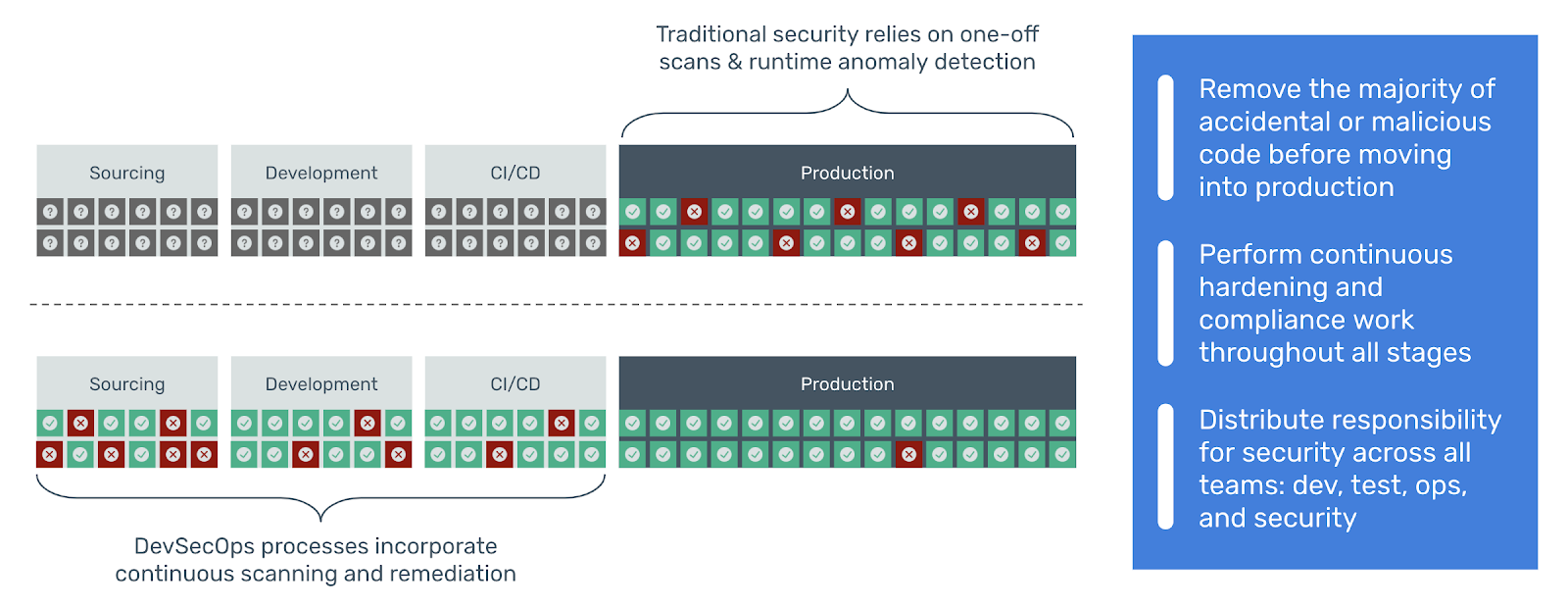
In order to shift security left in the development lifecycle without compromising production velocity, security requirements must be automated and embedded into continuous integration / continuous delivery workflows. Organizations can achieve this through the automated implementation, verification, remediation, monitoring and reporting of compliance into the development pipeline. Furthermore, organizations can manage security requirements in code repositories like any other piece of code using Anchore policy bundles.
