture:
The vast majority are “Negligible” Debian vulnerabilities. These are vulnerabilities the Debian security team after careful analysis has decided are lower than low and will be de-prioritized compared to other vulnerabilities.
I scanned the latest Debian container and these are the results: 0 critical, 0 high, 1 medium, 5 low, 40 negligible. That’s very impressive, and it’s also a great reason to keep your software up to date. Also keep in mind that many of these MCP Debian images haven’t been updated in a long time. It’s hardly Debian’s fault when the author of a container builds it then never updates the Debian packages.
But how bad is it overall?
On the topic of vulnerability severities, what does that graph look like across all packages in all the containers?
This graph looks a bit like that Debian distribution, but here we are seeing 263 critical vulnerabilities. That’s 263 critical vulnerabilities in 161 container images which seems like a lot. If we break this down into the packages affected by critical vulnerabilities this is what we get.
Ecosystem
Count
Debian
93
Go
92
NPM
42
Alpine
19
Python
15
Binary
2
While we know there are a lot of outdated Debian packages, it’s clear most of the other ecosystems have problems as well. We haven’t done enough research to say if these critical findings could be exploited, but even if not, it’s bad optics. It’s common for an organization to have a policy of no critical vulnerabilities in any software they deploy, it doesn’t matter if it’s exploitable or not.
Deep dive into 36,000 NPM packages
If we recall the table of all package types at the beginning of this post, there were more than 36,000 NPM packages installed in these 161 container images. Since NPM is significantly more than all the other ecosystems combined, we should investigate a bit further. What are the most installed NPM packages?
It is impressive that minipass has almost 700 installs in 161 containers, unless you are an NPM developer, then these packages won’t surprise you. They are widely used across NPM both for MCP and non-MCP software.
As a note to myself, a future research project should be looking for NPM packages that have been removed for having malware, or could be typosquatted or slopsquatted.
When working with these types of data sets, I am always interested to look at the size of files in the images.
If we look at the graph, there are a huge number of small files but also always outliers that are much larger than one would expect. One datapoint even nears 600 Megabytes. That’s a pretty big file, and my initial thought was that it could be some sort of LLM model or training content. In the clickhouse container there is a shared library in a python package that’s nearly 600 Megabytes in size. It’s a binary library in a file named _chdb.cpython-313-x86_64-linux-gnu.so. chdb is an in-memory database with data needed by the MCP server, so yeah, it’s AI content.
The other outliers around 100 MB are clickhouse and vizro containers with the pyarrow library, about 66 MB. And the aws-terraform container with a 120MB package called playwright.
It’s likely these large files aren’t mistakes but are indeed used by the container images. There’s nothing wrong with large containers. But it’s always interesting to look for outlier data to ensure mistakes haven’t been made somewhere along the way. We want to make sure we don’t accidentally include some sensitive files, or extra packages, or even debug data that nobody needs.
Conclusion…if you want to call them that
This post has a lot of data for us to think about, it’s probably overwhelming at a first glance. I don’t suggest that this should be treated as some sort of deep security analysis of MCP, it’s meant to be a brief overview of some interesting findings while digging into data. My goal is to start conversations and hopefully see more deeper research into these MCP images. If you think I did something wrong, or want to ask different questions, nothing would make me happier to be proven wrong, or inspire further research.
For now, these are the conclusions I have drawn. All of these images would benefit from some common vulnerability handling best practices:
Keeping software updated is a great first step. Regular updates are hard, but also table stakes for anyone building software in the modern age.
Minimizing attack surfaces should also be used when possible. There are small container images to build on top of. Make sure you prune out unused dependencies on a regular basis. Only use the dependencies and libraries that are needed.
And most importantly is to keep an inventory of what you’re shipping, then using that inventory to make informed decisions.
Software doesn’t age like a fine wine, more like milk. It’s important we keep track of what we’re shipping. When you produce software, it’s never a “one and done” sort of situation. It needs constant care and feeding. Understand what our threat model and risk profiles are, and most importantly, keep things updated.
Learn about the role that SBOMs for the security of your organization in this white paper.
The software industry faces a growing problem: we have far more open issues than we have contributors multiplied by available time. Every project maintainer knows this pain. We certainly recognize this across our open source tools Syft, Grype and Grant.
The backlogs grow faster than teams can address them, and “good first issues” can sit untouched for months. What if we could use AI tools not just to write code, but to tackle this contributor time shortage systematically?
Friends and podcast presenters frequently share their perspective that LLMs are terrible at coding tasks. Rather than accepting this at face value, I wanted to conduct a controlled experiment using our own open source tools at Anchore.
My specific hypothesis: Can an LLM take me from start to finish; selecting a bug to work on, implementing a fix, and submitting a pull request that gets merged; while helping me learn something valuable about the codebase?
Explore SBOM use-cases for almost any department of the enterprise and learn how to unlock enterprise value to make the most of your software supply chain.
Most repositories tag specific issues as “good-first-issue”, a label typically assigned by the core developers. They tend to know the project well enough to identify work items suitable for newcomers. These issues represent the sweet spot: meaningful contributions that may not require deep architectural knowledge, which is why I think they might be suitable for this test.
Rather than manually browsing through dozens of issues, I wrote a quick script that uses gh to gather all the relevant data systematically. The expectation is that I can benefit from an LLM to pick an appropriate issue from this list.
#!/bin/bash# Script to find and save open issues with # a specific label from a GitHub repository.# # Usage: ./find-labelled-issues.sh [org/repo] [label] [limit]set -erepo="${1:-anchore/syft}"label="${2:-good-first-issue}" limit="${3:-50}"tmpfile=$(mktemp)results="./results/$repo"cleanup() { rm -f "$tmpfile"}trap cleanup EXITmkdir -p "$results"# Grab the issues with the specified labelecho "Fetching issues from repo with label 'label'..."gh issue list -R "repo" --label "$label" --state "open" --limit "$limit" --json number --jq '.[] | .number' > "tmpfile"while read -r issue_number; do echo "Processing repo issue #issue_number" filename="(echo $repo | tr '/' '_')_issue_issue_number.json" gh issue view "issue_number" -R "$repo" --json title,body,author,createdAt,updatedAt,comments,labels --jq '. | {title: .title, body: .body, author: .author.login, createdAt: .createdAt, updatedAt: .updatedAt, comments: .comments, labels: [.labels[].name]}' | jq . > "$results/filename"done < "$tmpfile"echo "All issues processed. Results saved in the $results directory."
This script does the heavy lifting of gathering not just the initial bug reports, but all the comments and discussions that often contain crucial implementation hints from the project maintainers.
I ran this across multiple Anchore repositories, to get the first fifty:
for repo in syft grype grant stereoscope; do ./find-good-first-issues.sh anchore/$repo good-first-issue 50done
Letting the LLM Choose
With all the data collected, I presented the entire set to Claude and asked them to recommend which issue I should work on. I deliberately provided it with minimal criteria, allowing the LLM to develop its own evaluation framework.
Claude devised an evaluation criterion based on the following factors and weights:
Impact & User Value (Weight: 30%)
High: Critical functionality, affects many users, or enables new important use cases
Medium: Useful improvements or bug fixes affecting moderate user base
Medium: Some assistance possible for research or boilerplate
Low: Requires deep domain expertise or complex architectural decisions
Community Need (Weight: 10%)
High: Many comments, long-standing issue, or frequently requested
Medium: Some community interest
Low: Limited engagement
Using the above criteria, Claude grouped the current open issues into three “Tiers” and “Avoid”, for those that might be too complex or have insufficient information to complete. The “Top Tier” issues included Syft issue #675 – “Markdown Table Output Support”, and #2555 – “Windows .NET6 Dependency Parsing Fix”, but finally landed on Syft issue #2250 – “package.json authors keyword parsing”. This involves parsing the authors field in package.json files. Quoting the LLM’s response, the rationale was somewhat compelling:
"This issue stands out as the best choice because it's ideal for AI assistance—it involves JSON parsing, regex patterns, and code generation—all areas where LLMs excel. The problem has crystal clear requirements with exact examples of expected JSON structures, a manageable scope contained in a single file. It provides real user impact by improving npm package metadata parsing accuracy."
The issue was well-documented with specific examples:
With the issue selected, I moved into VS Code and enabled GitHub Copilot’s agent mode, which allows the AI to edit code and run commands rather than just make suggestions. My initial prompt was deliberately simple:
#codebaseThis is the syft codebase. Syft is an SBOM generator.I have analyzed all the open bugs in syft that are tagged "good first issue" and found 2250 a good one to start with.The rationale is in #file:anchore_syft_issue_2250_rationale.md and the bug itself is detailed in #file:anchore_syft_issue_2250.jsonPlease formulate a plan for implementing the fix. Do not start working on the code. I would like you to break down the fix into the necessary steps and explain them. If you need more information, ask questions.
The key was treating this as a collaborative process. I read every response, examined all generated code, and made sure I understood each step. Working in a feature branch meant I could experiment freely, abandon approaches that weren’t working, and restart with different prompts when needed. I was under no obligation to accept any of the suggestions from the LLM.
The Iterative Process
The most valuable part of this experiment was the back-and-forth dialog. When the LLM-generated code was unclear to me, I asked questions. When it made assumptions about the codebase structure, I corrected them. When it needed more context about contributing guidelines, I provided that information by directing it to the CONTRIBUTING.md and DEVELOPING.md files from the repository.
This iterative approach allowed me to learn about the Syft codebase structure, Go programming patterns, and the project’s testing conventions throughout the process. The LLM worked as a knowledgeable pair-programming partner rather than a black-box code generator.
Testing and Validation
The LLM automatically detected the project’s existing test structure and generated appropriate test cases for the new functionality. It was understood that any changes needed to maintain backward compatibility and avoid breaking existing package.json parsing behavior.
Running the test suite confirmed that the implementation worked correctly and didn’t introduce regressions, a crucial step that many rushed “vibe-coded” AI-assisted contributions skip.
Pull Request Creation
When the code was ready, I asked the LLM to draft a pull request description using the project’s template. I edited this slightly to match my writing style before submitting, but the generated description covered all the key points: what the change does, why it’s needed, and how it was tested.
The pull request was submitted like any other contribution and entered the standard review process.
Results and Lessons Learned
The experiment succeeded: the pull request was merged after review and feedback from the maintainers. But the real insights came from what happened during the process:
Speed Gains: The development process was somewhere around 3-5 times faster than if I had tackled this issue manually. The LLM handled the routine parsing logic while I focused on understanding the broader codebase architecture.
Learning Acceleration: Rather than just producing code, the process accelerated my understanding of how Syft’s package parsing works, Go testing patterns, and the project’s contribution workflow.
Maintainer Perspective: The project maintainers could tell the code was AI-assisted (interesting in itself), but this wasn’t a significant problem. They provided thoughtful feedback that I was able to incorporate with the LLM’s help.
Room for Improvement: I should have explicitly pointed the LLM to the contributing guidelines instead of relying on the codebase to infer conventions. This would have saved some iteration cycles.
When This Approach Makes Sense
I wouldn’t use this process for every contribution. Consuming all the good-first-issues would leave nothing for human newcomers who want to learn through direct contribution. The sweet spot seems to be:
Straightforward issues with clear requirements.
Learning-focused development where you want to understand a new codebase.
Time-constrained situations where you need to move faster than usual.
Problems that involve routine parsing or data transformation logic.
Future Refinements
For the next contributions, I will make several improvements:
Add explicit prompts to match my writing style for pull request descriptions.
Point the LLM directly to the contributing guidelines and coding standards, which are in the repository, but sometimes require explicit mention.
Consider working on issues that aren’t tagged as “good-first-issue” to preserve those seemingly “easier” ones for other human newcomers.
Add a note in the pull request acknowledging the use of a tool-assisted approach.
The goal isn’t to replace human contributors, but to find ways that AI tools can help us tackle the growing backlog of open issues while genuinely accelerating our learning and understanding of the codebases we work with.
This experiment suggests that with the right approach, LLMs can be valuable partners in open source contribution, not just for generating code, but for navigating unfamiliar codebases and understanding project conventions. The key is maintaining active engagement with the entire process, rather than treating AI as a one-click magic solution.
After conducting this experiment, I discussed the outcomes with the Anchore Open Source team, which welcomes contributions to all of its projects. They were quick to point out the quality difference between a well-curated AI-assisted pull request and a “vibe-coded” one, thrown over the wall.
What similar experiments would you want to see? The intersection of AI tools and open-source contributions feels like fertile ground for making our development workflows both faster and more educational.
Learn about the role that SBOMs for the security of your organization in this white paper.
A previous blog article titled “Navigating the New Compliance Frontier” discussed some of the new trends with compliance. But it’s not as simple as just claiming “because compliance”–that’s the easy answer that doesn’t tell us much. Compliance doesn’t say anything about using hardened container images. But here’s the thing: many compliance standards do have things to say about configuration management, attack surface, and vulnerabilities. We’re not being told to use hardened images, but hardened images solve many of these problems, so they are getting used. It’s one of those situations where the practical solution emerges not because someone mandated it, but because it actually works.
When you operate in a regulated space (as we all will be soon, thanks to the CRA) you have to justify configuration changes, software changes, and every vulnerability. The idea behind the hardened images is to have only the software you absolutely need and nothing else. That translates into you only having a list of the vulnerabilities that directly affect you.
There’s an additional reason that’s giving small hardened images extra attention. The ability to scan your software for vulnerabilities is better than it’s ever been. Historically trying to scan software for vulnerabilities wasn’t very reliable or even a good use of anyone’s time. Scanners of the past missed a lot of things. It was a lot harder to figure out what all the software installed on bare metal, VMs, or containers. And by harder we really mean it was nearly impossible. It was common to just fall back to spreadsheets with people doing this all manually.
Scanning for vulnerabilities was basically out of the question, nobody had a decent inventory of their software supply chain. The scanners also had incomplete data if they even had data at all. The false positive rate made the results useless and the false negative rate made those useless results dangerous. It was also common to scan a system and just get no results at all. Not because there are no vulnerabilities, but because the scanners couldn’t figure anything out.
That’s not true anymore. If you scan any modern Linux distribution you’re going to get results. Language ecosystems like Python, Java, and Go are well supported. A lot of scanners can even figure out what pre-built binaries are in a container image. Scanners have gotten pretty good at finding the software in a container.
Interested to learn how Anchore built Syft, a modern software composition analysis (SCA) scanner & SBOM generator, to overcome the challenges that plagued legacy scanners? Check out our behind the scene blog series:
This also means that if we have a reliable list of software, we can also scan that list for vulnerabilities. Something you’ll notice quickly is a hardened minimal image has fewer findings than a more traditional container image. This doesn’t mean a minimal container image is better than a more traditional one. They solve different problems.Here’s an example, let’s look at an Alpine image and a Debian image. We can scan the container image with the Syft SBOM scanner.
The Alpine image has 16 packages in it. The Debian image has 78. That’s a pretty big difference. It’s pretty clear that an Alpine image would fall under the umbrella of a minimal hardened image while Debian does not.If we scan these for vulnerabilities the results are similar. The Grype vulnerability scanner does a great job when scanning both Alpine and Debian container images.
We see 0 vulnerabilities in the Alpine image and 46 vulnerabilities in the Debian image. Now this doesn’t make Debian worse, they have limited time and fix the most dangerous vulnerabilities first. It’s 1 medium, 5 low, and 40 negligible. It’s pretty clear the Debian security folks are staying on top of all this.
Keep in mind that Debian has a lot more software than you get in an Alpine image. There are many problems that are easier to solve with Debian than Alpine because it has more software available. There are also problems that are easier to solve with Alpine because it has less software.
In the case of hardened container images, if our primary problem is justifying security findings, you’re going to have less work to do if you have fewer vulnerabilities. Less software means fewer vulnerabilities. This seems like a pretty easy logical conclusion. Even when a security vulnerability is marked as “negligible” as we see in the above Debian report, security and compliance auditors will want a justification. Those justifications come with a cost. We can remove that cost by just not having those vulnerabilities present. One way to get fewer vulnerabilities is to ship less software. This is that case where Alpine solves a problem Debian doesn’t.
Of course we could try to build our own tiny variant of Debian. Is that a problem we want to solve? The care and feeding of container base images has been solved by many other companies and open source projects. If you need a giant image full of stuff, or a small image that only contains what you need. This is one of those classic situations where you can use an existing solution to solve a problem. You don’t generate your own electricity, you pay a utility. Why are you trying to manage the operating system in your container images?
Hardened container images aren’t the end goal of meeting your compliance requirements, they are the first step in a long journey. There are many stages to release software and services. We’re going to see increasing attention to how we build our software, what the dependencies are, what the vulnerabilities in those dependencies are. There won’t be a single simple answer for any of these new requirements. However, now that we have some requirements we can start to figure out the best way to solve these new problems.
This is exactly why Anchore recently announced a strategic partnership with Chainguard, one of the leading companies in the hardened container space. The partnership recognizes something important: starting with secure, hardened container images is just the beginning. You also need continuous scanning, policy enforcement, and compliance monitoring as you build your own code on top of those secure foundations. It’s a “Start Safe, Stay Secure and Compliant” approach that acknowledges hardened images solve the base layer problem, but you still need to manage everything else in your software supply chain.
At Anchore we don’t think we can solve every problem, but we do think the combination of starting with hardened images and applying continuous security practices like SBOMs and policy evaluations throughout your development lifecycle is the most practical way forward in this new compliance world.
Learn how Chainguard’s hardened images and Anchore Enterprise’s SBOM-powered, vulnerability scanning and policy enforcement reduce audit effort and accelerate entry into new markets.
In 2018, Anchore partnered with the US Air Force on Platform One, a project focused on integrating DevSecOps principles into government software development. A core part of that project was the launch of the Iron Bank, a repository of container images hardened with Anchore’s software to remove security issues before deployment. This accelerated compliance status for the US government. Chainguard now champions the concept of hardened container images for the broader market. Today, we formally partner with Chainguard, enabling our customers to “Start Safe, Stay Secure and Compliant.”
Our joint partnership focused on guaranteeing seamless workflows between both products for our customers. Chainguard Images allow customers to start with hardened images with close to zero vulnerabilities. Anchore Enterprise scans images correctly, generating no false positives; then continuously monitors images for compliance as developers add code, guiding them on upgrades.
As the compliance burden increases from governmental regulations such as FedRAMP, DORA, NIS2, and CRA, customers can use Anchore and Chainguard to achieve compliance faster by avoiding the costly burden of triaging and patching security issues.
Default-to-Secure with Chainguard Images
Vulnerability management has become both more essential and challenging in recent years.
The pervasive use of open source software, often of varying quality, combined with the rise of novel supply chain attacks, means almost all software now contains vulnerabilities. Consequently, developers are bombarded with a long list of security issues as part of their very first build.
Chainguard provides hardened images, removing many vulnerabilities before development even begins. Developers can focus on the security of their own code and not the operating system underneath. Rather than shift more issues left to developers, the goal is to shift issues out of the view of the developers entirely.
However, if the vulnerability management tools in place are not tested or configured properly, there is a risk of content being misidentified and packages erroneously flagged as being vulnerable. Anchore and Chainguard have partnered to ensure that Anchore’s results are always up to date with the latest fixes from Chainguard and no false positives are generated. Beyond vulnerabilities, Chainguard’s published SBOMs for the base images have been tested for consistency with the automatic SBOMs that Anchore generates throughout the SDLC. Continuous Compliance with Anchore Enterprise
Hardened images offer developers a cleaner starting point, but ongoing scanning remains essential. Once developers add their code, with its own dependencies from GitHub or other upstream repositories, they must ensure no new vulnerabilities are introduced.
Continuous scanning with Anchore Enterprise
Anchore Enterprise will highlight vulnerabilities discovered in higher-level code not present in the base Chainguard image, directing developers only to fixes they can take action against. Anchore can also generate a list of vulnerable base images with critical CVEs, indicating when the images are stale and require upgrading from the Chainguard catalog. It is important to note that unlike other tools which need ongoing access to the original image or asset, the Anchore assessment is done continuously whenever new vulnerabilities are published. This means alerts for new issues go out immediately as soon as the data is received.
Our out-of-the-box policy packs immediately flag any findings that cause an environment to go out of compliance, prompting developer or security teams to follow up. Examples may include unencrypted secrets, incorrect file permissions, or exposed ports – all of which are explicitly called out in various US and European standards.
The Anchore Policy Engine also allows you to test images against multiple controls on the fly without needing to rescan the image.
Collaboration through continuous testing and Open Source
Chainguard has a long history of contributing to our open source projects: Syft, Grype, and Vunnel. We are excited to continue working with them on an upstream first basis to support Chainguard Images and future product offerings.
Extending the collaboration further, both Anchore and Chainguard are using each other’s commercial software as part of a continuous testing process to ensure that scans generate the best results for end users and any issues are detected early and quickly.
Join us tomorrow at 10am PT | 1 pm ET for a live demo and discussion on this new partnership with us and Chainguard – save your seat here.
Learn how Chainguard’s hardened images and Anchore Enterprise’s SBOM-powered, vulnerability scanning and policy enforcement reduce audit effort and accelerate entry into new markets.
Every modern application is built on a foundation of open source dependencies. Dozens, hundreds, sometimes thousands of packages can make up a unit of software being shipped to production. Each of these packages carries its own license terms. A single incompatible license deep in your dependency tree can create legal headaches, force costly rewrites, or even block a product release.
What looks like a routine compliance task can quickly turn into what some have called “death by a thousand cuts”. Every weekend disappears into spreadsheets, combing through packages, trying to spot the legal landmines buried in the latest snapshot of a software supply chain. The danger doesn’t normally come from the obvious places but from the invisible depths of transitive dependencies—the “dependencies of dependencies”—where one unexpected license could derail an entire product.
As software supply chains grow more complex, manual license review becomes an intractable method. That’s where Grant comes in. We’ve rebuilt key parts of Syft to make SBOM license inspection for Golang packages smarter, while also updating Grant’s config to allow for stricter policies that are easier to use.
90% improvements on license inspection for Golang modules
At its surface, the package detection problem for Golang seems straight forward. Give me the go.mod, enumerate all the entries, build the package list…done!. In actuality, it’s a lot more complicated if you want the licenses. When we tested Grant’s new Golang module integration on the MinIO Golang client (a popular S3-compatible storage solution), the new results for licenses detection were very promising:
Before: 295 packages with undetected licenses (go.mod approach)
After: Only 29 missing licenses – a 90% improvement (golang source inspection)
Each undetected license carries potential harm such as:
A competitor claiming code ownership
A consumer forced to open-source proprietary features
Personal liability for engineering leaders
For a company preparing for acquisition or IPO, having 295 unknown licenses in their SBOM could delay due diligence. With Grant’s improvements, that same audit/inspection can now isolate the problem packages and figure out what licenses are missing.
Stronger Policies for Safer (and Faster) Compliance
Detect Unlicensed Packages
“No license” cases are now flagged by default. This closes gaps where unlicensed code could slip through and gives organizations clearer control over compliance risks. If it’s ok that a package has no licenses, it’s quick to add it to the exceptions list for a green CI.
Understanding License Families
Grant now categorizes licenses into risk-based families, making it easier to create policies that match your organization’s risk tolerance. We create the following classification to help teams quickly identify which dependencies need legal review versus which can be auto-approved :
Strong Copyleft (High Risk): GPL, AGPL, SSPL
Requires derivative works to use the same license
Can “infect” proprietary code with open source obligations
Example policy: deny: ["GPL-*", "AGPL-*"]
Weak Copyleft (Medium Risk): LGPL, MPL, EPL
More permissive than strong copyleft
Allows linking without license propagation
Example policy: allow: ["LGPL-*"] # but review usage context
Permissive (Low Risk): MIT, Apache-2.0, BSD
Minimal restrictions on reuse
Generally safe for commercial products
Example policy: allow: ["MIT", "Apache-2.0", "BSD-*"]
Easier, Cleaner Configuration
The old .grant.yaml was powerful but too verbose and hard to manage. Users told us it was unwieldy, repetitive, and full of boilerplate. We rebuilt the configuration system with sensible defaults and simpler patterns.
👉 The result: policies that used to take ~50 lines can now be expressed in ~15.
Before: Verbose & Rule-Heavy
#.grant.yamlrules: - pattern: "BSD-*" name: "bsd-allow" mode: "allow" reason: "BSD is compatible with our project" exceptions: - my-package # denied for this package - pattern: "MIT" name: "mit-allow" mode: "allow" reason: "MIT is compatible with our project" - pattern: "*" name: "default-deny-all" mode: "deny" reason: "All licenses need to be explicitly allowed"
After: Streamlined & User-Friendly
# Default: DENY all licenses (including no-license packages)require-license: truerequire-known-license: falseallow: - MIT - MIT-* - Apache-2.0 - Apache-2.0-* - BSD-2-Clause - BSD-3-Clause - BSD-3-Clause-Clear - ISC - 0BSD - Unlicense - CC0-1.0ignore-packages: - github.com/mycompany/* # Our own Go modules
The new format is:
Shorter – no more repetitive rule definitions
Clearer – defaults make intent obvious (deny all unless explicitly allowed)
More flexible – glob patterns and ignore-packages handle common exceptions
CI/CD Upgrades with --dry-run and --allow-failure
Not every scan should block your build. Based on feedback from teams running Grant in CI/CD, we’ve added two new flags for more control:
--dry-run — preview scan results without enforcing policy
--allow-failure — let pipelines continue even if violations are found
These options make it easier to adopt Grant incrementally: start in “report-only” mode, then turn on strict enforcement when it fits your needs.
Smarter Package Discovery
Golang Toolchain Integration
The latest update builds Golang package licenses by using golang.org/x/tools/go/packages to build a full import graph, detect the main module, and pull licenses from the Golang module cache. If the toolchain isn’t available, we gracefully fall back to go.mod. This approach catches transitive dependencies that other tools might miss and handles complex scenarios like replace directives and local modules.
Under the Hood: How Go Module Discovery Works
Grant’s new Golang integration enhances how we discover licenses for dependencies:
Build-time analysis: We hook into golang.org/x/tools/go/packages to construct the actual import graph—not just what’s declared in go.mod, but what’s actually used.
Module cache mining: Instead of crawling vendor directories, we pull licenses directly from Go’s module cache, ensuring we get the canonical license files.
Graceful degradation: No Go toolchain? No problem. Grant still constructs the SBOM and grabs what licenses it can in the current directory’s context. It just won’t be as powerful as it is when combined with the go tool chain knowledge.
Expanded Package Type Support
Grant now leverages Syft’s enhanced cataloging capabilities to detect licenses across more package ecosystems:
Cataloging snap packages with transitive package support and their included licenses
Conda ecosystem support when license location available
Better license detection with over 1400 URL-to-license mappings
Better Data, Faster Runs
SPDX Upgrade
Added ~1,400 new URL-to-license mappings, improved lookups, and upgraded the SPDX license list from 3.22 → 3.27. Deprecated URLs now resolve cleanly to replacements.
Focused Crawling
License detection is now limited to common filenames (LICENSE, COPYING, NOTICE, etc.), avoiding slow scans through irrelevant directories. Users even have the ability to turn off Grant’s scanning feature with --disable-file-search if they trust the content of their SBOM.
In prior releases large directories of files would give grant issues since it would try to read the contents of every file to look for license evidence:
$ npx create-react-app . --template minimal$ grant check .~/d/test (main)> grant check . ⠹ Checking licenses ━━━━━━━━━━━━━━━━━━━━
The above would balloon a workstation’s memory usage and take about 3-4 cups of coffee before finishing its task.
With this change we see this process execute in a shorter amount of time.
$ time grant check dir:.Target: dir:. (directory)Status: ✗ NON-COMPLIANTSummary: Packages: 1289 total, 1289 denied, 43 unlicensed Licenses: 15 unique, 15 deniedDenied Packages (1256):...........................________________________________________________________Executed in 2.87 secs fish external usr time 2.22 secs 0.21 millis 2.22 secs sys time 1.26 secs 1.22 millis 1.26 secs
The secret? Focused crawling that skips irrelevant files and parallel license classification. The new --disable-file-search flag can also reduce scan times by another 40% when you only need licenses that are found in the SBOM and associated packages.
TLDR; Top 5 Grant Improvements
With this update, Grant is:
Stricter where it counts, by detecting unlicensed packages
Simpler to configure with defaults that reflect real-world needs
Safer to adopt in CI/CD with dry-run and allow-failure modes
Smarter for Go projects and other ecosystems with toolchain-backed cataloging
Faster across large repositories with reduced crawl time
Together these improvements make Grant a sharper, safer tool for software license inspection and evaluation.
And This Is What’s Next
This release sets the foundation for what’s coming next:
Configuration templates: Pre-built license configurations for common scenarios
License remediation hints: Automated suggestions for replacing problematic dependencies
MCP integration: Real-time license feedback from your favorite AI agent
SBOM enrichment: Adding edited/discovered licenses back into your SBOMs
Try it yourself
$ grant check dir:.
Join us on September 18 for our live webinar where we demo the latest functionality.
Questions? Issues? Join the discussion atanchore.com/discourse or reach out and file an issue!
Grant is part of Anchore’s open source toolkit for software supply chain security. Learn more about our complete SBOM and vulnerability management solutions atanchore.com.
To help organizations meet the DoD’s security controls, DISA develops Security Technical Implementation Guides (STIGs) to provide guidance on how to secure operating systems, network devices, software, and other IT systems. DISA regularly updates and releases new STIG versions.
STIG compliance is mandatory for any organization that operates within the DoD network or handles DoD information, including DoD contractors and vendors, government agencies, and DoD IT teams.
With more than 500 total STIGs (and counting!), your organization can streamline the STIG compliance process by identifying applicable STIGs upfront, prioritizing fixes, establishing a maintenance schedule, and assigning clear responsibilities to team members.
In the rapidly modernizing landscape of cybersecurity compliance, evolving to a continuous compliance posture is more critical than ever, particularly for organizations involved with the Department of Defense (DoD) and other government agencies. In February 2025, Microsoft reported that governments are in the top 3 most targeted sectors worldwide.
At the heart of the DoD’s modern approach to software development is the DoD Enterprise DevSecOps Reference Design, commonly implemented as a DoD Software Factory. A key component of this framework is adhering to the Security Technical Implementation Guides (STIGs) developed by the Defense Information Systems Agency (DISA).
STIG compliance within the DevSecOps pipeline not only accelerates the delivery of secure software but also embeds robust security practices directly into the development process, safeguarding sensitive data and reinforcing national security.
This comprehensive guide will walk you through what STIGs are, who should care about them, the levels and key categories of STIG compliance, how to prepare for the compliance process, and tools available to automate STIG implementation and maintenance. Read on for the full overview or skip ahead to find the information you need:
The Defense Information Systems Agency (DISA) is the DoD agency responsible for delivering information technology (IT) support to ensure the security of U.S. national defense systems. To help organizations meet the DoD’s rigorous security controls, DISA develops Security Technical Implementation Guides (STIGs).
STIGs are configuration standards that provide prescriptive guidance on how to secure operating systems, network devices, software, and other IT systems. They serve as a secure configuration standard to harden systems against cyber threats.
For example, a STIG for the open source Apache web server would specify that encryption is enabled for all traffic (incoming or outgoing). This would require the generation of SSL/TLS certificates on the server in the correct location, updating the server’s configuration file to reference this certificate and re-configuration of the server to serve traffic from a secure port rather than the default insecure port.
Who should care about STIG compliance?
In its annual Software Supply Chain Security report, Anchore found that the average organization complies with 4.9 cybersecurity compliance standards. STIG compliance, in particular, is mandatory for any organization that operates within the DoD network or handles DoD information. This includes:
DoD Contractors and Vendors: Companies providing products or services to the DoD, a.k.a. the defense industrial base (DIB)
Government Agencies: Federal agencies interfacing with the DoD
DoD Information Technology Teams: IT professionals within the DoD responsible for system security
Connection to the RMF and NIST SP 800-53
The Risk Management Framework (RMF)—known formally as NIST 800-37—is a framework that integrates security and risk management into IT systems as they are being developed. The STIG compliance process outlined below is directly integrated into the higher-level RMF process. As you follow the RMF, the individual steps of STIG compliance will be completed in turn.
STIGs are also closely connected to the NIST 800-53, colloquially known as the “Control Catalog”. NIST 800-53 outlines security and privacy controls for all federal information systems; the controls are not prescriptive about the implementation, only the best practices and outcomes that need to be achieved.
As DISA developed the STIG compliance standard, they started with the NIST 800-53 controls as a baseline, then “tailored” them to meet the needs of the DoD; these customized security best practices are known as Security Requirements Guides (SRGs). In order to remove all ambiguity around how to meet these higher-level best practices STIGs were created with implementation specific instructions.
For example, an SRG will mandate that all systems utilize a cybersecurity best practice, such as, role-based access control (RBAC) to prevent users without the correct privileges from accessing certain systems. A STIG, on the other hand, will detail exactly how to configure an RBAC system to meet the highest security standards.
Levels of STIG Compliance
The DISA STIG compliance standard uses Severity Category Codes to classify vulnerabilities based on their potential impact on system security. These codes help organizations prioritize remediation efforts. The three Severity Category Codes are:
Category I (Cat I): These are the highest severity or highest risk vulnerabilities, allowing an attacker immediate access to a system or network or allowing superuser access. Due to their high risk nature, these vulnerabilities be addressed immediately.
Category II (Cat II): These vulnerabilities provide information with a high potential of giving access to intruders. These findings are considered a medium risk and should be remediated promptly.
Category III (Cat III): These vulnerabilities constitute the lowest risk, providing information that could potentially lead to compromise. Although not as pressing as Cat II & III issues, it is still important to address these vulnerabilities to minimize risk and enhance overall security.
Understanding these categories is crucial in the STIG process, as they guide organizations in prioritizing remediation of vulnerabilities.
Key categories of STIG requirements
Given the extensive range of technologies used in DoD environments, there are nearly 500 STIGs (as of May 2025) applicable to different systems, devices, applications, and more. While we won’t list all STIG requirements and benchmarks here, it’s important to understand the key categories and who they apply to.
1. Operating System STIGs
Applies to: System Administrators and IT Teams managing servers and workstations
Examples:
Microsoft Windows STIGs: Provides guidelines for securing Windows operating systems.
Linux STIGs: Offers secure configuration requirements for various Linux distributions.
2. Network Device STIGs
Applies to: Network Engineers and Administrators
Examples:
Network Router STIGs: Outlines security configurations for routers to protect network traffic.
Network Firewall STIGs: Details how to secure firewall settings to control access to networks.
3. Application STIGs
Applies to: Software Developers and Application Managers
Examples:
Generic Application Security STIG: Outlines the necessary security best practices needed to be STIG compliant
Web Server STIG: Provides security requirements for web servers.
Database STIG: Specifies how to secure database management systems (DBMS).
4. Mobile Device STIGs
Applies to: Mobile Device Administrators and Security Teams
Examples:
Apple iOS STIG: Guides securing of Apple mobile devices used within the DoD.
Android OS STIG: Details security configurations for Android devices.
5. Cloud Computing STIGs
Applies to: Cloud Service Providers and Cloud Infrastructure Teams
Examples:
Microsoft Azure SQL Database STIG: Offers security requirements for Azure SQL Database cloud service.
Cloud Computing OS STIG: Details secure configurations for any operating system offered by a cloud provider that doesn’t have a specific STIG.
Each category addresses specific technologies and includes a STIG checklist to ensure all necessary configurations are applied.
Achieving DISA STIG compliance involves a structured approach. Here are the stages of the STIG process and tips to prepare:
Stage 1: Identifying Applicable STIGs
With hundreds of STIGs relevant to different organizations and technology stacks, this step should not be underestimated. First, conduct an inventory of all systems, devices, applications, and technologies in use. Then, review the complete list of STIGs to match each to your inventory to ensure that all critical areas requiring secure configuration are addressed. This step is essential to avoiding gaps in compliance.
Tip: Use automated tools to scan your environment, then match assets to relevant STIGs.
Stage 2: Implementation
After you’ve mapped your technology to the corresponding STIGs, the process of implementing the security configurations outlined in the guides begins. This step may require collaboration between IT, security, and development teams to ensure that the configurations are compatible with the organization’s infrastructure while enforcing strict security standards. Be sure to keep detailed records of changes made.
Tip: Prioritize implementing fixes for Cat I vulnerabilities first, followed by Cat II and Cat III. Depending on the urgency and needs of the mission, ATO can still be achieved with partial STIG compliance. Prioritizing efforts increases the chances that partial compliance is permitted.