How does Anchore Help Achieve this?
At Anchore, our focus is to help organizations embed compliance requirements into their containerized environments, establishing security guardrails earlier in the development pipeline.
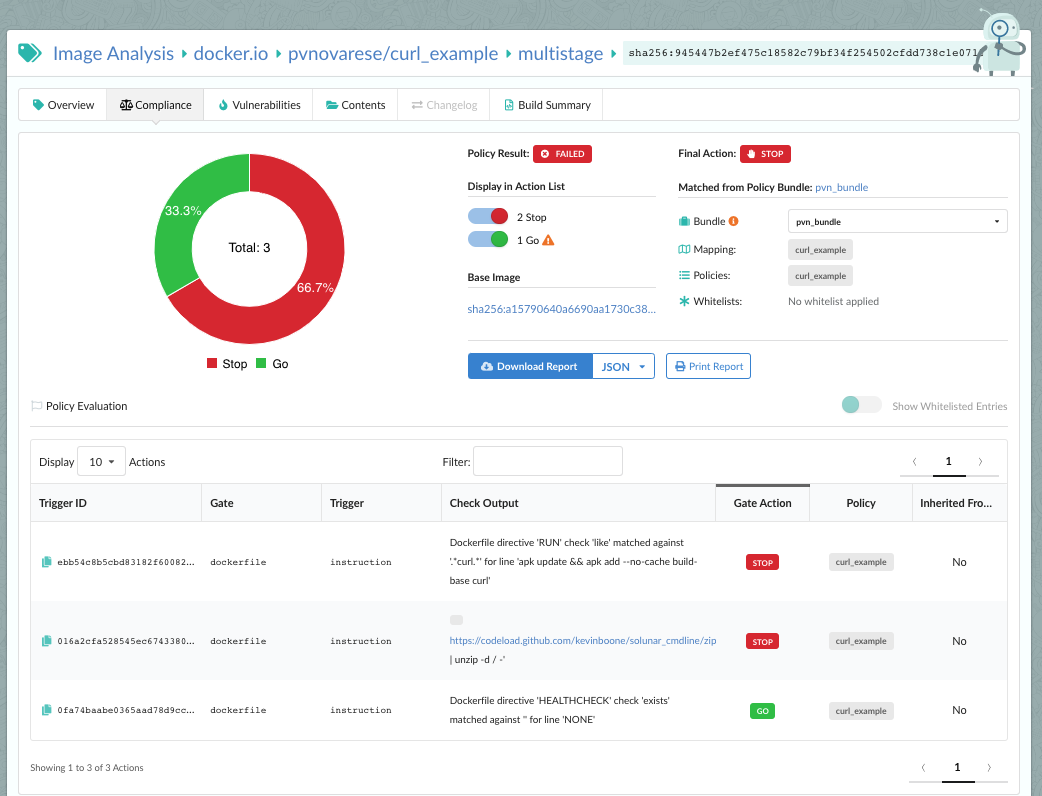
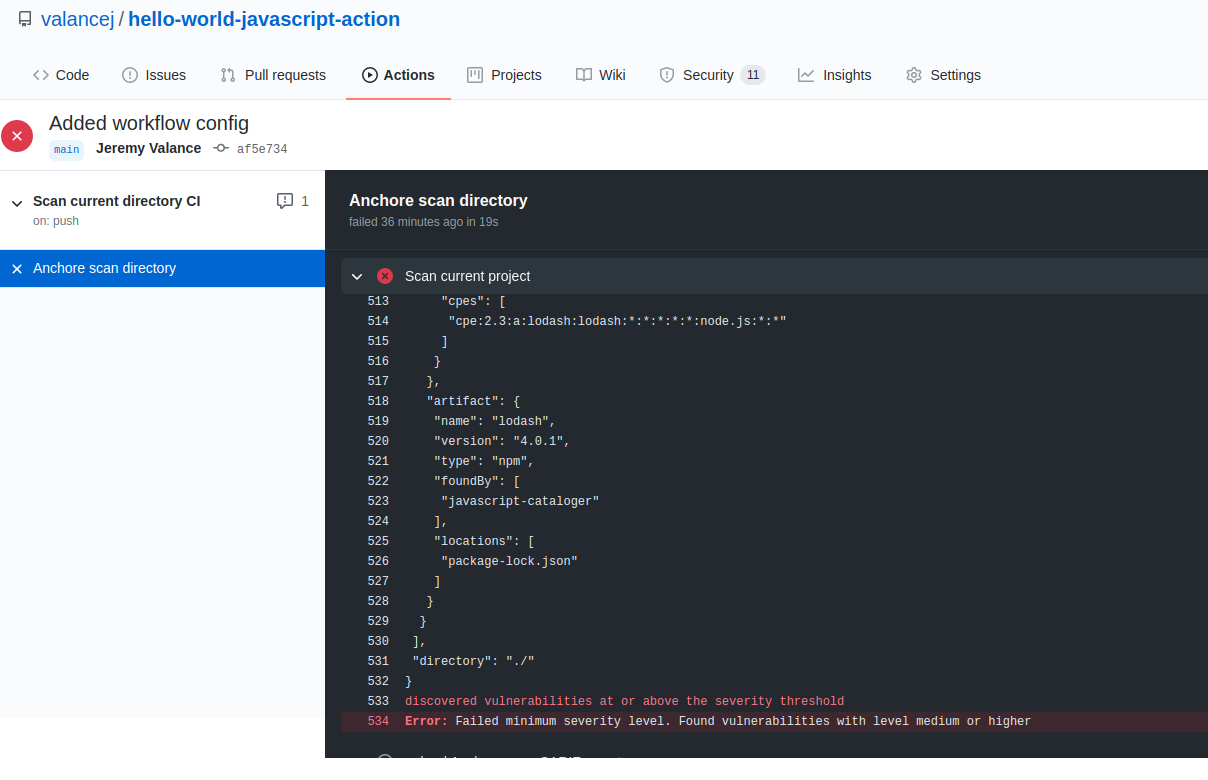
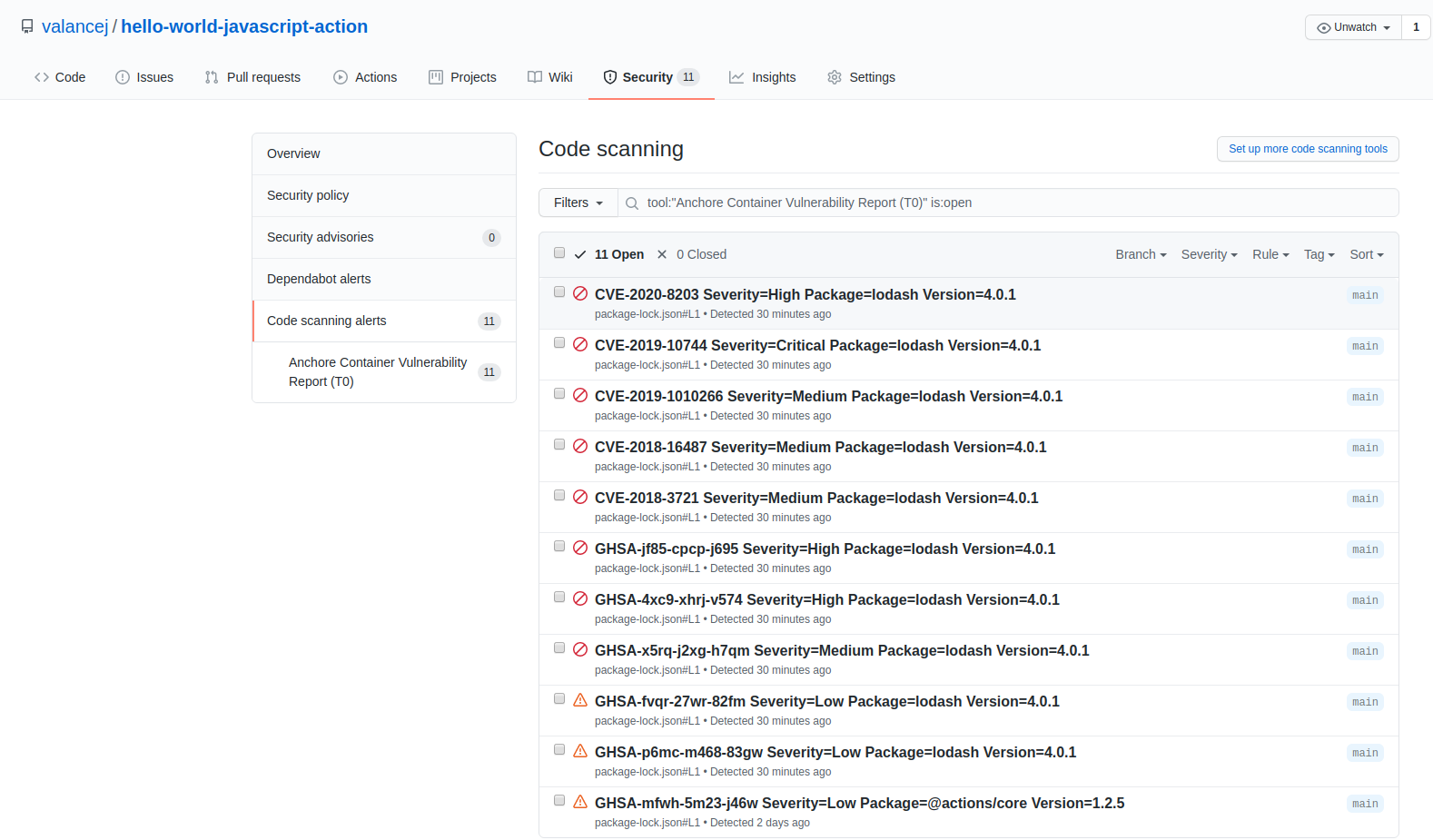
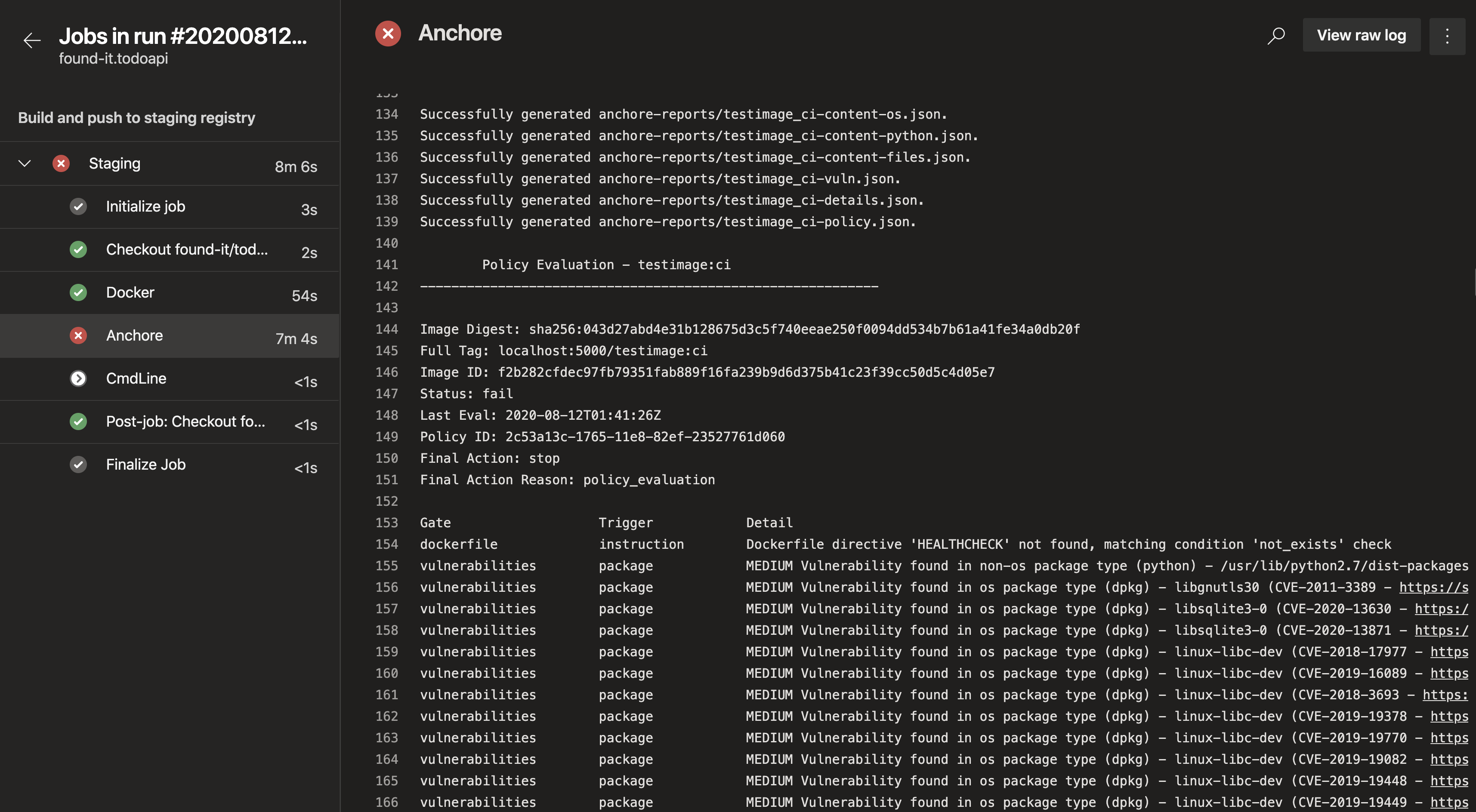
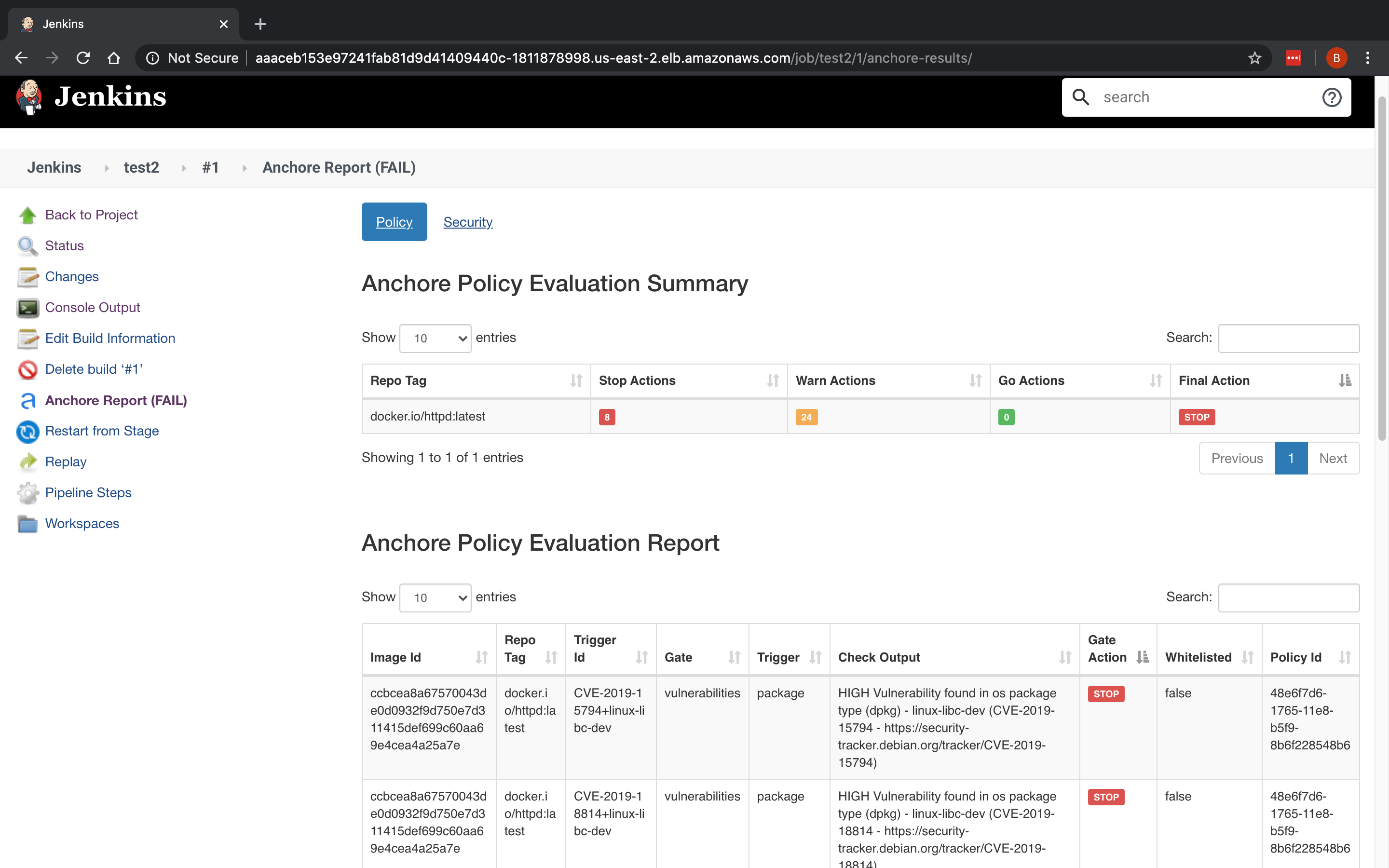
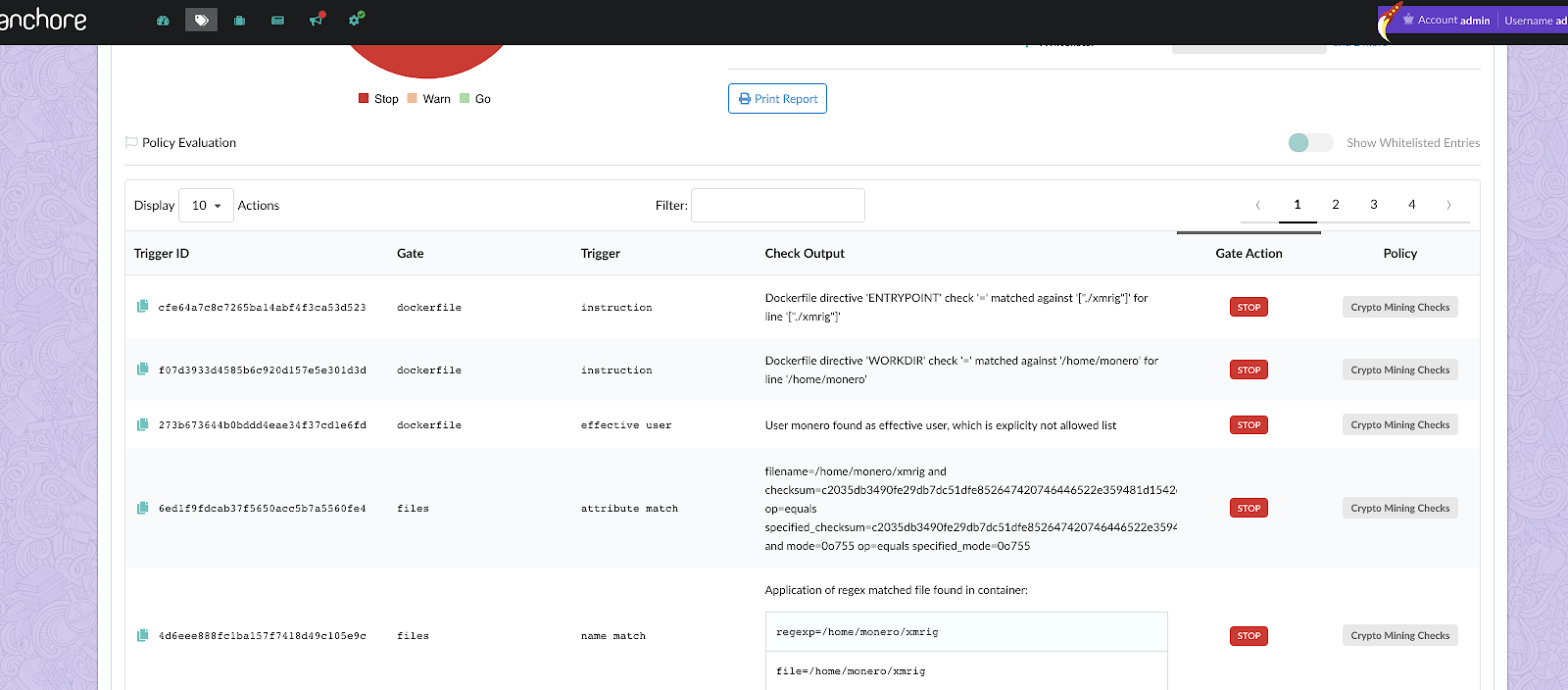
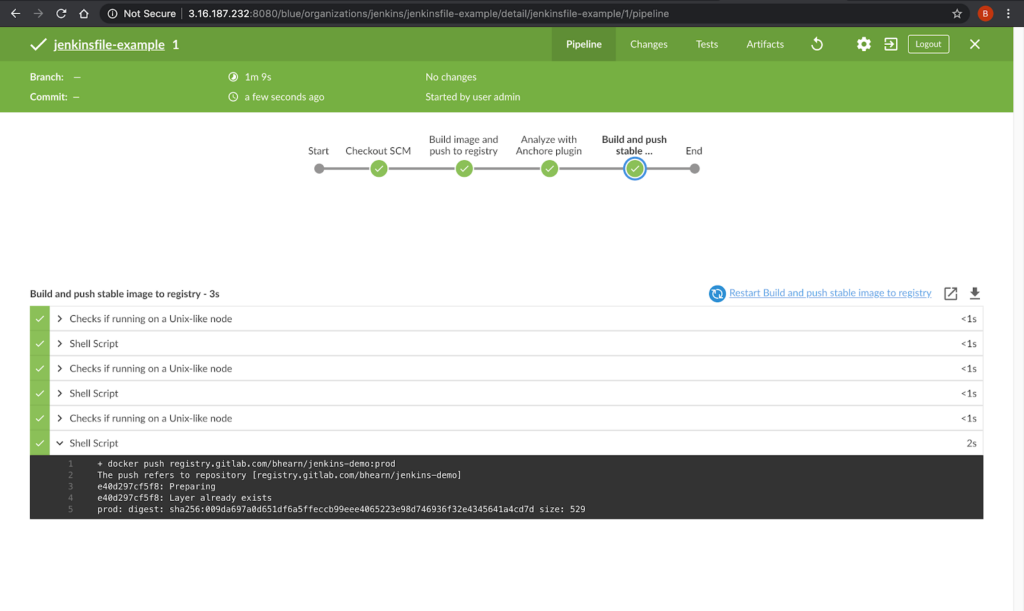
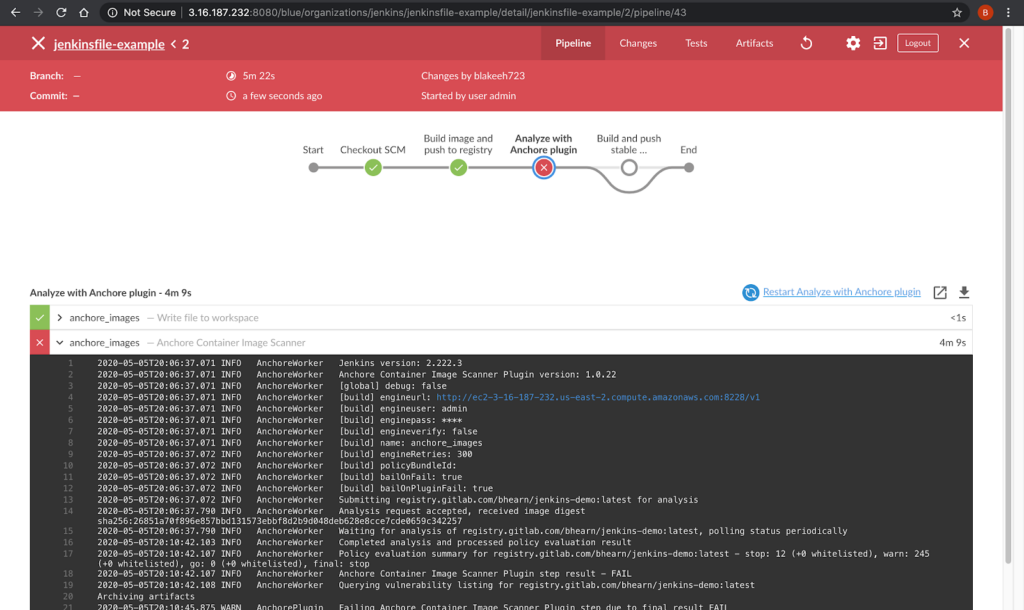
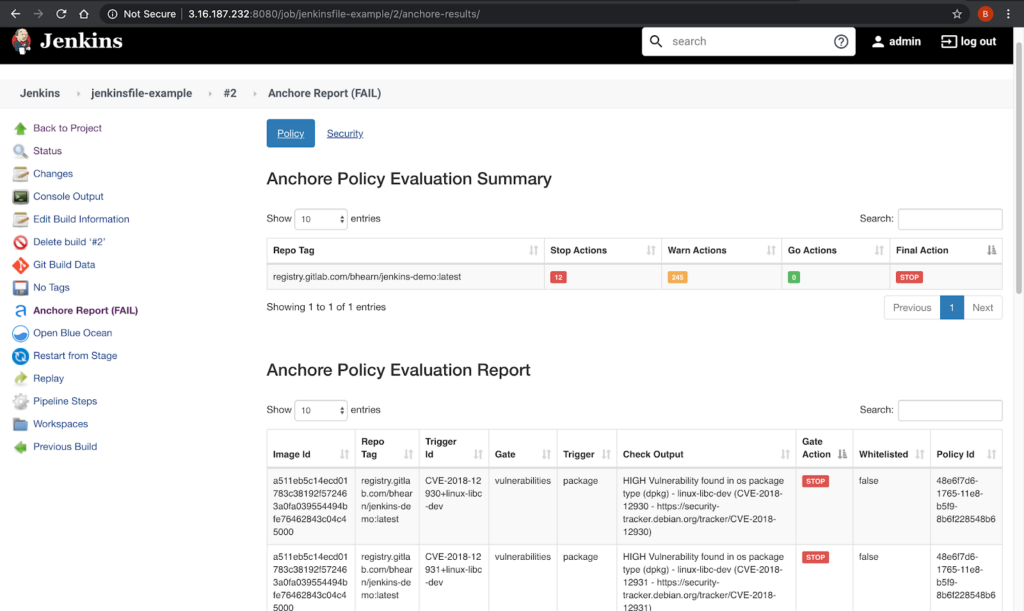