Stage 3: Auditing & Maintenance
After the STIGs have been implemented, regular auditing and maintenance are critical to ensure ongoing compliance, verifying that no deviations have occurred over time due to system updates, patches, or other changes. This stage includes periodic scans, manual reviews, and remediation of any identified gaps.
Organizations should also develop a plan to stay informed about new STIG releases and updates from DISA. You can sign up for automated emails on https://www.cyber.mil/stigs.
Tip: Establish a maintenance schedule and assign responsibilities to team members. Alternatively, you can adopt a policy-as-code approach to continuous compliance by embedding STIG requirements directly into your DevSecOps pipeline, enabling automated, ongoing compliance.
General Implementation Tips
Training: Ensure your team is familiar with STIG requirements and the compliance process.
Collaboration: Work cross-functionally with all relevant departments, including IT, security, and compliance teams.
Resource Allocation: Dedicate sufficient resources, including time and personnel, to the compliance effort.
Continuous Improvement: Treat STIG compliance as an ongoing process rather than a one-time project.
Test for Impact on Functionality: The downside of STIG controls’ high level of security is a potential to negatively impact functionality. Be sure to conduct extensive testing to identify broken features, compatibility issues, interoperability challenges, and more.
Tools to automate STIG implementation and maintenance
The 2024 Report on Software Supply Chain Security found “automating compliance checks” is a top priority, with 52% of respondents ranking it in their top 3 supply chain security challenges. For STIGs, automation can significantly streamline the compliance process. Here are a few tools that can help:
1. Anchore STIG (Static and Runtime)
Purpose: Automates the process of checking container images against STIG requirements.
Benefits:
Simplifies compliance for containerized applications.
Integrates into CI/CD pipelines for continuous compliance.
Use Case: Ideal for DevSecOps teams utilizing containers in their deployments.
Purpose: Identify vulnerabilities and compliance issues within your network.
Benefits:
Provides actionable insights to remediate security gaps.
Offers continuous monitoring capabilities.
Use Case: Critical for security teams focused on proactive risk management.
Wrap-Up
Achieving DISA STIG compliance is mandatory for organizations working with the DoD. By understanding what STIGs are, who they apply to, and how to navigate the compliance process, your organization can meet the stringent compliance requirements set forth by DISA. As a bonus, you will enhance its security posture and reduce the potential for a security breach.
Remember, compliance is not a one-time event but an ongoing effort that requires regular updates, audits, and maintenance. Leveraging automation tools like Anchore STIG and Anchore Secure can significantly ease this burden, allowing your team to focus on strategic initiatives rather than manual compliance tasks.
Stay proactive, keep your team informed, and make use of the resources available to ensure that your IT systems remain secure and compliant.
We’re excited to announce that Anchore Enterprise is now SDPX 3 ready. If you’re a native to the world of SBOMs this may feel a bit confusing given that the Linux Foundation announced the release of SPDX 3 last year. While this is true, it is also true that the software ecosystem is still awaiting reference implementations which is blocking the SBOM tools community from rolling out the new format. Regardless of this dynamic situation, Anchore is hearing demand from existing customers to stay at the cutting edge of the evolution of SBOMs. To that end, Anchore Enterprise now includes initial support for SPDX 3. These forward looking enterprises are seeking to future-proof their software development process and begin building a fine-grained historical record of their software supply chain while the software ecosystem matures.
Organizations today rely predominantly on two established SBOM standards: SPDX and CycloneDX. Many organizations mix-and-match these formats to address different aspects of modern security and risk management requirements, from increasing transparency into software component supply chains and managing third-party dependency vulnerabilities to enforcing regulatory compliance controls and software license management.
These traditional software-oriented formats continue to deliver significant enterprise value and remain essential for current operational needs. However, the software ecosystem is evolving toward distributed systems and AI-native applications that require a corresponding transformation of SBOM capabilities.
SPDX 3 represents this next generation, designed to capture complex interdependencies in modern distributed architectures that interweave AI features. Since the ecosystem is still awaiting an official reference implementation for SPDX 3 early adopters are experiencing significant turbulence.
For now, organizations need a dual-track approach: maintaining proven standards like SPDX 2.3 and CycloneDX for immediate vulnerability and license scanning needs while beginning to collect SPDX 3 documents in preparation for the ecosystem’s maturation. This parallel strategy ensures operational continuity while positioning organizations for the advanced capabilities that next-generation formats will enable.
The Value of Starting Your SPDX 3 Collection Today
While SPDX 3 processing capabilities are still maturing across the ecosystem, there’s compelling value in beginning collection today. Just as Anchore customers benefit from comprehensive SBOM historical records during zero-day vulnerability investigations, starting your SPDX 3 collection today creates an auditable trail that will power future service-oriented and AI specific use cases as they emerge.
The development lifecycle generates valuable state information at every stage—information that becomes irreplaceable during incident response and compliance audits. By collecting SPDX 3 SBOMs now, organizations ensure they have the historical context needed to leverage new capabilities as the ecosystem matures, rather than starting from zero when scalable SPDX 3 SBOM processing becomes available.
Anchore Enterprise, SPDX 3 Ready: Upgrade Now
As of version 5.20, Anchore Enterprise provides SPDX 3 document storage. This positions organizations for a seamless transition as the ecosystem matures. Users can upload, store, and retrieve valid SPDX 3 SBOMs through existing interfaces while maintaining operational workflows with battle-tested standards.
Organizations can now easily implement the dual-track approach that will allow them to have their SBOM cake and eat it too. The latest releases of Anchore Enterprise deliver the foundational capabilities organizations need to stay ahead of evolving supply chain security requirements. The combination of SPDX 3 support and enhanced SBOM management positions teams for success as software architectures continue to evolve toward distributed, AI-native systems.
Ready to upgrade?
Existing customers should reach out to their account manager to access the latest version of Anchore Enterprise and begin storing SPDX 3 SBOMs
Explore SBOM use-cases for almost any department of the enterprise and learn how to unlock enterprise value to make the most of your software supply chain.
On September 8, 2025 Anchore was made aware of an incident involving a number of popular NPM packages to insert malware. The technical details of the attack can be found in the Aikido blog post: npm debug and chalk packages compromised
After an internal audit, Anchore determined no Anchore products, projects, or development environments ever downloaded or used the malicious versions of these packages.
Anchore Enterprise and Grype both use the GitHub Advisory Database to source the vulnerability data for NPM packages. Since this database also includes malware packages such as this, both Anchore Enterprise and Grype will detect these malware packages if they are present.
The databases used by Anchore Enterprise and Grype will auto update on a regular basis. However, given the severity of this malware, users of Anchore Enterprise and Grype can update their feed database manually to ensure they are able to detect the malicious packages from this incident.
Which will download the updated vulnerability database.
Anchore Enterprise users can run:
$ anchorectl feed sync
Which will download the latest version of the vulnerability database.
Once the databases are updated, both Grype and Anchore Enterprise identify the malware in question. You can verify the vulnerability ID is found in your vulnerability dataset with the following API call:
If you develop or use software, which in 2025 is everyone, it feels like everything is starting to change. Software used to exist in a space where we could do almost anything they wanted and it didn’t seem like anyone was really paying attention. We all heard stories about mission critical Windows 95, still running today. Or running a version of Log4j older than the interns have been alive. Some will view it as some sort of golden age of software, to others it was the darkest of ages with no accountability. No matter what you think about how things used to work, we are on the precipice of change in the world of software development.
If you try to ask why things are starting to change, you’re going to get a multitude of answers. The why doesn’t really matter though, we need to understand the how. What is going to change? What should we be paying attention to? Anyone working on software will need to know what they have to pay attention to now. The what in this instance is compliance, a lot of new compliance standards.
So what are these standards we all need to start paying attention to? There’s not enough time to hit them all here, but a few names you’re going to start hearing more about are the EU Cyber Resilience Act (CRA), the Product Liability Directive (PLD). Secure Software Development Framework (SSDF), Cybersecurity in Medical Devices (everyone seems to be calling this “FDA”). And there are even more industry specific standards starting to emerge like PCI. We will cover all these and more over the course of this blog series.
What we’re seeing now is that the sort of compliance in healthcare doesn’t look like the compliance in automotive or financial. And then there are even broader things like the EU CRA that will cover everyone and everything. One of our challenges moving forward is figuring out which standards apply where and what needs to change. This can include the markets we sell into, the type of product we’re selling, the service(s) we’re providing. There won’t be any easy answers and we will all have to figure this out.
There’s a term I really like I heard someone use the other day: CompOps to build on the SecDevSecOpsSec sort of naming. Compliance Operations. A few years ago this could be dismissed as a weird and boring term, but as we see compliance everywhere we look, it’s going to be more important than ever to incorporate compliance into how we build and distribute software. Thinking about this with a DevOps mindset might be the only reasonable way forward.
We should take a moment to note the software industry is not special with all these new compliance standards. Virtually every existing industry has standards they must adhere to. Issues like food safety, human safety, auto safety, too many topics to list. Compliance is nothing new, we are not special. We’re finally catching up to everyone else.
While every one of these standards has different requirements. And we will of course cover many of those differences, there are certain things they all seem to have in common. The two that are probably easiest to understand and unpack are Software Bill of Materials (SBOMs) and vulnerabilities. At Anchore this is something we’ve been thinking about and working on for a very long time. Our SBOM and vulnerability projects Syft and Grype were created in 2020, and we had a tool called Anchore Engine before that.
Let’s start with SBOMs. Just because a compliance standard says you need an SBOM, that’s not necessarily helpful. What format does it need to be in? How are you supposed to store the SBOM? How long are you supposed to keep an SBOM around? Do you need to publish it on your website? Give it to customers, or regulators, or some other group? It’s one of those things that can seem really easy, but the devil is always in the details. We can answer some of these questions today, but some of them are going to evolve over time as the intention of regulators becomes more clear.
Vulnerabilities aren’t any easier, but might be a more tractable problem. You just need to release software that doesn’t have any vulnerabilities! That’s probably not easier than SBOMs. But recently we’ve seen very small hardened containers images show up that can make a huge difference with vulnerability wrangling. This doesn’t solve the problem of vulnerabilities in your dependencies and own code. But it will certainly free up your time to focus on your product rather than the things in your container base image.
Before we get to our exciting conclusion, it’s important to understand that all these compliance standards are going to have unintended consequences. There will be second and third order effects that create new problems while trying to solve the original problem. That’s how new standards work. It will be important for all of us to give feedback to the governing bodies of all these standards. They do listen and generally try to do the right things.
So what happens now? If you’ve never been involved in compliance standards before, this can all feel extremely overwhelming. It’s OK to panic for a little while, this sort of change is a big deal. There are a lot of resources available to help us all out. There are companies that can help us out. Plenty of people have made a career out of making compliance easy (or at least less hard).
This post is the start of a series where Anchore is going to help break down and explain many of the SBOM and software supply chain requirements in these standards. Helping out with SBOM requirements is something we’ve been working on for years. We knew SBOMs were going to end up in compliance standards, we just didn’t think it would happen so suddenly!
If this is your new reality, stay with us. We’ll be diving deep into each major standard, providing practical implementation guidance, and sharing what we’ve learned from organizations that are already ahead of the curve. Subscribe to our newsletter or follow us on LinkedIn to get these insights delivered directly to your inbox, because staying informed isn’t just a nice-to-have anymore: it’s a must-have.
Josh Bressers is Vice President of Security at Anchore where he guides security feature development for the company’s commercial and open source solutions. He serves on the Open Source Security Foundation technical advisory council and is a co-founder of the Global Security Database project, which is a Cloud Security Alliance working group that is defining the future of security vulnerability identifiers.
Learn about the role that SBOMs for the security of your organization in this white paper.
If you’re just joining us, this is part 2 of a series on practical implementation of software supply chain security to meet the most recent SBOM compliance requirements. In Part 1, we covered the fundamentals of automated SBOM generation—from deployment options to registry integration to vulnerability analysis across any container infrastructure. With your SBOMs now flowing into Anchore Enterprise, the real compliance value begins to emerge.
Part 2 focuses on the operational aspects that turn SBOM data into actionable compliance outcomes:
automated policy evaluation,
custom rule creation for your specific regulatory requirements, and
comprehensive reporting that satisfies auditors while providing actionable insights for development teams.
Whether you’re pursuing PCI DSS 4.0 compliance, preparing for the EU Cyber Resilience Act, or building frameworks for future regulatory requirements, these capabilities transform compliance from overhead into competitive advantage.
Learn about the role that SBOMs for the security of your organization in this white paper.
With high fidelity SBOMs now present in Anchore Enterprise, the system will automatically perform policy evaluations against them. This is important in order to establish a baseline for container image compliance with checks against various policies.
NOTE: When a container image is added, policy compliance checks are automatically applied against the SBOM in accordance with the default policy.
In the Anchore Enterprise UI, navigate to an image. The first page visible will be the policy and compliance evaluation summary. From here you can inspect the policy evaluation results and the recommended action by the policy, for example the rule which was triggered and the resultant action (such as STOP or WARN):
You may wish to export a compliance report to deliver feedback to application teams or other stakeholders, asking them to please fix or remediate these items. You can get this report from the UI at the click of a button:
NOTE: A compliance report can be downloaded in either json or csv format.
With application teams busy taking remedial action, they can build a new image and Anchore Enterprise can generate an SBOM from this and conduct another policy evaluation.
NOTE: It’s possible to watch a given tag which will ensure whenever a new version is pushed, it will be automatically scanned by Anchore Enterprise.
You can also use the CLI and API (via AnchoreCTL) for checking your container SBOM (for compliance). This is particularly useful when working with Anchore Enterprise and SBOMS in the development pipeline. To conduct a policy check on a newly built image, run the following command to compare with the default policy:
NOTE: The AnchoreCTL utility supports exporting the results in various formats (i.e., json, text, csv, json-raw, and id) with the -o flag. Text is the default format.
Both UI and CLI (AnchoreCTL) compliance management are described in further detail here.
Customising Policy (for compliance posture)
Using Anchore Enterprise’s policy engine, you can build a set of custom rules which map to your own organizational policy. Alternatively, if you are pursuing FedRAMP compliance, you can use optional policy packs which are available as addons for the product.
NOTE: Multiple policies are supported by Anchore Enterprise. However, only one policy can be set as active/default at any time.
In order to build or customize your own policy, you can navigate to the desired policy and begin editing the rulesets.
From the Policies (UI) page, you can view any policies listed under Policy Manager and select a given policy for editing.
When editing a policy, you can then view all rulesets associated with it and select a ruleset for editing.
When editing a ruleset, the recommended actions (STOP/WARN/GO) can be modified when a ruleset is triggered on policy evaluation.
The ruleset parameters can also be modified to change the existing values.
You can also use CLI tooling to gather certain aspects related to a policy.
To list all policies both active and inactive:
$ anchorectl policy list
To list the rulesets associated with a policy (including names and actions):
$ anchorectl policy get <The policy name or ID>
Downloading Account-Wide Compliance Reports
Sometimes you need to demonstrate your compliance with policy at the account-level or across multiple accounts. Anchore Enterprise allows you to do just that with its Reporting feature. Anchore Enterprise Reports as it’s known aggregates data across all accounts to:
Maintain a summary of all current and historical images/tags, and
Maintain vulnerability reports and policy evaluations for these respective images and tags.
From the Reports (UI) page, you can generate a “New Report” based on pre-defined system templates and filters.
The first dropdown allows you to select one of the included templates for generating a report.
In turn, the second dropdown allows you to select one or more report filters.
After selecting your template and report filter(s), you can also toggle between generating a report for the account you’re logged into or for all accounts.
From the “Templates” tab, you can view all the current system templates or even any custom templates as you have the capability to create your own (templates).
Once you’re ready to generate a report, it can either be downloaded in csv or json (native/raw) format or saved for later reference and run later either ad-hoc or on a schedule.
NOTE: Reporting is described in further detail here.
Wrap-Up
The journey from SBOM generation to automated compliance demonstrates how regulatory requirements can drive meaningful security improvements rather than just administrative overhead. Organizations that embrace this automated approach aren’t just meeting current compliance deadlines—they’re building resilient supply chain security practices that scale with their business growth.
Throughout this two-part series, we’ve seen how Anchore Enterprise transforms complex regulatory requirements into manageable, automated workflows. From initial SBOM generation across diverse container registries to sophisticated policy enforcement and comprehensive reporting, the platform provides continuous visibility into security risks while streamlining compliance processes.
The strategic advantage becomes clear when comparing manual approaches to automated SBOM management. Manual processes create bottlenecks that slow development cycles and generate compliance debt that compounds over time. Automated approaches integrate compliance checking into existing workflows, providing real-time feedback that helps development teams build more secure applications from the start.
As regulatory requirements continue expanding globally, organizations with robust SBOM management capabilities will find themselves better positioned to adapt quickly to new requirements. The foundation built for PCI DSS 4.0 and EU Cyber Resilience Act compliance provides the framework needed for whatever regulatory changes emerge next.
The choice facing organizations today isn’t whether to implement SBOM management—it’s whether to build sustainable, automated practices that turn compliance into competitive advantage or to continue with manual approaches that become more unsustainable with each new regulatory requirement. The 2025 compliance deadlines mark the beginning of this new reality, not the end.
Explore SBOM use-cases for almost any department of the enterprise and learn how to unlock enterprise value to make the most of your software supply chain.
When Log4Shell hit, one Anchore Enterprise customer faced the same nightmare scenario as thousands of organizations worldwide: Where is log4j hiding in our infrastructure?
The difference? While most organizations spent weeks manually hunting through systems, this customer ran a single API command and identified every instance of log4j across their entire environment in five minutes.
That’s the transformation Josh Bressers (VP of Security, Anchore) and Brian Thomason (Solutions Engineering Manager, Anchore) demonstrated in their recent webinar on rapid incident response to zero-day vulnerabilities—and it represents a fundamental shift in how security teams can respond to critical threats.
TL;DR:Traditional vulnerability management treats SBOMs as compliance artifacts, but modern incident response requires treating them as operational intelligence.
This technical deep-dive covers three critical scenarios that every security team will face:
Proactive Threat Hunting: How to identify vulnerable components before CVE disclosure using SBOM archaeology
Runtime Vulnerability Prioritization: Real-time identification of critical vulnerabilities in production Kubernetes environments
CI/CD Security Blindness: The massive attack surface hiding in build environments that most teams never scan
Ready to see the difference between reactive firefighting and strategic preparation? Keep reading for the technical insights that will change how you approach zero-day response.
The CUPS Case Study: Getting Ahead of Zero-Day Disclosure
In September 2024, security researchers began dropping hints on Twitter about a critical Linux vulnerability affecting systems “by default.” No CVE. No technical details. Just cryptic warnings about a two-week disclosure timeline.
The security community mobilized to solve the puzzle, eventually identifying CUPS as the target. But here’s where most organizations hit a wall: How do you prepare for a vulnerability when you don’t know what systems contain the affected component?
Traditional approaches require manual system audits—a process that scales poorly and often misses transitive dependencies buried deep in container layers. The SBOM-centric approach inverts this narrative.
“One of the examples I like to use is when log4j happened, we have an Anchore enterprise customer that had all of their infrastructure stored inside of Anchore Enterprise as SBOMs. Log4Shell happens and they’re like, holy crap, we need to search for log4Shell. And so we’re like, ah, you can do that here, run this command. And literally in five minutes they knew where every instance of log4j was in all of their environments.“ —Josh Bressers, VP of Security, Anchore
The Technical Implementation
What was the command they used? The webinar demonstrates this live against thousands of stored SBOMs to locate CUPS across an entire infrastructure:
This single command returns every container image containing CUPS, complete with version information, registry details, and deployment metadata. The query executes against historical and current SBOMs, providing comprehensive coverage across the entire software supply chain.
Security teams can begin impact assessment and remediation planning before vulnerability details become public, transforming reactive incident response into proactive threat management.
What Else You’ll Discover
This proactive discovery capability represents just the foundation of a comprehensive demonstration that tackles the blind spots plaguing modern security operations.
Runtime Vulnerability Management: The Infrastructure You Don’t Control
Josh revealed a critical oversight in most security programs; vulnerabilities in Kubernetes infrastructure components that application teams never see.
The demonstration focused on a critical CVE in the nginx ingress controller—infrastructure deployed by SRE teams but invisible to application security scans. Using Anchore Enterprise’s Kubernetes runtime capabilities, the team showed how to:
Identify running containers with critical vulnerabilities in real-time
Prioritize remediation based on production deployment status
Bridge the visibility gap between application and infrastructure security
“I could have all of my software tracked in Anchore Enterprise and I wouldn’t have any insight into this — because it wasn’t my code. It was someone else’s problem. But it’s still my risk.” —Josh Bressers, VP of Security, Anchore
CI/CD Archaeology: When the Past Comes Back
The most eye-opening demonstration involved scanning a GitHub Actions runner environment—revealing 13,000 vulnerabilities across thousands of packages in a standard build environment.
The technical process showcased how organizations can:
Generate comprehensive SBOMs of build environments using filesystem scanning
Maintain historical records of CI/CD dependencies for incident investigation
“This is literally someone else’s computer building our software, and we might not know what’s in it. That’s why SBOM archaeology matters.” —Josh Bressers, VP of Security, Anchore
Why SBOMs Are the Strategic Differentiator
Four truths stood out:
Speed is critical: Minutes, not months, decide outcomes.
Visibility gaps are real: Runtime and CI/CD are blind spots for most teams.
History matters: SBOMs are lightweight evidence when past build logs are gone.
Automation is essential: Manual tracking doesn’t scale to millions of dependencies.
Or as Josh put it:
“Storing images forever is expensive. Storing SBOMs? Easy. They’re just JSON documents—and we’re really good at searching JSON.”
The Bottom Line: Minutes vs. Months
When the next zero-day hits your infrastructure, will you spend five minutes identifying affected systems or five months hunting through manual inventories?
The technical demonstrations in this webinar show exactly how SBOM-driven incident response transforms security operations from reactive firefighting into strategic threat management. This is the difference between organizations that contain breaches and those that make headlines.
For the last 7 years CISA has been one of the major public stewards of SBOMs – publishing many whitepapers, hosting a multitude of meetings, and evangelizing the term so nearly everyone in the industry now recognizes. For those of us who have been working in the SBOM community over the years, one of the best meetings was a Monday morning SBOM community call (morning if you’re in the US, not morning most everywhere else on the planet). The agenda usually started with an informal discussion about news and events and moved to a semi formal presentation about a tool or idea that was being worked on. Occasionally the discussions lasted the entire hour and the topics were always informative and interesting.
As the world of SBOMs has grown, one of the biggest challenges is just keeping track of everything; There are too many events, tools and talks and it is impossible for one person to be on top of it all. And that’s why the Monday community meeting was so useful to its attendees. Even if you weren’t trying to actively keep track of the SBOM universe, the SBOM universe would come to you!
Unfortunately the Monday community meeting has recently been discontinued. It’s tough to keep a meeting like this going, especially for many years, so hats off to CISA for all the hard work! That meeting shall be missed, but we can all respect the need to focus the existing resources to better align with the CISA mission.
But given how valuable the CISA meeting has been, a few of us at the OpenSSF have decided we miss the meeting and would like to keep it going. So the OpenSSF SBOM Coffee Club has been started! Same time on Monday as the CISA meeting (11am Eastern). The format is going to be exactly the same: Show up, discuss the latest news and happenings and share interesting SBOM related events. Just like the CISA list of SBOM events, this one will be pretty flexible and only need to be vaguely SBOM related to deserve a mention.
One of the often overlooked aspects of building a community are the little things that bring everyone together. I’ve been part of many communities over the years, I am honored to be part of the SBOM community now. While our community is built on top of SBOMs, that’s not enough to keep everyone connected. We need a place to discuss topics, share experiences, and talk about new things and ideas, and most importantly, let new people find us. That was the Monday SBOM call. It’s important to me and others to keep a place going that can help the existing community thrive and bring in new people in a safe and welcoming way.
Everyone is welcome, it doesn’t matter if you’re not an OpenSSF member. The invite is available on the OpenSSF public calendar (it’s pretty full of events, look for “OpenSSF SBOM Coffee Club” on Monday. You are welcome to check out the notes document. This will be updated before and during the meeting each week. Even if you don’t attend you are welcome to keep track of what’s happening from the meeting notes. We’ve quite literally copied the events list from the last CISA call and we are going to keep it updated.
I hope to see you at a future meeting to learn, to share and evangelize. I promise you will learn something. And if you have an idea to present, or a tool, or anything really, reach out to the group. See you next Monday!
2025 has become the year of SBOM compliance deadlines. March 31st marked PCI DSS 4.0’s enforcement date, requiring payment processors to maintain comprehensive inventories of all software components. Meanwhile, the EU’s Cyber Resilience Act takes full effect in August 2027, but organizations selling products with digital elements in Europe must start preparing now—meaning SBOM implementation can’t wait.
These aren’t isolated regulatory experiments—they’re the latest milestones in a global trend that shows no signs of slowing. As regulatory bodies worldwide continue to steadily drive SBOM adoption, organizations face a stark choice: accept this new reality and commit to comprehensive software supply chain security, or get left behind by competitors who embrace transparency as a competitive advantage.
The urgency is real, but so is the solution. Anchore Enterprise serves as the “easy button” for organizations looking to comply with both newly updated frameworks while building a foundation for whatever regulatory requirements come next. Rather than scrambling to manually catalog software components or piece together makeshift compliance solutions, organizations can automate SBOM generation and analysis across their entire container portfolio.
Explore SBOM use-cases for almost any department of the enterprise and learn how to unlock enterprise value to make the most of your software supply chain.
Anchore Enterprise is a self-hosted SBOM management solution that can be deployed across various cloud and on-premises environments. It’s available as cloud images for appliance-like experiences or in container form for deployment to Kubernetes clusters. For organizations using cloud platforms, this might mean deploying on Amazon EC2, Azure VMs, or Google Compute Engine. For Kubernetes users, deployment options include hyper-scaler Kubernetes engines or on-premises Kubernetes distributions.
Deployment Options:
Cloud Image Deployment: Available as AMIs for AWS EC2, similar images for other cloud providers
Container Deployment: Helm charts for any Kubernetes cluster (cloud or on-premises)
Above: A typical Container Image deployment on Amazon EKS
With Anchore Enterprise deployed in your environment, you can immediately start generating SBOMs for software in your repositories by scanning container registries or uploading SBOMs directly via API, CLI and UI import mechanisms. With stored SBOMs, Anchore Enterprise provides a comprehensive view into your software contents, issuing alerts to developers or security teams on vulnerabilities or content drift. Policy-based enforcement allows you to act on vulnerabilities in content or content from unapproved sources and vendors. Searches can be performed on any metadata contained within the SBOM to enable fast response during zero day situations such as the infamous Log4j.
Full details on how to deploy the solution can be found here.
SBOM Generation Methods
Anchore Enterprise supports two primary SBOM generation approaches that work with any container registry:
Distributed Scanning: The SBOM is generated using a command line tool, AnchoreCTL (based on the Syft open source project). This tool is typically invoked in CI/CD pipelines but can also be run on developer workstations. The resulting SBOM is then uploaded to the Anchore Enterprise API for processing. This approach works regardless of your registry provider.
Centralized Scanning: Anchore Enterprise retrieves container images from registries either as one-time operations or on an ongoing basis using repository or tag subscriptions. The SBOM is then generated from the retrieved image within the Anchore Enterprise deployment itself. This method supports all major container registries with appropriate authentication.
For this walkthrough, we’ll demonstrate centralized scanning using Amazon ECR as an example, but the same principles apply to other container registries.
Connecting to Container Registries
Before importing images for SBOM generation, Anchore Enterprise requires access to your container registries. The authentication method varies by registry type:
For Cloud Registries:
AWS ECR: IAM roles, access keys, or service account integration
Azure ACR: Service principals, managed identity, or access tokens
Google GCR/Artifact Registry: Service accounts or workload identity
Docker Hub: Username/password or access tokens
For Private Registries:
Harbor, Quay, Nexus: Username/password, certificates, or token-based authentication
Example: Configuring Amazon ECR Access
For cloud Kubernetes deployments, Anchore Enterprise can leverage cloud-native authentication. For AWS, this might involve IAM roles presented to Kubernetes Service Accounts. Other cloud providers offer similar mechanisms (Azure managed identity, Google workload identity).
With appropriate permissions configured, add your registry:
# For AWS ECR
$ ANCHORECTL_REGISTRY_PASSWORD=awsauto anchorectl registry add \
your_account_id.dkr.ecr.region.amazonaws.com \
--username awsauto --type awsecr
# For other registries, authentication varies:
# Docker Hub
$ anchorectl registry add docker.io --username your_username
# Harbor
$ anchorectl registry add your-harbor.company.com --username harbor_user
# Confirm the registry has been added:
$ anchorectl registry list
The Anchore Enterprise UI also provides a visual interface for managing registry credentials across all supported registry types.
Generating SBOMs from Container Images
With registry access configured, you can begin adding container images for SBOM generation. This process is consistent regardless of your registry provider:
# Add images from any supported registry
$ anchorectl image add registry_url/repository:tag
# Examples for different registries:
# AWS ECR
$ anchorectl image add aws_account_id.dkr.ecr.region.amazonaws.com/repository:tag
# Azure ACR
$ anchorectl image add myregistry.azurecr.io/myapp:v1.0
# Google GCR
$ anchorectl image add gcr.io/my-project/myapp:v1.0
# Harbor
$ anchorectl image add harbor.company.com/project/myapp:v1.0
Anchore Enterprise will download the image from your registry, unpack and analyze it, then store the comprehensive SBOM in its database. You can also add annotations during scanning for better organization:
$ anchorectl image add registry_url/repository:tag --annotation owner=team-alpha
# Verify images have been added:
$ anchorectl image list
Both UI and CLI (AnchoreCTL) image analysis are described in further detail here.
Inspecting Container SBOMs for Vulnerabilities
Once SBOMs are stored in Anchore Enterprise, you can analyze their contents through both UI and CLI interfaces. The analysis capabilities remain consistent regardless of the source registry.
With your SBOMs now stored in Anchore Enterprise, you can view the respective contents through the UI by clicking on the image digest:
Next, click on the Vulnerabilities (UI) tab to see a list of vulnerabilities present in this image. From here you can toggle on/off severity or OS/non-OS CVEs. You can also download the vulnerability report for both the entire image or a particular vulnerability itself. Doing the latter will allow you to find all other images impacted by this vulnerability!
You can also use the CLI tooling for this purpose, using the flag for all vulnerability types:
# View all vulnerabilities in an image
$ anchorectl image vulnerabilities registry_url/repository:tag -t all
# Export vulnerability data for further processing
$ anchorectl image vulnerabilities registry_url/repository:tag -o json > vuln_report.json
NOTE: You can also reference the unique digest in your CLI commands.
The vulnerability data includes detailed information about affected packages, severity scores, available fixes, and impact assessments that help prioritize remediation efforts.
Inspecting Container SBOMs for Additional Content
You can also use the SBOM as a mechanism to inspect the image for other contents, such as files, malware or secrets:
NOTE: SBOMs can be exported in either Native JSON (Syft), SPDX, or CycloneDX format.
Alternatively, you can use the CLI and API (via AnchoreCTL) for inspecting your container SBOM (for vulnerabilities).
To view all available content types cataloged in the SBOM, use the -a flag:
$ anchorectl image content aws_account_id.dkr.ecr.region.amazonaws.com/repository:tag -a
To list secrets which may have been located in the image:
NOTE: SBOMs can be exported via the UI or AnchoreCTL for external use.
What’s Next
In Part 2 of this series, we’ll explore how to leverage these SBOMs for automated compliance checking, policy enforcement, and comprehensive reporting across your entire container portfolio. We’ll cover how to customize policies for your organization’s specific compliance requirements and generate the reports needed for audit and governance purposes.
This is Part 1 of a 2-part series on automated SBOM management. [Continue to Part 2: Compliance and Policy Management →]
Learn about the role that SBOMs for the security of your organization in this white paper.
Powered by Anchore’s Syft & Grype, IBM’s Platform Development Environment Factory delivers DevSecOps-as-a-Service for federal agencies seeking operational readiness without the integration nightmare.
Federal agencies are navigating a complex landscape: while DevOps has delivered on its promise of increased velocity, modern compliance frameworks like EO 14028 and continuous Authority to Operate (cATO) requirements introduce new challenges that demand sophisticated DevSecOps practices across civilian agencies and the Defense Industrial Base (DIB). For many teams, maintaining both speed and compliance requires careful orchestration of security tools, visibility platforms, and audit processes that can impact development resources.
The challenge often lies in implementation complexity. Software development platforms built from disparate components that should integrate seamlessly often require significant customization work. Teams can find themselves spending valuable time on integration tasks—configuring YAML files, writing connectivity code, and troubleshooting compatibility issues—rather than focusing on mission-critical capabilities. Building and managing a standards-compliant DevSecOps platform requires specialized expertise to deliver the reliability that developers need, while compliance audit processes add operational overhead that can slow time to production.
Net effect: Projects stall in glue-code purgatory long before a single security control is satisfied.
IBM Federal’s PDE Factory changes this equation entirely. This isn’t another pick-your-own-modules starter repository—it’s a fully composed DevSecOps platform you can deploy in hours, not months, with SBOM-powered supply chain security baked into every layer.
Challenge: Tool Sprawl Meets Compliance Deadlines
An application stack destined for federal deployment might need a vulnerability scanner, SBOM generator, signing service, policy engine, and runtime monitoring—each potentially from different vendors. Development teams burn entire sprints wiring these modules together, patching configuration files, and writing custom integration code to resolve subtle interoperability issues that surface during testing.
Every integration introduces fresh risk. Versions drift between environments. APIs break without warning. Documentation assumes knowledge that exists nowhere in your organization. Meanwhile, compliance frameworks like NIST’s Secure Software Development Framework (SSDF) demand comprehensive coverage across software bill of materials (SBOM) generation, continuous vulnerability management, and policy enforcement. Miss one pillar, and the entire compliance review fails.
DIY Integration Pain
Mission Impact
Fragmented visibility
Vulnerability scanners can’t correlate with registry contents; audit trails become patchwork documentation spread across multiple systems.
Context-switching overhead
Engineers toggle between six different UIs and CLI tools to trace a single CVE from detection through remediation.
Late-stage discovery
Critical security issues surface after artifacts are already staged for production, triggering war-room incidents that halt deployments.
Compliance scramble
Evidence collection requires manual log parsing and screenshot gathering—none of it standardized, signed, or audit-ready.
The US Air Force Platform One learned the lessons above early. Their container ecosystem, now secured with Anchore Enterprise, required extensive tooling integration to achieve the operational readiness standards demanded by mission-critical workloads. Similarly, Iron Bank—the DoD’s hardened container repository—relies on Anchore Enterprise to maintain the security posture that defense contractors and military units depend on for operational continuity.
Solution: A Pre-Wired Factory, No Yak-Shaving Required
IBM Federal’s PDE Factory eliminates the integration nightmare by delivering a fully composed DevSecOps platform deployable in hours rather than months. This isn’t about faster setup—it’s about operational readiness from day one.
Architecture at a glance:
GitLab CI orchestrates every build with security gates enforced at each stage
Harbor registry stores signed container images with embedded SBOMs
Argo CD drives GitOps-based deployments into production Kubernetes clusters
Terraform automation executes the entire stack deployment with enterprise-grade reliability
Syft & Grype by Anchore: comes integrated with the PDE Factory giving users SBOM-powered vulnerability scanning “out of the box”
Outcome: A production-ready DevSecOps environment that supports the code-to-cloud kill chain federal agencies need, deployable in hours instead of the weeks-to-months typical of greenfield builds.
Anchore Inside: The SBOM Backbone
Before any container image reaches your registry, Anchore’s battle-tested supply chain tools attach comprehensive security and compliance metadata that travels through your entire deployment pipeline.
How the integration works:
Syft performs deep software composition analysis, cataloging every component down to transitive dependencies and generating standards-compliant SBOMs
Grype ingests those SBOMs and enriches them with current vulnerability data from multiple threat intelligence feeds
Policy enforcement blocks non-compliant builds before they can compromise downstream systems
Evidence collection happens automatically—when auditors arrive, you hand them signed JSON artifacts instead of manually compiled documentation
SBOM = portable mission truth. Because SBOMs are machine-readable and cryptographically signed, PDE Factory can automate both rapid “shift-left” feedback loops and comprehensive audit trail generation. This aligns directly with CISA’s Secure by Design initiative—preventing insecure builds from entering the pipeline rather than detecting problems after deployment.
The US Navy’s Black Pearl Factory exemplifies this approach in action. Working with Sigma Defense, they reduced audit preparation time from three days of manual evidence gathering to two minutes of automated report generation—a force multiplier that redirects valuable engineering resources from compliance overhead back to mission delivery.