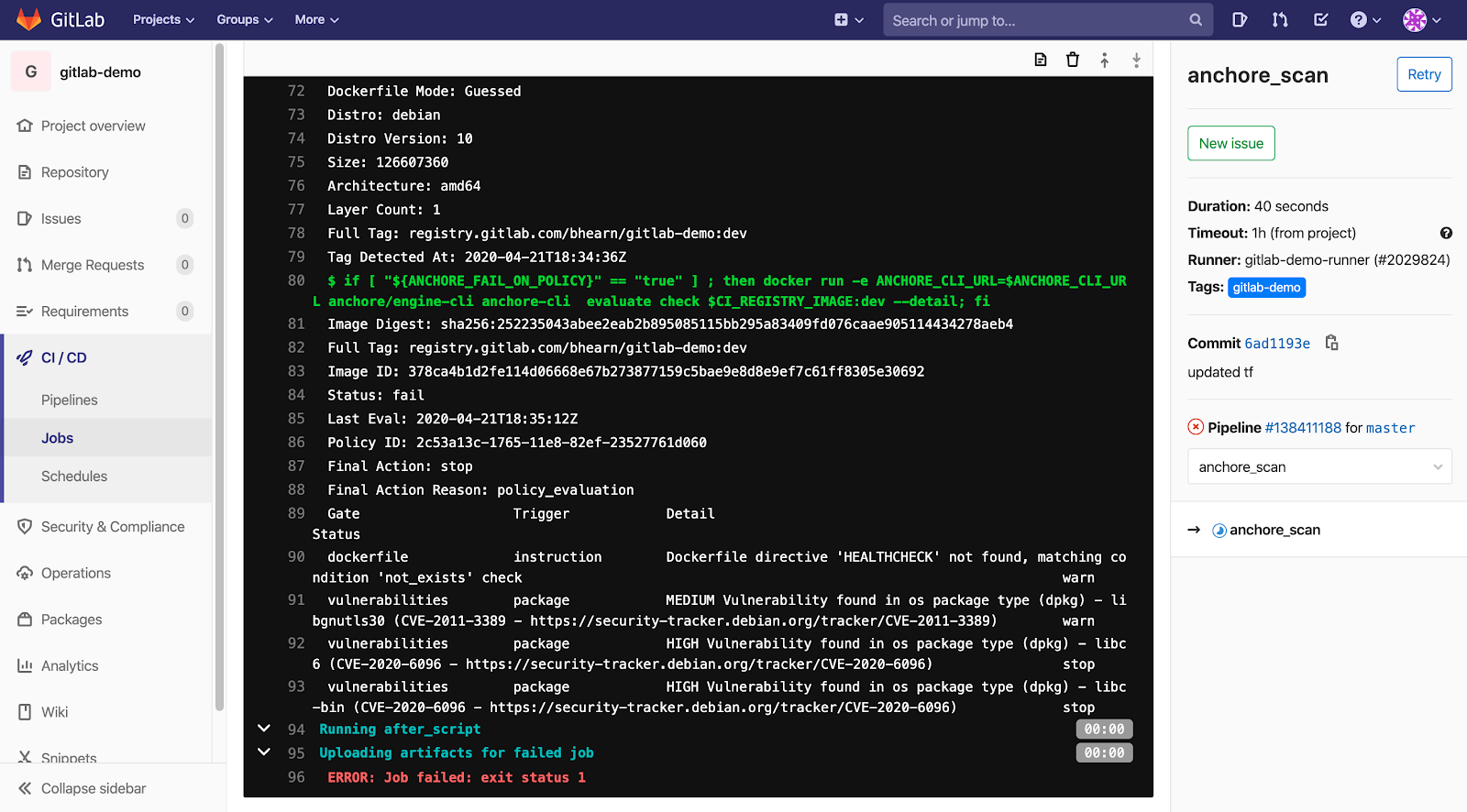
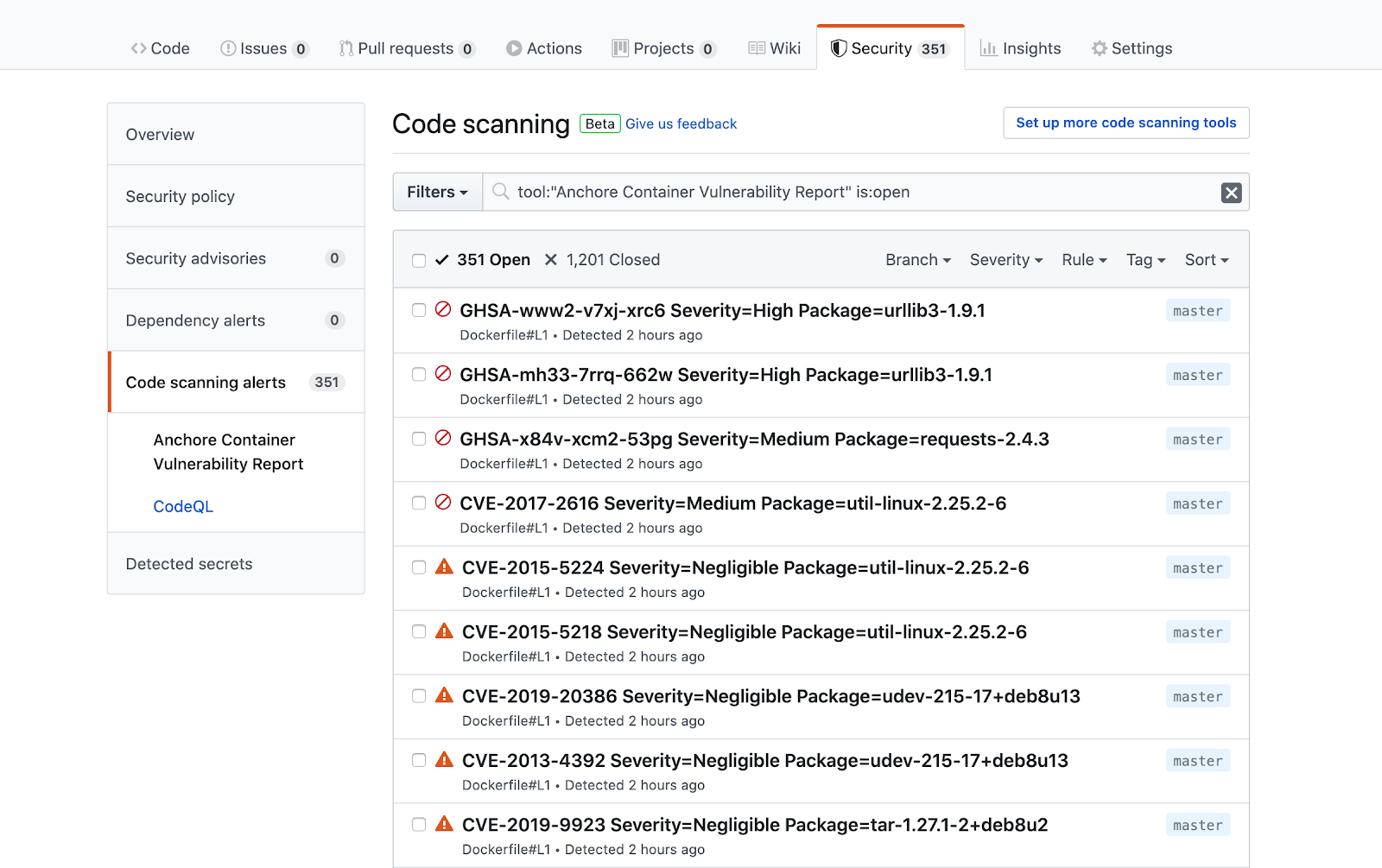
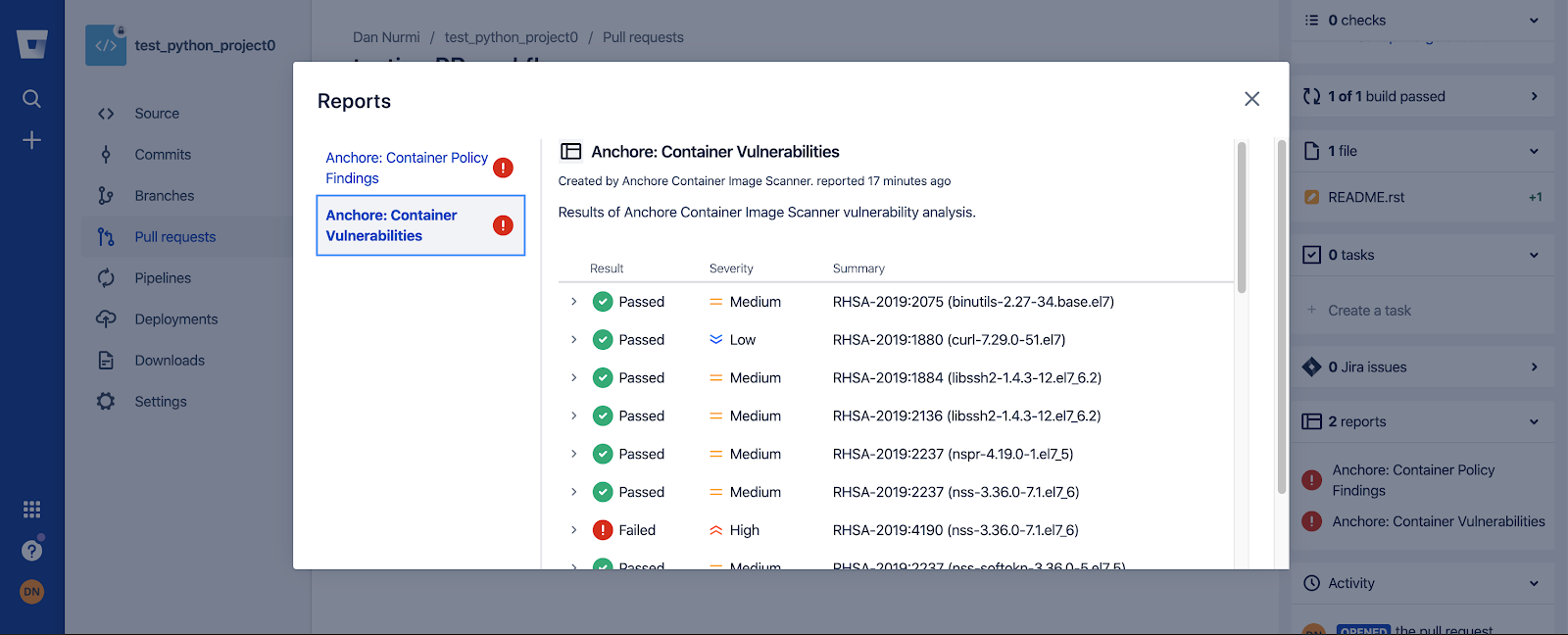
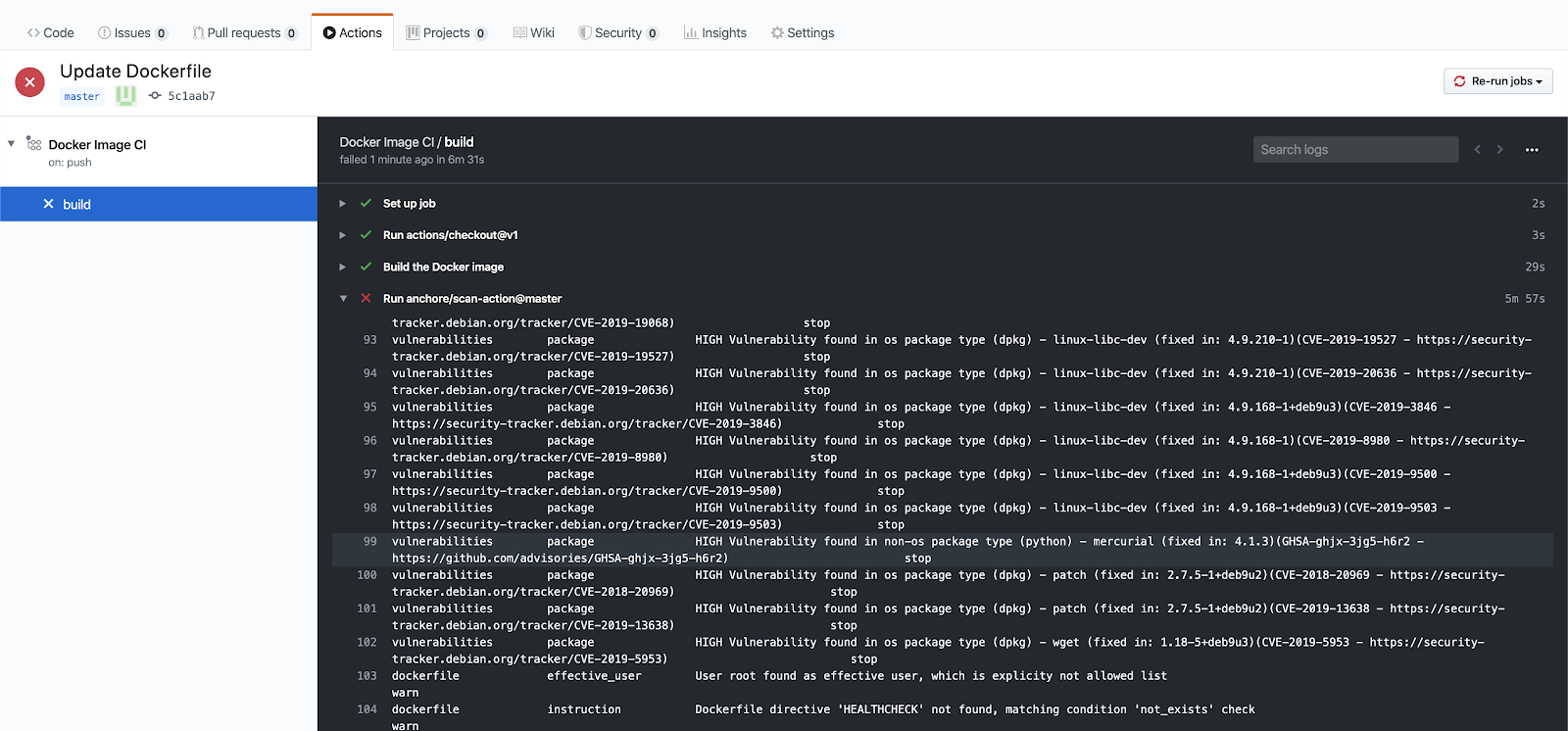
CVE scanning allows developers to be proactive about security as they will get a near-immediate feedback loop on potentially vulnerable images. As developers add container images to the build pipeline, Anchore image scanning will scan the contents of the image to identify any known vulnerabilities in the container images. Taking this a step further, security and development teams can build policies according to security requirements and evaluate each image in the pipeline against these policies. This adds a layer of control to the images being scanned and facilitates the ability to decide which images should be promoted into production environments.
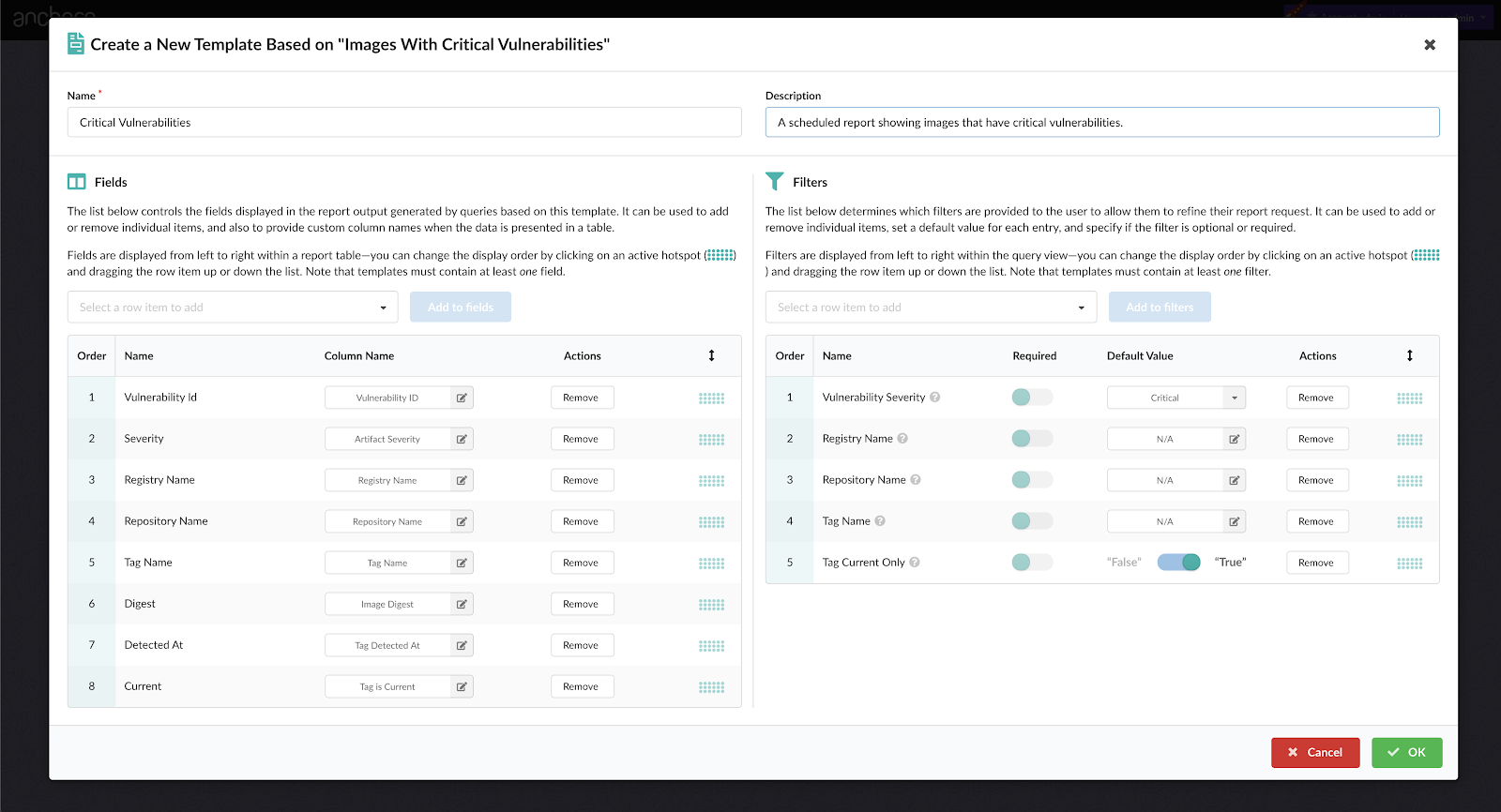
Components of a Policy Bundle
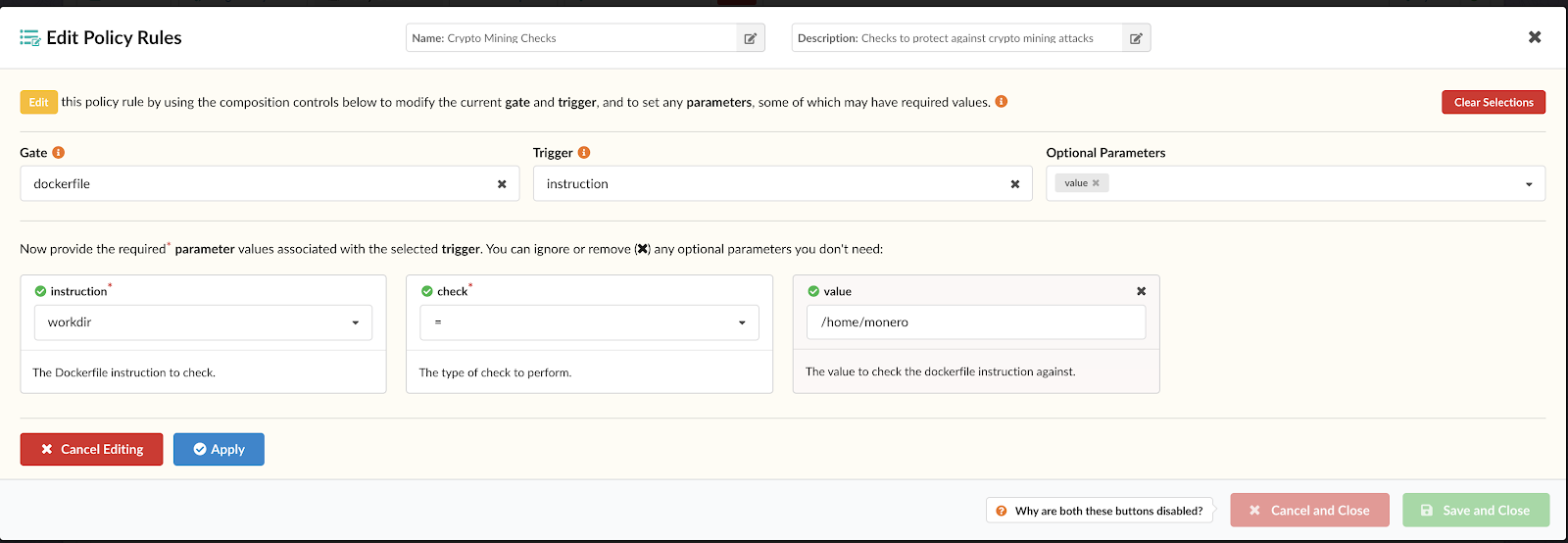
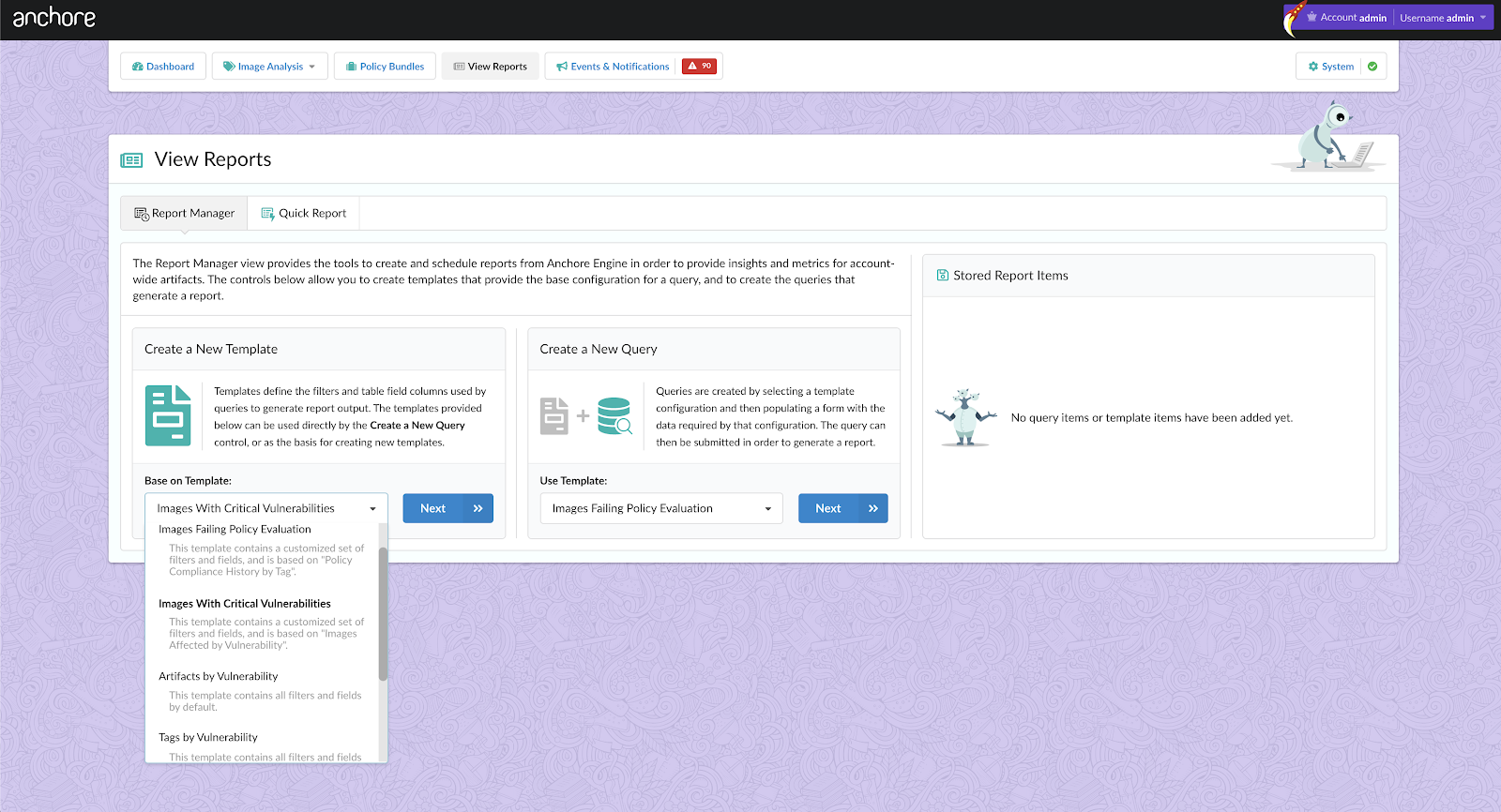
Anchore policy bundles (structured as JSON documents) are essentially the unit of policy definition and evaluation for your organization’s requirements.