Day-in-the-Life: From Commit to Compliant Deploy
Here’s how operational readiness looks in practice:
Developer commits code to GitLab, triggering the automated security pipeline
Container build includes Syft SBOM generation and cryptographic signing
Grype vulnerability scanning correlates SBOM components against current threat data
Policy gates enforce NIST SSDF requirements before allowing registry promotion
Argo CD deployment validates runtime security posture against DoD standards
Kubernetes admission controller performs final compliance verification using stored SBOM and vulnerability data
Result: A hardened deployment pipeline that maintains operational readiness without sacrificing development velocity.
For agencies requiring enhanced security posture, upgrading to Anchore Enterprise unlocks Compliance-as-a-Service capabilities:
Open Source Foundation
Anchore Enterprise Upgrade
Operational Advantage
Syft & Grype
Anchore Secure with centralized vulnerability management
Hours saved on manual CVE triage and false positive elimination
Basic policy enforcement
Anchore Enforce with pre-built SSDF, DISA, and NIST policy packs
Accelerated ATO timelines through automated compliance validation
Manual evidence collection
Automated audit trail generation
Weeks removed from compliance preparation cycles
Operational Payoff: Mission Metrics That Matter
Capability Metric
DIY Integration Approach
IBM PDE Factory
Platform deployment time
45-120 days
< 8 hours
Security rework percentage per sprint
~20%
< 5%
Critical vulnerability MTTR
~4 hours
< 1 hour
Audit preparation effort
Weeks of manual work
Automated nightly exports
This isn’t just about developer productivity—it’s about mission continuity. When federal agencies can deploy secure software faster and maintain compliance posture without operational overhead, they can focus resources on capabilities that directly serve citizens and national security objectives.
Your Operational Readiness Path Forward
Federal agencies have an opportunity to streamline their development processes by adopting proven infrastructure that the DoD already trusts.
IBM Federal’s PDE Factory, powered by Anchore’s SBOM-first approach, delivers the operational readiness federal agencies need while reducing the integration complexity that often challenges DevSecOps initiatives. Start with the open source foundation—Syft and Grype provide immediate value. Scale to Anchore Enterprise when you need Compliance-as-a-Service capabilities that accelerate your Authority to Operate timeline.
Ready to see proven DoD software factory security in action?
Anchore brings deep expertise in securing mission-critical software factories across the Department of Defense, from Platform One to Iron Bank to the Navy’s Black Pearl Factory. Our battle-tested SBOM-powered approach has enabled DoD organizations to achieve operational readiness while maintaining the security standards required for defense environments.
Book an Anchore Enterprise demo to see how our proven software supply chain security integrates with IBM’s PDE Factory to deliver “no SBOM, no deploy” enforcement without compromising development velocity.
Fortify your pipeline. Harden your releases. Accelerate your operational readiness.
The mission demands secure software. Your developers deserve tools that deliver it.
Learn how to harden your containers and make them “STIG-Ready” with our definitive guide.
An exclusive look at insights from the ITGRC Forum’s latest webinar on demonstrating the value of cybersecurity investments.
Three cybersecurity veterans with a combined 80+ years of experience recently gathered for a Forum webinar that challenged everything we thought we knew about the funding of enterprise security investments.
Colin Whitaker (30+ years, Informed Risk Decisions),
Paulo Amarol (Senior Director GRC, Diligent),
Dirk Shrader (25+ years, Netwrix), and
Josh Bressers (VP Security, Anchore) delivered insights that explain why some organizations effortlessly secure millions for security initiatives while others struggle for basic tool budgets.
The central revelation?Compliance isn’t just regulatory burden—it’s become the primary pathway for security investment in modern enterprises.
The 75-minute discussion covered critical territory for any security or GRC professional trying to demonstrate value to leadership:
When Compliance Became the Gateway to Security Investment: How regulatory requirements transformed from cost centers to business enablers
The Software Supply Chain Compliance Revolution: Why SBOM mandates are forcing visibility that security teams have wanted for decades
Death by a Thousand Cuts: The Hidden Costs of Fragmented Compliance: The true operational impact of manual compliance processes
The Future of Compliance-Driven Security Investment: Where emerging regulations are heading and how to get ahead
Not ready to commit to a full webinar? Keep reading to get a taste for the discussion and how it will change your perspective on the relationship between cybersecurity and regulatory compliance.
⏱️ Can’t wait till the end? 📥 Watch the full webinar now 👇👇👇
When Compliance Became the Gateway to Security Investment
For decades, security professionals have faced an uphill battle for executive attention and funding. While IT budgets grew and development teams expanded, security often fought for scraps—forced to justify theoretical risks against concrete revenue opportunities.
Traditional security arguments relied on preventing abstract future threats. Leadership heard endless presentations about potential breaches, theoretical vulnerabilities, and statistical possibilities.
When the business is deciding between allocating resources toward revenue-generating features that will generate an ROI in months versus product security features that will reduce—BUT never eliminate—the possibility of a breach; it’s not difficult to figure out how we got into this situation. Meanwhile, regulatory compliance offered something security never could: immediate business necessity.
Modern compliance frameworks (e.g., EU CRA, DORA, NIS2) invert this narrative by making penalties certain, quantifiable, and time-sensitive. Annual non-compliance penalties and the threat of losing access to sell into European markets shift the story from “possible future breach” to “definite revenue loss.”
“I think now that there’s regulators saying you have to do this stuff or you can’t sell your product here now we have business incentive right because just from a purely practical perspective if a business can’t sell into one of the largest markets on the planet that has enormous consequences for the business.” —Josh Bressers, VP of Security, Anchore
Not only does modern regulatory compliance create the “financial teeth” needed to align business incentives but it has also evolved the security requirements to be at parity with current DevSecOps best practices. The days of laughable security controls and checkbox compliance are past. Modern laws are now delivering on the promise of “Trust, but verify.”
The Strategic Partnership Opportunity
These two fundamental changes—business-aligned incentives and technically sound requirements—create an unprecedented opportunity for security and compliance teams to partner in reducing organizational risk. Rather than working in silos with competing priorities, both functions can now pursue shared objectives that directly support business goals.
Security teams gain access to executive attention and budget allocation through compliance mandates. Compliance teams benefit from security expertise and automation capabilities that reduce manual audit overhead. Together, they can implement comprehensive risk management programs that satisfy regulatory requirements while building genuine security capabilities.
The result transforms both functions from cost centers into strategic business enablers—compliance ensures market access while security protects the operations that generate revenue.
“However when security and compliance work together now security has a story they can start to tell that gets you the funding you need that get you the support you need from your leadership.” —Josh Bressers, VP of Security, Anchore
What Else You’ll Discover in the Full Webinar
This transformation in security funding represents just one thread in a comprehensive discussion that tackles the most pressing challenges facing security and GRC professionals today.
The Software Supply Chain Compliance Revolution
Josh Bressers reveals why organizations with proper SBOM capabilities identified Log4j vulnerabilities in 10 minutes while others needed 3 months—and how compliance mandates are finally forcing the software supply chain visibility security teams have wanted for decades.
“Between 70-90% of all code is open source [and] … 95% of products have open source inside of them. The numbers are just absolutely staggering.” —Josh Bressers, VP of Security, Anchore
Death by a Thousand Cuts: The Hidden Costs of Fragmented Compliance
Dirk Shrader breaks down the operational disruption costs that 54% of organizations recognize but haven’t calculated, including the “mangled effort” of manual compliance processes that diverts skilled staff from strategic initiatives.
“Security and IT teams spend excessive time pulling data from disparate systems: correlating activities, generating audit reports … chasing that individual rabbit.” —Dirk Shrader, Global VP Security Research, Netwrix
The Future of Compliance-Driven Security Investment
Paulo Amarol demonstrates how GRC platforms are evolving from “evidence lockers” into strategic business intelligence systems that translate technical security data into executive-ready risk assessments.
“We’re able to slice and combine data from various sources—apps, operational security tooling, awareness training, even identity provider data—in ways that our leaders can bring this risk data into their decision-making. You can really automate the process of bringing data in, normalizing it, and mapping it to bigger picture strategic risks.” —Paulo Amarol, Senior Director GRC, Diligent Corporation
The panelists also explore:
Poll insights revealing where most organizations stand on compliance cost calculations
Regulatory proliferation across global markets and how to find common ground
Automation imperatives for continuous compliance monitoring
Cultural transformation as security and GRC functions converge
Implementation strategies for aligning security programs with business objectives
Ready to Transform Your Security Investment Strategy?
This isn’t another theoretical discussion about security ROI. It’s a practical guide from practitioners who’ve solved the funding challenge by repositioning security as a compliance-driven business enabler.
Stay ahead of the compliance-security convergence: Follow Anchore on LinkedIn and Bluesky for ongoing analysis of emerging regulations, industry trends, and practical implementation guidance from software supply chain security experts.
Subscribe to our newsletter for exclusive insights on SBOM requirements, compliance automation, and the strategic intersection of security and regulatory requirements.
The convergence of security and compliance isn’t just happening—it’s accelerating. Don’t get left behind.
Explore SBOM use-cases for almost any department of the enterprise and learn how to unlock enterprise value to make the most of your software supply chain.
Just as the open source software revolution fundamentally transformed software development in the 2000s—bringing massive productivity gains alongside unprecedented supply chain complexity—we’re witnessing history repeat itself with Large Language Models (LLMs). The same pattern that caused organizations to lose visibility into their software dependencies is now playing out with LLMs, creating an entirely new category of supply chain risk.
Not to worry though, The Linux Foundation has been preparing for this eventuality. SPDX 3.0 provides the foundational metadata standard needed to extend proven DevSecOps practices to applications that integrate LLMs.
By introducing AI and Dataset Profiles, it enables organizations to apply the same supply chain security practices that have proven effective for software dependencies to the emerging world of AI supply chains. History may be repeating itself but this time, we have the opportunity to get ahead of it.
LLMs Create New Supply Chain Vulnerabilities That Traditional Security Tools Can’t Grok
The integration of LLMs into software applications has fundamentally altered the threat landscape. Unlike traditional software vulnerabilities that exploit code weaknesses, LLM-era attacks target the unique characteristics of AI systems:
their training data is both data and code, and
their behavior (i.e., both data and code) can be manipulated by users.
This represents a paradigm shift that requires security teams to think beyond traditional application security.
LLMs merge data and code + a second supply chain to secure
LLMs are fundamentally different from traditional software components. Where conventional code follows deterministic logic paths. LLMs operate on statistical patterns learned from “training” on datasets. This fundamental difference creates a new category of “code” that needs to be secured—not just the model weights and architecture, but the training data, fine-tuning datasets, and even the prompts that guide model behavior.
When organizations integrate LLMs into their applications, they’re not just adding another software dependency. They’re creating an entire second supply chain—the LLM data supply chain—that operates alongside their traditional software supply chain.
The challenge is that this new supply chain operates with fundamentally different risk patterns. Where software vulnerabilities are typically discrete and patchable, AI risks can be subtle, emergent, and difficult to detect.
A single compromised dataset can introduce bias that affects all downstream applications.
A prompt injection attack can manipulate model behavior without touching any traditional code.
Model theft can occur through API interactions that leave no trace in traditional security logs.
Data poisoning and model theft: Novel attack vectors
The emergence of LLMs has introduced attack vectors that simply didn’t exist in traditional software systems, requiring security teams to expand their threat models and defensive strategies.
Data Poisoning Attacks represent one of the most intractable new threat categories. Training data manipulation can occur at multiple points in the AI supply chain.
Consider this: what’s stopping a threat actor from modifying a public dataset that’s regularly used to train foundational LLM models? Popular datasets hosted on platforms like Hugging Face or GitHub can be edited by contributors, and if these poisoned datasets are used in model training, the resulting models inherit the malicious behavior.
RAG poisoning attacks take this concept further by targeting the retrieval systems that many production LLM applications rely on. Attackers can create SEO-optimized content and embed hidden text with instructions designed to manipulate the model’s behavior.
When RAG systems retrieve this content as context for user queries, the hidden instructions can override the model’s original alignment, leading to unauthorized actions or information disclosure. Recent research has demonstrated that attackers can inject as few as five poisoned documents into datasets of millions and achieve over 90% success rates in manipulating model outputs.
Model Theft and Extraction attacks exploit the API-accessible nature of modern LLM deployments. Through carefully crafted queries, attackers can extract valuable intellectual property without ever accessing the underlying model files. API-based extraction attacks involve sending thousands of strategically chosen prompts to a target model and using the responses to train a “shadow model” that replicates much of the original’s functionality.
Self-instruct model replication takes this further by using the target model to generate synthetic training data, effectively teaching a competitor model to mimic the original’s capabilities.
These attacks create new categories of business risk that organizations must consider. Beyond traditional concerns about data breaches or system availability, LLM-integrated applications face risks of intellectual property theft, reputational damage from biased or inappropriate outputs, and regulatory compliance violations in increasingly complex AI governance environments.
Enterprises are losing supply chain visibility as AI-native applications grow
Organizations are mostly unaware of the fact that the data supply chain for LLMs is equally as important to track as their software supply chain. As teams integrate foundation model APIs, deploy RAG systems, and fine-tune models for specific use cases, the complexity of LLM data supply chains is exploding.
Traditional security tools that excel at scanning software dependencies for known vulnerabilities are blind to LLM-specific risks like bias, data provenance, or model licensing complications.
This growing attack surface extends far beyond what traditional application security can address. When a software component has a vulnerability, it can typically be patched or replaced. When an AI model exhibits bias or has been trained on problematic data, the remediation may require retraining, which can cost millions of dollars and months of time. The stakes are fundamentally different, and the traditional reactive approach to security simply doesn’t scale.
So how do we deal with this fundamental shift in how we secure supply chains?
The answer is—unsurprisingly—SBOMs. But more specifically, next-generation SBOM formats like SPDX 3.0. While Anchore doesn’t have an official tagline, if we did, there’s a strong chance it would be “you can’t secure your supply chain without knowing what is in it.” SPDX 3.0 has updated the SBOM standard to store AI model and dataset metadata, extending the proven principles of software supply chain security to the world of LLMs.
AI Bill of Materials: machine-readable security metadata for LLMs
SPDX 3.0 introduces AI and Dataset Profiles that create machine-readable metadata for LLM system components. These profiles provide comprehensive tracking of models, datasets, and their relationships, creating what’s essentially an “LLM Bill of Materials” that documents every component in an AI-powered application.
The breakthrough is that SPDX 3.0 increases visibility into AI systems by defining the key AI model metadata—read: security signals—that are needed to track risk and define enterprise-specific security policies. This isn’t just documentation for documentation’s sake; it’s about creating structured data that existing DevSecOps infrastructure can consume and act upon.
The bonus is that this works with existing tooling: SBOMs, CI/CD pipelines, vulnerability scanners, and policy-as-code evaluation engines can all be extended to handle AI profile metadata without requiring organizations to rebuild their security infrastructure from scratch.
Learn about how SBOMs have adapted to the world of micro-services architecture with the co-founder of SPDX and SBOMs.
3 novel security use-cases for AI-native apps enabled by SPDX 3.0
Bias Detection & Policy Enforcement becomes automated through the knownBias field, which allows organizations to scan AI BOMs for enterprise-defined bias policies just like they scan software SBOMs for vulnerable components.
Traditional vulnerability scanners can be enhanced to flag models or datasets that contain documented biases that violate organizational policies. Policy-as-code frameworks can enforce bias thresholds automatically, preventing deployment of AI systems that don’t meet enterprise standards.
Risk-Based Deployment Gates leverage the safetyRiskAssessment field, which follows EU risk assessment methodology to categorize AI systems as serious, high, medium, or low risk.
This enables automated risk scoring in CI/CD pipelines, where deployment gates can block high-risk models from reaching production or require additional approvals based on risk levels. Organizations can set policy thresholds that align with their risk tolerance and regulatory requirements.
Data Provenance Validation uses fields like dataCollectionProcess and suppliedBy to track the complete lineage of training data and models. This enables allowlist and blocklist enforcement for data sources, ensuring that models are only trained on approved datasets.
Supply chain integrity verification becomes possible by tracking the complete chain of custody for AI components, from original data collection through model training and deployment.
An SPDX 3.0 SBOM hierarchy for an AI-native application might look like this:
The key insight is that SPDX 3.0 makes AI systems legible to existing DevSecOps infrastructure. Rather than requiring organizations to build parallel security processes for AI workflows and components, it extends current security investments to cover the new AI supply chain. This approach reduces adoption friction by leveraging familiar tooling and processes that security teams already understand and trust.
History Repeats Itself: The Supply Chain Security Story
This isn’t the first time we’ve been through a transition where software development evolution increases productivity while also creating supply chain opacity. The pattern we’re seeing with LLM data supply chains is remarkably similar to what happened with the open source software explosion of the 2000s.
Software supply chains evolution: From trusted vendors to open source complexity to automated security
Phase 1: The Trusted World (Pre-2000s) was characterized by 1st-party code and trusted commercial vendors. Organizations primarily wrote their own software or purchased it from established vendors with clear support relationships.
Manual security reviews were feasible because dependency trees were small and well-understood. There was high visibility into what components were being used and controlled dependencies that could be thoroughly vetted.
Phase 2: Open Source Software Explosion (2000s-2010s) brought massive productivity gains from open source libraries and frameworks. Package managers like npm, Maven, and PyPI made it trivial to incorporate thousands of 3rd-party components into applications.
Dependency trees exploded from dozens to thousands of components, creating a visibility crisis where organizations could no longer answer the basic question: “What’s actually in my application?”
This led to major security incidents like the Equifax breach (Apache Struts vulnerability), the SolarWinds supply chain attack, and the event-stream npm package compromise that affected millions of applications.
Phase 3: Industry Response (2010s-2020s) emerged as the security industry developed solutions to restore visibility and control.
SBOM standards like SPDX and CycloneDX provided standardized ways to document software components. Software Composition Analysis (SCA) tools proliferated, offering automated scanning and vulnerability detection for open source dependencies. DevSecOps integration and “shift-left” security practices made supply chain security a standard part of the development workflow.
LLM supply chains evolution: Same same—just faster
We’re now seeing this exact pattern repeat with AI systems, just compressed into a much shorter timeframe.
Phase 1: Model Gardens (2020-2023) featured trusted foundation models from established providers like OpenAI, Google, and Anthropic. LLM-powered application architectures were relatively simple, with limited data sources and clear model provenance.
Manual AI safety reviews were feasible because the number of models and data sources was manageable. Organizations could maintain visibility into their AI components through manual processes and documentation.
Phase 2: LLM/RAG Explosion (2023-Present) has brought foundation model APIs that enable massive productivity gains for AI application development.
Complex AI supply chains now feature transitive dependencies where models are fine-tuned on other models, RAG systems pull data from multiple sources, and agent frameworks orchestrate multiple AI components.
We’re currently re-living the same but different visibility crisis where organizations have lost the ability to understand the supply chains that power their production systems. Emerging attacks like data poisoning, and model theft are targeting these complex supply chains with increasing sophistication.
Phase 3: Industry Response (Near Future) is just beginning to emerge. SBOM standards like SPDX 3.0 are leading the charge to re-enable supply chain transparency for LLM supply chains constructed from both code and data. AI-native security tools are starting to appear, and we’re seeing the first extensions of DevSecOps principles to AI systems.
Where do we go from here?
We are still in the early stages of new software supply chain evolution, which creates both risk and opportunity for enterprises. Those who act now can establish LLM data supply chain security practices before the major attacks hit, while those who wait will likely face the same painful lessons that organizations experienced during the software supply chain security crisis of the 2010s.
Crawl: Embed SBOMs into your current DevSecOps pipeline
A vital first step is making sure you have a mature SBOM initiative for your traditional software supply chains. You won’t be ready for the future transition to LLM supply chains without this base.
This market is mature and relatively lightweight to deploy. It will power software supply chain security or up-level current software supply chain security (SSCS) practices. Organizations that have already invested in SBOM tooling and processes will find it much easier to extend these capabilities to an AI-native world.
Walk: Experiment with SPDX 3.0 and system bills of materials
Early adopters who want to over-achieve can take several concrete steps:
Upgrade to SPDX 3.0 and begin experimenting with the AI and Dataset Profiles. Even if you’re not ready for full production deployment, understanding the new metadata fields and how they map to your LLM system components will prepare you for the tooling that’s coming.
Begin testing AI model metadata collection by documenting the models, datasets, and AI components currently in use across your organization. This inventory process will reveal gaps in visibility and help identify which components pose the highest risk.
Insert AI metadata into SBOMs for applications that already integrate AI components. This creates a unified view of both software and LLM dependencies, enabling security teams to assess risk across the entire application stack.
Explore trends and patterns to extract insights from your LLM component inventory. Look for patterns in data sources, model licensing, risk levels, and update frequencies that can inform policy development.
This process will eventually evolve into a full production LLM data supply chain security capability that will power AI model security at scale. Organizations that begin this journey now will have significant advantages as AI supply chain attacks become more sophisticated and regulatory requirements continue to expand.
The window of opportunity is open, but it won’t remain that way indefinitely. Just as organizations that ignored software supply chain security in the 2000s paid a heavy price in the 2010s, those who ignore AI supply chain security today will likely face significant challenges as AI attacks mature and regulatory pressure increases.
Follow us on LinkedIn or subscribe to our newsletter to stay up-to-date on progress. We will continue to update as this space evolves, sharing practical guidance and real-world experiences as organizations begin implementing LLM data supply chain security at scale.
Explore SBOM use-cases for almost any department of the enterprise and learn how to unlock enterprise value to make the most of your software supply chain.
The latest release of Anchore Enterprise 5.19 features two major enhancements that address critical needs in government, defense, and enterprise environments:
Anchore STIG for Container Images, and
Anchore One-Time Scan.
Anchore STIG for Container Images automates the process of running a STIG evaluation against a container image to shift compliance “left”. By embedding STIG validation directly into the CI/CD pipeline as automated policy-as-code rules, compliance violations are detected early, reducing the time to reach compliance in production.
Anchore One-Time Scan is a new API which is optimized for scanning in CI/CD by removing the persistence requirement for storing the SBOM. Now security and software engineers can get stateless scanning, comprehensive vulnerability assessment and policy evaluation through a single CLI command or API call.
These new features bring automated compliance validation and flexible scanning options directly into your DevSecOps workflows, enabling organizations to maintain security standards without sacrificing development velocity.
Anchore STIG for Container Images: Compliance Automation at Scale
Before we jump into the technical details, it’s important to understand the compliance challenges that government and defense organizations face daily. Security Technical Implementation Guides (STIGs) represent the gold standard for cybersecurity hardening in federal environments, providing detailed configuration requirements that systems must meet to operate securely. However, traditional STIG compliance has been a largely manual process—time-consuming, error-prone, and difficult to integrate into automated CI/CD pipelines.
The challenge for modern development teams is that STIG evaluations have traditionally required manual assessment and configuration validation, creating bottlenecks in deployment pipelines and increasing the risk of non-compliant systems reaching production. For organizations pursuing FedRAMP authorization or operating under federal compliance mandates, this manual overhead can significantly slow development cycles while still leaving room for human error.
For a real-world example of how STIG compliance challenges are being solved at scale, check out our Cisco Umbrella case study, which details how Cisco uses Anchore Enterprise with STIG for Container Images on their AWS EC2 base images.
Learn how to harden your containers and make them “STIG-Ready” with our definitive guide.
Anchore STIG for Container Images delivers immediate value across multiple organizational levels:
Development teams gain access to “STIG Ready” base images
Security teams can access STIG evaluation documents in a single location
The automated approach eliminates the manual audit overhead that traditionally slows compliance workflows, while the policy gate integration prevents images which are not evaluated from reaching production. This proactive compliance model significantly reduces the risk of security violations and streamlines the path to regulatory compliance authorizations such as FedRAMP or DoD ATO.
How Anchore STIG for Container Images Works
Anchore STIG for Container Images automates the entire STIG evaluation process through seamless integration with Cinc (i.e., open source Chef IaC system) and AnchoreCTL orchestration. The solution provides a four-step workflow that transforms manual compliance checking into an automated pipeline component:
Install Cinc on your scanning host alongside AnchoreCTL
Execute STIG checks using specific profiles through AnchoreCTL commands
$ anchorectl image stig run <FULLY_QUALIFIED_URL_TO_CONTAINER_IMAGE> \
--stig-profile ./<DIRECTORY_PATH_TO_EXTRACTED_STIG_PROFILES>/ubi8/anchore-ubi8-disa-stig-1.0.0.tar.gz
Upload results directly to Anchore Enterprise for centralized management and reporting
The add-on supports comprehensive profiles for RHEL 8/9 and Ubuntu 22.04/24.04, with tech preview profiles available for critical applications including:
PostgreSQL
Apache Tomcat
MongoDB Enterprise
Java Runtime Environment
New API endpoints provide full programmatic access to STIG evaluations, while the integrated policy gate ensures that only compliant images can progress through your deployment pipeline. The screenshot below shows an example gate that can evaluate whether a STIG evaluation exists for a container and if the age of the evaluation is older than a specified number of days.
Anchore Enterprise One-Time Scan: Lightweight Security for Agile Workflows
Not every security scanning scenario requires persistent data storage in your Anchore Enterprise deployment. Modern DevSecOps teams often need quick vulnerability assessments for third-party images, temporary validation in CI/CD pipelines, or rapid security triage during incident response. Traditional scanning approaches that persist all data can create unnecessary overhead for these ephemeral use-cases.
CI/CD pipeline flexibility is particularly important for organizations operating at scale, where resource optimization and scanning speed directly impact development velocity. Teams need the ability to perform comprehensive security evaluation without the infrastructure overhead of full data persistence, especially when assessing external images or performing one-off security validations.
Why and Where to Utilize the One-Time Scan Feature
One-Time Scan significantly reduces scanning overhead by eliminating the storage and processing requirements associated with persistent image data. This approach is particularly valuable for organizations scanning large numbers of ephemeral workloads or performing frequent one-off assessments.
Primary Use Cases:
CI/CD Pipeline Validation: Quick security checks for ephemeral build environments
Third-Party Image Assessment: Evaluate external images without adding them to your inventory
Incident Response: Rapid vulnerability assessment during security investigations
Compliance Verification: Policy evaluation for images that don’t require long-term tracking
The stateless operation of One Time Scan provides faster scanning results for time-sensitive workflows, while the new stateless_sbom_evaluation metric enables teams to track usage patterns and optimize their scanning strategies. This flexibility supports diverse operational requirements without compromising security analysis quality.
How One Time Scan Works
Anchore Enterprise’s One Time Scan feature introduces a stateless scanning capability that delivers comprehensive vulnerability assessment and policy evaluation without persisting data in your Anchore Enterprise deployment. The feature provides a single API endpoint (POST /v2/scan) that accepts image references and returns complete security analysis results in real-time.
The stateless operation includes full policy evaluation against your active policy bundles, specifically leveraging Anchore Secure’s gates for vulnerabilities and secret scans. This ensures that even temporary scans benefit from your organization’s established security policies and risk thresholds.
For CLI-based workflows, the new AnchoreCTL command anchorectl image one-time-scan <image> provides immediate access to stateless scanning capabilities.
$ anchorectl image one-time-scan python:latest --from registry
✔ Completed one time scan python:latest
Tag: python:latest
Digest: sha256:238379aacf40f83bfec1aa261924a463a91564b85fbbb97c9a96d44dc23bebe7
Policy ID: anchore_secure_default
Last Evaluation: 2025-07-08T14:29:47Z
Evaluation: pass
Final Action: warn
Reason: policy_evaluation
Policy Evaluation Details:
┌─────────────────┬─────────┬───────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────┬────────┬──────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────┐
│ GATE │ TRIGGER │ DESCRIPTION │ ACTION │ RECOMMENDATION │
├─────────────────┼─────────┼───────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────┼────────┼──────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────┤
│ vulnerabilities │ package │ HIGH Vulnerability found in os package type (dpkg) - libdjvulibre-text-3.5.28-2 (fixed in: 3.5.28-2.1~deb12u1)(CVE-2025-53367 - https://security-tracker.debian.org/tracker/CVE-2025-53367) │ warn │ Packages with low, medium, and high vulnerabilities present can be upgraded to resolve these findings. If upgrading is not possible the finding should be added to an allowlist. │
│ vulnerabilities │ package │ HIGH Vulnerability found in os package type (dpkg) - libdjvulibre21-3.5.28-2+b1 (fixed in: 3.5.28-2.1~deb12u1)(CVE-2025-53367 - https://security-tracker.debian.org/tracker/CVE-2025-53367) │ warn │ Packages with low, medium, and high vulnerabilities present can be upgraded to resolve these findings. If upgrading is not possible the finding should be added to an allowlist. │
│ vulnerabilities │ package │ MEDIUM Vulnerability found in non-os package type (binary) - /usr/local/bin/python3.13 (fixed in: 3.14.0b3)(CVE-2025-6069 - https://nvd.nist.gov/vuln/detail/CVE-2025-6069) │ warn │ Packages with low, medium, and high vulnerabilities present can be upgraded to resolve these findings. If upgrading is not possible the finding should be added to an allowlist. │
│ vulnerabilities │ package │ HIGH Vulnerability found in os package type (dpkg) - libdjvulibre-dev-3.5.28-2+b1 (fixed in: 3.5.28-2.1~deb12u1)(CVE-2025-53367 - https://security-tracker.debian.org/tracker/CVE-2025-53367) │ warn │ Packages with low, medium, and high vulnerabilities present can be upgraded to resolve these findings. If upgrading is not possible the finding should be added to an allowlist. │
└─────────────────┴─────────┴───────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────┴────────┴──────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────┘
Upgrade to Anchore Enterprise 5.19
Anchore Enterprise 5.19 represents a significant advancement in container security automation, delivering the compliance capabilities and scanning flexibility that modern organizations require. The combination of automated STIG compliance and stateless scanning options enables teams to maintain rigorous security standards without creating a drag on development velocity.
Whether you’re pursuing FedRAMP authorization, managing compliance requirements in government environments, or simply need more flexible scanning options for your DevSecOps workflows, these new capabilities provide the foundation for scalable, automated container security.
Ready to upgrade?
Existing customers should reach out to their account manager to access Anchore Enterprise 5.19 and begin leveraging these new capabilities.
For technical implementation guidance and detailed configuration instructions, visit our documentation site.
Anchore Enterprise AWS Machine Image (AMI) is now available for streamlined deployment
These announcements represent another major step in Anchore and AWS’s deepening collaboration to help Fortune 2000 enterprises, federal agencies, and defense contractors secure their software supply chains.
The AWS Security Competency validates what Anchore customers have known for many years — Anchore is ready to provide SBOM management, container security and automated compliance enforcement to Fortune 2000 enterprises, federal agencies, and defense contractors who require a bullet-proof software supply chain.
This competency represents technical validation of Anchore’s SBOM-powered security capabilities through a rigorous AWS assessment of our solution architecture and customer success stories. AWS evaluated our platform’s ability to deliver comprehensive software supply chain transparency, vulnerability management, and automated compliance enforcement at enterprise scale.
Real-world validation comes from customers like:
Cisco Umbrella leveraged Anchore’s SBOM-powered container security to accelerate meeting all six FedRAMP requirements. They deployed Anchore into a high-security environment that had to meet stringent compliance standards, including STIG compliance for Amazon EC2 nodes backing their Amazon EKS deployment.
DoD Iron Bank adopted Anchore for SBOM-powered container security and DoD software factory compliance, validating our platform’s ability to meet the most demanding security requirements in government and defense environments.
For decision makers, the AWS Security Competency provides confidence in solution reliability and seamless AWS integration. It streamlines procurement through verified partner status and ensures enhanced support through our strengthened AWS partnership.
Anchore Enterprise Cloud Image: Simplifying Deployment with an AWS AMI
The Anchore Enterprise Cloud Image represents a pre-built, virtual appliance deployment option that serves as an alternative to the popular Kubernetes Helm chart deployments for use-cases that require a lightweight, batteries-included integration. This isn’t about reducing features—it’s about eliminating complexity where Kubernetes expertise isn’t readily available or necessary.
Technical advantages include:
Dramatically reduced deployment complexity through a ready-to-run Amazon Machine Image (AMI) that eliminates the need for a PhD in Kubernetes. The AMI delivers optimized performance on select AWS instance types, with deterministic performance guidelines for better capacity planning and cost management.
Anchore’s interactive Cloud Image Manager provides guided setup that intelligently assesses your AWS environment, ensures correct resource provisioning, and automates installation with appropriate configurations. Integrated compliance policy packs for NIST, SSDF and FedRAMP frameworks ensure your container security posture aligns with regulatory requirements from day one.
Business benefits that matter to leadership:
Faster time-to-value for container security initiatives means your teams can focus on securing containers rather than managing infrastructure. Reduced operational overhead frees up resources for strategic security initiatives rather than deployment troubleshooting.
This prescriptive solution is ideal for teams without extensive Kubernetes expertise, proof-of-concept deployments, and smaller-scale implementations that need enterprise-grade security without enterprise-level complexity.
Strengthening Our AWS Partnership for Customer Success
These milestones build on our growing AWS collaboration, including our AWS Marketplace availability and ISV Accelerate Program membership. This represents our broader commitment to enterprise and public sector customers who rely on AWS infrastructure for their most critical applications.
The joint value proposition is clear: seamless AWS infrastructure integration combined with enhanced support through our combined AWS and Anchore expertise. We’re addressing the full spectrum of deployment preferences, whether you need the scale-out capabilities of EKS or the simplified deployment of our EC2 AMI option.
This partnership strengthening directly benefits our mutual customers through validated integration patterns, streamlined support channels, and deployment flexibility that matches your team’s expertise and requirements.
Moving Forward Together
The combination of AWS Security Competency validation and simplified AMI deployment options demonstrates our commitment to comprehensive support for enterprise and government security requirements. These milestones strengthen our partnership and enable customer success at scale, whether you’re securing containers for a commercial enterprise or meeting compliance requirements for federal agencies.
Our deepening AWS partnership ensures you have the deployment flexibility, validated security capabilities, and enterprise support needed to secure your software supply chain with confidence.
Ready to get started?
For AMI deployment: Contact our sales team for Cloud Image deployment consultation tailored to your AWS environment
For general inquiries: Connect with our team to discuss how AWS Security Competency benefits and deployment options can accelerate your software supply chain security initiatives
Save your developers time with Anchore Enterprise. Get instant access with a 15-day free trial.
If you last tried Grype a year ago and haven’t checked back recently, you’re in for some pleasant surprises. The past twelve months have significantly improved the accuracy and performance of our open sourcevulnerability scanner. Whether you’re dealing with false positives, slow database updates, or wanting deeper insights into your vulnerability data, Grype has evolved considerably.
Let’s dive into the highlights that make now a perfect time to give Grype another look.
Dramatically Fewer False Positives
One of the most common complaints we’ve heard over the years was about false positives – vulnerabilities being incorrectly flagged where they didn’t actually exist. This problem was particularly acute when scanning Java applications, where a Python package named “redis” might trigger vulnerabilities meant for the Redis database server, or where different ecosystems would cross-contaminate results.
The root cause was our reliance on CPE (Common Platform Enumeration) matching from the National Vulnerability Database. While comprehensive, CPE matching often lacked the ecosystem-specific context needed for accurate results.
The solution? We’ve fundamentally shifted our approach to prioritize the GitHub Advisory Database, which provides ecosystem-specific vulnerability data. The results speak for themselves:
Up to 80% reduction in false positives across some ecosystems
More accurate matching that respects package ecosystem boundaries
Cleaner, more actionable scan results
# Before: Multiple false positives for "redis"
$ grype redis:latest
...
CVE-2022-0543 redis pkg:gem/[email protected]
# After: Only legitimate vulnerabilities reported
$ grype redis:latest
# Clean results focused on actual Redis server vulnerabilities
Don’t worry if you still need CPE matching for specific use cases – it’s still available and configurable. But for most users, the new defaults provide dramatically better accuracy.
So, while not completely solved, we’re another step closer to nirvana.
Database Revolution: Faster, Smaller, Smarter
Behind the scenes, we’ve completely reimagined how Grype stores and accesses vulnerability data with our move from database schema v5 to v6. This isn’t just a version bump – it’s a fundamental architectural improvement.