A policy bundle consists of:
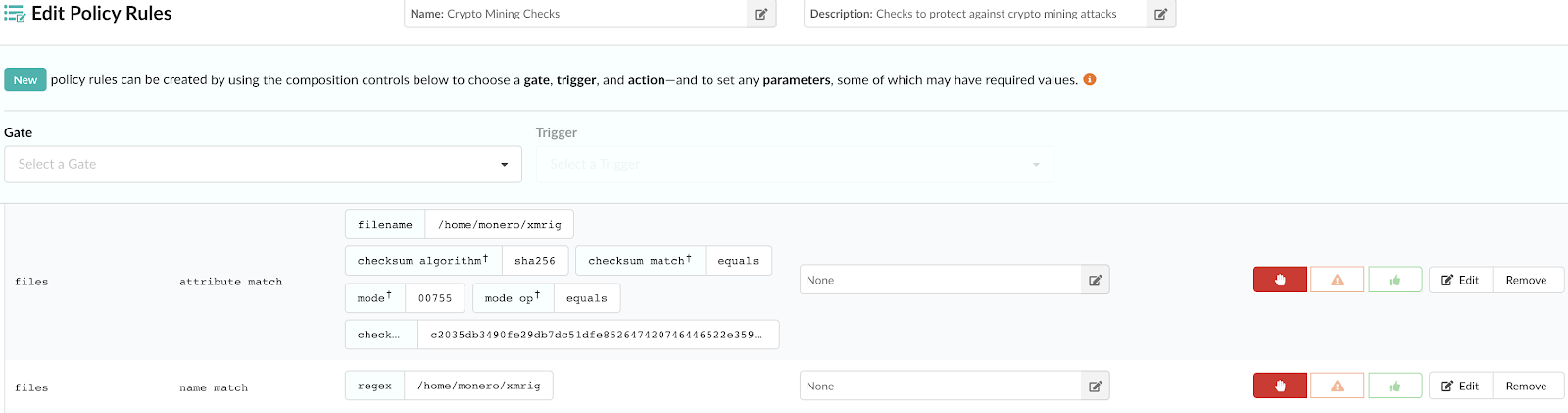
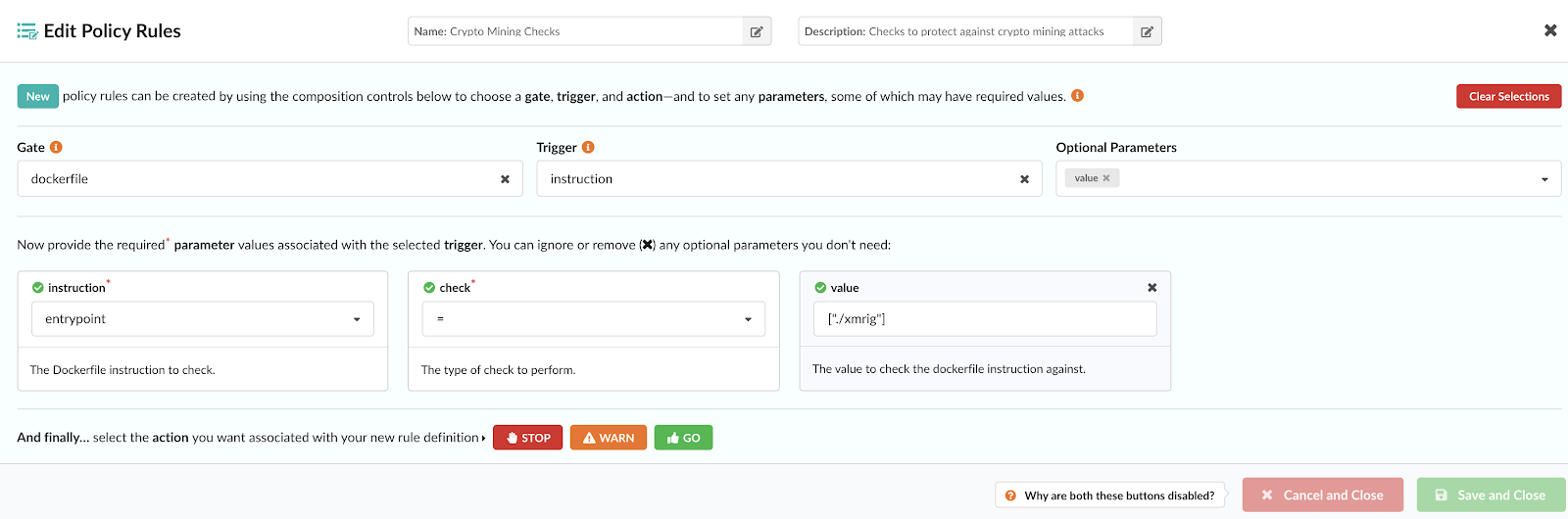
1. Policies: A set of rules to evaluate against an image and recommended actions if a match is found. Detail on these rules can be found in our documentation. A policy or whitelist can be used to evaluate an image against the following criteria:
- Security vulnerabilities
- Package whitelists and blacklists
- Configuration file contents
- Presence of credentials in an image
- Image manifest changes
- Exposed ports
- Anchore policies returning a pass or fail decision result
2. Whitelists: A set of exclusions for matches found during policy evaluation. When a policy rule result is whitelisted, it is still present in the output of the policy evaluation, but it’s action is set to go and it is indicated that there was a whitelist match.
3. Mappings: Ordered rules that determine which policies and whitelists should be applied to a given container registry, repository or image at evaluation. Mappings are evaluated similar to access control lists, where the first rule matching an input is applied and any subsequent rules are ignored.
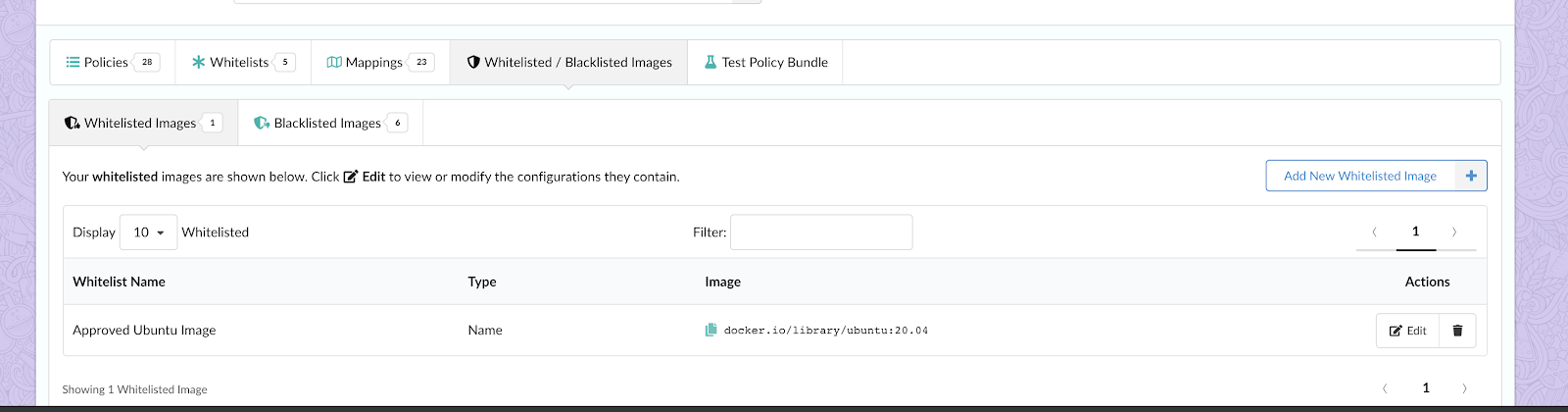
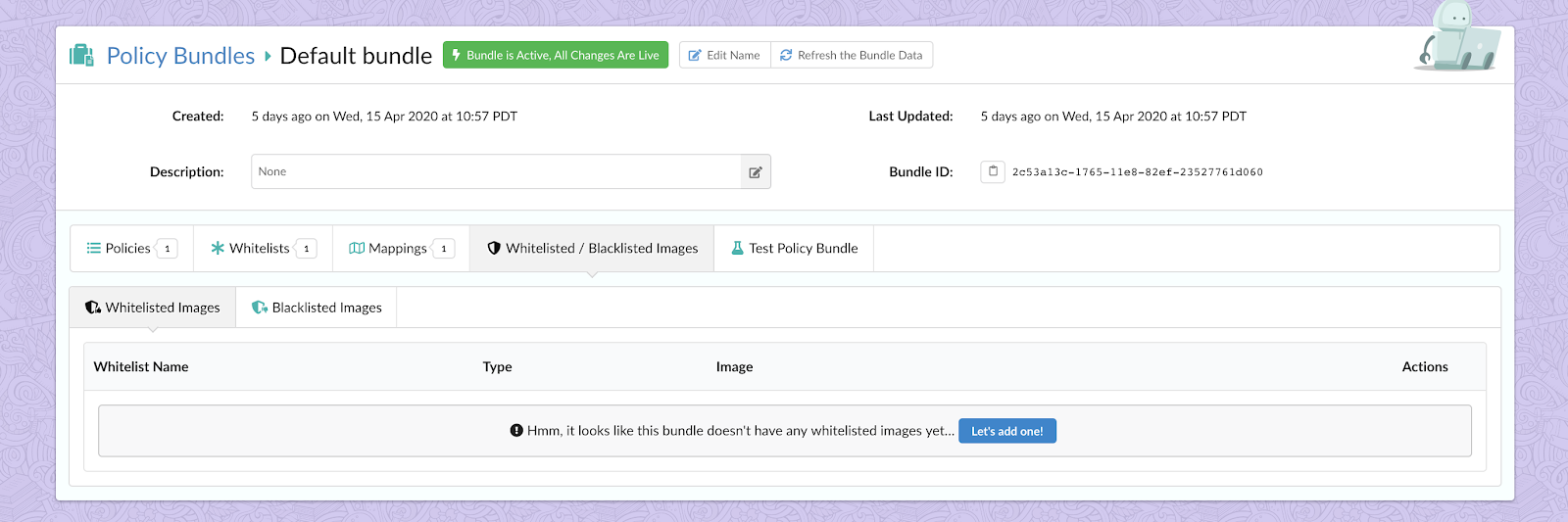
4. Whitelisted Images: Whitelisted images are images, defined by registry, repository, and tag/digest/imageId, that will always result in a pass status for bundle evaluation unless the image is also matched in the blacklisted images section.