The numbers tell the story:
Metric
Schema v5
Schema v6
Improvement
Download Size
210 MB
↓ 65 MB
↓69% smaller
On-disk DB Size
1.6 GB
↓ 900 MB
↓ 44% smaller
For your day-to-day workflow, this means:
Faster CI/CD pipelines with quicker database updates
Reduced bandwidth costs especially important for air-gapped environments
Better performance on resource-constrained systems
But the improvements go beyond just size. The new schema is built around OSV (Open Source Vulnerability) standards and includes powerful new datasets:
Enhanced Intelligence with CISA KEV and EPSS
Grype now includes CISA’s Known Exploited Vulnerabilities (KEV) database and EPSS (Exploit Prediction Scoring System) data. This means you can now prioritize vulnerabilities actively exploited in the wild or have a high probability of exploitation.
This contextual information helps security teams focus their remediation efforts on the most important vulnerabilities.
The KEV and EPSS data and a vulnerability’s severity are now used to calculate a “Risk” value, presented in the Grype tabular output.
The tabular output from Grype is now sorted by the calculated “Risk” column by default.
Database Search: Your New Best Friend
One of the most powerful additions to Grype is the enhanced database search functionality. Previously, investigating vulnerability data meant manually searching through multiple sources. Now, you can query the Grype database directly to understand what’s in there and why certain matches occur.
This is best illustrated with a few examples:
Find all vulnerabilities affecting log4j
Search for specific vulnerability details
Search for vulns in a specific package/library and ecosystem
This transparency helps with:
Debugging unexpected results – understand exactly why a match occurred
Security research – explore vulnerability patterns across ecosystems
Compliance reporting – validate that your scanning covers relevant vulnerability sources
A Cast of Thousands (Well, Five): The Ecosystem Advantage
While Grype is the star of this story, its improvements are powered by advances across our entire toolchain. Syft, our SBOM generation tool, has dramatically expanded its package detection capabilities over the past year:
New Binary Detection:
Chrome/Chromium browsers
curl and other common utilities
Dart language binaries
PHP interpreters and extensions
Haskell and OCaml binaries
Enhanced Language Support:
Improved .NET detection with better dependency relationships
NuGet package support
Enhanced Java cataloging with better Maven support
Python packaging improvements with dependency relationships
Support for Rust cargo-auditable binaries
Better Container Analysis:
Support for scanning Debian archives directly
Improved handling of symlinks and complex file systems
Better performance with large container images
This expanded detection means Grype can now find and assess vulnerabilities in a broader range of software components, giving you more comprehensive security coverage.
Configuration Profiles: Simplify Your Setup
Managing Grype configuration across different environments previously required maintaining separate config files. Now, Grype supports hierarchical configuration with profiles, making it easy to maintain different scanning policies for various environments as well as per-project exclusion lists.
PURL Support: Scan What You Know
Sometimes you don’t need to scan an entire container image – you just want to check if a specific package version has known vulnerabilities. Grype now supports direct PURL (Package URL) scanning:
Check a specific package version
Feed Grype one or more PURLs from a file
This is particularly useful for dependency checking in CI/CD pipelines or when you want to validate specific component versions.
Performance Under the Hood
Beyond the user-facing features, significant engineering work has improved Grype’s performance and reliability:
Faster vulnerability matching with optimized database queries
Reduced memory consumption especially when scanning large container images
Better error handling with more informative messages when things go wrong
The Road Ahead
The past year has established a solid foundation for Grype’s future. With the new database architecture in place, we can more rapidly integrate new vulnerability sources and provide richer context about security issues.
Key areas we’re continuing to develop include:
Enhanced support for emerging package ecosystems
Better integration with vulnerability management workflows
More sophisticated vulnerability prioritization
Expanded scanning capabilities for different artifact types
Try It Today
If you’re already using Grype, updating to the latest version will automatically give you these improvements. If you’re new to Grype or haven’t tried it recently, installation is straightforward, from brew or using our installer.
Have you tested Grype recently? Maybe you’re comparing it to other tools in the market. Let us know how we got on, we would love to know. This post on our community Discourse is a great place to share your experience and give us your feedback.
I also put all the above commands in there, for easy copy/paste-ability!
Get Involved
Grype is open source, and community contributions have been essential to these improvements. Whether you’re reporting bugs, suggesting features, or contributing code, there are multiple ways to get involved:
The past year has shown that security scanning becomes a force multiplier rather than a bottleneck when tooling gets out of the way and provides accurate, actionable results. Grype’s evolution continues to focus on this goal: giving you the information you need to secure your software supply chain without the noise.
Give it another look – you might be surprised by how much has changed!
The next phase of software supply chain security isn’t about better software supply chain inventory management—it’s the realization that distributed, micro-services architecture expands an application’s “supply chain” beyond the walls of isolated, monolithic containers to a dynamic graph of interconnected services working in concert.
Kate Stewart, co-founder of SPDX and one of the most influential voices in software supply chain security, discovered this firsthand while developing SPDX 3.0. Users were importing SBOMs into databases and asking interconnection questions that the legacy format couldn’t answer. Her key insight drove the development of SPDX 3.0: “It’s more than just software now, it really is a system.” The goal became transforming the SBOM format into a graph-native data structure that captures complex interdependencies between constellations of services.
In a recent interview with Anchore’s Director of Developer Relations on the Future of SBOMs, Stewart shared insights, shaped by decades of collaboration in the trenches with SBOM users and the sculpting of SBOM standards based on ground truth needs. Her perspectives are uniquely tailored to illuminate the challenge of adapting traditional security models designed for fully self-contained applications to the world of distributed micro-services architectures.
The architectural evolution from monolithic, containerized application to interconnected constellations of single-purpose services doesn’t just change how software is built—it fundamentally changes what we’re trying to secure.
Learn about how SBOMs have adapted to the world of micro-services architecture with the co-founder of SPDX and SBOMs.
In the containerized monolith era, traditional SBOMs (think: < SPDX 2.2) were perfectly suited for their purpose. They were designed for self-contained applications with clear boundaries where everything needed was packaged together. Risk assessment was straightforward: audit the container, secure the application.
[ User ] | v +------------+ | Frontend | (container) 👈 Thing... +------------+ | v +--------------+ | API Server | (container) 👈 [s]... +--------------+ / \ v v+----------+ +--------+| Auth Svc | | Orders | (container) 👈 to...+----------+ +--------+ \ / v v +------------+ | Database | (container) 👈 scan. +------------+
But the distributed architecture movement changed everything. Cloud-native architectures spread components across multiple domains. Microservices created interdependencies that span networks, data stores, and third-party services. AI systems introduced entirely new categories of components including training data, model pipelines, and inference endpoints. Suddenly, the neat boundaries of traditional applications dissolved into complex webs of interconnected services.
Even with this evolution in software systems, the fundamental question of software supply chain security hasn’t evolved. Security teams still need to know, “what showed up; at what point in time AND do it at scale.” The new challenge is that system complexity has exploded exponentially and the legacy SBOM standards weren’t prepared for it.
Supply chain risk now flows through connections, not just components. Understanding what you’re securing requires mapping relationships, not just cataloging parts.
But if the structure of risk has changed, so has the nature of vulnerabilities themselves.
Where Tomorrow’s Vulnerabilities Will Hide
The next generation of critical vulnerabilities won’t just be in code—they’ll emerge from the connections and interactions between complex webs of software services.
Traditional security models relied on a castle-and-moat approach: scan containers at build time, stamp them for clearance, and trust them within the perimeter. But distributed architectures expose the fundamental flaw in this thinking. When applications are decomposed into atomic services the holistic application context is lost. A low severity vulnerability in one system component that is white listed for the sake of product delivery speed can still be exploited and alter a payload that is benign to the exploited component but disastrous to a downstream component.
The shift to interconnected services demands a zero-trust security paradigm where each interaction between services requires the same level of assurance as initial deployment. Point-in-time container scans can’t account for the dynamic nature of service-to-service communication, configuration changes, or the emergence of new attack vectors through legitimate service interactions.
In order to achieve this new security paradigm, SPDX needed a facelift. The new idea about an SBOM that can store the entire application context across independent services is sometimes called a SaaSBOM. SPDX 3.0 implements this idea via a new concept called profiles, where application profiles can be built from a collection of individual service profiles and operations or infrastructure profiles can also capture data on the build and runtime environments.
Your risk surface isn’t just your code anymore—it’s your entire operational ecosystem from hardware component supplier to data providers to third-party cloud service.
Understanding these expanding risks requires a fundamental shift from periodic snapshots (i.e., castle-and-moat posture) to continuous intelligence (i.e., zero-trust posture).
From Periodic Audits to Continuous Risk Intelligence
The shift to zero-trust architectures requires more than just changing security policies—it demands a fundamental reimagining of how we monitor and verify the safety of interconnected systems in real-time.
Traditional compliance operates on snapshot thinking: quarterly audits, annual assessments, point-in-time inventories. This approach worked when applications were monolithic containers that changed infrequently. But when services communicate continuously across network boundaries, static assessments become obsolete before they’re complete. By the time audit results are available, dozens of deployments, configuration changes, and scaling events have already altered the system’s risk profile.
Kate Stewart’s vision of “continuous compliance” addresses this fundamental mismatch between static assessment and dynamic systems. S—System—BOMs capture dependencies and their relationships in real-time as they evolve, enabling automated policy enforcement that can keep pace with DevOps-speed development. This continuous visibility means teams can verify that each service-to-service interaction maintains the same security assurance as initial deployment, fulfilling the zero-trust requirement.
The operational transformation is profound. Teams can understand blast radius immediately when incidents occur, tracing impact through the actual dependency graph rather than outdated documentation. Compliance verification happens inline with development pipelines rather than as a separate audit burden. Most importantly, security teams can identify and address misconfigurations or policy violations before they create exploitable vulnerabilities.
This evolution transforms security from a periodic checkpoint into continuous strategic intelligence, turning what was once a cost center into a competitive advantage that enables faster, safer innovation.
The Strategic Imperative—Why This Matters Now
Organizations that adapt to system-level visibility will have decisive advantages in risk management, compliance, and operational resilience as the regulatory and competitive landscape evolves.
The visibility problem remains foundational: you can’t secure what you can’t see. Traditional tools provide (system) component visibility, but emergent system risks only emerge through relationship mapping. Kate emphasizes this idea noting that “safety is a system property”. If you want to achieve system-level guarantees of security or risk, being able to see only the trees and not the forest won’t cut it.
Regulatory evolution is driving urgency around this transition. Emerging regulations (e.g., EO 14028, EU CRA, DORA, FedRAMP, etc.) increasingly focus on system-level accountability, making organizations liable for the security of entire systems, including interactions with trusted third-parties. Evidence requirements are evolving from point-in-time documentation to continuously demonstrable evidence, as seen in initiatives like FedRAMP 20x. Audit expectations are moving toward continuous verification rather than periodic assessment.
Competitive differentiation emerges through comprehensive risk visibility that enables faster, safer innovation. Organizations achieve reduced time-to-market through automated compliance verification. Customer trust builds through demonstrable security posture. Operational resilience becomes a competitive moat in markets where system reliability determines business outcomes.
Business continuity integration represents perhaps the most significant strategic opportunity. Security risk management aligns naturally with business continuity planning. System understanding enables scenario planning and resilience testing. Risk intelligence feeds directly into business decision-making. Security transforms from a business inhibitor into an enabler of agility.
This isn’t just about security—it’s about business resilience and agility in an increasingly interconnected world.
The path forward requires both vision and practical implementation.
The Path Forward
The transition from S—software—BOMs to S—system—BOMs represents more than technological evolution—it’s a fundamental shift in how we think about risk management in distributed systems.
Four key insights emerge from this evolution.
Architectural evolution demands corresponding security model evolution—the tools and approaches that worked for monoliths cannot secure distributed systems.
Risk flows through connections, requiring graph-based understanding that captures relationships and dependencies.
Continuous monitoring and compliance must replace periodic audits to match the pace of modern development and deployment.
System-level visibility becomes a competitive advantage for organizations that embrace it early.
Organizations that make this transition now will be positioned for success as distributed architectures become even more complex and regulatory requirements continue to evolve. The alternative—continuing to apply monolithic security thinking to distributed systems—becomes increasingly untenable.
The future of software supply chain security isn’t about better inventory—it’s about intelligent orchestration of system-wide risk management.
If you’re interested in how to make the transition from generating static software SBOMs to dynamic system SBOMs, check out Anchore SBOM or reach out to our team to schedule a demo.
Explore SBOM use-cases for almost any department of the enterprise and learn how to unlock enterprise value to make the most of your software supply chain.
Your sales team just got off a call with a major prospect. The customer is asking for an SBOM—a software bill of materials—and they want it written directly into the contract. The request is escalated to the executive team and from there directly into your inbox. Maybe it’s a government agency responding to new federal mandates, a highly regulated enterprise implementing board-level security requirements, or a large EU-based SaaS buyer preparing for upcoming regulatory changes.
Suddenly, a deal that seemed straightforward now hinges on your ability to deliver comprehensive software supply chain transparency. If this scenario sounds familiar, you’re definitely not alone. SBOM requirements are increasing across industries, fueled by new regulations like the US Executive Order 14028 and the EU Cyber Resilience Act. For most software vendors, this represents entirely new territory where the stakes—revenue, reputation, and customer trust—are very real.
This development isn’t entirely negative news, however. Organizations that proactively build robust SBOM capabilities are discovering they’re not just avoiding lost deals—they’re actually building a significant competitive advantage. Early adopters consistently report faster sales cycles with security-conscious prospects and access to previously unreachable government contracts that require supply chain transparency.
Don’t believe me? I’ve brought the receipts:
We’re seeing a lot of traction with data warehousing use-cases. Security is absolutely critical for these environments. Being able to bring an SBOM to the conversation at the very beginning completely changes the conversation and allows CISOs to say, ‘let’s give this a go’. —CEO, API Management Vendor
This blog post will walk you through the critical steps needed to meet customer SBOM demands effectively, help you avoid costly implementation mistakes, and even show you how to turn compliance requirements into genuine business advantages.
5-Minute Decision Framework: Are SBOMs Urgent for Your Organization?
Medium urgency signals: Industry peers discussing SBOM strategies, security questionnaires becoming more detailed, procurement teams asking about vulnerability management.
Red flags: Legacy systems with unknown dependencies, manual build processes, siloed teams, limited engineering bandwidth.
Why Customers Are Demanding SBOMs—And What That Means For You
SBOMs aren’t a passing trend. In fact, the regulatory pressure from governments around the world are steadily driving SBOM adoption outside of the public sector. These new regulations have forced vendors, especially those selling to the US government and in the EU, to scrutinize what’s in the software.
US Government: EO 14028 requires federal agencies to collect SBOMs from vendors
EU Enterprises: The EU Cyber Resilience Act (CRA) requires an SBOM for any enterprise that sells “products with software components” in the EU market
BUT won’t be fully enforced until December 2027—you still have time to get ahead of this one!
Highly regulated industries: Meaning defense (continuous ATO), healthcare (FDA approval) and finance (DORA, PCI DSS 4.0) all require SBOMs
But what are your customers really after? Most are looking for:
A clear, standardized inventory of what’s in your software (open source, third-party, proprietary)
Depth: Do you want only direct dependencies, or transitive (all sub-dependencies) as well?
Delivery: How do you want to receive the SBOM—portal, API, email, physical media?
Minimum requirements
Most regulated buyers accept SPDX or CycloneDX formats as long as they meet the NTIA’s Minimum Elements. One SBOM per major release is typical, unless otherwise specified.
Requests for highly granular or proprietary information you can’t legally or safely disclose
Contract language examples
“Vendor shall provide an SBOM in SPDX or CycloneDX format at product release.”
“Vendor will update the SBOM within 30 days of any significant component change.”
Key Risks and Negotiation Tactics
The biggest risk? Overcommitting—contractually agreeing to deliver what you can’t.
Contract negotiations around SBOM requirements present unique challenges that combine technical complexity with significant business risk. Understanding common problematic language and developing protective strategies prevents overcommitment and reduces legal exposure.
Here’s how to stay safe:
Risks
Operational: You lack fully instrumented software development pipeline with integrated SBOM generation and can’t meet the update frequency as promised.
Legal: You don’t have complete supply chain transparency and risk exposing proprietary or third-party code you’re not allowed to disclose.
Reputational: Missing deadlines or failing to deliver undermines customer trust.
Red flags in contracts
Unlimited liability clauses for SBOM accuracy
100% accurate SBOMs create impossible standards—no automated tool achieves this level of accuracy, and manual verification is prohibitively expensive
Penalty clauses for incomplete or inaccurate SBOMs
You should be able to remediate mistakes in a reasonable timeframe
Real-time or continuous SBOM update requirements ignoring practical development and release cycles
Requirements for complete proprietary component disclosure
May violate third-party licensing agreements or expose competitive advantages
No provision for IP protection
If you’re increasing their supply chain transparency they need to reciprocate and protect your interests
Vague standards (“must provide industry best-practice SBOMs” without specifics)
How to negotiate
Push back on frequency:
“We can provide an updated SBOM at each major release, but not with every build.”
Standard delivery timelines should align with existing release cycles—quarterly updates for stable enterprise software, per-release delivery for rapidly evolving products.
Don’t roll over on accuracy:
“We can generate SBOMs automatically as part of our normal software development process, provide reasonable manual validation and correct any identified issues.”
Reasonable accuracy standards acknowledge tool limitations while demonstrating good faith effort.
Protect sensitive info:
“SBOM details do not extend to proprietary components or components protected by confidentiality.”
Redact or omit sensitive components, and communicate this upfront.
Quick-Start: Fast Path to SBOM Compliance (for Resource-Constrained Teams)
You don’t need to boil the ocean. Here’s how to get started—fast:
First Five Moves
Clarify the ask: Use the questions above to pin down what’s really required.
Inventory your software: Identify what you build, ship, and what major dependencies you include.
Choose your tooling:
For modern apps, consider open source tools (e.g., Syft) or commercial platforms (e.g., Anchore SBOM).
For legacy systems, some manual curation may be needed.
Assign ownership: Clearly define who in engineering, security, or compliance is responsible.
Pilot a single SBOM: Run a proof of concept for one release, review, and iterate.
Pro tips:
Automate where possible (integrate SBOM tools into CI/CD).
Don’t over-engineer for the first ask—start with what you can support.
Handling legacy/complex systems:
Sometimes, a partial or high-level SBOM is enough. Communicate limitations honestly and document your rationale.
Efficient Operationalization: Making SBOMs Work in Your Workflow
When you’re ready to operationalize your SBOM initiative, there are four important topics to consider:
Automate SBOM creation: Integrate tools into your build pipeline; trigger SBOM creation with each release.
SBOM management: Store SBOMs in a central repository for easy search and analysis.
Version and change management: Update SBOMs when major dependencies or components change.
Delivery methods:
Secure portal
Customer-specific API
Encrypted email attachment
This is also a good time to consider the build vs buy question. There are commercial options to solve this challenge if building a homegrown system would be a distraction to your company’s core mission.
Turning Compliance into Opportunity
SBOMs aren’t just a checkbox—they can help your business:
Win deals faster: “Having a ready SBOM helped us close with a major public sector buyer ahead of a competitor.”
Shorten security reviews: Automated SBOM delivery means less back-and-forth during customer due diligence.
Build trust: Demonstrate proactive risk management and transparency.
Consider featuring your SBOM readiness as a differentiator in sales and marketing materials.
SBOM Readiness Checklist
::Checklist::
Have we clarified the customer’s actual SBOM requirements?
✅: Continue
❌: Send request back to customer account team with SBOM requirements
Do we know which SBOM format(s) are acceptable?
✅: Continue
❌: Send request back to customer account team with SBOM requirements
Have we inventoried all shipped software and dependencies?
✅: Continue
❌: Send to engineering to build a software supply chain inventory
Have we selected and tested an SBOM generation tool?
✅: Continue
❌: Send to engineering to select and integrate an SBOM generation tool into CI/CD pipeline
Do we have clear roles for SBOM creation, review, and delivery?
✅: Continue
❌: Work with legal, compliance, security and engineering to document SBOM workflow
Are our contractual obligations documented and achievable?
✅: Continue
❌: Work to legal to clarify and document obligations
Do we have a process for handling sensitive or proprietary code?
✅: You’re all good
❌: Work with engineering and security to identify sensitive or proprietary information and develop a redaction process
Conclusion: From Reactive to Strategic
SBOM requirements are here to stay—but meeting them doesn’t have to be painful or risky.
The most forward-thinking organizations are transforming SBOM compliance from a burden into a strategic advantage. By proactively developing robust SBOM capabilities, you’re not just checking a box—you’re positioning your company as a market leader in security maturity and transparency. As security expectations rise across all sectors, your investment in SBOM readiness can become a key differentiator, driving higher contract values and protecting your business against less-prepared competitors.
Ready to take the first step?
Save your developers time with Anchore SBOM. Get instant access with a 15-day free trial.
“Most SBOMs are barely valid, few meet minimum government requirements, and almost none are useful.”
Harsh. But this is still a common sentiment by SBOM users on LinkedIn. Software bills of materials (SBOMs) often feel like glorified packing slips—technically present but practically worthless.
Yet Kate Stewart, one of the most respected figures in open source, has dedicated over a decade of her career to SBOMs. As co-founder of SPDX and a Linux Foundation Fellow, she’s guided this standard from its inception in 2010 through multiple evolutions. Why would someone of her caliber pour years into something supposedly “useless”?
Because Stewart, the Linux Foundation and the legion of SDPX contributors see something the critics don’t: today’s limitations aren’t a failure of vision—they’re a foundation for the growing complexity of the software supply chain of the future.
Because Stewart, the Linux Foundation and the legion of SDPX contributors see something the critics don’t: today’s limitations aren’t a failure of vision—they’re a deliberate strategy. They’re following the classic startup playbook: nail a minimal use-case first, achieve critical mass, then expand horizontally. The “uselessness” critics complain about? That’s a feature, not a bug.
Death by a Thousand Cuts
To understand where we’re headed, we need to start where it all began: back in 2009 with Kate and a few of her key software architects at Freescale Semiconductor spending their weekends manually scanning software packages for licenses before the launch of a new semiconductor chip.
Stewart and her team faced what seemed like a manageable challenge—tracking open source software (OSS) licenses for roughly 500 dependencies. But as she recalls, “It was death by a thousand cuts.” Every weekend, they’d pore over packages, hunting for license information, trying to avoid the legal landmines hidden in their newest chip’s software supply chain.
The real shock came from discovering how naive their assumptions were. “Everyone assumes the top-level license is all there is,” Stewart explains, “but surprise!” Buried deep in transitive dependencies—the dependencies of dependencies—were licenses that could torpedo entire projects. GPL code hidden three layers deep could force a proprietary product open source. MIT licenses with unusual clauses could create attribution nightmares.
This wasn’t just Freescale’s problem. Across the industry, companies were hemorrhaging engineering hours on manual license compliance.
The Counterintuitive Choice
Here’s where the story takes an unexpected turn. When the Linux Foundation’s FOSSBazaar working group came together to design a solution, they made a choice that still frustrates people today: they went minimal. Radically minimal.
The working group—including Stewart and other industry experts—envisioned SBOMs as “software metadata containers”—infinitely expandable vessels for any information about software components. The technology could support hashing, cryptographic attestations, vulnerability data, quality metrics, and more. But instead of trying to predict every potential use-case they chose to pare the original SPDX spec down to only its essentials.
Stewart knew that removing these features would make SBOMs “appear” almost useless for any purpose. So why did they proceed?
The answer lies in a philosophy that would define SBOM’s entire evolution:
“[We framed] SBOMs as simply an “ingredients list”…but there’s a lot more information and metadata that you can annotate and document to open up significant new use-cases. [The additional use-cases are] really powerful BUT we needed to start with the minimum viable definition.”
The goal wasn’t to solve every problem on day one—it was to get everyone speaking the same language. They chose adoption over the overwhelming complexity of a fully featured standard.
Why the ‘Useless’ Jab Persists
By launching SPDX with a minimal definition to encourage broad adoption and make the concept approachable, the industry began evaluating it equally as minimally—seeing SBOMs as simple ingredient lists rather than an extensible framework. The simplicity of the standard made it easier to grasp, but also easier to dismiss.
Today’s critics have valid points:
Most SBOMs barely meet government minimums
They’re treated as static documents, generated once and forgotten
Organizations create them purely for compliance, extracting zero operational value
The tools generating them produce inconsistent, often invalid outputs
But here’s what the critics miss: SBOMs aren’t truly static documents—at least, not in practice. They’re more like Git version-controlled files: static snapshots that form a dynamic record over time. Each one captures the meta state of an application at a given moment, but their value emerges from their evolution. As Stewart emphasizes, “Every time you apply a security fix you are revving your package. A new revision needs a new SBOM.” Just as Git commits accumulate to form a living history of a codebase, SBOMs should accumulate and evolve to reflect the ongoing lifecycle of an application.
The perception problem is real, but it’s also temporary.
The HTTP Playbook
To understand why the minimal SBOMs strategy is powerful, consider the evolution of HTTP.
In 1991, the original HTTP/0.9 protocol could only request a document using a GET method and receive raw HTML bytes in return. There were no status codes, no headers, and no extensibility. Critics at the time leveled familiar critiques against the fledgling protocol—”barely functional”, “useless”, etc. But that simplicity was its genius. It was a minimum viable definition that was easy to implement and rapidly adopted.
Nobody in 1991 imagined we’d use HTTP headers to prevent cross‑site scripting attacks or optimize mobile performance. But the extensible design made it possible.
SBOMs are following the exact same playbook. The industry expected them to solve license management—the original Package Facts vision. Instead, the killer app turned out to be vulnerability management, driven by the explosion of software supply chain attacks like SolarWinds and Log4j.
“SPDX has grown use‑case by use‑case,” Stewart notes. And each new use-case doesn’t just add features—it enables entirely new categories of applications.
SBOMs today are where HTTP was in 1991—functionally limited but primed for explosion.
The Expansion Is Already Here
The evolution from SPDX 2.x to 3.0 proves this strategy is working. The changes aren’t incremental—they’re transformational:
From Documents to Graphs: SPDX 3.0 abandons the monolithic document model for knowledge graph model. Instead of one big file, you have interconnected metadata that can be queried, analyzed, and visualized as a network.
From Software to Systems: The new specification handles…
Service profiles for cloud infrastructure
AI model and dataset profiles (tracking what data trained your models)
Hardware BOMs for IoT and embedded systems
Build profiles that cryptographically link source to binary
End-of-life metadata for dependency lifecycle management
Build SBOM that cryptographically links everything together
These implementations show SBOMs evolving from compliance checkboxes to operational necessities.
The Endgame: Transparency at Scale
Kate Stewart summarizes the vision in seven words: “Transparency is the path to minimizing risk.”
But transparency alone isn’t valuable—it’s what transparency enables that matters. When every component in your software supply chain has rich, queryable metadata, you can:
The platform effect is already kicking in. More adoption drives more use-cases. More use-cases drive better tooling. Better tooling drives more adoption. It’s the same virtuous cycle that turned HTTP from a simple network protocol into the nervous system of the web.
Explore SBOM use-cases for almost any department of the enterprise and learn how to unlock enterprise value to make the most of your software supply chain.
The critiques of SBOMs as they are today suffer from a failure of imagination. Yes, they’re minimal. Yes, they’re often poorly implemented. Yes, they feel like “compliance theater”. All true.
The founders of SPDX made a calculated bet: it’s better to have adoption of a simple but potentially “useless” standard that can evolve than to have a perfect standard that nobody uses. By starting small, they avoided the fate of countless over-engineered standards that died in committee.
Now, with the cold start overcome and adoption growing, the real expansion begins. As software supply chains grow more complex—incorporating AI models, IoT devices, and cloud services—the metadata infrastructure to manage them must evolve as well.
The teams generating “barely valid” SBOMs today are building the muscle memory and tooling that will power tomorrow’s software transparency infrastructure. Every “useless” SBOM is a vote for an open, transparent, secure software ecosystem.
The paradox resolves itself: SBOMs are useless today precisely so they can become essential tomorrow.
Learn about SBOMs, how they came to be and how they are used to enable valuable use-cases for modern software.
Imagine this: Friday afternoon, your deployment pipeline runs smoothly, tests pass, and you’re ready to push that new release to production. Then suddenly: BEEP BEEP BEEP – your vulnerability scanner lights up like a Christmas tree: “CRITICAL VULNERABILITY DETECTED!”
Your heart sinks. Is it a legitimate security concern requiring immediate action, or just another false positive that will consume your weekend? If you’ve worked in DevSecOps for over five minutes, you know this scenario all too well.
False positives and false negatives are the yin and yang of vulnerability scanning – equally problematic but in opposite ways. False positives cry wolf when there’s no real threat, leading to alert fatigue and wasted resources. False negatives are the silent killers, allowing actual vulnerabilities to slip through undetected. Both undermine confidence in your security tooling.
At Anchore, we’ve been battling these issues alongside our community, and the GitHub issues for our open source scanner, Grype, tell quite a story. In this post, we’ll dissect real-world examples of false results, explain their root causes, and show how vulnerability scanning has evolved to become more accurate over time.
The Curious Case of Cross-Ecosystem Confusion
One of the most common causes of false positives is “cross-ecosystem confusion.” This happens when a vulnerability scanner mistakenly applies a vulnerability from one ecosystem to a different but similarly named package in another ecosystem.
Take the case of Google’s Protobuf libraries. In early 2023, Grype flagged Go applications using google.golang.org/protobuf as vulnerable to CVE-2015-5237 and CVE-2021-22570, both of which affect the C++ version of Protobuf.
“I was just bitten by the CVEs affecting the C++ version of protobuf when I’m using the Go package. Arguably, it shouldn’t even be included on those CVEs in Github because it’s a completely different code base…”
This user wasn’t alone. Looking at the data, we found a whopping 44 instances of these cross-ecosystem false positives across various projects, affecting everything from etcd to Prometheus to kubectl.
The root cause? CPE-based vulnerability matching. The Common Platform Enumeration (CPE) system, while standardized, often lacks the granularity needed to distinguish between different implementations of similarly named software.
When Binary Isn’t So Binary: The System Package Conundrum
Another fascinating case study comes from Issue #2527, where Grype reported CVE-2022-1271 for the gzip utility on Ubuntu 22.04 despite the package being patched.
The problem stemmed from how Linux distributions like Ubuntu handle symbolic links between /bin and /usr/bin. The package manager knew the file was part of the gzip package, but Syft (Grype’s companion tool for generating SBOMs) was identifying the binary separately without connecting it to its parent package.
“This issue was related to how Syft handled symlinks, particularly with the ‘user merge’ in some Linux distributions. Syft wasn’t correctly following symlinks in parent directories when associating files with their Debian packages.”
This case is particularly interesting because it highlights the complex relationship between package managers and the actual files on disk. Even when a vulnerability is properly patched in a package, the scanner might still flag the binary if it doesn’t correctly associate it.
The .NET Parent-Child Relationship Drama
.NET developers will appreciate this next one. In Issue #1693, a user reported that Grype wasn’t detecting the GHSA-98g6-xh36-x2p7 vulnerability in System.Data.SqlClient version 4.8.5.
The issue was related to how .NET packages are cataloged. Syft was finding the .NET assemblies and reporting their assembly versions (like 4.700.22.51706), but these don’t align with the NuGet package versions (4.8.5) used in vulnerability databases.
A contributor demonstrated:
$ grype -q dir:.✔ Vulnerability DB [no update available]✔ Indexed file system /Users/wagoodman/scratch/grype-1693✔ Cataloged contents 500f014f33608c18├── ✔ Packages [1 packages]└── ✔ Executables [0 executables]✔ Scanned for vulnerabilities [0 vulnerability matches]NAME INSTALLED FIXED-IN TYPE VULNERABILITY SEVERITYSystem.Data.SqlClient 4.8.5 4.8.6 dotnet GHSA-98g6-xh36-x2p7 High
This issue highlights the challenges of correctly identifying artifacts across different packaging systems, especially when version information is stored or represented differently.
Goodbye CPE, Hello GHSA: The Evolution of Matching
If there’s a hero in these tales of false results, it’s the shift from CPE-based matching to more ecosystem-aware approaches. In 2023, we published a blog post, “Say Goodbye to False Positives, ” announcing a significant change in Grype’s approach.
As Keith Zantow explained:
“After experimenting with a number of options for improving vulnerability matching, ultimately one of the simplest solutions proved most effective: stop matching with CPEs.”
Instead, Grype primarily relies on the GitHub Advisory Database (GHSA) for vulnerability data. This change led to dramatic improvements:
“In our set of test data, we have been able to reduce false positive matches by 2,000+, while only seeing 11 false negatives.”
That’s a trade-off most security teams would gladly accept! The shift to GHSA-based matching also brought another significant benefit: community involvement in correcting vulnerability data.
Practical Strategies for Managing False Results
Based on our experiences and community feedback, here are some practical strategies for dealing with false results in vulnerability scanning:
Use a quality gate in your CI/CD pipeline: Similar to Grype’s quality gate, which compares results against manually labeled vulnerabilities, you can create a baseline of known issues to avoid regression.
Customize matching behavior: Modern vulnerability scanners like Grype allow you to adjust matching behavior through configuration. For instance, you can modify CPE matching for specific ecosystems:
Create ignore rules for known false positives: When all else fails, explicitly ignore known false positives. Grype supports this through configuration:
Contribute upstream: We believe the best solution is often to fix the data at its source. This is not a consistent practice across the industry. However, as one contributor noted in Issue #773:
The battle against false results in vulnerability scanning is never truly over. Scanners must continuously adapt as software ecosystems evolve and new packaging systems emerge.
The good news is that we’re making substantial progress. By analyzing the closed issues in the Grype repository over the past 12 months, we can see that the community has successfully addressed dozens of false-positive patterns affecting hundreds of real-world applications.
In the immortal words of one relieved user after we fixed a particularly vexing set of false positives: “OMG. This is my favorite GH issue ever now. Great work to the grype team. Holy cow! 🐮 I’m really impressed.”
At Anchore, we remain committed to this quest for accuracy. After all, vulnerability scanning is only helpful if you can trust the results. Whether you’re using our open-source tools like Grype and Syft or Anchore Enterprise, know that each false positive you report helps improve the system for everyone.
So the next time your vulnerability scanner lights up like a Christmas tree on Friday afternoon, remember: you’re not alone in this battle, and the tools are improving daily. And who knows? Maybe it’s a real vulnerability this time, and you’ll be the hero who saved the day!
Are you struggling with false positives or false negatives in your vulnerability scanning? Share your experiences on our Discourse, and report any issues on GitHub. And if you’re looking for a way to manage your SBOMs and vulnerability findings at scale, check out Anchore Enterprise.
This blog post has been archived and replaced by the supporting pillar page that can be found here: https://anchore.com/wp-admin/post.php?post=987475325&action=edit
The blog post is meant to remain “public” so that it will continue to show on the /blog feed. This will help discoverability for people browsing the blog and potentially help SEO. If it is clicked on it will automatically redirect to the pillar page.
Today, we’re launching Anchore SBOM. Anchore Enterprise now allows you to manage internal and external SBOMs in a single location to track your software supply chain issues and meet your compliance requirements.
What is Anchore SBOM?
Anchore SBOM is a set of new capabilities in Anchore Enterprise that allow customers to gain comprehensive visibility into the software components present in both their internally developed and third-party supplied software to identify and mitigate security and compliance risks. It provides a centralized platform for viewing, managing, and analyzing Software Bill of Materials (SBOMs), including the capability to “Bring Your Own SBOMs” (BYOS) by importing SBOMs created outside of Anchore Enterprise and organizing them into groups, reflecting a logical organization structures for easier management, control, analysis, and reporting for enhanced collaboration across business and engineering functions. Importing external SBOMs enables users to go beyond standard container analysis by incorporating SBOMs generated outside of Anchore, whether from other SCA tools or vendor sources, which, in turn, ensures comprehensive visibility across all components of their applications.
Why are SBOMs Important?
In an era of escalating software supply chain attacks—and mounting pressure from regulators, customers, and security teams—visibility into what goes into your applications is no longer optional. Modern software is complex and often built by distributed teams on a foundation of open-source and third-party components. Staying secure and compliant requires continuous, end-to-end insight into your software stack. That means knowing exactly what’s in your applications at every stage of the DevOps lifecycle—from code to cloud. This is where SBOMs come in. SBOMs are machine-readable inventories that capture the full composition of your applications by listing every package and dependency they include.
Key Features and Benefits
Bring Your Own SBOM (BYOS): Import SBOMs in SPDX (versions 2.1-2.3), CycloneDX (versions 1.0-1.6), and Syft native formats – analyze components and manage prioritized vulnerabilities.
Validate SBOMs: Assess uploaded SBOM quality to ensure they meet schema standards and contain necessary data for vulnerability scanning.
Manage SBOMs Centrally: Store and group SBOMs to reflect logical organization structures for easier management, control, analysis, and reporting for enhanced collaboration across business and engineering functions.
Identify Vulnerabilities: Identify and report vulnerabilities within uploaded SBOMs for fast and efficient remediation.
Prioritize and Triage with Anchore Score: A prioritized vulnerability rating based on CVSS Score and Severity, EPSS, and CISA KEV data reduces noise and drastically improves triage time.
Why Does This Matter?
Demand for software supply chain transparency is surging, driven by emerging regulations (such as NIS2, U.S. Cybersecurity Executive Orders, and the EU’s Cyber Resilience Act), industry standards (like PCI DSS), and sector-specific requirements from agencies such as the FDA and SEC. As a result, SBOMs have become essential for enterprises and government agencies seeking critical visibility into their software ecosystems.
Anchore SBOM enables you to consolidate SBOMs continuously generated throughout your development lifecycle—scanning every commit in Git, every build artifact in the CI/CD pipeline, and every deployment to Kubernetes—alongside external SBOMs produced by other tools or provided by your software vendors. This unified view offers comprehensive visibility into your software supply chain. It enables you to meet regulatory requirements and satisfy your customers’ asks with a complete, up-to-date inventory of all your assets and their current security issues.
With the newly announced Anchore SBOM feature, teams can start safely consuming OSS while mitigating security and compliance risks. Register for our technical launch webinar.
The blog post is meant to remain “public” so that it will continue to show on the /blog feed. This will help discoverability for people browsing the blog and potentially help SEO. If it is clicked on it will automatically redirect to the pillar page.
There’s another article about an open source package posing a potential risk, fast-glob in this instance. It’s the same basic idea, but there’s again zero cause for concern at this time. Both of these articles have been all bark and no bite.
So what’s the deal? Are the adversaries using open source as a trojan horse into our software? They are, without question. Remember XZ Utils or tj-actions/changed-files? Those are both well resourced attacks against important open source components. It’s clear that open source is a target for attackers. We can name two examples, it’s likely there are more.
But what about easyjson and fast-glob? Is that a supply chain attack? So far it doesn’t look like it. There is no evidence that using the easyjson or fast-glob libraries creates a risk for an organization. Could this change someday? Absolutely, but so could any other open source library. The potential risk from a Russian company controlling a popular open source library probably isn’t an important detail.
Let’s look at some examples.
Pulling all this data is a lot of work, but there are some quick things anyone can observe in a web browser. Let’s use a couple of popular NPM packages. It’s easy to find this list which is why I’m using NPM, but the example will apply to anything in GitHub
If we dig into the owners of those widely used repositories, the only one that lists a real location is React, it’s in Menlo Park, California, USA—the headquarters for Meta. Where are those other repositories located? We don’t really know. It’s also worth pointing out that all of those repositories have many contributors from all over the world. Just because a project is controlled by an organization in a country doesn’t mean all contributions are from that country.
We know easyjson and fastglob are from a Russian company because they aren’t trying to hide this fact. The organization that holds the easyjson repository is Mail.ru, a Russian company—and they list their location as Russia. The fast-glob package is held by an open source maintainer who resides in Russia. If they want to conduct nefarious activities against open source, this isn’t the best way to do it.
There are some lessons in this though.
Knowing exactly what software pieces you have is super important for keeping things secure and running smoothly. Imagine you need to find every place you’re using easyjson or fast-glob. Could you do it quickly? Probably not easily, right? Today’s software has a lot of hidden parts and pieces. If you don’t have a clear inventory of all those pieces, a software bill of materials (SBOM), finding something like easyjson or fast-glob will take forever and you might miss something. If there’s a security problem, that delay in finding it can cause serious trouble and make you vulnerable. Being able to quickly find and fix these kinds of issues is important when most of our software is open source.
The issue of open source sovereignty introduces complex challenges in today’s interconnected world. If organizations and governments decide to prioritize understanding the origins of their open source dependencies, they immediately encounter a fundamental question: which countries warrant the most scrutiny? Establishing such a list risks geopolitical bias and may not accurately reflect the actual threat landscape. Furthermore, the practicalities of tracking the geographical origins of open source contributions are significant. Developers and maintainers operate globally, and attributing code contributions to a specific nation-state is fraught with difficulty. IP address geolocation can be easily circumvented, and self-reported location data is unreliable, especially in the context of malicious actors who would intentionally falsify such information. This raises serious doubts about relying on geographical data for assessing open source security risks. It necessitates exploring alternative or supplementary methods for ensuring the integrity and trustworthiness of the open source software supply chain, methods that move beyond simplistic notions of national origin.
For a long time, we’ve kind of just trusted open source stuff without really checking it out. Organizations grab these components and throw them into their systems, and so far that’s mostly worked. Things are changing though. People are getting more worried about vulnerabilities, and there are new rules coming out, like the Cyber Resilience Act, that are going to make us be more careful with software. We’re probably going to have to check things out before we use them, keep an eye on them for security issues, and update them regularly. Basically, just assuming everything’s fine isn’t going to cut it anymore. We need to start being a lot more aware of security. This means organizations are going to have to learn new ways to work and change how they do things to make sure their software is safe and follows the rules.
Wrapping up
The origin of easyjson and fast-glob being traced back to a Russian raises a valid point about the perception and utilization of open source software. While the geographical roots of a project don’t inherently signify malicious intent, this instance serves as a potent reminder that open source is not simply “free stuff” devoid of obligations for its users. The responsibility for ensuring the security and trustworthiness of the software we integrate into our projects lies squarely with those who build and deploy it.
Anchore has two tools, Syft and Grype that can help us take responsibility for the open source software we use. Syft can generate SBOMs, making sure we know what we have. Then we can use Grype to scan those SBOMs for vulnerabilities, making sure our software isn’t an actual threat to our environments. When a backdoor is found in an open source package, like XZ Utils, Grype will light up like a Christmas tree letting you know there’s a problem.
The EU Cyber Resilience Act (CRA) shifts this burden of responsibility onto software builders. This approach acknowledges the practical limitations of expecting individual open source developers, who often contribute their time and effort voluntarily, to shoulder the comprehensive security and maintenance demands of widespread software usage. Instead of relying on the goodwill and diligence of unpaid contributors to conduct our due diligence, the CRA framework encourages a more proactive and accountable stance from the entities that commercially benefit from and distribute software, including open source components.
This shift in perspective is crucial for the long-term health and security of the software ecosystem. It fosters a culture of proactive risk assessment, thorough vetting of dependencies, and ongoing monitoring for vulnerabilities. By recognizing open source as a valuable resource that still requires careful consideration and due diligence, rather than a perpetually free and inherently secure commodity, we can collectively contribute to a more resilient and trustworthy digital landscape. The focus should be on building secure systems by responsibly integrating open source components, rather than expecting the open source community to single-handedly guarantee the security of every project that utilizes their code.
Learn the 5 best practices for container security and how SBOMs play a pivotal role in securing your software supply chain.
The blog post is meant to remain “public” so that it will continue to show on the /blog feed. This will help discoverability for people browsing the blog and potentially help SEO. If it is clicked on it will automatically redirect to the pillar page.
Now, we’ll examine how SBOMs intersect with various disciplines across the software ecosystem.
SBOMs don’t exist in isolation—they’re part of a broader landscape of software development, security, and compliance practices. Understanding these intersections is crucial for organizations looking to maximize the value of their SBOM initiatives.
Regulatory Compliance and SBOMs: Global SBOM Mandates
As regulations increasingly mandate SBOMs, staying informed about compliance requirements is crucial for software businesses.
The US was the first-mover in the “mandatory SBOM for securing software supply chains” movement with the White House’s Executive Order (EO) 14028 impacting enterprises that do business with the US federal government
The EU Cyber Resilience Act (CRA) was the fast follower of the movement but with a much larger scope. Any company selling software in the EU must maintain SBOMs of their product
How to interpret specific EO 14028 requirements for your organization
Which artifacts satisfy compliance requirements and which don’t
Pro tips on how to navigate EO 14028 with the least amount of frustration
Open Source Software Security and SBOMs: Risk Management for Invisible Risk
Open source components dominate modern applications, yet create an accountability paradox. Your software likely contains 150+ OSS dependencies you didn’t write and can’t fully audit but you’re entirely responsible for any vulnerabilities they introduce. On top of this, OSS adoption is only getting bigger. This means your organization will inherit more vulnerabilities as time goes on.
Shows how to automate SBOM generation, validation, and analysis
Explores integration with release and deploy pipelines
Provides practical examples of SBOM-driven security gates
Conclusion: The SBOM Journey Continues
Throughout our five-part series on SBOMs, we’ve provided the knowledge you need to implement effective software supply chain security. From foundational concepts to technical implementation, scaling strategies, and regulatory compliance, you now have comprehensive understanding to put SBOMs to work immediately. Software supply chain attacks continue to escalate, making SBOM implementation essential for proactive security.
Understanding the evolving role of SBOMs in software supply chain security requires more than just technical knowledge—it demands strategic vision. In this post, we share insights from industry experts who are shaping the future of SBOM standards, practices, and use-cases.
Insights on SBOMs in the LLM Era
LLMs have impacted every aspect of the software industry and software supply chain security is no exception. To understand how industry luminaries like Kate Stewart are thinking about the future of SBOMs through this evolution, watch Understanding SBOMs: Deep Dive with Kate Stewart.
This webinar highlights several key points:
LLMs pose unique transparency challenges:The emergence of large language models reduces transparency since behavior is stored in datasets and training processes rather than code
Software introspection limitations: Already difficult with traditional software, introspection becomes both harder AND more important in the LLM era
Dataset lineage tracking: Stewart draws a parallel between SBOMs for supply chain security and the need for dataset provenance for LLMs
Behavior traceability: She advocates for “SBOMs of [training] datasets” that allow organizations to trace behavior back to a foundational source
“Transparency is the path to minimizing risk.” —Kate Stewart
This perspective expands the SBOM concept beyond mere software component inventories to encompass the broader information needed for transparency in AI-powered systems.
Content over format debates: Springett emphasizes that “content is king”—the actual data within SBOMs and their practical use-cases matter far more than format wars
Machine-readable attestations: Historically manual compliance activities can now be automated through structured data that provides verifiable evidence to auditors
Business process metadata: CycloneDX can include compliance process metadata like security training completion, going beyond component inventories
Compliance flexibility: The ability to attest to any standard, from government requirements to custom internal company policies
Quality-focused approach: Springett introduces five dimensions for evaluating SBOM completeness and a maturity model with profiles for different stakeholders (AppSec, SRE, NetSec, Legal/IP)
“The end-goal is transparency.” — Steve Springett
Echoing the belief of Kate Stewart, Springett reinforces the purpose of SBOMs as transparency tools. His perspective transforms our understanding of SBOMs from static component inventories to versatile data containers that attest to broader security and compliance activities.
Kelsey Hightower, Google’s former distinguished engineer, offers a pragmatic perspective that reframes security in developer-friendly terms. Watch Software Security in the Real World with Kelsey Hightower to learn how his “Security as Unit Tests” mental model helps developers integrate security naturally into their workflow by:
Treating security requirements as testable assertions
How SBOMs act as source of truth for supply chain data for tests
Integrating verification into the CI/CD pipeline
Making security outcomes measurable and reproducible
Hightower’s perspective helps bridge the gap between development practices and security requirements, with SBOMs serving as a foundational element in automated verification.
As we’ve seen from these expert perspectives, SBOMs are not just a technical tool but a strategic asset that intersects with many aspects of software development and security. In our final post, we’ll explore these intersections in depth, examining how SBOMs relate to DevSecOps, open source security, and regulatory compliance.
Stay tuned for the final installment in our series, “SBOMs as the Crossroad of the Software Supply Chain,” where we’ll complete our comprehensive exploration of software bills of materials.
As your SBOM adoption graduates from proof-of-concept to enterprise implementation, several critical questions emerge:
How do you manage thousands—or even millions—of SBOMs?
How do you seamlessly integrate SBOM processes into complex CI/CD environments?
How do you extract maximum value from your growing SBOM repository?
Let’s explore three powerful resources that form a roadmap for scaling your SBOM initiative across your organization.
SBOM Automation: The Key to Scale
After you’ve generated your first SBOM and discovered the value, the next frontier is scaling across your entire software environment. Without robust automation, manual SBOM processes quickly become bottlenecks in fast-moving DevOps environments.
Key benefits:
Eliminates time-consuming manual SBOM generation and analysis
Ensures consistent SBOM quality across all repositories
Enables real-time security and compliance insights
The webinar Understanding SBOMs: How to Automate, Generate & Manage SBOMs delivers practical strategies for building automation into your SBOM pipeline from day one. This session unpacks how well-designed SBOM management services can handle CI/CD pipelines that process millions of software artifacts daily.
Real-world SBOMs: How Google Scaled to 4M+ SBOMs Daily
Nothing builds confidence like seeing how industry leaders have conquered the same challenges you’re facing. Google’s approach to SBOM implementation offers invaluable lessons for organizations of any size.
How Google architected their SBOM ecosystem for massive scale
Integration patterns that connect SBOMs to their broader security infrastructure
Practical lessons learned during their implementation journey
This resource transforms theoretical SBOM scaling concepts into tangible strategies you can adapt for your environment. If an organization as large and complex as Google can successfully deploy an SBOM initiative at scale—you can too!
Building a scalable SBOM data pipeline with advanced features like vulnerability management and automated compliance policy enforcement represents a significant engineering investment. For many organizations, leveraging purpose-built solutions makes strategic sense.
Anchore Enterprise offers an alternative path with three integrated components:
Anchore SBOM: A turnkey SBOM management platform with enterprise-grade features
Anchore Secure: Cloud-native vulnerability management powered by comprehensive SBOM data
Anchore Enforce: An SBOM-driven policy enforcement engine that automates compliance checks
As you scale your SBOM initiative, keep one eye on emerging trends and use cases. The SBOM ecosystem continues to evolve rapidly, with new applications emerging regularly.
In our next post, we’ll explore insights from industry experts on the future of SBOMs and their strategic importance. Stay tuned for part four of our series, “SBOM Insights on LLMs, Compliance Attestations and Security Mental Models”.
This post is designed for hands-on practitioners—the engineers, developers, and security professionals who want to move from theory to implementation. We’ll explore practical tools and techniques for generating, integrating, and leveraging SBOMs in your development workflows.
A list of the 4 most popular SBOM generation tools
How to install and configure Syft
How to scan source code, a container or a file directory’s supply chain composition
How to generate an SBOM in CycloneDX or SPDX formats based on the supply chain composition scan
A decision framework for evaluating and choosing an SBOM generator
Generating accurate SBOMs is the foundation of your software supply chain transparency initiative. Without SBOMs, valuable use-cases like vulnerability management, compliance audit management or license management are low-value, time sinks instead of efficient, value-add activities.
If you’re looking for step-by-step guides for popular ecosystems like Javascript, Python, GitHub or Docker 👈follow the links).
Under the Hood: How SBOM Generation Works
For those interested in the gory technical details of how a software composition analysis (SCA) tool and SBOM generator scale this function, How Syft Scans Software to Generate SBOMs is the perfect blog post to scratch that intellectual itch.
What you’ll learn:
The scanning algorithms that identify software components
How Syft handles package ecosystems (npm, PyPI, Go modules, etc.)
Performance optimization techniques for large codebases
Ways to contribute to the open source project
Understanding the “how” behind the SBOM generation process enables you to troubleshoot edge cases and customize tools when you’re ready to squeeze the most value from your SBOM initiative.
Pro tip: Clone the Syft repository and step through the code with a debugger to really understand what’s happening during a scan. It’s the developer equivalent of taking apart an engine to see how it works.
Advancing with Policy-as-Code
Our guide, The Developer’s Guide to SBOMs & Policy-as-Code, bridges the gap between generating SBOMs and automating the SBOM use-cases that align with business objectives. A policy-as-code strategy allows many of the use-cases to scale in cloud native environments and deliver outsized value.
What you’ll learn:
How to automate tedious compliance tasks with PaC and SBOMs
How to define security policies (via PaC) that leverage SBOM data
Integration patterns for CI/CD pipelines
How to achieve continuous compliance with automated policy enforcement
Combining SBOMs with policy-as-code creates a force multiplier for your security efforts, allowing you to automate compliance and vulnerability management at scale.
Pro tip: Start with simple policies that flag known CVEs, then gradually build more sophisticated rules as your team gets comfortable with the approach
Taking the Next Step
After dipping your feet into the shallow end of SBOM generation and integration, the learning continues with an educational track on scaling SBOMs for enterprise-grade deployments. In our next post, we’ll lay out how to take your SBOM initiative from proof-of-concept to production, with insights on automation, management, and real-world case studies.
Stay tuned for part three of our series, “DevOps-Scale SBOM Management,” where we’ll tackle the challenges of implementing SBOMs across large teams and complex environments.
Short on time but need to understand SBOMs yesterday? Start your educational journey with this single-serving webinar on SBOM fundamentals—watch it at 2x for a true speedrun.
This webinar features Anchore’s team of SBOM experts who guide you through all the SBOM basics – topics covered:
Defining SBOM standards and formats
Best practices for generating and automating SBOMs
Integrating SBOMs into existing infrastructure and workflows
Practical tips for protecting against emerging supply chain threats
“You really need to know what you’re shipping and what’s there.” —Josh Bressers
This straightforward yet overlooked insight demonstrates the foundational nature of SBOMs to software supply chain security. Operating without visibility into your components creates significant security blind spots. SBOMs create the transparency needed to defend against the rising tide of supply chain attacks.
Improve SBOM Initiative Success: Crystalize the Core SBOM Mental Models
Explain how SBOMs are the central component of software supply chain
A quick reference table of SBOM use-cases
This gives you a strong foundation to build your SBOM initiative on. The mental models presented in the eBook help you:
avoid common implementation pitfalls,
align your SBOM strategy with security objectives, and
communicate SBOM value to stakeholders across your organization.
Rather than blindly following compliance requirements, you’ll learn the “why” behind SBOMs and make informed decisions about automation tools, integration points, and formats that are best suited for your specific environment.
Security teams: Rapidly identify vulnerable components when zero-days hit the news
Engineering teams: Make data-driven architecture decisions about third-party dependencies to incorporate
Compliance teams: Automate evidence collection for compliance audits
Legal teams: Proactively manage software license compliance and IP risks
Sales teams: Accelerate sales cycles by using transparency as a tool to build trust fast
“Transparency is the path to minimizing risk.” —Kate Stewart, VP of Embedded Systems at The Linux Foundation and Founder of SPDX
This core SBOM principle applies across all business functions. Our white paper shows how properly implemented SBOMs create a unified source of truth about your software components that empowers teams beyond security to make better decisions.
Perfect for technical leaders who need to justify SBOM investments and drive cross-team adoption.
After completing the fundamentals, you’re ready to get your hands dirty and learn the nitty-gritty of SBOM generation and CI/CD build pipeline integration. In our next post, we’ll map out a technical learning path with deep-dives for practitioners looking to get hands-on experience. Stay tuned for part two of our series, “SBOM Generation Step-by-Step”.
A DoD Software Factory is a DevSecOps-based development pipeline adapted to the DoD’s high-threat environment, reflecting the government’s broader push for software and cybersecurity modernization.
DoD software factories typically include code repositories, CI/CD build pipelines, artifact repositories, and runtime orchestrators and platforms.
Use pre-existing software factories or roll out your own by following DoD best practices like continuous vulnerability scanning and automated policy checks.
SCA tools like Anchore Enterprise address the unique security, compliance, and operational needs of DoD Software Factories by delivering end-to-end software supply chain security and automated compliance.
In the rapidly evolving landscape of national defense and cybersecurity, the concept of a Department of Defense (DoD) software factory has emerged as a cornerstone of innovation and security. These software factories represent an integration of the principles and practices found within the DevSecOps movement, tailored to meet the unique security requirements of the DoD and Defense Industrial Base (DIB).
By fostering an environment that emphasizes continuous monitoring, automation, and cyber resilience, DoD Software Factories are at the forefront of the United States Government’s push towards modernizing its software and cybersecurity capabilities. This initiative not only aims to enhance the velocity of software development but also ensures that these advancements are achieved without compromising on security, even against the backdrop of an increasingly sophisticated threat landscape.
Building and running a DoD software factory is so central to the future of software development that “Establish a Software Factory” is the one of the explicitly named plays from the DoD DevSecOps Playbook. On top of that, the compliance capstone of the authorization to operate (ATO) or its DevSecOps infused cousin the continuous ATO (cATO) effectively require a software factory in order to meet the requirements of the standard. In this blog post, we’ll break down the concept of a DoD software factory and a high-level overview of the components that make up one.
A Department of Defense (DoD) Software Factory is a software development pipeline that embodies the principles and tools of the larger DevSecOps movement with a few choice modifications that conform to the extremely high threat profile of the DoD and DIB. It is part of the larger software and cybersecurity modernization trend that has been a central focus for the United States Government in the last two decades.
The goal of a DoD Software Factory is aimed at creating an ecosystem that enables continuous delivery of secure software that meet the needs of end-users while ensuring cyber resilience (a DoD catchphrase that emphasizes the transition from point-in-time security compliance to continuous security compliance). In other words, the goal is to leverage automation of software security tasks in order to fulfill the promise of the DevSecOps movement to increase the velocity of software development.
Example of a DoD software factory
Platform One is the canonical example of a DoD software factory. Run by the US Air Force, it offers both a comprehensive portfolio of software development tools and services. It has come to prominence due to its hosted services like Repo One for source code hosting and collaborative development, Big Bang for a end-to-end DevSecOps CI/CD platform and the Iron Bank for centralized container storage (i.e., container registry). These services have led the way to demonstrating that the principles of DevSecOps can be integrated into mission critical systems while still preserving the highest levels of security to protect the most classified information.
Any organization that works with the DoD as a federal service integrator will want to be intimately familiar with DoD software factories as they will either have to build on top of existing software factories or, if the mission/program wants to have full control over their software factory, be able to build their own for the agency.
Department of Defense (DoD) Mission
Any Department of Defense (DoD) mission will need to be well-versed on DoD software factories as all of their software and systems will be required to run on a software factory as well as both reach and maintain a cATO.
Principles of DevSecOps embedded into a DoD software factory
A DoD software factory is composed of both high-level principles and specific technologies that meet these principles. Below are a list of some of the most significant principles of a DoD software factory:
Breakdown organizational silos: This principle is borrowed directly from the DevSecOps movement, specifically the DoD aims to integrate software development, test, deployment, security and operations into a single culture with the organization.
Open source and reusable code: Composable software building blocks is another principle of the DevSecOps that increases productivity and reduces security implementation errors from developers writing secure software packages that they are not experts in.
Immutable Infrastructure-as-Code (IaC): This principle focuses on treating the infrastructure that software runs on as ephemeral and managed via configuration rather than manual systems operations. Enabled by cloud computing (i.e., hardware virtualization) this principle increases the security of the underlying infrastructure through templated secure-by-design defaults and reliability of software as all infrastructure has to be designed to fail at any moment.
Microservices architecture (via containers): Microservices are a design pattern that creates smaller software services that can be built and scale independently of each other. This principle allows for less complex software that only performs a limited set of behavior.
Shift Left: Shift left is the DevSecOps principle that re-frames when and how security testing is done in the software development lifecycle. The goal is to begin security testing while software is being written and tested rather than after the software is “complete”. This prevents insecure practices from cascading into significant issues right as software is ready to be deployed.
Continuous improvement through key capabilities: The principle of continuous improvement is a primary characteristic of the DevSecOps ethos but the specific key capabilities that are defined in the DoD DevSecOps playbook are what make this unique to the DoD.
Define a DevSecOps pipeline: A DevSecOps pipeline is the workflow that utilizes all of the preceding principles in order to create the continuously improving security outcomes that is the goal of the DoD software factory program.
Cyber resilience: Cyber resiliency is the goal of a DoD software factory, is it defined as, “the ability to anticipate, withstand, recover from, and adapt to adverse conditions, stresses, attacks, or compromises on the systems that include cyber resources.”
Common tools and systems for implementing a DoD software factory
Implementing a DoD software factory requires more than just modern development practices; it depends on a secure, repeatable toolchain that meets strict compliance and accreditation standards. At its core, a software factory is built on a set of foundational systems that move code from development through deployment. Below are the key components most commonly used across DoD software factories, and how they work together to deliver secure, mission-ready software.
Code Repository (e.g., Repo One): Central location where software source code is stored and version-controlled. In DoD environments, repositories ensure controlled access, auditability, and secure collaboration across distributed teams.
CI/CD Build Pipeline (e.g., Big Bang): Automates builds, runs security and compliance checks, executes tests, and packages code for deployment. Automation reduces human error and enforces consistency so that every release meets DoD security and accreditation requirements.
Artifact Repository (e.g., Iron Bank): Trusted storage for approved software components and final build artifacts. Iron Bank, for example, provides digitally signed and hardened container images, reducing supply chain risk and ensuring only vetted software moves forward.
Runtime Orchestrator and Platform (e.g., Big Bang): Deploys and manages software artifacts at scale. Orchestrators like hardened Kubernetes stacks enable repeatable deployments across multiple environments (classified and unclassified), while maintaining security baselines and reliability.
Together, these systems form a secure pipeline: code enters Repo One, passes through CI/CD checks, vetted artifacts are stored in Iron Bank, and then deployed and orchestrated with Big Bang. Anchore Enterprise integrates directly into this flow, scanning and enforcing policy at each stage to ensure only compliant, secure software artifacts move through the factory.
How do I meet the security requirements for a DoD Software Factory? (Best Practices)
Use a pre-existing software factory
The benefit of using a pre-existing DoD software factory is the same as using a public cloud provider; someone else manages the infrastructure and systems. What you lose is the ability to highly customize your infrastructure to your specific needs. What you gain is the simplicity of only having to write software and allow others with specialized skill sets to deal with the work of building and maintaining the software infrastructure. When you are a car manufacturer, you don’t also want to be a civil engineering firm that designs roads.
If you need the flexibility and customization of managing your own software factory then we’d recommend following the DoD Enterprise DevSecOps Reference Design as the base framework. There are a few software supply chain security recommendations that we would make in order to ensure that things go smoothly during the authorization to operate (ATO) process:
Continuous vulnerability scanning across all stages of CI/CD pipeline: Use a cloud-native vulnerability scanner that can be directly integrated into your CI/CD pipeline and called automatically during each phase of the SDLC
Automated policy checks to enforce requirements and achieve ATO: Use a cloud-native policy engine in tandem with your vulnerability scanner in order to automate the reporting and blocking of software that is a security threat and a compliance risk
Remediation feedback: Use a cloud-native policy engine that can provide automated remediation feedback to developers in order to maintain a high velocity of software development
Compliance (Trust but Verify): Use a reporting system that can be directly integrated with your CI/CD pipeline to create and collect the compliance artifacts that can prove compliance with DoD frameworks (e.g., CMMC and cATO)
Is a software factory required in order to achieve cATO?
Technically, no. Effectively, yes. A cATO requires that your software is deployed on an Approved DoD Enterprise DevSecOps Reference Design not a software factory specifically. If you build your own DevSecOps platform that meets the criteria for the reference design then you have effectively rolled your own software factory.
How Anchore can help
The easiest and most effective method for achieving the security guarantees that a software factory is required to meet for its software supply chain are by using:
DoD software factories can come off as intimidating at first but hopefully we have broken them down into a more digestible form. At their core they reflect the best of the DevSecOps movement with specific adaptations that are relevant to the extreme threat environment that the DoD has to operate in, as well as, the intersecting trend of the modernization of federal security compliance standards.
If you’re looking to dive deeper into all things DoD software factory, we have a white paper that lays out the 6 best practices for container images in highly secure environments. Download the white paper below.
Anchore has been leading the SBOM charge for almost a decade: providing educational resources, tools and insights, and to help organizations secure their software supply chains. To help organizations navigate this critical aspect of software development, we’re excited to announce SBOM Learning Week!
Each day of the week we will be publishing a new blog post that provides an overview of how to progress on your SBOM educational journey. By the end of the week, you will have a full learning path laid out to guide you from SBOM novice to SBOM expert.
Why SBOM Learning Week, Why Now?
With recent executive orders (e.g., EO 14028) mandating SBOMs for federal software vendors and industry standards increasingly recommending their adoption, organizations across sectors are racing to weave SBOMs into their software development lifecycle. However, many still struggle with fundamental questions:
What exactly is an SBOM and why does it matter?
How do I generate, manage, and leverage SBOMs effectively?
How do I scale SBOM practices across a large organization?
What do leading experts predict for the future of SBOM adoption?
How do SBOMs integrate with existing security and development practices?
SBOM Learning Week answers these questions through a carefully structured learning journey designed for both newcomers and experienced practitioners.
What to Expect Each Day
Monday: SBOM Fundamentals
We’ll start with the fundamentals, exploring what SBOMs are, why they matter, and the key standards that define them. This foundational knowledge will prepare you for the more advanced topics to come.
Day two focuses on hands-on implementation, with practical guidance for generating SBOMs using open source tools, integrating them into CI/CD pipelines, and examining how SBOM generation actually works under the hood.
Moving beyond initial implementation, we’ll explore how organizations can scale their SBOM practices across enterprise environments, featuring real-world examples from companies like Google.
Thursday: SBOM Insights on LLMs, Compliance Attestations and Security Mental Models
On day four, we’ll share insights from industry thought leaders on how software supply chain security and SBOMs are adapting to LLMs, how SBOMs are better thought of as compliance data containers than supply chain documents and how SBOMs and vulnerability scanners fit into existing developer mental models.
Whether you’re a security leader looking to strengthen your organization’s defenses, a developer seeking to integrate security into your workflows, or an IT professional responsible for compliance, SBOM Learning Week offers valuable insights for your role.
Each day’s post will build on the previous content, creating a comprehensive resource you can reference as you develop and mature your organization’s SBOM initiative. We’ll also be monitoring comments and questions on our social channels (LinkedIn, BlueSky, X) throughout the week to help clarify concepts and address specific challenges you might face.
Mark your calendars and join us starting Monday as we embark on this exploration of one of today’s most important cybersecurity technologies. The journey to a more secure software supply chain begins with understanding what’s in your code—and SBOM Week will show you exactly how to get there.
That’s why we’re excited to announce our new white paper, “Unlocking Federal Markets: The Enterprise Guide to FedRAMP.” This comprehensive resource is designed for cloud service providers (CSPs) looking to navigate the complex FedRAMP authorization process, providing actionable insights and step-by-step guidance to help you access the lucrative federal cloud marketplace.
From understanding the authorization process to implementing continuous monitoring requirements, this guide offers a clear roadmap through the FedRAMP journey. More than just a compliance checklist, it delivers strategic insights on how to approach FedRAMP as a business opportunity while minimizing the time and resources required.
⏱️ Can’t wait till the end? 📥 Download the white paper now 👇👇👇
FedRAMP is the gateway to federal cloud business, but many organizations underestimate its complexity and strategic importance. Our white paper transforms your approach by:
Clarifying the Authorization Process: Understand the difference between FedRAMP authorization and certification, and learn the specific roles of key stakeholders.
Streamlining Compliance: Learn how to integrate security and compliance directly into your development lifecycle, reducing costs and accelerating time-to-market.
Establishing Continuous Monitoring: Build sustainable processes that maintain your authorization status through the required continuous monitoring activities.
Creating Business Value: Position your FedRAMP authorization as a competitive advantage that opens doors across multiple agencies.
What’s Inside the White Paper?
Our guide is organized to follow your FedRAMP journey from start to finish. Here’s a preview of what you’ll find:
FedRAMP Overview: Learn about the historical context, goals and benefits of the program.
Key Stakeholders: Understand the roles of federal agencies, 3PAOs and the FedRAMP PMO.
Authorization Process: Navigate through all phases—Preparation, Authorization and Continuous Monitoring—with detailed guidance for each step.
Strategic Considerations: Make informed decisions about impact levels, deployment models and resource requirements.
Compliance Automation: Discover how Anchore Enforce can transform FedRAMP from a burdensome audit exercise into a streamlined component of your software delivery pipeline.
You’ll also find practical insights on staffing your authorization effort, avoiding common pitfalls and estimating the level of effort required to achieve and maintain FedRAMP authorization.
Transform Your Approach to Federal Compliance
The white paper emphasizes that FedRAMP compliance isn’t just a one-time hurdle but an ongoing commitment that requires a strategic approach. By treating compliance as an integral part of your DevSecOps practice—with automation, policy-as-code and continuous monitoring—you can turn FedRAMP from a cost center into a competitive advantage.
Whether your organization is just beginning to explore FedRAMP or looking to optimize existing compliance processes, this guide provides the insights needed to build a sustainable approach that opens doors to federal business opportunities.
Download the White Paper Today
FedRAMP authorization is more than a compliance checkbox—it’s a strategic enabler for your federal market strategy. Our comprehensive guide gives you the knowledge and tools to navigate this complex process successfully.
📥 Download the white paper now and unlock your path to federal markets.
Learn how to navigate FedRAMP authorization while avoiding all of the most common pitfalls.
When CVE-2025-1974 (#IngressNightmare) was disclosed, incident response teams had hours—at most—before exploits appeared inthewild. Imagine two companies responding:
Company A rallies a war room with 13 different teams frantically running kubectl commands across the org’s 30+ clusters while debugging inconsistent permission issues.
Company B’s security analyst runs a single query against their centralized SBOM inventory and their policy-as-code engine automatically dispatches alerts and remediation recommendations to affected teams.
Which camp would you rather be in when the next critical CVE drops? Most of us prefer the team that built visibility for their software supply chain security before the crisis hit.
CVE-2025-1974 was particularly acute because of ingress-nginx‘s popularity as a Kubernetes Admission Controller (40%+ of Kubernetes administrators) and the type/severity of the vulnerability (RCE & CVSS 9.8—scary!) We won’t go deep on the details; there are plenty of good existing resources already.
Instead we’ll focus on:
The inconsistency between the naive incident response guidance and real-world challenges
The negative impacts common to incident response for enterprise-scale Kubernetes deployments
When the Ingress Nightmare vulnerability was published, security blogs and advisories quickly filled with remediation advice. The standard recommendation was clear and seemed straightforward: run a simple kubectl command to determine if your organization was impacted:
kubectl get pods --all-namespaces --selector app.kubernetes.io/name=ingress-nginx
If vulnerable versions were found, upgrade immediately to the patched versions.
This advice isn’t technically wrong. The command will indeed identify instances of the vulnerable ingress-nginx controller. But it makes a set of assumptions that bear little resemblance to Kubernetes deployments in modern enterprise organizations:
That you run a single Kubernetes cluster
That you have a single Kubernetes administrator
That this admin has global privileges across the entire cluster
For the vast majority of enterprises today, none of these assumptions are true.
The Reality of Enterprise-Scale Kubernetes: Complex & Manual
The reality of Kubernetes deployments at large organizations is far more complex than most security advisories acknowledge:
1. Inherited Complexity
Kubernetes administration structures almost always mirror organizational complexity. A typical enterprise doesn’t have a single cluster managed by a single team—they have dozens of clusters spread across multiple business units, each with their own platform teams, their own access controls, and often their own security policies.
This organizational structure, while necessary for business operations, creates significant friction for vital incident response activities; vulnerability detection and remediation. When a critical CVE like Ingress Nightmare drops, there’s no single person who can run that kubectl command across all environments.
2. Vulnerability Management Remains Manual
While organizations have embraced Kubernetes to automate their software delivery pipelines and increase velocity, the DevOps-ification of vulnerability and patch management have lagged. Instead they retain their manual, human-driven processes.
During the Log4j incident in 2021, we observed engineers across industries frantically connecting to servers via SSH and manually dissecting container images, trying to determine if they were vulnerable. Three years later, for many organizations, the process hasn’t meaningfully improved—they’ve just moved the complexity to Kubernetes.
The idea that teams can manually track and patch vulnerabilities across a sprawling Kubernetes estate is not just optimistic—it’s impossible at enterprise-scale.
The Cascading Negative Impacts: Panic, Manual Coordination & Crisis Response
When critical vulnerabilities emerge, organizations without supply chain visibility face:
Organizational Panic: The CISO demands answers within the hour while security teams scramble through endless logs, completely blind to which systems contain the vulnerable components.
Complex Manual Coordination: Security leads discover they need to scan hundreds of clusters but have access to barely a fifth of them, as Slack channels erupt with conflicting information and desperate access requests.
Resource-Draining Incident Response: By day three of the unplanned war room, engineers with bloodshot eyes and unchanged clothes stare at monitors, missing family weekends while piecing together an ever-growing list of affected systems.