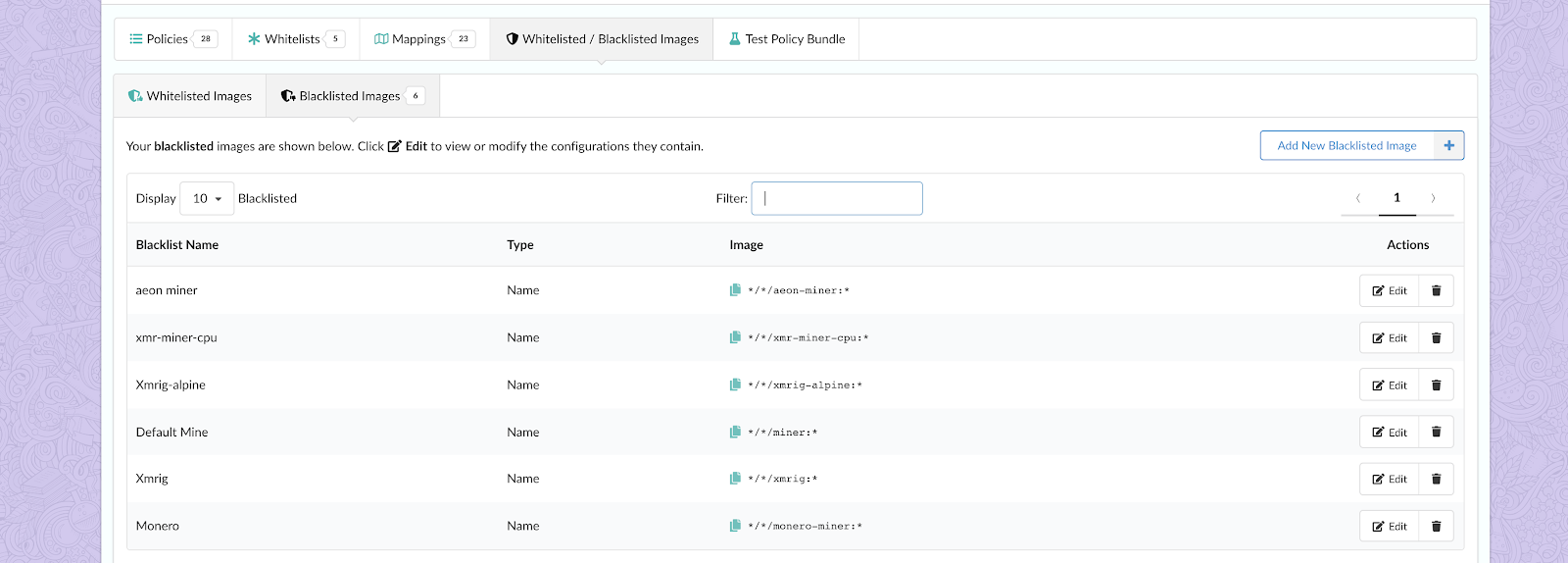
5. Blacklisted Images: Overrides for specific images to statically set the final result of a policy evaluation to fail regardless of the actual evaluation results. Blacklisted image matches override any whitelisted image matches.
Policy Bundle Examples
Now that we’ve discussed the importance of compliance as code and how Anchore can help integrate your requirements into the container pipeline, let’s walk through some examples of how you can enforce security in your container images using Anchore policies.
Ensure a minimal base image is used
Utilizing minimal images that bundle only the necessary system tools and libraries minimizes the attack surface and ensures that you ship a secure OS.
{
"action": "WARN",
"comment": "Ensure dockerfile is provided during analysis",
"gate": "dockerfile",
"params": [],
"trigger": "no_dockerfile_provided"
},
{
"action": "STOP",
"comment": "Ensure a minimal base image is used",
"gate": "dockerfile",
"params": [
{
"name": "instruction",
"value": "FROM"
},
{
"name": "check",
"value": "!="
},
{
"name": "value",
"value": "node:stretch-slim"
},
{
"name": "actual_dockerfile_only",
"value": "false"
}
],
"trigger": "instruction"
}
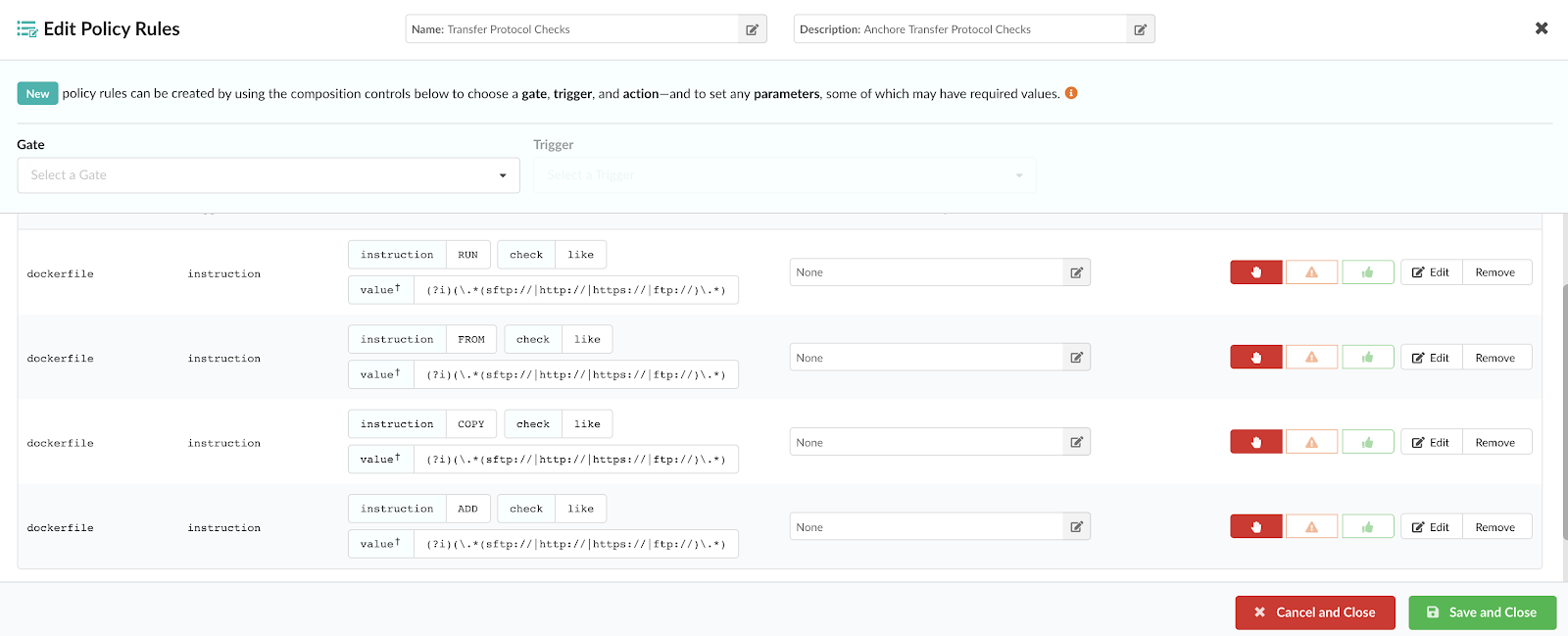
Blacklist exposed ports / ensure sshd is disabled or absent
Your container applications shouldn’t be running an SSH or Telnet server. Checking the dockerfile for explicit management ports can ensure that these services are not exposed while blacklisting their associated packages can provide more enhanced security.
{
"action": "STOP",
"comment": "Blacklist ssh package",
"gate": "packages",
"params": [
{
"name": "name",
"value": "openssh-server"
}
],
"trigger": "blacklist"
},
{
"action": "STOP",
"comment": "Blacklist ssh package",
"gate": "packages",
"params": [
{
"name": "name",
"value": "libssh2"
}
],
"trigger": "blacklist"
},
{
"action": "STOP",
"comment": "Blacklist ssh package",
"gate": "packages",
"params": [
{
"name": "name",
"value": "libssh"
}
],
"trigger": "blacklist"
},
{
"action": "WARN",
"comment": "Ensure openssh configuration files are absent from image",
"gate": "packages",
"params": [
{
"name": "only_packages",
"value": "ssh"
},
{
"name": "only_directories",
"value": "/etc/sshd"
},
{
"name": "check",
"value": "missing"
}
],
"trigger": "verify"
}
Ensure the COPY instruction is used instead of ADD
The COPY instruction copies local files recursively, given explicit source and destination files or directories.
The ADD instruction copies local files recursively, implicitly creates the destination directory if non-existant, and accepts archives as local or remote URLs as its source, which it expands or downloads respectively into the destination directory.
General best practice is to use the COPY command over ADD when copying data to your container image.
{
"action": "STOP",
"comment": "The \"COPY\" instruction should be used instead of \"ADD\"",
"gate": "dockerfile",
"params": [
{
"name": "instruction",
"value": "ADD"
},
{
"name": "check",
"value": "exists"
},
{
"name": "actual_dockerfile_only",
"value": "false"
}
],
"trigger": "instruction"
}
Checking for secrets
Secrets such as API keys and access credentials should never be present in your container image.
Scan images for AWS credentials:
{
"action": "STOP",
"gate": "secret_scans",
"params": [
{
"name": "content_regex_name",
"value": "AWS_ACCESS_KEY"
},
{
"name": "match_type",
"value": "found"
}
],
"trigger": "content_regex_checks"
}
Scan images for API keys:
{
"action": "STOP",
"gate": "secret_scans",
"params": [
{
"name": "content_regex_name",
"value": "API_KEY"
},
{
"name": "match_type",
"value": "found"
}
],
"trigger": "content_regex_checks"
}
Checking for vulnerable packages
Identifying vulnerable packages and dependencies in your container images as early as possible can improve production velocity and ensure your container applications are shipped free of bugs and malicious packages.
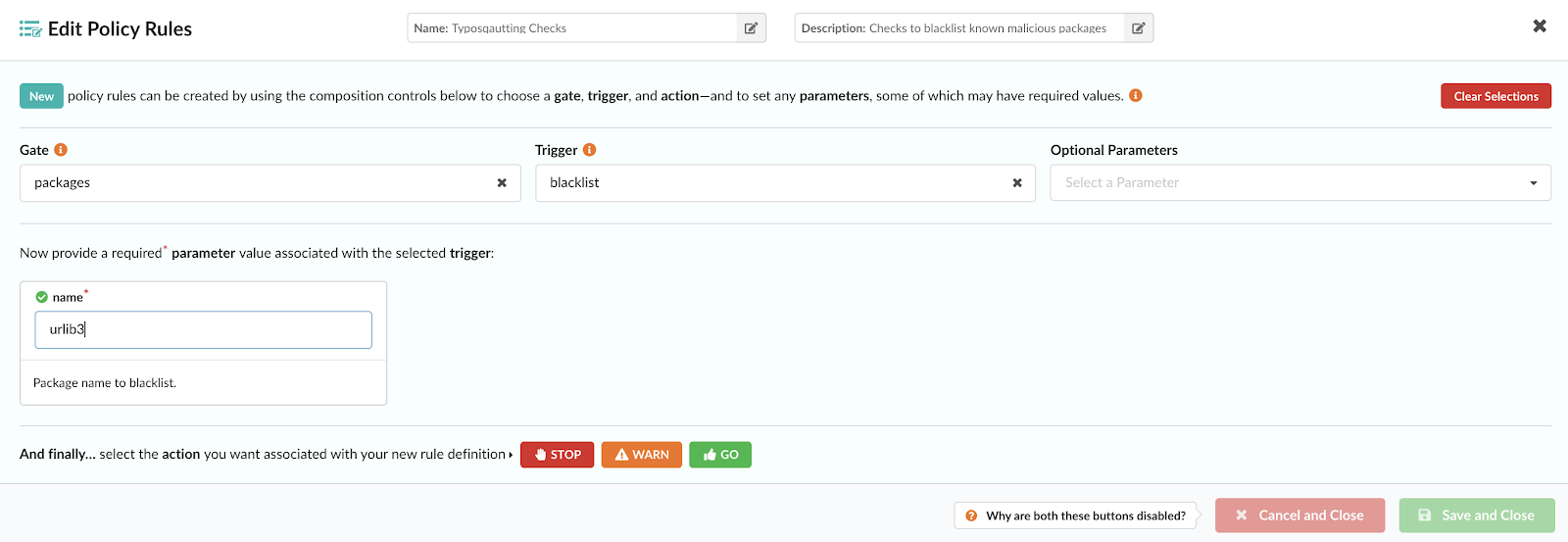
Blacklist malicious package identified as typo-squatting:
{
"action": "STOP",
"comment": "Malicious library discovered [11.29.2019] typosquatting \"jellyfish\"",
"gate": "packages",
"params": [
{
"name": "name",
"value": "jeIlyfish"
}
],
"trigger": "blacklist"
},
{
"action": "STOP",
"comment": "Malicious library discovered [11.29.2019] typosquatting python-dateutil",
"gate": "packages",
"params": [
{
"name": "name",
"value": "python3-dateutil"
}
],
"trigger": "blacklist"
}
Blacklist vulnerable package versions:
{
"action": "STOP",
"comment": "Django 1.11 before 1.11.29, 2.2 before 2.2.11, and 3.0 before 3.0.4 allows SQL Injection if untrusted data is used as a tolerance parameter in GIS functions and aggregates on Oracle.",
"gate": "packages",
"params": [
{
"name": "name",
"value": "Django"
},
{
"name": "version",
"value": "2.2.3"
}
],
"trigger": "blacklist"
},
{
"action": "STOP",
"comment": "A flaw was found in Mercurial before 4.9. It was possible to use symlinks and subrepositories to defeat Mercurial's path-checking logic and write files outside a repository",
"gate": "packages",
"params": [
{
"name": "name",
"value": "mercurial"
},
{
"name": "version",
"value": "4.8.2"
}
],
"trigger": "blacklist"
},
{
"action": "STOP",
"comment": "Python 2.7.x through 2.7.16 and 3.x through 3.7.2 is affected by: Improper Handling of Unicode Encoding (with an incorrect netloc) during NFKC normalization",
"gate": "packages",
"params": [
{
"name": "name",
"value": "Python"
},
{
"name": "version",
"value": "2.7.16"
}
],
"trigger": "blacklist"
}
Remove setuid and setgid permissions
Removal of setuid and setgid permissions can prevent privilege escalation in running containers.