Delayed Remediation: Six weeks after discovering the vulnerability in a critical payment processor, the patch remains undeployed as IT bureaucracy delays the maintenance window while exposed customer data hangs in the balance.
The Solution: Centralized SBOM Inventory + Automated Policy Enforcement
Organizations with mature software supply chain security leverage Anchore Enterprise to address these challenges through an integrated SBOM inventory and policy-as-code approach:
Anchore Enterprise transforms vulnerability response through its industry-leading SBOM repository. When a critical vulnerability like Ingress Nightmare emerges, security teams use Anchore’s intuitive dashboard to instantly answer the existential question: “Are we impacted?”
This approach works because:
Role-based access to a centralized inventory is provided by Anchore SBOM for security incident response teams, cataloging every component across all Kubernetes clusters regardless of administrative boundaries
Components missed by standard package manager checks (including binaries, language-specific packages, and container base images) are identified by AnchoreCTL, a modern software composition analysis (SCA) scanner
Vulnerability correlation in seconds is enabled through Anchore SBOM’s repository with its purpose-built query engine, turning days of manual work into a simple search operation
2. Anchore Enforce: Automated Policy Enforcement
Beyond just identifying vulnerable components, Anchore Enforce’s policy engine integrates directly into an existing CI/CD pipeline (i.e., policy-as-code security gates). This automatically answers the follow-up questions: “Where and how do we remediate?”
Anchore Enforce empowers teams to:
Alert code owners to the specific location of vulnerable components
Provide remediation recommendations directly in developer workflows (Jira, Slack, GitLab, GitHub, etc.)
Eliminate manual coordination between security and development teams with the policy engine and DevTools-native integrations
Quantifiable Benefits: No Panic, Reduced Effort & Reduced Risk
Organizations that implement this approach see dramatic improvements across multiple dimensions:
Eliminated Panic: The fear and uncertainty that typically accompany vulnerability disclosures disappear when you can answer “Does this impact us?” in minutes rather than days.
Immediate clarity on the impact of the disclosure is at your finger tips with the Anchore SBOM inventory and Kubernetes Runtime Dashboard
Reduced Detection Effort: The labor-intensive coordination between security, platform, and application teams becomes unnecessary.
Security incident response teams already have access to all the data they need through the centralized Anchore SBOM inventory generated as part of normal CI/CD pipeline use.
Minimized Exploitation Risk: The window of vulnerability shrinks dramatically as developers are able to address vulnerabilities before they can be exploited.
Developers receive automated alerts and remediation recommendations from Anchore Enforce’s policy engine that integrate natively with existing development workflows.
How to Mitigate CVE-2025-1974 with Anchore Enterprise
Let’s walk through how to detect and mitigate CVE-2025-1974 with Anchore Enterprise across a Kubernetes cluster. The Kubernetes Runtime Dashboard serves as the user interface for your SBOM database. We’ll demonstrate how to:
Identify container images with ingress-nginx integrated
Locate images where CVE-2025-1974 has been detected
Generate reports of all vulnerable container images
Generate reports of all vulnerable running container instances in your Kubernetes cluster
Step 1: Identify location(s) of impacted assets
The Anchore Enterprise Dashboard can be filtered to show all clusters with the ingress-nginx controller deployed. Thanks to the existing SBOM inventory of cluster assets, this becomes a straightforward task, allowing you to quickly pinpoint where vulnerable components might exist.
Step 2: Drill into container image analysis for additional details
By examining vulnerability and policy compliance analysis at the container image level, you gain increased visibility into the potential cluster impact. This detailed view helps prioritize remediation efforts based on risk levels.
Step 3: Drill down into container image vulnerability report
When you drill down into the CVE-2025-1974 vulnerability, you can view additional details that help understand its nature and impact. Note the vulnerability’s unique identifier, which will be needed for subsequent steps. From here, you can click the ‘Report’ button to generate a comprehensive vulnerability report for CVE-2025-1974.
Step 4: Configure a vulnerability report for CVE-2025-1974
To generate a report on all container images tagged with the CVE-2025-1974 unique vulnerability ID:
Select the Vulnerability Id filter
Paste the CVE-2025-1974 vulnerability ID into the filter field
The vulnerability report identifies all container images tagged with the unique vulnerability ID. To remediate the vulnerability effectively, base images that running instances are built from need to be updated to ensure the fix propagates across all cluster services.
While there may be only two base images containing the vulnerability, these images might be reused across multiple products and services in the Kubernetes cluster. A report based solely on base images can obscure the true scale of vulnerable assets in a cluster. A namespace-based report provides a more accurate picture of your exposure.
Wrap-Up: Building Resilience Before the Crisis
The next Ingress Nightmare-level vulnerability isn’t a question of if, but when. Organizations that invest in software supply chain security before a crisis occurs will respond with targeted remediation rather than scrambling in war rooms.
Anchore’s SBOM-powered SCA provides the comprehensive visibility and automated policy enforcement needed to transform vulnerability response from a chaotic emergency into a routine, manageable process. By building software supply chain security into your DevSecOps pipeline today, you ensure you’ll have the visibility you need when it matters most.
Ready to see how Anchore Enterprise can strengthen your Kubernetes security posture? Request a demo today to learn how our solutions can help protect your critical infrastructure from vulnerabilities like CVE-2025-1974.
Learn how Spectro Cloud secured their Kubernetes-based software supply chain and the pivotal role SBOMs played.
Today, we’re launching the Anchore Enterprise Cloud Image, a pre-built image designed to dramatically reduce the complexity and time associated with deploying Anchore Enterprise in your AWS environment.
Anchore Enterprise Cloud Image is designed for practitioners working on small teams or projects that are focused on integrating robust container scanning and compliance checks into build pipelines, but perhaps without the immediate need for the full scale-out capabilities of a Kubernetes-based deployment. No working knowledge of Kubernetes is required in order to fully utilize SBOM powered Software Composition Analysis provided by Anchore Enterprise.
Addressing the Deployment Overhead:
Anchore Enterprise has long been recognized for its powerful analysis engine and comprehensive policy enforcement, typically deployed on Kubernetes using Helm. While this architecture provides immense scalability, scheduling and flexibility for large organizations handling 10,000s of daily scans, we understand that for smaller teams or individual projects, the operational overhead of managing a Kubernetes cluster can be atime and resource burden.
The Anchore Enterprise Cloud Image directly addresses this challenge. We’ve packaged a fully functional Anchore Enterprise instance into a ready-to-run Amazon Machine Image (AMI). This prescriptive deployment eliminates the need for intricate Kubernetes knowledge, allowing you to focus on securing your containers from day one.
Key Features and Benefits for AWS Practitioners:
Radically Simplified Deployment: Forget complex Helm charts and manual configuration. Simply launch the AMI from the AWS Marketplace in your preferred region (including GovCloud), and you’re on your way. This significantly reduces the time and effort required for initial setup.
Interactive Cloud Image Manager: We’ve introduced a user-friendly, console-based Cloud Image Manager that guides you through the initial configuration and manages upgrades. Upon booting the AMI, this tool intelligently assesses your AWS environment, ensures the correct resources are provisioned, and then prompts you for basic setup parameters. It then automates the installation and all of the services necessary to run it with their appropriate configurations.
Guided First Scan Experience: Once the installation is complete, accessing the Anchore Enterprise UI is seamless. A new in-product wizard will walk you through the process of performing your first container image scan, allowing you to quickly experience the power of Anchore’s deep analysis capabilities.
Optimized Performance on Select Instance Types: We’ve rigorously tested Anchore Enterprise on a specific set of AWS instance types to identify the optimal balance of cost and performance for the application. This means we can provide you with deterministic performance guidelines regarding the volume of data the deployment can effectively process, allowing for better capacity planning and cost management.
Integrated Compliance Policy Packs: For organizations with stringent compliance requirements, the Cloud Image simplifies the adoption of industry-standard policies. Based on your subscription entitlement, the Cloud Image will automatically install relevant policy packs, such as those aligned with NIST or FedRAMP frameworks. This ensures that your container security posture aligns with your regulatory needs from the outset.
Who is this for?
The Anchore Enterprise Cloud Image on AWS is ideal for:
Small to medium-sized teams looking for a streamlined deployment experience.
Projects that require immediate container scanning and compliance capabilities without the overhead of managing Kubernetes.
Organizations seeking a prescriptive and easily manageable container security solution on AWS.
Teams wanting to quickly evaluate the capabilities of Anchore Enterprise in their AWS environment.
Getting Started
We believe the Anchore Enterprise Cloud Image represents a significant step in making our powerful container security platform more accessible to a wider range of AWS customers. By abstracting away the complexities of infrastructure management, we empower you to focus on what matters most: securing your software supply chain.
If you are interested in trying Anchore Enterprise as a Cloud Image, please contact sales.
> Josh, can you tell our readers what you mean when you say NVD stopped enriching data?
Sure! When people or organizations disclose a new security vulnerability, it’s often just a CVE (Common Vulnerabilities and Exposures) number (like CVE-2024-1234) and a description.
Historically, NVD would take this data, and NVD analysts would add two key pieces of information: the CPEs (Common Platform Enumerations), which are meant to identify the affected software, and the CVSS (Common Vulnerability Scoring System) score, which is meant to give users of the data a sense of how serious the vulnerability is and how it can be exploited.
For many years, NVD kept up pretty well. Then, in March 2024, they stopped.
> That sounds bad. Were they able to catch up?
Not really.
One of the problems they face is that the number of CVEs in existence is growing exponentially. They were having trouble keeping up in 2024, but 2025 is making CVEs even faster than 2024 did, plus they have the backlog of CVEs that weren’t enriched during 2024.
It seems unlikely that they can catch up at this point.
Graph showing how few CVE IDs are being enriched with matching data since April 2024
Graph showing the number of total CVEs (green) and the number of enriched CVEs (red). “The line slopes say it all”—NVD is behind and the number of unreviewed CVEs is growing.
> So what’s the upshot here? Why should we care that NVD isn’t able to enrich vulnerabilities?
Well, there are basically two problems with NVD not enriching vulnerabilities.
First, if they don’t have CPEs on them, there’s no machine-readable way to know what software they affect. In other words, part of the work NVD was doing is writing down what software (or hardware) is affected in a machine-readable way, enabling vulnerability scanners and other software to tell which components are affected.
The loss of this is obviously bad. It means that there is a big pile of security flaws that are public—meaning that threat actors know about them—but security teams will have a harder time detecting them. Un-enriched CVEs are not labeled with CPEs, so programmatic analysis is off the table and teams will have to fall back to manual review.
Second, enrichment of CVEs is supposed to add a CVSS score—essentially a severity level—to CVEs. CVSS isn’t perfect, but it does allow organizations to say things like, “this vulnerability is very easy to exploit, so we need to get it fixed before this other CVE which is very hard to exploit.” Without CVSS or something like it, these tradeoffs are much harder for organizations to make.
> And this has been going on for more than a year? That sounds bad. What is Anchore doing to keep their customers safe?
The first thing we needed to do was make a place where we can take up some of the slack that NVD can’t. To do this, we created a public database of our own CVE enrichment. This means that, when major CVEs are disclosed, we can enrich them ahead of NVD, so that our scanning tools (both Grype and Anchore Secure) are able to detect vulnerable packages—even if NVD never has the resources to look into that particular CVE.
Additionally, because NVD severity scores are becoming less reliable and less available, we’ve built a prioritization algorithm into Anchore Secure that allows customers to keep doing the kind of triaging they used to rely on NVD CVSS for.
> Is the vulnerability enhancement data publicly available?
Yes, the data is publicly available.
Also, the process for changing it is out in the open. One of the more frustrating things about working with NVD enrichment was that sometimes they would publish an enrichment with really bad data and then all you could do was email them—sometimes they would fix it right away and sometimes they would never get to it.
With Anchore’s open vulnerability data, anyone in the community can review and comment on these enrichments.
> So what are your big takeaways from the past year?
I think the biggest takeaway is that we can still do vulnerability matching.
We’re pulling together our own public vulnerability database, plus data feeds from various Linux distributions and of course GitHub Security Advisories to give our customers the most accurate vulnerability scan we can. In many ways, reducing our reliance on NVD CPEs has improved our matching (see this post, for example).
The other big takeaway is that, because so much of our data and tooling are open source, the community can benefit from and help with our efforts to provide the most accurate security tools in the world.
> What can community members do to help?
Well, first off, if you’re really interested in vulnerability data or have expertise with the security aspects of specific open source projects/operating systems, head on over to our vulnerability enhancement repo or start contributing to the tools that go into our matching like Syft, Grype, and Vunnel.
But the other thing to do, and I think more people can do this, is just use our open source tools!
File issues when you find things that aren’t perfect. Ask questions on our forum.
And of course, when you get to the point that you have dozens of folders full of Syft SBOMs and tons of little scripts running Grype everywhere—call us—and we can let Anchore Enterprise take care of that for you.
Learn the 5 best practices for container security and how SBOMs play a pivotal role in securing your software supply chain.
In an era where a single line of compromised code can bring entire enterprise systems to their knees, software supply chain security has transformed from an afterthought to a mission-critical priority. The urgency is undeniable: while software supply chain attacks grew by a staggering 540% year-over-year from 2019 to 2022, organizations have rapidly responded.
Organizations have taken notice—the priority given to software supply chain security saw a remarkable 200% increase in 2024 alone, signaling a collective awakening to the existential threat of supply chain attacks. Cybercriminals are no longer just targeting individual applications—they’re weaponizing the complex, interconnected software supply chains that power global businesses.
To combat this rising threat, organizations are deploying platforms to automate BOTH detecting vulnerabilities AND enforcing supply chain security policies. This one-two combo is reducing the risk of a breach from a 3rd-party supplier from cascading into their software environment.
Anchore Enforce, a module of Anchore Enterprise, enables organizations to automate both security and compliance policy checks throughout the development lifecycle. It allows teams to shift compliance left and easily generate reporting evidence for auditors by defining detailed security standards and internal best practices ‘as-code‘.
In this blog post, we’ll demonstrate how to get started with using Anchore Enforce’s policy engine to automate both discovering non-compliant software and preventing it from reaching production.
Learn about software supply chain security in the real-world with former Google Distinguish Engineer, Kelsey Hightower.
Policy-as-code (PaC) translates organizational policies—whether security requirements, licensing restrictions, or compliance mandates—from human-readable documentation into machine-executable code that integrates with your existing DevSecOps platform and tooling. This typically comes in the form of a policy pack.
A policy pack is a set of pre-defined security and compliance rules the policy engine executes to evaluate source code, container images or binaries.
To make policy integration as easy as possible, Anchore Enforce comes with out-of-the-box policy packs for a number of popular compliance frameworks (e.g., FedRAMP or STIG compliance).
A policy consists of three key components:
Triggers: The code that checks whether a specific compliance control is present and configured correctly
Gates: A group of triggers that act as a checklist of security controls to check for
Actions: A stop, warn or go directive explaining the policy-compliant action to take
To better understand PaC and policy packs, we use airport security as an analogy.
When you travel, you pass through multiple checkpoints, each designed to identify and catch different risks. At security screening, officers check for weapons, liquids, and explosives. At immigration control, officials verify visas and passports. If something is wrong, like an expired visa or a prohibited item, you might be stopped, warned, or denied entry.
Anchore Enforce works in a similar way for container security. Policy gates act as checkpoints, ensuring only safe and compliant images are deployed. One aspect of a policy might check for vulnerabilities (like a security screening for dangerous items), while another ensures software licenses are valid (like immigration checking travel documents). If a container has a critical flaw such as a vulnerable version of Log4j it gets blocked, just like a flagged passenger would be stopped from boarding a flight.
By enforcing these policies, Anchore Enforce helps secure an organization’s software supply chain; just as airport security ensures dangerous passengers/items from making it through.
Getting started with Anchore Enforce is easy but determining where to insert it into your workflow is critical. A perfect home for Anchore Enforce is distributed within the CI/CD process, specifically during the localised build process.
This approach enables rapid feedback for developers, providing a gate which can determine whether a build should progress or halt depending on your policies.
Container images are great for software developers—they encapsulate an application and all of its dependencies into a portable package, providing consistency and simplified management. As a developer, you might be building a container image on a local machine or in a pipeline, using Docker and a dockerfile.
For this example, we’ll assume you are using a GitLab Runner to run a job which builds an image for your application. We’ll also be using AnchoreCTL, Anchore Enterprise’s CLI tool to automate calling Anchore Enforce’s policy engine to evaluate your container against the CIS security standard—a set of industry standard container security best practices.
First, you’ll want to set a number of environment variables in your GitLab repository:
ANCHORECTL_USERNAME (protected)ANCHORECTL_PASSWORD (protected and masked)ANCHORECTL_URL (protected)ANCHORECTL_ACCOUNT
These variables will be used to authenticate against your Anchore Enterprise deployment. Anchore Enterprise also supports API keys.
Next, you’ll want to set up your GitLab Runner job definition whereby AnchoreCTL is run after you’ve built a container image. The job definition below shows how you might build an image, then run AnchoreCTL to perform a policy evaluation:
The following environment variable (which can also be passed as the -f flag to AnchoreCTL) ensures that the return code is set to 1 if the policy evaluation result shows as ‘fail’. You can use this to break your build:
ANCHORECTL_FAIL_BASED_ON_RESULTS: "true"
Then the AnchoreCTL image check command can be used to either validate against the default policy or specifically against a given policy (using the -p flag). This could be useful since your account in Anchore Enterprise can only have one default policy permanently active:
When executed, this pipeline will scan your container image against your selected policy requirements and immediately provide feedback. Developers see exactly which policy gates failed and receive specific remediation steps, often as simple as updating a package or adjusting a configuration parameter.
And that’s it! With a few extra lines in your job definition, you’re now validating your newly built image against Anchore Enterprise for policy violations.
On failure, the job will stop and if the build fails in this manner, the –detail option will give you an explanation of failures with remediation recommendations! This is a great way to get fast feedback and stop/warn/go directives directly within the development flow.
Operationalizing Compliance Checks: the Security Engineer Perspective
While developers benefit from shift-left security checks during builds, security teams need a broader view across the entire container landscape. They’ll likely be working to scan containers after they are built by the development teams, having already been pushed or staged testing or even deployed and already running. The critical requirement for the security team is the need to evaluate a large number of images regularly for the latest critical vulnerabilities. This can also be done with policy evaluation; feeding everything in the registry through policy gates.
Below you can see how the team might manage this via the Anchore Enforce user interface (UI). The security team has access to a range of policies, including:
CIS (included by default in all Anchore Enterprise deployments)
NIST 800-53
NIST 800-190
US DoD (Iron Bank)
DISA
FedRAMP
For this UI walkthrough, we will demonstrate the use-case using the CIS policy pack. Navigate to the policy section in your Anchore UI and activate your desired policy.
If you are an Anchore customer and do not have a desired policy pack, contact our Customer Success team for further information on entitlements.
Once this is activated, we will see how this is set in action by scanning an image.
Navigate to Images, and select the image you want to check for compliance by clicking on the image digest.
Once the policy check is complete, you will see a screen containing the results of the policy check.
This screen displays the actions applied to various artifacts based on Anchore Enforce’s policy engine findings, aligned with the rules defined in the policy packs. It also highlights the specific rule an artifact is failing. Based on these results, you can determine the appropriate remediation approach.
The security team can generate reports in JSON or CSV format, simplifying the sharing of compliance check results.
Wrap-Up
As software supply chain attacks continue to evolve and grow in sophistication, organizations need robust, automated solutions to protect their environments. Anchore Enforce delivers exactly that by providing:
Automated compliance enforcement that catches issues early in the development process, when they’re easiest and least expensive to fix
Comprehensive policy coverage with pre-built packs for major standards like CIS, NIST, and FedRAMP that eliminate the need to translate complex requirements into executable controls
Flexible implementation options for both developers seeking immediate feedback and security teams managing enterprise-wide compliance
Actionable remediation guidance that helps teams quickly address policy violations without extensive research or security expertise
By integrating Anchore Enforce into your DevSecOps workflow, you’re not just checking a compliance box—you’re establishing a powerful defense against the rising tide of supply chain attacks. You’re also saving developer time, reducing friction between security and development teams, and building confidence with customers and regulators who demand proof of your security posture.
The software supply chain security challenge isn’t going away. With Anchore Enforce, you can meet it head-on with automation that scales with your organization. Reach out to our team to learn more or start a free trial to kick the tires yourself.
Automate FedRAMP and STIG compliance with Anchore Enterprise. Get instant access with a 15-day free trial.
Is your organization’s PCI compliance coming up for renewal in 2025? Or are you looking to achieve PCI compliance for the first time?
Version 4.0 of the Payment Card Industry Data Security Standard (PCI DSS) became mandatory on March 31, 2025. For enterprise’s utilizing a 3rd-party software software supply chain—essentially all companies, according to The Linux Foundation’s report on open source penetration—PCI DSS v4.0 requires companies to maintain comprehensive inventories of supply chain components. The SBOM standard has become the cybersecurity industry’s consensus best practice for securing software supply chains and meeting the requirements mandated by regulatory compliance frameworks.
This document serves as a comprehensive guide to understanding the pivotal role of SBOMs in navigating the complexities of PCI DSS v4.0 compliance.
Learn about the role that SBOMs for the security of your organization in this white paper.
Understanding the Fundamentals: PCI DSS 4.0 and SBOMs
What is PCI DSS 4.0?
Developed to strengthen payment account data (e.g., credit cards) security and standardize security controls globally, PCI DSS v4.0 represents the next evolution of this standard; ultimately benefiting consumers worldwide.
This version supersedes PCI DSS 3.2.1, which was retired on March 31, 2023. The explicit goals of PCI DSS v4.0 include promoting security as a continuous process, enhancing flexibility in implementation, and introducing enhancements in validation methods. PCI DSS v4.0 achieved this by introducing a total of 64 new security controls.
NOTE: PCI DSS had a minor version bump to 4.0.1 in mid-2024. The update is limited and doesn’t add or remove any controls or change any deadlines, meaning the software supply chain requirements apply to both versions.
Demystifying SBOMs
A software bill of materials (SBOM) is fundamentally an inventory of all software dependencies utilized by a given application. Analogous to a “Bill of Materials” in manufacturing, which lists all raw materials and components used to produce a product, an SBOM provides a detailed list of software components, including libraries, 3rd-party software, and services, that constitute an application.
The benefits of maintaining SBOMs are manifold, including enhanced transparency into the software supply chain, improved vulnerability management by identifying at-risk components, facilitating license compliance management, and providing a foundation for comprehensive supply chain risk assessment.
How SBOMs Address PCI DSS 4.0 Requirements—The Critical Link
PCI DSS Requirement 6: Develop and Maintain Secure Systems and Software
PCI DSS Principal Requirement 6, titled “Develop and Maintain Secure Systems and Software,” aims to ensure the creation and upkeep of secure systems and applications through robust security measures and regular vulnerability assessments and updates. This requirement encompasses five primary areas:
Processes and mechanisms for developing and maintaining secure systems and software are defined and understood
Bespoke and custom software are developed securely
Security vulnerabilities are identified and addressed
Public-facing web applications are protected against attacks
Changes to all system components are managed securely
Deep Dive into Requirement 6.3.2: Component Inventory for Vulnerability Management
Within the “Security vulnerabilities are identified and addressed” category of Requirement 6, Requirement 6.3.2 mandates:
An inventory of bespoke and custom software, and 3rd-party software components incorporated into bespoke and custom software is maintained to facilitate vulnerability and patch management
The purpose of this evolving requirement is to enable organizations to effectively manage vulnerabilities and patches within all software components, including 3rd-party components such as libraries and APIs embedded in their bespoke and custom software.
While PCI DSS v4.0 does not explicitly prescribe the use of SBOMs, they represent the cybersecurity industry’s consensus method for achieving compliance with this requirement by providing a detailed and readily accessible inventory of software components.
How SBOMs Enable Compliance with 6.3.2
By requiring an inventory of all software components, Requirement 6.3.2 necessitates a mechanism for comprehensive tracking. SBOMs automatically generate an inventory of all components in use, whether developed internally or sourced from third parties.
This detailed inventory forms the bedrock for identifying known vulnerabilities associated with these components. Platforms leveraging SBOMs can map component inventories to databases of known vulnerabilities, providing continuous insights into potential risks.
Consequently, SBOMs are instrumental in facilitating effective vulnerability and patch management by enabling organizations to understand their software supply chain and prioritize remediation efforts.
Connecting SBOMs to other relevant PCI DSS 4.0 Requirements
Beyond Requirement 6.3.2, SBOMs offer synergistic benefits in achieving compliance with other aspects of PCI DSS v4.0.
Requirement 11.3.1.1
This requirement necessitates the resolution of high-risk or critical vulnerabilities. SBOMs enable ongoing vulnerability monitoring, providing alerts for newly disclosed vulnerabilities affecting the identified software components, thereby complementing the requirement for tri-annual vulnerability scans.
Platforms like Anchore Secure can track newly disclosed vulnerabilities against SBOM inventories, facilitating proactive risk mitigation.
Implementing SBOMs for PCI DSS 4.0: Practical Guidance
Generating Your First SBOM
The generation of SBOMs can be achieved through various methods. A Software Composition Analysis (SCA) tool, like the open source SCA Syft or the commercial AnchoreCTL, offer automated software composition scanning and SBOM generation for source code, containers or software binaries.
These tools integrate with build pipelines and can output SBOMs in standard formats like SPDX and CycloneDX. For legacy systems or situations where automated tools have limitations, manual inventory processes may be necessary, although this approach is generally less scalable and prone to inaccuracies.
Regardless of the method, it is crucial to ensure the accuracy and completeness of the SBOM, including both direct and transitive software dependencies.
The true value of an SBOM lies in its active utilization for software supply chain use-cases beyond component inventory management.
Vulnerability Management
SBOMs serve as the foundation for continuous vulnerability monitoring. By integrating SBOM data with vulnerability databases, organizations can proactively identify components with known vulnerabilities. Platforms like Anchore Secure enable the mapping of SBOMs to known vulnerabilities, tracking exploitability and patching cadence.
Patch Management
A comprehensive SBOM facilitates informed patch management by highlighting the specific components that require updating to address identified vulnerabilities. This allows security teams to prioritize patching efforts based on the severity and exploitability of the vulnerabilities within their software ecosystem.
It is essential to maintain thorough documentation of vulnerability remediation efforts in order to achieve the emerging continuous compliance trend from global regulatory bodies. Utilizing formats like CVE (Common vulnerabilities and Exposures) or VEX (Vulnerability Exploitability eXchange) alongside SBOMs can provide a standardized way to communicate the status of vulnerabilities, whether a product is affected, and the steps taken for mitigation.
Acquiring SBOMs from Third-Party Suppliers
PCI DSS Requirement 6.3.2 explicitly includes 3rd-party software components. Therefore, organizations must not only generate SBOMs for their own bespoke and custom software but also obtain SBOMs from their technology vendors for any libraries, applications, or APIs that are part of the card processing environment.
Engaging with suppliers to request SBOMs, potentially incorporating this requirement into contractual agreements, is a critical step. It is advisable to communicate preferred SBOM formats (e.g., CycloneDX, SPDX) and desired data fields to ensure the received SBOMs are compatible with internal vulnerability management processes. Challenges may arise if suppliers lack the capability to produce accurate SBOMs; in such instances, alternative risk mitigation strategies and ongoing communication are necessary.
Implementing SBOMs across an organization can present several challenges:
Generating SBOMs for closed-source or legacy systems where build tool integration is difficult may require specialized tools or manual effort
The volume and frequency of software updates necessitate automated processes for SBOM generation and continuous monitoring
Ensuring the accuracy and completeness of SBOM data, including all levels of dependencies, is crucial for effective risk management
Integrating SBOM management into existing software development lifecycle (SDLC) and security workflows requires collaboration and process adjustments
Effective SBOM adoption necessitates cross-functional collaboration between development, security, and procurement teams to establish policies and manage vendor relationships
Best Practices for SBOM Management
To ensure the sustained effectiveness of SBOMs for PCI DSS v4.0 compliance and beyond, organizations should adopt the following best practices:
Automate SBOM generation and updates wherever possible to maintain accuracy and reduce manual effort
Establish clear internal SBOM policies regarding format, data fields, update frequency, and retention
Select and implement appropriate SBOM management tooling that integrates with existing security and development infrastructure
Clearly define roles and responsibilities for SBOM creation, maintenance, and utilization across relevant teams
Provide education and training to development, security, and procurement teams on the importance and practical application of SBOMs
Wrap-Up: Embracing SBOMs for a Secure Payment Ecosystem
The integration of SBOMs into PCI DSS v4.0 signifies a fundamental shift towards a more secure and transparent payment ecosystem. SBOMs are no longer merely a recommended practice but a critical component for achieving and maintaining compliance with the evolving requirements of PCI DSS v4.0, particularly Requirement 6.3.2.
By providing a comprehensive inventory of software components and their dependencies, SBOMs empower organizations to enhance their security posture, reduce the risk of costly data breaches, improve their vulnerability management capabilities, and effectively navigate the complexities of regulatory compliance. Embracing SBOM implementation is not just about meeting a requirement; it is about building a more resilient and trustworthy software foundation for handling sensitive payment card data.
If you’re interested to learn more about how Anchore Enterprise can help your organization harden their software supply chain and achieve PCI DSS v4.0 compliance, get in touch with our team!
Interested to learn about all of the software supply chain use-cases that SBOMs enable? Read our new white paper and start unlocking enterprise value.
Let’s be honest: modern JavaScript projects can feel like a tangled web of packages. Knowing exactly what’s in your final build is crucial, especially with rising security concerns. That’s where a Software Bill of Materials (SBOM) comes in handy – it lists out all the components. We’ll walk you through creating SBOMs for your JavaScript projects using Anchore’s open-source tool called Syft, which makes the process surprisingly easy (and free!).
Why You Need SBOMs for Your JavaScript Projects
JavaScript developers face unique supply chain security challenges. The NPM ecosystem has seen numerous security incidents, from protestware to dependency confusion attacks. With most JavaScript applications containing hundreds or even thousands of dependencies, manually tracking each one becomes impossible.
SBOMs solve this problem by providing:
Vulnerability management: Quickly identify affected packages when new vulnerabilities emerge
License compliance: Track open source license obligations across all dependencies
Dependency visibility: Map your complete software supply chain
Regulatory compliance: Meet evolving government and industry requirements
Let’s explore how to generate SBOMs across different JavaScript project scenarios.
Getting Started with Syft
Syft is an open source SBOM generation tool that supports multiple formats including SPDX and CycloneDX. It’s written in Go, and ships as a single binary. Let’s install it:
For Linux & macOS:
# Install the latest release of Syft using our installer scriptcurl-sSfLhttps://raw.githubusercontent.com/anchore/syft/main/install.sh | sh-s---b/usr/local/bin
Let’s start by scanning a container image of EverShop, an open source NodeJS e-commerce platform. Container scanning is perfect for projects already containerized or when you want to analyze production-equivalent environments.
# Pull and scan the specified containersyftevershop/evershop:latest
Here’s the first few lines, which summarise the work Syft has done.
Next is a human-readable table consisting of the name of the software package, the version found and the type which could be npm, deb, rpm and so-on. The output is very long (over a thousand lines), because, as we know, javascript applications often contain many packages. We’re only showing the first and last few lines here:
The output shows a comprehensive inventory of packages found in the container, including:
System packages (like Ubuntu/Debian packages)
Node.js dependencies from package.json
Other language dependencies if present
For a more structured output that can be consumed by other tools, use format options:
# Scan the container and output a CycloneDX SBOMsyftevershop/evershop:latest-ocyclonedx-json > ./evershop-sbom.json
This command generates a CycloneDX JSON SBOM, which is widely supported by security tools and can be shared with customers or partners.
Scenario 2: Scanning Source Code Directories
When working with source code only, Syft can extract dependency information directly from package manifest files.
Let’s clone the EverShop repository and scan it:
# Clone the repogitclonehttps://github.com/evershopcommerce/evershop.gitcd./evershop# Check out the latest releasegitcheckoutv1.2.2# Create a human readble list of contentssyftdir:.✔Indexedfilesystem.✔Catalogedcontentscdb4ee2aea69cc6a83331bbe96dc2c…├──✔Packages [1,045 packages]├──✔Filedigests [3 files]├──✔Filemetadata [3 locations]└──✔Executables [0 executables][0000] WARN no explicit name and version provided for directory source, deriving artifact ID from the given path (whichisnotideal)NAMEVERSIONTYPE@alloc/quick-lru.5.2.0npm@ampproject/remapping2.3.0npm@aws-crypto/crc325.2.0npm@aws-crypto/crc32c5.2.0npm@aws-crypto/sha1-browser5.2.0npm⋮yaml1.10.2npmyaml2.6.0npmyargs16.2.0npmyargs-parser20.2.9npmzero-decimal-currencies1.2.0npm
The source-only scan focuses on dependencies declared in package.json files but won’t include installed packages in node_modules or system libraries that might be present in a container.
For tracking changes between versions, we can check out a specific tag:
# Check out an earlier tag from over a year agogitcheckoutv1.0.0# Create a machine readable SBOM document in SPDX formatsyftdir:.-ospdx-json > ./evershop-v1.0.0-sbom.json
Scenario 3: Scanning a Built Project on Your Workstation
For the most complete view of your JavaScript project, scan the entire built project with installed dependencies:
# Assuming you're in your project directory and have run npm installsyftdir:.-ospdx-json > ./evershop-v1.2.2-sbom.json# Grab five random examples from the SBOM with version and license infojq'.packages[] | "\(.name) \(.versionInfo) \(.licenseDeclared)"'\ < ./evershop-v1.2.2-sbom.json | shuf | head-n5"pretty-time 1.1.0 MIT""postcss-js 4.0.1 MIT""minimist 1.2.8 MIT""@evershop/postgres-query-builder 1.2.0 MIT""path-type 4.0.0 MIT"
This approach captures:
Declared dependencies from package.json
Actual installed packages in node_modules
Development dependencies if they’re installed
Any other files that might contain package information
Going Beyond SBOM Generation: Finding Vulnerabilities with Grype
An SBOM is most valuable when you use it to identify security issues. Grype, another open source tool from Anchore, can scan directly or use Syft SBOMs to find vulnerabilities.
For Linux & macOS:
# Install the latest release of Grype using our installer scriptcurl-sSfLhttps://raw.githubusercontent.com/anchore/grype/main/install.sh | sh-s---b/usr/local/bin
Let’s check an older version of EverShop for known vulnerabilities. Note that the first time you run grype, it will download a ~66MB daily vulnerability database and unpack it.
# Clone the example repo, if we haven't alreadygitclonehttps://github.com/evershopcommerce/evershop.gitcd./evershop# Check out an older release of the application from > 1 year agogitcheckoutv1.0.0# Create an SPDX formatted SBOM and keep itsyftdir:.-ospdx-json > ./evershop-v1.0.0-sbom.json# Scan the SBOM for known vulnerabilitiesgrype./evershop-v1.0.0-sbom.json
We can also scan the directory directly with Grype, which leverages Syft internally. However, it’s usually preferable to use Syft to generate the SBOM initially, because that’s a time consuming part of the process.
grypedir:.
Either way we run it, Grype identifies vulnerabilities in the dependencies, showing severity levels, the vulnerability ID, and version that the issue was fixed in.
We can even ask Grype to explain the vulnerabilities in more detail. Let’s take one of the critical vulnerabilities and get Grype to elaborate on the details. Note that we are scanning the existing SBOM, which is faster than running Grype against the container or directory, as it skips the need to build the SBOM internally.
# Analyze licenses used by packages listed in the SBOMgrantanalyze-severshop-sbom.json
Grant identifies licenses for each component and flags any potential license compliance issues in your dependencies. By default the Grant configuration has a deny-all for all licenses.
Generate SBOMs for both development and production dependencies: Each has different security implications
Use package lockfiles: These provide deterministic builds and more accurate SBOM generation
Include SBOMs in your release process: Make them available to users of your libraries or applications
Automate the scanning process: Don’t rely on manual checks
Keep tools updated: Vulnerability databases are constantly evolving
Wrapping Up
The JavaScript ecosystem moves incredibly fast, and keeping track of what’s in your apps can feel like a never-ending battle. That’s where tools like Syft, Grype, and Grant come in. They give you X-ray vision into your dependencies without the hassle of sign-ups, API keys, or usage limits.
Once developers start generating SBOMs and actually see what’s lurking in their node_modules folders, they can’t imagine going back to flying blind. Whether you’re trying to patch the next Log4j-style vulnerability in record time or just making sure you’re not accidentally violating license terms, having that dependency data at your fingertips is a game-changer.
Give these tools a spin in your next project. Your future self will thank you when that critical security advisory hits your inbox, and you can immediately tell if you’re affected and exactly where.
Here at Anchore, we consistently work with our users and customers to improve the security of their container images. During these conversations, there is typically an initiative to embed container image scanning into CI/CD pipelines to meet DevSecOps goals. But what do we mean when we say DevSecOps? We can think of DevSecOps as empowering engineering teams to take ownership of how their products will perform in production by integrating security practices into their existing automation and DevOps workflow.
A core principle of DevSecOps is creating a ‘Security as Code’ culture. Now that’s there is increased transparency and collaboration, security is now everyone’s responsibility. By building on the cultural changes of the DevOps framework, security teams are added to DevOps initiatives early to help plan for security automation. Additionally, security engineers should constantly be providing feedback and educating both Ops and development teams on best practices.
What are the Benefits of DevSecOps?
There are quite a few benefits to including security practices to the software development and delivery lifecycle. I’ve listed some of the core benefits below:
Costs are reduced by uncovering and fixing security issues further left in the development lifecycle versus in production environments.
Speed of product delivery is increased by incorporating automated security tests versus adding security testing at the end of lifecycle.
Increased transparency and team collaboration leads to faster detection and recovery of threats.
Implementing immutable infrastructure improves overall security by reducing vulnerabilities, increasing automation, and encourages organizations to move to the cloud.
When thinking about what tooling and tests to put in place, organizations should look at their entire development lifecycle and environment. This can often include source control, third-party libraries, container registries, CI/CD pipelines, and orchestration and release tools.
Anchore and DevSecOps
As a container security company, we strongly believe containers help with a successful journey to DevSecOps. Containers are lightweight, faster than VMs, and allow developers to create predictable, scalable environments isolated from other applications or services. This leads to increased productivity across all teams, faster development, and less time fixing bugs and other environment issues. Containers are also immutable, meaning unchanged once created. To fix a vulnerable container, it is simply replaced by a patched, newer version.
When planning security steps in a continuous integration pipeline, I often recommend adding a mandatory image analysis step to uncover vulnerable packages, secrets, credentials, or misconfigurations prior to the image being pushed to a production registry. As part of this image scanning step, I also recommend enforcing policies on the contents of the container images that have just been analyzed. Anchore policies are made up of a set of user-defined rules such as:
Security vulnerabilities
Image manifest changes
Configuration file contents
Presence of credentials in an image
Unused exposed ports
Package whitelists and blacklists
Based on the rules created and the final result of the policy evaluation, users can choose to fail the image scanning step of a CI build, and not promote the image to a production container registry. The integration of a flexible policy engine helps organizations stay on top of compliance requirements constantly and can react faster if audited. Security teams responsible for creating policy rules should be educating developers on why these rules are being created and what steps they can take to avoid breaking them.
Conclusion
DevSecOps means integrating security practices into application development from start to finish. Not only does this require new tooling, automation, and integration, but it also involves a significant culture change and investment from every developer, release engineer, and security engineer. Everyone is responsible for openness, feedback, and education. Once the culture is intact and in place, DevSecOps practices and processes can be implemented to achieve a more secure development process as a whole.
If you’re a developer, this vignette may strike a chord: You’re deep in the flow, making great progress on your latest feature, when someone from the security team sends you an urgent message. A vulnerability has been discovered in one of your dependencies and has failed a compliance review. Suddenly, your day is derailed as you shift from coding to a gauntlet of bureaucratic meetings.
This is an unfortunate reality for developers at organizations where security and compliance are bolt-on processes rather than integrated parts of the whole. Your valuable development time is consumed with digging through arcane compliance documentation, attending security reviews and being relegated to compliance training sessions. Every context switch becomes another drag on your productivity, and every delayed deployment impacts your ability to ship code.
Two niche DevSecOps/software supply chain technologies have come together to transform the dynamic between developers and organizational policy—software bills of materials (SBOMs) and policy-as-code (PaC). Together, they dramatically reduce the friction between development velocity and risk management requirements by making policy evaluation and enforcement:
Automated and consistent
Integrated into your existing workflows
Visible early in the development process
In this guide, we’ll explore how SBOMs and policy-as-code work, the specific benefits they bring to your daily development work, and how to implement them in your environment. By the end, you’ll understand how these tools can help you spend less time manually doing someone else’s job and more time doing what you do best—writing great code.
Interested to learn about all of the software supply chain use-cases that SBOMs enable? Read our new white paper and start unlocking enterprise value.
You’re probably familiar with Infrastructure-as-Code (IaC) tools like Terraform, AWS CloudFormation, or Pulumi. These tools allow you to define your cloud infrastructure in code rather than clicking through web consoles or manually running commands. Policy-as-Code (PaC) applies this same principle to policies from other departments of an organization.
What is policy-as-code?
At its core, policy-as-code translates organizational policies—whether they’re security requirements, licensing restrictions, or compliance mandates—from human-readable documents into machine-readable representations that integrate seamlessly with your existing DevOps platform and tooling.
Think of it this way: IaC gives you a DSL for provisioning and managing cloud resources, while PaC extends this concept to other critical organizational policies that traditionally lived outside engineering teams. This creates a bridge between development workflows and business requirements that previously existed in separate silos.
Why do I care?
Let’s play a game of would you rather. Choose the activity from the table below that you’d rather do:
Before Policy-as-Code
After Policy-as-Code
Read lengthy security/legal/compliance documentation to understand requirements
Reference policy translated into code with clear comments and explanations
Manually review your code policy compliance and hope you interpreted policy correctly
Receive automated, deterministic policy evaluation directly in CI/CD build pipeline
Attend compliance training sessions because you didn’t read the documentation
Learn policies by example as concrete connections to actual development tasks
Setup meetings with security, legal or compliance teams to get code approval
Get automated approvals through automated policy evaluation without review meetings
Wait till end of sprint and hope VP of Eng can get exception to ship with policy violations
Identify and fix policy violations early when changes are simple to implement
While the game is a bit staged, it isn’t divorced from reality. PaC is meant to relieve much of the development friction associated with the external requirements that are typically hoisted onto the shoulders of developers.
From oral tradition to codified knowledge
Perhaps one of the most under appreciated benefits of policy-as-code is how it transforms organizational knowledge. Instead of policies living in outdated Word documents or in the heads of long-tenured employees, they exist as living code that evolves with your organization.
When a developer asks “Why do we have this restriction?” or “What’s the logic behind this policy?”, the answer isn’t “That’s just how we’ve always done it” or “Ask Alice in Compliance.” Instead, they can look at the policy code, read the annotations, and understand the reasoning directly.
In the next section, we’ll explore how software bills of materials (SBOMs) provide the perfect data structure to pair with policy-as-code for managing software supply chain security.
A Brief Introduction to SBOMs (in the Context of PaC)
If policy-as-code provides the rules engine for your application’s dependency supply chain, then Software Bills of Materials (SBOMs) provide the structured, supply chain data that the policy engine evaluates.
What is an SBOM?
An SBOM is a formal, machine-readable inventory of all components and dependencies used in building a software artifact. If you’re familiar with Terraform, you can think of an SBOM as analogous to a dev.tfstate file but it stores the state of your application code’s 3rd-party dependency supply chain which is then reconciled against a main.tf file (i.e., policy) to determine if the software supply chain is compliant or in violation of the defined policy.
SBOMs vs package manager dependency files
You may be thinking, “Don’t I already have this information in my package.json, requirements.txt, or pom.xml file?” While these files declare your direct dependencies, they don’t capture the complete picture:
They don’t typically include transitive dependencies (dependencies of your dependencies)
They don’t include information about the components within container images you’re using
They don’t provide standardized metadata about vulnerabilities, licenses, or provenance
They aren’t easily consumable by automated policy engines across different programming languages and environments
SBOMs solve these problems by providing a standardized format that comprehensively documents your entire software supply chain in a way that policy engines can consistently evaluate.
A universal policy interface: How SBOMs enable policy-as-code
Think of SBOMs as creating a standardized “policy interface” for your software’s supply chain metadata. Just as APIs create a consistent way to interact with services, SBOMs create a consistent way for policy engines to interact with your software’s composable structure.
This standardization is crucial because it allows policy engines to operate on a known data structure rather than having to understand the intricacies of each language’s package management system, build tool, or container format.
For example, a security policy that says “No components with critical vulnerabilities may be deployed to production” can be applied consistently across your entire software portfolio—regardless of the technologies used—because the SBOM provides a normalized view of the components and their vulnerabilities.
In the next section, we’ll explore the concrete benefits that come from combining SBOMs with policy-as-code in your development workflow.
How do I get Started with SBOMs and Policy-as-Code
Now that you understand what SBOMs and policy-as-code are and why they’re valuable, let’s walk through a practical implementation. We’ll use Anchore Enterprise as an example of a policy engine that has a DSL to express a security policy which is then directly integrated into a CI/CD runbook. The example will focus on a common software supply chain security best practice: preventing the deployment of applications with critical vulnerabilities.
Tools we’ll use
For this example implementation, we’ll use the following components from Anchore:
AnchoreCTL: A software composition analysis (SCA) tool and SBOM generator that scans source code, container images or application binaries to populate an SBOM with supply chain metadata
Anchore Enforce: The policy engine that evaluates SBOMs against defined policies
Anchore Enforce JSON: The Domain-Specific Language (DSL) used to define policies in a machine-readable format
While we’re using Anchore in this example, the concepts apply to other SBOM generators and policy engines as well.
Step 1: Translate human-readable policies to machine-readable code
The first step is to take your organization’s existing policies and translate them into a format that a policy engine can understand. Let’s start with a simple but effective policy.
Human-Readable Policy:
Applications with critical vulnerabilities must not be deployed to production environments.
{"id": "critical_vulnerability_policy","version": "1.0","name": "Block Critical Vulnerabilities","comment": "Prevents deployment of applications with critical vulnerabilities","rules": [ {"id": "block_critical_vulns","gate": "vulnerabilities","trigger": "package","comment": "Rule evaluates each dependency in an SBOM against vulnerability database. If the dependency is found in the database, all known vulnerability severity scores are evaluated for a critical value. If match if found policy engine returns STOP action to CI/CD build task","parameters": [ { "name": "package_type", "value": "all" }, { "name": "severity_comparison", "value": "=" }, { "name": "severity", "value": "critical" }, ],"action": "stop" } ]}
This policy code instructs the policy engine to:
Examine all application dependencies (i.e., packages) in the SBOM
Check if any dependency/package has vulnerabilities with a severity of “critical”
If found, return a “stop” action that will fail the build
If you’re looking for more information on the capabilities of the Anchore Enforce DSL, our documentation provides the full capabilities of the Anchore Enforce policy engine.
Step 2: Deploy Anchore Enterprise with the policy engine
With the example policy defined, the next step is to deploy Anchore Enterprise (AE) and configure the Anchore Enforce policy engine. The high-level steps are:
Configure access controls/permissions between AE deployment and CI/CD build pipeline
If you’re interested to get hands-on with this, we have developed a self-paced workshop that walks you through a full deployment and how to set up a policy. You can get a trial license by signing up for our free trial.
Step 3: Integrate SBOM generation into your CI/CD pipeline
Now you need to generate SBOMs as part of your build process and have them evaluated against your policies. Here’s an example of how this might look in a GitHub Actions workflow:
name: Build App and Evaluate Supply Chain for Vulnerabilitieson:push:branches: [ main ]pull_request:branches: [ main ]jobs:build-and-evaluate:runs-on: ubuntu-lateststeps: - uses: actions/checkout@v3 - name: Build Applicationrun: | # Build application as container image docker build -t myapp:latest . - name: Generate SBOMrun: | # Install AnchoreCTL curl -sSfL https://anchorectl-releases.anchore.io/v1.0.0/anchorectl_1.0.0_linux_amd64.tar.gz | tar xzf - -C /usr/local/bin # Execute supply chain composition scan of container image, generate SBOM and send to policy engine for evaluation anchorectl image add --wait myapp:latest - name: Evaluate Policyrun: | # Get policy evaluation results RESULT=$(anchorectl image check myapp:latest --policy critical_vulnerability_policy) # Handle the evaluation result if [[ $RESULT == *"Status: pass"* ]]; then echo "Policy evaluation passed! Proceeding with deployment." else echo "Policy evaluation failed! Deployment blocked." exit 1 fi - name: Deploy if Passedif: success()run: | # Your deployment steps here
This workflow:
Builds your application as a container image using Docker
Installs AnchoreCTL
Scans container image with SCA tool to map software supply chain
Generates an SBOM based on the SCA results
Submits the SBOM to the policy engine for evaluation
Gets evaluation results from policy engine response
Continues or halts the pipeline based on the policy response
Step 4: Test the integration
With the integration in place, it’s time to test that everything works as expected:
Create a test build that intentionally includes a component with a known critical vulnerability
Push the build through your CI/CD pipeline
Confirm that:
The SBOM is correctly generated
The policy engine identifies the vulnerability
The pipeline fails as expected
If all goes well, you’ve successfully implemented your first policy-as-code workflow using SBOMs!
Step 5: Expand your policy coverage
Once you have the basic integration working, you can begin expanding your policy coverage to include:
Security policies
Compliance policies
Software license policies
Custom organizational policies
Environment-specific requirements (e.g., stricter policies for production vs. development)
Work with your security and compliance teams to translate their requirements into policy code, and gradually expand your automated policy coverage. This process is a large upfront investment but creates recurring benefits that pay dividends over the long-term.
Step 6: Profit!
With SBOMs and policy-as-code implemented, you’ll start seeing the benefits almost immediately:
Fast feedback on security and compliance issues
Reduced manual compliance tasks
Better documentation of what’s in your software and why
Consistent evaluation and enforcement of policies
Certainty about policy approvals
The key to success is getting your security and compliance teams to embrace the policy-as-code approach. Help them understand that by translating their policies into code, they gain more consistent enforcement while reducing manual effort.
Wrap-Up
As we’ve explored throughout this guide, SBOMs and policy-as-code represent a fundamental shift in how developers interact with security and compliance requirements. Rather than treating these as external constraints that slow down development, they become integrated features of your DevOps pipeline.
Key takeaways
Policy-as-Code transforms organizational policies from static documents into dynamic, version-controlled code that can be automated, tested, and integrated into CI/CD pipelines.
SBOMs provide a standardized format for documenting your software’s components, creating a consistent interface that policy engines can evaluate.
Together, they enable “shift-left” security and compliance, providing immediate feedback on policy violations without meetings or context switching.
Integration is straightforward with pre-built plugins for popular DevOps platforms, allowing you to automate policy evaluation as part of your existing build process.
The benefits extend beyond security to include faster development cycles, reduced compliance burden, and better visibility into your software supply chain.
Get started today
Ready to bring SBOMs and policy-as-code to your development environment? Anchore Enterprise provides a comprehensive platform for generating SBOMs, defining policies, and automating policy evaluation across your software supply chain.
Learn the 5 best practices for container security and how SBOMs play a pivotal role in securing your software supply chain.
Software security depends on accurate vulnerability data. While organizations like NIST maintain the National Vulnerability Database (NVD), the sheer volume of vulnerabilities discovered daily means that sometimes data needs improvement. At Anchore, we’re working to enhance this ecosystem through open-source contributions, and we need your help.
Why Vulnerability Data Matters
When you run a security scanner like Grype, it relies on vulnerability data to determine if your software components have known security issues. This data includes crucial details like:
Which versions of software are affected
How the vulnerability can be exploited
What versions contain the fix
However, this data isn’t always perfect. Sometimes, version ranges are incorrect, package names don’t match reality, or the metadata needs enrichment. These inaccuracies can lead to false positives (flagging secure components as vulnerable) and false negatives (missing actual vulnerabilities).
Our Approach to Better Data
We maintain a set of open-source repositories that help improve vulnerability data quality:
A data enrichment repository where contributors can submit corrections
Tools for processing and validating these corrections
Generated outputs that integrate with existing vulnerability databases
This approach allows us to fix inaccuracies quickly and share these improvements with the broader security community. For example, we’ve helped correct version ranges for Java packages where the official data was incomplete and added missing metadata for WordPress plugins.
How You Can Help
We’ve published a comprehensive technical guide for contributors, but here’s the quick version:
Find an Issue: Maybe you’ve noticed incorrect version information in a CVE, or you’re aware of missing package metadata
Make the Fix: Clone our repository and use our tools to create or update the relevant records
Submit a Pull Request: Share your improvements with the community
The most valuable contributions often come from security researchers and developers encountering data issues daily. Your real-world experience helps identify where the data needs improvement.
Impact of Contributions
Every contribution helps make security tooling more accurate for everyone. When you fix a false positive, you help thousands of developers avoid unnecessary security alerts. When you add missing metadata, you help security tools better understand the software ecosystem.
These improvements benefit individual developers using our open-source tools like Grype and major organizations, including Microsoft, Cisco, and various government agencies. By contributing, you’ll help make the entire software supply chain more secure.
Getting Started
Ready to contribute? Here’s what to do next:
Check out our technical guide for detailed setup instructions
Start with small improvements – even fixing one incorrect version range makes a difference
The security community strengthens when we work together. Your contributions, whether big or small, help make vulnerability data more accurate for everyone. Let’s improve software security one pull request at a time.
The blog post is meant to remain “public” so that it will continue to show on the /blog feed. This will help discoverability for people browsing the blog and potentially help SEO. If it is clicked on it will automatically redirect to the pillar page.
Security engineers at modern enterprises face an unprecedented challenge: managing software supply chain risk without impeding development velocity, all while threat actors exploit the rapidly expanding attack surface. With over 25,000 new vulnerabilities in 2023 alone and supply chain attacks surging 540% year-over-year from 2019 to 2022, the exploding adoption of open source software has created an untenable security environment. To overcome these challenges security teams are in need of tools to scale their impact and invert the they are a speed bump for high velocity software delivery.
If your DevSecOps pipeline utilizes the open source Harbor registry then we have the perfect answer to your needs. Integrating Anchore Enterprise—the SBOM-powered container vulnerability management platform—with Harbor offers the force-multiplier security teams need. This one-two combo delivers:
Proactive vulnerability management: Automatically scan container images before they reach production
Actionable security insights: Generate SBOMs, identify vulnerabilities and alert on actionable insights to streamline remediation efforts
Lightweight implementation: Native Harbor integration requiring minimal configuration while delivering maximum value
Improved cultural dynamics: Reduce security incident risk and, at the same time, burden on development teams while building cross-functional trust
This technical guide walks through the implementation steps for integrating Anchore Enterprise into Harbor, equipping security engineers with the knowledge to secure their software supply chain without sacrificing velocity.
Learn the essential container security best practices to reduce the risk of software supply chain attacks in this white paper.
Anchore Enterprise can integrate with Harbor in two different ways—each has pros and cons:
Pull Integration Model
In this model, Anchore uses registry credentials to pull and analyze images from Harbor:
Anchore accesses Harbor using standard Docker V2 registry integration
Images are analyzed directly within Anchore Enterprise
Results are available in Anchore’s interface and API
Ideal for organizations where direct access to Harbor is restricted but API access is permitted
Push Integration Model
In this model, Harbor uses its native scanner adapter feature to push images to Anchore for analysis:
Harbor initiates scans on-demand through its scanner adapter as images are added
Images are scanned within the Anchore deployment
Vulnerability scan results are stored in Anchore and sent to Harbor’s UI
Better for environments with direct access to Harbor that want immediate scans
Both methods provide strong security benefits but differ in workflow and where results are accessed.
Setting Up the Pull Integration
Let’s walk through how to configure Anchore Enterprise to pull and analyze images from your Harbor registry.
Prerequisites
Anchore Enterprise installed and running
Harbor registry deployed and accessible
Harbor user account with appropriate permissions
Step 1: Configure Registry Credentials in Anchore
In Anchore Enterprise, navigate to the “Registries” section
Select “Add Registry”
Fill in the following details:
Registry Hostname or IP Address: [your Harbor API URL or IP address, e.g., http://harbor.yourdomain.com]Name: [Human readable name]Type: docker_v2Username: [your Harbor username, e.g., admin]Password: [your Harbor password]
Configure any additional options like SSL validation if necessary
Test the connection
Save the configuration
Step 2: Analyze an Image from Harbor
Once the registry is configured, you can analyze images stored in Harbor:
Navigate to the “Images” section in Anchore Enterprise
Select “Add Image”
Choose your Harbor registry from the dropdown
Specify the repository and tag for the image you want to analyze
Click “Analyze”
Anchore will pull the image from Harbor, decompose it, generate an SBOM, and scan for vulnerabilities. This process typically takes a few minutes depending on image size.
Step 3: Review Analysis Results
After analysis completes:
View the vulnerability report in the Anchore UI
Check the generated SBOM for all dependencies
Review compliance status against configured policies
Export reports or take remediation actions as needed
Setting Up the Push Integration
Now let’s configure Harbor to push images to Anchore for scanning using the Harbor Scanner Adapter.
Review the results in your Harbor UI once scanning completes
Advanced Configuration Features
Now that you have the base configuration working for the Harbor Scanner Adapter, you are ready to consider some additional features to increase your security posture.
Scheduled Scanning
Beyond on-push scanning, you can configure scheduled scanning to catch newly discovered vulnerabilities in existing images:
In Harbor, navigate to “Administration” → “Interrogation Services” → “Vulnerability”
Set the scan schedule (hourly, daily, weekly, etc.)
Save the configuration
This ensures all images are regularly re-scanned as vulnerability databases are updated with newly discovered and documented vulnerabilities.
Security Policy Enforcement
To enforce security at the pipeline level:
In your Harbor project, navigate to “Configuration”
Enable “Prevent vulnerable images from running”
Select the vulnerability severity level threshold (Low, Medium, High, Critical)
Images with vulnerabilities above this threshold will be blocked from being pulled*
*Be careful with this setting for a production environment. If an image is flagged as having a vulnerability and your container orchestrator attempts to pull the image to auto-scale a service it may cause instability for users.
Proxy Image Cache
Harbor’s proxy cache capability provides an additional security layer:
Navigate to “Registries” in Harbor and select “New Endpoint”
Configure a proxy cache to a public registry like Docker Hub
All images pulled from Docker Hub will be cached locally and automatically scanned for vulnerabilities based on your project settings
Security Tips and Best Practices from the Anchore Team
Use Anchore Enterprise for highest fidelity vulnerability data
The Anchore Enterprise dashboard surfaces complete vulnerability details
Full vulnerability data can be configured with downstream integrations like Slack, Jira, ServiceNow, etc.
“Good data empowers good people to make good decisions.”
—Dan Perry, Principal Customer Success Engineer, Anchore
Configuration Best Practices
For optimal security posture:
Configure per Harbor project: Use different vulnerability scanning settings for different risk profiles
Mind your environment topology: Adjust network timeouts and SSL settings based on network topology; make sure Harbor and Anchore Enterprise deployments are able to communicate securely
Secure Access Controls
Adopt least privilege principle: Use different credentials per repository
Utilize API keys: For service accounts and integrations, use API keys rather than user credentials
Conclusion
Integrating Anchore Enterprise with Harbor registry creates a powerful security checkpoint in your DevSecOps pipeline. By implementing either the pull or push model based on your specific needs, you can automate vulnerability scanning, enforce security policies, and maintain compliance requirements.
This integration enables security teams to:
Detect vulnerabilities before images reach production
Generate and maintain accurate SBOMs
Enforce security policies through prevention controls
Maintain continuous security through scheduled scans
With these tools properly integrated, you can significantly reduce the risk of deploying vulnerable containers to production environments, helping to secure your software supply chain.
Save your developers time with Anchore Enterprise. Get instant access with a 15-day free trial.
In our latest Grype release, we’ve updated the DB schema to v6. This update isn’t just a cosmetic change; it’s a thoughtful redesign that optimizes data storage and matching performance. For you, this means faster database updates (65MB vs 210MB downloads), quicker scans, and more comprehensive vulnerability detection, all while maintaining the familiar output format and user experience you rely on.
The Past: Schema v5
Originally, grype’s vulnerability data was managed using two main tables:
VulnerabilityModel: This table stores package-specific vulnerability details. Each affected package version required a separate row, which led to significant metadata duplication.
VulnerabilityMetadataModel: To avoid duplicating large strings (like detailed vulnerability descriptions), metadata was separated into its own table.
This v1 design was born out of necessity. Early CGO-free SQLite drivers didn’t offer SQLite’s plethora of features. In later releases we were able to swap out the SQLite driver to the newly available modernc.org/sqlite driver and use GORM for general access.
However, v2 – v5 had the same basic design approach. This led to space inefficiencies: the on-disk footprint grew to roughly 1.6 GB, and the cost was notable even after compression (210 MB as a tar.gz).
When it came to searching the database, we organized rows into “namespaces” which was a string that indicated the intended ecosystem this affected (e.g. a specific distro name + version, a language name, etc, for instance redhat:distro:redhat:7 or cpe:nvd).
When searching for matches in Grype, we would cast a wide net on an initial search within the database by namespace + package name and refine the results by additionally parsed attributes, effectively casting a smaller net as we progressed. As the database grew we came across more examples where the idea of a “namespace” just didn’t make sense (for instance, what if you weren’t certain what namespace your software artifact landed in, do you simply search all namespaces?). We clearly needed to remove the notion of namespaces as a core input into searching the database.
Another thing that happened after the initial release of the early Grype DB schemas: the Open Source Vulnerability schema (OSV) was released. This format enabled a rich, machine-readable format that could be leveraged by vulnerability data providers when publishing vulnerability advisories, and meant that tools could more easily consume data from a broad set of vulnerability sources, providing more accurate results for end users. We knew that we wanted to more natively be able to ingest this format and maybe even express records internally in a similar manner.
The Present: Schema v6
To address these challenges, we’ve entirely reimagined how Grype stores and accesses vulnerability data:
At a high level, the new DB is primarily a JSON blob store for the bulk of the data, with specialized indexes for efficient searching. The stored JSON blobs are heavily inspired by the OSV schema, but tailored to meet Grype’s specific needs. Each entity we want to search by gets its own table with optimized indexes, and these rows point to the OSV-like JSON blob snippets.
Today, we have three primary search tables:
AffectedPackages: These are packages that exist in a known language, packaging ecosystem, or specific Linux distribution version.
AffectedCPEs: These are entries from NVD which do not have a known packaging ecosystem.
Vulnerabilities: These contain core vulnerability information without any packaging information.
One of the most significant improvements is removing “namespaces” entirely from within the DB. Previously, client-based changes were needed to craft the correct namespace for database searches. This meant shipping software updates for what were essentially data corrections. In v6, we’ve shifted these cases to simple lookup tables in the DB, normalizing search input. We can fix or add search queries through database updates alone, no client update required.
Moreover, the v6 schema’s modular design simplifies extending functionality. Integrating additional vulnerability feeds or other external data sources is now far more straightforward, ensuring that Grype remains flexible and future-proof.
The Benefits: What’s New in the Database
In terms of content, v6 includes everything from v5 plus important additions:
Withdrawn vulnerabilities: We now persist “withdrawn” vulnerabilities. While this doesn’t affect matching, it improves reference capabilities for related vulnerability data
Enhanced datasets: We’ve added the CISA Known Exploited Vulnerabilities and EPSS (Exploit Prediction Scoring System) datasets to the database
The best way to explore this data is with the grype db search and grype db search vuln commands.
search allows you to discover affected packages by a wide array of parameters (package name, CPE, purl, vulnerability ID, provider, ecosystem, linux distribution, added or modified since a particular date, etc):
As with all of our tools, there is -o json available with these commands to be able to explore the raw affected package, affected CPE, and vulnerability records:
$ grype db search vuln CVE-2021-44228 -o json --provider nvd[ {"id": "CVE-2021-44228","assigner": ["[email protected]" ],"description": "Apache Log4j2 2.0-beta9 through 2.15.0 (excluding security releases 2.12.2, 2.12.3, and 2.3.1) JNDI features...","refs": [...],"severities": [...],"provider": "nvd","status": "active","published_date": "2021-12-10T10:15:09.143Z","modified_date": "2025-02-04T15:15:13.773Z","known_exploited": [ {"cve": "CVE-2021-44228","vendor_project": "Apache","product": "Log4j2","date_added": "2021-12-10","required_action": "For all affected software assets for which updates exist, the only acceptable remediation actions are: 1) Apply updates; OR 2) remove affected assets from agency networks. Temporary mitigations using one of the measures provided at https://www.cisa.gov/uscert/ed-22-02-apache-log4j-recommended-mitigation-measures are only acceptable until updates are available.","due_date": "2021-12-24","known_ransomware_campaign_use": "known","urls": ["https://nvd.nist.gov/vuln/detail/CVE-2021-44228" ],"cwes": ["CWE-20","CWE-400","CWE-502" ] } ],"epss": [ {"cve": "CVE-2021-44228","epss": 0.97112,"percentile": 0.9989,"date": "2025-03-03" } ] }]
Dramatic Size Reduction: The Technical Journey
One of the standout improvements of v6 is the dramatic size reduction:
Metric
Schema v5
Schema v6
Improvement
Raw DB Size
1.6 GB
900 MB
44% smaller
Compressed Archive
210 MB
65 MB
69% smaller
This means you’ll experience significantly faster database updates and reduced storage requirements.
We build and distribute Grype database archives daily to provide users with the most up-to-date vulnerability information. Over the past five years, we’ve added more vulnerability sources, and the database has more than doubled in size, significantly impacting users who update their databases daily.
Our optimization strategy included:
Switching to zstandard compression: This yields better compression ratios compared to gzip, providing immediate space savings.
Database layout optimization: We prototyped various database layouts, experimenting with different normalization levels (database design patterns that eliminate data redundancy). While higher normalization saved space in the raw database, it sometimes yielded worse compression results. We found the optimal balance between normalization and leaving enough unnormalized data for compression algorithms to work effectively.
Real-World Impact
These improvements directly benefit several common scenarios:
CI/CD Pipelines: With a 69% smaller download size, your CI/CD pipelines will update vulnerability databases faster, reducing build times and costs.
Air-gapped Environments: If you’re working in air-gapped environments and need to transport the database, its significantly smaller size makes this process much more manageable.
Resource-constrained Systems: The smaller memory footprint means Grype can now run more efficiently on systems with limited resources.
Conclusion
The evolution of the Grype database schema from v5 to v6 marks a significant milestone. By rethinking our database structure and using the OSV schema as inspiration, we’ve created a more efficient, scalable, and feature-rich database that directly benefits your vulnerability management workflows.
We’d like to encourage you to update to the latest version of Grype to take advantage of these improvements. If you have feedback on the new schema or ideas for further enhancements, please share them with us on Discourse, and if you spot a bug, let us know on GitHub.
If you’d like to get updates about the Anchore Open Source Community, sign up for our low-traffic community newsletter. Stay tuned for more updates as we refine Grype and empower your security practices!
Security professionals often need to analyze the contents of virtual machines (VMs) to generate Software Bills of Materials (SBOMs). This seemingly straightforward task can become surprisingly complex. I’d like to introduce sbom-vm, a prototype tool I created to simplify this process.
The Current Challenge
Security teams typically use tools such as Syft to generate SBOMs by running it directly inside virtual machines. While this approach works, it comes with significant limitations. VMs with constrained resources can experience out-of-memory errors during scanning. Large filesystems containing millions of files can lead to scans that take hours or even days. In some environments, running analysis tools inside production VMs isn’t permitted at all.
These limitations surfaced through various user reports and feature requests in the Syft project. While Syft and other libraries, such as stereoscope could be extended to handle VM disk images directly, users needed a solution today.
A New Approach with sbom-vm
I developed sbom-vm over a weekend to tackle this challenge from a different angle. Instead of operating inside the virtual machine, sbom-vm works directly with VM disk images from the host system. The tool mounts these images in read-only mode using qemu-nbd, automatically detects and mounts common filesystem types, and runs Syft against the mounted filesystem from the host system.
This approach fundamentally changes how we analyze VM contents. Running outside the virtual machine, sbom-vm sidesteps resource constraints and performance limitations. The read-only nature of all operations ensures the safety of the source material, while support for multiple disk formats and filesystem types provides broad compatibility.
Technical Implementation
At its core, sbom-vm leverages standard Linux utilities to handle disk images safely. Here’s an example of how it manages filesystem mounting:
The tool currently supports multiple disk formats, including qcow2 and vmdk, along with common filesystems such as ext4, ZFS, BTRFS, NTFS, HFS+, and APFS. This broad compatibility ensures it works with most virtual machine images you’ll likely encounter. But it’s early days—I don’t know what crazy filesystems and disk image systems others may have.
Getting Started
To try sbom-vm, you’ll need a Linux system with some common utilities installed:
# Install Syft, so we can generate an SBOM from the VM# See also: https://github.com/anchore/syft$snapinstallsyft# Install Linux utilities to manage disk images$sudoaptinstallqemu-utilsgdiskfdiskpartedutil-linux# Grab sbom-vm from GitHub$gitclonehttps://github.com/popey/sbom-vm$cdsbom-vm
There’s a script provided to generate test images:
# Generate/download some test images to play with$sudo./generate-test-images.py
Generating the test images doesn’t take long:
Now you can scan the images with sbom-vm!
# Run sbom-vm against one of the test images. $sudo./sbom-vm.py./test_images/ubuntu_22.04_zfs.qcow2
Here’s what that looks like, slightly speeded up:
Future Development
So, while sbom-vm provides a practical solution today, there’s room for enhancement. Future development could add support for additional disk image formats, enhance filesystem type detection, and integrate with cloud provider VM snapshots. Performance optimizations for large filesystems and potential integration with Syft’s native capabilities are also on the roadmap.
Join the Project
sbom-vm is open source under the MIT license, and I welcome contributions. Whether you’re interested in adding support for new filesystem types, improving documentation, or reporting issues, you can find the project on GitHub at https://github.com/popey/sbom-vm.
While sbom-vm began as a weekend project, it potentially provides immediate value for security professionals who need to analyze VM disk images. It demonstrates how targeted solutions can bridge gaps in the security toolchain while considering more extensive architectural changes. If you’d like to get updates about the Anchore Open Source Community, sign up for our low-traffic community newsletter and drop by our community discourse.
The blog post is meant to remain “public” so that it will continue to show on the /blog feed. This will help discoverability for people browsing the blog and potentially help SEO. If it is clicked on it will automatically redirect to the pillar page.
Software Bill of Materials (SBOMs) are no longer optional—they’re mission-critical.
That’s why we’re excited to announce the release of our new white paper, “Unlock Enterprise Value with SBOMs: Use-Cases for the Entire Organization.” This comprehensive guide is designed for security and engineering leadership at both commercial enterprises and federal agencies, providing actionable insights into how SBOMs are transforming the way organizations manage software complexity, mitigate risk, and drive business outcomes.
From software supply chain security to DevOps acceleration and regulatory compliance, SBOMs have emerged as a cornerstone of modern software development. They do more than provide a simple inventory of application components; they enable rapid security incident response, automated compliance, reduced legal risk, and accelerated software delivery.
⏱️ Can’t wait till the end? 📥 Download the white paper now 👇👇👇
SBOMs are no longer just a checklist item—they’re a strategic asset. They provide an in-depth inventory of every component within your software ecosystem, complete with critical metadata about suppliers, licensing rights, and security postures. This newfound transparency is revolutionizing cross-functional operations across enterprises by:
Accelerating Incident Response: Quickly identify vulnerable components and neutralize threats before they escalate.
Enhancing Vulnerability Management: Prioritize remediation efforts based on risk, ensuring that developer resources are optimally deployed.
Reducing Legal Risk: Manage open source license obligations proactively, ensuring that every component meets your organization’s legal and security standards.
What’s Inside the White Paper?
Our white paper is organized by organizational function; each section highlighting the relevant SBOM use-cases. Here’s a glimpse of what you can expect:
Security: Rapidly identify and mitigate zero-day vulnerabilities, scale vulnerability management, and detect software drift to prevent breaches.
Engineering & DevOps: Eliminate wasted developer time with real-time feedback, automate dependency management, and accelerate software delivery.
Regulatory Compliance: Automate policy checks, streamline compliance audits, and meet requirements like FedRAMP and SSDF Attestation with ease.
Legal: Reduce legal exposure by automating open source license risk management.
Sales: Instill confidence in customers and accelerate sales cycles by proactively providing SBOMs to quickly build trust.
Also, you’ll find real-world case studies from organizations that have successfully implemented SBOMs to reduce risk, boost efficiency, and gain a competitive edge. Learn how companies like Google and Cisco are leveraging SBOMs to drive business outcomes.