{
"action": "STOP",
"comment": "Remove setuid and setgid permissions in the images",
"gate": "files",
"params": [],
"trigger": "suid_or_guid_set"
}
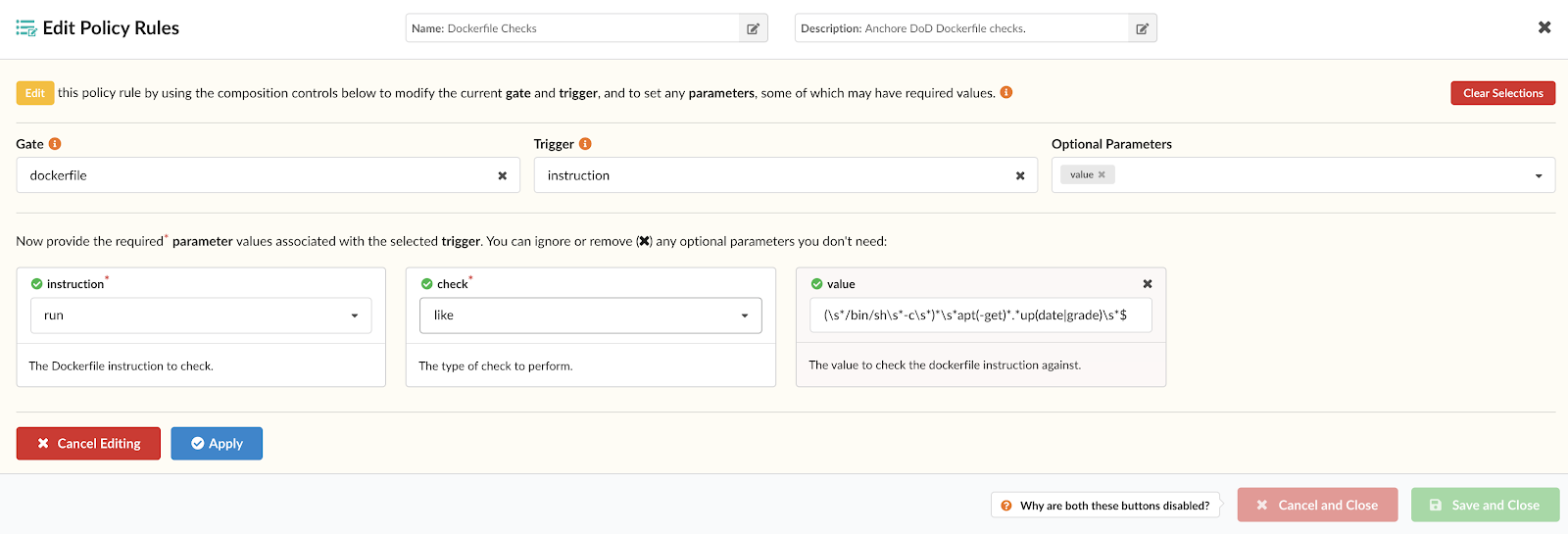
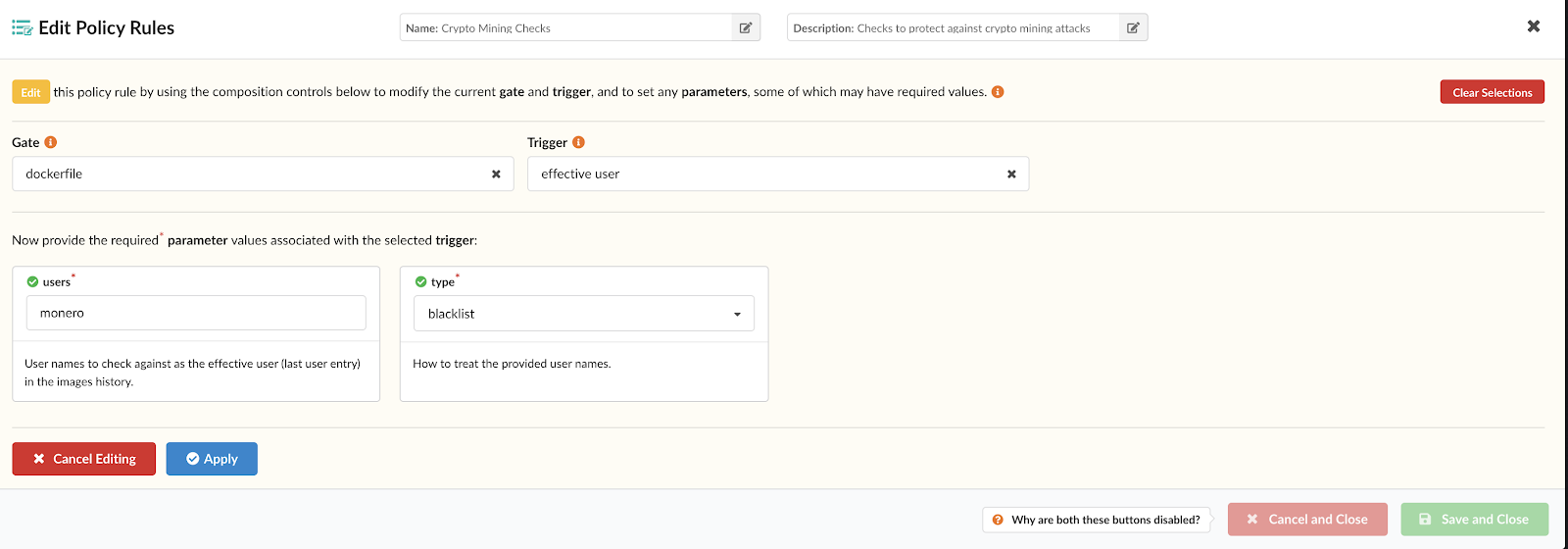
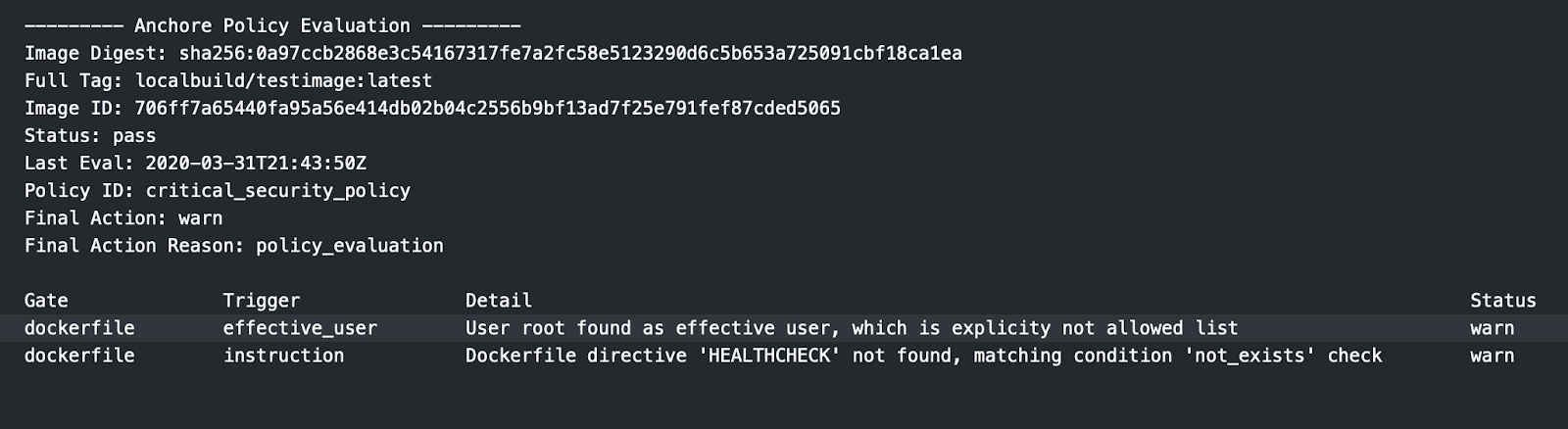
Ensure images implement use of a non-root user (UID not 0)
If not specified in the Dockerfile, a container will be executed as the root user. This is bad practice as it violates least privilege and puts the underlying docker host and any other running containers at risk.
{
"action": "STOP",
"comment": "Blacklist root user (uid 0)",
"gate": "retrieved_files",
"params": [
{
"name": "path",
"value": "/etc/passwd"
},
{
"name": "check",
"value": "match"
},
{
"name": "regex",
"value": "root:x:0:0:root:/root:/bin/bash"
}
],
"trigger": "content_regex"
},
{
"action": "STOP",
"comment": "Ensure user \"root\" is not explicitly referenced in Dockerfile",
"gate": "dockerfile",
"params": [
{
"name": "users",
"value": "root"
},
{
"name": "type",
"value": "blacklist"
}
],
"trigger": "effective_user"
}
Enforce PID Limits
Enforcing PID limits minimizes the number of processes running in each container. Limiting the number of processes in the container prevents excessive spawning of new processes, lateral movement, fork bombs (processes that continually replicate themselves) and anomalous processes.