Empower Your Enterprise with SBOM-Centric Strategies
The white paper underscores that SBOMs are not a one-trick pony. They are the cornerstone of modern software supply chain management, driving benefits across security, engineering, compliance, legal, and customer trust. Whether your organization is embarking on its SBOM journey or refining an established process, this guide will help you unlock cross-functional value and future-proof your technology operations.
Download the White Paper Today
SBOMs are more than just compliance checkboxes—they are a strategic enabler for your organization’s security, development, and business operations. Whether your enterprise is just beginning its SBOM journey or operating a mature SBOM initiative, this white paper will help you uncover new ways to maximize value.
Explore SBOM use-cases for almost any department of the enterprise and learn how to unlock enterprise value to make the most of your software supply chain.
SBOM (software bill of materials) generation is becoming increasingly important for software supply chain security and compliance. Several approaches exist for generating SBOMs for Python projects, each with its own strengths. In this post, we’ll explore two popular methods: using pipdeptree with cyclonedx-py and Syft. We’ll examine their differences and see why Syft is better for many use-cases.
Learn the 5 best practices for container security and how SBOMs play a pivotal role in securing your software supply chain.
Before diving into the tools, let’s understand why generating an SBOM for your Python packages is increasingly critical in modern software development. Security analysis is a primary driver—SBOMs provide a detailed inventory of your dependencies that security teams can use to identify vulnerabilities in your software supply chain and respond quickly to newly discovered threats. The cybersecurity compliance landscape is also evolving rapidly, with many organizations and regulations (e.g., EO 14028) now requiring SBOMs as part of software delivery to ensure transparency and traceability in an organization’s software supply chain.
From a maintenance perspective, understanding your complete dependency tree is essential for effective project management. SBOMs help development teams track dependencies, plan updates, and understand the potential impact of changes across their applications. They’re particularly valuable when dealing with complex Python applications that may have hundreds of transitive dependencies.
License compliance is another crucial aspect where SBOMs prove invaluable. By tracking software licenses across your entire dependency tree, you can ensure your project complies with various open source licenses and identify potential conflicts before they become legal issues. This is especially important in Python projects, where dependencies might introduce a mix of licenses that need careful consideration.
Generating a Python SBOM with pipdeptree and cyclonedx-py
The first approach we’ll look at combines two specialized Python tools: pipdeptree for dependency analysis and cyclonedx-py for SBOM generation. Here’s how to use them:
# Install the required tools$ pip install pipdeptree cyclonedx-bom# Generate requirements with dependencies$ pipdeptree --freeze > requirements.txt# Generate SBOM in CycloneDX format$ cyclonedx-py requirements requirements.txt > cyclonedx-sbom.json
This Python-specific approach leverages pipdeptree‘s deep understanding of Python package relationships. pipdeptree excels at:
Detecting circular dependencies
Identifying conflicting dependencies
Providing a clear, hierarchical view of package relationships
Generating a Python SBOM with Syft: A Universal SBOM Generator
Syft takes a different approach. As a universal SBOM generator, it can analyze Python packages and multiple software artifacts. Here’s how to use Syft with Python projects:
# Install Syft (varies by platform)# See: https://github.com/anchore/syft#installation$ curl -sSfL https://raw.githubusercontent.com/anchore/syft/main/install.sh | sh -s -- -b /usr/local/bin# Generate SBOM from requirements.txt$ syft requirements.txt -o cyclonedx-json# Or analyze an entire Python project$ syft path/to/project -o cyclonedx-json
Key Advantages of Syft
Syft’s flexibility in output formats sets it apart from other tools. In addition to the widely used CycloneDX format, it supports SPDX for standardized software definitions and offers its own native JSON format that includes additional metadata. This format flexibility allows teams to generate SBOMs that meet various compliance requirements and tooling needs without switching between multiple generators.
Syft truly shines in its comprehensive analysis capabilities. Rather than limiting itself to a single source of truth, Syft examines your entire Python environment, detecting packages from multiple sources, including requirements.txt files, setup.py configurations, and installed packages. It seamlessly handles virtual environments and can even identify system-level dependencies that might impact your application.
The depth of metadata Syft provides is particularly valuable for security and compliance teams. For each package, Syft captures not just basic version information but also precise package locations within your environment, file hashes for integrity verification, detailed license information, and Common Platform Enumeration (CPE) identifiers. This rich metadata enables more thorough security analysis and helps teams maintain compliance with security policies.
Comparing the Outputs
We see significant differences in detail and scope when examining the outputs from both approaches. The pipdeptree with cyclonedx-py combination produces a focused output that concentrates specifically on Python package relationships. This approach yields a simpler, more streamlined SBOM that’s easy to read but contains limited metadata about each package.
Syft, on the other hand, generates a more comprehensive output that includes extensive metadata for each package. Its SBOM provides rich details about package origins, includes comprehensive CPE identification for better vulnerability matching, and offers built-in license detection. Syft also tracks the specific locations of files within your project and includes additional properties that can be valuable for security analysis and compliance tracking.
Here’s a snippet comparing the metadata for the rich package in both outputs:
While both approaches are valid, Syft offers several compelling advantages. As a universal tool that works across multiple software ecosystems, Syft eliminates the need to maintain different tools for different parts of your software stack.
Its rich metadata gives you deeper insights into your dependencies, including detailed license information and precise package locations. Syft’s support for multiple output formats, including CycloneDX, SPDX, and its native format, ensures compatibility with your existing toolchain and compliance requirements.
The project’s active development means you benefit from regular updates and security fixes, keeping pace with the evolving software supply chain security landscape. Finally, Syft’s robust CLI and API options make integrating into your existing automation pipelines and CI/CD workflows easy.
How to Generate a Python SBOM with Syft
Ready to generate SBOMs for your Python projects? Here’s how to get started with Syft:
While pipdeptree combined with cyclonedx-py provides a solid Python-specific solution, Syft offers a more comprehensive and versatile approach to SBOM generation. Its ability to handle multiple ecosystems, provide rich metadata, and support various output formats makes it an excellent choice for modern software supply chain security needs.
Whether starting with SBOMs or looking to improve your existing process, Syft provides a robust, future-proof solution that grows with your needs. Try it and see how it can enhance your software supply chain security today.
Learn about the role that SBOMs for the security of your organization in this white paper.
As software supply chain security becomes a top priority, organizations are turning to Software Bill of Materials (SBOM) generation and analysis to gain visibility into the composition of their software and supply chain dependencies in order to reduce risk. However, integrating SBOM analysis tools into existing workflows can be complex, requiring extensive configuration and technical expertise. Anchore Enterprise, a leading SBOM management and container security platform, simplifies this process with seamless integration capabilities that cater to modern DevSecOps pipelines.
This article explores how Anchore makes SBOM analysis effortless by offering automation, compatibility with industry standards, and integration with popular CI/CD tools.
Learn about the role that SBOMs for the security of your organization in this white paper.
SBOMs play a crucial role in software security, compliance, and vulnerability management. However, organizations often face challenges when adopting SBOM analysis tools:
Complex Tooling: Many SBOM solutions require significant setup and customization.
Scalability Issues: Enterprises managing thousands of dependencies need scalable and automated solutions.
Compatibility Concerns: Ensuring SBOM analysis tools work seamlessly across different DevOps environments can be difficult.
Anchore addresses these challenges by providing a sleek approach to SBOM analysis with easy-to-use integrations.
How Anchore Simplifies SBOM Analysis Integration
1. Automated SBOM Generation and Analysis
Anchore automates SBOM generation from various sources, including container images, software packages, and application dependencies. This eliminates the need for manual intervention, ensuring continuous security and compliance monitoring.
Automatically scans and analyzes SBOMs for vulnerabilities, licensing issues, and security and compliance policy violations.
Provides real-time insights to security teams.
2. Seamless CI/CD Integration
DevSecOps teams require tools that integrate effortlessly into their existing workflows. Anchore achieves this by offering:
Popular CI/CD platform plugins: Jenkins, GitHub Actions, GitLab CI/CD, Azure DevOps and more.
API-driven architecture: Embed SBOM generation and analysis in any DevOps pipeline.
Policy-as-code support: Enforce security and compliance policies within CI/CD workflows.
AnchoreCTL: A command-line (CLI) tool for developers to generate and analyze SBOMs locally before pushing to production.
3. Cloud Native and On-Premises Deployment
Organizations have diverse infrastructure requirements, and Anchore provides flexibility through:
Cloud native support: Works seamlessly with Kubernetes, OpenShift, AWS, and GCP.
On-premises deployment: For organizations requiring strict control over data security.
Hybrid model: Allows businesses to use cloud-based Anchore Enterprise while maintaining on-premises security scanning.
Bonus: Anchore also offers an air-gapped deployment option for organizations working with customers that provide critical national infrastructure like energy, financial services or defense.
A major challenge in SBOM adoption is developer resistance due to complexity. Anchore makes security analysis developer-friendly by:
Providing CLI and API tools for easy interaction.
Delivering clear, actionable vulnerability reports instead of overwhelming developers with false positives.
Integrating directly with development environments, such as VS Code and JetBrains IDEs.
Providing an industry standard 24/7 customer support through Anchore’s customer success team.
Conclusion
Anchore has positioned itself as a leader in SBOM analysis by making integration effortless, automating security checks, and supporting industry standards. Whether an organization is adopting SBOMs for the first time or looking to enhance its software supply chain security, Anchore provides a scalable and developer-friendly solution.
By integrating automated SBOM generation, CI/CD compatibility, cloud native deployment, and compliance management, Anchore enables businesses (no matter the size) and government institutions to adopt SBOM analysis without disrupting their workflows. As software security becomes increasingly critical, tools like Anchore will play a pivotal role in ensuring a secure and transparent software supply chain.For organizations seeking a simple to deploy SBOM analysis solution, Anchore Enterprise is here to deliver results to your organization. Request a demo with our team today!
Learn the 5 best practices for container security and how SBOMs play a pivotal role in securing your software supply chain.
We’re excited to announce Syft v1.20.0! If you’re new to the community, Syft is Anchore’s open source software composition analysis (SCA) and SBOM generation tool that provides foundational support for software supply chain security for modern DevSecOps workflows.
The latest version is packed with performance improvements, enhanced SBOM accuracy, and several community-driven features that make software composition scanning more comprehensive and efficient than ever.
Scanning projects with numerous DLLs was reported to take peculiarly long when running on Windows, sometimes up to 50 minutes. A sharp-eyed community member (@rogueai) discovered that certificate validation was being performed unnecessarily during DLL scanning. A fix was merged into this release and those lengthy scans have been dramatically reduced from to just a few minutes—a massive performance improvement for Windows users!
Bitnami Embedded SBOM Support: Maximum Accuracy
Container images from Bitnami include valuable embedded SBOMs located at /opt/bitnami/. These SBOMs, packaged by the image creators themselves, represent the most authoritative source for package metadata. Thanks to community member @juan131 and maintainer @willmurphyscode, Syft now includes a dedicated cataloger for these embedded SBOMs.
This feature wasn’t simple to implement. It required careful handling of package relationships and sophisticated deduplication logic to merge authoritative vendor data with Syft’s existing scanning capabilities. The result? Scanning Bitnami images gives you the most accurate SBOM possible, combining authoritative vendor data with Syft’s comprehensive analysis.
Smarter License Detection
Handling licenses for non-open source projects can be a bit tricky. We discovered that when license files can’t be matched to a valid SPDX expression, they sometimes get erroneously marked as “unlicensed”—even when valid license text is present. For example, our dpkg cataloger occasionally encountered a license like:
NVIDIA Software License Agreement and CUDA Supplement to Software License Agreement
And categorized the package as unlicensed. Ideally, the cataloger would capture this non-standards compliant license whether the maintainer follows SDPX or not.
Community member @HeyeOpenSource and maintainer @spiffcs tackled this challenge with an elegant solution: a new configuration option that preserves the original license text when SPDX matching fails. While disabled by default for compatibility, you can enable this feature with license.include-unknown-license-content: true in your configuration. This ensures you never lose essential license information, even for non-standard licenses.
Go 1.24: Better Performance and Versioning
The upgrade to Go 1.24 brings two significant improvements:
Faster Scanning: Thanks to Go 1.24’s optimized map implementations, discussed in this Bytesize Go post—and other performance improvements—we’re seeing scan times reduced by as much as 20% in our testing.
Enhanced Version Detection: Go 1.24’s new version embedding means Syft can now accurately report its version and will increasingly provide more accurate version information for Go applications it scans:
syft: go1.24.0
$ go version -m ./syft
path github.com/anchore/syft/cmd/syft
mod github.com/anchore/syft v1.20.0
This also means that as more applications are built with Go 1.24—the versions reported by Syft will become increasingly accurate over time. Everyone’s a winner!
Join the Conversation
We’re proud of these enhancements and grateful to the community for their contributions. If you’re interested in contributing or have ideas for future improvements, head to our GitHub repo and join the conversation. Your feedback and pull requests help shape the future of Syft and our other projects. Happy scanning!
Stay updated on future community spotlights and events by subscribing to our community newsletter.
Learn how MegaLinter leverages Syft and Grype to generate SBOMs and create vulnerability reports
Want to learn how a powerful open-source linting tool that supports over 50 programming languages came to be? Join us for an engaging conversation with Nicolas Vuillamy, the creator of MegaLinter, as he shares the journey from its Bash origins to becoming a comprehensive static code analysis solution developers use worldwide.
In this discussion, Nicolas explores:
– The evolution and core features of MegaLinter – Why static code analysis matters for development teams – How MegaLinter helps maintain code quality and security – Tips for getting started with the tool – How MegaLinter leverages Syft and Grype to generate SBOMs and create vulnerability reports
Watch the whole discussion on YouTube to dive deeper into Nicolas’s insights and learn how MegaLinter can enhance your development workflow.
Stay updated on future community spotlights and events by subscribing to our community newsletter.
This blog post has been archived and replaced by the supporting pillar page that can be found here: https://anchore.com/wp-admin/post.php?post=987474886&action=edit
The blog post is meant to remain “public” so that it will continue to show on the /blog feed. This will help discoverability for people browsing the blog and potentially help SEO. If it is clicked on it will automatically redirect to the pillar page.
Syft is an open source CLI tool and Go library that generates a Software Bill of Materials (SBOM) from source code, container images and packaged binaries. It is a foundational building block for various use-cases: from vulnerability scanning with tools like Grype, to OSS license compliance with tools like Grant. SBOMs track software components—and their associated supplier, security, licensing, compliance, etc. metadata—through the software development lifecycle.
At a high level, Syft takes the following approach to generating an SBOM:
Determine the type of input source (container image, directory, archive, etc.)
Orchestrate a pluggable set of catalogers to scan the source or artifact
Each package cataloger looks for package types it knows about (RPMs, Debian packages, NPM modules, Python packages, etc.)
In addition, the file catalogers gather other metadata and generate file hashes
Aggregate all discovered components into an SBOM document
Output the SBOM in the desired format (Syft, SPDX, CycloneDX, etc.)
Let’s dive into each of these steps in more detail.
Explore SBOM use-cases for almost any department of the enterprise and learn how to unlock enterprise value to make the most of your software supply chain.
Container images (both from registries and local Docker/Podman engines)
Local filesystems and directories
Archives (TAR, ZIP, etc.)
Single files
This flexibility is important as SBOMs are used in a variety of environments, from a developer’s workstation to a CI/CD pipeline.
When you run Syft, it first tries to autodetect the source type from the provided input. For example:
# Scan a container image syft ubuntu:latest# Scan a local filesystemsyft ./my-app/
Pluggable Package Catalogers
The heart of Syft is its decoupled architecture for software composition analysis (SCA). Rather than one monolithic scanner, Syft delegates scanning to a collection of catalogers, each focused on a specific software ecosystem.
Some key catalogers include:
apk-db-cataloger for Alpine packages
dpkg-db-cataloger for Debian packages
rpm-db-cataloger for RPM packages (sourced from various databases)
python-package-cataloger for Python packages
java-archive-cataloger for Java archives (JAR, WAR, EAR)
npm-package-cataloger for Node/NPM packages
Syft automatically selects which catalogers to run based on the source type. For a container image, it will run catalogers for the package types installed in containers (RPM, Debian, APK, NPM, etc). For a filesystem, Syft runs a different set of catalogers looking for installed software that is more typical for filesystems and source code.
This pluggable architecture gives Syft broad coverage while keeping the core streamlined. Each cataloger can focus on accurately detecting its specific package type.
If we look at a snippet of the trace output from scanning an Ubuntu image, we can see some catalogers in action:
Here, the dpkg-db-cataloger found 91 Debian packages, while the rpm-db-cataloger and npm-package-cataloger didn’t find any packages of their types—which makes sense for an Ubuntu image.
Aggregating and Outputting Results
Once all catalogers have finished, Syft aggregates the results into a single SBOM document. This normalized representation abstracts away the implementation details of the different package types.
Source information (repository, download URL, etc.)
File digests and metadata
It also contains essential metadata, including a copy of the configuration used when generating the SBOM (for reproducibility). The SBOM will contain detailed information about package evidence, which packages were parsed from (within package.Metadata).
Finally, Syft serializes this document into one or more output formats. Supported formats include:
Syft’s native JSON format
SPDX’s tag-value and JSON
CycloneDX’s JSON and XML
Having multiple formats allows integrating Syft into a variety of toolchains and passing data between systems that expect certain standards.
Revisiting the earlier Ubuntu example, we can see a snippet of the final output:
NAME VERSION TYPEapt 2.7.14build2 debbase-files 13ubuntu10.1 debbash 5.2.21-2ubuntu4 deb
Container Image Parsing with Stereoscope
To generate high-quality SBOMs from container images, Syft leverages a stereoscope library for parsing container image formats.
Stereoscope does the heavy lifting of unpacking an image into its constituent layers, understanding the image metadata, and providing a unified filesystem view for Syft to scan.
This encapsulation is quite powerful, as it abstracts the details of different container image specs (Docker, OCI, etc.), allowing Syft to focus on SBOM generation while still supporting a wide range of images.
Cataloging Challenges and Future Work
While Syft can generate quality SBOMs for many source types, there are still challenges and room for improvement.
One challenge is supporting the vast variety of package types and versioning schemes. Each ecosystem has its own conventions, making it challenging to extract metadata consistently. Syft has added support for more ecosystems and evolved its catalogers to handle edge-cases to provide support for an expanding array of software tooling.
Another challenge is dynamically generated packages, like those created at runtime or built from source. Capturing these requires more sophisticated analysis that Syft does not yet do. To illustrate, let’s look at two common cases:
Runtime Generated Packages
Imagine a Python application that uses a web framework like Flask or Django. These frameworks allow defining routes and views dynamically at runtime based on configuration or plugin systems.
For example, an application might scan a /plugins directory on startup, importing any Python modules found and registering their routes and models with the framework. These plugins could pull in their own dependencies dynamically using importlib.
From Syft’s perspective, none of this dynamic plugin and dependency discovery happens until the application actually runs. The Python files Syft scans statically won’t reveal those runtime behaviors.
Furthermore, plugins could be loaded from external sources not even present in the codebase Syft analyzes. They might be fetched over HTTP from a plugin registry as the application starts.
To truly capture the full set of packages in use, Syft would need to do complex static analysis to trace these dynamic flows, or instrument the running application to capture what it actually loads. Both are much harder than scanning static files.
Source Built Packages
Another typical case is building packages from source rather than installing them from a registry like PyPI or RubyGems.
Consider a C++ application that bundles several libraries in a /3rdparty directory and builds them from source as part of its build process.
When Syft scans the source code directory or docker image, it won’t find any already built C++ libraries to detect as packages. All it will see are raw source files, which are much harder to map to packages and versions.
One approach is to infer packages from standard build tool configuration files, like CMakeLists.txt or Makefile. However, resolving the declared dependencies to determine the full package versions requires either running the build or profoundly understanding the specific semantics of each build tool. Both are fragile compared to scanning already built artifacts.
Some Language Ecosystems are Harder Than Others
It’s worth noting that dynamism and source builds are more or less prevalent in different language ecosystems.
Interpreted languages like Python, Ruby, and JavaScript tend to have more runtime dynamism in their package loading compared to compiled languages like Java or Go. That said, even compiled languages have ways of loading code dynamically, it just tends to be less common.
Likewise, some ecosystems emphasize always building from source, while others have a strong culture of using pre-built packages from central registries.
These differences mean the level of difficulty for Syft in generating a complete SBOM varies across ecosystems. Some will be more amenable to static analysis than others out of the box.
What Could Help?
To be clear, Syft has already done impressive work in generating quality SBOMs across many ecosystems despite these challenges. But to reach the next level of coverage, some additional analysis techniques could help:
Static analysis to trace dynamic code flows and infer possible loaded packages (with soundness tradeoffs to consider)
Dynamic instrumentation/tracing of applications to capture actual package loads (sampling and performance overhead to consider)
Standardized metadata formats for build systems to declare dependencies (adoption curve and migration path to consider)
Heuristic mapping of source files to known packages (ambiguity and false positives to consider)
None are silver bullets, but they illustrate the approaches that could help push SBOM coverage further in complex cases.
Ultimately, there will likely always be a gap between what static tools like Syft can discover versus the actual dynamic reality of applications. But that doesn’t mean we shouldn’t keep pushing the boundary! Even incremental improvements in these areas help make the software ecosystem more transparent and secure.
Syft also has room to grow in terms of programming language support. While it covers major ecosystems like Java and Python well, more work is needed to cover languages like Go, Rust, and Swift completely.
As the SBOM landscape evolves, Syft will continue to adapt to handle more package types, sources, and formats. Its extensible architecture is designed to make this growth possible.
Get Involved
Syft is fully open source and welcomes community contributions. If you’re interested in adding support for a new ecosystem, fixing bugs, or improving SBOM generation, the repo is the place to get started.
There are issues labeled “Good First Issue” for those new to the codebase. For more experienced developers, the code is structured to make adding new catalogers reasonably straightforward.
No matter your experience level, there are ways to get involved and help push the state of the art in SBOM generation. We hope you’ll join us!
Learn about the role that SBOMs for the security of your organization in this white paper.
The blog post is meant to remain “public” so that it will continue to show on the /blog feed. This will help discoverability for people browsing the blog and potentially help SEO. If it is clicked on it will automatically redirect to the pillar page.
Today, we’re excited to announce the launch of “Software Bill of Materials 101: A Guide for Developers, Security Engineers, and the DevSecOps Community”. This eBook is free and open source resource that provides a comprehensive introduction to all things SBOMs.
Why We Created This Guide
While SBOMs have become increasingly critical for software supply chain security, many developers and security professionals still struggle to understand and implement them effectively. We created this guide to help bridge that knowledge gap, drawing on our experience building popular SBOM tools like Syft.
What’s Inside
The ebook covers essential SBOM topics, including:
Practical guidance for integrating SBOMs into DevSecOps pipelines
We’ve structured the content to be accessible to newcomers while providing enough depth for experienced practitioners looking to expand their knowledge.
Community-Driven Development
This guide is published under an open source license and hosted on GitHub at https://github.com/anchore/sbom-ebook. The collective wisdom of the DevSecOps community will strengthen this resource over time. We welcome contributions whether fixes, new content, or translations.
Getting Started
You can read the guide online, download PDF/ePub versions, or clone the repository to build it locally. The source is in Markdown format, making it easy to contribute improvements.
The software supply chain security challenges we face require community collaboration. We hope this guide advances our collective understanding of SBOMs and their role in securing the software ecosystem.
Learn about the role that SBOMs play for the security of your organization in this white paper.
The blog post is meant to remain “public” so that it will continue to show on the /blog feed. This will help discoverability for people browsing the blog and potentially help SEO. If it is clicked on it will automatically redirect to the pillar page.
While many issues were identified, the executive order named and shamed software vendors for signing and submitting secure software development compliance documents without fully adhering to the framework. The full quote:
In some instances, providers of software to the Federal Government commit[ed] to following cybersecurity practices, yet do not fix well-known exploitable vulnerabilities in their software, which put the Government at risk of compromise. The Federal Government needs to adopt more rigorous 3rd-party risk management practices and greater assurance that software providers… are following the practices to which they attest.
In response to this behavior, the 2025 Cybersecurity EO has taken a number of additional steps to both encourage cybersecurity compliance and deter non-compliance—the carrot and the stick. This comes in the form of 4 primary changes:
Compliance verification by CISA
Legal repercussions for non-compliance
Contract modifications for Federal agency software acquisition
Mandatory adoption of software supply chain risk management practices by Federal agencies
In this post, we’ll explore the new cybersecurity EO in detail, what has changed in software supply chain security compliance and what both federal agencies and software providers can do right now to prepare.
What Led to the New Cybersecurity Executive Order?
In the wake of massive growth of supply chain attacks—especially those from nation-state threat actors like China—EO 14028 made software bill of materials (SBOMs) and software supply chain security spotlight agenda items for the Federal government. As directed by the EO, the National Institute of Standards and Technology (NIST) authored the Secure Software Development Framework (SSDF) to codify the specific secure software development practices needed to protect the US and its citizens.
Following this, the Office of Management and Budget (OMB) published a memo that established a deadline for agencies to require vendor compliance with the SSDF. Importantly, the memo allowed vendors to “self-attest” to SSDF compliance.
In practice, many software providers chose to go the easy route and submitted SSDF attestations while only partially complying with the framework. Although the government initially hoped that vendors would not exploit this somewhat obvious loophole, reality intervened, leading to the issuance of the 2025 cybersecurity EO to close off these opportunities for non-compliance.
What’s Changing in the 2025 EO?
1. Rigorous verification of secure software development compliance
No longer can vendors simply self-attest to SSDF compliance. The Cybersecurity and Infrastructure Security Agency (CISA) is now tasked with validating these attestations and via the additional compliance artifacts the new EO requires. Providers that fail validation risk increased scrutiny and potential consequences such as…
2. CISA authority to refer non-compliant vendors to DOJ
A major shift comes from the EO’s provision allowing CISA to forward fraudulent attestations to the Department of Justice (DOJ). In the EO’s words, officials may “refer attestations that fail validation to the Attorney General for action as appropriate.” This raises the stakes for software vendors, as submitting false information on SSDF compliance could lead to legal consequences.
3. Explicit SSDF compliance in software acquisition contracts
The Federal Acquisition Regulatory Council (FAR Council) will issue contract modifications that explicitly require SSDF compliance and additional items to enable CISA to programmatically verify compliance. Federal agencies will incorporate updated language in their software acquisition contracts, making vendors contractually accountable for any misrepresentations in SSDF attestations.
See the “FAR council contract updates” section below for the full details.
4. Mandatory adoption of supply chain risk management
Agencies must now embed supply chain risk management (SCRM) practices agency-wide, aligning with NIST SP 800-161, which details best practices for assessing and mitigating risks in the supply chain. This elevates SCRM to a “must-have” strategy for every Federal agency.
NIST will update both NIST SP 800-53, the “Control Catalog”, and the SSDF (NIST SP 800-218) to align with the new policy. The updates will incorporate additional controls and greater detail on existing controls. Although no controls have yet been formally added or modified, NIST is tasked with modernizing these documents to align with changes in secure software development practices. Once those updates are complete, agencies and vendors will be expected to meet the revised requirements.
Policy-as-code pilot
Section 7 of the EO describes a pilot program focused on translating security controls from compliance frameworks into “rules-as-code” templates. Essentially, this adopts a policy-as-code approach, often seen in DevSecOps, to automate compliance. By publishing machine-readable security controls that can be integrated directly into DevOps, security, and compliance tooling, organizations can reduce manual overhead and friction, making it easier for both agencies and vendors to consistently meet regulatory expectations.
FedRAMP incentives and new key management controls
The Federal Risk and Authorization Management Program (FedRAMP), responsible for authorizing cloud service providers (CSPs) for federal use, will also see important updates. FedRAMP will develop policies that incentivize or require CSPs to share recommended security configurations, thereby promoting a standard baseline for cloud security. The EO also proposes updates to FedRAMP security controls to address cryptographic key management best practices, ensuring that CSPs properly safeguard cryptographic keys throughout their lifecycle.
How to Prepare for the New Requirements
FAR council contract updates
Within 30 days of the EO release, the FAR Council will publish recommended contract language. This updated language will mandate:
Machine-readable SSDF Attestations: Vendors must provide an SSDF attestation in a structured, machine-readable format.
Compliance Reporting Artifacts: High-level artifacts that demonstrate evidence of SSDF compliance, potentially including automated scan results, security test reports, or vulnerability assessments.
Customer List: A list of all civilian agencies using the vendor’s software, enabling CISA and federal agencies to understand the scope of potential supply chain risk.
Important Note: The 30-day window applies to the FAR Council to propose new contract language—not for software vendors to become fully compliant. However, once the new contract clauses are in effect, vendors who want to sell to federal agencies will need to meet these updated requirements.
Action Steps for Federal Agencies
Federal agencies will bear new responsibilities to ensure compliance and mitigate supply chain risk. Here’s what you should do now:
Perform a vulnerability scan on all 3rd-party components. If you already have SBOMs, scanning them for vulnerabilities is a quick way to find identity risk.
Identify Critical Suppliers
Determine which software vendors are mission-critical. This helps you understand where to focus your risk management efforts.
Assess Data Sensitivity
If a vendor handles sensitive data (e.g., PII), extra scrutiny is needed. A breach here has broader implications for the entire agency.
Map Potential Lateral Movement Risk
Understand if a vendor’s software could provide attackers with lateral movement opportunities within your infrastructure.
Action Steps for Software Providers
For software vendors, especially those who sell to the federal government, proactivity is key to maintaining and expanding federal contracts.
Inventory Your Software Supply Chain
Implement an SBOM-powered SCA solution within your DevSecOps pipeline to gain real-time visibility into all 3rd-party components.
Assess Supplier Risk
Perform vulnerability scanning on 3rd-party supplier components to identify any that could jeopardize your compliance or your customers’ security.
Identify Sensitive Data Handling
If your software processes personally identifiable information (PII) or other sensitive data, expect increased scrutiny. On the flip side, this may make your offering “mission-critical” and less prone to replacement—but it also means compliance standards will be higher.
Map Your Own Attack Surface
Assess whether a 3rd-party supplier breach could cascade into your infrastructure and, by extension, your customers.
Prepare Compliance Evidence
Start collecting artifacts—such as vulnerability scan reports, secure coding guidelines, and internal SSDF compliance checklists—so you can quickly meet new attestation requirements when they come into effect.
Wrap-Up
The 2025 Cybersecurity EO is a direct response to the flaws uncovered in EO 14028’s self-attestation approach. By requiring 3rd-party validation of SSDF compliance, the government aims to create tangible improvements in its cybersecurity posture—and expects the same from all who supply its agencies.
Given the rapid timeline, preparation is crucial. Both federal agencies and software providers should begin assessing their supply chain risks, implementing SBOM-driven visibility, and proactively planning for new attestation and reporting obligations. By taking steps now, you’ll be better positioned to meet the new requirements.
Learn about SSDF Attestation with this guide. The eBook will take you through everything you need to know to get started.
The blog post is meant to remain “public” so that it will continue to show on the /blog feed. This will help discoverability for people browsing the blog and potentially help SEO. If it is clicked on it will automatically redirect to the pillar page.
In recent years, we’ve witnessed software supply chain security transition from a quiet corner of cybersecurity into a primary battlefield. This is due to the increasing complexity of modern software that obscures the full truth—applications are a tower of components of unknown origin. Cybercriminals have fully embraced this hidden complexity as a ripe vector to exploit.
Software Bills of Materials (SBOMs) have emerged as the focal point to achieve visibility and accountability in a software ecosystem that will only grow more complex. SBOMs are an inventory of the complex dependencies that make up modern applications. SBOMs help organizations scale vulnerability management and automate compliance enforcement. The end goal is to increase transparency in an organization’s supply chain where 70-90% of modern applications are open source software (OSS) dependencies. This significant source of risk demands a proactive, data-driven solution.
Looking ahead to 2025, we at Anchore, see two trends for SBOMs that foreshadow their growing importance in software supply chain security:
Global regulatory bodies continue to steadily drive SBOM adoption
Foundational software ecosystems begin to implement build-native SBOM support
In this blog, we’ll walk you through the contextual landscape that leads us to these conclusions; keep reading if you want more background.
Global Regulatory Bodies Continue Growing Adoption of SBOMs
As supply chain attacks surged, policymakers and standards bodies recognized this new threat vector as a critical threat with national security implications. To stem the rising tide supply chain threats, global regulatory bodies have recognized that SBOMs are one of the solutions.
Over the past decade, we’ve witnessed a global legislative and regulatory awakening to the utility of SBOMs. Early attempts like the US Cyber Supply Chain Management and Transparency Act of 2014 may have failed to pass, but they paved the way for more significant milestones to come. Things began to change in 2021, when the US Executive Order (EO) 14028 explicitly named SBOMs as the foundation for a secure software supply chain. The following year the European Union’s Cyber Resilience Act (CRA) pushed SBOMs from “suggested best practice” to “expected norm.”
The one-two punch of the US’s EO 14028 and the EU’s CRA has already prompted action among regulators worldwide. In the years following these mandates, numerous global bodies issued or updated their guidance on software supply chain security practices—specifically highlighting SBOMs. Cybersecurity offices in Germany, India, Britain, Australia, and Canada, along with the broader European Union Agency for Cybersecurity (ENISA), have each underscored the importance of transparent software component inventories. At the same time, industry consortiums in the US automotive (Auto-ISAC) and medical device (IMDRF) sectors recognized that SBOMs can help safeguard their own complex supply chains, as have federal agencies such as the FDA, NSA, and the Department of Commerce.
By the close of 2024, the pressure mounted further. In the US, the Office of Management and Budget (OMB) set a due date requiring all federal agencies to comply with the Secure Development Framework (SSDF), effectively reinforcing SBOM usage as part of secure software development. Meanwhile, across the Atlantic, the EU CRA officially became law, cementing SBOMs as a cornerstone of modern software security. This constant pressure ensures that SBOM adoption will only continue to grow. It won’t be long until SBOMs become table stakes for anyone operating an online business. We expect the steady march forward of SBOMs to continue in 2025.
In fact, this regulatory push has been noticed by the foundational ecosystems of the software industry and they are reacting accordingly.
Software Ecosystems Trial Build-Native SBOM Support
Until now, SBOM generation has been relegated to afterthought in software ecosystems. Businesses scan their internal supply chains with software composition analysis (SCA) tools; trying to piece together a picture of their dependencies. But as SBOM adoption continues its upward momentum, this model is evolving. In 2025, we expect that leading software ecosystems will promote SBOMs to a first-class citizen and integrate them natively into their build tools.
Industry experts have recently begun advocating for this change. Brandon Lum, the SBOM Lead at Google, notes, “The software industry needs to improve build tools propagating software metadata.” Rather than forcing downstream consumers to infer the software’s composition after the fact, producers will generate SBOMs as part of standard build pipelines. This approach reduces friction, makes application composition discoverable, and ensures that software supply chain security is not left behind.
We are already seeing early examples:
Linux Ecosystem (Yocto): The Yocto Project’s OpenEmbedded build system now includes native SBOM generation. This demonstrates the feasibility of integrating SBOM creation directly into the developer toolchain, establishing a blueprint for other ecosystems to follow.
Python Ecosystem: In 2024, Python maintainers explored proposals for build-native SBOM support, motivated by the regulations such as, the Secure Software Development Framework (SSDF) and the EU’s CRA. They’ve envisioned a future where projects, package maintainers, and contributors can easily annotate their code with software dependency metadata that will automatically propagate at build time.
Java Ecosystem: The Eclipse Foundation and VMware’s Spring Boot team have introduced plug-ins for Java build tools like Maven or Gradle that streamline SBOM generation. While not fully native to the compiler or interpreter, these integrations lower the barrier to SBOM adoption within mainstream Java development workflows.
In 2025 we won’t just be talking about build-native SBOMs in abstract terms—we’ll have experimental support for them from the most forward thinking ecosystems. This shift is still in its infancy but it foreshadows the central role that SBOMs will play in the future of cybersecurity and software development as a whole.
Closing Remarks
The writing on the wall is clear: supply chain attacks aren’t slowing down—they are accelerating. In a world of complex, interconnected dependencies, every organization must know what’s inside its software to quickly spot and respond to risk. As SBOMs move from a nice-to-have to a fundamental part of building secure software, teams can finally gain the transparency they need over every component they use, whether open source or proprietary. This clarity is what will help them respond to the next Log4j or XZ Utils issue before it spreads, putting security team’s back in the driver’s seat and ensuring that software innovation doesn’t come at the cost of increased vulnerability.
Learn about the role that SBOMs for the security of your organization in this white paper.