{
"action": "STOP",
"comment": "Enforce PID Limits",
"gate": "retrieved_files",
"params": [
{
"name": "path",
"value": "/proc/sys/kernel/pid_max"
},
{
"name": "check",
"value": "match"
},
{
"name": "regex",
"value": "256"
}
],
"trigger": "content_regex"
}
Identify unusually large images
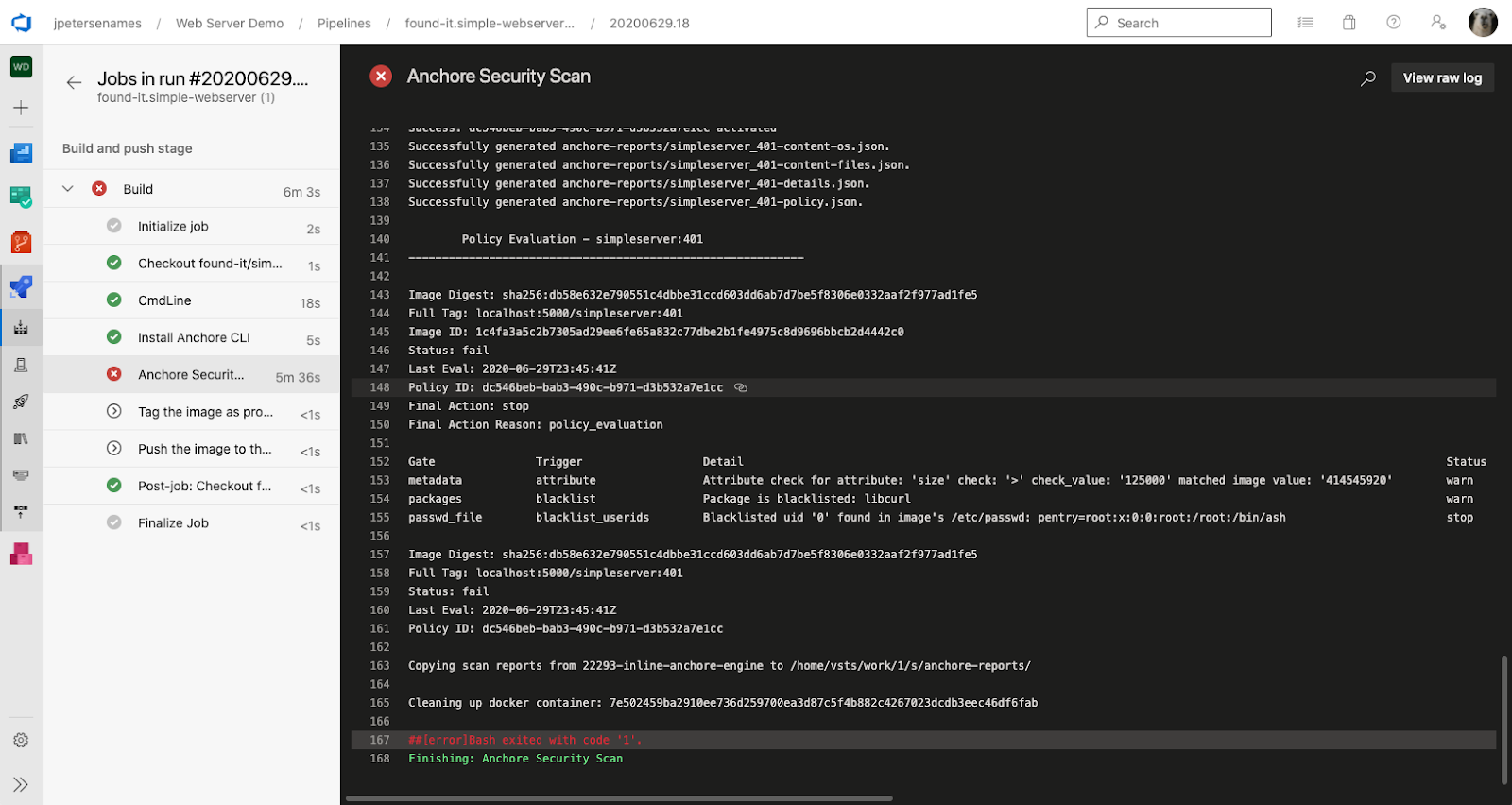
Auditing the size of your container images can help identify any anomalies such unsanctioned packages or files that have been added to the image.
{
"action": "WARN",
"comment": "Warn on image size",
"gate": "metadata",
"params": [
{
"name": "attribute",
"value": "size"
},
{
"name": "check",
"value": ">"
},
{
"name": "value",
"value": "125000"
}
],
"trigger": "attribute"
}
Blacklist unapproved licenses found in a container image
Container images can contain thousands of OS files and packages from open source libraries. Identifying the licenses governing these packages can ensure your organization maintains legal compliance.
{
"action": "WARN",
"comment": "Warn on presence of unapproved licenses",
"gate": "licenses",
"params": [
{
"name": "licenses",
"value": "GPLv2+, GPL-3+"
}
],
"trigger": "blacklist_exact_match"
}
Conclusion
These policies are basic, but can help you get started with Anchore policies. Using them, you can establish a security baseline that improves over time. To learn more, visit our documentation.
The entire policy, when assembled, looks like this:
{
"description": "",
"name": "anchore-policy-blog",
"policies": [
{
"comment": "",
"name": "General Checks",
"rules": [
{
"action": "WARN",
"comment": "Warn on image size",
"gate": "metadata",
"params": [
{
"name": "attribute",
"value": "size"
},
{
"name": "check",
"value": ">"
},
{
"name": "value",
"value": "125000"
}
],
"trigger": "attribute"
},
{
"action": "WARN",
"comment": "Warn on presence of unapproved licenses",
"gate": "licenses",
"params": [
{
"name": "licenses",
"value": "GPLv2+, GPL-3+"
}
],
"trigger": "blacklist_exact_match"
}
],
"version": "1_0"
},
{
"comment": "",
"name": "File System Checks",
"rules": [
{
"action": "STOP",
"comment": "Remove setuid and setgid permissions in the images",
"gate": "files",
"params": [],
"trigger": "suid_or_guid_set"
},
{
"action": "STOP",
"comment": "Blacklist root user (uid 0)",
"gate": "passwd_file",
"params": [
{
"name": "user_ids",
"value": "0"
}
],
"trigger": "blacklist_userids"
},
{
"action": "STOP",
"comment": "Blacklist ssh package",
"gate": "packages",
"params": [
{
"name": "name",
"value": "openssh-server"
}
],
"trigger": "blacklist"
},
{
"action": "STOP",
"comment": "Blacklist ssh package",
"gate": "packages",
"params": [
{
"name": "name",
"value": "libssh2"
}
],
"trigger": "blacklist"
},
{
"action": "STOP",
"comment": "Blacklist ssh package",
"gate": "packages",
"params": [
{
"name": "name",
"value": "libssh"
}
],
"trigger": "blacklist"
},
{
"action": "WARN",
"comment": "Ensure openssh configuration files are absent from image",
"gate": "packages",
"params": [
{
"name": "only_packages",
"value": "ssh"
},
{
"name": "only_directories",
"value": "/etc/sshd"
},
{
"name": "check",
"value": "missing"
}
],
"trigger": "verify"
},
{
"action": "STOP",
"comment": "Enforce PID Limits",
"gate": "retrieved_files",
"params": [
{
"name": "path",
"value": "/proc/sys/kernel/pid_max"
},
{
"name": "check",
"value": "match"
},
{
"name": "regex",
"value": "256"
}
],
"trigger": "content_regex"
}
],
"version": "1_0"
},
{
"comment": "Blacklist vulnerable packages",
"name": "Vulnerable Packages",
"rules": [
{
"action": "STOP",
"comment": "Django 1.11 before 1.11.29, 2.2 before 2.2.11, and 3.0 before 3.0.4 allows SQL Injection if untrusted data is used as a tolerance parameter in GIS functions and aggregates on Oracle.",
"gate": "packages",
"params": [
{
"name": "name",
"value": "Django"
},
{
"name": "version",
"value": "2.2.3"
}
],
"trigger": "blacklist"
},
{
"action": "STOP",
"comment": "A flaw was found in Mercurial before 4.9. It was possible to use symlinks and subrepositories to defeat Mercurial's path-checking logic and write files outside a repository",
"gate": "packages",
"params": [
{
"name": "name",
"value": "mercurial"
},
{
"name": "version",
"value": "4.8.2"
}
],
"trigger": "blacklist"
},
{
"action": "STOP",
"comment": "Python 2.7.x through 2.7.16 and 3.x through 3.7.2 is affected by: Improper Handling of Unicode Encoding (with an incorrect netloc) during NFKC normalization",
"gate": "packages",
"params": [
{
"name": "name",
"value": "Python"
},
{
"name": "version",
"value": "2.7.16"
}
],
"trigger": "blacklist"
}
],
"version": "1_0"
},
{
"comment": "Blacklist malicious package types",
"name": "Malicious Packages",
"rules": [
{
"action": "STOP",
"comment": "Malicious library discovered [11.29.2019] typosquatting \"jellyfish\"",
"gate": "packages",
"params": [
{
"name": "name",
"value": "jeIlyfish"
}
],
"trigger": "blacklist"
},
{
"action": "STOP",
"comment": "Malicious library discovered [11.29.2019] typosquatting python-dateutil",
"gate": "packages",
"params": [
{
"name": "name",
"value": "python3-dateutil"
}
],
"trigger": "blacklist"
}
],
"version": "1_0"
},
{
"comment": "Dockerfile security checks",
"name": "Dockerfile Checks",
"rules": [
{
"action": "STOP",
"comment": "The \"COPY\" instruction should be used instead of \"ADD\"",
"gate": "dockerfile",
"params": [
{
"name": "instruction",
"value": "ADD"
},
{
"name": "check",
"value": "exists"
},
{
"name": "actual_dockerfile_only",
"value": "false"
}
],
"trigger": "instruction"
},
{
"action": "STOP",
"comment": "Blacklist SSH & Telnet ports",
"gate": "dockerfile",
"params": [
{
"name": "ports",
"value": "22,23"
},
{
"name": "type",
"value": "blacklist"
},
{
"name": "actual_dockerfile_only",
"value": "false"
}
],
"trigger": "exposed_ports"
},
{
"action": "STOP",
"comment": "Ensure dockerfile is provided during analysis",
"gate": "dockerfile",
"params": [],
"trigger": "no_dockerfile_provided"
},
{
"action": "STOP",
"comment": "Ensure a minimal base image is used",
"gate": "dockerfile",
"params": [
{
"name": "instruction",
"value": "FROM"
},
{
"name": "check",
"value": "!="
},
{
"name": "value",
"value": "node:stretch-slim"
},
{
"name": "actual_dockerfile_only",
"value": "false"
}
],
"trigger": "instruction"
}
],
"version": "1_0"
}
],
"version": "1_0"
}


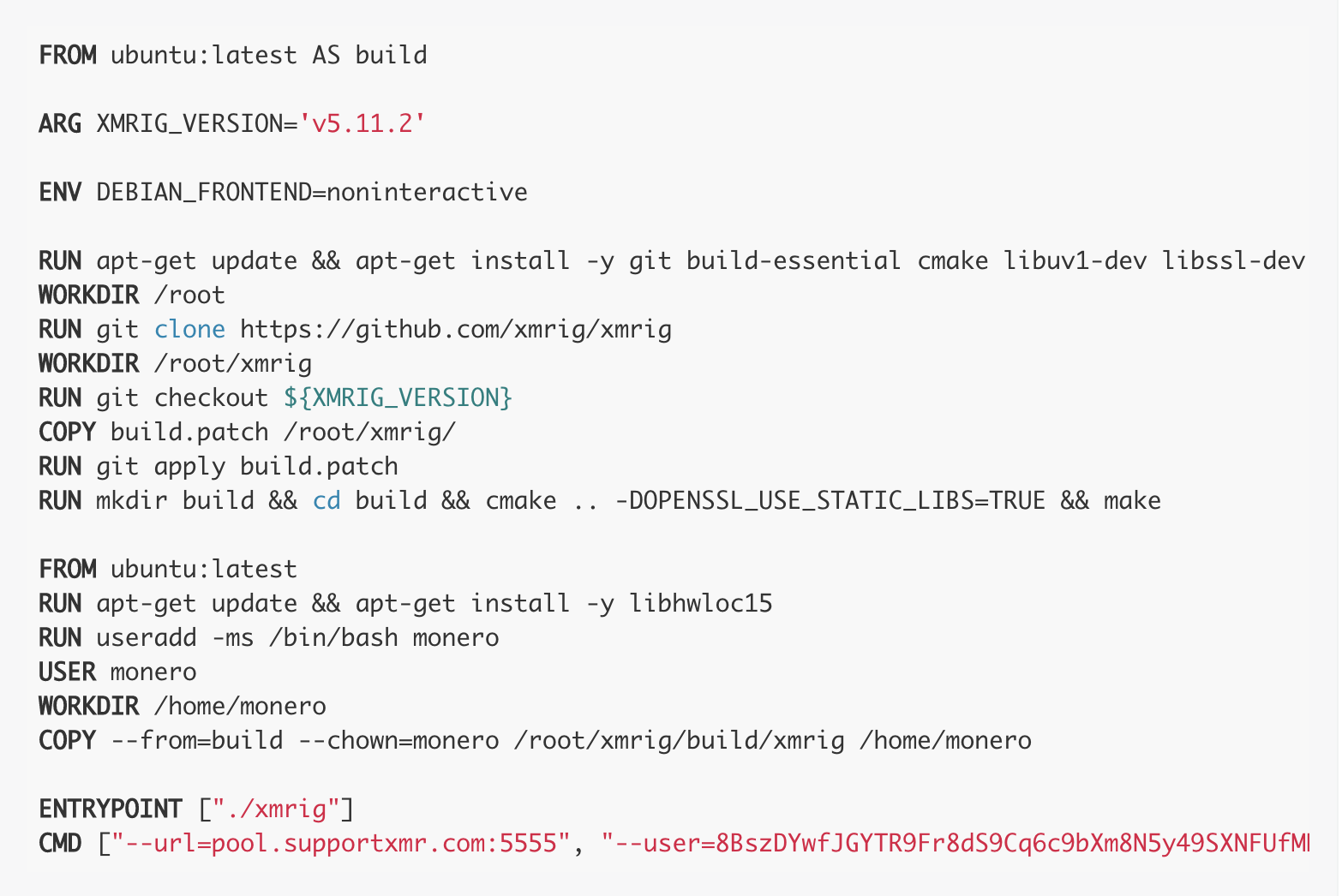
 It all started with a fish tank… You don’t hear that often, but for Anchore employees
It all started with a fish tank… You don’t hear that often, but for Anchore employees 









{kind=link}